C++哈希表的实现
C++哈希表的实现
- 一.unordered系列容器的介绍
- 二.哈希介绍
- 1.哈希概念
- 2.哈希函数的常见设计
- 3.哈希冲突
- 4.哈希函数的设计原则
- 三.解决哈希冲突
- 1.闭散列(开放定址法)
- 1.线性探测
- 1.动图演示
- 2.注意事项
- 3.代码的注意事项
- 4.代码实现
- 2.开散列(哈希桶,拉链法)
- 1.概念
- 2.动图演示
- 3.增容问题
- 1.拉链法的负载因子
- 2.说明
- 3.开散列和闭散列的比较
- 四.开散列哈希表的实现
- 1.跟闭散列哈希表相同的部分
- 2.析构,查找,删除
- 1.析构
- 2.查找
- 3.删除
- 3.插入
- 1.不扩容的代码
- 2.扩容代码
- 3.插入的完整代码
- 4.开散列哈希表的完整代码
一.unordered系列容器的介绍


二.哈希介绍
1.哈希概念

2.哈希函数的常见设计
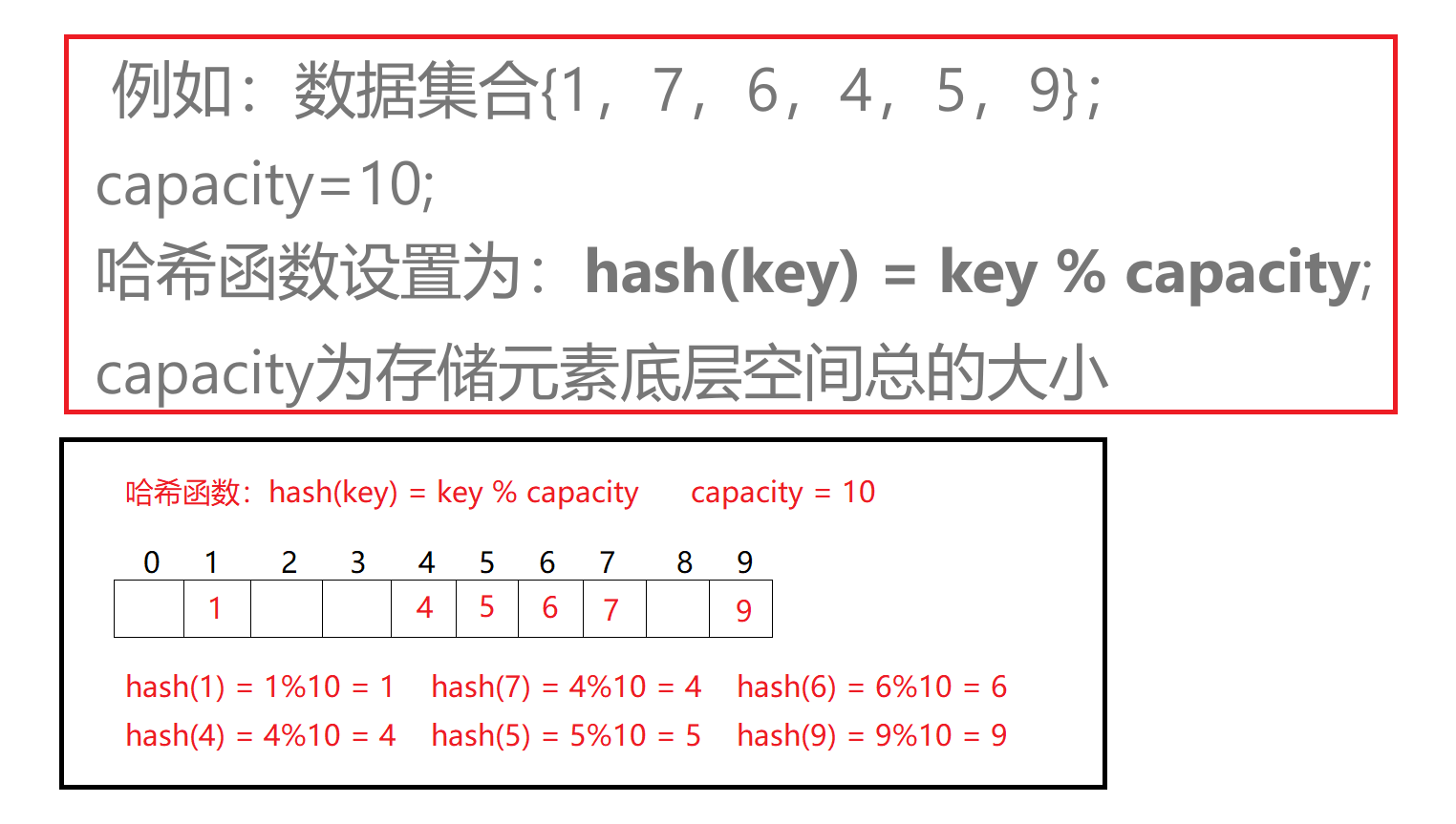
3.哈希冲突

4.哈希函数的设计原则

三.解决哈希冲突
解决哈希冲突两种常见的方法是:闭散列和开散列
1.闭散列(开放定址法)

因为线性探测跟二次探测很像,所以这里就只实现线性探测了
1.线性探测
1.动图演示


2.注意事项

3.代码的注意事项
1.仿函数的问题:
(1).因为string类型不能进行取模运算,因此给string类型增加一个仿函数
该仿函数可以将string转为整型,整型可以进行取模运算
因此这就相当于二层映射
string -> int -> 哈希表中的下标
(2)
因为这里要考虑到顺序问题,比如"abc",“acb”
或者ASCII码值相等的问题:“aad”,“abc”
所以很多大佬设计了很多字符串哈希算法
各种字符串Hash函数
大家感兴趣的话可以看这篇博客当中的介绍
(3)因为string类型的哈希映射太常用了,
所以这里使用了模板特化,以免每次要存放string时都要指名传入string的哈希函数
这里的哈希函数只返回了整形值,计算下标时一定不要忘了对哈希表大小取模
否则就会有vector的越界错误,直接assert断言暴力报错了
哈希表是Key-Value模型
哈希下标是按照Key来计算的
//仿函数
//整型的hash函数
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
//模板特化
//string的哈希函数
template<>
struct HashFunc<string>
{size_t operator()(const string& key){// BKDR字符串哈希函数size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
....
4.代码实现
namespace open_address
{enum Status{EMPTY,EXIST,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;Status _s; //状态};//仿函数//整型的hash函数template<class K>struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};//模板特化//string的哈希函数template<>struct HashFunc<string>{size_t operator()(const string& key){// BKDR字符串哈希函数size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable(){_tables.resize(10);}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因子0.7就扩容if (_n * 10 / _tables.size() == 7){size_t newSize = _tables.size() * 2;HashTable<K, V, Hash> newHT;newHT._tables.resize(newSize);// 遍历旧表for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);}Hash hf;// 线性探测size_t hashi = hf(kv.first) % _tables.size();while (_tables[hashi]._s == EXIST){hashi++;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._s = EXIST;++_n;return true;}HashData<K, V>* Find(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();while (_tables[hashi]._s != EMPTY){if (_tables[hashi]._s == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}hashi++;hashi %= _tables.size();}return NULL;}// 伪删除法bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_s = DELETE;--_n;return true;}else{return false;}}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 存储的关键字的个数};
}
2.开散列(哈希桶,拉链法)
上面的闭散列并不好用,因此我们重点介绍和实现开散列方法
1.概念

2.动图演示
插入之前:

插入过程:
插入之后:
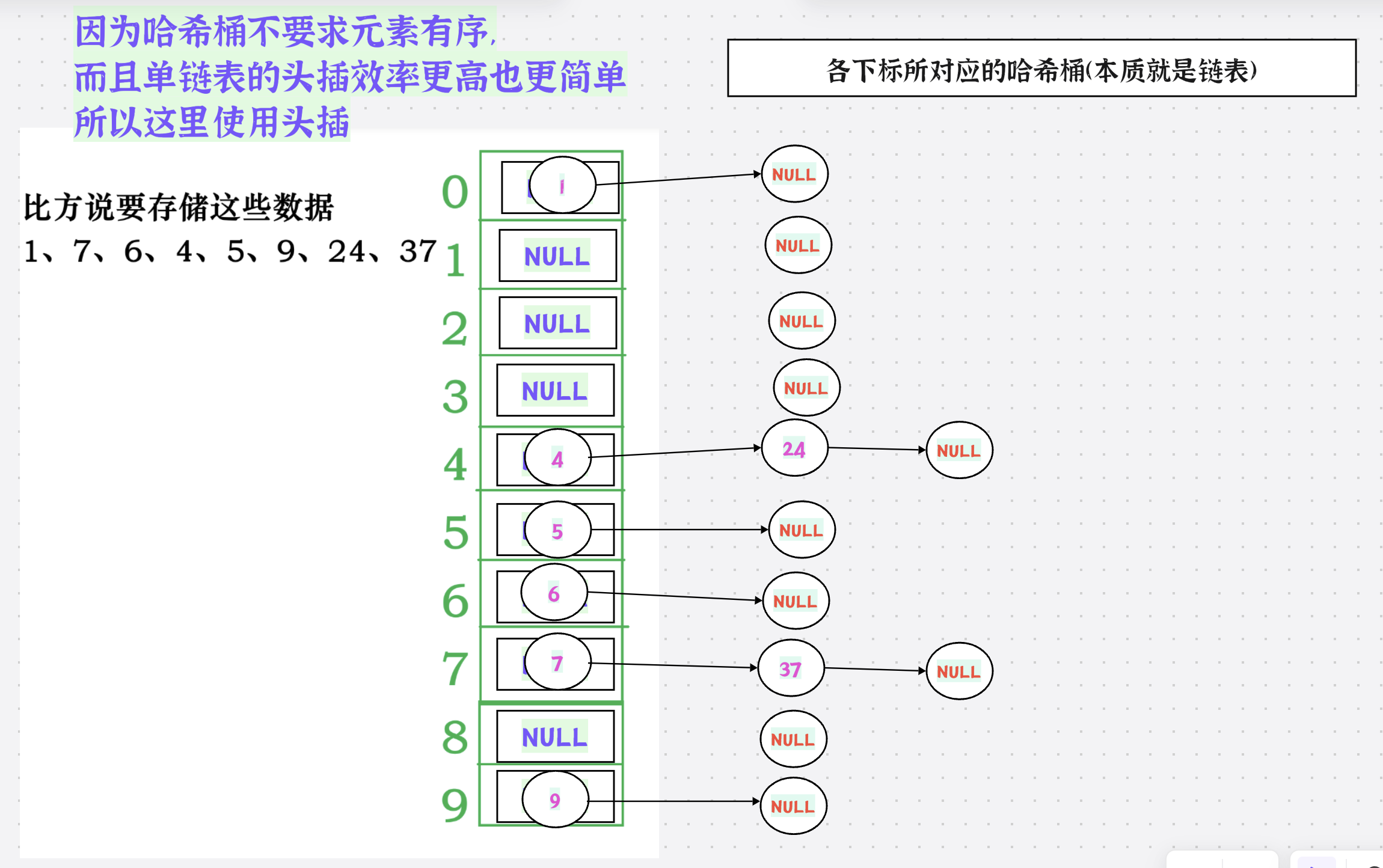
3.增容问题
1.拉链法的负载因子

注意:扩容时因为要将下标重新映射所以扩容会使一个桶当中的数据被打散到不同的桶当中,使得这种极端情况很难发生
2.说明
1.对于这里的哈希桶我们采用单链表
2.为了后续使用开散列的哈希桶封装unordered_set和unordered_map,我们不使用STL库中的forward_list(C++11新增容器:单链表),而是自己手撕单链表
3.因为这里的单链表是我们自己实现的,所以要写析构函数,不能使用编译器默认生成的析构函数
4.为了提高效率,哈希表增容时我们直接转移节点,并不会去进行节点的深拷贝,那样太浪费空间了
5.开散列的哈希表无非就是一个指针数组而已,所以大家不要有任何的害怕
AVL树和红黑树我们都能实现,哈希表怕什么…
3.开散列和闭散列的比较

四.开散列哈希表的实现
1.跟闭散列哈希表相同的部分
namespace wzs
{//HashFunc<int>template<class K>//整型的哈希函数struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};//HashFunc<string>//string的哈希函数template<>struct HashFunc<string>{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}};template<class K, class V>struct HashNode{HashNode* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:HashTable(){_tables.resize(10);}~HashTable();bool Insert(const pair<K, V>& kv);Node* Find(const K& key);bool Erase(const K& key);private://哈希表是一个指针数组vector<Node*> _tables;size_t _n = 0;Hash hash;};
}
2.析构,查找,删除
1.析构
析构就是遍历哈希表,把每个单链表都销毁即可
~HashTable()
{for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}
}
2.查找
1.根据哈希函数计算出下标,找到对应的哈希桶
2.遍历哈希桶,找数据即可
3.找到则返回该节点,找不到返回空指针
Node* Find(const K& key)
{int hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;
}
3.删除
删除就是找到该节点,让该节点的前驱指向该节点的后继,然后delete该节点
注意:
如果该节点是该哈希桶的头节点,直接让该哈希桶的头节点成为该节点的后继,然后delete该节点即可
bool Erase(const K& key)
{int hashi = hash(key) % _tables.size();Node* cur = _tables[hashi], * prev = nullptr;while (cur){if (cur->_kv.first == key){if (cur == _tables[hashi]){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}return true;}prev = cur;cur = cur->_next;}return false;
}
3.插入
因为我们的哈希表不支持存放重复值,所以插入时
1.先查找在不在,如果在,返回false表示插入失败
2.不在,判断是否需要扩容,如果需要,则进行扩容
3.插入时,先根据哈希函数计算出对应的下标,然后找到该哈希桶头插即可
1.不扩容的代码
bool Insert(const pair<K, V>& kv)
{//先查找在不在//如果在,返回false,插入失败if (Find(kv.first)){return false;}//扩容....//1.利用哈希函数计算需要插入到那个桶里面int hashi = hash(kv.first) % _tables.size();//头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;
}
2.扩容代码
1.开辟新的哈希表
2.将新哈希表的容量扩为2倍(一定要做,因为转移数据时需要根据新表的大小映射下标)
3.转移数据时
(1).遍历旧表取节点
(2).利用哈希函数计算该节点在新表中的下标
(3).头插该节点
4.转移完数据后不要忘记把旧表中的哈希桶的节点置空,否则会出现野指针问题
bool Insert(const pair<K, V>& kv)
{//扩容if (_n == _tables.size()){//开辟新的哈希表HashTable newtable;int newcapacity = _tables.size() * 2;//扩2倍newtable._tables.resize(newcapacity);//转移数据for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;int hashi = hash(cur->_kv.first) % newtable._tables.size();cur->_next = newtable._tables[hashi];newtable._tables[hashi] = cur;cur = next;}//防止出现野指针导致重复析构..._tables[i] = nullptr;}}
}
3.插入的完整代码
bool Insert(const pair<K, V>& kv)
{//先查找在不在//如果在,返回false,插入失败if (Find(kv.first)){return false;}//扩容if (_n == _tables.size()){//开辟新的哈希表HashTable newtable;int newcapacity = _tables.size() * 2;//扩2倍newtable._tables.resize(newcapacity);//转移数据for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;int hashi = hash(cur->_kv.first) % newtable._tables.size();cur->_next = newtable._tables[hashi];newtable._tables[hashi] = cur;cur = next;}//防止出现野指针导致重复析构..._tables[i] = nullptr;}//交换两个vector,从而做到交换两个哈希表//通过学习vector的模拟实现,我们知道vector进行交换时只交换first,finish,end_of_storage_tables.swap(newtable._tables);}//1.利用哈希函数计算需要插入到那个桶里面int hashi = hash(kv.first) % _tables.size();//头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;
}
4.开散列哈希表的完整代码
namespace wzs
{//HashFunc<int>template<class K>//整型的哈希函数struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};//HashFunc<string>//string的哈希函数template<>struct HashFunc<string>{size_t operator()(const string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}};template<class K, class V>struct HashNode{HashNode* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:HashTable(){_tables.resize(10);}~HashTable(){for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){//先查找在不在//如果在,返回false,插入失败if (Find(kv.first)){return false;}//扩容if (_n == _tables.size()){//开辟新的哈希表HashTable newtable;int newcapacity = _tables.size() * 2;//扩2倍newtable._tables.resize(newcapacity);//转移数据for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;int hashi = hash(cur->_kv.first) % newtable._tables.size();cur->_next = newtable._tables[hashi];newtable._tables[hashi] = cur;cur = next;}//防止出现野指针导致重复析构..._tables[i] = nullptr;}//交换两个vector,从而做到交换两个哈希表//通过学习vector的模拟实现,我们知道vector进行交换时只交换first,finish,end_of_storage_tables.swap(newtable._tables);}//1.利用哈希函数计算需要插入到那个桶里面int hashi = hash(kv.first) % _tables.size();//头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){int hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){int hashi = hash(key) % _tables.size();Node* cur = _tables[hashi], * prev = nullptr;while (cur){if (cur->_kv.first == key){if (cur == _tables[hashi]){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}return true;}prev = cur;cur = cur->_next;}return false;}private://哈希表是一个指针数组vector<Node*> _tables;size_t _n = 0;Hash hash;};
}
以上就是C++哈希表的实现的全部内容,希望能对大家有所帮助!
相关文章:
C++哈希表的实现
C哈希表的实现 一.unordered系列容器的介绍二.哈希介绍1.哈希概念2.哈希函数的常见设计3.哈希冲突4.哈希函数的设计原则 三.解决哈希冲突1.闭散列(开放定址法)1.线性探测1.动图演示2.注意事项3.代码的注意事项4.代码实现 2.开散列(哈希桶,拉链法)1.概念2.动图演示3.增容问题1.拉…...
[Angular] 笔记 6:ngStyle
ngStyle 指令: 用于更新 HTML 元素的样式。设置一个或多个样式属性,用以冒号分隔的键值对指定。键是样式名称,带有可选的 .<unit> 后缀(如 ‘top.px’、‘font-style.em’),值为待求值的表达式,得到…...

Linux环境下使用logrotate工具实现nginx日志切割
本文已同步到专业技术网站 www.sufaith.com, 该网站专注于前后端开发技术与经验分享, 包含Web开发、Nodejs、Python、Linux、IT资讯等板块. 一. 前提背景及需求 nginx运行日志默认保存在nginx安装目录下的 /usr/local/nginx/logs 文件夹, 包含access.log和error.log两个文件.…...
数字信号的理解
1 数字信号处理简介 数字信号处理 digital signal processing(DSP)经常与实际的数字系统相混淆。这两个术语都暗示了不同的概念。数字信号处理在本质上比实际的数字系统稍微抽象一些。数字系统是涉及的硬件、二进制代码或数字域。这两个术语之间的普遍混…...

【计算机网络】TCP心跳机制、TCP粘包问题
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 更多计算机网络知识专栏:计算机网络🔥 给大家跳段…...
【Linux驱动】字符设备驱动程序框架 | LED驱动
🐱作者:一只大喵咪1201 🐱专栏:《RTOS学习》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀Hello驱动程序⚽驱动程序框架⚽编程 🏀LED驱动⚽配置GPIO⚽编程驱动…...
关于编程网站变成了地方这件事
洛谷: 首页 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) csdn CSDN - 专业开发者社区 力扣 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 常州市力扣紧固件有限公司 常州市 力扣 紧固件 有限公司 博客园 博客园 - 开发…...

stable diffusion工作原理
目录 序言stable diffusion能做什么扩散模型正向扩散逆向扩散 如何训练逆向扩散 Stable Diffusion模型潜在扩散模型变分自动编码器图像分辨率图像放大为什么潜在空间可能存在?在潜在空间中的逆向扩散什么是 VAE 文件? 条件化(conditioning)文本条件化&am…...

华清远见嵌入式学习——ARM——作业2
目录 作业要求: 现象: 代码: 思维导图: 模拟面试题: 作业要求: GPIO实验——3颗LED灯的流水灯实现 现象: 代码: .text .global _start _start: 设置GPIOEF时钟使能 0X50000…...
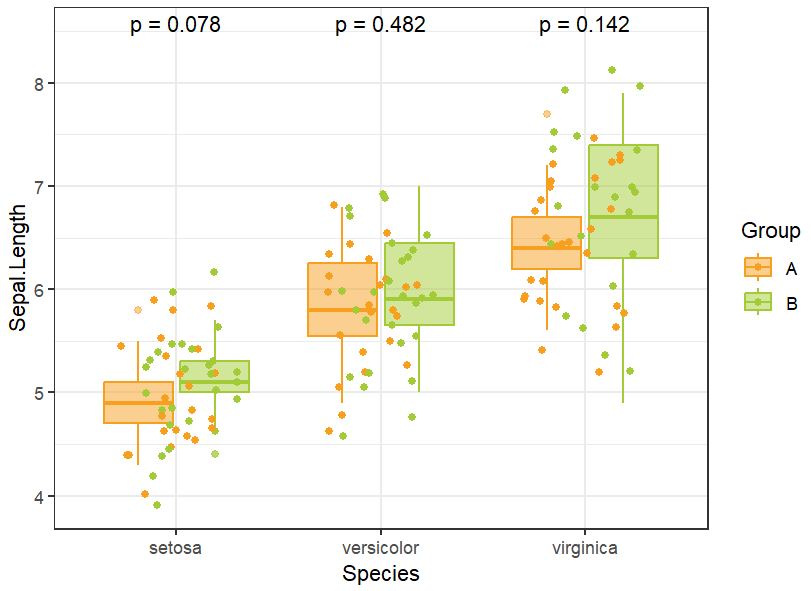
R语言中使用ggplot2绘制散点图箱线图,附加显著性检验
散点图可以直观反映数据的分布,箱线图可以展示均值等关键统计量,二者结合能够清晰呈现数据蕴含的信息。 本篇笔记主要内容:介绍R语言中绘制箱线图和散点图的方法,以及二者结合展示教程,添加差异比较显著性分析…...

51单片机的羽毛球计分器系统【含proteus仿真+程序+报告+原理图】
1、主要功能 该系统由AT89C51单片机LCD1602显示模块按键等模块构成。适用于羽毛球计分、乒乓球计分、篮球计分等相似项目。 可实现基本功能: 1、LCD1602液晶屏实时显示比赛信息 2、按键控制比赛的开始、暂停和结束,以及两位选手分数的加减。 本项目同时包含器件清…...

设计模式之-责任链模式,快速掌握责任链模式,通俗易懂的讲解责任链模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

Qt通用属性工具:随心定义,随时可见(一)
一、开胃菜,没图我说个DIAO 先不BB,给大家上个效果图展示下: 上图我们也没干啥,几行代码: #include "widget.h" #include <QApplication> #include <QObject> #include "QtPropertyEdit…...

Python中json模块的使用与pyecharts绘图的基本介绍
文章目录 json模块json与Python数据的相互转化 pyecharts模块pyecharts基本操作基础折线图配置选项全局配置选项 json模块的数据处理折线图示例示例代码 json模块 json实际上是一种数据存储格式,是一种轻量级的数据交互格式,可以把他理解成一个特定格式…...
nodejs+vue+微信小程序+python+PHP医院挂号系统-计算机毕业设计推荐
当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术, 本医院挂号系统也是紧跟科学技术的发展,运用当今一流的软件技术实现软件系统的开发,让家具销…...

数据大模型与低代码开发:赋能技术创新的黄金组合
在当今技术领域,数据大模型和低代码开发已经成为两个重要的趋势。数据大模型借助庞大的数据集和强大的计算能力,助力我们从海量数据中挖掘出有价值的洞见和预测能力。与此同时,低代码开发通过简化开发流程和降低编码需求,使得更多…...

Redis BitMap(位图)
这里是小咸鱼的技术窝(CSDN板块),我又开卷了 之前经手的项目运行了10多年,基于重构,里面有要实现一些诸如签到的需求,以及日历图的展示,可以用将签到信息存到传统的关系型数据库(MyS…...

使用eclipse创建一个java文件并运行
启动 Eclipse 并创建一个新的 Java 项目: 打开 Eclipse。 选择 “File” > “New” > “Java Project”(文件 > 新建 > Java 项目)。 在弹出的窗口中,为你的项目命名,比如 MyJavaProject。 点击 “Finish”ÿ…...

C#上位机与欧姆龙PLC的通信05---- HostLink协议
1、介绍 Hostlink协议是欧姆龙PLC与上位机链接的公开协议。上位机通过发送Hostlink命令,可以对PLC进行I/O读写、可以对PLC进行I/O读写、改变操作模式、强制置位/复位等操作。由于是公开协议,即便是非欧姆龙的上位设备(软件)&…...
Uniapp 开发 BLE
BLE 低功耗蓝牙(Bluetooth Low Energy,或称Bluetooth LE、BLE,旧商标Bluetooth Smart),用于医疗保健、运动健身、安防、工业控制、家庭娱乐等领域。在如今的物联网时代下大放异彩,扮演者重要一环ÿ…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...

Arm Neoverse CMN-700性能监控与优化实践
1. Arm Neoverse CMN-700性能监控体系解析在现代多核处理器架构中,性能监控单元(PMU)如同系统的"听诊器",能够实时捕捉微架构层面的各种行为指标。Arm Neoverse CMN-700作为面向基础设施级应用的互联架构,其PMU设计尤其强调对Mesh网…...

AI智能体开发实战:从Devin现象到代码辅助智能体构建
1. 项目概述:当开发者遇上AI智能体最近在GitHub上闲逛,发现一个叫“awesome-devins”的仓库热度飙升。点进去一看,好家伙,这简直是一个关于“AI智能体”的宝藏目录。这个由e2b-dev团队维护的项目,本质上是一个精心整理…...

告别命令行启动!在Ubuntu 20.04上为Clion创建桌面快捷方式的保姆级教程
告别命令行启动!在Ubuntu 20.04上为Clion创建桌面快捷方式的保姆级教程 每次打开Clion都要在终端输入./clion.sh?作为从Windows转战Linux的开发者,这种操作简直让人抓狂。本文将彻底解决这个痛点,手把手教你用.desktop文件创建专业…...

ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南
ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一个基于Web的开源工具,专门用于解析城通网盘分享链接并获…...

扩展卡尔曼滤波锂电池SOC估算【附代码】
✨ 长期致力于锂离子电池、SOC估算、锂离子电池建模、EKF算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二阶RC等效电路建模与温度自适应参数修正…...

UPS Ground运输时间估算:从纽约10013到全美各区域的实操指南
1. 物流时间估算的核心价值与挑战在电商和供应链的世界里,时间就是金钱,而运输时间则是连接承诺与现实的桥梁。无论是作为卖家管理客户预期,还是作为买家规划项目进度,一个相对准确的运输时间预估都至关重要。UPS Ground作为美国境…...
)
Word分栏排版进阶:如何实现左右栏独立编辑与中英文对照排版(解决内容错乱问题)
Word分栏排版进阶:左右栏独立编辑与中英文对照排版实战指南 在专业文档制作中,双语对照排版是教师、翻译人员和外语学习者经常遇到的挑战。传统分栏功能虽然简单易用,但当我们需要左边显示英文原文、右边显示对应中文翻译时,直接分…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...

基于ADT7410与ESP8266的物联网温度监测系统实战指南
1. 项目概述:从传感器到云端的温度监测闭环在嵌入式开发和物联网项目中,温度监测是一个经典且高频的需求场景。无论是实验室环境监控、智能家居的恒温控制,还是工业设备的状态感知,一个稳定、精确且能远程访问的温度数据流都是基础…...