Milvus向量数据库基础用法及注意细节
1、Milvus数据类型与python对应的数据类型
| Milvus | Python |
| DataType.INT64 | numpy.int64 |
| DataType.INT32 | numpy.int32 |
| DataType.INT16 | numpy.int16 |
| DataType.BOOL | Boolean |
| DataType.FLOAT | numpy.float32 |
| DataType.DOUBLE | numpy.double |
| DataType.ARRAY | list |
| DataType.VARCHAR | str |
| DataType.JSON | dict |
| FLOAT_VECTOR(浮点数向量) | numpy.ndarray or list (元素为numpy.float) |
2、python创建集合->构建索引->发布步骤
(1)连接向量数据库:
from pymilvus import connections,db
connections.connect("default",host="localhost",prot="19530")(2)删除现有集合:
from pymilvus import utility
utility.drop_collection('ITEM_INFO')(3)字段常用数据类型创建:
from pymilvus import FieldSchema, DataType
# 创建数据类型为INT64的主键,且主键ID自动递增
ID_col = FieldSchema(name="ID",dtype=DataType.INT64,is_primary=True,description='主键、序号',auto_id=True)
# 创建一个768维的浮点向量
vec_col = FieldSchema(name="itemVec",dtype=DataType.FLOAT_VECTOR,dim=768,description = '向量')
# 创建一个长度128维的字符串
name_col = FieldSchema(name = 'itemName',dtype = DataType.VARCHAR,max_length = 128,description = '商品名称')
# 创建double类型的浮点数
price_col = FieldSchema(name = 'itemPrice',dtype = DataType.DOUBLE,description = '价格')
# 创建json格式的字段
keywords_col = FieldSchema(name = 'keywords',dtype = DataType.JSON)(4)创建集合
from pymilvus import CollectionSchema, Collection, connections
# 集合所包含的字段
schema = CollectionSchema(fields=[ID_col,vec_col,name_col,price_col,keywords_col],description="商品信息表",enable_dynamic_field=True
)
# 集合名称
collection_name = "GOODS_INFO"
# 构建集合后断开连接
collection = Collection(name=collection_name,schema=schema,using='default',shards_num=2)
connections.disconnect("default")(5)构建索引
Milvus中构建索引的数据量最小为1024,满足2的幂次方,数据量不满1024时必须使用1024构建索引。
from pymilvus import Collection
# 连接集合
collection = Collection("GOODS_INFO")
# 构建索引所需的参数
index_params = {"metric_type":"L2","index_type":"IVF_FLAT","params":{"nlist":1024}
}
# 在向量上构建索引
collection.create_index(field_name="itemVec", index_params=index_params)(6)发布集合
from pymilvus import Collection, utility, connections
# 连接集合
collection = Collection("GOODS_INFO")
# 发布集合
collection.load()
# 检查集合上线状态
utility.load_state("GOODS_INFO")
# 断开与向量数据库的连接
connections.disconnect('default')3、条件过滤
1、假设集合中有一字段A的数据类型为整型或浮点型,则可以
expr = 'A > 0 && A <= 10'2、假设集合中有一字段A为任意数据类型,则可以
# a,b,c,d为任意数据类型,可与A相同或不同
expr = 'A in [a,b,c,d]'
expr = 'A not in [a,b,c,d]'3、假设集合中有一字段A为字符类型,则可以 # 在条件过滤中字符串要添加引号确定
# 在条件过滤中字符串要添加引号确定
expr = "A == 'Hello World!'"4、假设集合中有一字段A为字符类型,则可以
# 从A开头为123的向量中进行向量检索,目前milvus只支持字符前缀匹配,不支持'1%23'或'%123'
expr = "A like '123%'"5、假设集合中有一字段A为json类型,则可以
# A = {"x": [1,2,3]}
expr = 'json_contains(A["x"], 1)' # ==> true
expr = 'json_contains(A["x"], "a")' # ==> false# A = {"x": [[1,2,3], [4,5,6], [7,8,9]]}
expr = 'json_contains(A["x"], [1,2,3])' # ==> true
expr = 'json_contains(A["x"], [3,2,1])' # ==> false# A = {"x": [1,2,3,4,5,7,8]}
expr = 'json_contains_all(A["x"], [1,2,8])' # ==> true
expr = 'json_contains_all(A["x"], [4,5,6])' # ==> false 6 is not exists# A = {"x": [1,2,3,4,5,7,8]}
expr = 'json_contains_any(A["x"], [1,2,8])' # ==> true
expr = 'json_contains_any(A["x"], [4,5,6])' # ==> true
expr = 'json_contains_any(A["x"], [6,9])' # ==> false6、假设集合中有一字段A为list类型,则可以
# 该方法为上述方法2、的逆方法
# A: [1,2,3]
expr = 'array_contains(A, 1)' # ==> true
expr = 'array_contains(A, "a")' # ==> false# A: [1,2,3,4,5,7,8]
expr = 'array_contains_all(A, [1,2,8])' # ==> true
expr = 'array_contains_all(A, [4,5,6])' # ==> false 6 is not exists# A: [1,2,3,4,5,7,8]
expr = 'array_contains_any(A, [1,2,8])' # ==> true
expr = 'array_contains_any(A, [4,5,6])' # ==> true
expr = 'array_contains_any(A, [6,9])' # ==> false# A: [1,2,3,4,5,7,8]
expr = 'array_length(int_array) == 7' # ==> true假设有一集合,集合当中包含V、A、B、C四个字段:
V:浮点向量
A:向量的字符表达形式
B:A的属性1
C:A的属性2
现有一查询向量S、过滤条件E1和过滤条件E2(E1、E2均为列表),集合需要返回S与V相似度最高,且B包含于E1、C包含于E2的字符名称A。如果采用上述1、2、3、4方法中较基础的数据类型存表会导致查询速度和代码复杂度都较高。假设E1 = [1,2,3],E2 = [4,5,6],则对于同一条向量,需要做3 x 3 = 9次过滤。若使用5、6方法中的数据类型存表则可以将过滤次数降为2次。
例如
# B和C为字符串类型
expr = '(1 in B && 4 in C) or (1 in B && 5 in C) or (1 in B && 6 in C) ...'# B和C为keywords中的元素,keywords为json格式
expr = "json_contains_any(keywords['B'], E1) && json_contains_any(keywords['C'], E2)"# B和C均为列表
expr = "array_contains_any(B, E1) && json_contains_any(C, E2)"4、查询
from pymilvus import Collection, connections# 连接数据库,连接集合,将集合数据上传至内存
connections.connect("default",host="localhost",prot="19530")
knowledge = Collection('GOODS_INFO', using='default')
knowledge.load()# 查询参数
search_params = {"metric_type": "L2","offset": 0,"ignore_growing": False,"params": {"nprobe": 10,# "radius": 10, # 对于L2,返回距离在[5,10)之间的向量# "range_filter": 5.0 # 对于IP,返回相似度在(0.8,1]之间的向量}
}# 进行向量查询
results = knowledge.search(data=query, #带查询向量anns_field='itemVec', #表中向量字段名称param=search_params, #查询参数limit=5, #返回数量expr=expr, #过滤条件,expr = None或''时,默认为不使用条件过滤output_fields=['itemName', 'itemPrice', 'keywords'] #返回的字段名称)# 断开数据库连接
connections.remove_connection('default')5、参考资料
Create a Collection Milvus documentation
相关文章:

Milvus向量数据库基础用法及注意细节
1、Milvus数据类型与python对应的数据类型 Milvus Python DataType.INT64 numpy.int64 DataType.INT32 numpy.int32 DataType.INT16 numpy.int16 DataType.BOOL Boolean DataType.FLOAT numpy.float32 DataType.DOUBLE numpy.double DataType.ARRAY list DataT…...

虚拟机多开怎么设置不同IP?虚拟机设置独立IP的技巧
随着虚拟化技术的不断发展,虚拟机已经成为了许多人的必备工具。在虚拟机中,我们可以轻松地创建多个虚拟机,并在每个虚拟机中设置不同的IP地址。下面,我们将介绍如何在虚拟机中设置独立IP地址的方法。 一、虚拟机多开设置不同IP的方…...
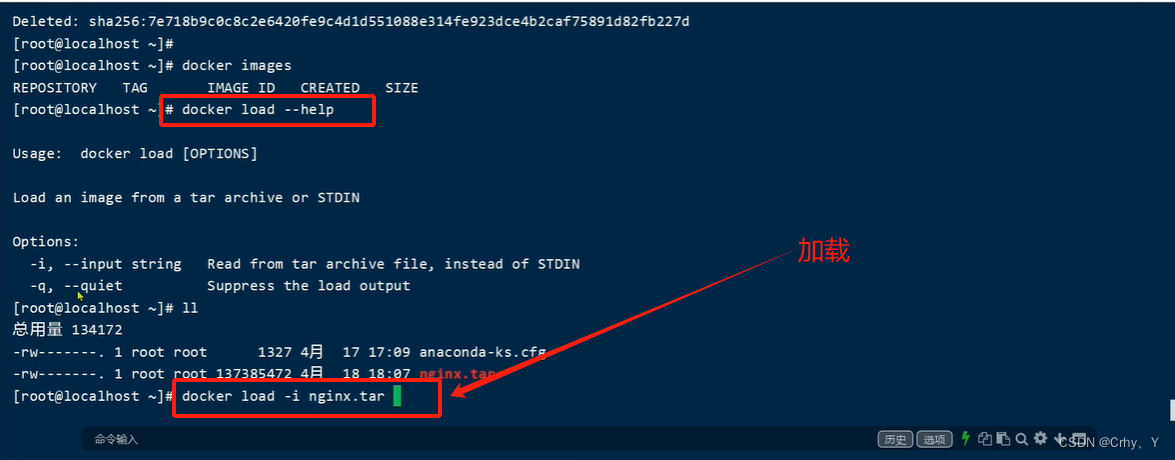
使用Docker-镜像命令
镜像名称一般分两部分组成:[repository]:[tag] 在没有指定tag时,默认是latest,代表最新版本的镜像 目录 案例一:从DockerHub中拉取一个nginx镜像并查看 1.1. 首先去镜像仓库搜索nginx镜像,比如DockerHub 编辑 1.2.操作拉取n…...

4.3 C++对象模型和this指针
4.3 C对象模型和this指针 4.3.1 成员变量和成员函数分开存储 在C中,类内的成员变量和成员函数分开存储 只有非静态成员变量才属于类的对象上 #include <iostream>class Person { public:Person() {mA 0;} //非静态成员变量占对象空间int mA;//静态成员变量…...
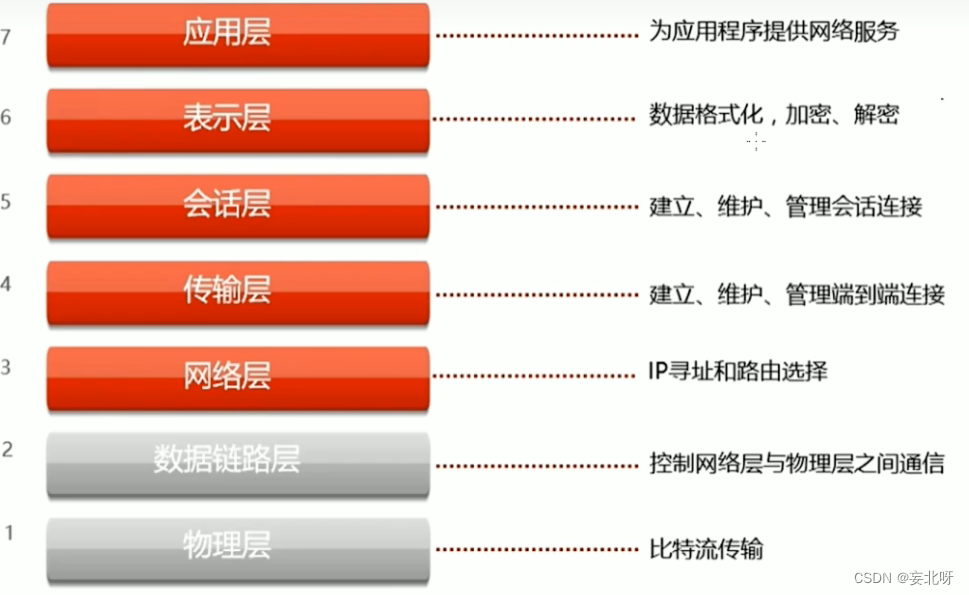
计算机网络——计算机网络的概述(一)
前言: 面对马上的期末考试,也为了以后找工作,需要掌握更多的知识,而且我们现实生活中也已经离不开计算机,更离不开计算机网络,今天开始我们就对计算机网络的知识进行一个简单的学习与记录。 目录 一、什么…...

基于多反应堆的高并发服务器【C/C++/Reactor】(中)ChannelMap 模块的实现
(三)ChannelMap 模块的实现 这个模块其实就是为Channel来服务的,前面讲了Channel这个结构体里边它封装了文件描述符。假如说我们得到了某一个文件描述符,需要基于这个文件描述符进行它对应的事件处理,那怎么办呢&…...

微信小程序实现一个音乐播放器的功能
微信小程序实现一个音乐播放器的功能 要求代码实现wxml 文件wxss 文件js文件 解析 要求 1.页面包含一个音乐列表,点击列表中的音乐可以播放对应的音乐。 2.播放中的音乐在列表中有标识,并且可以暂停或继续播放。 3.显示当前音乐的播放进度和总时长&#…...

算法基础之表达整数的奇怪方式
表达整数的奇怪方式 中国剩余定理: 求M 所有m之积 然后Mi M / mi x 如下图 满足要求 扩展中国剩余定理 找到x **使得x mod mi ai**成立 对于每两个式子 都可以推出①式 即 用扩展欧几里得算法 可以算出k1,-k2和m2–m1 判无解 : 若**(m2–m1) % d ! 0** 说明该等式无解 …...
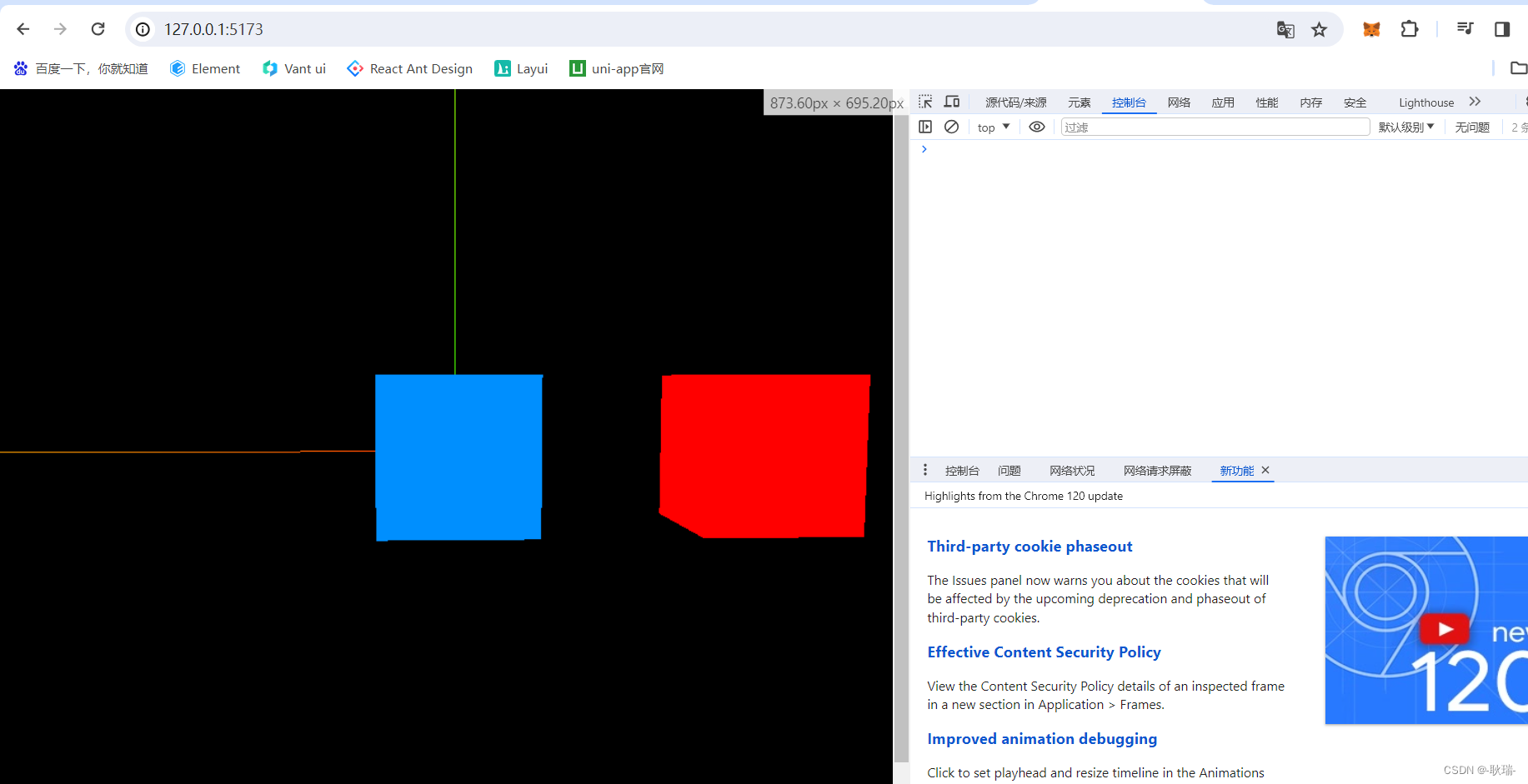
WEB 3D技术 three.js 设置图像随窗口大小变化而变化
本文 我们来讲讲我们图层适应窗口变化的效果 可能这样说有点笼统 那么 自适应应该大家更熟悉 就是 当我们窗口发生变化说 做一些界面调整比例 例如 我们这样一个i项目界面 我们打开 F12 明显有一部分被挡住了 那么 我们可以刷新 这样是正常了 但是 我们将F12关掉 给F12的…...
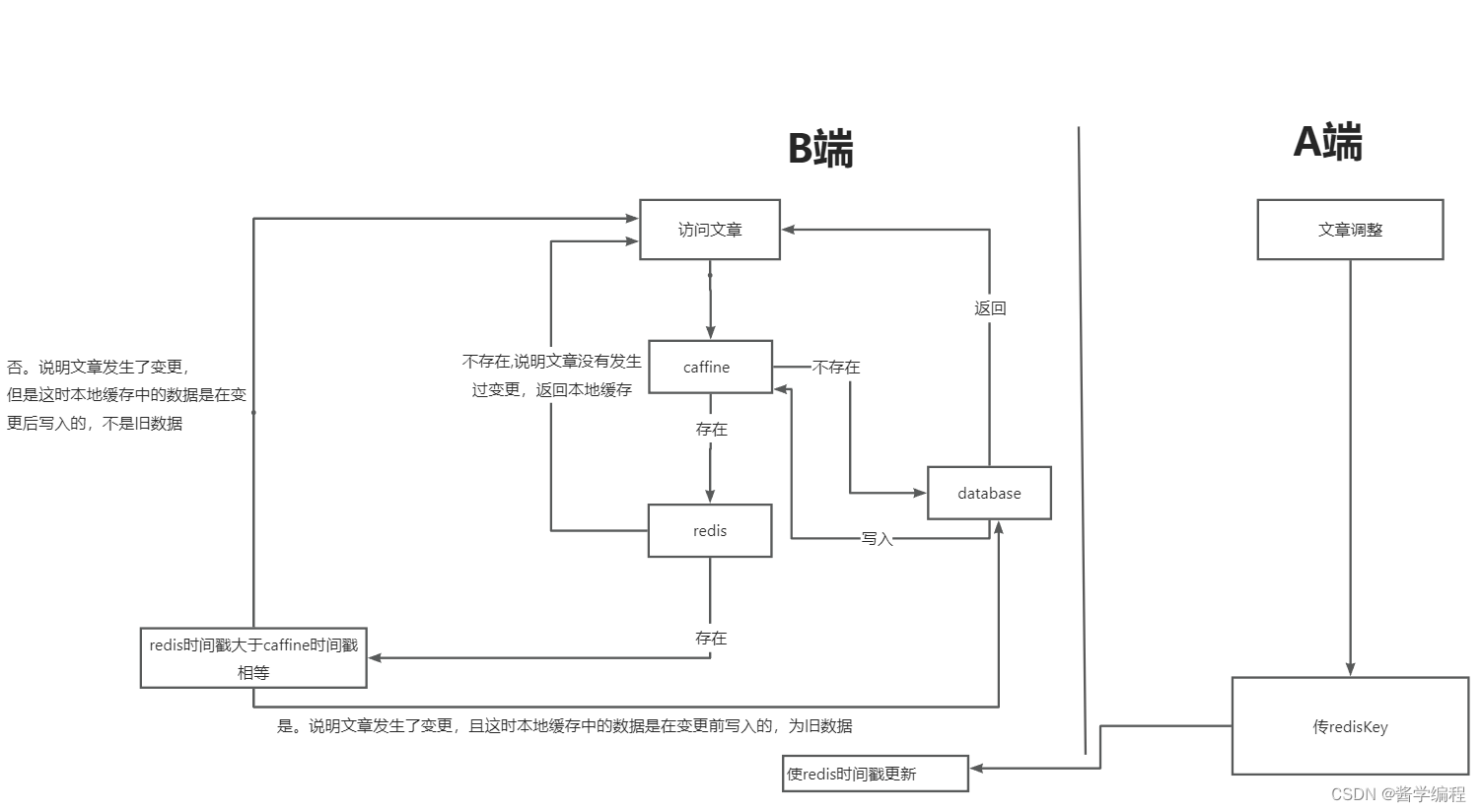
实战案例:缓存不一致问题的解决(redis+本地缓存caffine)
一.问题引入 目前在写项目的时候,在B端查看文章,A端修改文章。为了增加效率,以及防止堆内存溢出,在B端选择本地缓存文章的方案。但是目前出现了A端对文章修改之后,B端读的还是旧数据,出现了缓存不一致的问…...

【开源CDP】市场增长未来的探索,开源CDP带来的技术崛起与变革
数字化趋势之下,数据成了企业竞争的核心资源,不管是公域还是私域,网络俨然成了品牌打响市场的一线战场,然而,在这场数字战役里,许多企业不得不面临一个共同问题:数据零散、分散、平台众多、无法…...
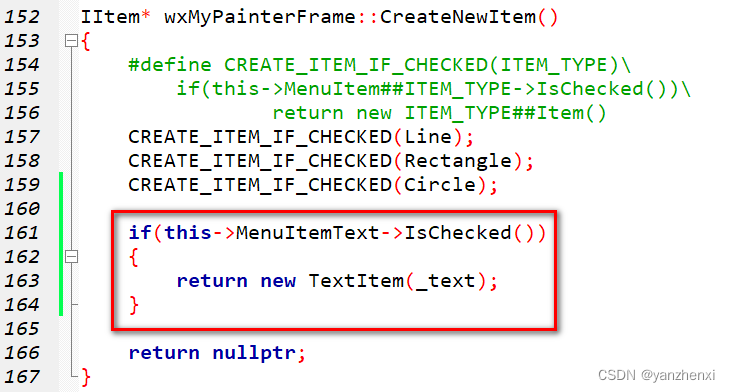
第11章 GUI Page423~424 步骤六 支持文字,使用菜单,对话框输入文字
运行效果: 点击OK,然后再窗口上按住左键,拖动鼠标 关键代码: 新增头文件和成员,新增私有成员_text 成员初始化 为菜单项MenuItemText添加响应函数 新增创建TextItem()的代码...

【Qt】Qt Creator 警告: Unused parameter ‘xxx‘
1. 问题 Qt开发中,有些函数参数没有使用,会报Unused parameter xxx警告,这个警告不影响代码正常运行。 2. 屏蔽这个警告的方法 2.1 方法1 函数中添加 Q_UNUSED(arg); TestClass::TestClass(QObject *parent) {Q_UNUSED(parent); }2.2 方…...

「Vue3面试系列」Vue3.0性能提升主要是通过哪几方面体现的?
文章目录 一、编译阶段diff算法优化静态提升事件监听缓存SSR优化 二、源码体积三、响应式系统参考文献 一、编译阶段 回顾Vue2,我们知道每个组件实例都对应一个 watcher 实例,它会在组件渲染的过程中把用到的数据property记录为依赖,当依赖发…...

网络结构模式
一、C/S结构 服务器 - 客户机,即 Client - Server ( C/S )结构。 C/S 结构通常采取两层结构。服务器负责数据的 管理,客户机负责完成与用户的交互任务。客户机是因特网上访问别人信息的机器,服务器则是提 供信息供人…...

IIC及OLED实验
I2C (Inter-Integrated Circuit): I2C 是一种用于在芯片之间进行短距离数字通信的串行通信协议。它允许多个设备通过两根导线(一根数据线 SDA 和一根时钟线 SCL)进行通信。I2C 常常用于嵌入式系统中连接传感器、存储器、显示屏和其他外设。 数据线和时钟…...

day6 力扣公共前缀--go实现---对字符串的一些思考
今日份知识: curl -x 指定方法名 请求的url -d 请求体body里面的内容 //curl命令 curl -x Get 127.0.0.1:8080/add/user -d jinlicurl如果不指定方法,默认使用get方法,在go里面,get方法到底可以不可以把内容数据写在body里面传…...
27.Java程序设计-基于Springboot的在线考试系统小程序设计与实现
1. 引言 随着数字化教育的发展,在线考试系统成为教育领域的一项重要工具。本论文旨在介绍一个基于Spring Boot框架的在线考试系统小程序的设计与实现。在线考试系统的开发旨在提高考试的效率,简化管理流程,并提供更好的用户体验。 2. 系统设…...

Redis可视化工具Redis Desktop Manager mac功能特色
Redis Desktop Manager mac是一款非常实用的Redis可视化工具。RDM支持SSL / TLS加密,SSH隧道,基于SSH隧道的TLS,为您提供了一个易于使用的GUI,可以访问您的Redis数据库并执行一些基本操作:将键视为树,CRUD键…...

【C++】揭开运算符重载的神秘面纱
目录 一、引言 优点 二、介绍 1.定义 2.语法 三、示例 1.加法运算符重载 2.一元运算符重载 3.友元函数 4.流插入和流提取 5.自增自减运算符 总结 一、引言 何为运算符重载?运算符重载,是C中的一项强大特性,赋予了程序员在自定义类…...
)
久鼎私域测流模式系统(现成方案)
久鼎私域测流模式系统是一套专注于私域流量监测与分析的解决方案,适用于企业精细化运营私域用户池。其核心功能包括流量来源追踪、用户行为分析、转化效果评估等,支持多平台数据整合。核心功能模块流量监测 实时监控私域流量入口(如小程序、公…...

【SLAM实战解析】卡方检验在ORB-SLAM2外点剔除中的关键作用
1. 卡方检验在SLAM中的核心价值 第一次在ORB-SLAM2的代码里看到卡方检验时,我盯着那行chi2测试代码愣了半天。这个在统计学课本里见过的概念,怎么突然出现在视觉SLAM系统中?后来才发现,这简直是SLAM开发者处理异常值的"瑞士军…...

告别编译跳转失败!手把手教你为Nordic nRF Connect SDK工程配置VS Code Workspace
告别编译跳转失败!手把手教你为Nordic nRF Connect SDK工程配置VS Code Workspace 在嵌入式开发中,代码导航和智能感知是提升开发效率的关键。对于使用Nordic nRF Connect SDK的开发者来说,VS Code本应是一个强大的开发环境,但很多…...

UICKeyChainStore常见问题解答:解决开发者遇到的典型问题
UICKeyChainStore常见问题解答:解决开发者遇到的典型问题 【免费下载链接】UICKeyChainStore UICKeyChainStore is a simple wrapper for Keychain on iOS, watchOS, tvOS and macOS. Makes using Keychain APIs as easy as NSUserDefaults. 项目地址: https://gi…...

STM32CubeMX 6.4.0 + STM32F407ZGT6 实战:基于YT8512C PHY的lwIP以太网配置与调试
1. 环境准备与硬件连接 最近在做一个物联网项目时,发现正点原子探索者开发板的PHY芯片从常见的DP83848换成了YT8512C,导致之前能跑通的以太网代码突然失效了。经过一番折腾,终于用STM32CubeMX 6.4.0完成了配置。先说说硬件准备: 开…...

Stable Yogi Leather-Dress-Collection 皮革设计效果惊艳展示:多风格高清作品集
Stable Yogi Leather-Dress-Collection 皮革设计效果惊艳展示:多风格高清作品集 最近在AI设计圈里,有个模型挺火的,叫Stable Yogi Leather-Dress-Collection。光听名字你可能就猜到了,它专门用来生成皮革连衣裙的设计图。我花了一…...

DW_apb_uart初始化全流程解析:从时钟门控到中断配置的15个关键步骤
DW_apb_uart深度初始化指南:从寄存器配置到中断优化的15个实战要点 在嵌入式系统开发中,UART通信作为最基础却又最关键的接口之一,其稳定性和性能直接影响整个系统的可靠性。DW_apb_uart作为业界广泛使用的高性能UART IP核,其初始…...

5分钟掌握防撤回神器:让重要消息无处可逃
5分钟掌握防撤回神器:让重要消息无处可逃 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_Tre…...

提升大语言模型对话体验:text-generation-webui全流程优化指南
提升大语言模型对话体验:text-generation-webui全流程优化指南 【免费下载链接】text-generation-webui A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. 项目地址: https://gitcode.com/G…...

Cursor Pro激活器技术深度解析:突破API限制的逆向工程实践
Cursor Pro激活器技术深度解析:突破API限制的逆向工程实践 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...