《Python》面试常问:深拷贝、浅拷贝、赋值之间的关系(附可变与不可变)【用图文讲清楚!】
背景
想必大家面试或者平时学习经常遇到问python的深拷贝、浅拷贝和赋值之间的区别了吧?看网上的文章很多写的比较抽象,小白接收的难度有点大,于是乎也想自己整个文章出来供参考

可变与不可变
讲深拷贝和浅拷贝之前想讲讲什么是可变数据类型和不可变数据类型
这里有点绕,大概就是:
- 可变指的是值变化后,变量的id地址没变(同一块地址,值是可以变得)
- 不可变指的是值变化后,变量的id地址也变了(同一块地址,只能有一个值)
可变的数据类型有:列表(list)、字典(dict)、集合(set)
不可变数据类型有:整型(int)、浮点数(float)、字符串(string)、元组(tuple)、布尔(bool)
什么是不可变数据类型?
不可变具体怎么体现呢,以整形为例:
python中所有的整形都已经有自己的地址了,我们将整形赋值给变量的过程其实是变量的地址指向整形的地址
print(id(1)) # 140721648427816
a = 1
# a的id地址和1是一样的
print(id(a)) # 140721648427816
print(id(999999999999999999)) # 2210500291920
b = 999999999999999999
print(id(b)) # 2210500291920
c = 1
# c也指向了1的地址,所以a和c的地址是一样的
print(id(a)==id(c)) # True同样的,如果将a的值修改为2,那么a的地址就会指向2的id地址。
print(id(1)) # 140721648427816
a = 1
# a的id地址和1是一样的
print(id(a)) # 140721648427816
a = 2
print(id(a)) # 140721573258056所以,其实可变和不可变是对于id来说的,一个id地址只能指向一个值的数据类型,就是不可变数据类型(换句话就是值变了,地址也变了)
什么是可变数据类型?
直接上代码!
l1 = [1,2,3]
print(id(l1)) # 2259540475456
# 修改变量的值
l1.append(4)
print(id(l1)) # 2259540475456
# 重新给列表赋值
l1 = [3,4,5]
print(id(l1)) # 2259540541952
# 给其他列表赋同样的值
l2 = [3,4,5]
print(id(l2)) # 2259540475456可以看到,我们修改了列表的值,但是变量的id地址没有发生变化。像这种可以修改值,但是地址
没变,也就是id地址指向的值可以变化的,就叫做可变数据类型
但是!我们可以发现如果是重新给列表赋值,列表的地址是会发生变化的(这里需要注意赋值和修改是不一样的),同样的我们也可以看到给别的列表赋同样的值,他们的id地址也是不一样的。
这是因为我们赋值的是一个列表,那么python在赋值之前呢就会创建一个列表对象(python一切皆对象!),那么创建列表对象的时候python就会给这个列表对象分配一个id,然后我们给l2进行赋值的时候也创建了新的列表对象,那么他就会有新的id
# 代码1
print(id([1,2,3])) # 2048797408832
print(id([1,2,3])) # 2048797408832
print(id([1,2,3])) # 2048797408832
l1 = [1,2,3]
l2 = [1,2,3]
print(id(l1)) # 2048797408832
print(id(l2)) # 2048797475328# 代码2
a = [1]
print(id(a)) # 执行三次,每次id都不一样再来看看上面的代码,代码1,连续打印三个[1,2,3]他们的id是相同的,因为创建了[1,2,3]这个临时列表对象,且该对象还没有被回收。[1,2,3]赋值给l1后,居然id和[1,2,3]是一样的,是因为[1,2,3]有值但没有变量名(临时),在l1赋值[1,2,3]的时候就直接把id给了第一次出现的l1,而l2则是生成了一个新的列表对象,所以id和l1的不一样。
浅拷贝、深拷贝和赋值的区别
看到这里相信你已经知道什么是可变数据类型和不可变数据类型了,我们的浅拷贝和深拷贝之间的区别其实只有在可变数据类型才有区别的,或者说是对于可变数据类型才有的深拷贝
不可变数据类型下的浅拷贝、深拷贝和赋值
我们先来看看不可变数据类型的浅拷贝、深拷贝和赋值的区别:
import copya = "hello"
# a赋值给b
b = a
# c是a的浅拷贝
c = copy.copy(a)
# d是a的深拷贝
d = copy.deepcopy(a)
print("a的id:", id(a))
print("b的id:", id(b))
print("c的id:", id(c))
print("d的id:", id(d))结果我们发现他们的id都是一样的,这是因为:
创建了一个临时字符串对象“hello”时分配了地址,然后声明变量a时,a指向了这个地址,然后赋值给b时,其实就是b也指向了a指向的地址,然后浅拷贝和深拷贝其实是返回了a这个变量
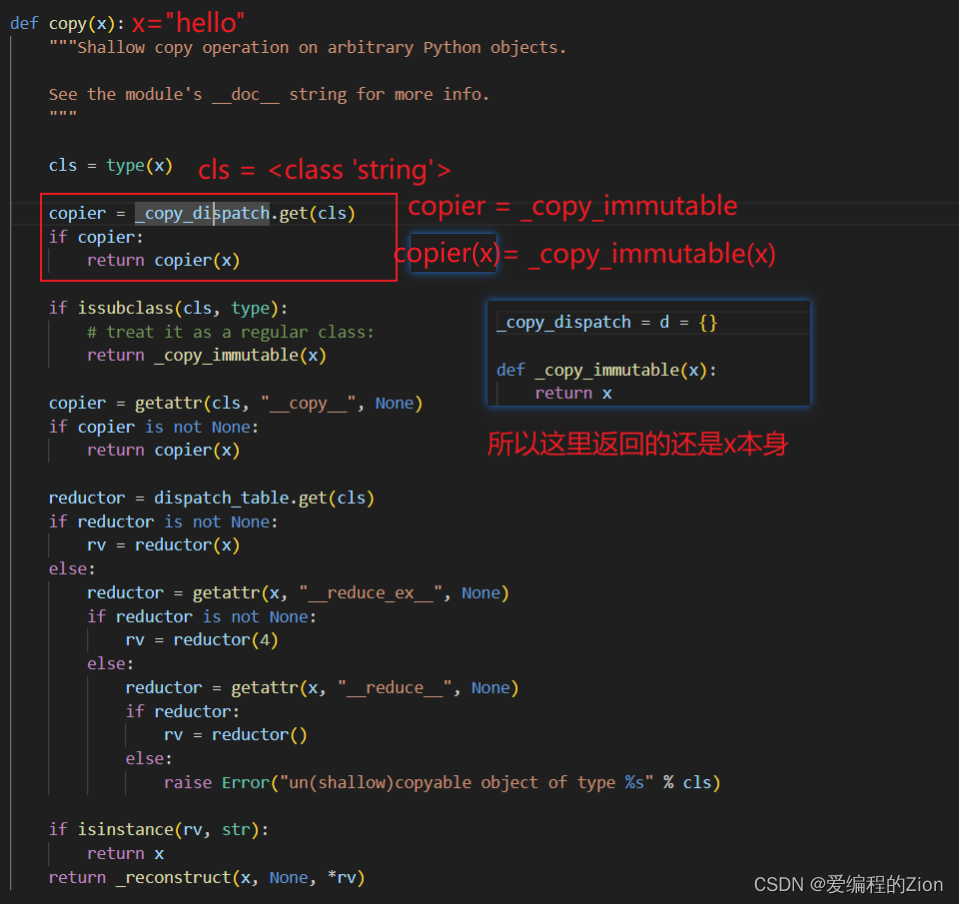
我们可以看看copy的源码:(如果不想看分析可以直接点目录看可变数据类型就知其区别)

copy的源码维护了一个_copy_dispatch的字典,第一个框是处理不可变数据类型的,如果是不可变数据类型的话会给这个字典赋值一个函数变量,比如
_copy_dispatch[<class 'int'>]=_copy_immutable
假如是我们刚刚传的字符串,那么代码是这样执行的:
可变数据类型下的浅拷贝、深拷贝和赋值【看这里快速弄懂!】
我们再来看看可变数据类型
import copy
a = [1,2,3]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
print("a的id:", id(a)) # a的id: 2880639630592
print("b的id:", id(b)) # b的id: 2880639630592
print("c的id:", id(c)) # c的id: 2880639446144
print("d的id:", id(d)) # d的id: 2880639446272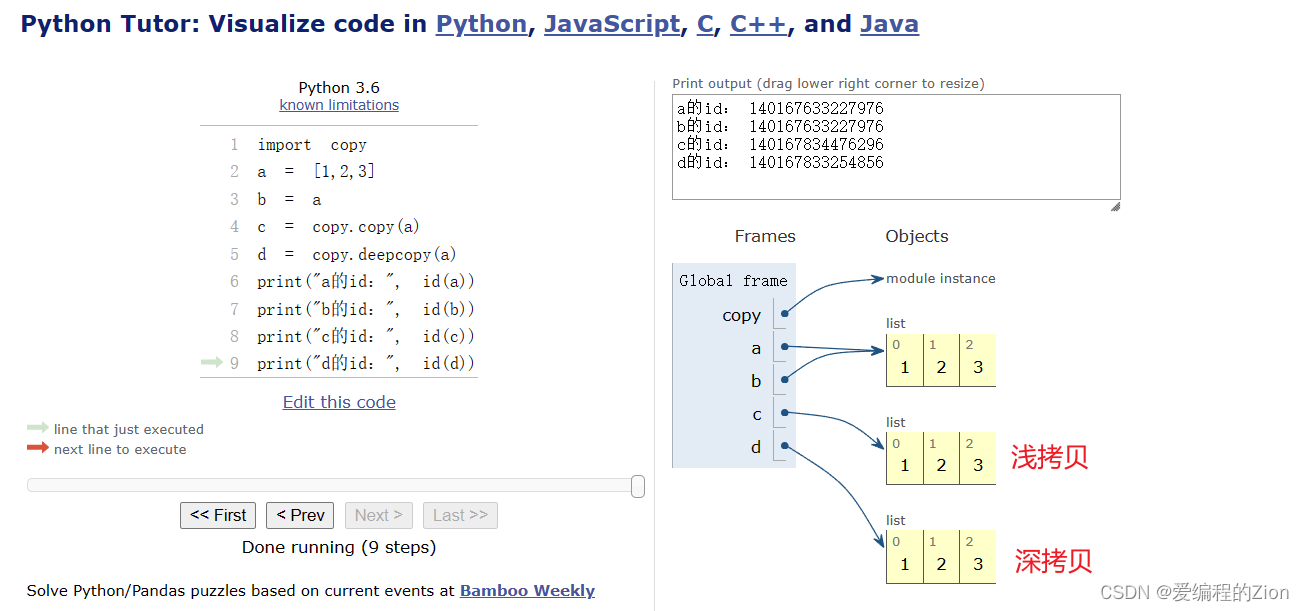
这里我们可以看到a的b的id是一样的,这里不再赘述,c和d都是新的id,好了这里我们可以看到和不可变数据类型的区别了,但是还看不出来浅拷贝和深拷贝的区别,我们继续往下看
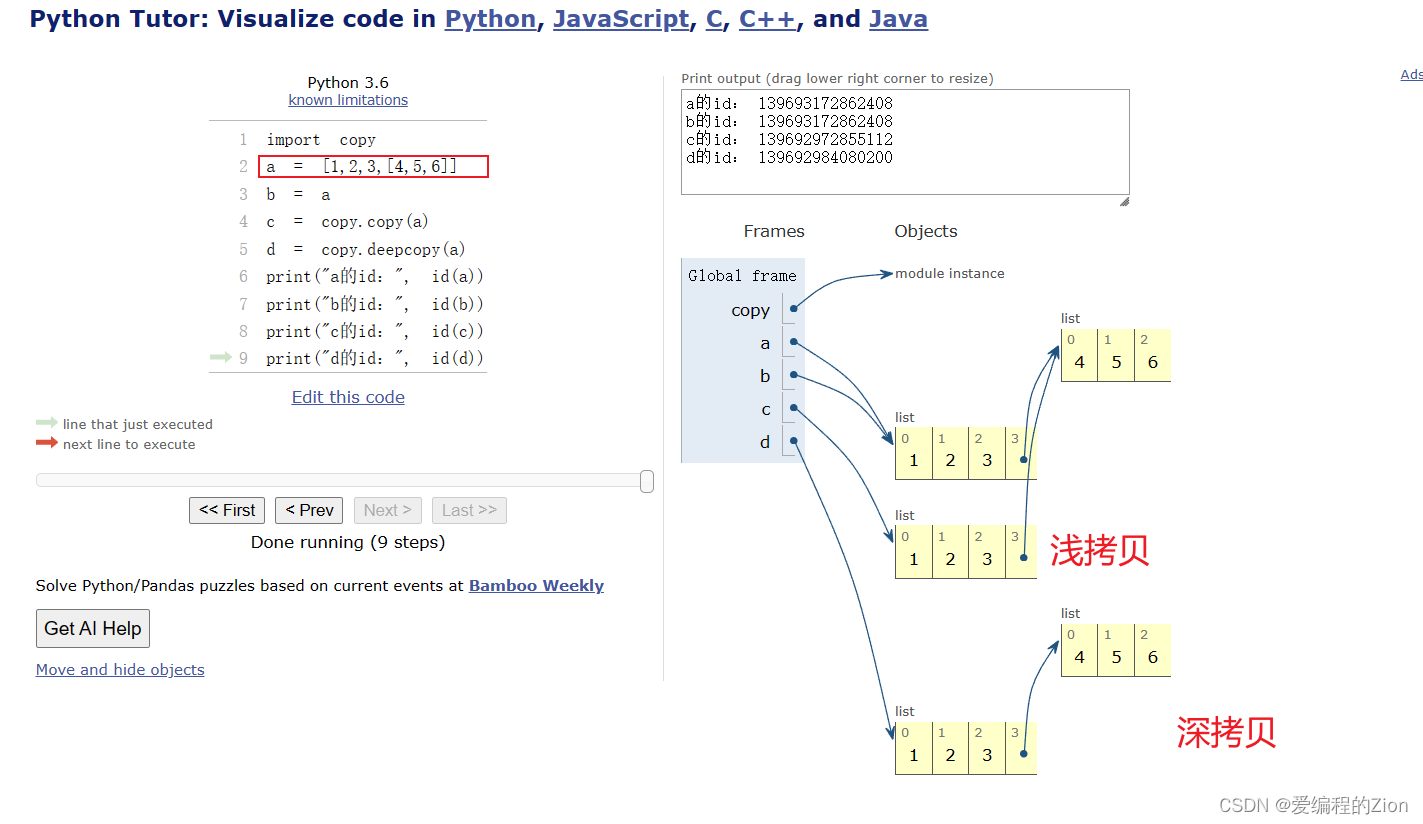
如果是这种嵌套列表的(其他数据类型也可以只要是可变的就行)
浅拷贝时申请了一片新的地址,然后复制了a列表的第一层的值,后面其实还是指向了a嵌套列表的地址
这个时候我们发现如果你去修改c的嵌套列表是会影响a的值的!
import copy
a = [1,2,3,[4,5,6]]
c = copy.copy(a)
print(a) # [1, 2, 3, [4, 5, 6]]
print(c) # [1, 2, 3, [4, 5, 6]]
# 修改c的第一个元素和嵌套列表的第一个元素
c[0] = 0
c[3][0] = 7
print(a) # a中嵌套列表的值也变了 # [1, 2, 3, [7, 5, 6]]
print(c) # [0, 2, 3, [7, 5, 6]]有时候一些软件bug就是这样来的,找半天也想到是吧
但是浅拷贝就不一样了,他完全是自己的id地址,不会影响a了
import copy
a = [1,2,3,[4,5,6]]
d = copy.deepcopy(a)
print(a) # [1, 2, 3, [4, 5, 6]]
print(d) # [1, 2, 3, [4, 5, 6]]
# 修改d的第一个元素和嵌套列表的第一个元素
d[0] = 0
d[3][0] = 7
print(a) # a中嵌套列表的值没变 # [1, 2, 3, [4, 5, 6]]
print(d) 结语
到这里差不多就讲完了,相信你已经十分了解浅拷贝、深拷贝和赋值之间的关系和区别了吧!如果你觉得文章对你有用能不能帮忙点点赞,收藏起来以防复习找不到呢
代码调试地址(实时内存分配图形显示):Python Tutor code visualizer: Visualize code in Python, JavaScript, C, C++, and Java
相关文章:
《Python》面试常问:深拷贝、浅拷贝、赋值之间的关系(附可变与不可变)【用图文讲清楚!】
背景 想必大家面试或者平时学习经常遇到问python的深拷贝、浅拷贝和赋值之间的区别了吧?看网上的文章很多写的比较抽象,小白接收的难度有点大,于是乎也想自己整个文章出来供参考 可变与不可变 讲深拷贝和浅拷贝之前想讲讲什么是可变数据类型…...
使用PE信息查看工具和Dependency Walker工具排查因为库版本不对导致程序启动报错问题
目录 1、问题说明 2、问题分析思路 3、问题分析过程 3.1、使用Dependency Walker打开软件主程序,查看库与库的依赖关系,查看出问题的库 3.2、使用PE工具查看dll库的时间戳 3.3、解决办法 4、最后 VC常用功能开发汇总(专栏文章列表&…...

Python编程题目答疑「Python一对一辅导考试真题解析」
你好,我是悦创。 待会更新~ 更新计划 答案 题目 记得点赞收藏! 题目 之后更新 Solution Question 1 # 读取输入 a float(input("请输入实数 a: ")) b float(input("请输入实数 b: ")) c float(input("请输…...

Python---搭建Python自带静态Web服务器
1. 静态Web服务器是什么? 可以为发出请求的浏览器提供静态文档的程序。 平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,页面的数据不会发生变化。 …...

在服务器上部署SpringBoot项目jar包
以下是在服务器上部署Spring Boot项目jar包的步骤: 打包项目: 使用IDEA或者命令行工具(如Maven或Gradle)将Spring Boot项目打包为一个可执行的jar文件。如果使用Maven,可以在项目的根目录下运行以下命令来打包项目&…...

[python]python实现对jenkins 的任务触发
目录 关键词平台说明背景一、安装 python-jenkins 库二、code三、运行 Python 脚本四、注意事项 关键词 python、excel、DBC、jenkins 平台说明 项目Valuepython版本3.6 背景 用python实现对jenkins 的任务触发。 一、安装 python-jenkins 库 pip install python-jenkin…...

Python生成圣诞节贺卡-代码案例剖析【第18篇—python圣诞节系列】
文章目录 ❄️Python制作圣诞节贺卡🐬展示效果🌸代码🌴代码剖析 ❄️Python制作圣诞树贺卡🐬展示效果🌸代码🌴代码剖析🌸总结 🎅圣诞节快乐! ❄️Python制作圣诞节贺卡 …...
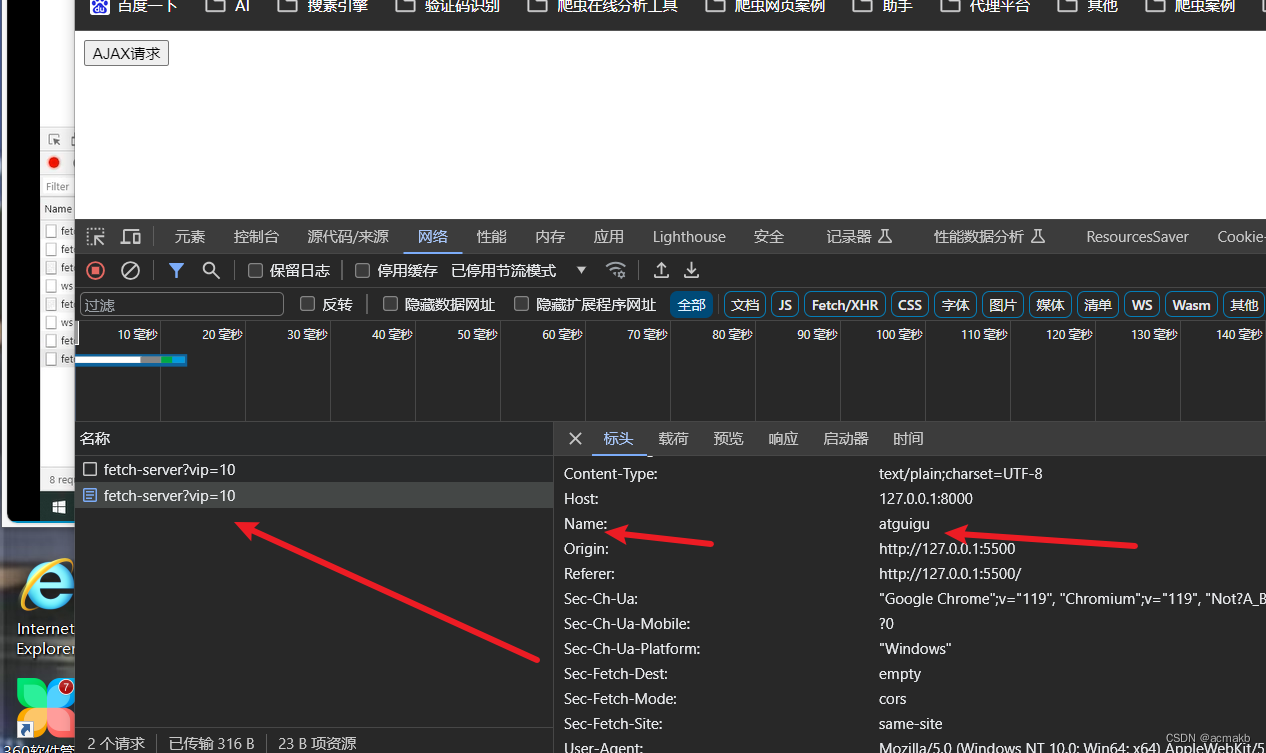
深度剖析Ajax实现方式(原生框架、JQuery、Axios,Fetch)
Ajax学习 简介: Ajax 代表异步 JavaScript 和 XML(Asynchronous JavaScript and XML)的缩写。它指的是一种在网页开发中使用的技术,通过在后台与服务器进行数据交换,实现页面内容的更新,而无需刷新整个…...
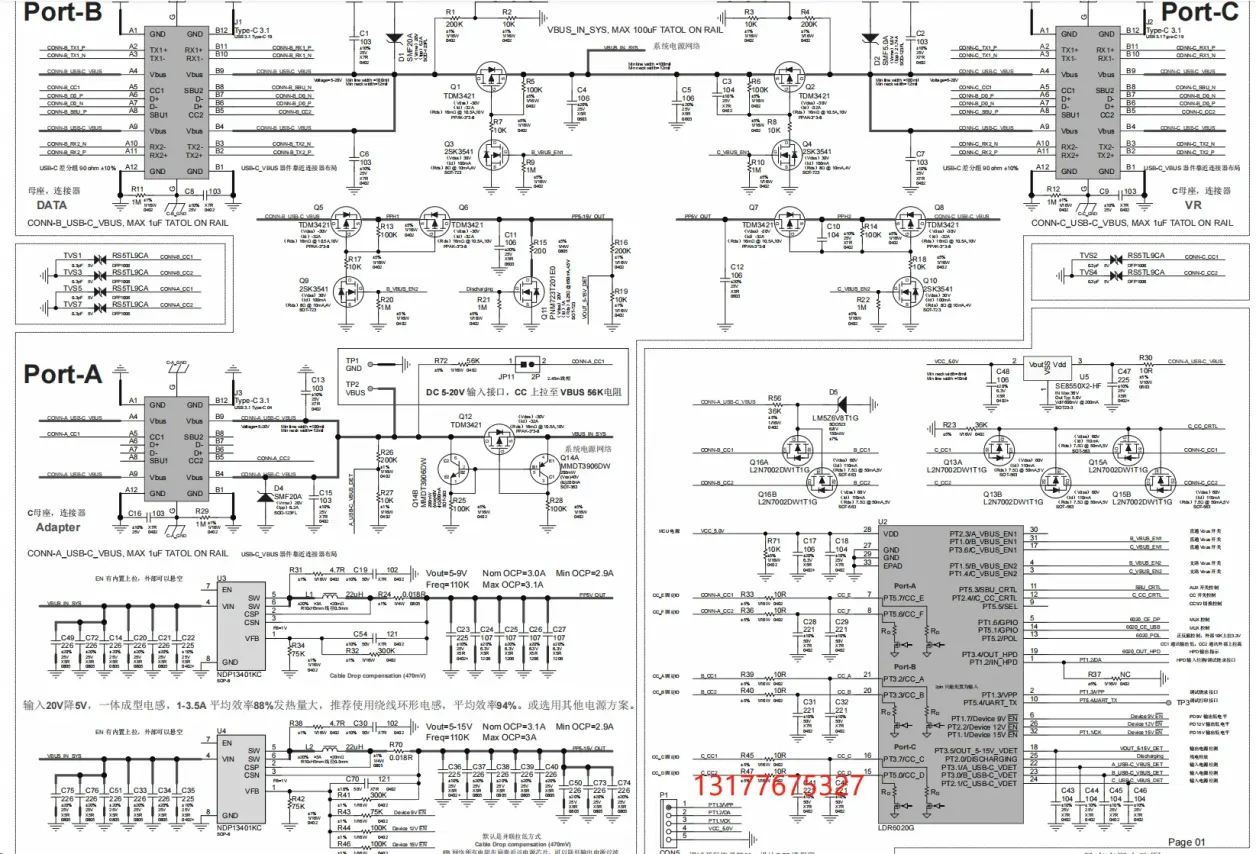
任天堂,steam游戏机通过type-c给VR投屏与PD快速充电的方案 三type-c口投屏转接器
游戏手柄这个概念,最早要追溯到二十年前玩FC游戏的时候,那时候超级玛丽成为了许多人童年里难忘的回忆,虽然长大了才知道超级玛丽是翻译错误,应该是任天堂的超级马里奥,不过这并不影响大家对他的喜爱。 当时FC家用机手柄…...
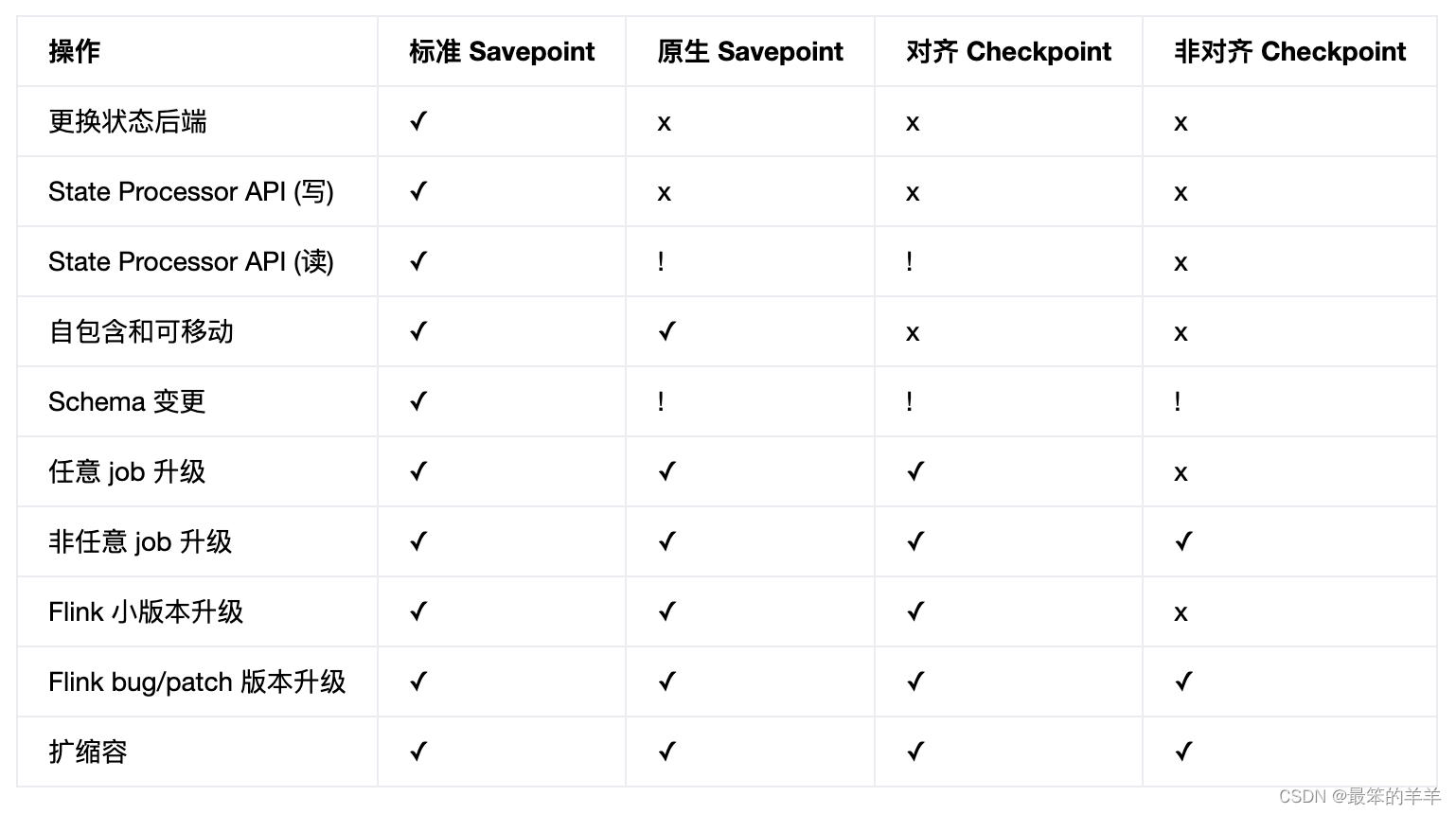
Flink系列之:Checkpoints 与 Savepoints
Flink系列之:Checkpoints 与 Savepoints 一、概述二、功能和限制 一、概述 从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。 Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 …...

【优质书籍推荐】LoRA微调的技巧和方法
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…...
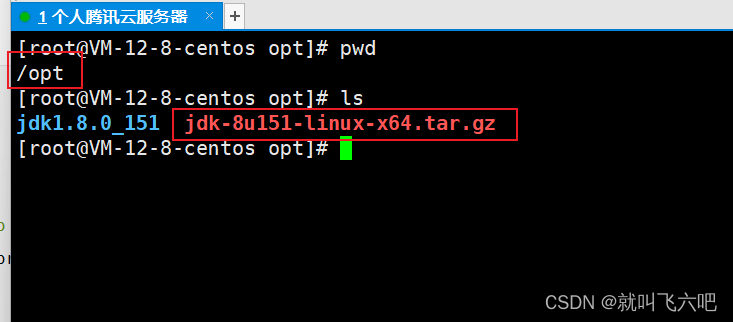
Linux一行命令配置jdk环境
使用方法: 压缩包上传 到/opt, 更换命令中对应的jdk包名即可。 注意点:jdk-8u151-linux-x64.tar.gz 解压后名字是jdk1.8.0_151 sudo tar -zxvf jdk-8u151-linux-x64.tar.gz -C /opt && echo export JAVA_HOME/opt/jdk1.8.0_151 | sudo tee -a …...

从0开始刷剑指Offer
剑指Offer题解 剑指 Offer 11. 旋转数组的最小数字 思路: 二分O(logn) class Solution {public int stockManagement(int[] stock) {int l 0;int r stock.length - 1;while(l < r && stock[0] stock[r]) r --;if(stock[r] > stock[l]) return stock[0];whi…...

使用Java语言中的算法输出杨辉三角形
一、算法思想 创建一个名为YanghuiTest的类,然后创建二维数组,然后遍历二维数组的第一层,然后初始化第二层数组的大小,然后遍历第二层数组,然后将两侧的数组元素赋为1,然后其它数值通过公式计算,最后可以输…...
人工智能_机器学习071_SVM支持向量机_人脸识别算法_LFW人脸数据加载_与理解---人工智能工作笔记0111
然后我们继续来看 这里有个lfw_home可以看到这个数据是,包含了人脸数据 然后我们继续看,在我们的顶你用户目录下,如果安装了,sklearn就会有这样一个目录, scikit_learn_data目录,这个里面可以看到 可以看到这个文件夹中有个 lfw_home文件夹是对.zip文件夹的解压,这个下载以后…...

Java 8中流Stream API详解
先给个示例,展示Java 8流API的优势 假设我们有以下任务: 给定一个字符串列表,我们需要执行以下操作: 筛选出所有以"A"开头的字符串。 将这些字符串转换为大写。 对这些字符串按照长度进行排序。 最后,将…...

通过 xlsx 解析上传excel的数据
一、前言 在前端开发中,特别是在后台管理系统中,导入数据(上传excel)到后端是是否常见的功能;而一般的实现方式都是通过接口将excel上传到后端,再有后端进行数据解析并做后续操作。 今天,来记录…...

Flink系列之:JDBC SQL 连接器
Flink系列之:JDBC SQL 连接器 一、JDBC SQL 连接器二、依赖三、创建 JDBC 表四、连接器参数五、键处理六、分区扫描七、Lookup Cache八、幂等写入九、JDBC Catalog十、JDBC Catalog 的使用十一、JDBC Catalog for PostgreSQL十二、JDBC Catalog for MySQL十三、数据…...

OpenCV与YOLO学习与研究指南
引言 OpenCV是一个开源的计算机视觉和机器学习软件库,而YOLO(You Only Look Once)是一个流行的实时对象检测系统。对于大学生和初学者而言,掌握这两项技术将大大提升他们在图像处理和机器视觉领域的能力。 基础知识储备 在深入…...

hive中map相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释 hive官网函数大全地址: hive官网函数大全地址 Return TypeNameDescriptionmapmap(key1, value1, key2, value2, …)Creates a map with the given key/value pairs.arraymap_values(Map<K.V>)Returns an un…...
)
【ElevenLabs情绪语音实战指南】:零代码接入非正式语调+3种微情绪参数调优法(附2024最新API密钥绕过技巧)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs非正式情绪语音的核心能力与技术边界 ElevenLabs 的非正式情绪语音(Informal Emotional Voice)并非标准 TTS 模式,而是通过隐式情感建模与上下文感知微调实…...

Microsoft 365 E7 ,“AI+安全+身份”三位一体,打造 AI 时代的一站式操作系统
在AI智能体加速渗透企业各个业务场景的今天,如何在释放AI生产力的同时,有效管控智能体带来的安全与治理风险,成为了所有企业数字化转型过程中必须面对的核心挑战。2026年5月1日,微软正式推出Microsoft 365 E7(前沿办公…...

晨芯阳HC9616带防止逆流功能,500mA高速LDO
HC9616是一系列高精度,低功耗LDO线性稳压器,内部集成防止逆流保护功能、短路保护,过流保护等功能。输出具有高精度、低噪声、高纹波抑制比、低压差等特点,输出可使用小型陶瓷电容,良好的线性和负载调整特性。且具有使能…...

开源智能家居中枢搭建:从架构解析到自动化场景实践
1. 项目概述与核心价值最近在折腾智能家居中枢时,发现了一个挺有意思的开源项目,叫contextzero/nest_hub。乍一看名字,很容易让人联想到谷歌的 Nest Hub 智能显示屏,但深入探究后,你会发现它其实是一个旨在“模拟”或“…...

DSub:Android平台上最完整的Subsonic音乐客户端指南
DSub:Android平台上最完整的Subsonic音乐客户端指南 【免费下载链接】Subsonic Home of the DSub Android client fork 项目地址: https://gitcode.com/gh_mirrors/su/Subsonic DSub是一款专为Android设备设计的开源Subsonic客户端,让您能够随时随…...

开源命令中心OpenClaw:统一管理与编排自动化任务工作流
1. 项目概述:一个开源命令中心的诞生最近在折腾一个很有意思的项目,叫openclaw-command-center。光看这个名字,你可能会联想到科幻电影里的控制台,或者某种自动化运维工具。没错,它的核心定位就是一个开源、可扩展的命…...
:LLM Task)
OpenClaw从入门到应用——工具(Tools):LLM Task
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 llm-task 是一个可选插件工具,用于运行纯 JSON 格式的 LLM 任务,并返回结构化输出(可选择是否依据 JSON Schema 进行验证&#x…...

ARM调试器AXD核心功能与定时刷新机制详解
1. ARM调试器AXD核心功能解析ARM调试器AXD作为嵌入式开发领域的专业调试工具,其核心价值在于为开发者提供对ARM架构处理器(如Cortex-M系列)的深度调试能力。不同于通用调试工具,AXD针对ARM处理器特性进行了专门优化,特…...
)
ArcGIS布局视图下,3分钟搞定地图经纬网添加与样式美化(附详细截图)
ArcGIS布局视图中经纬网的高效设计与视觉优化指南 在地理信息系统的制图工作中,经纬网不仅是坐标参考的基础元素,更是提升地图专业度和视觉层次的关键设计要素。许多初学者往往止步于基础功能的实现,却忽略了通过精细化调整让地图脱颖而出的机…...

【Midjourney Sand印相终极指南】:从零掌握参数调优、材质控制与暗房级输出技巧
更多请点击: https://intelliparadigm.com 第一章:Midjourney Sand印相的技术起源与核心范式 Midjourney Sand印相并非官方术语,而是社区对Midjourney v6中一种高保真纹理建模能力的隐喻性命名——“Sand”取自其对沙粒、纸浆、矿物结晶等微…...