【大数据】NiFi 的基本使用
NiFi 的基本使用
- 1.NiFi 的安装与使用
- 1.1 NiFi 的安装
- 1.2 各目录及主要文件
- 2.NiFi 的页面使用
- 2.1 主页面介绍
- 2.2 面板介绍
- 3.NiFi 的工作方式
- 3.1 基本方式
- 3.2 选择处理器
- 3.3 组件状态
- 3.4 组件的配置
- 3.4.1 SETTINGS(通用配置)
- 3.4.2 SCHEDULING(处理器调度)
- 3.4.3 COMMENTS(备注区)
- 3.4.4 PROPERITIES(属性区)
- 3.5 队列管道操作
- 3.5.1 管道的来源
- 3.5.2 手动清空管道
- 3.5.3 查看数据
- 3.5.4 设置超时清空
- 3.5.5 删除
- 3.6 NiFi 的迁移
- 3.6.1 局部备份迁移
- 3.6.2 整体备份迁移
1.NiFi 的安装与使用
1.1 NiFi 的安装
首先说一下 NiFi 的安装,这里 NiFi 可以支持 Windows 版和 Linux,只需要去官网 http://nifi.apache.org/,根据自己需要的版本,选择下载,然后安装解压就行。


1.2 各目录及主要文件
解压安装以后的 NiFi 目录如下:

基本的,bin 目录下放置了整个系统的控制脚本,lib 目录下放置的 NiFi 自带的一个个 nar 程序包(其实就是 NiFi 内置的一个个组件)和它本身的程序所需要的加载编译等等的底层包,state 是运行期间的一些数据,docs 和 work 是 NiFi 的一些官方文档和学习样例。
conf 目录下放置的是 NiFi 的配置文件,这里详细说一下:

作为我们基本的使用,这里只需要注意两个文件就好,关于其他的配置,有兴趣的可以去 NiFi 官网查看,首先是 nifi-properties 文件,这个文件基本就是整个 NiFi 的配置中心,里面包含很多的基本配置,例如 启动端口、内存分配 等等,第二个就是 flow.xml.gz,这个文件主要是你整个 NiFi 使用的全记录,解释的通俗点,如果你遇到了这么一个问题 “我在一台机器上部署了一个 NiFi,并且进行了一段时间的使用,建立了很多流程和功能,这时候,需要换到别的机器的 NiFi 上进行开发”,你建立那些肯定不能挨个再在新环境上来一遍啊,这时候只需要把这个 flow.xml.gz 替换到新机器的 NiFi 环境里,重启新环境的 NiFi 就可以了。
logs 目录里放的是 NiFi 运行后的主要的日志。这里运行后会有三个日志, 分别是:
- ✅
nifi-app.log:整个应用的运行日志。 - ✅
nifi-bootstrap.log:底层类加载一系列的日志。 - ✅
nifi-user.log:就简单理解为用户的访问操作日志吧。
2.NiFi 的页面使用
NiFi 默认启动端口是 8080 8080 8080,使用 Windows 下就 bin 目录下双击 run-nifi.bat,Linux 下就在 bin 目录下,执行 ./nifi.sh start。
2.1 主页面介绍

进入主页面以后,它整体就是一个画布的形式,最上方是个公共导航栏,左侧那个 Navigate 没啥用,不用在意,就是一个全局视角,下面的 Operate 是组件控制面板,可以进行单个组件的控制,也可以选中一片组件进行统一的启动,停止等等。
2.2 面板介绍
首先:

刚刚已经把 NiFi 的整个页面理解为一个工作台,最上方就是个导航栏了,从最上面开始,这里的导航栏分为两部分,上半部分是提供给我们工作的,下半部分是对整个 NiFi 环境下的一个监控信息。这里简单介绍一下:
| 图标 | |
|---|---|
 | 导航栏中的这个菜单,我们可以理解为处理器(Processor)商城,用鼠标单击拖出到画布上,便会出现处理器(Processor)菜单。 |
 | 导航栏中这个菜单,我叫它为组,什么叫组呢,当你拉了很多处理器(Processor),形成了一个完整的流程的时候,我们可以单独把这块划分成一个整体了,这时候就要用组把它包裹起来。 |
 | 有了组以后,组和组之间可能也需要联通、通信,这时候就可以用入口和出口,把它们放在组内。 |
 | 这个组件需要配合 Operate 中的上传使用,主要是用来迁移模板的,这块后续会专门抽章节讲一下。 |
 | 这一组件,是集群 NiFi 进行数据通信的时候用的。 |
 | 这一组件,就是个便签,用来写个备注呀啥的。 |
 | 这一组件就是个漏斗,主要作用就是把四散的数据可以汇集在一起。 |
3.NiFi 的工作方式
3.1 基本方式
NiFi 其实就是一个 数据接入、处理、清洗、分发的系统,它的工作方式就是将数据看作水管中的水,它是顺着某个流程管道流动,在这中间,可以在任意节点处堵截这个“水流”,并对它进行改造,然后放回管道继续向下流去。
这里的节点,其实就是 NiFi 的 Processor,你叫它处理器也可以,叫他组件也好,它就是一个黑盒小模块,不同的模块有不同的功能。
然后,节点和节点直接的通道,在 NiFi 里叫 Relationship,我把它称之为 管道,就像水管一样,它本身的意义就是充当水管,把上节点处理完的水传下去。
在 NiFi 中,都是一个个的流程(处理器 + 管道),形成一个数据的处理通路。

像这个例子,GetFile 组件负责从一个文件里读取数据,然后把读到的数据通过管道传到 ExecuteScript 组件(这个组件支持用脚本代码处理数据),经过 ExecuteScript 之后,流向 PutFile 组件(将数据写入到指定文件中)。
基本流程就是:选则一个处理器 ➡ 配置该组件至可运行状态 ➡ 关联下一组件建立管道。
3.2 选择处理器

通过 “组件商城” 图标进行处理器的选择,处理器是最常用的组件,因为它负责数据的流入、流出、路由和操作。有许多不同类型的处理器。实际上,这是 NiFi 中非常常见的扩展点,这意味着许多供应商可能会实现自己的处理器来执行其所需的任何功能。将处理器拖动到画布上时,会向用户显示一个对话框:

这里可以通过处理器的包、处理器的属性、处理器的名称等维度进行组件的筛选、选择。选中后,双击则可拖拉至画布中。
3.3 组件状态

- 状态:显示处理器的当前状态。以下指标是可能的:
| 图标 | 状态 | |
|---|---|---|
 | 正在运行 | 处理器当前正在运行。 |
 | 已停止 | 处理器有效并已启用但未运行。 |
 | 无效 | 处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。一般情况下是需要我们完成必须的配置。 |
 | 已禁用 | 处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。 |
- 名称:这是处理器的用户定义名称。默认情况下组件的名称与它的 Type 相同。在示例中,此值为
ExecuteGroovyScript,是一个专门用于执行 Groovy 脚本的组件。 - 任务:此处理器当前正在执行的任务数。此数字受处理器配置对话框的计划选项卡中的并发任务设置的约束。在这里,我们可以看到处理器当前正在执行一项任务。如果 NiFi 实例是集群的,则此值表示当前正在集群中的所有节点上执行的任务数。
- 实时日志:这里是用于监控当前处理器状态的,当处理器内部出现问题,一般会在此处显示错误日志。
- 数据流入流出看板:这里主要是展示处理数据过程中数据的流入流出情况,NiFi 默认是 5 5 5 分钟更新一次页面上的看板情况,当然用户也可以在画布空白处,鼠标右键选择刷新,以达到实时查看的效果。
In:处理器从其传入处理器的队列中提取的数据量。此值表示为count / size,其中count是从队列中提取的 FlowFiles 的数量,size是这些 FlowFiles 内容的总大小。Read/Write:处理器从磁盘读取并写入磁盘的 FlowFile 内容的总大小。这提供了有关此处理器所需的 I/O 性能的有用信息。某些处理器可能只读取数据而不写入任何内容,而某些处理器不会读取数据但只会写入数据。其他可能既不会读取也不会写入数据,而某些处理器会读取和写入数据。Out:处理器已传输到其出站连接的数据量。这不包括处理器自行删除的 FlowFiles,也不包括路由到自动终止的连接的 FlowFiles。与上面的In指标一样,此值表示为count / size,其中count是已转移到出站Connections的 FlowFiles 的数量,size是这些 FlowFiles 内容的总大小。Tasks/Time:此处理器在过去 5 分钟内被触发运行的次数,以及执行这些任务所花费的时间。时间格式为hour : minute : second。请注意,所花费的时间可能超过五分钟,因为许多任务可以并行执行。例如,如果处理器计划运行 60 个并发任务,并且每个任务都需要一秒钟才能完成,则所有 60 个任务可能会在一秒钟内完成。但是,在这种情况下,我们会看到时间指标显示它需要 60 秒,而不是 1 秒。
3.4 组件的配置
NiFi 的处理器,一般都有四个标签页,分别是 SETTINGS,SCHEDULING,PROPERITIES,COMMENTS。
除了 PROPERITIES 之外,另外三个几乎是通用的,这里主要说一下这三个实用的。
3.4.1 SETTINGS(通用配置)

基本的 Name 这里就不说了,就是用户自定义的名称,Id、Type、Bundle 这三个是这个处理器组件所属的代码包等基本信息,这里也不过多介绍,Enable 这个选项,就是控制组件由启用到禁用 状态的切换。
最右边包含自动终止关系(Automatically Terminate Relationships)部分。此处列出了处理器定义的每个关系及其描述。为了使处理器被视为有效且能够运行,处理器定义的每个关系必须连接到下游组件或自动终止。我们可以通过选中它,例如图中选中 Failure 一样,来表示我们弃用这个输出,也就是不需要它指向下一个组件,这样这个处理器就变成只有一个对外输出数据的 Relationship 了。
接下来是两个用于配置 Penalty Duration 和 Yield Duration 的对话框。在处理一条数据(FlowFile)的正常过程中,可能发生事件,该事件指示处理器此时不能处理数据但是数据可以在稍后进行处理。在发生这种情况时,处理器可以选择 Penalize FlowFile。这将阻止 FlowFile 在一段时间内被处理。例如,如果处理器要将数据推送到远程服务,但远程服务已经有一个与处理器指定的文件名同名的文件,则处理器可能会惩罚 FlowFile。Penalty Duration 允许 DFM 指定 FlowFile 应该受到多长时间的惩罚,默认值为 30 30 30 seconds,(简单理解为推后一段时间再处理),类似的处理器可以确定存在某种情况,处理器没法进行处理数据。例如,如果处理器要将数据推送到远程服务并且该服务没有响应。这样的话处理器应该 Yield,这将阻止处理器运行一段时间。通过设置 Yield Duration 来指定该时间段。默认值为 1 1 1 second。
最下方 Bulletin Level 可以简单的理解为组件的日志输出等级的选择,有选择地进行日志等级输出。
3.4.2 SCHEDULING(处理器调度)

这一标签页,代表的就是如何驱动处理器,或者说处理器的运作方式:
第一个配置选项是调度策略(Scheduling Strategy)。调度有三种可能的选项:
- Timer driven:这是默认模式。处理器将定期运行。即多久运行一次,运行处理器的时间间隔由
Run Schedule选项定义(当Run Schedule为 0 时,则代表瞬时执行)。 - Event driven:选择此模式时,将由一个事件触发处理器运行,当 FlowFiles 进入连接此处理器的 Connections 时,将产生这个事件。此模式目前被认为是实验性的,并非所有处理器都支持。选择此模式时,
Run Schedule选项不可配置。此外,只有此模式下Concurrent Tasks选项可以设置为 0。这种情况,线程数仅受管理员配置的事件驱动线程池的大小限制。 - CRON 驱动:这是定时执行模式,即通过
cron表达式,进行定时运行的控制。
下面的配置就是 线程的分配(Concurrent Tasks):这可以控制处理器将使用的线程数。换句话说,它控制此处理器应同时处理多少个 FlowFiles。增加此值通常会使处理器在相同的时间内处理更多数据。但是,它是通过使用其他处理器无法使用的系统资源来实现此目的。这基本上提供了处理器的相对权重 - 应该将多少系统资源分配给此处理器而不是其他处理器。该字段适用于大多数处理器。但是,某些类型的处理器只能使用单个任务进行调度。
关于 Execution,执行设置用于确定处理器将被调度执行的节点。选择 All Nodes 将导致在集群中的每个节点上调度此处理器。选择 Primary Node 将导致此处理器仅在主节点上进行调度。一般单节点的情况下,我们都使用 Primary Node。
Run Duration 选项卡的右侧包含一个用于选择运行持续时间的滑块。这可以控制处理器每次触发时应安排运行的时间。在滑块的左侧,标记为 Lower latency(较低延迟),而右侧标记为 Higher throughput(较高吞吐量)。处理器完成运行后,必须更新存储库才能将 FlowFiles 传输到下一个 Connection。更新存储库的成本很高,因此在更新存储库之前可以立即完成的工作量越多,处理器可以处理的工作量就越多(吞吐量越高)。这意味着在上一批数据处理更新此存储库之前,Processor 是无法开始处理接下来的 FlowFiles。结果是,延迟时间会更长(从开始到结束处理 FlowFile 所需的时间会更长)。因此,滑块提供了一个频谱,DFM 可以从中选择支持较低延迟或较高吞吐量。
3.4.3 COMMENTS(备注区)
这块把它称之为 “备注区”,即用来为用户提供一个区域,以包含适用于此组件的任何注释。
3.4.4 PROPERITIES(属性区)
这一标签页差别较大,一般不同的组件所需要的配置各不相同,具体如果想了解对应组件的属性配置可以参考官网文档。
✅ http://nifi.apache.org/docs.html
3.5 队列管道操作

对于队列管道,它即是数据从一个处理器流向另一个处理器的中间队列,最多的用处就是用来监控数据是否正常流通,以及在开发使用过程中,可能调试定位问题等需要查看一下管道的数据,这里主要从 管道的来源、手动清空、查看数据、设置超时清空、删除 来描述一下对于管道队列
3.5.1 管道的来源
管道的建立十分简单,两个组件进行一下拖拉连线即可,管道建立后,就需要选择前置处理器选用哪个 Relationship 输出的数据作为管道的源头,也就是上面配置项那里的 Relationship。
3.5.2 手动清空管道
管道内的数据承载是有限的,有些时候(阻塞或者需要删除组件)需要进行手动清空管道的数据,操作方式是:选中管道,右键会出现:

3.5.3 查看数据
查看管道中的数据可以选中管道,右键后的 List queue 选项。

3.5.4 设置超时清空
当有些组件处理速度过慢,导致阻塞(允许数据丢失的情况下),我们不能挨个进行手动的清空,这时候可以在管道的右键 configure 选项中进入管道的配置页面。

在 FlowFile Expiration 进行超时自动清空的设置,默认为 0 是不做自动清空。
3.5.5 删除
一般删除处理器之前,是需要断开所有与其关联的管道,即删除管道,删除时如果管道中有数据,需要手动制空后,选择 Delete。
3.6 NiFi 的迁移
使用 NiFi 的过程中,当进行了一系列的开发,想要对绘制的各种流程图,以及其中的配置、代码进行备份或者迁移的时候,NiFi 本身提供了很友好的迁移方式。
3.6.1 局部备份迁移
如果仅对部分流程进行备份,可以对选中的区域,使用  进行创建模板,在另一 NiFi 中,使用
进行创建模板,在另一 NiFi 中,使用  上传模板,选择
上传模板,选择  样例进行复原。
样例进行复原。
3.6.2 整体备份迁移
当整个 NiFi 的全景图需要进行备份或者迁移的时候,可以对 NiFi 安装目录下的 /conf/flow.xml.gz 文件进行复制和替换,然后重启被替换的 NiFi,即可以还原 NiFi 之前的流程和模板。
注:未进行认证设置的 NiFi 的 flow.xml.gz 是无法直接在配置了认证权限的 NiFi 上使用的!
相关文章:
【大数据】NiFi 的基本使用
NiFi 的基本使用 1.NiFi 的安装与使用1.1 NiFi 的安装1.2 各目录及主要文件 2.NiFi 的页面使用2.1 主页面介绍2.2 面板介绍 3.NiFi 的工作方式3.1 基本方式3.2 选择处理器3.3 组件状态3.4 组件的配置3.4.1 SETTINGS(通用配置)3.4.2 SCHEDULING࿰…...

5 分钟内搭建一个免费问答机器人:Milvus + LangChain
搭建一个好用、便宜又准确的问答机器人需要多长时间? 答案是 5 分钟。只需借助开源的 RAG 技术栈、LangChain 以及好用的向量数据库 Milvus。必须要强调的是,该问答机器人的成本很低,因为我们在召回、评估和开发迭代的过程中不需要调用大语言…...

WPF Border
在 WPF 中,Border 是一种常用的控件,用于给其他控件提供边框和背景效果。 要使用 Border 控件,您可以在 XAML 代码中添加以下代码: <Border BorderBrush"Black" BorderThickness"2" Background"Lig…...
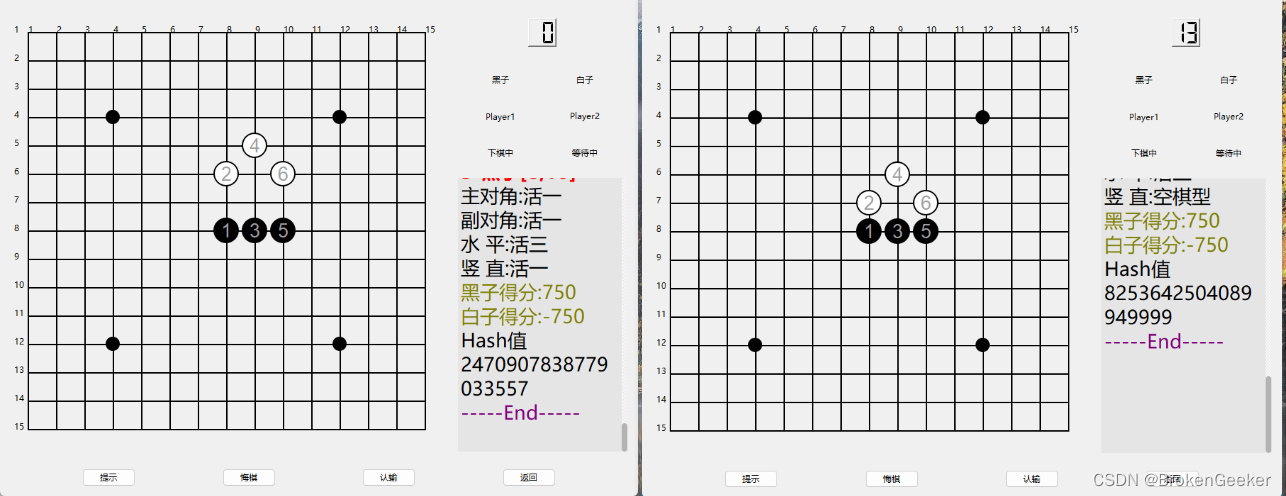
基于博弈树的开源五子棋AI教程[4 静态棋盘评估]
引子 静态棋盘的评估是棋力的一个很重要的体现,一个优秀的基于博弈树搜索的AI往往有上千行工作量,本文没有做深入讨论,仅仅写了个引子用来抛砖引玉。 评估一般从两个角度入手,一个是子力,另一个是局势。 1 评估维度 …...

STL--排序与检索
题目 现有N个大理石,每个大理石上写了一个非负整数。首先把各数从小到大排序,然后回答Q个问题。每个问题是否有一个大理石写着某个整数x,如果是,还要回答哪个大理石写着x。排序后的大理石从左到右编写为1-N。(样例中,…...
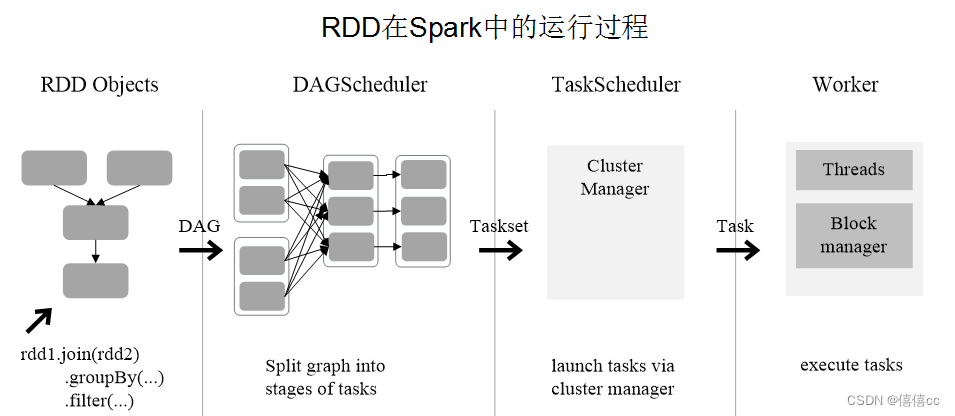
大数据处理与分析-Spark
导论 (基于Hadoop的MapReduce的优缺点) MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架 MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它将数据处理过程分为两个主要阶段:Map阶…...
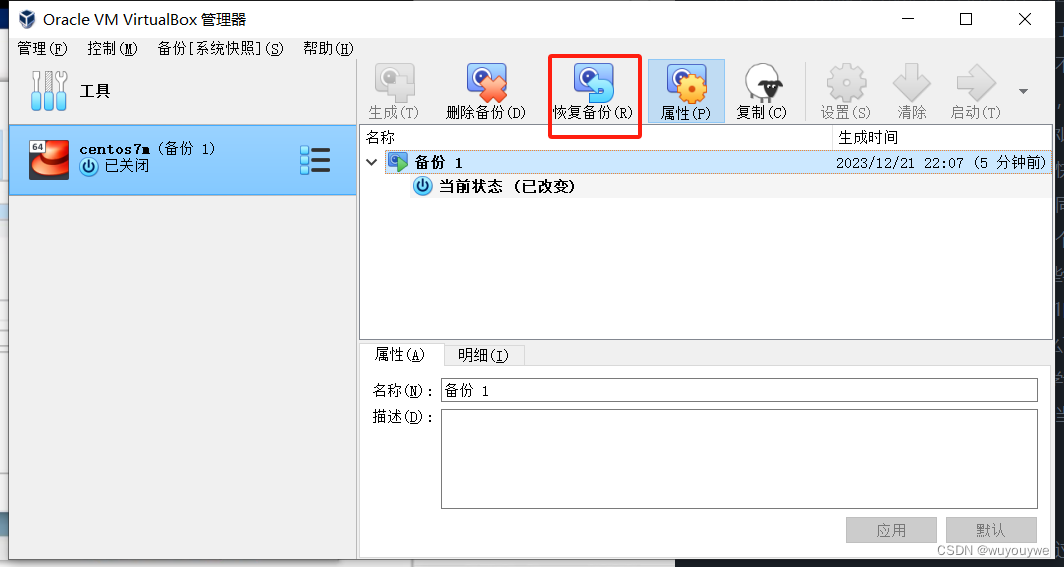
虚拟机的下载、安装(模拟出服务器)
下载 vmware workstation(收费的虚拟机) 下载vbox 网址:Oracle VM VirtualBox(免费的虚拟机) 以下选择一个下载即可,建议下载vbox,因为是免费的。安装的时候默认下一步即可(路径最好…...

K8S Pod Terminating/Unknown故障排查
一、pod异常出现现象 优雅终止周期(Graceful termination period): 当pod被删除时,会进入"Terminating"状态,等待容器优雅关闭。如果容器关闭所需时间超过默认期限(默认30秒),则pod将保持在"Terminating"状态。 Finalize…...

labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)
这里主要是搬运一下能找到的 labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)的代码,以供需要时参考和提供相关帮助。 1、官方labelme实现 如下是labelme官方网址,提供了源代码,以及相关使用方…...

MySQL报错:1366 - Incorrect integer value: ‘xx‘ for column ‘xx‘ at row 1的解决方法
我在插入表数据时遇到了1366报错,报错内容:1366 - Incorrect integer value: Cindy for column name at row 1,下面我演示解决方法。 根据上图,原因是Cindy’对应的name字段数据类型不正确。我们在左侧找到该字段所在的grade_6表&…...
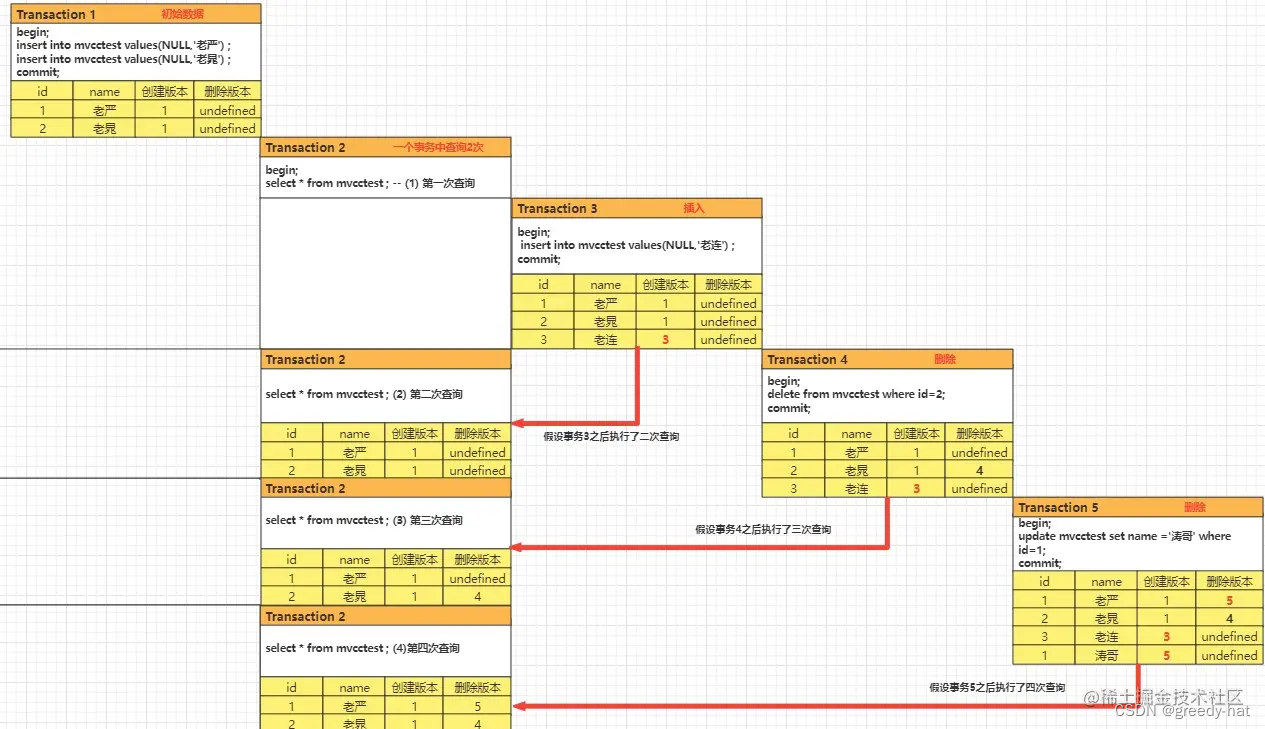
MySQL中MVCC的流程
参考文章一 参考文章二 当谈到数据库的并发控制时,多版本并发控制(MVCC)是一个重要的概念。MVCC 是一种用于实现数据库事务隔离性的技术,常见于像 PostgreSQL 和 Oracle 这样的数据库系统中。 MVCC 的核心思想是为每个数据行维护…...

朴素贝叶斯法_naive_Bayes
朴素贝叶斯法(naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入 x x x,利用贝叶斯定理…...
Windows下安装MongoDB实践总结
本文记录Windows环境下的MongoDB安装与使用总结。 【1】官网下载 官网下载地址:Download MongoDB Community Server | MongoDB 这里可以选择下载zip或者msi,zip是解压后自己配置,msi是傻瓜式一键安装。这里我们分别对比进行实践。 【2】ZI…...
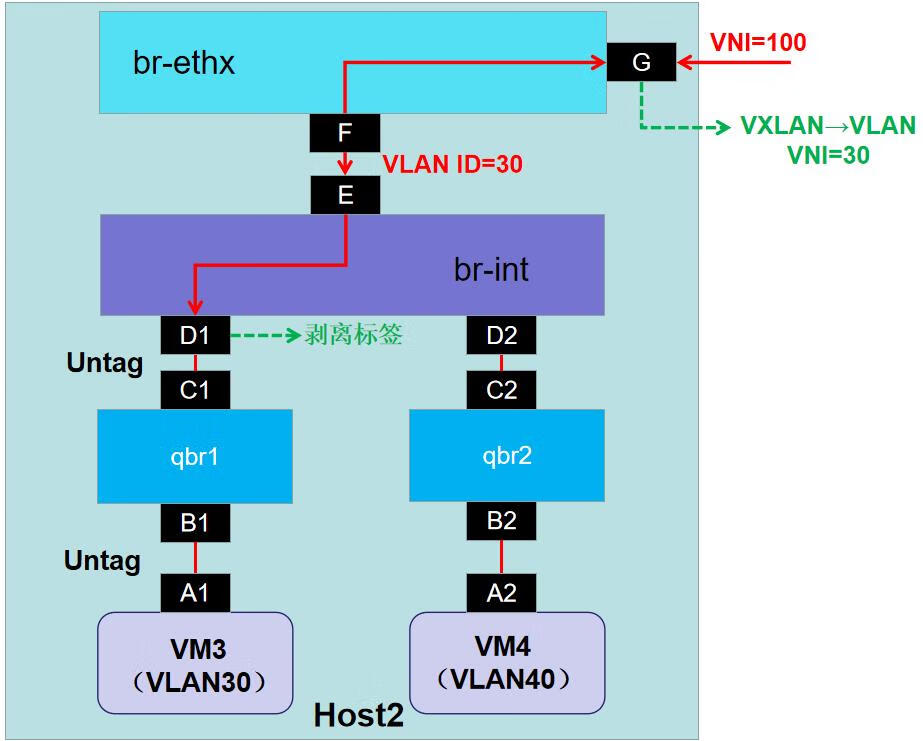
华为云Stack 8.X 流量模型分析(二)
二、流量模型分析相关知识 1.vNIC 虚拟网络接口卡(vNIC)是基于主机物理 NIC 的虚拟网络接口。每个主机可以有多个 NIC,每个 NIC 可以是多个 vNIC 的基础。 将 vNIC 附加到虚拟机时,Red Hat Virtualization Manager 会在虚拟机之间创建多个关联的…...
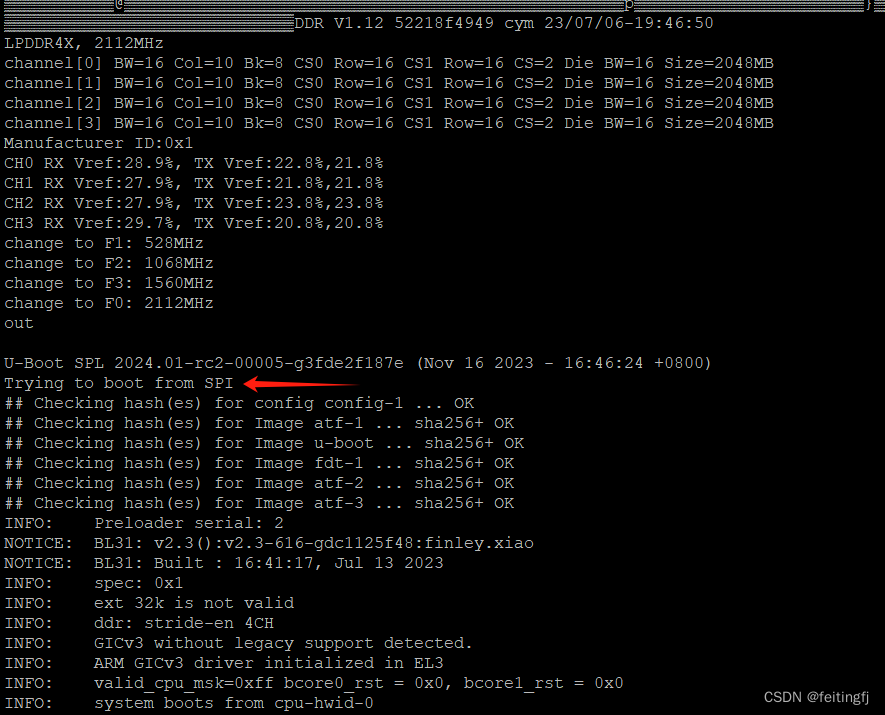
rk3588 之启动
目录 uboot版本配置修改编译 linux版本配置修改编译 启动sd卡启动制作spi 烧录 参考 uboot 版本 v2024.01-rc2 https://github.com/u-boot/u-boot https://github.com/rockchip-linux/rkbin 配置修改 使用这两个配置即可: orangepi-5-plus-rk3588_defconfig r…...
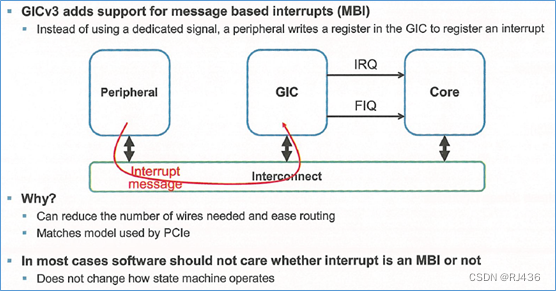
ARM GIC (五)gicv3架构-LPI
在gicv3中,引入了一种新的中断类型。message based interrupts,消息中断。 一、消息中断 外设,不在通过专用中断线,向gic发送中断,而是写gic的寄存器,来发送中断。 这样的一个好处是,可以减少中断线的个数。 为了支持消息中断,gicv3,增加了LPI,来支持消息中断。并且…...
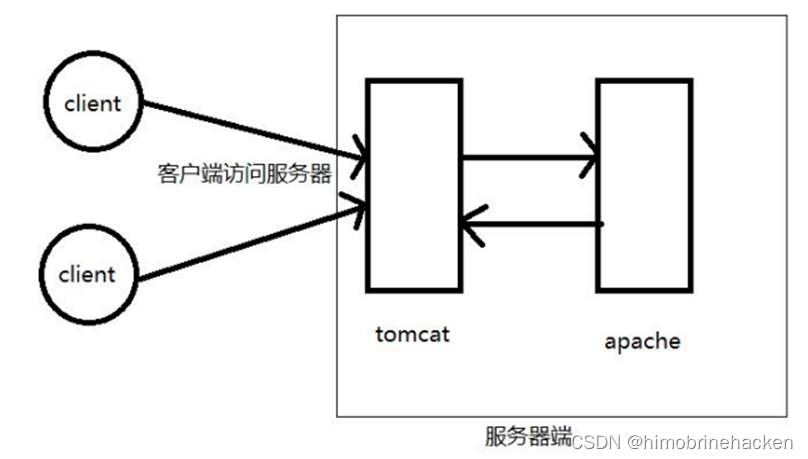
sql-labs服务器结构
双层服务器结构 一个是tomcat的jsp服务器,一个是apache的php服务器,提供服务的是php服务器,只是tomcat向php服务器请求数据,php服务器返回数据给tomcat。 此处的29-32关都是这个结构,不是用docker拉取的镜像要搭建一下…...
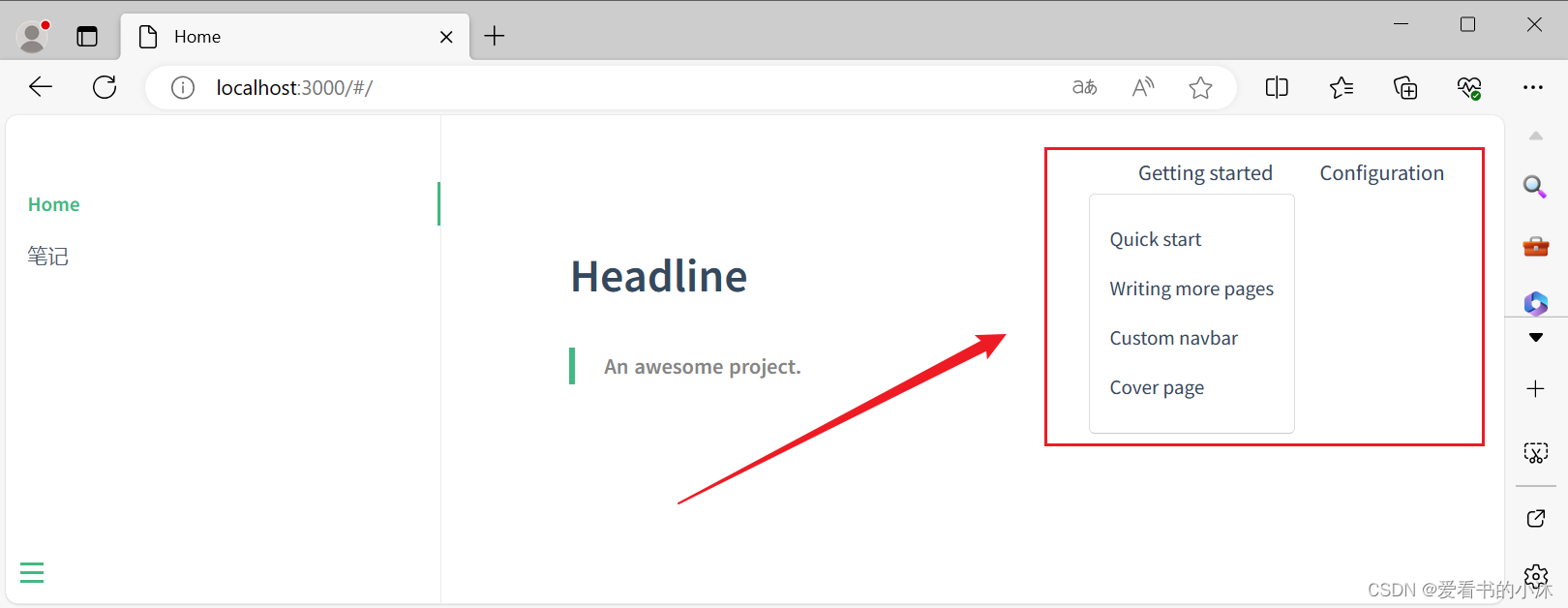
【小沐学写作】Docsify制作在线电子书、技术文档(Docsify + Markdown + node)
文章目录 1、简介2、安装2.1 node2.2 docsify-cli 3、配置3.1 初始化3.2 预览效果3.3 加载对话框3.4 更多页面3.5 侧 栏3.6 自定义导航栏 结语 1、简介 https://docsify.js.org/#/?iddocsify 一个神奇的文档网站生成器。 简单轻巧没有静态构建的 html 文件多个主题 Docsify…...
电脑完全重装教程——原版系统镜像安装
注意事项 本教程会清除所有个人文件 请谨慎操作 请谨慎操作 请谨慎操作 前言 本教程是以系统安装U盘为介质进行系统重装操作,照着流程操作会清除整个硬盘里的文件,请考虑清楚哦~ 有些小伙伴可能随便在百度上找个WinPE作为启动盘就直接…...
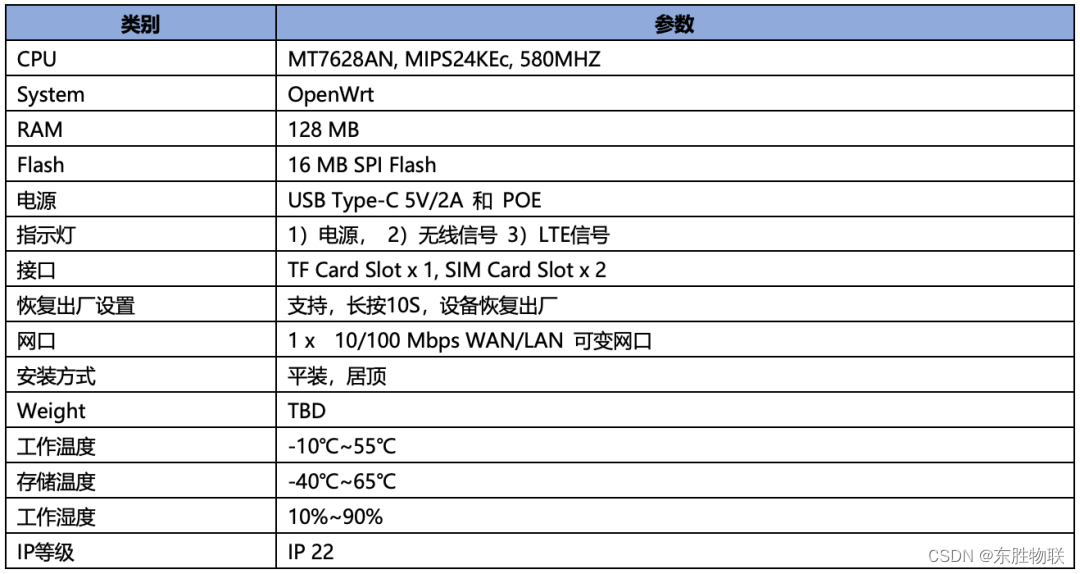
【智慧办公】如何让智能会议室的电子标签实现远程、批量更新信息?东胜物联网硬件网关让解决方案更具竞争力
近年来,为了减少办公耗能、节能环保、降本增效,越来越多的企业开始从传统的办公模式转向智慧办公。 以智能会议室为例,会议是企业业务中不可或缺的一部分,但在传统办公模式下,一来会议前行政人员需要提前准备会议材料…...

Boss-Key:办公隐私保护神器,一键隐藏敏感窗口的智能解决方案
Boss-Key:办公隐私保护神器,一键隐藏敏感窗口的智能解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在当今…...

告别NuWriter!手把手教你用命令行打包新唐NUC980 SPI NAND完整系统镜像
新唐NUC980 SPI NAND量产化镜像构建实战指南 在嵌入式设备量产过程中,传统烧录方式往往成为效率瓶颈。当面对新唐NUC980这类基于SPI NAND的工控设备时,产线工程师常需要反复切换工具链、分步烧录不同组件,不仅耗时费力,还容易因人…...

基于LangChain与本地LLM构建私有化知识库问答系统实践
1. 项目概述:从零构建一个垂直领域的知识库与问答系统最近在整理个人技术资料时,我遇到了一个非常典型的问题:手头积累了大量来自不同渠道的电子书、技术文档、知乎专栏文章以及各种开源项目的README,内容虽然优质,但过…...

AI智能体诊断工具openclaw-agent-doctor:原理、应用与实战指南
1. 项目概述:当AI智能体化身“代码医生”最近在开源社区里,一个名为openclaw-agent-doctor的项目引起了我的注意。这个名字本身就很有意思——“OpenClaw” 智能体医生。它不是一个传统的代码库,而是一个专门为AI智能体(Agent&…...

SPA06-003温压传感器实战:从I2C/SPI接口到Arduino/Python项目开发
1. 项目概述与传感器选型考量在嵌入式开发和物联网项目中,环境参数的精确感知是构建智能系统的第一步。无论是监测室内空气质量、构建个人气象站,还是为无人机提供高度参考,温度和气压数据都是不可或缺的基础信息。市面上传感器选择众多&…...

对比官方价格Taotoken的活动价确实带来了可观节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格,Taotoken的活动价确实带来了可观节省 作为一名长期使用多个大模型API进行项目开发的个人开发者ÿ…...

BaklavaJS执行引擎详解:实现节点图的拓扑排序与数据流计算 [特殊字符]
BaklavaJS执行引擎详解:实现节点图的拓扑排序与数据流计算 🚀 【免费下载链接】baklavajs Graph / node editor in the browser using VueJS 项目地址: https://gitcode.com/gh_mirrors/ba/baklavajs BaklavaJS是一个基于VueJS的强大浏览器图形节…...
)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码) 在5G NR系统中,随机接入过程是终端设备与基站建立连接的关键第一步。而其中ZC序列作为preamble的核心组成部分,其特性直接决定了随机接入的性能…...

BDInfo终极指南:如何用免费工具深度解析蓝光光盘技术参数
BDInfo终极指南:如何用免费工具深度解析蓝光光盘技术参数 【免费下载链接】BDInfo BDInfo from http://www.cinemasquid.com/blu-ray/tools/bdinfo 项目地址: https://gitcode.com/gh_mirrors/bd/BDInfo 还在为看不懂蓝光光盘的技术规格而烦恼吗?…...

自适应算法研究与应用综述
ArticleObjectiveMethodComments基于深度学习的领域自适应语义分割算法的综述与评论介绍最新的基于深度学习的领域自适应语义分割算法,并对未来的研究方向进行探讨通过对比实验,使用GTA5、Cityscapes和SYNTHIA等数据集进行性能评估无监督领域自适应语义分…...