机器学习或深度学习的数据读取工作(大数据处理)
机器学习或深度学习的数据读取工作(大数据处理)主要是.split和re.findall和glob.glob运用。
读取文件的路径(为了获得文件内容)和提取文件路径中感兴趣的东西(标签)
1,“glob.glob”用于读取文件路径
2,“.split“用于字符串分割
3,”re.findall“用于获取字符串里的感兴趣的东西
文章目录
- 一、目标是什么?
- 二、实验代码
- 2.1 获取全部路径(包含文件名的路径)
- 2.1.1 获取全部路径错误代码如下(示例):
- 2.1.2 获取全部路径错误代码结果:
- 2.1.3 获取全部路径正确代码:
- 2.1.4 获取全部路径正确代码结果
- 2.2 分别获取训练集和测试集的文件路径
- 2.3 获取文件名里面指定的内容
- 3 全部代码
- 注意事项
一、目标是什么?
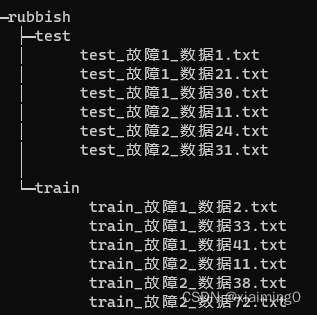
获取rubbish文件夹下以.txt结尾文件的路径,并提取文件名里面指定的内容(本次实验是获取文件名(test_故障1_数据1.txt)里“数据”后面的数字)。
二、实验代码
2.1 获取全部路径(包含文件名的路径)
2.1.1 获取全部路径错误代码如下(示例):
import numpy as np
import glob
import re# 1,错误获取路径
data_path_error = glob.glob(r'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish/*/*.txt')
data_path_error.sort()
2.1.2 获取全部路径错误代码结果:
# ['C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据1.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据21.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据30.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据24.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据31.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据2.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据33.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据41.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据38.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据72.txt']
路径下既有单斜杠(“/”)又有所斜杠(“\”),python的很多读取函数识别不了。
2.1.3 获取全部路径正确代码:
# 1,正确获取路径
data_path_right = glob.glob('C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\*\\*.txt')
data_path_right.sort()
2.1.4 获取全部路径正确代码结果
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
2.2 分别获取训练集和测试集的文件路径
代码如下(示例):
# 2,分别获取训练集和测试集的文件路径
# 2.1,获取文件名
file_name = [x.split('\\')[-1] for x in data_path_right]
file_name_temp = [x.split('_')[0] for x in file_name]
# 2.1,将训练集和测试集分开
# 2.1.1,获取训练集和测试集大小
test_size = 0
train_size = 0
for i in file_name_temp:if i == "test":test_size = test_size + 1elif i == "train":train_size = train_size + 1
# 2.1.2,获取训练集和测试集文件路径
train_path = np.empty((train_size), dtype=object)
test_path = np.empty((test_size), dtype=object)
test_size_index = 0
train_size_index = 0
for i_index, i in enumerate(file_name_temp):if i == "test":test_path[test_size_index] = data_path_right[i_index]test_size_index = test_size_index + 1elif i == "train":train_path[train_size_index] = data_path_right[i_index]train_size_index = train_size_index + 1
train_path = list(train_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
test_path = list(test_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt']
2.3 获取文件名里面指定的内容
test_fault_severity = [x.split('\\')[-1] for x in test_path]
test_fault_severity = [x.split('_')[-1] for x in test_fault_severity]
test_fault_severity = [x.split('.')[0] for x in test_fault_severity]
test_fault_severity = [re.findall(r'\d+', path)[0] for path in test_fault_severity]
print(test_fault_severity)
结果:
[‘1’, ‘21’, ‘30’, ‘11’, ‘24’, ‘31’]
3 全部代码
import numpy as np
import glob
import re# 1,错误获取路径
data_path_error = glob.glob(r'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish/*/*.txt')
data_path_error.sort()
# ['C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据1.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据21.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据30.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据24.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据31.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据2.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据33.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据41.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据38.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据72.txt']# 1,正确获取路径
data_path_right = glob.glob('C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\*\\*.txt')
data_path_right.sort()
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']# 2,分别获取训练集和测试集的文件路径
# 2.1,获取文件名
file_name = [x.split('\\')[-1] for x in data_path_right]
file_name_temp = [x.split('_')[0] for x in file_name]
# 2.1,将训练集和测试集分开
# 2.1.1,获取训练集和测试集大小
test_size = 0
train_size = 0
for i in file_name_temp:if i == "test":test_size = test_size + 1elif i == "train":train_size = train_size + 1
# 2.1.2,获取训练集和测试集文件路径
train_path = np.empty((train_size), dtype=object)
test_path = np.empty((test_size), dtype=object)
test_size_index = 0
train_size_index = 0
for i_index, i in enumerate(file_name_temp):if i == "test":test_path[test_size_index] = data_path_right[i_index]test_size_index = test_size_index + 1elif i == "train":train_path[train_size_index] = data_path_right[i_index]train_size_index = train_size_index + 1
train_path = list(train_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
test_path = list(test_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt']# 3,分别获取训练集和测试集的故障类型
test_fault_severity = [x.split('\\')[-1] for x in test_path]
test_fault_severity = [x.split('_')[-1] for x in test_fault_severity]
test_fault_severity = [x.split('.')[0] for x in test_fault_severity]
test_fault_severity = [re.findall(r'\d+', path)[0] for path in test_fault_severity]
print(test_fault_severity)
print("HELLO WORLD!")
注意事项
1,.split解释
# x.split('\\')
# 将字符串分割成一个列表,并以指定的分隔符进行分割。在这个例子中,我们使用“\\”作为分隔符。
2,.findall解释
# def findall(pattern, string, flags=0):
# string中所有与pattern匹配的全部字符串,返回形式为列表,如果pattern中含有分组,返回分组的匹配结果。如果有pattern中有多个分组,则返回元组列表。
# 例子:
# import re
# kk = re.compile(r'\d+')
# kk.findall('one1two2three3four4')
# #[1,2,3,4]
正则表达式,需要时查即可,不需要特殊关注
相关文章:
机器学习或深度学习的数据读取工作(大数据处理)
机器学习或深度学习的数据读取工作(大数据处理)主要是.split和re.findall和glob.glob运用。 读取文件的路径(为了获得文件内容)和提取文件路径中感兴趣的东西(标签) 1,“glob.glob”用于读取文件路径 2,“.…...

Rust 生命周期
Rust 第17节 生命周期 先看一段错误代码 /* //一段错误的代码 // Rust 编译时会报错; */let r;{let x 5;r &x;}println!("{}",r);Rust 在编译时使用 借用检查器, 比较作用域来检查所有的借用是否合法; 很明显;r…...
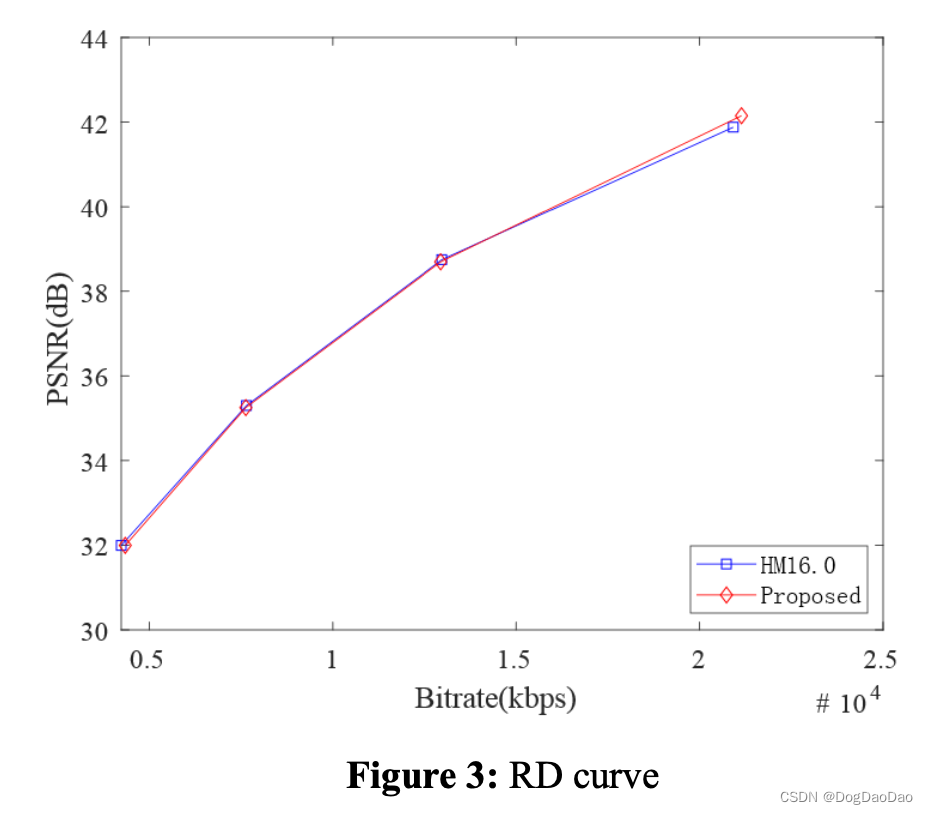
【论文解读】CNN-Based Fast HEVC Quantization Parameter Mode Decision
时间:2019 年 级别:SCI 机构:南京信息工程大学 摘要 随着多媒体呈现技术、图像采集技术和互联网行业的发展,远程通信的方式已经从以前的书信、音频转变为现在的音频/视频。和 视频在工作、学习和娱乐中的比例不断提高࿰…...

在Linux上安装CLion
本教程将指导你如何在Linux系统上安装CLion,下载地址为:https://download.jetbrains.com.cn/cpp/CLion-2022.3.3.tar.gz。以下是详细的安装步骤: 步骤1:下载CLion 首先,你需要使用wget命令从提供的URL下载CLion的tar…...
R语言贝叶斯网络模型、INLA下的贝叶斯回归、R语言现代贝叶斯统计学方法、R语言混合效应(多水平/层次/嵌套)模型
目录 ㈠ 基于R语言的贝叶斯网络模型的实践技术应用 ㈡ R语言贝叶斯方法在生态环境领域中的高阶技术应用 ㈢ 基于R语言贝叶斯进阶:INLA下的贝叶斯回归、生存分析、随机游走、广义可加模型、极端数据的贝叶斯分析 ㈣ 基于R语言的现代贝叶斯统计学方法(贝叶斯参数估…...

多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测
多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测 目录 多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多…...

Oracle 学习(1)
Oracle简介 Oracle是殷墟(yīn Xu)出土的甲骨文(oracle bone inscriptions)的英文翻译的第一个单词,在英语里是“神谕”的意思。Oracle公司成立于1977年,总部位于美国加州,是世界领先的信息管…...
华为HCIA认证H12-811题库新增
801、[单选题]178/832、在系统视图下键入什么命令可以切换到用户视图? A quit B souter C system-view D user-view 试题答案:A 试题解析:在系统视图下键入quit命令退出到用户视图。因此答案选A。 802、[单选题]“网络管理员在三层交换机上创建了V…...

Nginx Unit 1.27.0 发布
目录 介绍 更新内容 将 HTTP 请求重定向到 HTTPS 为纯路径 URI 提供可配置的文件名 完整的更新日志 其他 平台更新 介绍 Nginx Unit 是一个动态应用服务器,能够与 Nginx Plus 和 Nginx 开源版并行或独立运行。Nginx Unit 支持 RESTful JSON API,…...

【影像组学入门百问】#32—#34
#32-影像组学研究过程中,图像重采样参 数怎么选择? 在影像组学研究过程中,选择合适的图像重采样参数对于保证分析质量和准确性至关重要。以下是在选择图像重采样参数时需要考虑的一些建议: 1.目标分辨率:首先&#…...

YOLOv5代码解析——yolo.py
yolo.py的主要功能是构建模型。 1、最主要的函数是parse_model,用于解析yaml文件,并根据解析的结果搭建网络。这个函数的注释如下: def parse_model(d, ch): # model_dict, input_channels(3)"""解析模型文件,并…...

4种feature classification在代码的实现上是怎么样的?Linear / MLP / CNN / Attention-Based Heads
具体的分类效果可以看:【Arxiv 2023】Diffusion Models Beat GANs on Image Classification 1、线性分类器 (Linear, A) 使用一个简单的线性层,通常与一个激活函数结合使用。 import torch.nn as nnclass LinearClassifier(nn.Module):def __init__(se…...

最新Unity DOTS Physics物理引擎碰撞事件处理
最近DOTS发布了正式的版本,同时基于DOTS的理念实现了一套高性能的物理引擎,今天我们给大家分享和介绍一下这个物理引擎的碰撞事件处理以及核心相关概念。 Unity.Physics物理引擎的主要流程与Pipeline Unity.Physics物理引擎做仿真迭代计算的时候主要通过以下步骤来…...
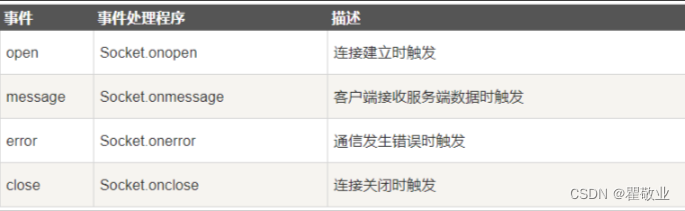
springboot集成websocket全全全!!!
一、界面展示 二、前置了解 1.什么是websocket WebSocket是一种在单个TCP连接上进行全双工通信的持久化协议。 全双工协议就是客户端可以给我们服务器发数据 服务器也可以主动给客户端发数据。 2.为什么有了http协议 还要websocket 协议 http协议是一种无状态,非…...

SpringMVC:整合 SSM 中篇
文章目录 SpringMVC - 04整合 SSM 中篇一、优化二、总结三、说明注意: SpringMVC - 04 整合 SSM 中篇 一、优化 在 spring-dao.xml 中配置 dao 接口扫描,可以动态地实现 dao 接口注入到 Spring 容器中。 优化前:手动创建 SqlSessionTempl…...
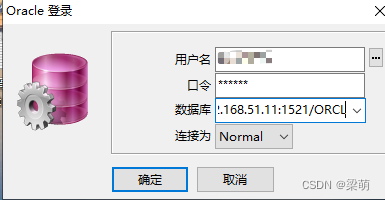
oracle即时客户端(Instant Client)安装与配置
之前的文章记录了oracle客户端和服务端的下载与安装,内容参见: 在Windows中安装Oracle_windows安装oracle 如果不想安装oracle客户端(或者是电脑因为某些原因无法安装oracle客户端),还想能够连接oracle远程服务&#…...

POP3协议详解
基本介绍 POP3是一种用于从邮件服务器获取电子邮件的协议。它允许邮件客户端连接到邮件服务器,检索服务器上存储的邮件,并将邮件下载到客户端设备上。POP3的工作原理如下: 连接和身份验证: 邮件客户端通过TCP/IP连接到邮件服务器…...

电子病历编辑器源码,提供电子病历在线制作、管理和使用的一体化电子病历解决方案
概述: 电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录,是病历的一种记录形式。 医院通过电子病历以电子化方式记录患者就诊的信息,包括&…...

WT2605C高品质音频蓝牙语音芯片:外接功放实现双声道DAC输出的优势
在音频处理领域,双声道DAC输出能够提供更为清晰、逼真的音效,增强用户的听觉体验。针对这一需求,唯创知音的WT2605C高品质音频蓝牙语音芯片,通过外接功放实现双声道DAC输出,展现出独特的应用优势。 一、高品质音频处理…...

IntelliJ IDEA 2023.3 最新版如何如何配置?IntelliJ IDEA 2023.3 最新版试用方法
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

低配置电脑适配 OpenClaw 搭配 Ollama 流畅使用技巧
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑已成功安装运行 OpenClaw 客户端,顶部 Gateway 状态保持在线网络正常,可顺利访问 Ollama 官方网站电脑空余磁盘空间充足,本地 AI 模型占用体积较大提…...

Sophia优化器:二阶曲率感知如何加速大模型训练与调参
1. 项目概述:当优化器遇上“二阶”智慧最近在复现一些前沿的论文实验时,我又一次被优化器的选择给卡住了。AdamW虽然稳,但在某些超大规模模型或特定任务上,总觉得收敛速度不够快,调参又是个玄学。就在我对着损失曲线发…...

解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒
解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾想过将脑海中的创意场景转化为生动的视频内容࿰…...

基于电子纸与ESP32的物联网桌面日历制作指南
1. 项目概述:打造一个永不掉电的桌面物联网日历如果你和我一样,喜欢在桌面上放点既实用又有科技感的小玩意儿,那么这个基于电子纸的物联网日历绝对能让你眼前一亮。它不像普通屏幕那样需要一直插着电,显示完日历后,你甚…...

基于MCP协议构建Naver搜索服务器,为AI智能体赋能实时信息获取
1. 项目概述:一个连接AI与实时信息的桥梁最近在折腾AI应用开发,特别是围绕OpenAI的Assistant API和Claude的Tool Use功能时,我一直在思考一个问题:如何让这些强大的AI模型摆脱其知识库的“时间枷锁”,获取到最新、最实…...
)
别再让Ubuntu20.04时间错乱了!用hwclock和timedatectl搞定硬件时钟时区(附原理详解)
彻底解决Ubuntu 20.04时间同步问题:硬件时钟与系统时钟的深度调校指南 每次重启电脑后,系统时间总是不准?在Windows和Ubuntu双系统间切换时,时间显示总是莫名其妙差8小时?这些困扰Linux用户多年的"时间错乱"…...
)
FPGA驱动ADS1256的ADC精度优化实战(三)
1. 硬件连接优化:从杜邦线到PCB布局的精度跃升 第一次用杜邦线连接FPGA和ADS1256时,我测得的电压误差居然有30mV,这让我差点怀疑人生。后来把万用表直接怼到ADC引脚上,才发现杜邦线本身就有5-8mV的压降波动。这种看似微不足道的干…...
)
手把手教你用Vivado 2020.1给MicroBlaze工程挂上DDR3内存(附完整IP核配置流程)
从BRAM到DDR3:MicroBlaze系统内存扩展实战指南 在FPGA嵌入式开发领域,MicroBlaze处理器因其灵活性和可定制性成为众多项目的首选。当系统复杂度从简单的"Hello World"升级到需要处理大量数据时,片上BRAM的有限容量很快会成为瓶颈。…...

3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案
3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案 【免费下载链接】Fusion-360-FDM-threads 项目地址: https://gitcode.com/gh_mirrors/fu/Fusion-360-FDM-threads 你是否在3D打印螺纹连接件时经常遇到螺纹断裂、装配困难或打印失败的问题&…...
)
Unity SLG大地图实战:用TileManager和AOI搞定网格管理与视野同步(附Demo代码)
Unity SLG大地图开发实战:网格管理与AOI视野同步的工程化解决方案 在SLG游戏开发中,大地图系统是核心体验的基石。面对动辄数万网格的动态管理需求,以及需要与后端高效协作的视野同步问题,传统开发方式往往陷入性能瓶颈和逻辑混乱…...