Elasticsearch之常用DSL语句
目录
1. Elasticsearch之常用DSL语句
1.1 操作索引
1.2 文档操作
1.3 DSL查询
1.4 搜索结果处理
1.5 数据聚合
1. Elasticsearch之常用DSL语句
1.1 操作索引
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
创建索引
PUT /goods
{"mappings": {"properties": {"brandName": {"type": "keyword"},"categoryName": {"type": "keyword"},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"id": {"type": "keyword"},"price": {"type": "double"},"saleNum": {"type": "integer"},"status": {"type": "integer"},"stock": {"type": "integer"},"title": {"type": "text","analyzer": "ik_max_word",}}}
}查询索引
GET /goods修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}删除索引库
DELETE /goods1.2 文档操作
新增文档
POST /goods/_doc/1
{"id": 1,"brandName": "Apple","categoryName": "手机","createTime": "2023-12-26 20:00:00","price": 8000,"saleNum": 100,"status": 0,"stock": 100,"title": "Apple iPhone 15 Pro 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机"
}POST /goods/_doc/2
{"id": 2,"brandName": "Huawei","categoryName": "手机","createTime": "2023-12-26 20:00:00","price": 7000,"saleNum": 400,"status": 0,"stock": 200,"title": "华为 HUAWEI Mate 60 Pro 智能手机 鸿蒙系统卫星通话昆仑玻璃"
}查询文档
GET /goods/_doc/1//批量获取
GET goods/_doc/_mget
{"ids":["1","2"]
}
删除文档
DELETE /goods/_doc/1修改文档
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
增量修改是只修改指定id匹配的文档中的部分字段。
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}1.3 DSL查询
查询所有
GET /goods/_search
{"query": {"match_all": {}}
}全文检索
//单字段查询
GET /goods/_search
{"query": {"match": {"title": "手机"}}
}//多字段查询
GET /goods/_search
{"query": {"multi_match": {"query": "手机","fields": ["title"]}}
}精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
term查询的字段是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
GET /goods/_search
{"query": {"term": {"categoryName": {"value": "手机"}}}
}//匹配多个term
GET /goods/_search
{"query": {"terms": {"categoryName": ["手机","电脑"]}}
}范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
GET /goods/_search
{"query": {"range": {"price": {"gte": 7500,"lte": 9000}}}
}复合查询
- must:必须匹配的条件,可以理解为“与”
- should:选择性匹配的条件,可以理解为“或”
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
POST goods/_search
{"query": {"bool": {"must": [{"term": {"brandName": {"value": "Apple"}}}],"should": [{"term": {"categoryName": {"value": "手机"}}}],"filter": [{"range": {"stock": {"gt": 0}}}]}}
}1.4 搜索结果处理
普通字段排序
GET /goods/_search
{"query": {"match_all": {}},"sort": [{"stock": "desc" //asc升序}]
}分页
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
GET /goods/_search
{"query": {"match_all": {}},"from": 0,"size": 1
}高亮显示
POST goods/_search
{"query": {"match": {"title": "手机"}},"highlight": {"fields": {"title": {"pre_tags": ["<font color='red'>"],"post_tags": ["</font>"]}}}
}1.5 数据聚合
聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做聚合
统计所有数据中的品牌有几种,按照品牌对数据分组。
GET /goods/_search
{"size": 0, //设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brandName", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}对于每个品牌的聚合限定聚合范围,并且根据Bucket内的文档数量进行升序排序
GET /goods/_search
{"query": {"range": {"stock": {"gte": 10}}}, "size": 0, //设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brandName", // 参与聚合的字段"size": 20, // 希望获取的聚合结果数量"order": {"_count": "asc"}}}}
}按照品牌分组,形成了一个个桶。对桶内的数据做运算,获取每个品牌的stock的min、max、avg等值。
GET /goods/_search
{"query": {"range": {"stock": {"gte": 10}}}, "size": 0, "aggs": { "brandAgg": {"terms": {"field": "brandName", "size": 20, "order": {"_count": "asc"}},"aggs": {"stock_status": {"stats": {"field": "stock"}}}}}
}相关文章:

Elasticsearch之常用DSL语句
目录 1. Elasticsearch之常用DSL语句 1.1 操作索引 1.2 文档操作 1.3 DSL查询 1.4 搜索结果处理 1.5 数据聚合 1. Elasticsearch之常用DSL语句 1.1 操作索引 mapping是对索引库中文档的约束,常见的mapping属性包括: - type:字段数据类…...
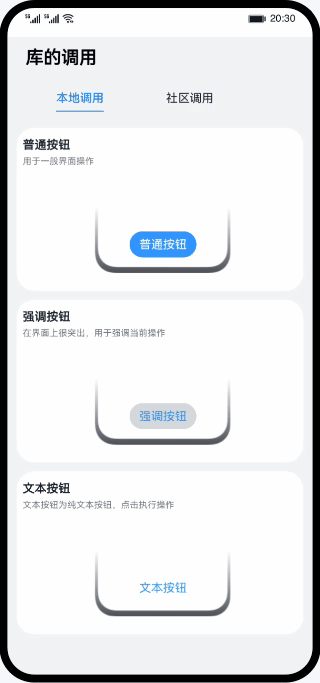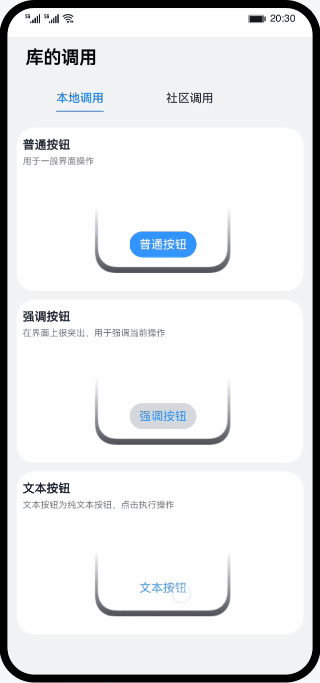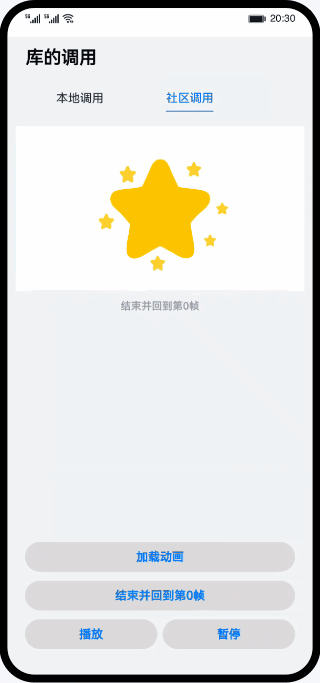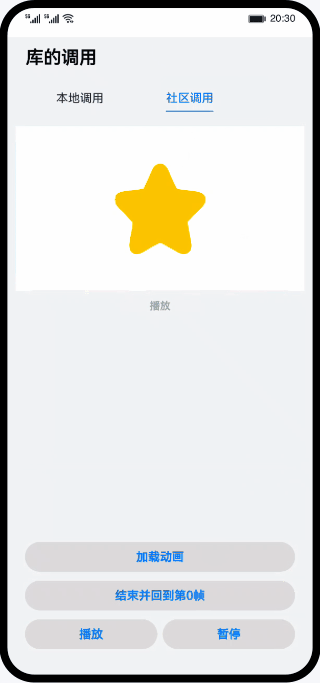
鸿蒙实战-库的调用(ArkTS)
整体框架搭建 主页面、本地库组件页面、社区库组件页面三个页面组成,主页面由Navigation作为根组件实现全局标题,由Tabs组件实现本地库和社区库页面的切换。 // MainPage.ets import { Outer } from ../view/OuterComponent; import { Inner } from ..…...

观察者模式学习
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的: Define a one-to-many dependency between objects so th…...

人工智能_机器学习078_聚类算法_概念介绍_聚类升维_降维_各类聚类算法_有监督机器学习_无监督机器学习---人工智能工作笔记0118
首先看一下什么是聚类,我们可以进入sklearn的官网去看看 可以看到这里,首先classification 这个分类我们学完了,然后就是regression回归我们也学完了对吧,其实我们现实生活中的,大部分问题就是 这两种问题就可以解决了. 然后我们再来看一个: clustering,这个就是聚类对吧.聚类算…...
基于AR+地图导航的景区智慧导览设计
随着科技的飞速发展,智慧旅游已经成为现代旅游业的一个重要趋势。在这个背景下,景区智慧导览作为智慧旅游的核心组成部分,正逐渐受到越来越多游客的青睐。本文将深入探讨地图导航软件在景区智慧导览中的应用,并分析其为游客和景区…...

git基本指令
下载代码 git clone http://.......设置分支 git checkout 分支名查询当前分支 git checkout打开终端或命令行窗口,进入你要操作的项目目录,执行以下命令,列出所有的分支,这会列出当前代码仓库中的所有分支,用带星号…...

ECMAScript基础入门
ECMAScript(简称ES)是一种标准化了的高级编程语言,它是JavaScript语言的标准化版本,由Ecma International组织发布。ECMAScript描述了JavaScript的语法和核心特性,而JavaScript是实现ECMAScript标准的编程语言。随着We…...

神经网络介绍
目录 知识点介绍 知识点介绍 前馈神经网络:(前馈网络的数据只向一个方向传播) RNN循环神经网络,下图中多个 RNN 层都是“同一个层”,这一点与之前的神经网络是不一样的。...

CPU亲和性和NUMA架构
何为CPU的亲和性 CPU的亲和性,进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性,进程迁移的频率小就意味着产生的负载小。亲和性一词是从affinity翻译来的,实际可以称为CPU绑定。 在多核运行的机器上,…...

目标检测-Two Stage-Fast RCNN
文章目录 前言一、Fast RCNN的网络结构和流程二、Fast RCNN的创新点1.特征提取分类回归合一2.更快的训练策略 总结 前言 前文目标检测-Two Stage-SPP Net中提到SPP Net的主要缺点是: 分开训练多个模型困难且复杂尽管比RCNN快10-100倍,但仍然很慢SPP Ne…...

vol----随记!!!
目录 一、代码生成1.先新建一个功能的对应的代码配置各项解释: 2.后设置配置菜单3.再点保存,生成vue页面,生成model,生成业务类4.再通过菜单设置编写系统菜单 一、代码生成 1.先新建一个功能的对应的代码配置 各项解释ÿ…...

vue中样式动态绑定写法
绑定样式: class样式 写法:class"xxx"xXX可以是字符串、对象、数组。 字符串写法适用于:类名不确定,要动态获取。 对象写法适用于:要绑定多个样式,个数不确定,名字也不确定。 数组写法适用于:要绑定多个样式,个数确定,…...
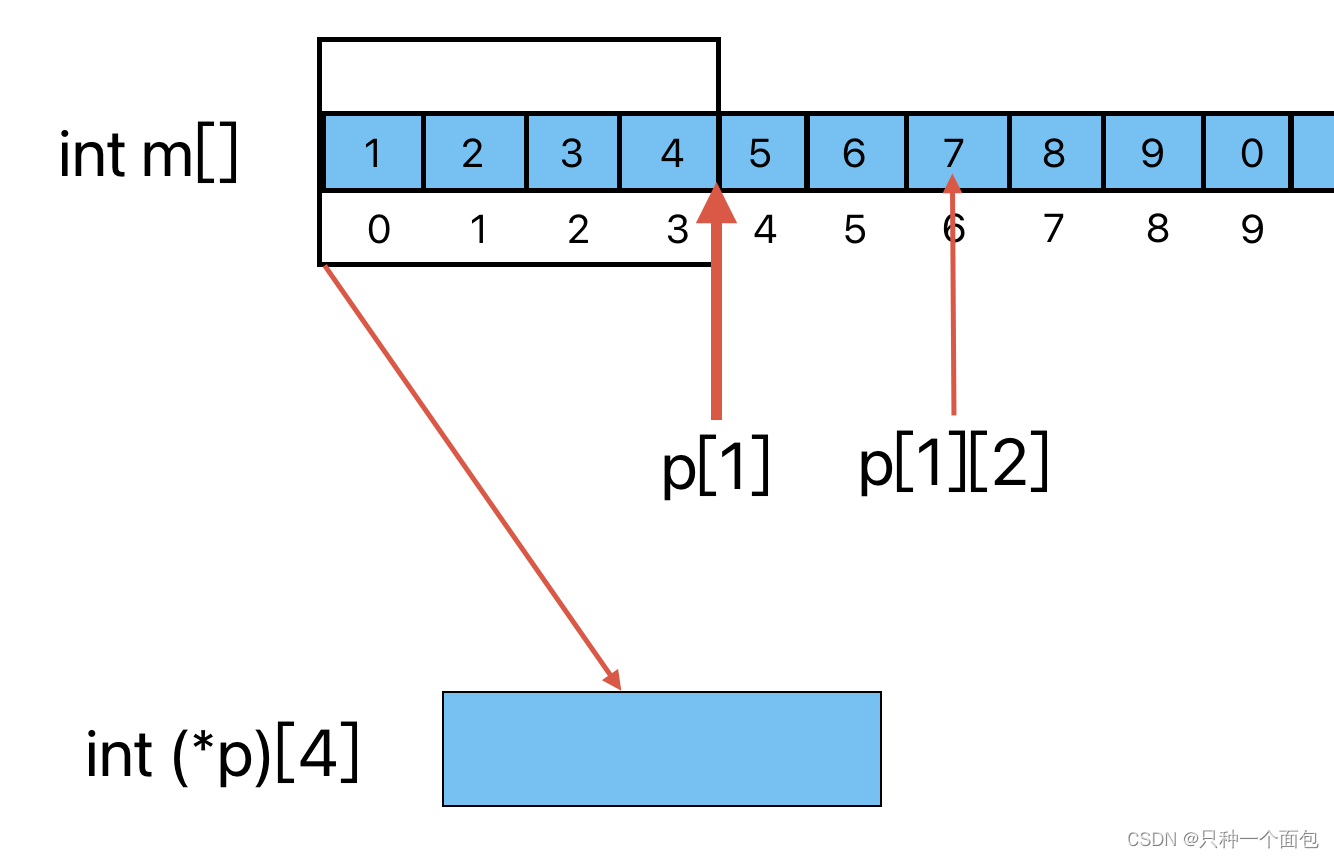
C语言—每日选择题—Day63
指针相关博客 打响指针的第一枪:指针家族-CSDN博客 深入理解:指针变量的解引用 与 加法运算-CSDN博客 第一题 1. 设C语言中,一个int型数据在内存中占2个字节,则unsigned int型数据的取值范围为 A:0~255 B:0…...

Mac_通过chmod处理文件权限
chmod 简介 chmod 是一个 Unix 和类 Unix 系统中的命令,用于更改文件或目录的权限。chmod 的名称来源于 “change mode”,它允许用户修改文件或目录的读取(read)、写入(write)和执行(execute&a…...

实战指南:使用 Spring Cloud Stream 集成 Kafka 构建高效消息驱动微服务
实战指南:使用 Spring Cloud Stream 集成 Kafka 构建高效消息驱动微服务 视频地址: Stream为什么被引入-尚硅谷SCS-1-内容介绍-图灵诸葛 官方文档: Spring Cloud Stream 什么是 Spring Cloud Stream? Spring Cloud Stream(SCS) 是一个用于构…...

线性代数基础【3】向量
第一节 向量的概念与运算 一、基本概念 ①向量 ②向量的模(长度) ③向量的单位化 ④向量的三则运算 ⑤向量的内积 二、向量运算的性质 (一)向量三则运算的性质 α β β αα (β γ) (α β) γk (α β) kα kβ(k l) α kα lα (二)向量内积运…...

Spring Boot + MinIO 实现文件切片极速上传技术
文章目录 1. 引言2. 文件切片上传简介3. 技术选型3.1 Spring Boot3.2 MinIO 4. 搭建Spring Boot项目5. 集成MinIO5.1 配置MinIO连接信息5.2 MinIO配置类 6. 文件切片上传实现6.1 控制器层6.2 服务层6.3 文件切片上传逻辑 7. 文件合并逻辑8. 页面展示9. 性能优化与拓展9.1 性能优…...

uniapp中如何使用image图片
当在UniApp中使用图片时,可以通过<image>标签将图片显示在页面上。这个标签可以指定src属性来引用图片,并且可以通过mode属性来设置图片的显示模式。除此之外,还可以利用click事件来实现图片的点击事件。在编写代码时,要注意…...

docker-compose 安装gitlab
写在前面的话:docker-compose的文件是通用的,因此可以切换任意版本的gitlab的镜像版本。 往期docker-compose部署系列如: docker-compose语法格式docker-compose部署openldapdocker-compose 安装Sonar并集成gitlab 文章目录 1. 参考文档2. 环…...
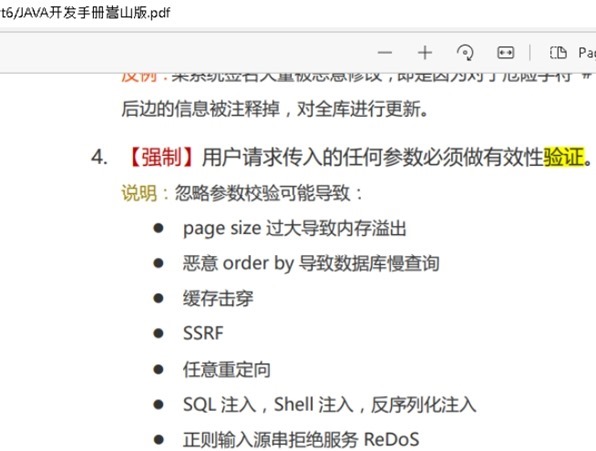
到底是前端验证还是后端验证
背景 软件应用研发中, 前端验证还是后端验证这是意识与认知问题。鉴于某些入门同学还不清楚,我们再来看下: 一. 从软件行业来自国外 Q: 前端验证和后端验证都是对同一个数据的验证,有什么区别? A: 二者的目的不同&…...
)
Midjourney大画幅风格实战手册(从失效黑边到完美展陈:2023全球TOP 50商业项目验证的7大避坑节点)
更多请点击: https://kaifayun.com 第一章:Midjourney大画幅风格的本质解构与视觉范式跃迁 大画幅风格并非单纯指图像物理尺寸的放大,而是Midjourney通过隐式参数空间重构所催生的一种高密度视觉语义范式——它融合了胶片颗粒质感、景深压缩…...
)
别再手动复制文件了!Mathtype 7.4 一键配置脚本,搞定Office和WPS(附常见错误修复)
数学公式编辑神器Mathtype 7.4全自动部署方案:告别手动配置的繁琐时代 在科研论文、技术文档撰写过程中,数学公式的编辑效率直接影响工作进度。Mathtype作为专业数学公式编辑工具,其强大功能常被手动配置的复杂步骤所掩盖。传统方法需要用户反…...
)
算法高频难题——链表环检测(快慢指针核心实现)
链表操作是算法面试的重中之重,而“检测链表中是否存在环”更是高频考题,字节、阿里等大厂面试中多次出现,热度稳居算法类难题TOP3。很多开发者会陷入“遍历存节点”的误区,导致空间复杂度过高,无法通过面试优化要求。…...

万用表档位介绍与测量
万用表档位介绍与测量一:万用表档位介绍二:表笔的连接三:电阻测量(Ω)四:电流测量注意事项:1、测电流一定是串联,绝对不能直接把表笔搭在电源两极!一搭就烧表、炸保险。2…...

.9017R 座充充电管理 IC
概述 .9017R 是恒流/恒压座充充电管理芯片,主要应用于单节锂电池充电。应用电路无需外接检测电阻,其内部为MOSFET 结构,因此也无需外接反向二极管。 .9017R 在大功率和高环境温度下可以自动调节充电电流以限制芯片温度。它的充电电压固定在4.…...

ComfyUI插件革命:如何用AI字幕生成器彻底改变你的图片描述体验
ComfyUI插件革命:如何用AI字幕生成器彻底改变你的图片描述体验 【免费下载链接】ComfyUI_SLK_joy_caption_two ComfyUI Node 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_SLK_joy_caption_two 你是否曾经为了一张图片绞尽脑汁却写不出合适的描述&a…...

为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式
为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式 【免费下载链接】ZeroOmega Manage and switch between multiple proxies quickly & easily. 项目地址: https://gitcode.com/gh_mirrors/ze/ZeroOmega 在现代网络环境中,频繁切换代理…...

Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案
Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案 【免费下载链接】Tidal-Media-Downloader Download TIDAL Music On Windows/Linux/MacOs (PYTHON/C#) 项目地址: https://gitcode.com/gh_mirrors/ti/Tidal-Media-Downloader 还在为无法随时随地畅享…...

Chrome-Charset:3步彻底解决网页乱码问题,告别天书般的浏览体验![特殊字符]
Chrome-Charset:3步彻底解决网页乱码问题,告别天书般的浏览体验!🚀 【免费下载链接】Chrome-Charset An extension used to modify the page default encoding for Chromium 55 based browsers. 项目地址: https://gitcode.com/…...

大学生选择网络工程,后期就业方向有哪些?
每年高考填志愿那阵子,总有学弟学妹跑来问:"网络工程这个专业怎么样?毕业了好找工作吗?"说实话,这个问题不太好回答。不是方向少,而是方向太多,而且每个方向的天花板和薪资差距不小。 我当年也是稀里糊涂选的网络工程,入学才知道跟计算机科学不是一回事。但…...