【教学类-42-02】20231224 X-Y 之间加法题判断题2.0(按2:8比例抽取正确题和错误题)
作品展示:
0-5: 21题,正确21题,错误21题=42题 。小于44格子,都写上,哪怕输入2:8,实际也是5:5

0-10 66题,正确66题,错误66题=132题 大于44格子,正确66题抽取44*20%=8.8=8题,错误题66题*80%=44-8=36题
背景需求:
很多大班孩子很熟练做“0-5,0-10的加法、或减法题目,需要新的题型来换花样。除了”比大小“,我能想起的就是”判断加法题答案是否正确。
1.0模板是所有的题目都是错误答案,2.0模板能控制一定比例的正确题目出现
WORD模板





代码展示:
'''
X-Y 之间的所有加法题的判断题2.0(随机生成错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,timeimport docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qnfrom docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor# 第一步:制作不重复所有“+”、不重复所有减法# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))# 5以内“+”题共21题
P1=[]# 正确for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字for b in range(0,sum2+1): # 起始数字为0,if 0<=a+b<sum2+1: w=random.randint(sum1,sum2) # 随机生成错误数字 # print('{}+{}='.format(a,b)) P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))if 0<=b+a<sum2+1: # print('{}+{}='.format(a,b))P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))else:passP1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建D=[]
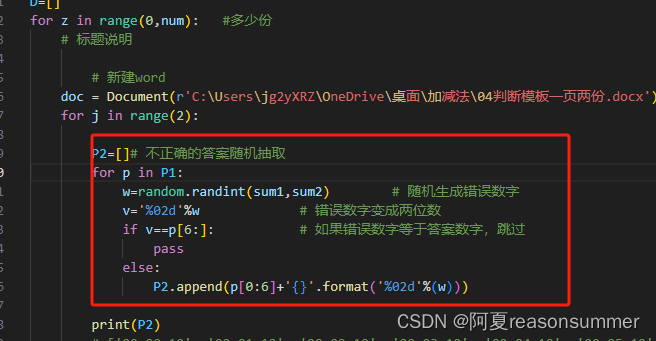
for z in range(0,num): #多少份 # 标题说明# 新建worddoc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx') for j in range(2):P2=[]# 不正确的答案随机抽取for p in P1:w=random.randint(sum1,sum2) # 随机生成错误数字P2.append(p[0:6]+'{}'.format('%02d'%(w)))print(P2)# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']P3=P1+P2# [[],[]]print('P3长度{}'.format(len(P3)))# 二位数去0P4=[]for i in P3: # 每个内容是00+00=00,一共6个字符# print(i)if i[0]=='0'and i[3]=='0' and i[6]=='0':P4.append(i[1:3]+i[4:6]+i[7]) if i[0]=='0'and i[3]=='0'and i[6]!='0':P4.append(i[1:3]+i[4:]) if i[0]=='0'and i[3]!='0'and i[6]!='0': P4.append(i[1:])if i[0]=='0'and i[3]!='0'and i[6]=='0': P4.append(i[1:6]+i[7])if i[0]!='0'and i[3]=='0'and i[6]=='0': P4.append(i[0:3]+i[4:6]+i[7])if i[0]!='0'and i[3]!='0'and i[6]=='0':P4.append(i[0:6]+i[7]) if i[0]!='0'and i[3]=='0'and i[6]!='0': P4.append(i[0:3]+i[4:])if i[0]!='0'and i[3]!='0'and i[6]!='0':P4.append(i)print(P4)print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42# 如果正确题+错误题大于44题P=[] if len(P4)>gz: # 正确题在前,错误题在后P5=[]f=int(len(P4)/2) # 21for e in range(int(len(P4)/f)):P5.append(P4[e*f:e*f+f])print(P5)# 随机抽取比例 共44题zq=int(gz*(bl*10/100))cw=gz-zq# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P a1=P5[0]a2=P5[1]t1=random.sample (a1,zq)t2=random.sample (a2,cw)for t3 in t1:P.append(t3)for t4 in t2:P.append(t4)# 暂时不打乱if len(P4)<=gz:for t5 in P4:P.append(t5) # print(P)# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42# 第一行的班级和项目A=[]c='{}'.format(classroom)if len(P) <=gz:title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),len(P),bl,10-bl)if len(P) >gz:title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)d=['0003','0006']# 表格0 表格2的 03 05单元格里写入标题信息cA.append(c)A.append(title)print(A)# 制作"单元格"bg=[]for x in range(0,weight1*3,3): # 5 #数列 先宽 后高 for y in range(1,height1+1): # 23s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x bg.append(s1) print(bg) print(len(bg))bg.insert(0,d[1])bg.insert(0,d[0])print(bg)print(len(bg))# 如果题目总数小于155,就提取# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复PP=[]PPP=[]PP.clear() # P.clear()if len(P)<=gz:for l in P : # 先写入固定的21题PP.append(l)print(PP)print('第1组长度{}'.format(len(PP)))# 0-0只有1题,所以批量155次for e in range(gz):PP.append('') # 预留一个空行做分割线v=random.sample(P,len(P)) # 从21题随机抽取不重复21for u in v: # 遍历提取PP.append(u) # 添加到PPPP=PP[:gz] # 提取前55个print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))print(PPP)else:w=random.sample(P,len(P)) # 从21题随机抽取不重复21PPP=wPPP.insert(0,title)PPP.insert(0,classroom)print(PPP)print(len(PPP))# # 房间模板(第一个表格)要写入的门牌号列表 table = doc.tables[j] # 表0,表2 写标题用的# 标题写入3、5单元格 for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字pp=int(bg[t][0:2]) # qq=int(bg[t][2:4])k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字print(pp,qq,k)# 图案符号的字体、大小参数run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案run.font.name = '黑体'#输入时默认华文彩云字体# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片run.font.size = Pt(size) #是否加粗# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.bold=True# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距r = run._elementr.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中 #
# doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word time.sleep(1)from docx2pdf import convert# docx 文件另存为PDF文件inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在# 先创建 不存在的 文件f1 = open(outputFile, 'w')f1.close()# 再转换往PDF中写入内容convert(inputFile, outputFile)print('----------第4步:把都有PDF合并为一个打印用PDF------------')# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:print(pdf)file_merger.append(pdf)if len(P) <=gz:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹终端展示
2.0版判断题说明:
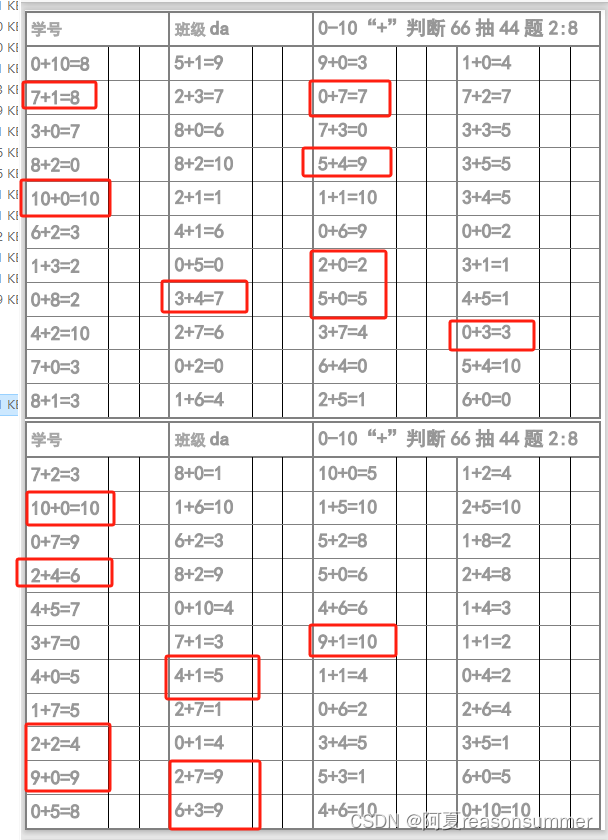
以0-5为例,21题,按比例抽取正确题20%和错误题80%。因为21正确题+21错误题总数42题,小于44格子,所以默认都写入表格,先正确题,后错误题,不考虑20%和80%的比例。
以0-10为例,66题,按比例抽取正确题20%和错误题80%。因为66正确题+66错误题总数132题,大于44格子,所以考虑按正确题20%和错误题80%的比例随机打乱抽取

以上为了演示正确错误题目的数量正确性,,而“先正确题”“后错误题。”
打乱时,只要把这两个取消隐藏,显示出来,就能够做出正确与错误题混合的效果

'''
X-Y 之间的所有加法题的判断题2.0(打乱版 随机生成错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,timeimport docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qnfrom docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor# 第一步:制作不重复所有“+”、不重复所有减法# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))# 5以内“+”题共21题
P1=[]# 正确for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字for b in range(0,sum2+1): # 起始数字为0,if 0<=a+b<sum2+1: w=random.randint(sum1,sum2) # 随机生成错误数字 # print('{}+{}='.format(a,b)) P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))if 0<=b+a<sum2+1: # print('{}+{}='.format(a,b))P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))else:passP1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建D=[]
for z in range(0,num): #多少份 # 标题说明# 新建worddoc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx') for j in range(2):P2=[]# 不正确的答案随机抽取for p in P1:w=random.randint(sum1,sum2) # 随机生成错误数字P2.append(p[0:6]+'{}'.format('%02d'%(w)))print(P2)# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']P3=P1+P2# [[],[]]print('P3长度{}'.format(len(P3)))# 二位数去0P4=[]for i in P3: # 每个内容是00+00=00,一共6个字符# print(i)if i[0]=='0'and i[3]=='0' and i[6]=='0':P4.append(i[1:3]+i[4:6]+i[7]) if i[0]=='0'and i[3]=='0'and i[6]!='0':P4.append(i[1:3]+i[4:]) if i[0]=='0'and i[3]!='0'and i[6]!='0': P4.append(i[1:])if i[0]=='0'and i[3]!='0'and i[6]=='0': P4.append(i[1:6]+i[7])if i[0]!='0'and i[3]=='0'and i[6]=='0': P4.append(i[0:3]+i[4:6]+i[7])if i[0]!='0'and i[3]!='0'and i[6]=='0':P4.append(i[0:6]+i[7]) if i[0]!='0'and i[3]=='0'and i[6]!='0': P4.append(i[0:3]+i[4:])if i[0]!='0'and i[3]!='0'and i[6]!='0':P4.append(i)print(P4)print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42# 如果正确题+错误题大于44题P=[] if len(P4)>gz: # 正确题在前,错误题在后P5=[]f=int(len(P4)/2) # 21for e in range(int(len(P4)/f)):P5.append(P4[e*f:e*f+f])print(P5)# 随机抽取比例 共44题zq=int(gz*(bl*10/100))cw=gz-zq# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P a1=P5[0]a2=P5[1]t1=random.sample (a1,zq)t2=random.sample (a2,cw)for t3 in t1:P.append(t3)for t4 in t2:P.append(t4)random.shuffle(P) # 随机打乱# 暂时不打乱if len(P4)<=gz:for t5 in P4:P.append(t5) random.shuffle(P) # 随机打乱 # print(P)# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42# 第一行的班级和项目A=[]c='{}'.format(classroom)if len(P) <=gz:title='{}-{}“+”判断{}抽{}题5:5'.format(sum1,sum2,len(P1),len(P),bl,10-bl)if len(P) >gz:title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)d=['0003','0006']# 表格0 表格2的 03 05单元格里写入标题信息cA.append(c)A.append(title)print(A)# 制作"单元格"bg=[]for x in range(0,weight1*3,3): # 5 #数列 先宽 后高 for y in range(1,height1+1): # 23s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x bg.append(s1) print(bg) print(len(bg))bg.insert(0,d[1])bg.insert(0,d[0])print(bg)print(len(bg))# 如果题目总数小于155,就提取# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复PP=[]PPP=[]PP.clear() # P.clear()if len(P)<=gz:for l in P : # 先写入固定的21题PP.append(l)print(PP)print('第1组长度{}'.format(len(PP)))# 0-0只有1题,所以批量155次for e in range(gz):PP.append('') # 预留一个空行做分割线v=random.sample(P,len(P)) # 从21题随机抽取不重复21for u in v: # 遍历提取PP.append(u) # 添加到PPPP=PP[:gz] # 提取前55个print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))print(PPP)else:w=random.sample(P,len(P)) # 从21题随机抽取不重复21PPP=wPPP.insert(0,title)PPP.insert(0,classroom)print(PPP)print(len(PPP))# # 房间模板(第一个表格)要写入的门牌号列表 table = doc.tables[j] # 表0,表2 写标题用的# 标题写入3、5单元格 for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字pp=int(bg[t][0:2]) # qq=int(bg[t][2:4])k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字print(pp,qq,k)# 图案符号的字体、大小参数run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案run.font.name = '黑体'#输入时默认华文彩云字体# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片run.font.size = Pt(size) #是否加粗# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.bold=True# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距r = run._elementr.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中 #
# doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word time.sleep(1)from docx2pdf import convert# docx 文件另存为PDF文件inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在# 先创建 不存在的 文件f1 = open(outputFile, 'w')f1.close()# 再转换往PDF中写入内容convert(inputFile, outputFile)print('----------第4步:把都有PDF合并为一个打印用PDF------------')# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:print(pdf)file_merger.append(pdf)if len(P) <=gz:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹

存在问题:
随机生成的错误答案中也会有正确答案(随机抽取数字)。范围越小(0-5),这种情况月明显,正确数量超过21题,。后续需要设计,确保错误题答案不会有正确数字
解决
添加代码,遇到正确答案,就跳过,实现了“”每份0-10 正确题目20%=8题“”的目标
'''
X-Y 之间的所有加法题的判断题2.0(随机生成绝对错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,timeimport docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qnfrom docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor# 第一步:制作不重复所有“+”、不重复所有减法# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))# 5以内“+”题共21题
P1=[]# 正确for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字for b in range(0,sum2+1): # 起始数字为0,if 0<=a+b<sum2+1: w=random.randint(sum1,sum2) # 随机生成错误数字 # print('{}+{}='.format(a,b)) P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))if 0<=b+a<sum2+1: # print('{}+{}='.format(a,b))P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))else:passP1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建D=[]
for z in range(0,num): #多少份 # 标题说明# 新建worddoc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx') for j in range(2):P2=[]# 不正确的答案随机抽取for p in P1:w=random.randint(sum1,sum2) # 随机生成错误数字v='%02d'%w # 错误数字变成两位数if v==p[6:]: # 如果错误数字等于答案数字,跳过passelse:P2.append(p[0:6]+'{}'.format('%02d'%(w)))print(P2)# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']P3=P1+P2# [[],[]]print('P3长度{}'.format(len(P3)))# 二位数去0P4=[]for i in P3: # 每个内容是00+00=00,一共6个字符# print(i)if i[0]=='0'and i[3]=='0' and i[6]=='0':P4.append(i[1:3]+i[4:6]+i[7]) if i[0]=='0'and i[3]=='0'and i[6]!='0':P4.append(i[1:3]+i[4:]) if i[0]=='0'and i[3]!='0'and i[6]!='0': P4.append(i[1:])if i[0]=='0'and i[3]!='0'and i[6]=='0': P4.append(i[1:6]+i[7])if i[0]!='0'and i[3]=='0'and i[6]=='0': P4.append(i[0:3]+i[4:6]+i[7])if i[0]!='0'and i[3]!='0'and i[6]=='0':P4.append(i[0:6]+i[7]) if i[0]!='0'and i[3]=='0'and i[6]!='0': P4.append(i[0:3]+i[4:])if i[0]!='0'and i[3]!='0'and i[6]!='0':P4.append(i)print(P4)print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42# 如果正确题+错误题大于44题P=[] if len(P4)>gz: # 正确题在前,错误题在后P5=[]f=int(len(P4)/2) # 21for e in range(int(len(P4)/f)):P5.append(P4[e*f:e*f+f])print(P5)# 随机抽取比例 共44题zq=int(gz*(bl*10/100))cw=gz-zq# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P a1=P5[0]a2=P5[1]t1=random.sample (a1,zq)t2=random.sample (a2,cw)for t3 in t1:P.append(t3)for t4 in t2:P.append(t4)random.shuffle(P) # 随机打乱# 暂时不打乱if len(P4)<=gz:for t5 in P4:P.append(t5) random.shuffle(P) # 随机打乱 # print(P)# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42# 第一行的班级和项目A=[]c='{}'.format(classroom)if len(P1) <=gz:title='{}-{}“+”判断{}抽{}题5:5'.format(sum1,sum2,len(P1),len(P),bl,10-bl)if len(P1) >gz:title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)d=['0003','0006']# 表格0 表格2的 03 05单元格里写入标题信息cA.append(c)A.append(title)print(A)# 制作"单元格"bg=[]for x in range(0,weight1*3,3): # 5 #数列 先宽 后高 for y in range(1,height1+1): # 23s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x bg.append(s1) print(bg) print(len(bg))bg.insert(0,d[1])bg.insert(0,d[0])print(bg)print(len(bg))# 如果题目总数小于155,就提取# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复PP=[]PPP=[]PP.clear() # P.clear()if len(P)<=gz:for l in P : # 先写入固定的21题PP.append(l)print(PP)print('第1组长度{}'.format(len(PP)))# 0-0只有1题,所以批量155次for e in range(gz):PP.append('') # 预留一个空行做分割线v=random.sample(P,len(P)) # 从21题随机抽取不重复21for u in v: # 遍历提取PP.append(u) # 添加到PPPP=PP[:gz] # 提取前55个print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))print(PPP)else:w=random.sample(P,len(P)) # 从21题随机抽取不重复21PPP=wPPP.insert(0,title)PPP.insert(0,classroom)print(PPP)print(len(PPP))# # 房间模板(第一个表格)要写入的门牌号列表 table = doc.tables[j] # 表0,表2 写标题用的# 标题写入3、5单元格 for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字pp=int(bg[t][0:2]) # qq=int(bg[t][2:4])k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字print(pp,qq,k)# 图案符号的字体、大小参数run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案run.font.name = '黑体'#输入时默认华文彩云字体# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片run.font.size = Pt(size) #是否加粗# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255run.bold=True# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距r = run._elementr.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中 #
# doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word time.sleep(1)from docx2pdf import convert# docx 文件另存为PDF文件inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在# 先创建 不存在的 文件f1 = open(outputFile, 'w')f1.close()# 再转换往PDF中写入内容convert(inputFile, outputFile)print('----------第4步:把都有PDF合并为一个打印用PDF------------')# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:print(pdf)file_merger.append(pdf)if len(P) <=gz:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹相关文章:
【教学类-42-02】20231224 X-Y 之间加法题判断题2.0(按2:8比例抽取正确题和错误题)
作品展示: 0-5: 21题,正确21题,错误21题42题 。小于44格子,都写上,哪怕输入2:8,实际也是5:5 0-10 66题,正确66题,错误66题132题 大于44格子,正确66题抽取44*…...
轻量Http客户端工具VSCode和IDEA
文章目录 前言Visual Studio Code 的插件 REST Client编写第一个案例进阶,设置变量进阶,设置Token IntelliJ IDEA 的 HTTP请求构建http脚本HTTP的环境配置结果值暂存 前言 作为一个WEB工程师,在日常的使用过程中,HTTP请求是必不可…...
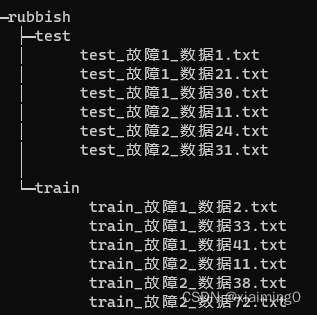
机器学习或深度学习的数据读取工作(大数据处理)
机器学习或深度学习的数据读取工作(大数据处理)主要是.split和re.findall和glob.glob运用。 读取文件的路径(为了获得文件内容)和提取文件路径中感兴趣的东西(标签) 1,“glob.glob”用于读取文件路径 2,“.…...

Rust 生命周期
Rust 第17节 生命周期 先看一段错误代码 /* //一段错误的代码 // Rust 编译时会报错; */let r;{let x 5;r &x;}println!("{}",r);Rust 在编译时使用 借用检查器, 比较作用域来检查所有的借用是否合法; 很明显;r…...
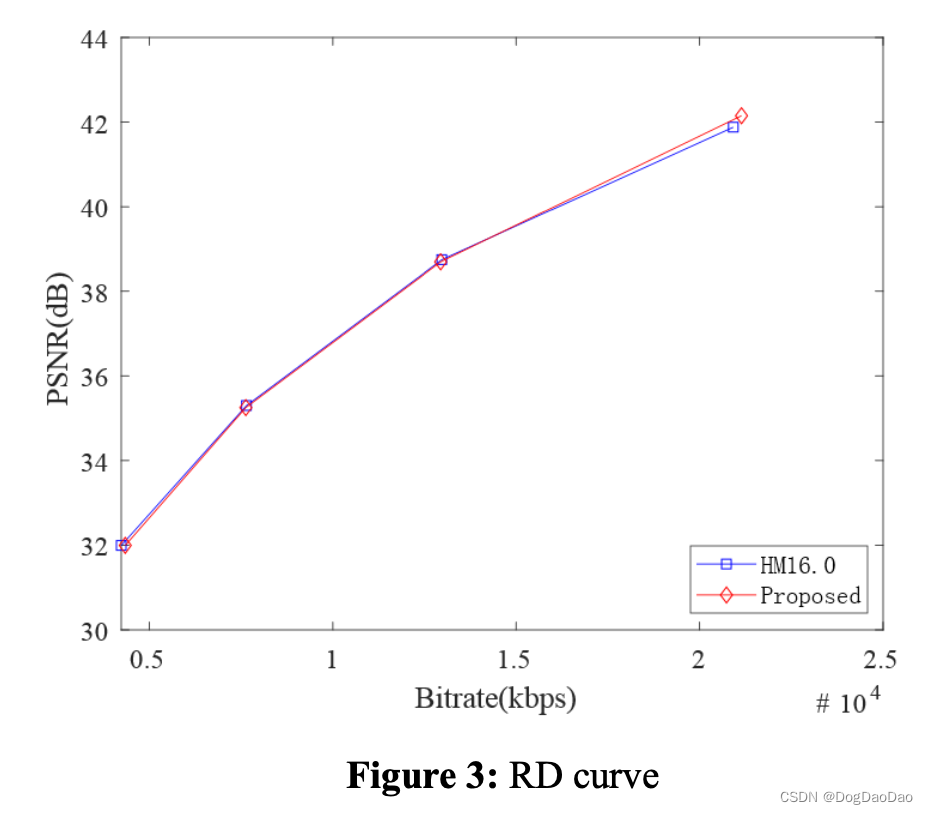
【论文解读】CNN-Based Fast HEVC Quantization Parameter Mode Decision
时间:2019 年 级别:SCI 机构:南京信息工程大学 摘要 随着多媒体呈现技术、图像采集技术和互联网行业的发展,远程通信的方式已经从以前的书信、音频转变为现在的音频/视频。和 视频在工作、学习和娱乐中的比例不断提高࿰…...

在Linux上安装CLion
本教程将指导你如何在Linux系统上安装CLion,下载地址为:https://download.jetbrains.com.cn/cpp/CLion-2022.3.3.tar.gz。以下是详细的安装步骤: 步骤1:下载CLion 首先,你需要使用wget命令从提供的URL下载CLion的tar…...
R语言贝叶斯网络模型、INLA下的贝叶斯回归、R语言现代贝叶斯统计学方法、R语言混合效应(多水平/层次/嵌套)模型
目录 ㈠ 基于R语言的贝叶斯网络模型的实践技术应用 ㈡ R语言贝叶斯方法在生态环境领域中的高阶技术应用 ㈢ 基于R语言贝叶斯进阶:INLA下的贝叶斯回归、生存分析、随机游走、广义可加模型、极端数据的贝叶斯分析 ㈣ 基于R语言的现代贝叶斯统计学方法(贝叶斯参数估…...

多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测
多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测 目录 多维时序 | Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 Matlab实现PSO-GCNN粒子群优化分组卷积神经网络多…...

Oracle 学习(1)
Oracle简介 Oracle是殷墟(yīn Xu)出土的甲骨文(oracle bone inscriptions)的英文翻译的第一个单词,在英语里是“神谕”的意思。Oracle公司成立于1977年,总部位于美国加州,是世界领先的信息管…...
华为HCIA认证H12-811题库新增
801、[单选题]178/832、在系统视图下键入什么命令可以切换到用户视图? A quit B souter C system-view D user-view 试题答案:A 试题解析:在系统视图下键入quit命令退出到用户视图。因此答案选A。 802、[单选题]“网络管理员在三层交换机上创建了V…...

Nginx Unit 1.27.0 发布
目录 介绍 更新内容 将 HTTP 请求重定向到 HTTPS 为纯路径 URI 提供可配置的文件名 完整的更新日志 其他 平台更新 介绍 Nginx Unit 是一个动态应用服务器,能够与 Nginx Plus 和 Nginx 开源版并行或独立运行。Nginx Unit 支持 RESTful JSON API,…...

【影像组学入门百问】#32—#34
#32-影像组学研究过程中,图像重采样参 数怎么选择? 在影像组学研究过程中,选择合适的图像重采样参数对于保证分析质量和准确性至关重要。以下是在选择图像重采样参数时需要考虑的一些建议: 1.目标分辨率:首先&#…...

YOLOv5代码解析——yolo.py
yolo.py的主要功能是构建模型。 1、最主要的函数是parse_model,用于解析yaml文件,并根据解析的结果搭建网络。这个函数的注释如下: def parse_model(d, ch): # model_dict, input_channels(3)"""解析模型文件,并…...

4种feature classification在代码的实现上是怎么样的?Linear / MLP / CNN / Attention-Based Heads
具体的分类效果可以看:【Arxiv 2023】Diffusion Models Beat GANs on Image Classification 1、线性分类器 (Linear, A) 使用一个简单的线性层,通常与一个激活函数结合使用。 import torch.nn as nnclass LinearClassifier(nn.Module):def __init__(se…...

最新Unity DOTS Physics物理引擎碰撞事件处理
最近DOTS发布了正式的版本,同时基于DOTS的理念实现了一套高性能的物理引擎,今天我们给大家分享和介绍一下这个物理引擎的碰撞事件处理以及核心相关概念。 Unity.Physics物理引擎的主要流程与Pipeline Unity.Physics物理引擎做仿真迭代计算的时候主要通过以下步骤来…...
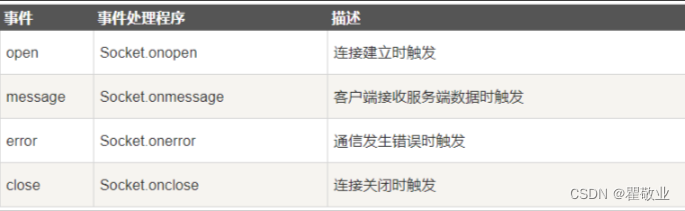
springboot集成websocket全全全!!!
一、界面展示 二、前置了解 1.什么是websocket WebSocket是一种在单个TCP连接上进行全双工通信的持久化协议。 全双工协议就是客户端可以给我们服务器发数据 服务器也可以主动给客户端发数据。 2.为什么有了http协议 还要websocket 协议 http协议是一种无状态,非…...

SpringMVC:整合 SSM 中篇
文章目录 SpringMVC - 04整合 SSM 中篇一、优化二、总结三、说明注意: SpringMVC - 04 整合 SSM 中篇 一、优化 在 spring-dao.xml 中配置 dao 接口扫描,可以动态地实现 dao 接口注入到 Spring 容器中。 优化前:手动创建 SqlSessionTempl…...
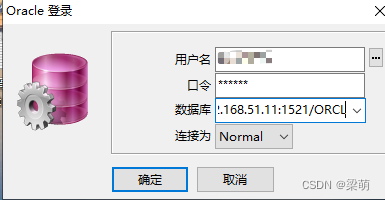
oracle即时客户端(Instant Client)安装与配置
之前的文章记录了oracle客户端和服务端的下载与安装,内容参见: 在Windows中安装Oracle_windows安装oracle 如果不想安装oracle客户端(或者是电脑因为某些原因无法安装oracle客户端),还想能够连接oracle远程服务&#…...

POP3协议详解
基本介绍 POP3是一种用于从邮件服务器获取电子邮件的协议。它允许邮件客户端连接到邮件服务器,检索服务器上存储的邮件,并将邮件下载到客户端设备上。POP3的工作原理如下: 连接和身份验证: 邮件客户端通过TCP/IP连接到邮件服务器…...

电子病历编辑器源码,提供电子病历在线制作、管理和使用的一体化电子病历解决方案
概述: 电子病历是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录,是病历的一种记录形式。 医院通过电子病历以电子化方式记录患者就诊的信息,包括&…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...

MCP服务器部署模板:容器化与CI/CD自动化实践指南
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或维护一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且对如何将其优雅、可靠地部署到生产环境感到头疼,那么你很可能已经…...

U64JSON编码技术解析与Iris框架性能优化
1. Iris框架与U64JSON编码技术解析 在嵌入式系统和高性能计算领域,数据交换效率直接影响整体系统性能。传统JSON虽然具有可读性好、跨平台等优势,但其文本特性带来的解析开销和带宽占用成为性能瓶颈。Arm Iris框架采用的U64JSON编码方案,通过…...

雷达目标检测与成像算法实时实现【附代码】
✨ 长期致力于阵列雷达、多输入多输出、现场可编程门阵列、目标检测定位、高分辨成像研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)相控阵和差波束目…...
)
告别3D-DNA的卡顿:用Chromap+Yahs快速搞定植物Hi-C辅助组装(附完整代码)
植物基因组Hi-C辅助组装新方案:ChromapYahs全流程解析 在植物基因组研究中,Hi-C技术已成为提升组装连续性的重要手段。然而传统3D-DNA流程在植物数据上的表现常令研究者头疼——运行速度缓慢、内存占用高,且对植物特有的重复序列处理效果欠佳…...

Arm Neoverse CMN-650架构解析与性能优化
1. Arm Neoverse CMN-650架构概览CMN-650是Arm Neoverse平台中的第三代一致性网格网络(Coherent Mesh Network)互连技术,专为高性能计算和数据中心场景设计。作为SoC内部的核心互连架构,它承担着连接处理器集群、内存控制器、I/O子系统以及加速器单元的关…...
)
腾讯云秒杀活动是什么?2026年最新参与指南(附抢购技巧)
腾讯云秒杀活动是什么?怎么参与?本文将详细解析腾讯云秒杀活动规则、参与入口、抢购技巧及备选方案,助力大家低成本开启云端之旅! 一、活动介绍 腾讯云秒杀活动是腾讯云官方推出的限量限时抢购活动,主打高性价比的轻量…...
)
Automa实战:除了循环数字,这两种更高效的网页数据抓取方法你知道吗?(附避坑指南)
Automa进阶实战:突破循环数字的网页抓取高效方法论 当你在深夜盯着屏幕上那个不断转圈的Automa工作流,第37次尝试抓取动态加载的电商商品列表却依然失败时,或许该重新思考自动化抓取的本质了。循环数字就像用螺丝刀当锤子——在某些场景下能勉…...

现代C++错误处理中的异常与结果类型权衡
现代C错误处理中的异常与结果类型权衡C 错误处理长期存在两条路线:异常和返回值。现代工程实践里,问题不再是“哪一个绝对更好”,而是如何根据边界、性能和调用模式做出清晰选择。异常的优势在于主路径简洁:#include #includeint …...

Cursor配置管理:使用符号链接与CLI实现多项目环境一键切换
1. 项目概述:为什么我们需要管理Cursor的配置?如果你和我一样,每天大部分时间都泡在Cursor这个AI驱动的代码编辑器里,那你肯定遇到过这样的场景:早上打开电脑,准备开始一个全新的前端项目,你熟练…...