分布式搜索elasticsearch概念
什么是elasticsearch?
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容

目录
elasticsearch的场景
elasticsearch的发展
Lucene篇
Elasticsearch篇
elasticsearch的安装
elasticsearch的场景
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack (ELK)。被广泛应用在日志数据分析、实时监控等领域。

elasticsearch是elastic stack的核心,负责存储、搜索、分析数据
elasticsearch的发展
Lucene篇
Lucene是一个ava语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。
官网地址: https://lucene.apache.org/
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
Lucene的缺点:
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
Elasticsearch篇
2004年ShayBanon基于Lucene开发了Compass。
2010年shay Banon 重写了Compass,取名为Elasticsearch。
目前最新的版本是:7.12.1
官网地址: https://www.elastic.co/cn/
相比与lucene,elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
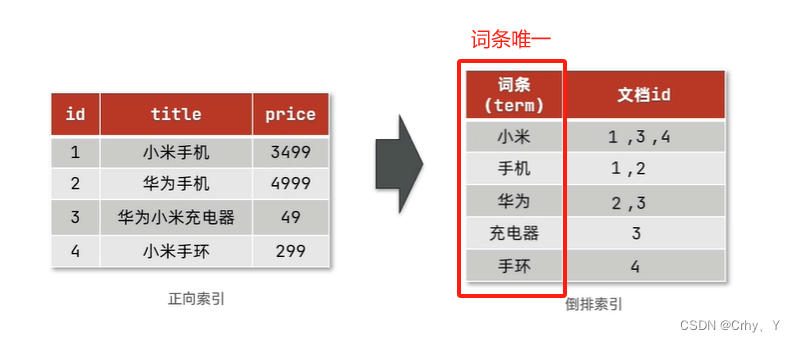
正排索引 与 倒排索引(Elasticsearch)
传统数据库(如MySQL)采用正向索引,例如给下表(tb goods)中的id创建索引

搜索'title'字段,'手机' 的内容 👉 select *from tb_goods where title like %手机%

正排索引:当模糊查询某字段时会逐一检索所有记录,效率较低
elasticsearch采用倒排索引
- 文档(document):每条数据就是一个文档(相对于Mysql,一个mysql表就是一个文档)
- 词条(term):文档按照语义分成的词语(记录文档中的关键词)
例:搜索'华为手机'(根据索引查询效率增加)
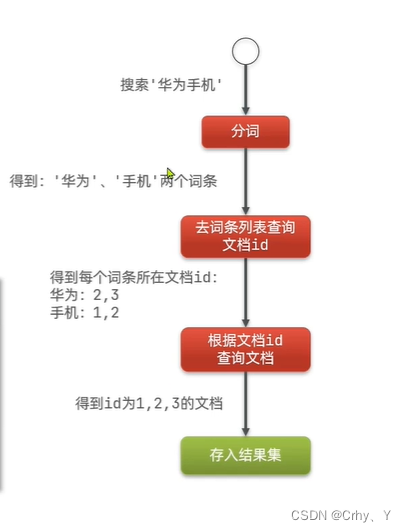
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包
- 含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
相关文章:
分布式搜索elasticsearch概念
什么是elasticsearch? elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容 目录 elasticsearch的场景 elasticsearch的发展 Lucene篇 Elasticsearch篇 elasticsearch的安装 elasticsearch的场景 elasticsear…...

Linux环境安装Hadoop
(1)下载Hadoop安装包并上传 下载Hadoop安装包到本地,并导入到Linux服务器的/opt/software路径下 (2)解压安装包 解压安装文件并放到/opt/module下面 [roothadoop100 ~]$ cd /opt/software [roothadoop100 software…...
swing快速入门(二十五)
注释很详细,直接上代码 新增内容 1.ImageIO.write读取并显示图片 2.ImageIO.writeImageIO.write读取并保存图片 package swing21_30;import javax.imageio.ImageIO; import java.awt.*; import java.awt.event.WindowAdapter; import java.awt.event.WindowEvent…...

智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.卷尾猴算法4.实验参数设定5.算法结果6.参考文…...
前端传输formDate格式的数据,后端不能用@RequestBody接收
写了个接口,跟前端对接,前端说怎么一直415的报错 我寻思不对啊,我swagger都请求成功了,后来发现前端一直是以formdata格式提交的数据,这样我其实是可以不加RequestBody的; 知识点: RequestBody…...

【AivaAI】做音乐,无人能比它更专业
关于Aiva Aiva AIVA是音乐制作初创公司AIVA Technologies打造的一款人工智能产品。是人工智能领域头款获得国际认证的虚拟作曲家。 Aiva登录 可以选择Google登录,或者其他邮箱登录。 输入用户名,登录完成。 开始制作音乐 在主页选择“创建曲目…...

嵌入式开发网络配置——windows连热点,开发板和电脑网线直连
目录 电脑 WiFi 上网,开发板和电脑直连 使用场景 设置VMware虚拟机的网络配置 Ubuntu设置——版本18.04 编辑 windows设置 开发板设置 原因:虚拟机Linux移植可执行程序到开发板失败 最后发现虚拟机的Linuxping不通开发板 下面是我的解决方法 …...
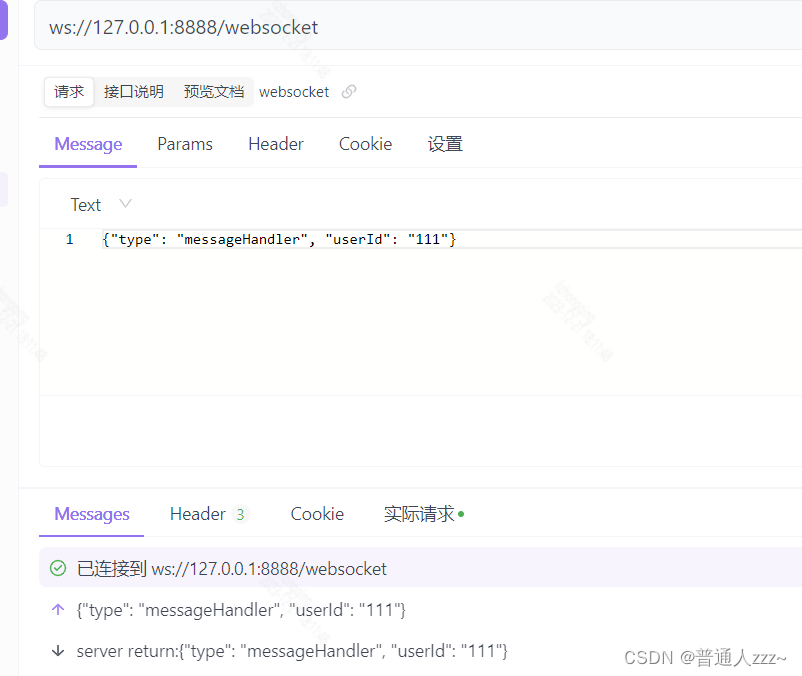
基于Netty构建Websocket服务端
除了构建TCP和UDP服务器和客户端,Netty还可以用于构建WebSocket服务器。WebSocket是一种基于TCP协议的双向通信协议,可以在Web浏览器和Web服务器之间建立实时通信通道。下面是一个简单的示例,演示如何使用Netty构建一个WebSocket服务器。 项目…...

基于Rocket MQ扩展的无限延迟消息队列
基于Rocket MQ扩展的无限延迟消息队列 背景: Rocket MQ支持的延迟队列时间是固定间隔的, 默认19个等级(包含0等级): 0s, 1s, 5s, 10s, 30s, 1m, 2m, 3m, 4m, 5m, 6m, 7m, 8m, 9m, 10m, 20m, 30m, 1h. 我们的需求是实现用户下单后48小时或72小时给用户发送逼单邮件. 使用默认的…...

Python办公自动化 – 日志分析和自动化FTP操作
Python办公自动化 – 日志分析和自动化FTP操作 以下是往期的文章目录,需要可以查看哦。 Python办公自动化 – Excel和Word的操作运用 Python办公自动化 – Python发送电子邮件和Outlook的集成 Python办公自动化 – 对PDF文档和PPT文档的处理 Python办公自动化 – 对…...

MyBatis 关联查询
目录 一、一对一查询(sqlMapper配置文件) 1、需求: 2、创建account和user实体类 3、创建AccountMapper 接口 4、创建并配置AccountMapper.xml 5、测试 二、一对多查询(sqlMapper配置文件) 1、需求:…...

NVIDIA NCCL 源码学习(十二)- double binary tree
上节我们以ring allreduce为例看到了集合通信的过程,但是随着训练任务中使用的gpu个数的扩展,ring allreduce的延迟会线性增长,为了解决这个问题,NCCL引入了tree算法,即double binary tree。 double binary tree 朴素…...
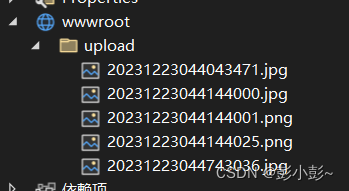
.net core webapi 大文件上传到wwwroot文件夹
1.配置staticfiles(program文件中) app.UseStaticFiles();2.在wwwroot下创建upload文件夹 3.返回结果封装 namespace webapi;/// <summary> /// 统一数据响应格式 /// </summary> public class Results<T> {/// <summary>/// 自定义的响应码ÿ…...
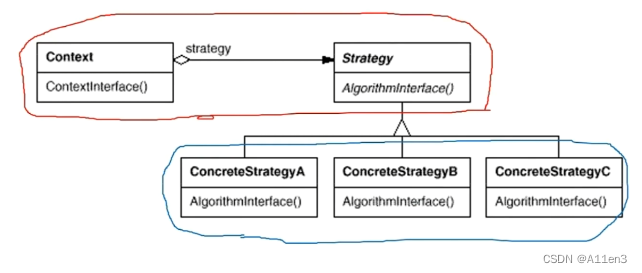
C++设计模式 #3策略模式(Strategy Method)
动机 在软件构建过程中,某些对象使用的的算法可能多种多样,经常改变。如果将这些算法都写在类中,会使得类变得异常复杂;而且有时候支持不频繁使用的算法也是性能负担。 如何在运行时根据需求透明地更改对象的算法?将…...

金融知识——OMS、EMS和PMS分别是什么意思
金融知识——OMS、EMS和PMS分别是什么意思 OMSEMSPMS OMS OMS(Order Management System)是为了管理头寸,以多种方式创建订单,并进行订单屈从检验以使得用户在订单创建时收到一些约束。在交易管理方面,OMS提供交易组合…...

Docker——微服务的部署
Docker——微服务的部署 文章目录 Docker——微服务的部署初识DockerDocker与虚拟机Docker架构安装DockerCentOS安装Docker卸载(可选)安装docker启动docker配置镜像加速 Docker的基本操作Docker的基本操作——镜像Docker基本操作——容器Docker基本操作—…...

AI时代架构设计新模式
云原生架构原则 云原生架构本身作为一种架构,也有若干架构原则作为应用架构的核心架构控制面,通过遵从这些架构原则可以让技术主管和架构师在做技术选择时不会出现大的偏差。 服务化原则 当代码规模超出小团队的合作范围时,就有必要进行服务…...

速盾网络:高防IP的好处
随着互联网的快速发展,网络安全问题日益突出,越来越多的企业和个人开始关注网络安全防护。其中,高防IP作为一种高效的防御手段,越来越受到用户的青睐。本文将介绍速盾网络高防IP的好处,帮助您了解其优势和应用场景。一…...

创建Maven Web工程
目录下也会有对应的生命周期。其中常用的是:clean、compile、package、install。 比如这里install ,如果其他项目需要将这里的模块作为依赖使用,那就可以 install 。安装到本地仓库的位置: Java的Web工程,所以我们要选…...
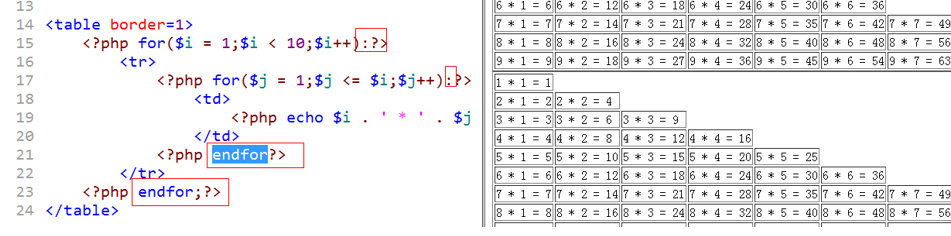
【PHP入门】2.2 流程控制
-流程控制- 流程控制:代码执行的方向 2.2.1控制分类 顺序结构:代码从上往下,顺序执行。(代码执行的最基本结构) 分支结构:给定一个条件,同时有多种可执行代码(块)&am…...

基于MCP协议构建AI智能体记忆系统:mnemo-mcp实战指南
1. 项目概述:一个为AI记忆而生的开源工具最近在折腾AI应用开发,特别是围绕大语言模型(LLM)构建智能体(Agent)时,一个绕不开的痛点就是“记忆”。模型本身没有持久化记忆,每次对话都是…...

LuckyLilliaBot终极指南:一站式构建跨协议QQ机器人的完整解决方案
LuckyLilliaBot终极指南:一站式构建跨协议QQ机器人的完整解决方案 【免费下载链接】LuckyLilliaBot 支持 OneBot 11、Satori 和 Milky 协议 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot 还在为QQ机器人开发中协议不兼容、功能单一而烦恼吗&…...

037、LVGL动画类型与参数配置
LVGL动画类型与参数配置 上周帮一个做智能家居面板的客户调试,遇到个挺典型的坑:他用了lv_anim_set_path_cb()自定义了一个缓动曲线,结果动画跑起来像抽风一样忽快忽慢。我让他把回调函数贴出来一看——好家伙,路径函数里直接调了lv_anim_set_time()改时长。这种在动画执行…...

openclaw-route-check:多协议路由诊断工具的原理、安装与实战应用
1. 项目概述与核心价值最近在折腾一些需要跨地域、跨网络环境访问的服务时,路由问题总是最让人头疼的环节。你可能也遇到过类似情况:明明服务部署在A地,从B地访问时延迟高得离谱,或者干脆时通时不通,排查起来像大海捞针…...

Miniblink49深度解析:如何用6MB浏览器内核重构你的桌面应用架构
Miniblink49深度解析:如何用6MB浏览器内核重构你的桌面应用架构 【免费下载链接】miniblink49 a lighter, faster browser kernel of blink to integrate HTML UI in your app. 一个小巧、轻量的浏览器内核,用来取代wke和libcef 项目地址: https://git…...

使用 Taotoken 后如何通过用量看板清晰掌握各模型消耗与成本分布
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后如何通过用量看板清晰掌握各模型消耗与成本分布 当你在项目中接入多个大模型时,一个常见的困扰是成本…...

开源桌面宠物应用开发指南:从原理到实践
1. 项目概述:一个开源的桌面宠物应用 最近在逛GitHub的时候,发现了一个挺有意思的开源项目,叫“openclaw-desktop-pet”。简单来说,它就是一个可以让你在电脑桌面上养一只小宠物的应用。这只宠物不是静态的图片,而是一…...
)
手把手教你用rtsp-simple-server和FFmpeg在Windows上搭建个人视频流媒体服务器(保姆级教程)
手把手教你用rtsp-simple-server和FFmpeg在Windows上搭建个人视频流媒体服务器 在数字化生活日益普及的今天,个人视频流媒体服务器的需求正在快速增长。无论是想搭建家庭监控系统原型,还是为开发项目创建测试环境,亦或是单纯出于技术爱好探索…...

WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案
WechatSogou微信公众号爬虫实战指南:高效获取公众号数据的Python解决方案 【免费下载链接】WechatSogou 基于搜狗微信搜索的微信公众号爬虫接口 项目地址: https://gitcode.com/gh_mirrors/we/WechatSogou 在信息爆炸的时代,微信公众号已成为内容…...
Spring Boot TransactionTemplate 实战:从声明式到编程式事务的进阶指南
1. 为什么需要编程式事务? 在Spring Boot开发中,事务管理就像给数据库操作上的保险。我们最熟悉的Transactional注解确实方便,就像自动驾驶模式——简单标注一下,Spring就会自动帮我们处理事务的开启、提交和回滚。但实际开发中总…...