Flink系列之:JDBC SQL 连接器
Flink系列之:JDBC SQL 连接器
- 一、JDBC SQL 连接器
- 二、依赖
- 三、创建 JDBC 表
- 四、连接器参数
- 五、键处理
- 六、分区扫描
- 七、Lookup Cache
- 八、幂等写入
- 九、JDBC Catalog
- 十、JDBC Catalog 的使用
- 十一、JDBC Catalog for PostgreSQL
- 十二、JDBC Catalog for MySQL
- 十三、数据类型映射
一、JDBC SQL 连接器
- Scan Source: Bounded
- Lookup Source: Sync Mode
- Sink: Batch
- Sink: Streaming Append & Upsert Mode
JDBC 连接器允许使用 JDBC 驱动向任意类型的关系型数据库读取或者写入数据。本文档描述了针对关系型数据库如何通过建立 JDBC 连接器来执行 SQL 查询。
如果在 DDL 中定义了主键,JDBC sink 将以 upsert 模式与外部系统交换 UPDATE/DELETE 消息;否则,它将以 append 模式与外部系统交换消息且不支持消费 UPDATE/DELETE 消息。
二、依赖
在连接到具体数据库时,也需要对应的驱动依赖,目前支持的驱动如下:
| Driver | Group Id | Artifact Id | JAR |
|---|---|---|---|
| MySQL | mysql | mysql-connector-java | 下载 |
| Oracle | com.oracle.database.jdbc | ojdbc8 | 下载 |
| PostgreSQL | org.postgresql | postgresql | 下载 |
| Derby | org.apache.derby | derby | 下载 |
| SQL Server | com.microsoft.sqlserver | mssql-jdbc | 下载 |
三、创建 JDBC 表
JDBC table 可以按如下定义:
-- 在 Flink SQL 中注册一张 MySQL 表 'users'
CREATE TABLE MyUserTable (id BIGINT,name STRING,age INT,status BOOLEAN,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:3306/mydatabase','table-name' = 'users'
);-- 从另一张表 "T" 将数据写入到 JDBC 表中
INSERT INTO MyUserTable
SELECT id, name, age, status FROM T;-- 查看 JDBC 表中的数据
SELECT id, name, age, status FROM MyUserTable;-- JDBC 表在时态表关联中作为维表
SELECT * FROM myTopic
LEFT JOIN MyUserTable FOR SYSTEM_TIME AS OF myTopic.proctime
ON myTopic.key = MyUserTable.id;
这段代码是在Flink SQL中注册一个MySQL表"users",表结构包括id、name、age、status等字段,并设置id作为主键。
接下来通过INSERT INTO语句,从名为"T"的表中将数据写入到JDBC表"MyUserTable"中。INSERT INTO语句用于将"T"表中的id、name、age、status字段的值插入到"MyUserTable"表中。
然后使用SELECT语句查看JDBC表中的数据,返回id、name、age、status字段的值。
最后一段语句是将JDBC表"MyUserTable"作为维表,与实时流数据源"myTopic"进行时态表关联。通过FOR SYSTEM_TIME AS OF子句指定以"myTopic.proctime"字段的时间为基准,将"myTopic"的key字段与"MyUserTable"的id字段进行关联查询,返回所有字段的值。
通过这段代码,可以实现将数据从一个表写入到MySQL表中,并在流处理中进行关联查询,从而实现时态表的操作。
四、连接器参数
| 参数 | 是否必填 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| connector | 必填 | (none) | String | 指定使用什么类型的连接器,这里应该是’jdbc’。 |
| url | 必填 | (none) | String | JDBC 数据库 url。 |
| table-name | 必填 | (none) | String | 连接到 JDBC 表的名称。 |
| driver | 可选 | (none) | String | 用于连接到此 URL 的 JDBC 驱动类名,如果不设置,将自动从 URL 中推导。 |
| username | 可选 | (none) | String | JDBC 用户名。如果指定了 ‘username’ 和 ‘password’ 中的任一参数,则两者必须都被指定。 |
| password | 可选 | (none) | String | JDBC 密码。 |
| connection.max-retry-timeout | 可选 | 60s | Duration | 最大重试超时时间,以秒为单位且不应该小于 1 秒。 |
| scan.partition.column | 可选 | (none) | String | 用于将输入进行分区的列名。 |
| scan.partition.num | 可选 | (none) | Integer | 分区数。 |
| scan.partition.lower-bound | 可选 | (none) | Integer | 第一个分区的最小值。 |
| scan.partition.upper-bound | 可选 | (none) | Integer | 最后一个分区的最大值。 |
| scan.fetch-size | 可选 | 0 | Integer | 每次循环读取时应该从数据库中获取的行数。如果指定的值为 ‘0’,则该配置项会被忽略。 |
| scan.auto-commit | 可选 | true | Boolean | 在 JDBC 驱动程序上设置 auto-commit 标志, 它决定了每个语句是否在事务中自动提交。有些 JDBC 驱动程序,特别是 Postgres,可能需要将此设置为 false 以便流化结果。 |
| lookup.cache | 可选 | (none) | 枚举类型,可选值: NONE, PARTIAL | 维表的缓存策略。 目前支持 NONE(不缓存)和 PARTIAL(只在外部数据库中查找数据时缓存)。 |
| lookup.cache.max-rows | 可选 | (none) | Integer | 维表缓存的最大行数,若超过该值,则最老的行记录将会过期。 使用该配置时 “lookup.cache” 必须设置为 "PARTIAL”。 |
| lookup.partial-cache.expire-after-write | 可选 | (none) | Duration | 在记录写入缓存后该记录的最大保留时间。 使用该配置时 “lookup.cache” 必须设置为 "PARTIAL”。 |
| lookup.partial-cache.expire-after-access | 可选 | (none) | Duration | 在缓存中的记录被访问后该记录的最大保留时间。 使用该配置时 “lookup.cache” 必须设置为 "PARTIAL”。 |
| lookup.partial-cache.cache-missing-key | 可选 | (none) | Boolean | 是否缓存维表中不存在的键,默认为true。 使用该配置时 “lookup.cache” 必须设置为 "PARTIAL”。 |
| lookup.max-retries | 可选 | 3 | Integer | 查询数据库失败的最大重试次数。 |
| sink.buffer-flush.max-rows | 可选 | 100 | Integer | flush 前缓存记录的最大值,可以设置为 ‘0’ 来禁用它。 |
| sink.buffer-flush.interval | 可选 | 1s | Duration | flush 间隔时间,超过该时间后异步线程将 flush 数据。可以设置为 ‘0’ 来禁用它。注意, 为了完全异步地处理缓存的 flush 事件,可以将 ‘sink.buffer-flush.max-rows’ 设置为 ‘0’ 并配置适当的 flush 时间间隔。 |
| sink.max-retries | 可选 | 3 | Integer | 写入记录到数据库失败后的最大重试次数。 |
| sink.parallelism | 可选 | (none) | Integer | 用于定义 JDBC sink 算子的并行度。默认情况下,并行度是由框架决定:使用与上游链式算子相同的并行度。 |
五、键处理
当写入数据到外部数据库时,Flink 会使用 DDL 中定义的主键。如果定义了主键,则连接器将以 upsert 模式工作,否则连接器将以 append 模式工作。
在 upsert 模式下,Flink 将根据主键判断插入新行或者更新已存在的行,这种方式可以确保幂等性。为了确保输出结果是符合预期的,推荐为表定义主键并且确保主键是底层数据库中表的唯一键或主键。在 append 模式下,Flink 会把所有记录解释为 INSERT 消息,如果违反了底层数据库中主键或者唯一约束,INSERT 插入可能会失败。
六、分区扫描
为了在并行 Source task 实例中加速读取数据,Flink 为 JDBC table 提供了分区扫描的特性。
如果下述分区扫描参数中的任一项被指定,则下述所有的分区扫描参数必须都被指定。这些参数描述了在多个 task 并行读取数据时如何对表进行分区。 scan.partition.column 必须是相关表中的数字、日期或时间戳列。注意,scan.partition.lower-bound 和 scan.partition.upper-bound 用于决定分区的起始位置和过滤表中的数据。如果是批处理作业,也可以在提交 flink 作业之前获取最大值和最小值。
- scan.partition.column:输入用于进行分区的列名。
- scan.partition.num:分区数。
- scan.partition.lower-bound:第一个分区的最小值。
- scan.partition.upper-bound:最后一个分区的最大值。
七、Lookup Cache
JDBC 连接器可以用在时态表关联中作为一个可 lookup 的 source (又称为维表),当前只支持同步的查找模式。
默认情况下,lookup cache 是未启用的,你可以将 lookup.cache 设置为 PARTIAL 参数来启用。
lookup cache 的主要目的是用于提高时态表关联 JDBC 连接器的性能。默认情况下,lookup cache 不开启,所以所有请求都会发送到外部数据库。 当 lookup cache 被启用时,每个进程(即 TaskManager)将维护一个缓存。Flink 将优先查找缓存,只有当缓存未查找到时才向外部数据库发送请求,并使用返回的数据更新缓存。 当缓存命中最大缓存行 lookup.partial-cache.max-rows 或当行超过 lookup.partial-cache.expire-after-write 或 lookup.partial-cache.expire-after-access 指定的最大存活时间时,缓存中的行将被设置为已过期。 缓存中的记录可能不是最新的,用户可以将缓存记录超时设置为一个更小的值以获得更好的刷新数据,但这可能会增加发送到数据库的请求数。所以要做好吞吐量和正确性之间的平衡。
默认情况下,flink 会缓存主键的空查询结果,你可以通过将 lookup.partial-cache.cache-missing-key 设置为 false 来切换行为。
八、幂等写入
如果在 DDL 中定义了主键,JDBC sink 将使用 upsert 语义而不是普通的 INSERT 语句。upsert 语义指的是如果底层数据库中存在违反唯一性约束,则原子地添加新行或更新现有行,这种方式确保了幂等性。
如果出现故障,Flink 作业会从上次成功的 checkpoint 恢复并重新处理,这可能导致在恢复过程中重复处理消息。强烈推荐使用 upsert 模式,因为如果需要重复处理记录,它有助于避免违反数据库主键约束和产生重复数据。
除了故障恢复场景外,数据源(kafka topic)也可能随着时间的推移自然地包含多个具有相同主键的记录,这使得 upsert 模式是用户期待的。
由于 upsert 没有标准的语法,因此下表描述了不同数据库的 DML 语法:
| 数据库 | 更新语法 |
|---|---|
| MySQL | INSERT … ON DUPLICATE KEY UPDATE … |
| Oracle | MERGE INTO … USING (…) ON (…) WHEN MATCHED THEN UPDATE SET (…) WHEN NOT MATCHED THEN INSERT (…) VALUES (…) |
| PostgreSQL | INSERT … ON CONFLICT … DO UPDATE SET … |
| MS SQL Server | MERGE INTO … USING (…) ON (…) WHEN MATCHED THEN UPDATE SET (…) WHEN NOT MATCHED THEN INSERT (…) VALUES (…) |
九、JDBC Catalog
JdbcCatalog 允许用户通过 JDBC 协议将 Flink 连接到关系数据库。
目前,JDBC Catalog 有两个实现,即 Postgres Catalog 和 MySQL Catalog。目前支持如下 catalog 方法。其他方法目前尚不支持。
// Postgres Catalog & MySQL Catalog 支持的方法
databaseExists(String databaseName);
listDatabases();
getDatabase(String databaseName);
listTables(String databaseName);
getTable(ObjectPath tablePath);
tableExists(ObjectPath tablePath);
其他的 Catalog 方法现在尚不支持。
十、JDBC Catalog 的使用
本小节主要描述如果创建并使用 Postgres Catalog 或 MySQL Catalog。 请参阅 Dependencies 部分了解如何配置 JDBC 连接器和相应的驱动。
JDBC catalog 支持以下参数:
- name:必填,catalog 的名称。
- default-database:必填,默认要连接的数据库。
- username:必填,Postgres/MySQL 账户的用户名。
- password:必填,账户的密码。
- base-url:必填,(不应该包含数据库名)
- 对于 Postgres Catalog base-url 应为 “jdbc:postgresql://:” 的格式。
- 对于 MySQL Catalog base-url 应为 “jdbc:mysql://:” 的格式。
SQL:
CREATE CATALOG my_catalog WITH('type' = 'jdbc','default-database' = '...','username' = '...','password' = '...','base-url' = '...'
);USE CATALOG my_catalog;
Java:
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);String name = "my_catalog";
String defaultDatabase = "mydb";
String username = "...";
String password = "...";
String baseUrl = "..."JdbcCatalog catalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl);
tableEnv.registerCatalog("my_catalog", catalog);// 设置 JdbcCatalog 为会话的当前 catalog
tableEnv.useCatalog("my_catalog");
Scala:
val settings = EnvironmentSettings.inStreamingMode()
val tableEnv = TableEnvironment.create(settings)val name = "my_catalog"
val defaultDatabase = "mydb"
val username = "..."
val password = "..."
val baseUrl = "..."val catalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl)
tableEnv.registerCatalog("my_catalog", catalog)// 设置 JdbcCatalog 为会话的当前 catalog
tableEnv.useCatalog("my_catalog")
Python:
from pyflink.table.catalog import JdbcCatalogenvironment_settings = EnvironmentSettings.in_streaming_mode()
t_env = TableEnvironment.create(environment_settings)name = "my_catalog"
default_database = "mydb"
username = "..."
password = "..."
base_url = "..."catalog = JdbcCatalog(name, default_database, username, password, base_url)
t_env.register_catalog("my_catalog", catalog)# 设置 JdbcCatalog 为会话的当前 catalog
t_env.use_catalog("my_catalog")
YAML
execution:...current-catalog: my_catalog # 设置目标 JdbcCatalog 为会话的当前 catalogcurrent-database: mydbcatalogs:- name: my_catalogtype: jdbcdefault-database: mydbusername: ...password: ...base-url: ...
十一、JDBC Catalog for PostgreSQL
PostgreSQL 元空间映射
除了数据库之外,postgreSQL 还有一个额外的命名空间 schema。一个 Postgres 实例可以拥有多个数据库,每个数据库可以拥有多个 schema,其中一个 schema 默认名为 “public”,每个 schema 可以包含多张表。 在 Flink 中,当查询由 Postgres catalog 注册的表时,用户可以使用 schema_name.table_name 或只有 table_name,其中 schema_name 是可选的,默认值为 “public”。
因此,Flink Catalog 和 Postgres 之间的元空间映射如下:
| Flink 目录元空间结构 | Postgres 元空间结构 |
|---|---|
| catalog name (defined in Flink only) | N/A |
| database name | database name |
| table name | [schema_name.]table_name |
Flink 中的 Postgres 表的完整路径应该是 “..<schema.table>”。如果指定了 schema,请注意需要转义 <schema.table>。
这里提供了一些访问 Postgres 表的例子:
-- 扫描 'public' schema(即默认 schema)中的 'test_table' 表,schema 名称可以省略
SELECT * FROM mypg.mydb.test_table;
SELECT * FROM mydb.test_table;
SELECT * FROM test_table;-- 扫描 'custom_schema' schema 中的 'test_table2' 表,
-- 自定义 schema 不能省略,并且必须与表一起转义。
SELECT * FROM mypg.mydb.`custom_schema.test_table2`
SELECT * FROM mydb.`custom_schema.test_table2`;
SELECT * FROM `custom_schema.test_table2`;
十二、JDBC Catalog for MySQL
MySQL 元空间映射
MySQL 实例中的数据库与 MySQL Catalog 注册的 catalog 下的数据库处于同一个映射层级。一个 MySQL 实例可以拥有多个数据库,每个数据库可以包含多张表。 在 Flink 中,当查询由 MySQL catalog 注册的表时,用户可以使用 database.table_name 或只使用 table_name,其中 database 是可选的,默认值为创建 MySQL Catalog 时指定的默认数据库。
因此,Flink Catalog 和 MySQL catalog 之间的元空间映射如下:
| Flink 目录元空间结构 | Mysql 元空间结构 |
|---|---|
| catalog name (defined in Flink only) | N/A |
| database name | database name |
| table name | table_name |
Flink 中的 MySQL 表的完整路径应该是 “<catalog>.<db>.<table>”。
这里提供了一些访问 MySQL 表的例子:
-- 扫描 默认数据库中的 'test_table' 表
SELECT * FROM mysql_catalog.mydb.test_table;
SELECT * FROM mydb.test_table;
SELECT * FROM test_table;-- 扫描 'given_database' 数据库中的 'test_table2' 表,
SELECT * FROM mysql_catalog.given_database.test_table2;
SELECT * FROM given_database.test_table2;
十三、数据类型映射
Flink 支持连接到多个使用方言(dialect)的数据库,如 MySQL、Oracle、PostgreSQL、Derby 等。其中,Derby 通常是用于测试目的。下表列出了从关系数据库数据类型到 Flink SQL 数据类型的类型映射,映射表可以使得在 Flink 中定义 JDBC 表更加简单。
| MySQL type | Oracle type | PostgreSQL type | SQL Server type | Flink SQL type |
|---|---|---|---|---|
| TINYINT | TINYINT | TINYINT | ||
| SMALLINT, TINYINT UNSIGNED | SMALLINT, INT2, SMALLSERIAL, SERIAL2 | SMALLINT | SMALLINT | |
| INT, MEDIUMINT, SMALLINT UNSIGNED | INTEGER, SERIAL | INT | INT | |
| BIGINT, INT UNSIGNED | BIGINT, BIGSERIAL | BIGINT | BIGINT | |
| BIGINT UNSIGNED | DECIMAL(20, 0) | |||
| BIGINT | BIGINT | BIGINT | BIGINT | |
| FLOAT | BINARY_FLOAT | REAL, FLOAT4 | REAL | FLOAT |
| DOUBLE, DOUBLE PRECISION | BINARY_DOUBLE | FLOAT8, DOUBLE PRECISION | FLOAT | DOUBLE |
| NUMERIC(p, s), DECIMAL(p, s) | SMALLINT, FLOAT(s), DOUBLE PRECISION, REAL, NUMBER(p, s) | NUMERIC(p, s), DECIMAL(p, s) | DECIMAL(p, s) | DECIMAL(p, s) |
| BOOLEAN, TINYINT(1) | BOOLEAN | BIT | BOOLEAN | |
| DATE | DATE | DATE | DATE | DATE |
| TIME [§] | DATE | TIME [§] [WITHOUT TIMEZONE] | TIME(0) | TIME [§] [WITHOUT TIMEZONE] |
| DATETIME [§] | TIMESTAMP [§] [WITHOUT TIMEZONE] | TIMESTAMP [§] [WITHOUT TIMEZONE] | DATETIME, DATETIME2 | TIMESTAMP [§] [WITHOUT TIMEZONE] |
| CHAR(n), VARCHAR(n), TEXT | CHAR(n), VARCHAR(n), CLOB | CHAR(n), CHARACTER(n), VARCHAR(n), CHARACTER VARYING(n), TEXT | CHAR(n), NCHAR(n), VARCHAR(n), NVARCHAR(n), TEXT, NTEXT | STRING |
| BINARY, VARBINARY, BLOB | RAW(s), BLOB | BYTEA | BINARY(n), VARBINARY(n) | BYTES |
| ARRAY | ARRAY |
相关文章:

Flink系列之:JDBC SQL 连接器
Flink系列之:JDBC SQL 连接器 一、JDBC SQL 连接器二、依赖三、创建 JDBC 表四、连接器参数五、键处理六、分区扫描七、Lookup Cache八、幂等写入九、JDBC Catalog十、JDBC Catalog 的使用十一、JDBC Catalog for PostgreSQL十二、JDBC Catalog for MySQL十三、数据…...

OpenCV与YOLO学习与研究指南
引言 OpenCV是一个开源的计算机视觉和机器学习软件库,而YOLO(You Only Look Once)是一个流行的实时对象检测系统。对于大学生和初学者而言,掌握这两项技术将大大提升他们在图像处理和机器视觉领域的能力。 基础知识储备 在深入…...

hive中map相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释 hive官网函数大全地址: hive官网函数大全地址 Return TypeNameDescriptionmapmap(key1, value1, key2, value2, …)Creates a map with the given key/value pairs.arraymap_values(Map<K.V>)Returns an un…...

HttpServletRequestWrapper、HttpServletResponseWrapper结合 过滤器 实现接口的加解密、国际化
目录 一、HttpServletRequestWrapper代码 二、HttpServletRequestWrapper代码 三、加解密过滤器代码 四、国际化过滤器代码 一、HttpServletRequestWrapper代码 package com.vteam.uap.security.httpWrapper;import jakarta.servlet.ReadListener; import jakarta.servlet.…...

最大通关数
洛洛和晶晶计划一起挑战峡谷深渊,峡谷左右有不同数量的关卡,每个关卡需要不同的紫水晶通关,用给定的紫水晶依次通过最多的关卡。 (笔记模板由python脚本于2023年12月23日 12:16:50创建,本篇笔记适合熟悉贪心算法的coder翻阅) 【学…...

MySQL中EXPLAIN关键字解释
什么是MySQL的索引 索引是帮助MySQL高效获取数据的数据结构 MySQL再存储数据之外,数据库系统中还维护者满足特定查找算法的数据结构,这些数据结构以某种引用表中的数据,这样我们就可以通过数据结构上实现的高级查找算法来快速…...

初始JavaScript详解【精选】
Hi i,m JinXiang ⭐ 前言 ⭐ 本篇文章主要介绍初始JavaScript以及部分理论知识 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主收将持续更新学习记录获,友友们有任何问题可以在评论区留言 目录 ⭐…...

计数排序,基数排序及排序总结
稳定性:当要排序的数组有相同数据时,排序后相同数据的相对位置不变,则称该排序算法稳定,否则即为不稳定. 在这里我在说说计数排序吧,计数排序就是将给定数组中的数进行计数,在从小到大依次输出即可。简单过…...
)
【LeetCode】459. 重复的子字符串(KMP2.0)
今日学习的文章链接和视频链接 leetcode题目地址:459. 重复的子字符串 代码随想录题解地址:代码随想录 题目简介 给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。 看到题目的第一想法(可以贴代码) 1.…...

CSS(五) -- 动效实现(立体盒子旋转-四方体+正六边)
一. 四面立体旋转 正方形旋转 小程序中 wxss中 <!-- 背景 --><view class"dragon"><!--旋转物体位置--><view class"dragon-position"><!--旋转 加透视 有立体的感觉--><view class"d-parent"><view …...
)
Win10使用OpenSSL生成证书的详细步骤(NodeJS Https服务器源码)
远程开启硬件权限,会用到SSL证书。 以下是Win10系统下用OpenSSL生成测试用证书的步骤。 Step 1. 下载OpenSSL,一般选择64位的MSI Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions 一路点下来,如果后续请你捐款ÿ…...
sql_lab之sqli中的堆叠型注入(less-38)
堆叠注入(less-38) 1.判断注入类型 http://127.0.0.3/less-38/?id1 and 12 -- s 没有回显 http://127.0.0.3/less-38/?id1 and 11 -- s 有回显 则说明是单字节’注入 2.查询字段数 http://127.0.0.3/less-38/?id1 order by 4 -- s 报错 http:/…...

第5章-第3节-Java中对象的封装性以及局部变量、this、static
1、局部变量 【问题1】:什么是局部变量? 答:定义在局部位置的变量就是局部变量。 【问题2】:什么是局部位置? 答:方法的形参位置、方法体的内部。 【位置关系图】: class Xxx { //成员位…...

IP应用场景的规划
IP地址作为互联网通信的基石,在现代社会中扮演着至关重要的角色。本文将深入探讨IP地址在不同应用场景中的规划与拓展,探讨其在网络通信、安全、商业、医疗和智能城市等领域的关键作用与未来发展趋势。 IP地址的基本原理 IP地址是分配给网络上设备的数…...
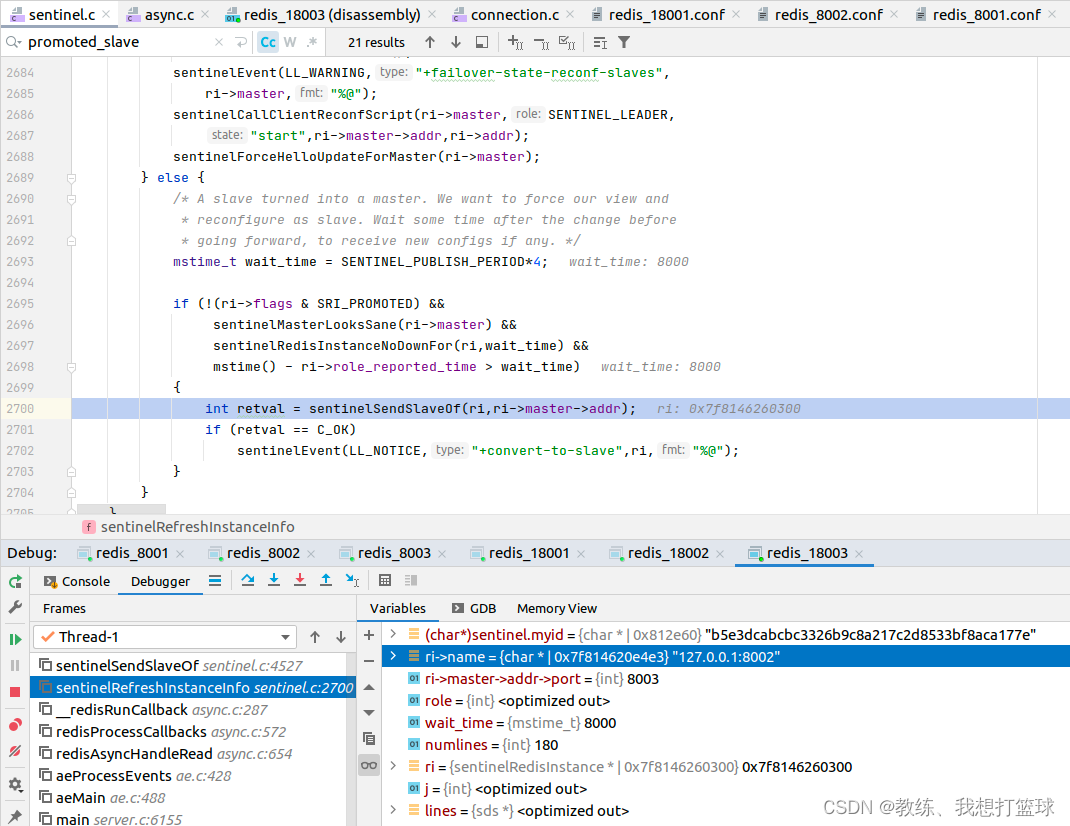
27 redis 的 sentinel 集群
前言 redis 的哨兵的相关业务功能的实现 哨兵的主要作用是 检测 redis 主从集群中的 master 是否挂掉, 单个哨兵节点识别 master 下线为主管下线, 超过 quorum 个 哨兵节点 认为 master 挂掉, 识别为 客观下线 然后做 failover 的相关处理, 重新选举 master 节点 我们这里…...

计算机网络 网络安全技术
网络安全基本要素 机密性 不泄密完整性 信息不会被破坏可用性 授权用户 正常有效使用可控性 被控制可审查性 网络安全的结构层次 物理安全 物理介质安全控制 计算机操作系统安全服务 应用层次 被动攻击 :截获信息 主动攻击 : 中断信息,篡改,伪造 篡改 …...

WebAssembly 的魅力:高效、安全、跨平台(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

二维码智慧门牌管理系统升级:确保公安机关数据安全无忧
文章目录 前言一、多重安全防护措施二、安全措施综述与展望 前言 数据安全挑战与重要性 在数字化社会,数据安全对公共管理机构,尤其是公安机关而言,至关重要。随着二维码技术在门牌管理系统中的广泛应用,管理变得更智能、更便捷。…...

Golang leetcode59 螺旋矩阵
螺旋矩阵 leetcode59 初次尝试,从中心向外 func main() {n : 3fmt.Println(generateMatrix(n)) }// 初版,我们从中心点开始 func generateMatrix(n int) [][]int {//1.nXn矩阵table : make([][]int, n)for i : 0; i < n; i {table[i] make([]int, …...
 简介)
深度学习(Deep Learning) 简介
深度学习(Deep Learning) 深度学习在海量数据情况下的效果要比机器学习更为出色。 多层神经网络模型 神经网络 有监督机器学习模型 输入层隐藏层 (黑盒)输出层 概念: 神经元 Neuron A^(n1)网络权重 Weights W^n偏移 bias b^n 激活函数: ReLUtan…...

终极PHPExcel性能优化指南:从512MB到1GB内存的突破技巧
终极PHPExcel性能优化指南:从512MB到1GB内存的突破技巧 【免费下载链接】PHPExcel ARCHIVED 项目地址: https://gitcode.com/gh_mirrors/ph/PHPExcel PHPExcel作为一款强大的PHP电子表格处理库,在处理大型数据时常常面临内存不足的挑战。本文将分…...

ARM性能采样机制与PMSFCR_EL1寄存器详解
1. ARM性能采样机制概述在现代处理器性能分析领域,硬件辅助的采样技术已成为不可或缺的工具。ARM架构通过FEAT_SPE(Statistical Profiling Extension)扩展提供了一套完整的性能采样解决方案,其中PMSFCR_EL1寄存器扮演着采样过滤控…...

航空EWIS自动化设计:合规挑战与工程实践
1. EWIS合规挑战与自动化设计价值现代航空器的电气线路互联系统(EWIS)设计正面临前所未有的合规压力。一架波音787包含超过100英里的电线和数千个连接器,每根导线都必须满足FAR 25.1701至25.1733的完整规范要求。我曾参与某型支线客机的EWIS设计项目,仅线…...

从“烧钱黑洞”到“精准印钞机”:某二手精雕机公司的SEM逆袭之路
这是一家专注于北京地区二手精雕机销售与服务的机械制造企业。在启动SEM竞价推广初期,公司面临着典型的B2B工业品营销困境:月均咨询量低、线索质量差、获客成本高企,推广投入仿佛掉入了“烧钱黑洞”🕳️。 困境具体表现与深层缘由…...

基于PI控制的双向DC-AC逆变器直流稳压与交流稳流仿真
目录 手把手教你学Simulink——基于PI控制的双向DC-AC逆变器直流稳压与交流稳流仿真 一、背景与挑战 1.1 为什么是“直流稳压 + 交流稳流”? 1.2 核心痛点与控制难点 二、系统架构与核心控制推导 2.1 整体架构:功率级与控制级的“左右互搏” 2.2 核心数学推导:逆变器模…...

如何快速掌握Obsidian OCR插件:面向初学者的完整教程
如何快速掌握Obsidian OCR插件:面向初学者的完整教程 【免费下载链接】obsidian-ocr Obsidian OCR allows you to search for text in your images and pdfs 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-ocr 你是否曾为无法搜索图片和PDF中的文字…...

期刊屡投不中?虎贲等考 AI:真文献 + 实证图表 + 期刊规范,高效冲击录用
职称评审、课题结题、科研评优、学业深造……一篇高质量期刊论文是所有学术人绕不开的硬指标。但框架难搭、文献难找、实证难做、格式难调、审稿太严,让无数人陷入 “写得慢、返修多、录用难” 的困境。通用 AI 爱编文献、普通工具无实证、办公软件不学术࿰…...

学习复盘:SQL 注入原理、类型、手工注入及绕过防御
一、前言今天系统继续学习了 Web 安全核心漏洞 SQL 注入,主要的内容就是手动注入SQL 注入是Web 渗透最基础也最重要的漏洞,几乎所有动态网站都曾出现过,是学习网安很重要的一部分二、理解SQL注入1. 简单理解 SQLSQL 是操作关系型数据库的语言…...

Midscene.js如何实现跨平台AI自动化测试:从零到精通的5步配置指南
Midscene.js如何实现跨平台AI自动化测试:从零到精通的5步配置指南 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene Midscene.js是一款基于视觉语言模型…...
:LLM Task)
OpenClaw从入门到应用——工具(Tools):LLM Task
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 llm-task 是一个可选插件工具,用于运行纯 JSON 格式的 LLM 任务,并返回结构化输出(可选择是否依据 JSON Schema 进行验证&#x…...