Spark开发
第一步:创建RDD
Spark提供三种创建RDD方式:** 集合、本地文件、HDFS文件**
- 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造一些测试数据,来测试后面的spark应用程序的流程。
- 使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件
- 使用HDFS文件创建RDD,是最常用的生产环境的处理方式,主要可以针对HDFS上存储的数据,进行离线批处理操作。
使用集合创建RDD
如果要通过集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上,形成一个分布式的数据集合,也就是一个RDD。相当于,集合中的部分数据会到一个节点上,而另一部分数据会到其它节点上。然后就可以用并行的方式来操作这个分布式数据集合了
object CreateRddByArrayscala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("CreateRddByArrayscala").setMaster("local")val sc = new SparkContext(conf)//创建集合 driver中执行val arr = Array(1,2,3,4,5)//基于集合创建RDDval rdd =sc.parallelize(arr)//对集合数据求和val sum =rdd.reduce(_ + _)//这行代码再driver中执行println(sum)
** 注意**
val arr = Array(1,2,3,4,5)还有println(sum)代码是在driver进程中执行的,这些代码不会并行执行parallelize还有reduce之类的操作是在worker节点中执行的
使用本地文件和HDFS文件创建RDD
通过SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD,RDD中的每个元素就是文件中的一行文本内容。textFile()方法支持针对目录、压缩文件以及通配符创建RDD
/*** 通过文件创建RDD*/
object CreateRddByFilescala {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("CreateRddByArrayscala").setMaster("local")val sc = new SparkContext(conf)var path = "D:\\hello.txt"//path = hdfs://bigdata01:9000/test/hello.txtvar rdd =sc.textFile(path,minPartitions = 2)//获取每一行数据的长度,计算文件内数据的总长度val length = rdd.map(_.length).reduce(_+_)println(length);sc.stop() }
}
** Spark中对RDD的操作**
Spark对RDD的操作可以整体分为两类:Transformation和Action
Transformation可以翻译为转换,表示是针对RDD中数据的转换操作,主要会针对已有的RDD创建一个新的RDD:常见的有map、flatMap、filter等等.
Action可以翻译为执行,表示是触发任务执行的操作,主要对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并且还可以把结果返回给Driver程序.
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子
其中Transformation算子有一个特性:** lazy **
lazy特性在这里指的是,如果一个spark任务中只定义了transformation算子,那么即使你执行这个任务,任务中的算子也不会执行.
只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。
Spark通过lazy这种特性,来进行底层的spark任务执行的优化,避免产生过多中间结果。
Action的特性:执行Action操作才会触发一个Spark 任务的运行,从而触发这个Action之前所有的Transformation的执行
算子 介绍
map 将RDD中的每个元素进行处理,一进一出
filter 对RDD中每个元素进行判断,返回true则保留
flatMap 与map类似,但是每个元素都可以返回一个或多个新元素
groupByKey 根据key进行分组,每个key对应一个Iterable<value>
reduceByKey 对每个相同key对应的value进行reduce操作
sortByKey 对每个相同key对应的value进行排序操作(全局排序)
join 对两个包含<key,value>对的RDD进行join操作
distinct 对RDD中的元素进行全局去重
Transformation操作开发实战
- map:对集合中每个元素乘以2
- filter:过滤出集合中的偶数
- flatMap:将行拆分为单词
- groupByKey:对每个大区的主播进行分组
- reduceByKey:统计每个大区的主播数量
- sortByKey:对主播的音浪收入排序
- join:打印每个主播的大区信息和音浪收入
- distinct:统计当天开播的大区信息
scala代码如下:
object TransformationOpScala {def main(args: Array[String]): Unit = {val sc= getSparkContextgroupByKeyOp(sc)}//flatMap:将行拆分为单词def flatMapOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(" good good study","day day up"))dataRdd.flatMap(_.split(" ")).foreach(println(_))}//groupbyKey 对每个大区主播进行分组def groupByKeyOp(sc: SparkContext): Unit = {val dataRdd =sc.parallelize(Array((150001,"us"),(1500002,"CN"),(150003,"CN"),(1500004,"IN")))//需要使用map对tuple中的数据位置进行互换,因为需要把大区作为key进行分组操作dataRdd.map(tup=>(tup._2,tup._1)).groupByKey().foreach(tup=>{//获取大区val area=tup._1println(area+":")//获取同一个大区对应的所有用户idval it = tup._2for(uid <- it){println(uid+" ")}println()})}//filter:过滤出集合中的偶数def filterOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))dataRdd.filter(_ %2 ==0).foreach(println(_))}
//map:对集合中每个元素乘以2def mapOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))dataRdd.map(_ * 2).foreach(println(_))}private def getSparkContext = {val conf = new SparkConf()conf.setAppName("CreateRddByArrayscala").setMaster("local")new SparkContext(conf)}
}
常用Action介绍
算子 介绍
reduce 将RDD中的所有元素进行聚合操作
collect 将RDD中所有元素获取到本地客户端(Driver)
count 获取RDD中元素总数
take(n) 获取RDD中前n个元素
saveAsTextFile 将RDD中元素保存到文件中,对每个元素调用toString
countByKey 对每个key对应的值进行count计数
foreach 遍历RDD中的每个元素
scala代码:
object ActionOpScala {def main(args: Array[String]): Unit = {val sc =getSparkContext//reduce聚合计算//reduceOp(sc)//collect:获取元素集合//colletOp(sc)// count:获取元素总数//countOp(sc)//saveAsTextFile:保存文件//saveAsTextFileOp(sc)//countByKey:统计相同的key出现多少次//countByKeyOp(sc)//foreach:迭代遍历元素foreachOp(sc)sc.stop()}//foreach:迭代遍历元素def foreachOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))dataRdd.foreach(println(_))}//countByKey:统计相同的key出现多少次def countByKeyOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(("A",1001),("B",1002),("A",1003),("C",1004)))val res = dataRdd.countByKey()for((k,v) <- res){println(k+","+v)}}//saveAsTextFile:保存文件def saveAsTextFileOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))dataRdd.saveAsTextFile("hdfs://bigdata01:9000/out001")}
// count:获取元素总数def countOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))val res = dataRdd.count()println(res)}//collect:获取元素集合def colletOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))//collect 返回的是一个Array数组val res = dataRdd.collect()for(item <- res){println(item)}}
//reduce聚合计算def reduceOp(sc: SparkContext): Unit = {val dataRdd = sc.parallelize(Array(1,2,3,4,5))val num = dataRdd.reduce(_ + _)println(num)}private def getSparkContext = {val conf = new SparkConf()conf.setAppName("CreateRddByArrayscala").setMaster("local")new SparkContext(conf)}
}
相关文章:

Spark开发
第一步:创建RDD Spark提供三种创建RDD方式:** 集合、本地文件、HDFS文件** 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造一些测试数据,来测试后面的spark应…...

Tornado异步框架
简介: tornado是Python的web框架。tornado和主流的web服务器框架有明显的区别:它是非阻塞式服务器,而且速度非常快,得力于其非阻塞的方式和epoll的运用tornado可以每秒处理数以千计的连接(号称) 基本配置 …...

openpnp - error - 吸嘴没下降到板子上, 就将元件松开
文章目录openpnp - error - 吸嘴没下降到板子上, 就将元件松开概述笔记ENDopenpnp - error - 吸嘴没下降到板子上, 就将元件松开 概述 以前用过国内一家openpnp厂家出的设备, 他们家的openpnp是自己改过的. 贴片流程已经走过一遍. 这次还是按照以前记录的笔记, 按照国内那家的…...

【Java】yyyy-MM-dd HH:mm:ss 时间格式 时间戳 全面解读超详细
时间格式 时间格式(协议)描述gg时期或纪元。y不包含纪元的年份。不具有前导零。yy不包含纪元的年份。具有前导零。yyyy包含纪元的四位数的年份。M月份数字。一位数的月份没有前导零。MM月份数字。一位数的月份有一个前导零。MMM月份的缩写名称,在AbbreviatedMonthN…...

快鲸SCRM发布口腔企业私域运营解决方案
口腔企业普遍面临着以下几方面运营痛点问题 1、获客成本居高不下,恶性竞争严重 2、管理系统落后,人员流失严重 3、客户顾虑多、决策时间长 4、老客户易流失,粘性差 以上这些痛点,不得不倒逼口腔企业向精细化运营客户迈进。 …...
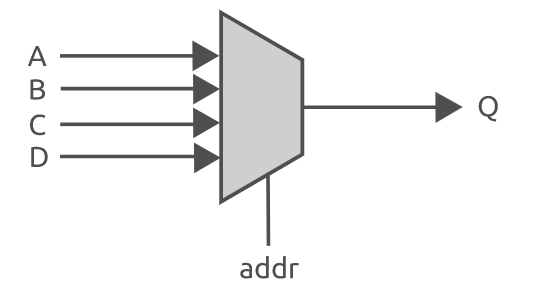
Verilog实现组合逻辑电路
在verilog 中可以实现的数字电路主要分为两类----组合逻辑电路和时序逻辑电路。组合逻辑电路比较简单,仅由基本逻辑门组成---如与门、或门和非门等。当电路的输入发生变化时,输出几乎(信号在电路中传递时会有一小段延迟)立即就发生…...

2023前端菜鸟笔试血泪史html5-one--找到工作前都更新
1.说说对html语义化的理解 什么的HTML语义化,顾名思义,HTML语义化就是可以不通过了解HTML的内容,就可以知道这个部分所代表的的意义。 HTML语义化的意义:在使用HTML标签构建页面时,避免大篇幅的使用无语义的标签。 …...
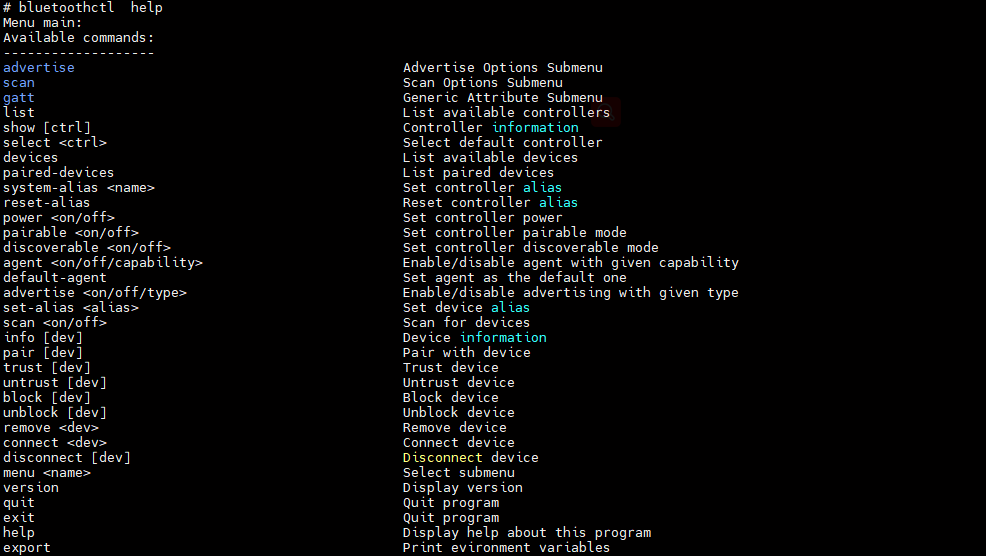
蓝牙调试工具集合汇总
BLE 该部分主要分享一下常用的蓝牙调试工具,方便后续蓝牙抓包及分析。 目录 1 hciconfig 2 hcitool 3 hcidump 4 hciattach 5 btmon 6 bluetoothd 7 bluetoothctl 1 hciconfig 工具介绍:hciconfig,HCI 设备配置工具 命令格式&…...

Java 获取文件后缀名【一文总结所有方法】
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
UML常见图的总结
一、概述 UML:Unified Modeling Language,统一建模语言,支持从需求分析开始的软件开发的全过程。是一个支持模型化和软件系统开发的图形化语言、为软件开发的所有阶段提供模型化和可视化支持,包括由需求分析到规格,到…...

WebRTC系列-工具系列之音频相关工具
文章目录 1. audio_util数据格式转换类2. WavFile文件读写类2.1 读取wav文件2.2 写入wav文件这篇文章主要介绍WebRTC中一些音频工具这些,大部分都在 common_audio目录下,这个文件夹下提供音频的大量算法,包括sinc重采样算法,音频数据格式的转换:例如 float转int16_t格式等…...
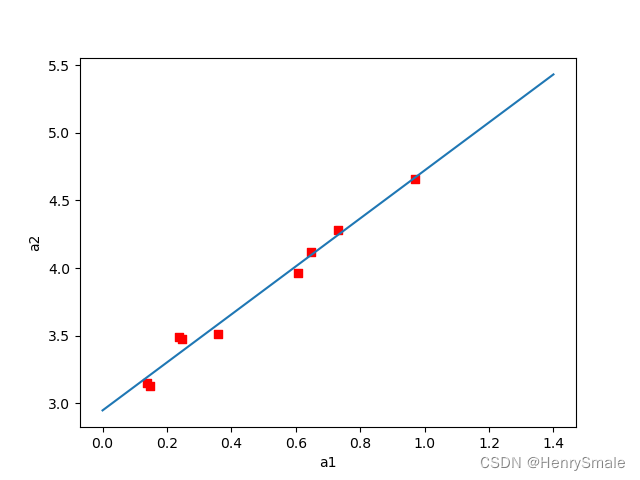
7 线性回归及Python实现
1 统计指标 随机变量XXX的理论平均值称为期望: μE(X)\mu E(X)μE(X)但现实中通常不知道μ\muμ, 因此使用已知样本来获取均值 X‾1n∑i1nXi.\overline{X} \frac{1}{n} \sum_{i 1}^n X_i. Xn1i1∑nXi.方差variance定义为: σ2E(∣X−μ∣2).\sigma^2 E(|…...

适合小团队协作、任务管理、计划和进度跟踪的项目任务管理工具有哪些?
适合小团队协作、任务管理、计划和进度跟踪的项目任务管理工具有哪些? 大家可以参考这个模板:http://s.fanruan.com/irhj8管理项目归根结底在管理人、物,扩展来说便是: 人:员工能力、组织机制; 物:项目内…...

从100%进口到自主可控,从600块降到10块,中科院攻克重要芯片
前言 2月28日,“20多位中科院专家把芯片价格打到10块”冲上微博热搜,据河南省官媒大象新闻报道,热搜中提到的中科院专家所在企业为全球最大的PLC分路器芯片制造商仕佳光子,坐落于河南鹤壁。 为实现芯片技术自主可控自立自强&#…...

关于git的一些基本点总结
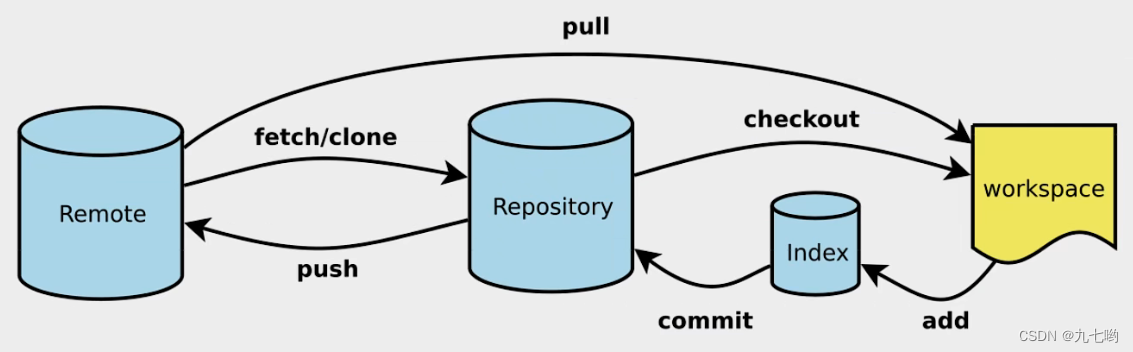
1.什么是git? git是一个常用的分布式版本管理工具。 2.git 的常用命令: clone(克隆): 从远程仓库中克隆代码到本地仓库 checkout (检出):从本地仓库中检出一个仓库分支然后进行修订 add(添加): 在提交前…...
PyTorch保姆级安装教程
1 安装CUDA1.1 查找Nvidia适用的CUDA版本桌面右键,【打开 NVIDIA控制面板】查看【系统信息】查看NVIDIA的支持的CUDA的版本,下图可知支持的版本是 10.11.2 下载CUDACUDA下载官方网址https://developer.nvidia.com/cuda-toolkit-archive找到适合的版本下载…...
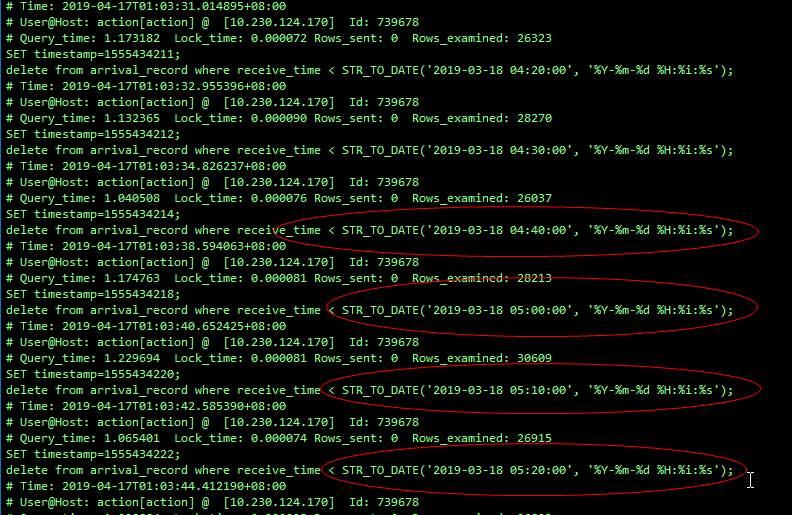
MySQL 上亿大表如何优化?
背景XX 实例(一主一从)xxx 告警中每天凌晨在报 SLA 报警,该报警的意思是存在一定的主从延迟。(若在此时发生主从切换,需要长时间才可以完成切换,要追延迟来保证主从数据的一致性)XX 实例的慢查询…...
Git(狂神课堂笔记)
1.首先去git官网下载我们对应的版本Git - Downloading Package (git-scm.com) 2.安装后我们会发现git文件夹里有三个应用程序: Git Bash:Unix与Linux风格的命令行,使用最多,推荐最多 Git CMD:Windows风格的命令行 G…...

「2」指针进阶,最详细指针和数组难题解题思路
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练 🔥座右铭:“不要等到什么都没有了,才下定决心去做” 🚀🚀🚀大家觉不错…...

云服务器是做什么的?云服务器典型的应用场景介绍
云服务器可能是很多企业以及个人上云用户的必选产品了,但是对于初学者或者非专业的用户来说云服务器还是比较陌生的,它到底是干什么的,如此生活中哪些地方可以接触到,这篇文章将详细的介绍云服务器使用的应用场景以及相关的操作 本…...

PPTist:零基础打造专业级在线演示文稿的完整指南
PPTist:零基础打造专业级在线演示文稿的完整指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the…...

【求职】衡量你职场流通性的,从来不是你的能力
衡量你职场流通性的,从来不是你的能力先问你一个问题。 你上一次被猎头主动联系,是什么时候? 如果你需要认真回忆,那这篇文章,你需要认真读完。一、"流通性"是个被严重低估的职场变量 大多数人谈职业发展&am…...

Pearcleaner:彻底清理Mac应用残留文件的开源解决方案
Pearcleaner:彻底清理Mac应用残留文件的开源解决方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经在Mac上删除应用后,发…...
)
别再傻傻分不清L2和L3了!一张图看懂自动驾驶分级(附SAE/国标对照表)
自动驾驶分级全解析:从L0到L5的技术演进与商业应用 当特斯拉车主开启Autopilot功能在高速公路上行驶,或是蔚来汽车宣传其NOP领航辅助时,这些究竟属于什么级别的自动驾驶?为什么有些厂商称自己的系统为"L2.999"ÿ…...

离线绘图新选择:draw.io桌面版,让敏感数据不再“上网”
离线绘图新选择:draw.io桌面版,让敏感数据不再“上网” 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 你是否曾因为网络不稳定而无法绘制重要的流程图&…...
)
SpringBoot 2.7项目里,用Knife4j 4.3.0给API文档换个‘高级脸’(OpenAPI3实战)
SpringBoot 2.7项目里,用Knife4j 4.3.0给API文档换个‘高级脸’(OpenAPI3实战) 当你的SpringBoot项目已经完成了基础的API文档集成,接下来要思考的是如何让这份文档从"能用"变成"好用且好看"。Knife4j作为Swa…...
一键Root)
保姆级教程:红米K70澎湃OS解锁BL后,如何用Delta面具(德尔塔面具)一键Root
红米K70澎湃OS深度Root指南:Delta面具全流程实战解析 在安卓玩机圈里,Root始终是释放设备潜力的终极钥匙。对于手持红米K70并已解锁Bootloader的进阶用户而言,Delta面具(Magisk Delta)无疑是当前最安全、最稳定的Root解…...

玩具可以多,父母的专心陪伴也千万别少
现在的孩子不缺玩具。很多家庭的客厅里,积木、遥控车、电动狗堆得满满当当。孩子坐在地上,周围一圈都是玩具,但他玩不了多久就扔下这个拿起那个,嘴里还喊着“妈妈你看我”。这个时候他需要的可能不是新玩具,而是你放下…...

Tunasync镜像同步工具:清华大学TUNA团队的高效解决方案
Tunasync镜像同步工具:清华大学TUNA团队的高效解决方案 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync是清华大学TUNA团队开发的一款专业镜像同步管理工具,为开源社区提…...

ADAU1701 DSP资源极限探索:从31段EQ到内存溢出,手把手教你做性能压力测试
ADAU1701 DSP资源极限探索:从31段EQ到内存溢出的性能压力测试方法论 在音频处理领域,ADAU1701作为一款经典的DSP芯片,其资源分配与性能边界一直是开发者关注的焦点。当客户提出"能否实现90段EQ"这类需求时,仅凭数据手册…...