Spark与Hadoop的关系和区别
在大数据领域,Spark和Hadoop是两个备受欢迎的分布式数据处理框架,它们在处理大规模数据时都具有重要作用。本文将深入探讨Spark与Hadoop之间的关系和区别,以帮助大家的功能和用途。
Spark和Hadoop简介
1 Hadoop
Hadoop是一个由Apache基金会维护的开源分布式数据处理框架。它包括两个核心组件:
- Hadoop分布式文件系统(HDFS):用于存储大规模数据的分布式文件系统。
- Hadoop MapReduce:用于分布式数据处理的编程模型和框架。
Hadoop最初是为批处理任务设计的,适用于对大规模数据进行批处理分析。
2 Spark
Spark也是一个由Apache基金会维护的开源分布式数据处理框架,但它提供了比Hadoop更多的灵活性和性能。Spark的核心特点包括:
- 基于内存的计算:Spark将数据存储在内存中,因此可以更快地处理数据。
- 多种API:Spark支持多种编程语言(如Scala、Java、Python)和API(如RDD、DataFrame、Streaming等)。
- 支持交互式查询:Spark允许用户在数据上运行SQL查询和实时流式处理。
Spark与Hadoop的关系
Spark与Hadoop之间存在密切的关系,事实上,Spark可以与Hadoop生态系统无缝集成。下面是一些Spark与Hadoop之间的关系:
1 Spark运行在Hadoop上
Spark可以运行在Hadoop集群之上,并与Hadoop的HDFS集成。这意味着可以使用Hadoop集群来存储和管理大规模数据,然后使用Spark来执行更高效的数据处理任务。
以下是一个使用Spark读取HDFS上的数据的示例代码:
from pyspark import SparkContextsc = SparkContext("local", "HDFS Example")
hdfs_path = "hdfs://<HDFS_MASTER>:<HDFS_PORT>/path/to/your/data"
data = sc.textFile(hdfs_path)
2 Spark与Hive、HBase等整合
Spark可以与Hive(用于数据仓库)和HBase(用于NoSQL存储)等Hadoop生态系统中的其他工具无缝集成。这可以在Spark中查询Hive表或与HBase进行交互,以实现更复杂的数据处理需求。
以下是一个使用Spark连接Hive并查询数据的示例代码:
from pyspark.sql import SparkSessionspark = SparkSession.builder \.appName("Hive Integration") \.config("spark.sql.warehouse.dir", "/user/hive/warehouse") \.enableHiveSupport() \.getOrCreate()result = spark.sql("SELECT * FROM my_hive_table")
3 Spark取代了Hadoop MapReduce
尽管Spark可以与Hadoop MapReduce共存,但在很多情况下,Spark已经取代了Hadoop MapReduce作为首选的数据处理引擎。Spark的内存计算和多API支持使其更适用于各种处理需求,而且性能更好。
以下是一个使用Spark来执行Word Count任务的示例代码,与传统的Hadoop MapReduce代码进行对比:
from pyspark import SparkContextsc = SparkContext("local", "Word Count")
text_file = sc.textFile("hdfs://<HDFS_MASTER>:<HDFS_PORT>/path/to/your/textfile.txt")
word_counts = text_file.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a + b)
word_counts.saveAsTextFile("hdfs://<HDFS_MASTER>:<HDFS_PORT>/path/to/your/output")
Spark与Hadoop的区别
虽然Spark与Hadoop有许多关系,但它们之间也存在一些重要的区别:
1 计算模型
- Hadoop使用批处理的MapReduce计算模型,适用于离线数据分析任务。
- Spark支持批处理、交互式查询、流式处理和机器学习等多种计算模型,更加灵活。
2 数据处理速度
- Spark使用内存计算,因此通常比Hadoop MapReduce更快。
- Hadoop MapReduce对于大规模离线批处理任务仍然是一个强大的选择。
3 编程接口
- Hadoop MapReduce需要编写更多的样板代码,相对较复杂。
- Spark提供多种编程语言和API,更容易上手。
Spark与Hadoop的适用场景
了解Spark与Hadoop的关系和区别后,还需要,以便更好地决定何时使用哪个框架。
1 使用Spark的场景
- 迭代算法:对于需要多次迭代的算法,如机器学习和图处理,Spark的内存计算特性可以显著提高性能。
- 实时数据处理:Spark Streaming和Structured Streaming支持实时数据处理,适用于需要快速响应数据的应用。
- 复杂数据流处理:如果需要进行复杂的数据流处理,例如窗口操作、状态管理和事件时间处理,Spark提供了强大的工具。
- 多种数据源:Spark支持多种数据源,包括HDFS、Kafka、Cassandra等,使其适用于多样化的数据存储和处理需求。
- 交互式查询:Spark SQL允许用户在数据上运行SQL查询,适用于需要交互式分析的场景。
2 使用Hadoop的场景
- 大规模批处理:如果有大规模的离线批处理任务,Hadoop MapReduce可能仍然是不错的选择。
- 成本敏感性:Hadoop通常在硬件成本较低的环境中运行,适用于对硬件资源敏感的情况。
- 稳定性与成熟性:Hadoop经过多年的发展和测试,被广泛认为是一个稳定和成熟的大数据框架。
- 整合Hive和HBase:如果已经在生产环境中使用Hive或HBase,那么Hadoop可能是更自然的选择,因为它们与Hadoop生态系统更紧密集成。
示例应用场景
为了更好地说明Spark和Hadoop的使用场景,以下是两个示例应用场景:
示例一:实时广告点击分析
假设正在构建一个广告点击分析平台,需要实时处理海量点击数据并生成实时报告。在这种情况下,Spark是更合适的选择,因为它支持实时数据处理,能够快速处理大量的事件流,并且具有易于使用的API。可以使用Spark Streaming或Structured Streaming来处理实时数据,并使用Spark SQL来查询和分析数据,最终生成实时报告。
示例二:离线批处理数据清洗
假设需要定期对大规模数据进行离线批处理数据清洗,以准备数据用于机器学习模型的训练。在这种情况下,Hadoop MapReduce可能是更合适的选择,因为它可以在廉价硬件上运行,并且适用于离线批处理任务。可以将数据存储在HDFS上,然后使用Hadoop MapReduce作业来清洗和准备数据。
总结
Spark与Hadoop都是强大的大数据处理框架,它们在大数据领域扮演着不同但重要的角色。了解它们之间的关系和区别以及适用场景对于在项目中做出正确的决策至关重要。根据具体需求和项目特点,可以灵活地选择使用Spark、Hadoop,或者两者的组合,以最大程度地发挥它们的优势。
无论选择哪个框架,都应该深入学习其文档和示例,以充分了解其功能和用法。大数据处理领域变化迅速,不断出现新的工具和技术,因此持续学习和更新知识是至关重要的。
相关文章:
Spark与Hadoop的关系和区别
在大数据领域,Spark和Hadoop是两个备受欢迎的分布式数据处理框架,它们在处理大规模数据时都具有重要作用。本文将深入探讨Spark与Hadoop之间的关系和区别,以帮助大家的功能和用途。 Spark和Hadoop简介 1 Hadoop Hadoop是一个由Apache基金会…...
蓝桥杯-Excel地址[Java]
目录: 学习目标: 学习内容: 学习时间: 题目: 题目描述: 输入描述: 输出描述: 输入输出样例: 示例 1: 运行限制: 题解: 思路: 学习目标: 刷蓝桥杯题库日记 学习内容: 编号96题目Ex…...

OSPF多区域配置-新版(12)
目录 整体拓扑 操作步骤 1.基本配置 1.1 配置R1的IP 1.2 配置R2的IP 1.3 配置R3的IP 1.4 配置R4的IP 1.5 配置R5的IP 1.6 配置R6的IP 1.7 配置PC-1的IP地址 1.8 配置PC-2的IP地址 1.9 配置PC-3的IP地址 1.10 配置PC-4的IP地址 1.11 检测R5与PC1连通性 1.12 检测…...
华为---USG6000V防火墙web基本配置示例
目录 1. 实验要求 2. 配置思路 3. 网络拓扑图 4. USG6000V防火墙端口和各终端相关配置 5. 在USG6000V防火墙web管理界面创建区域和添加相应端口 6. 给USG6000V防火墙端口配置IP地址 7. 配置通行策略 8. 测试验证 8.1 逐个删除策略,再看各区域终端通信情况 …...
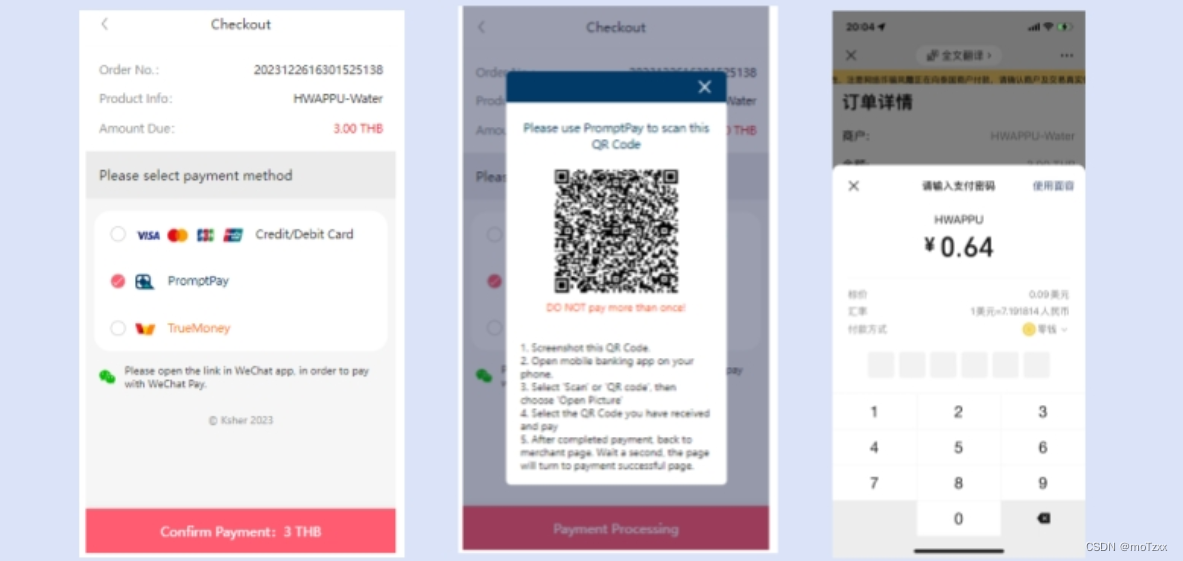
Ksher H5页面支付实例指导 (PHP实现)
背景 前两天,公司的项目,为了满足泰国客户的支付需求,要求使用 Ksher (开时支付) 对接任务突然就给了鄙人,一脸懵 … 通过了解客户的使用场景、以及参考官网指导 发现:Ksher支付最令人满意的便是 —— 提供了便捷的 支…...
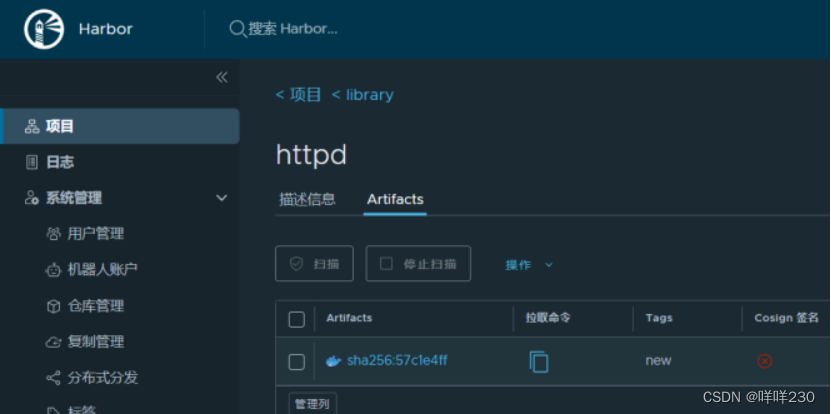
https密钥认证、上传镜像实验
一、第一台主机通过https密钥对认证 1、安装docker服务 (1)安装环境依赖包 yum -y install yum-utils device-mapper-persistent-data lvm2 (2)设置阿里云镜像源 yum-config-manager --add-repo http://mirrors.aliyun.com/do…...

three.js使用精灵模型Sprite渲染森林
效果: 源码: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div><div class"box-right&quo…...
什么是数据可视化?数据可视化的流程与步骤
前言 数据可视化将大大小小的数据集转化为更容易被人脑理解和处理的视觉效果。可视化在我们的日常生活中非常普遍,但它们通常以众所周知的图表和图形的形式出现。正确的数据可视化以有意义和直观的方式为复杂的数据集提供关键的见解。 数据可视化定义 数据可视化…...

2022年山东省职业院校技能大赛高职组云计算赛项试卷第二场-容器云
2022年山东省职业院校技能大赛高职组云计算赛项试卷 目录 【赛程名称】云计算赛项第二场-容器云 需要竞赛软件包以及资料可以私信博主! 【赛程名称】云计算赛项第二场-容器云 【赛程时间】2022-11-27 09:00:00至2022-11-27 16:00:00 说明:完成本任务…...

Unity3D 中播放 RTSP 监控视频
【Unity 3D】怎么在 WebGL 中低延迟播放 RTSP 监控 - 简书[Unity 3D] 开箱即食的头部监控厂商 SDK 集成框架 - 简书 Unity3d Windows播放视频(视频流)功能组/插件支持对比_ffmpeg for unity-CSDN博客Unity UMP打包黑屏问题总结-CSDN博客Unity Universal…...

[spark] DataFrame 的 checkpoint
在 Apache Spark 中,DataFrame 的 checkpoint 方法用于强制执行一个物理计划并将结果缓存到分布式文件系统,以防止在计算过程中临时数据丢失。这对于长时间运行的计算过程或复杂的转换操作是有用的。 具体来说,checkpoint 方法执行以下操作&…...

flask文件夹列表改进版--Bug追踪
把当前文件夹下的所有文件夹和文件列出来,允许点击返回上层目录,允许点击文件夹进入下级目录并显示此文件夹内容 允许点击文件进行下载 from flask import Flask, render_template, send_file, request, redirect, url_for import osapp Flask(__name_…...

Elasticsearch之常用DSL语句
目录 1. Elasticsearch之常用DSL语句 1.1 操作索引 1.2 文档操作 1.3 DSL查询 1.4 搜索结果处理 1.5 数据聚合 1. Elasticsearch之常用DSL语句 1.1 操作索引 mapping是对索引库中文档的约束,常见的mapping属性包括: - type:字段数据类…...
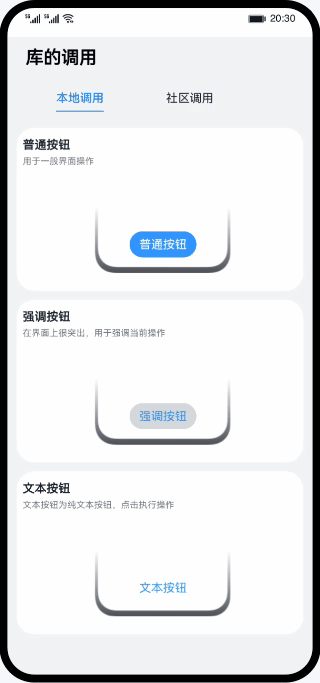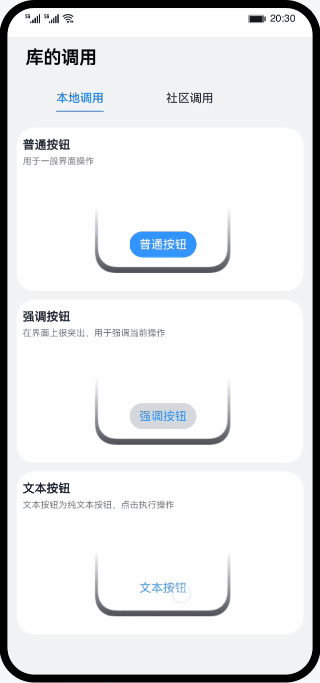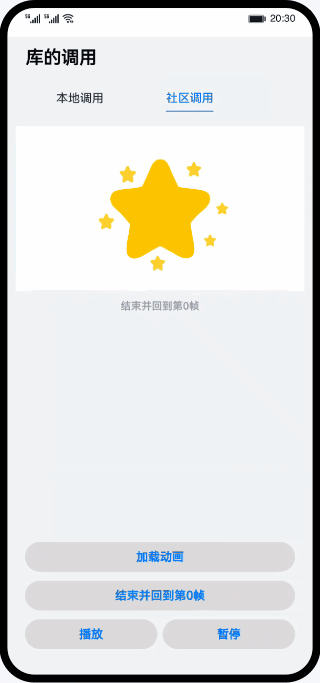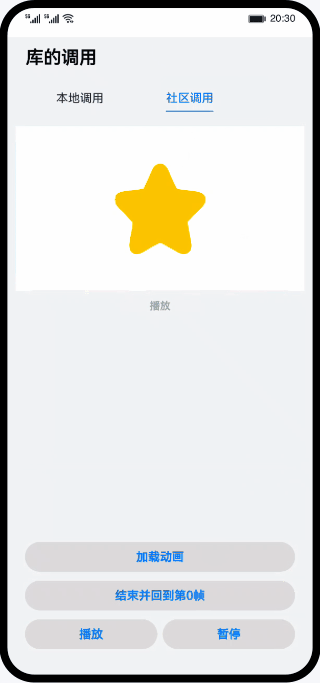
鸿蒙实战-库的调用(ArkTS)
整体框架搭建 主页面、本地库组件页面、社区库组件页面三个页面组成,主页面由Navigation作为根组件实现全局标题,由Tabs组件实现本地库和社区库页面的切换。 // MainPage.ets import { Outer } from ../view/OuterComponent; import { Inner } from ..…...

观察者模式学习
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的: Define a one-to-many dependency between objects so th…...

人工智能_机器学习078_聚类算法_概念介绍_聚类升维_降维_各类聚类算法_有监督机器学习_无监督机器学习---人工智能工作笔记0118
首先看一下什么是聚类,我们可以进入sklearn的官网去看看 可以看到这里,首先classification 这个分类我们学完了,然后就是regression回归我们也学完了对吧,其实我们现实生活中的,大部分问题就是 这两种问题就可以解决了. 然后我们再来看一个: clustering,这个就是聚类对吧.聚类算…...
基于AR+地图导航的景区智慧导览设计
随着科技的飞速发展,智慧旅游已经成为现代旅游业的一个重要趋势。在这个背景下,景区智慧导览作为智慧旅游的核心组成部分,正逐渐受到越来越多游客的青睐。本文将深入探讨地图导航软件在景区智慧导览中的应用,并分析其为游客和景区…...

git基本指令
下载代码 git clone http://.......设置分支 git checkout 分支名查询当前分支 git checkout打开终端或命令行窗口,进入你要操作的项目目录,执行以下命令,列出所有的分支,这会列出当前代码仓库中的所有分支,用带星号…...

ECMAScript基础入门
ECMAScript(简称ES)是一种标准化了的高级编程语言,它是JavaScript语言的标准化版本,由Ecma International组织发布。ECMAScript描述了JavaScript的语法和核心特性,而JavaScript是实现ECMAScript标准的编程语言。随着We…...

神经网络介绍
目录 知识点介绍 知识点介绍 前馈神经网络:(前馈网络的数据只向一个方向传播) RNN循环神经网络,下图中多个 RNN 层都是“同一个层”,这一点与之前的神经网络是不一样的。...

AzurLaneAutoScript深度解析:如何构建智能化的碧蓝航线自动化解决方案
AzurLaneAutoScript深度解析:如何构建智能化的碧蓝航线自动化解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript…...

软考高项案例分析14:项目配置、变更管理
软考高项案例分析14:项目配置、变更管理 一、配置管理 1. 配置管理活动有哪些 制订配置管理计划 配置项识别 配置项控制 配置状态报告 配置审计 配置管理回顾与改进 2. 基线配置项和非基线配置项 基线配置项:包含所有的设计文档和源程序; 非基线配置项:包括项目的…...

RT-DETRv2训练自定义数据集的排坑全记录
RT-DETRv2训练自定义数据集的排坑全记录 最近在使用lyuwenyu/RT-DETR的PyTorch版本训练自定义缺陷检测数据集,从启动报错到成功训练,踩了不少典型的“新手坑”,这里把完整的排坑过程和解决方案整理出来,帮大家一次性避坑ÿ…...

利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题 对于依赖Claude Code进行日常开发的工程师而言,服…...

ARMv8 A64内存拷贝指令CPYFPRTWN详解与优化
1. A64内存拷贝指令概述 在ARMv8架构中,内存拷贝操作是系统编程和底层优化的基础功能。CPYF*系列指令作为A64指令集的重要组成部分,提供了硬件级的内存数据搬运能力。与传统的软件循环拷贝相比,这些指令具有显著的性能优势: 单指…...

Python开发者快速上手,十分钟完成Taotoken API第一个聊天调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者快速上手,十分钟完成Taotoken API第一个聊天调用 对于希望快速体验不同大语言模型能力的Python开发者来说…...

如何突破Switch游戏限制:Ryujinx开源模拟器的5大实战解决方案
如何突破Switch游戏限制:Ryujinx开源模拟器的5大实战解决方案 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否渴望在PC上畅玩Switch独占游戏,却受限于硬件…...

KMS_VL_ALL_AIO:一键激活Windows与Office的完整解决方案
KMS_VL_ALL_AIO:一键激活Windows与Office的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经为Windows或Office的激活问题而烦恼?每次重装系统后都…...

利用Taotoken CLI工具一键配置团队开发环境中的大模型调用参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken CLI工具一键配置团队开发环境中的大模型调用参数 在团队开发环境中,统一管理大模型调用参数是一个常见痛…...

长期使用Taotoken Token Plan套餐在项目开发中的成本优势体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐在项目开发中的成本优势体会 在项目开发中,尤其是涉及大模型API调用的场景࿰…...