神经网络:深度学习基础
1.反向传播算法(BP)的概念及简单推导
反向传播(Backpropagation,BP)算法是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见算法。BP算法对网络中所有权重计算损失函数的梯度,并将梯度反馈给最优化方法,用来更新权值以最小化损失函数。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
接下来我们以全连接层,使用sigmoid激活函数,Softmax+MSE作为损失函数的神经网络为例,推导BP算法逻辑。由于篇幅限制,这里只进行简单推导,后续Rocky将专门写一篇PB算法完整推导流程,大家敬请期待。
首先,我们看看sigmoid激活函数的表达式及其导数:
s i g m o i d 表达式: σ ( x ) = 1 1 + e − x sigmoid表达式:\sigma(x) = \frac{1}{1+e^{-x}} sigmoid表达式:σ(x)=1+e−x1
s i g m o i d 导数: d d x σ ( x ) = σ ( x ) − σ ( x ) 2 = σ ( 1 − σ ) sigmoid导数:\frac{d}{dx}\sigma(x) = \sigma(x) - \sigma(x)^2 = \sigma(1- \sigma) sigmoid导数:dxdσ(x)=σ(x)−σ(x)2=σ(1−σ)
可以看到sigmoid激活函数的导数最终可以表达为输出值的简单运算。
我们再看MSE损失函数的表达式及其导数:
M S E 损失函数的表达式: L = 1 2 ∑ k = 1 K ( y k − o k ) 2 MSE损失函数的表达式:L = \frac{1}{2}\sum^{K}_{k=1}(y_k - o_k)^2 MSE损失函数的表达式:L=21k=1∑K(yk−ok)2
其中 y k y_k yk 代表ground truth(gt)值, o k o_k ok 代表网络输出值。
M S E 损失函数的偏导: ∂ L ∂ o i = ( o i − y i ) MSE损失函数的偏导:\frac{\partial L}{\partial o_i} = (o_i - y_i) MSE损失函数的偏导:∂oi∂L=(oi−yi)
由于偏导数中单且仅当 k = i k = i k=i 时才会起作用,故进行了简化。
接下来我们看看全连接层输出的梯度:
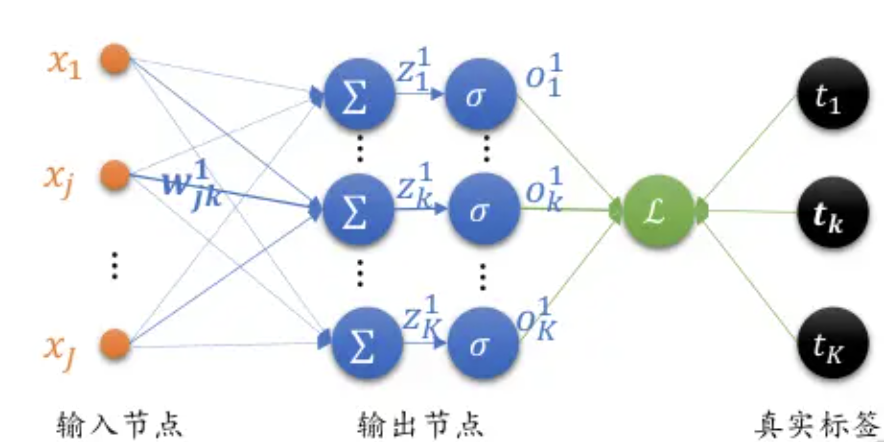
M S E 损失函数的表达式: L = 1 2 ∑ i = 1 K ( o i 1 − t i ) 2 MSE损失函数的表达式:L = \frac{1}{2}\sum^{K}_{i=1}(o_i^1 - t_i)^2 MSE损失函数的表达式:L=21i=1∑K(oi1−ti)2
M S E 损失函数的偏导: ∂ L ∂ w j k = ( o k − t k ) o k ( 1 − o k ) x j MSE损失函数的偏导:\frac{\partial L}{\partial w_{jk}} = (o_k - t_k)o_k(1-o_k)x_j MSE损失函数的偏导:∂wjk∂L=(ok−tk)ok(1−ok)xj
我们用 δ k = ( o k − t k ) o k ( 1 − o k ) \delta_k = (o_k - t_k)o_k(1-o_k) δk=(ok−tk)ok(1−ok) ,则能再次简化:
M S E 损失函数的偏导: d L d w j k = δ k x j MSE损失函数的偏导:\frac{dL}{dw_{jk}} = \delta_kx_j MSE损失函数的偏导:dwjkdL=δkxj
最后,我们看看那PB算法中每一层的偏导数:

输出层:
∂ L ∂ w j k = δ k K o j \frac{\partial L}{\partial w_{jk}} = \delta_k^K o_j ∂wjk∂L=δkKoj
δ k K = ( o k − t k ) o k ( 1 − o k ) \delta_k^K = (o_k - t_k)o_k(1-o_k) δkK=(ok−tk)ok(1−ok)
倒数第二层:
∂ L ∂ w i j = δ j J o i \frac{\partial L}{\partial w_{ij}} = \delta_j^J o_i ∂wij∂L=δjJoi
δ j J = o j ( 1 − o j ) ∑ k δ k K w j k \delta_j^J = o_j(1 - o_j) \sum_{k}\delta_k^Kw_{jk} δjJ=oj(1−oj)k∑δkKwjk
倒数第三层:
∂ L ∂ w n i = δ i I o n \frac{\partial L}{\partial w_{ni}} = \delta_i^I o_n ∂wni∂L=δiIon
δ i I = o i ( 1 − o i ) ∑ j δ j J w i j \delta_i^I = o_i(1 - o_i) \sum_{j}\delta_j^Jw_{ij} δiI=oi(1−oi)j∑δjJwij
像这样依次往回推导,再通过梯度下降算法迭代优化网络参数,即可走完PB算法逻辑。
2.滑动平均的相关概念
滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving avergae),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
变量 v v v 在 t t t 时刻记为 v t v_{t} vt , θ t \theta_{t} θt 为变量 v v v 在 t t t 时刻训练后的取值,当不使用滑动平均模型时 v t = θ t v_{t} = \theta_{t} vt=θt ,在使用滑动平均模型后, v t v_{t} vt 的更新公式如下:

上式中, β ϵ [ 0 , 1 ) \beta\epsilon[0,1) βϵ[0,1) 。 β = 0 \beta = 0 β=0 相当于没有使用滑动平均。
t t t 时刻变量 v v v 的滑动平均值大致等于过去 1 / ( 1 − β ) 1/(1-\beta) 1/(1−β) 个时刻 θ \theta θ 值的平均。并使用bias correction将 v t v_{t} vt 除以 ( 1 − β t ) (1 - \beta^{t}) (1−βt) 修正对均值的估计。
加入Bias correction后, v t v_{t} vt 和 v b i a s e d t v_{biased_{t}} vbiasedt 的更新公式如下:

当 t t t 越大, 1 − β t 1 - \beta^{t} 1−βt 越接近1,则公式(1)和(2)得到的结果( v t v_{t} vt 和 v b i a s e d 1 v_{biased_{1}} vbiased1 )将越来越接近。
当 β \beta β 越大时,滑动平均得到的值越和 θ \theta θ 的历史值相关。如果 β = 0.9 \beta = 0.9 β=0.9 ,则大致等于过去10个 θ \theta θ 值的平均;如果 β = 0.99 \beta = 0.99 β=0.99 ,则大致等于过去100个 θ \theta θ 值的平均。
下图代表不同方式计算权重的结果:
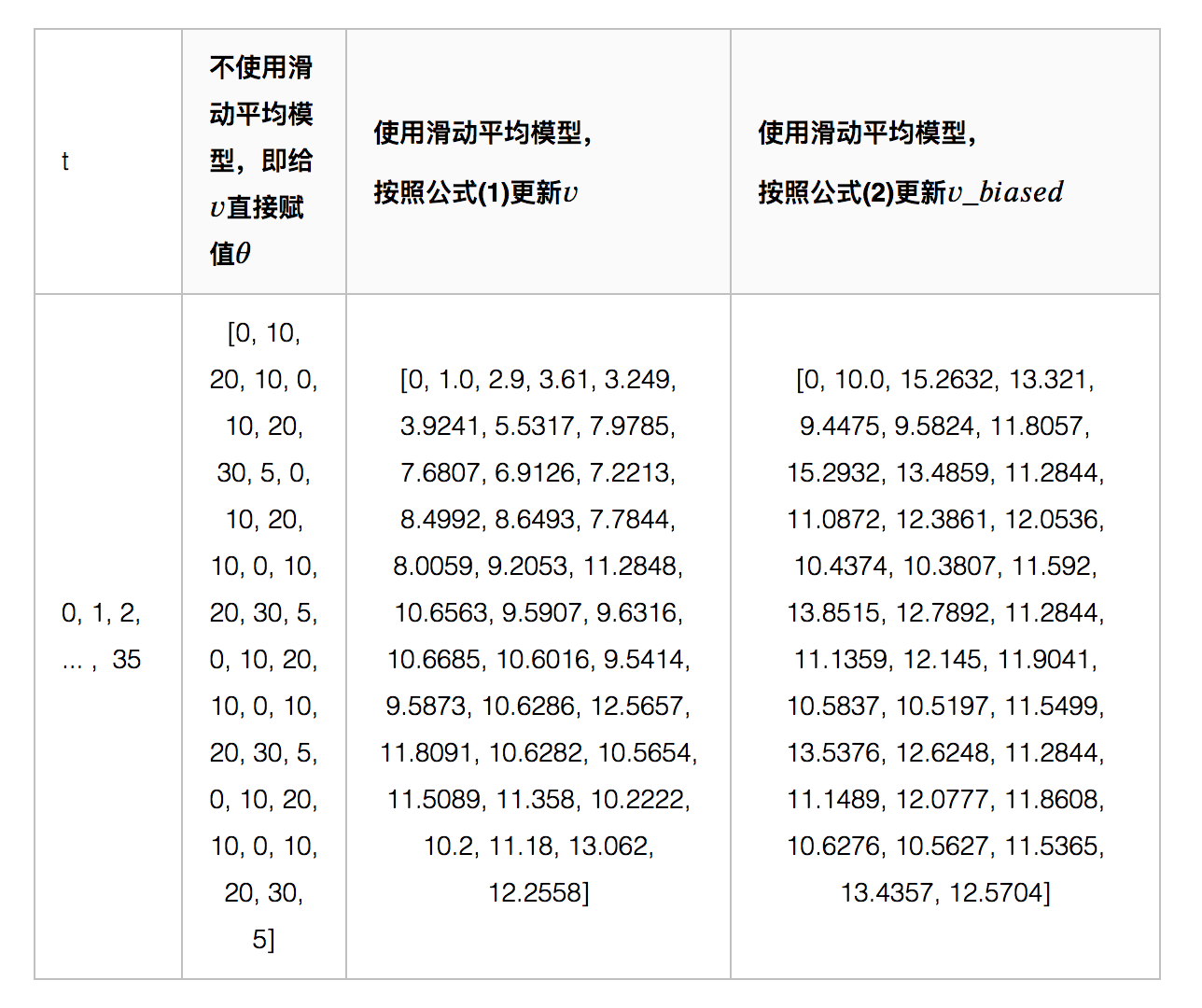
如上图所示,滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某种次的异常取值而使得滑动平均值波动很大。
滑动平均的优势: 占用内存少,不需要保存过去10个或者100个历史 θ \theta θ 值,就能够估计其均值。滑动平均虽然不如将历史值全保存下来计算均值准确,但后者占用更多内存,并且计算成本更高。
为什么滑动平均在测试过程中被使用?
滑动平均可以使模型在测试数据上更鲁棒(robust)。
采用随机梯度下降算法训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。
训练中对神经网络的权重 w e i g h t s weights weights 使用滑动平均,之后在测试过程中使用滑动平均后的 w e i g h t s weights weights 作为测试时的权重,这样在测试数据上效果更好。因为滑动平均后的 w e i g h t s weights weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远。比如假设decay=0.999,一个更直观的理解,在最后的1000次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的1000次抖动进行了平均,这样得到的权重会更加鲁棒。
相关文章:
神经网络:深度学习基础
1.反向传播算法(BP)的概念及简单推导 反向传播(Backpropagation,BP)算法是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见算法。BP算法对网络中所有权重计算…...
如何在Windows上搭建WebDAV服务并通过内网穿透实现公网访问
文章目录 前言1. 安装IIS必要WebDav组件2. 客户端测试3. 使用cpolar内网穿透,将WebDav服务暴露在公网3.1 安装cpolar内网穿透3.2 配置WebDav公网访问地址 4. 映射本地盘符访问 前言 在Windows上如何搭建WebDav,并且结合cpolar的内网穿透工具实现在公网访…...
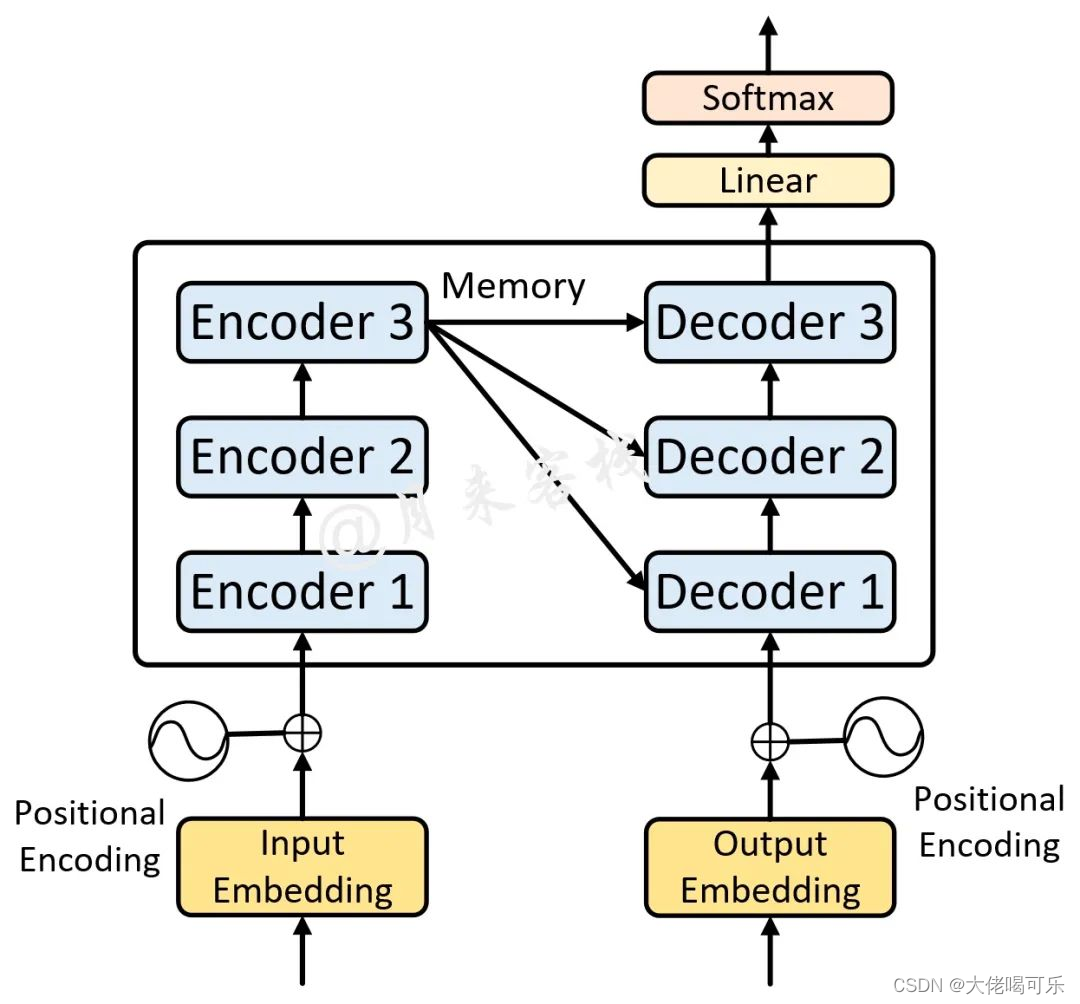
【Transformer框架代码实现】
Transformer Transformer框架注意力机制框架导入必要的库Input Embedding / Out EmbeddingPositional EmbeddingTransformer EmbeddingScaleDotProductAttention(self-attention)MultiHeadAttention 多头注意力机制EncoderLayer 编码层Encoder多层编码块/前馈网络层…...
Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580
Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580 已亲自复现 漏洞名称漏洞描述影响版本 漏洞复现环境搭建漏洞利用 修复建议总结 Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580 已亲自复现) 漏洞名称 漏洞描述 Apache ShenYu是一个异步的,高性能的&#x…...

锐捷配置重发布RIP进OSPF中
一、实验拓扑 二、实验目的 使用两种动态路由协议,并使两种协议间的路由可以传递 三、实验配置 第一步:配置全网基本IP R1 Ruijie>enable Ruijie#configure terminal Ruijie(config)#interface gigabitEthernet 0/0 Ruijie(config-if-GigabitEthe…...

Android R修改wifi热点默认为隐藏热点以及禁止自动关闭热点
前言 Android R系统中WLAN 热点设置里面默认是没有wifi热点的隐藏设置选项的,如果默认wifi热点为隐藏热点可以修改代码实现。另外wifi热点设置选项里面有个自动关闭热点,这个选项默认是打开的,有些机器里面配置wifi热点后默认是需要关闭掉的,以免自动关闭后要手动打开。 …...

智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.人工大猩猩部队算法4.实验参…...

[JS设计模式]Flyweight Pattern
Flyweight pattern 享元模式是一种结构化的设计模式,主要用于产生大量类似对象而内存又有限的场景。享元模式能节省内存。 假设一个国际化特大城市SZ;它有5个区,分别为nanshan、futian、luohu、baoan、longgang;每个区都有多个图…...
读取配置文件全面总结)
【.Net8教程】(一)读取配置文件全面总结
环境:.net8.0 1. 准备条件 先在appsettings.Development.json或appsettings.json添加配置 添加一个DbOption {"DbOption": {"Conn": "foolishsundaycsdn"} }2.直接读取json配置节点的几种写法 在Main函数中读取json配置 方式一 …...
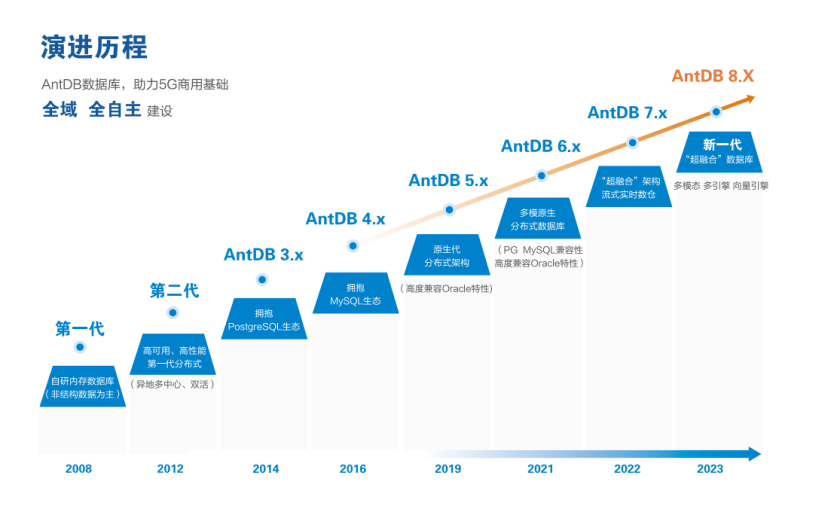
亚信安慧AntDB:支撑中国广电5G业务的数据库之力
自2019年6月获得5G牌照以来,中国广电积极利用700MHz频谱资源,迅速崛起为第四大运营商,标志着其在数字通信领域取得的巨大成就。通过与中国移动紧密合作,共建共享基站已超过400万座,为实现自主运营和差异化竞争提供了坚…...

C++哈希表的实现
C哈希表的实现 一.unordered系列容器的介绍二.哈希介绍1.哈希概念2.哈希函数的常见设计3.哈希冲突4.哈希函数的设计原则 三.解决哈希冲突1.闭散列(开放定址法)1.线性探测1.动图演示2.注意事项3.代码的注意事项4.代码实现 2.开散列(哈希桶,拉链法)1.概念2.动图演示3.增容问题1.拉…...
[Angular] 笔记 6:ngStyle
ngStyle 指令: 用于更新 HTML 元素的样式。设置一个或多个样式属性,用以冒号分隔的键值对指定。键是样式名称,带有可选的 .<unit> 后缀(如 ‘top.px’、‘font-style.em’),值为待求值的表达式,得到…...

Linux环境下使用logrotate工具实现nginx日志切割
本文已同步到专业技术网站 www.sufaith.com, 该网站专注于前后端开发技术与经验分享, 包含Web开发、Nodejs、Python、Linux、IT资讯等板块. 一. 前提背景及需求 nginx运行日志默认保存在nginx安装目录下的 /usr/local/nginx/logs 文件夹, 包含access.log和error.log两个文件.…...
数字信号的理解
1 数字信号处理简介 数字信号处理 digital signal processing(DSP)经常与实际的数字系统相混淆。这两个术语都暗示了不同的概念。数字信号处理在本质上比实际的数字系统稍微抽象一些。数字系统是涉及的硬件、二进制代码或数字域。这两个术语之间的普遍混…...

【计算机网络】TCP心跳机制、TCP粘包问题
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 更多计算机网络知识专栏:计算机网络🔥 给大家跳段…...
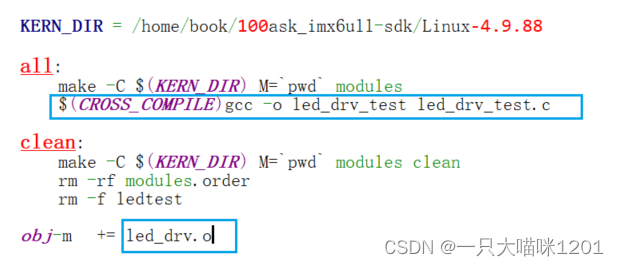
【Linux驱动】字符设备驱动程序框架 | LED驱动
🐱作者:一只大喵咪1201 🐱专栏:《RTOS学习》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀Hello驱动程序⚽驱动程序框架⚽编程 🏀LED驱动⚽配置GPIO⚽编程驱动…...
关于编程网站变成了地方这件事
洛谷: 首页 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) csdn CSDN - 专业开发者社区 力扣 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 常州市力扣紧固件有限公司 常州市 力扣 紧固件 有限公司 博客园 博客园 - 开发…...

stable diffusion工作原理
目录 序言stable diffusion能做什么扩散模型正向扩散逆向扩散 如何训练逆向扩散 Stable Diffusion模型潜在扩散模型变分自动编码器图像分辨率图像放大为什么潜在空间可能存在?在潜在空间中的逆向扩散什么是 VAE 文件? 条件化(conditioning)文本条件化&am…...

华清远见嵌入式学习——ARM——作业2
目录 作业要求: 现象: 代码: 思维导图: 模拟面试题: 作业要求: GPIO实验——3颗LED灯的流水灯实现 现象: 代码: .text .global _start _start: 设置GPIOEF时钟使能 0X50000…...
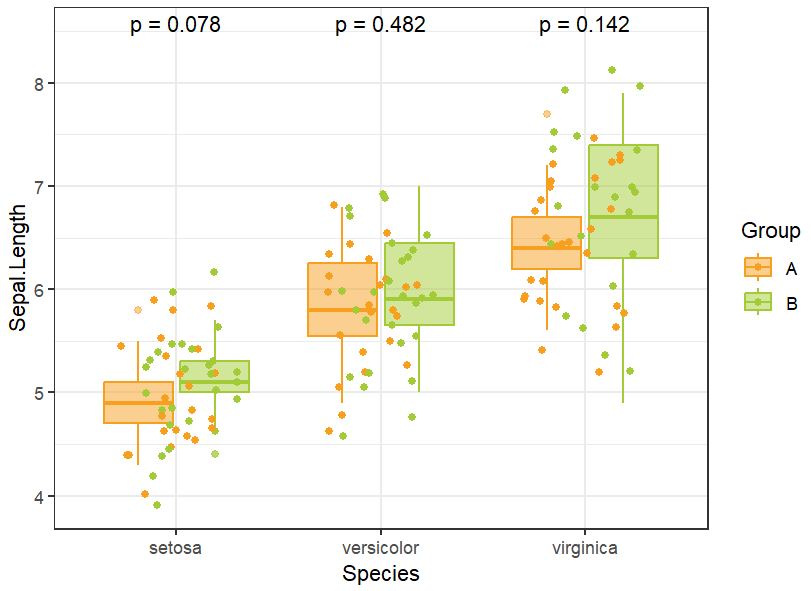
R语言中使用ggplot2绘制散点图箱线图,附加显著性检验
散点图可以直观反映数据的分布,箱线图可以展示均值等关键统计量,二者结合能够清晰呈现数据蕴含的信息。 本篇笔记主要内容:介绍R语言中绘制箱线图和散点图的方法,以及二者结合展示教程,添加差异比较显著性分析…...

RTX 5090功耗600W:高功耗显卡的系统级挑战与实战装机指南
1. 项目概述:从一则功耗新闻到显卡生态的深度解构最近,一则关于英伟达下一代旗舰显卡RTX 5090功耗可能高达600W的消息,在硬件圈和AI计算领域激起了不小的波澜。对于普通玩家而言,这或许只是一个“电老虎”又升级了的谈资ÿ…...

dotAI:将AI能力环境化,打造可配置的智能开发工作流
1. 项目概述:当AI成为你的“数字管家”最近在GitHub上看到一个挺有意思的项目,叫udecode/dotai。乍一看这个标题,你可能和我最初的反应一样,有点摸不着头脑。dotai?是“点AI”的意思吗?它和.env文件那种“点…...

长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助 对于一个持续数月、深度依赖大模型能力的项目组而言&#…...

零代码构建HomeKit运动检测系统:Adafruit IO与itsaSNAP实战指南
1. 项目概述:零代码构建HomeKit运动检测系统想给家里的走廊、储物间或者车库入口加个自动感应灯,但又不想折腾复杂的编程和服务器搭建?或者,你手头有一些非HomeKit原生设备,希望通过苹果的“家庭”App进行统一管理&…...

正规全能艺术台制造厂:可靠厂商选择要点解析
正规全能艺术台制造厂选择指南:5大可靠厂商评估要点FAQ“选对全能艺术台制造厂,不是看广告多响,而是看这5个‘隐性指标’——合规资质、自研技术、服务体系、数据安全、内容迭代能力!”很多公共文化场馆在采购全能艺术台时&#x…...

基于ESP32与WLED打造智能可编程灯饰:从硬件连接到软件配置全攻略
1. 项目概述:打造你的专属智能光影秀又到年底了,看着满大街千篇一律的彩灯装饰,是不是觉得有点审美疲劳?想不想自己动手,做一套独一无二、能通过手机随心控制颜色和动画的智能灯饰?今天分享的这个项目&…...
)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例) 当你第一次拿到一块Rockchip RK3566开发板时,最令人兴奋的莫过于让硬件真正"活"起来。而点亮一个LED,就像嵌入式世界的"Hello World&q…...

Divinity Mod Manager:如何用技术架构解决《神界:原罪2》模组管理的复杂性?
Divinity Mod Manager:如何用技术架构解决《神界:原罪2》模组管理的复杂性? 【免费下载链接】DivinityModManager A mod manager for Divinity: Original Sin - Definitive Edition. 项目地址: https://gitcode.com/gh_mirrors/di/Divinity…...

SmartNIC与DPU技术解析:计算卸载与性能优化实践
1. SmartNIC与DPU技术概述在数据中心和高性能计算领域,网络瓶颈一直是制约系统性能的关键因素。传统网卡仅负责简单的数据包收发,而现代计算密集型应用需要更智能的网络处理能力。这就是SmartNIC(智能网卡)和DPU(数据处…...

如何在Windows电脑上安装安卓应用:APK Installer完整使用指南
如何在Windows电脑上安装安卓应用:APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用吗&#x…...