竞赛保研 基于LSTM的天气预测 - 时间序列预测
0 前言
🔥 优质竞赛项目系列,今天要分享的是
机器学习大数据分析项目
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据集介绍
df = pd.read_csv(‘/home/kesci/input/jena1246/jena_climate_2009_2016.csv’)
df.head()
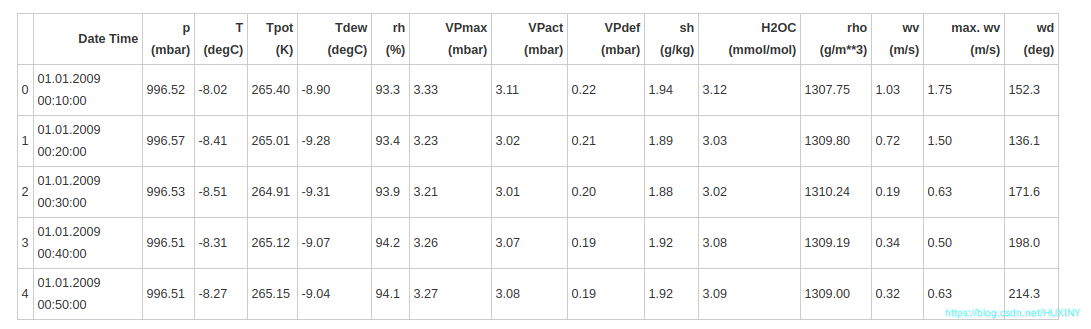
如上所示,每10分钟记录一次观测值,一个小时内有6个观测值,一天有144(6x24)个观测值。
给定一个特定的时间,假设要预测未来6小时的温度。为了做出此预测,选择使用5天的观察时间。因此,创建一个包含最后720(5x144)个观测值的窗口以训练模型。
下面的函数返回上述时间窗以供模型训练。参数 history_size 是过去信息的滑动窗口大小。target_size
是模型需要学习预测的未来时间步,也作为需要被预测的标签。
下面使用数据的前300,000行当做训练数据集,其余的作为验证数据集。总计约2100天的训练数据。
def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i)# Reshape data from (history`1_size,) to (history_size, 1)data.append(np.reshape(dataset[indices], (history_size, 1)))labels.append(dataset[i+target_size])return np.array(data), np.array(labels)
2 开始分析
2.1 单变量分析
首先,使用一个特征(温度)训练模型,并在使用该模型做预测。
2.1.1 温度变量
从数据集中提取温度
uni_data = df[‘T (degC)’]
uni_data.index = df[‘Date Time’]
uni_data.head()
观察数据随时间变化的情况
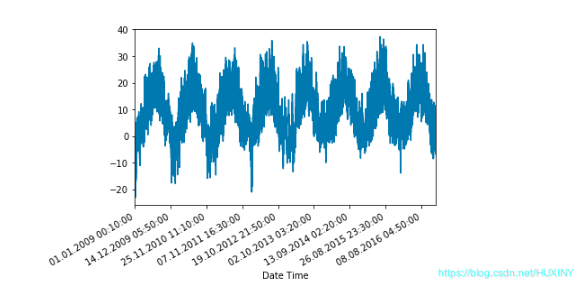
进行标准化
#标准化
uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
uni_data = (uni_data-uni_train_mean)/uni_train_std
#写函数来划分特征和标签
univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT, # 起止区间univariate_past_history,univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,univariate_past_history,univariate_future_target)
可见第一个样本的特征为前20个时间点的温度,其标签为第21个时间点的温度。根据同样的规律,第二个样本的特征为第2个时间点的温度值到第21个时间点的温度值,其标签为第22个时间点的温度……
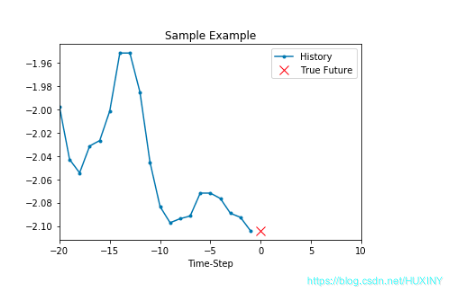
2.2 将特征和标签切片
BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
2.3 建模
simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]), # input_shape=(20,1) 不包含批处理维度
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
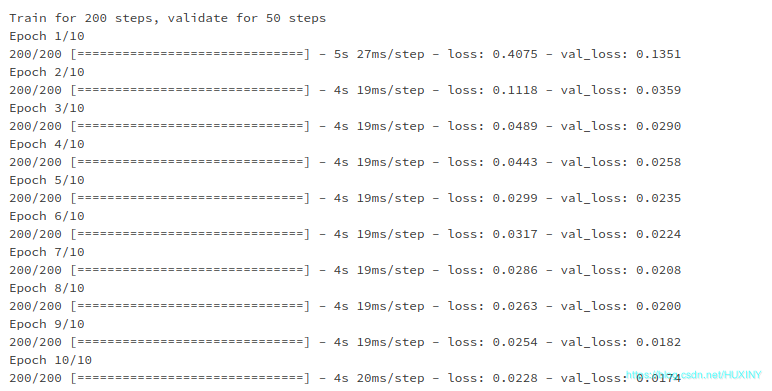
2.4 训练模型
EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_univariate, validation_steps=50)
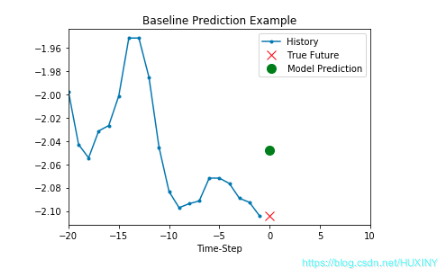
训练过程
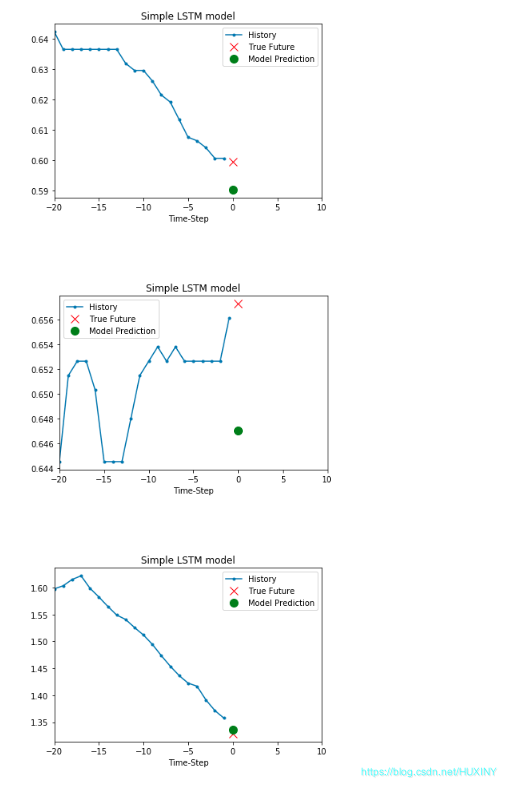
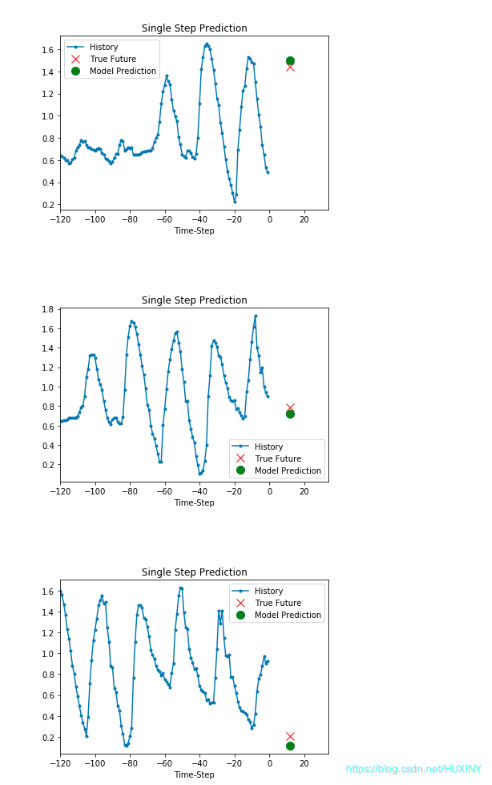
训练结果 - 温度预测结果
2.5 多变量分析
在这里,我们用过去的一些压强信息、温度信息以及密度信息来预测未来的一个时间点的温度。也就是说,数据集中应该包括压强信息、温度信息以及密度信息。
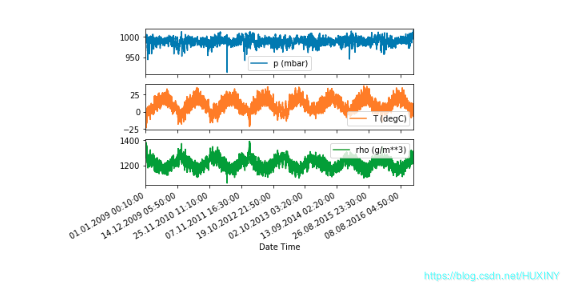
2.5.1 压强、温度、密度随时间变化绘图
2.5.2 将数据集转换为数组类型并标准化
dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_stddef multivariate_data(dataset, target, start_index, end_index, history_size,target_size, step, single_step=False):data = []labels = []start_index = start_index + history_sizeif end_index is None:end_index = len(dataset) - target_sizefor i in range(start_index, end_index):indices = range(i-history_size, i, step) # step表示滑动步长data.append(dataset[indices])if single_step:labels.append(target[i+target_size])else:labels.append(target[i:i+target_size])return np.array(data), np.array(labels)
2.5.3 多变量建模训练训练
single_step_model = tf.keras.models.Sequential()single_step_model.add(tf.keras.layers.LSTM(32,input_shape=x_train_single.shape[-2:]))single_step_model.add(tf.keras.layers.Dense(1))single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_data_single,validation_steps=50)def plot_train_history(history, title):loss = history.history['loss']val_loss = history.history['val_loss']epochs = range(len(loss))plt.figure()plt.plot(epochs, loss, 'b', label='Training loss')plt.plot(epochs, val_loss, 'r', label='Validation loss')plt.title(title)plt.legend()plt.show()plot_train_history(single_step_history,'Single Step Training and validation loss')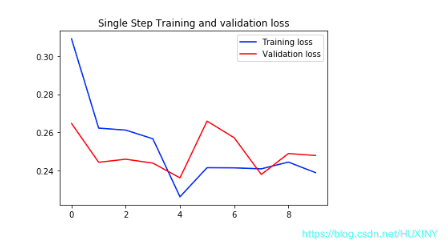
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛保研 基于LSTM的天气预测 - 时间序列预测
0 前言 🔥 优质竞赛项目系列,今天要分享的是 机器学习大数据分析项目 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/po…...

前端常用的开发工具
前端常用的开发工具🔖 文章目录 前端常用的开发工具🔖1. Snipaste--截图工具2. ScreenToGif--gif图片录制3. Typora--Markdown编辑器4. notepad--文本代码编辑器5. uTools--多功能工具6. EV录屏--录屏软件7. Xmind--思维导图8. Apifox -- 接口调试9. Tor…...
鸿蒙开发语言介绍--ArkTS
1.编程语言介绍 ArkTS是HarmonyOS主力应用开发语言。它在TypeScript (简称TS)的基础上,匹配ArkUI框架,扩展了声明式UI、状态管理等相应的能力,让开发者以更简洁、更自然的方式开发跨端应用。 2.TypeScript简介 自行补充TypeScript知识吧。h…...

关于“Python”的核心知识点整理大全36
目录 13.4.4 向下移动外星人群并改变移动方向 game_functions.py alien_invasion.py 13.5 射杀外星人 13.5.1 检测子弹与外星人的碰撞 game_functions.py alien_invasion.py 13.5.2 为测试创建大子弹 13.5.3 生成新的外星人群 game_functions.py alien_invasion.py …...
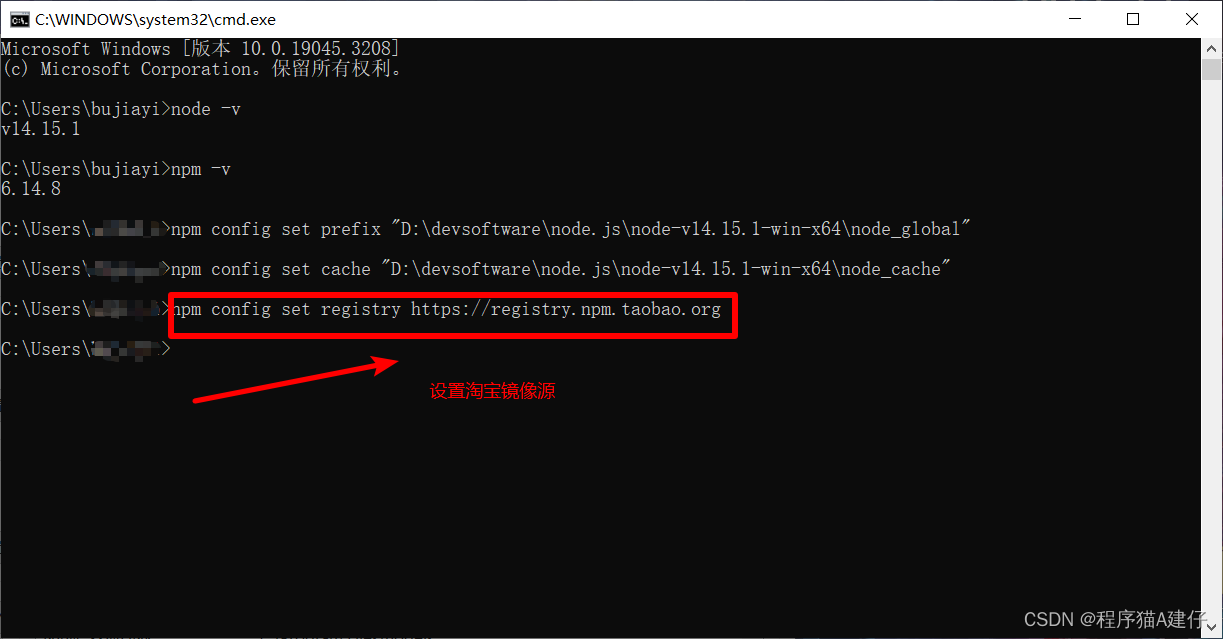
安装nodejs,配置环境变量并将npm设置淘宝镜像源
安装nodejs并将npm设置淘宝镜像源 1. 下载nodejs 个人不喜欢安装包,所以是下载zip包的方式。这里我下载的node 14解压包版本 下载地址如下:https://nodejs.org/dist/v14.15.1/node-v14.15.1-win-x64.zip 想要其他版本的小伙伴去https://nodejs.org/di…...

12.18构建哈夫曼树(优先队列),图的存储方式,一些细节(auto,pair用法,结构体指针)
为结构体自身时,用.调用成员变量;为结构体指针时,用->调用成员变量 所以存在结构体数组时,调用数组元素里的成员变量,就是要用. 结构体自身只有在new时才会创建出来,而其指针可以随意创建 在用new时&…...
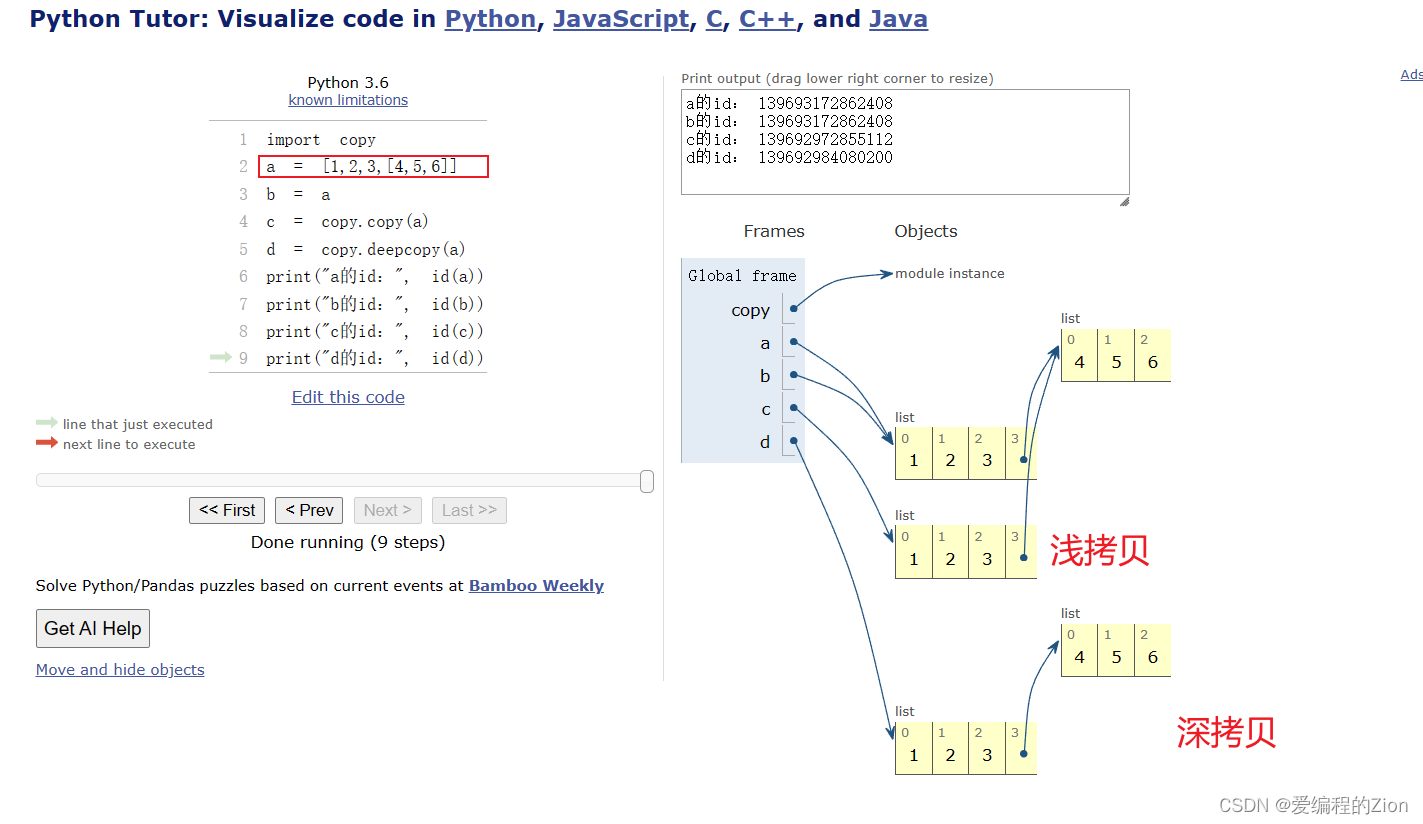
《Python》面试常问:深拷贝、浅拷贝、赋值之间的关系(附可变与不可变)【用图文讲清楚!】
背景 想必大家面试或者平时学习经常遇到问python的深拷贝、浅拷贝和赋值之间的区别了吧?看网上的文章很多写的比较抽象,小白接收的难度有点大,于是乎也想自己整个文章出来供参考 可变与不可变 讲深拷贝和浅拷贝之前想讲讲什么是可变数据类型…...
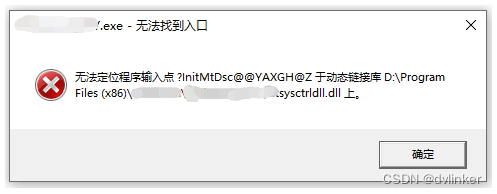
使用PE信息查看工具和Dependency Walker工具排查因为库版本不对导致程序启动报错问题
目录 1、问题说明 2、问题分析思路 3、问题分析过程 3.1、使用Dependency Walker打开软件主程序,查看库与库的依赖关系,查看出问题的库 3.2、使用PE工具查看dll库的时间戳 3.3、解决办法 4、最后 VC常用功能开发汇总(专栏文章列表&…...

Python编程题目答疑「Python一对一辅导考试真题解析」
你好,我是悦创。 待会更新~ 更新计划 答案 题目 记得点赞收藏! 题目 之后更新 Solution Question 1 # 读取输入 a float(input("请输入实数 a: ")) b float(input("请输入实数 b: ")) c float(input("请输…...

Python---搭建Python自带静态Web服务器
1. 静态Web服务器是什么? 可以为发出请求的浏览器提供静态文档的程序。 平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,页面的数据不会发生变化。 …...

在服务器上部署SpringBoot项目jar包
以下是在服务器上部署Spring Boot项目jar包的步骤: 打包项目: 使用IDEA或者命令行工具(如Maven或Gradle)将Spring Boot项目打包为一个可执行的jar文件。如果使用Maven,可以在项目的根目录下运行以下命令来打包项目&…...

[python]python实现对jenkins 的任务触发
目录 关键词平台说明背景一、安装 python-jenkins 库二、code三、运行 Python 脚本四、注意事项 关键词 python、excel、DBC、jenkins 平台说明 项目Valuepython版本3.6 背景 用python实现对jenkins 的任务触发。 一、安装 python-jenkins 库 pip install python-jenkin…...

Python生成圣诞节贺卡-代码案例剖析【第18篇—python圣诞节系列】
文章目录 ❄️Python制作圣诞节贺卡🐬展示效果🌸代码🌴代码剖析 ❄️Python制作圣诞树贺卡🐬展示效果🌸代码🌴代码剖析🌸总结 🎅圣诞节快乐! ❄️Python制作圣诞节贺卡 …...
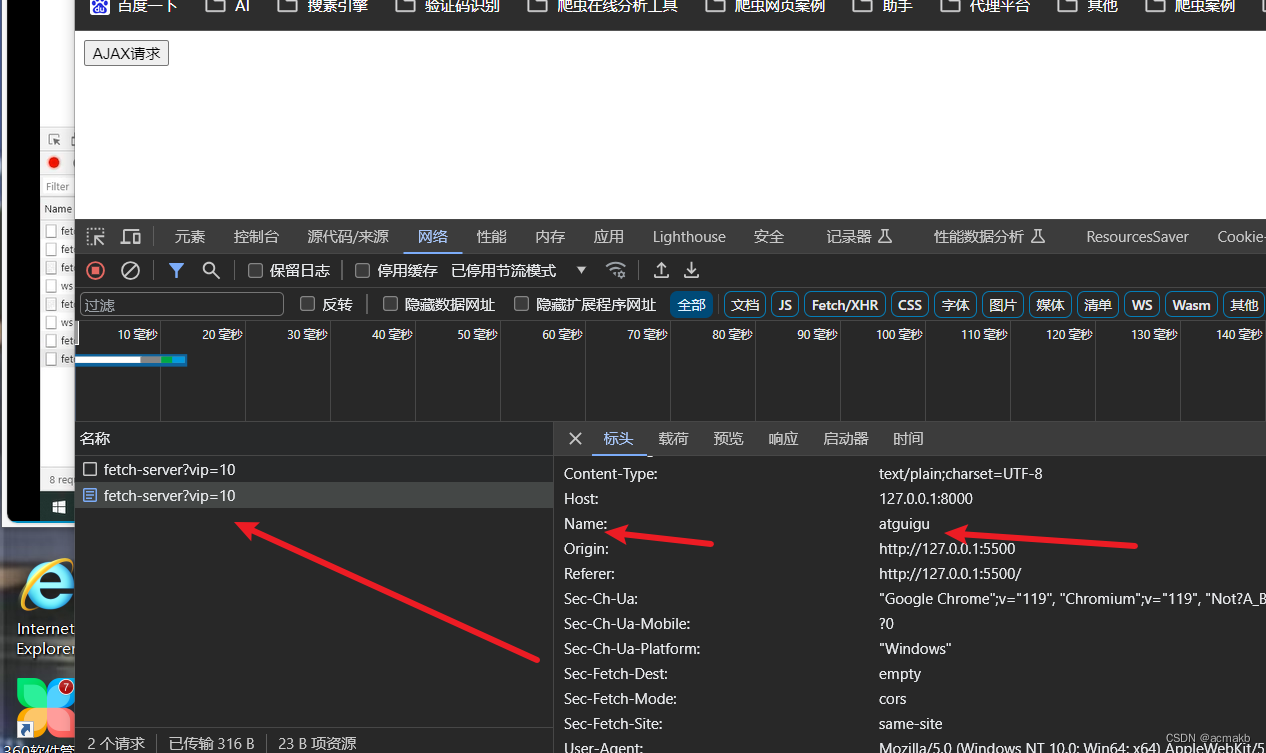
深度剖析Ajax实现方式(原生框架、JQuery、Axios,Fetch)
Ajax学习 简介: Ajax 代表异步 JavaScript 和 XML(Asynchronous JavaScript and XML)的缩写。它指的是一种在网页开发中使用的技术,通过在后台与服务器进行数据交换,实现页面内容的更新,而无需刷新整个…...
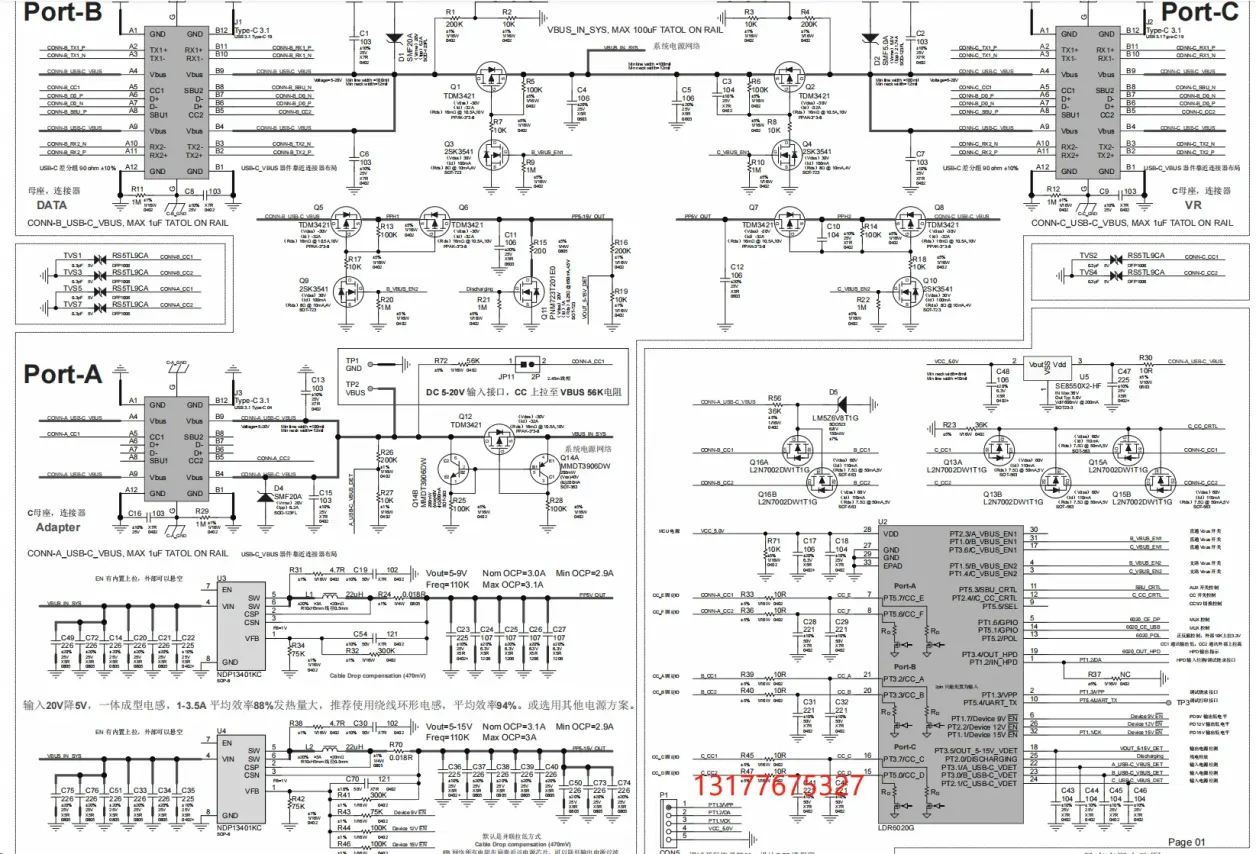
任天堂,steam游戏机通过type-c给VR投屏与PD快速充电的方案 三type-c口投屏转接器
游戏手柄这个概念,最早要追溯到二十年前玩FC游戏的时候,那时候超级玛丽成为了许多人童年里难忘的回忆,虽然长大了才知道超级玛丽是翻译错误,应该是任天堂的超级马里奥,不过这并不影响大家对他的喜爱。 当时FC家用机手柄…...
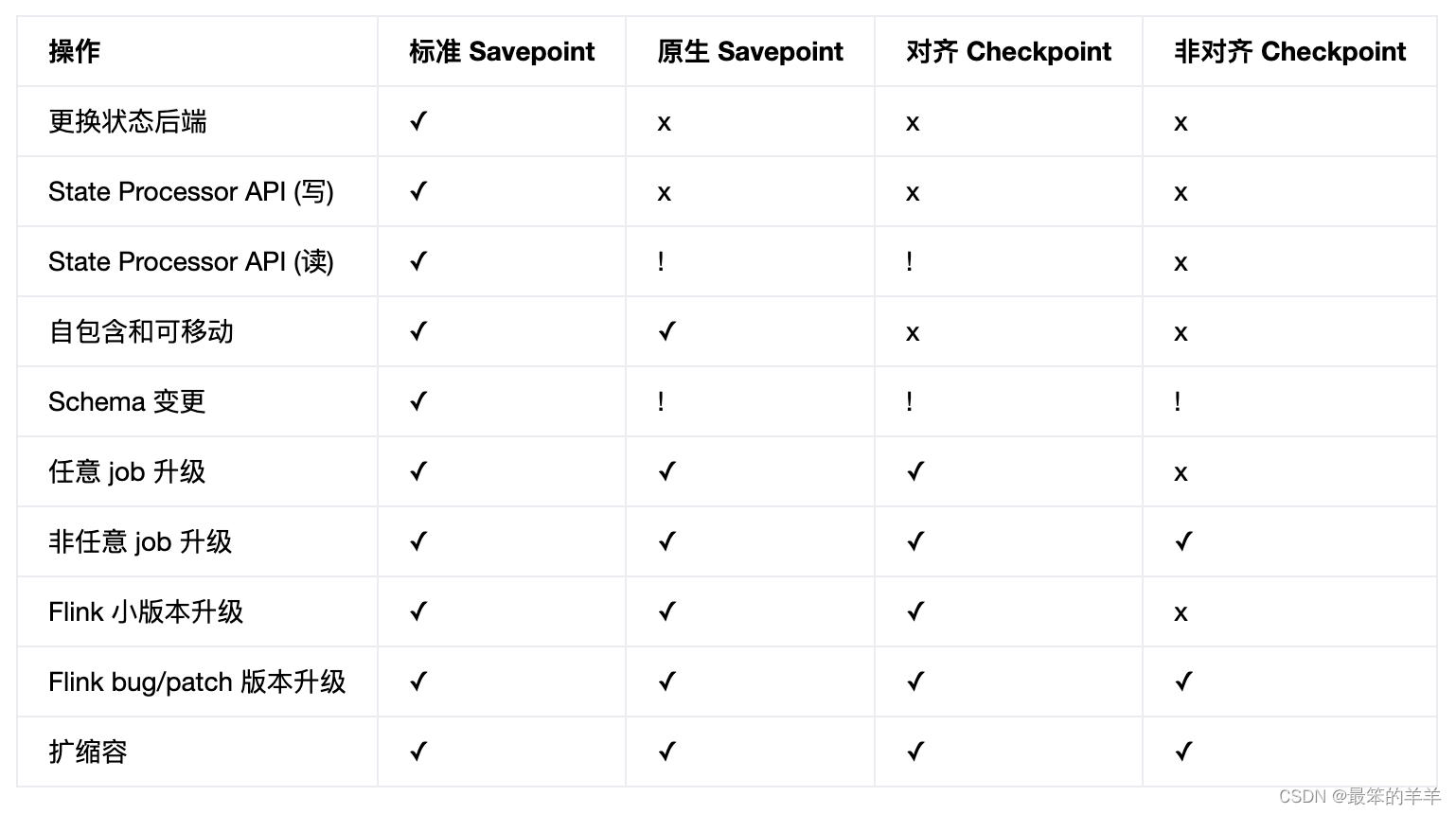
Flink系列之:Checkpoints 与 Savepoints
Flink系列之:Checkpoints 与 Savepoints 一、概述二、功能和限制 一、概述 从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。 Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 …...

【优质书籍推荐】LoRA微调的技巧和方法
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…...
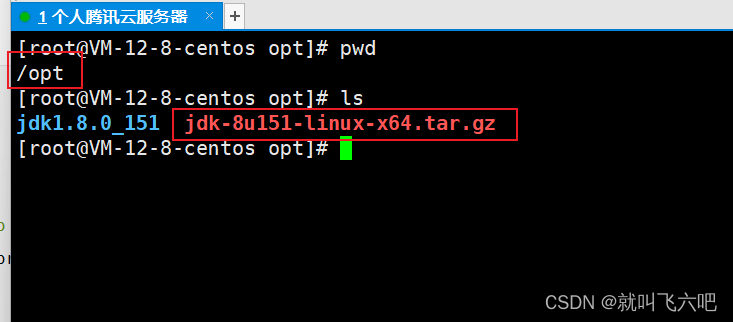
Linux一行命令配置jdk环境
使用方法: 压缩包上传 到/opt, 更换命令中对应的jdk包名即可。 注意点:jdk-8u151-linux-x64.tar.gz 解压后名字是jdk1.8.0_151 sudo tar -zxvf jdk-8u151-linux-x64.tar.gz -C /opt && echo export JAVA_HOME/opt/jdk1.8.0_151 | sudo tee -a …...

从0开始刷剑指Offer
剑指Offer题解 剑指 Offer 11. 旋转数组的最小数字 思路: 二分O(logn) class Solution {public int stockManagement(int[] stock) {int l 0;int r stock.length - 1;while(l < r && stock[0] stock[r]) r --;if(stock[r] > stock[l]) return stock[0];whi…...

使用Java语言中的算法输出杨辉三角形
一、算法思想 创建一个名为YanghuiTest的类,然后创建二维数组,然后遍历二维数组的第一层,然后初始化第二层数组的大小,然后遍历第二层数组,然后将两侧的数组元素赋为1,然后其它数值通过公式计算,最后可以输…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...