LSTM的记忆能力实验
长短期记忆网络(Long Short-Term Memory Network,LSTM)是一种可以有效缓解长程依赖问题的循环神经网络.LSTM 的特点是引入了一个新的内部状态(Internal State) 和门控机制(Gating Mechanism).不同时刻的内部状态以近似线性的方式进行传递,从而缓解梯度消失或梯度爆炸问题.同时门控机制进行信息筛选,可以有效地增加记忆能力.例如,输入门可以让网络忽略无关紧要的输入信息,遗忘门可以使得网络保留有用的历史信息.在上一节的数字求和任务中,如果模型能够记住前两个非零数字,同时忽略掉一些不重要的干扰信息,那么即时序列很长,模型也有效地进行预测.
LSTM 模型在第 t 步时,循环单元的内部结构如图6.10所示.

图6.10 LSTM网络的循环单元结构
提醒:为了和代码的实现保存一致性,这里使用形状为 (样本数量 × 序列长度 × 特征维度) 的张量来表示一组样本.
6.3.1 模型构建
在本实验中,我们将使用第6.1.2.4节中定义Model_RNN4SeqClass模型,并构建 LSTM 算子.只需要实例化 LSTM 算,并传入Model_RNN4SeqClass模型,就可以用 LSTM 进行数字求和实验
6.3.1.1 LSTM层
LSTM层的代码与SRN层结构相似,只是在SRN层的基础上增加了内部状态、输入门、遗忘门和输出门的定义和计算。这里LSTM层的输出也依然为序列的最后一个位置的隐状态向量。代码实现如下:
import torch import torch.nn.functional as F from torch import nn# 声明LSTM和相关参数 class LSTM(nn.Module):def __init__(self, input_size, hidden_size, Wi_attr=None, Wf_attr=None, Wo_attr=None, Wc_attr=None,Ui_attr=None, Uf_attr=None, Uo_attr=None, Uc_attr=None, bi_attr=None, bf_attr=None,bo_attr=None, bc_attr=None):super(LSTM, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeW_i = torch.randn([input_size, hidden_size])W_f = torch.randn([input_size, hidden_size])W_o = torch.randn([input_size, hidden_size])W_c = torch.randn([input_size, hidden_size])U_i = torch.randn([hidden_size, hidden_size])U_f = torch.randn([hidden_size, hidden_size])U_o = torch.randn([hidden_size, hidden_size])U_c = torch.randn([hidden_size, hidden_size])b_i = torch.randn([1, hidden_size])b_f = torch.randn([1, hidden_size])b_o = torch.randn([1, hidden_size])b_c = torch.randn([1, hidden_size])self.W_i = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(W_i, dtype=torch.float32), gain=1.0))# 初始化模型参数self.W_f = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(W_f, dtype=torch.float32), gain=1.0))self.W_o = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(W_o, dtype=torch.float32), gain=1.0))self.W_c = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(W_c, dtype=torch.float32), gain=1.0))self.U_i = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(U_i, dtype=torch.float32), gain=1.0))self.U_f = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(U_f, dtype=torch.float32), gain=1.0))self.U_o = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(U_o, dtype=torch.float32), gain=1.0))self.U_c = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(U_c, dtype=torch.float32), gain=1.0))self.b_i = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(b_i, dtype=torch.float32), gain=1.0))self.b_f = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(b_f, dtype=torch.float32), gain=1.0))self.b_o = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(b_o, dtype=torch.float32), gain=1.0))self.b_c = torch.nn.Parameter(torch.nn.init.xavier_uniform_(torch.as_tensor(b_c, dtype=torch.float32), gain=1.0))# 初始化状态向量和隐状态向量def init_state(self, batch_size):hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)return hidden_state, cell_state# 定义前向计算def forward(self, inputs, states=None):# inputs: 输入数据,其shape为batch_size x seq_len x input_sizebatch_size, seq_len, input_size = inputs.shape# 初始化起始的单元状态和隐状态向量,其shape为batch_size x hidden_sizeif states is None:states = self.init_state(batch_size)hidden_state, cell_state = states# 执行LSTM计算,包括:输入门、遗忘门和输出门、候选内部状态、内部状态和隐状态向量for step in range(seq_len):# 获取当前时刻的输入数据step_input: 其shape为batch_size x input_sizestep_input = inputs[:, step, :]# 计算输入门, 遗忘门和输出门, 其shape为:batch_size x hidden_sizeI_gate = F.sigmoid(torch.matmul(step_input, self.W_i) + torch.matmul(hidden_state, self.U_i) + self.b_i)F_gate = F.sigmoid(torch.matmul(step_input, self.W_f) + torch.matmul(hidden_state, self.U_f) + self.b_f)O_gate = F.sigmoid(torch.matmul(step_input, self.W_o) + torch.matmul(hidden_state, self.U_o) + self.b_o)# 计算候选状态向量, 其shape为:batch_size x hidden_sizeC_tilde = F.tanh(torch.matmul(step_input, self.W_c) + torch.matmul(hidden_state, self.U_c) + self.b_c)# 计算单元状态向量, 其shape为:batch_size x hidden_sizecell_state = F_gate * cell_state + I_gate * C_tilde# 计算隐状态向量,其shape为:batch_size x hidden_sizehidden_state = O_gate * F.tanh(cell_state)return hidden_stateWi_attr = torch.tensor([[0.1, 0.2], [0.1, 0.2]]) Wf_attr = torch.tensor([[0.1, 0.2], [0.1, 0.2]]) Wo_attr = torch.tensor([[0.1, 0.2], [0.1, 0.2]]) Wc_attr = torch.tensor([[0.1, 0.2], [0.1, 0.2]]) Ui_attr = torch.tensor([[0.0, 0.1], [0.1, 0.0]]) Uf_attr = torch.tensor([[0.0, 0.1], [0.1, 0.0]]) Uo_attr = torch.tensor([[0.0, 0.1], [0.1, 0.0]]) Uc_attr = torch.tensor([[0.0, 0.1], [0.1, 0.0]]) bi_attr = torch.tensor([[0.1, 0.1]]) bf_attr = torch.tensor([[0.1, 0.1]]) bo_attr = torch.tensor([[0.1, 0.1]]) bc_attr = torch.tensor([[0.1, 0.1]])lstm = LSTM(2, 2, Wi_attr=Wi_attr, Wf_attr=Wf_attr, Wo_attr=Wo_attr, Wc_attr=Wc_attr,Ui_attr=Ui_attr, Uf_attr=Uf_attr, Uo_attr=Uo_attr, Uc_attr=Uc_attr,bi_attr=bi_attr, bf_attr=bf_attr, bo_attr=bo_attr, bc_attr=bc_attr)inputs = torch.tensor([[[1, 0]]], dtype=torch.float32) hidden_state = lstm(inputs) print(hidden_state)


这里我们可以将自己实现的SRN和Paddle框架内置的SRN返回的结果进行打印展示,实现代码如下。
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size batch_size, seq_len, input_size = 8, 20, 32 inputs = torch.randn(size=[batch_size, seq_len, input_size])# 设置模型的hidden_size hidden_size = 32 torch_lstm = nn.LSTM(input_size, hidden_size) self_lstm = LSTM(input_size, hidden_size)self_hidden_state = self_lstm(inputs) torch_outputs, (torch_hidden_state, torch_cell_state) = torch_lstm(inputs)print("self_lstm hidden_state: ", self_hidden_state.shape) print("torch_lstm outpus:", torch_outputs.shape) print("torch_lstm hidden_state:", torch_hidden_state.shape) print("torch_lstm cell_state:", torch_cell_state.shape)

可以看到,自己实现的LSTM由于没有考虑多层因素,因此没有层次这个维度,因此其输出shape为[8, 32]。同时由于在以上代码使用Paddle内置API实例化LSTM时,默认定义的是1层的单向SRN,因此其shape为[1, 8, 32],同时隐状态向量为[8,20, 32].
接下来,我们可以将自己实现的LSTM与Paddle内置的LSTM在输出值的精度上进行对比 ,在进行实验时,首先定义输入数据inputs,然后将该数据分别传入Paddle内置的LSTM与自己实现的LSTM模型中,最后通过对比两者的隐状态输出向量。
import torchtorch.manual_seed(0)# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size batch_size, seq_len, input_size, hidden_size = 2, 5, 10, 10 inputs = torch.randn(size=[batch_size, seq_len, input_size])# 设置模型的hidden_size bih_attr = torch.nn.Parameter(torch.zeros([4 * hidden_size, ])) paddle_lstm = nn.LSTM(input_size, hidden_size) paddle_lstm.bias_ih_l0 = bih_attr paddle_lstm.bias_ih_l1 = bih_attr paddle_lstm.bias_ih_l2 = bih_attr paddle_lstm.bias_ih_l3 = bih_attr paddle_lstm.bias_ih_l4 = bih_attr# 获取paddle_lstm中的参数,并设置相应的paramAttr,用于初始化lstm print(paddle_lstm.weight_ih_l0.T.shape) chunked_W = torch.split(paddle_lstm.weight_ih_l0.T, split_size_or_sections=10, dim=-1) chunked_U = torch.split(paddle_lstm.weight_hh_l0.T, split_size_or_sections=10, dim=-1) chunked_b = torch.split(paddle_lstm.bias_hh_l0.T, split_size_or_sections=10, dim=-1) print(chunked_b[0].shape, chunked_b[1].shape, chunked_b[2].shape) Wi_attr = torch.tensor(chunked_W[0]) Wf_attr = torch.tensor(chunked_W[1]) Wc_attr = torch.tensor(chunked_W[2]) Wo_attr = torch.tensor(chunked_W[3]) Ui_attr = torch.tensor(chunked_U[0]) Uf_attr = torch.tensor(chunked_U[1]) Uc_attr = torch.tensor(chunked_U[2]) Uo_attr = torch.tensor(chunked_U[3]) bi_attr = torch.tensor(chunked_b[0]) bf_attr = torch.tensor(chunked_b[1]) bc_attr = torch.tensor(chunked_b[2]) bo_attr = torch.tensor(chunked_b[3]) self_lstm = LSTM(input_size, hidden_size, Wi_attr=Wi_attr, Wf_attr=Wf_attr, Wo_attr=Wo_attr, Wc_attr=Wc_attr,Ui_attr=Ui_attr, Uf_attr=Uf_attr, Uo_attr=Uo_attr, Uc_attr=Uc_attr,bi_attr=bi_attr, bf_attr=bf_attr, bo_attr=bo_attr, bc_attr=bc_attr)# 进行前向计算,获取隐状态向量,并打印展示 self_hidden_state = self_lstm(inputs) paddle_outputs, (paddle_hidden_state, _) = paddle_lstm(inputs) print("paddle SRN:\n", paddle_hidden_state.detach().numpy().squeeze(0)) print("self SRN:\n", self_hidden_state.detach().numpy())

可以看到,两者的输出基本是一致的。另外,还可以进行对比两者在运算速度方面的差异。代码实现如下:
import time# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size batch_size, seq_len, input_size = 8, 20, 32 inputs = torch.randn(size=[batch_size, seq_len, input_size])# 设置模型的hidden_size hidden_size = 32 self_lstm = LSTM(input_size, hidden_size) paddle_lstm = nn.LSTM(input_size, hidden_size)# 计算自己实现的SRN运算速度 model_time = 0 for i in range(100):strat_time = time.time()hidden_state = self_lstm(inputs)# 预热10次运算,不计入最终速度统计if i < 10:continueend_time = time.time()model_time += (end_time - strat_time) avg_model_time = model_time / 90 print('self_lstm speed:', avg_model_time, 's')# 计算Paddle内置的SRN运算速度 model_time = 0 for i in range(100):strat_time = time.time()outputs, (hidden_state, cell_state) = paddle_lstm(inputs)# 预热10次运算,不计入最终速度统计if i < 10:continueend_time = time.time()model_time += (end_time - strat_time) avg_model_time = model_time / 90 print('paddle_lstm speed:', avg_model_time, 's')
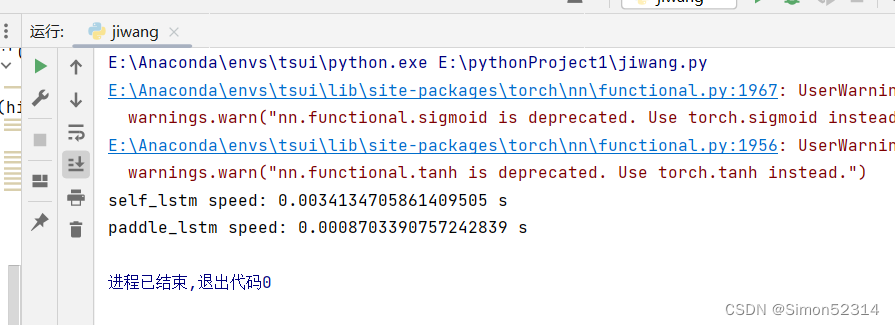
可以看到,由于Paddle框架的LSTM底层采用了C++实现并进行优化,Paddle框架内置的LSTM运行效率远远高于自己实现的LSTM。
6.3.1.2 模型汇总
在本节实验中,我们将使用6.1.2.4的Model_RNN4SeqClass作为预测模型,不同在于在实例化时将传入实例化的LSTM层。
动手联系6.2 在我们手动实现的LSTM算子中,是逐步计算每个时刻的隐状态。请思考如何实现更加高效的LSTM算子。
6.3.2 模型训练
6.3.2.1 训练指定长度的数字预测模型
本节将基于RunnerV3类进行训练,首先定义模型训练的超参数,并保证和简单循环网络的超参数一致. 然后定义一个train函数,其可以通过指定长度的数据集,并进行训练. 在train函数中,首先加载长度为length的数据,然后实例化各项组件并创建对应的Runner,然后训练该Runner。同时在本节将使用4.5.4节定义的准确度(Accuracy)作为评估指标,代码实现如下:
import os import random import numpy as np from nndl4.runner import RunnerV3# 训练轮次 num_epochs = 500 # 学习率 lr = 0.001 # 输入数字的类别数 num_digits = 10 # 将数字映射为向量的维度 input_size = 32 # 隐状态向量的维度 hidden_size = 32 # 预测数字的类别数 num_classes = 19 # 批大小 batch_size = 8 # 模型保存目录 save_dir = "./checkpoints"from torch.utils.data import Dataset,DataLoader import torch class DigitSumDataset(Dataset):def __init__(self, data):self.data = datadef __getitem__(self, idx):example = self.data[idx]seq = torch.tensor(example[0], dtype=torch.int64)label = torch.tensor(example[1], dtype=torch.int64)return seq, labeldef __len__(self):return len(self.data) class Embedding(nn.Module):def __init__(self, num_embeddings, embedding_dim):super(Embedding, self).__init__()self.W = nn.init.xavier_uniform_(torch.empty(num_embeddings, embedding_dim),gain=1.0)def forward(self, inputs):# 根据索引获取对应词向量embs = self.W[inputs]return embs# emb_layer = Embedding(10, 5) # inputs = torch.tensor([0, 1, 2, 3]) # emb_layer(inputs)# 基于RNN实现数字预测的模型 class Model_RNN4SeqClass(nn.Module):def __init__(self, model, num_digits, input_size, hidden_size, num_classes):super(Model_RNN4SeqClass, self).__init__()# 传入实例化的RNN层,例如SRNself.rnn_model = model# 词典大小self.num_digits = num_digits# 嵌入向量的维度self.input_size = input_size# 定义Embedding层self.embedding = Embedding(num_digits, input_size)# 定义线性层self.linear = nn.Linear(hidden_size, num_classes)def forward(self, inputs):# 将数字序列映射为相应向量inputs_emb = self.embedding(inputs)# 调用RNN模型hidden_state = self.rnn_model(inputs_emb)# 使用最后一个时刻的状态进行数字预测logits = self.linear(hidden_state)return logits # 可以设置不同的length进行不同长度数据的预测实验 def train(length):print(f"\n====> Training LSTM with data of length {length}.")np.random.seed(0)random.seed(0)# 加载长度为length的数据data_path = f"./datasets/{length}"train_examples, dev_examples, test_examples = load_data(data_path)train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples), DigitSumDataset(test_examples)train_loader = DataLoader(train_set, batch_size=batch_size)dev_loader = DataLoader(dev_set, batch_size=batch_size)test_loader = DataLoader(test_set, batch_size=batch_size)# 实例化模型base_model = LSTM(input_size, hidden_size)model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)# 指定优化器optimizer = torch.optim.Adam(lr=lr, params=model.parameters())# 定义评价指标metric = Accuracy()# 定义损失函数loss_fn = torch.nn.CrossEntropyLoss()# 基于以上组件,实例化Runnerrunner = RunnerV3(model, optimizer, loss_fn, metric)# 进行模型训练model_save_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=100, save_path=model_save_path)return runner
6.3.2.2 多组训练
接下来,分别进行数据长度为10, 15, 20, 25, 30, 35的数字预测模型训练实验,训练后的runner保存至runners字典中。
import os import random import torch import numpy as np# 训练轮次 num_epochs = 500 # 学习率 lr = 0.001 # 输入数字的类别数 num_digits = 10 # 将数字映射为向量的维度 input_size = 32 # 隐状态向量的维度 hidden_size = 32 # 预测数字的类别数 num_classes = 19 # 批大小 batch_size = 8 # 模型保存目录 save_dir = "./checkpoints"# 可以设置不同的length进行不同长度数据的预测实验 def train(length):print(f"\n====> Training LSTM with data of length {length}.")np.random.seed(0)random.seed(0)# 加载长度为length的数据data_path = f"./datasets/{length}"train_examples, dev_examples, test_examples = load_data(data_path)train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples), DigitSumDataset(test_examples)train_loader = DataLoader(train_set, batch_size=batch_size)dev_loader = DataLoader(dev_set, batch_size=batch_size)test_loader = DataLoader(test_set, batch_size=batch_size)# 实例化模型base_model = LSTM(input_size, hidden_size)model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes) # 指定优化器optimizer = torch.optim.Adam(lr=lr, params=model.parameters())# 定义评价指标metric = Accuracy()# 定义损失函数loss_fn = torch.nn.CrossEntropyLoss()# 基于以上组件,实例化Runnerrunner = RunnerV3(model, optimizer, loss_fn, metric)# 进行模型训练model_save_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=100, save_path=model_save_path)return runner



其中 load_data(data_path) 函数与之前的函数有差别,修改后为
# 加载数据 def load_data(data_path):# 加载训练集train_examples = []train_path = os.path.join(data_path, "train.txt")with open(train_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])train_examples.append((seq, label))# 加载验证集dev_examples = []dev_path = os.path.join(data_path, "dev.txt")with open(dev_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])dev_examples.append((seq, label))# 加载测试集test_examples = []test_path = os.path.join(data_path, "test.txt")with open(test_path, "r", encoding="utf-8") as f:for line in f.readlines():# 解析一行数据,将其处理为数字序列seq和标签labelitems = line.strip().split("\t")seq = [int(i) for i in items[0].split(" ")]label = int(items[1])test_examples.append((seq, label))return train_examples, dev_examples, test_examples
6.3.2.3 损失曲线展示
分别画出基于LSTM的各个长度的数字预测模型训练过程中,在训练集和验证集上的损失曲线,代码实现如下:
# 画出训练过程中的损失图 for length in lengths:runner = lstm_runners[length]fig_name = f"./images/6.11_{length}.pdf"plot_training_loss(runner, fig_name, sample_step=100)
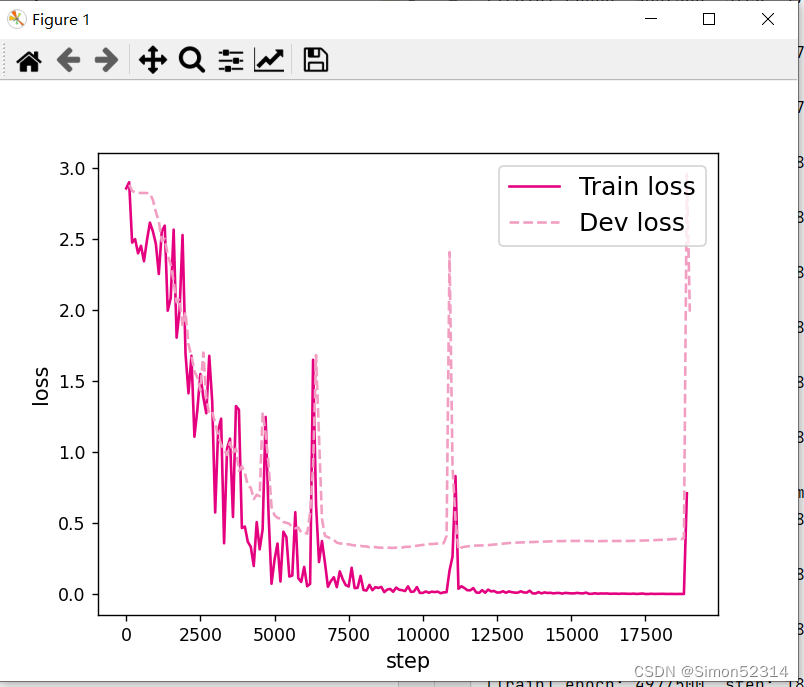

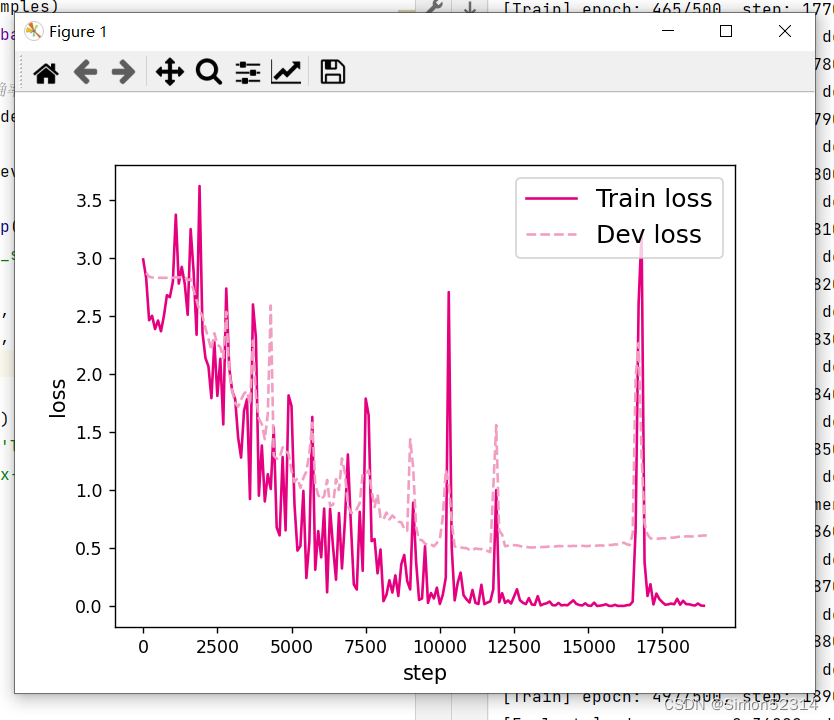
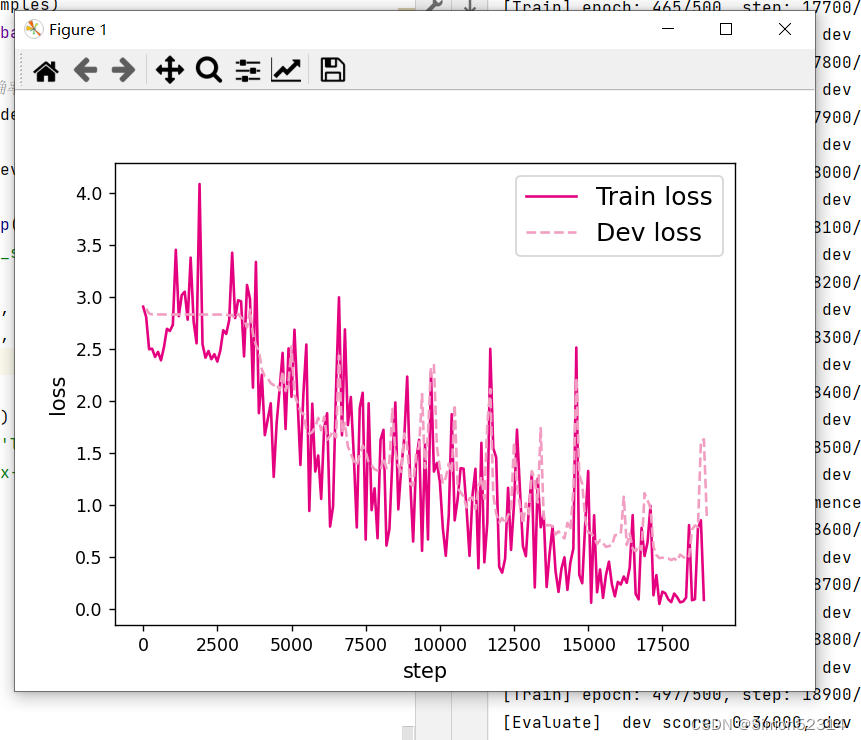
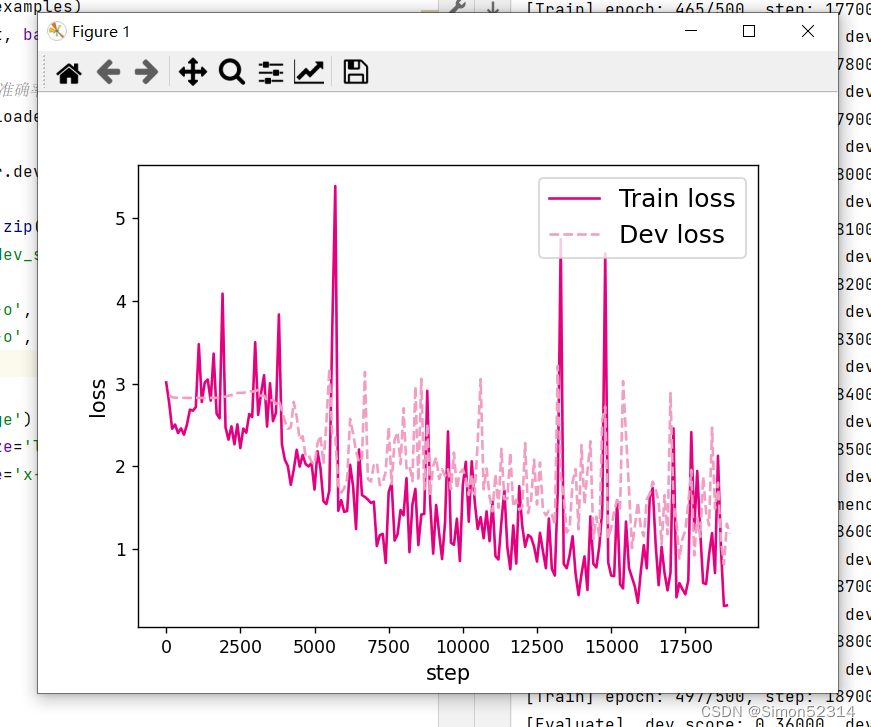

同SRN模型一样,随着序列长度的增加,训练集上的损失逐渐不稳定,验证集上的损失整体趋向于变大,这说明当序列长度增加时,保持长期依赖的能力同样在逐渐变弱. 同RNN的图相比,LSTM模型在序列长度增加时,收敛情况比SRN模型更好。
6.3.3 模型评价
6.3.3.1 在测试集上进行模型评价
使用测试数据对在训练过程中保存的最好模型进行评价,观察模型在测试集上的准确率. 同时获取模型在训练过程中在验证集上最好的准确率,实现代码如下:
lstm_dev_scores = [] lstm_test_scores = [] for length in lengths:print(f"Evaluate LSTM with data length {length}.")runner = lstm_runners[length]# 加载训练过程中效果最好的模型model_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")runner.load_model(model_path)# 加载长度为length的数据data_path = f"./datasets/{length}"train_examples, dev_examples, test_examples = load_data(data_path)test_set = DigitSumDataset(test_examples)test_loader = DataLoader(test_set, batch_size=batch_size)# 使用测试集评价模型,获取测试集上的预测准确率score, _ = runner.evaluate(test_loader)lstm_test_scores.append(score)lstm_dev_scores.append(max(runner.dev_scores))for length, dev_score, test_score in zip(lengths, lstm_dev_scores, lstm_test_scores):print(f"[LSTM] length:{length}, dev_score: {dev_score}, test_score: {test_score: .5f}")
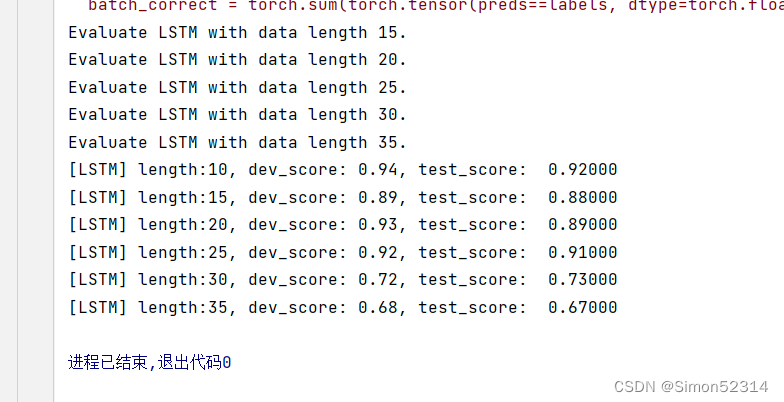
6.3.3.2 模型在不同长度的数据集上的准确率变化图
接下来,将SRN和LSTM在不同长度的验证集和测试集数据上的准确率绘制成图片,以方面观察。
import matplotlib.pyplot as plt plt.plot(lengths, lstm_dev_scores, '-o', color='#e8609b', label="LSTM Dev Accuracy") plt.plot(lengths, lstm_test_scores,'-o', color='#000000', label="LSTM Test Accuracy")#绘制坐标轴和图例 plt.ylabel("accuracy", fontsize='large') plt.xlabel("sequence length", fontsize='large') plt.legend(loc='lower left', fontsize='x-large')fig_name = "./images/6.12.pdf" plt.savefig(fig_name) plt.show()

展示了LSTM模型与SRN模型在不同长度数据集上的准确度对比。随着数据集长度的增加,LSTM模型在验证集和测试集上的准确率整体也趋向于降低;同时LSTM模型的准确率显著高于SRN模型,表明LSTM模型保持长期依赖的能力要优于SRN模型.
6.3.3.3 LSTM模型门状态和单元状态的变化
LSTM模型通过门控机制控制信息的单元状态的更新,这里可以观察当LSTM在处理一条数字序列的时候,相应门和单元状态是如何变化的。首先需要对以上LSTM模型实现代码中,定义相应列表进行存储这些门和单元状态在每个时刻的向量。
# 声明LSTM和相关参数 class LSTM(nn.Module):def __init__(self, input_size, hidden_size, Wi_attr=None, Wf_attr=None, Wo_attr=None, Wc_attr=None,Ui_attr=None, Uf_attr=None, Uo_attr=None, Uc_attr=None, bi_attr=None, bf_attr=None,bo_attr=None, bc_attr=None):super(LSTM, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_size# 初始化模型参数if Wi_attr==None:Wi=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)else:Wi = torch.tensor(Wi_attr, dtype=torch.float32)self.W_i = torch.nn.Parameter(Wi)if Wf_attr==None:Wf=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)else:Wf = torch.tensor(Wf_attr, dtype=torch.float32)self.W_f = torch.nn.Parameter(Wf)if Wo_attr==None:Wo=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)else:Wo = torch.tensor(Wo_attr, dtype=torch.float32)self.W_o =torch.nn.Parameter(Wo)if Wc_attr==None:Wc=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)else:Wc = torch.tensor(Wc_attr, dtype=torch.float32)self.W_c = torch.nn.Parameter(Wc)if Ui_attr==None:Ui = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)else:Ui = torch.tensor(Ui_attr, dtype=torch.float32)self.U_i = torch.nn.Parameter(Ui)if Uf_attr == None:Uf = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)else:Uf = torch.tensor(Uf_attr, dtype=torch.float32)self.U_f = torch.nn.Parameter(Uf)if Uo_attr == None:Uo = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)else:Uo = torch.tensor(Uo_attr, dtype=torch.float32)self.U_o = torch.nn.Parameter(Uo)if Uc_attr == None:Uc = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)else:Uc = torch.tensor(Uc_attr, dtype=torch.float32)self.U_c = torch.nn.Parameter(Uc)if bi_attr == None:bi = torch.zeros(size=[1,hidden_size], dtype=torch.float32)else:bi = torch.tensor(bi_attr, dtype=torch.float32)self.b_i = torch.nn.Parameter(bi)if bf_attr == None:bf = torch.zeros(size=[1,hidden_size], dtype=torch.float32)else:bf = torch.tensor(bf_attr, dtype=torch.float32)self.b_f = torch.nn.Parameter(bf)if bo_attr == None:bo = torch.zeros(size=[1,hidden_size], dtype=torch.float32)else:bo = torch.tensor(bo_attr, dtype=torch.float32)self.b_o = torch.nn.Parameter(bo)if bc_attr == None:bc = torch.zeros(size=[1,hidden_size], dtype=torch.float32)else:bc = torch.tensor(bc_attr, dtype=torch.float32)self.b_c = torch.nn.Parameter(bc)# 初始化状态向量和隐状态向量def init_state(self, batch_size):hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)return hidden_state, cell_state# 定义前向计算def forward(self, inputs, states=None):# inputs: 输入数据,其shape为batch_size x seq_len x input_sizebatch_size, seq_len, input_size = inputs.shape# 初始化起始的单元状态和隐状态向量,其shape为batch_size x hidden_sizeif states is None:states = self.init_state(batch_size)hidden_state, cell_state = states# 定义相应的门状态和单元状态向量列表self.Is = []self.Fs = []self.Os = []self.Cs = []# 初始化状态向量和隐状态向量cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)# 执行LSTM计算,包括:隐藏门、输入门、遗忘门、候选状态向量、状态向量和隐状态向量for step in range(seq_len):input_step = inputs[:, step, :]I_gate = F.sigmoid(torch.matmul(input_step, self.W_i) + torch.matmul(hidden_state, self.U_i) + self.b_i)F_gate = F.sigmoid(torch.matmul(input_step, self.W_f) + torch.matmul(hidden_state, self.U_f) + self.b_f)O_gate = F.sigmoid(torch.matmul(input_step, self.W_o) + torch.matmul(hidden_state, self.U_o) + self.b_o)C_tilde = F.tanh(torch.matmul(input_step, self.W_c) + torch.matmul(hidden_state, self.U_c) + self.b_c)cell_state = F_gate * cell_state + I_gate * C_tildehidden_state = O_gate * F.tanh(cell_state)# 存储门状态向量和单元状态向量self.Is.append(I_gate.detach().numpy().copy())self.Fs.append(F_gate.detach().numpy().copy())self.Os.append(O_gate.detach().numpy().copy())self.Cs.append(cell_state.detach().numpy().copy())return hidden_state
接下来,需要使用新的LSTM模型,重新实例化一个runner,本节使用序列长度为10的模型进行此项实验,因此需要加载序列长度为10的模型。
# 实例化模型 base_model = LSTM(input_size, hidden_size) model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes) # 指定优化器 optimizer = torch.optim.Adam(lr=lr, params=model.parameters()) # 定义评价指标 metric = Accuracy() # 定义损失函数 loss_fn = torch.nn.CrossEntropyLoss() # 基于以上组件,重新实例化Runner runner = RunnerV3(model, optimizer, loss_fn, metric)length = 10 # 加载训练过程中效果最好的模型 model_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams") runner.load_model(model_path)
接下来,给定一条数字序列,并使用数字预测模型进行数字预测,这样便会将相应的门状态和单元状态向量保存至模型中. 然后分别从模型中取出这些向量,并将这些向量进行绘制展示。代码实现如下:
import seaborn as sns import matplotlib.pyplot as plt def plot_tensor(inputs, tensor, save_path, vmin=0, vmax=1):tensor = np.stack(tensor, axis=0)tensor = np.squeeze(tensor, 1).Tplt.figure(figsize=(16,6))# vmin, vmax定义了色彩图的上下界ax = sns.heatmap(tensor, vmin=vmin, vmax=vmax) ax.set_xticklabels(inputs)ax.figure.savefig(save_path)# 定义模型输入 inputs = [6, 7, 0, 0, 1, 0, 0, 0, 0, 0] X = torch.as_tensor(inputs.copy()) X = X.unsqueeze(0) # 进行模型预测,并获取相应的预测结果 logits = runner.predict(X) predict_label = torch.argmax(logits, dim=-1) print(f"predict result: {predict_label.numpy()[0]}")# 输入门 Is = runner.model.rnn_model.Is plot_tensor(inputs, Is, save_path="./images/6.13_I.pdf") # 遗忘门 Fs = runner.model.rnn_model.Fs plot_tensor(inputs, Fs, save_path="./images/6.13_F.pdf") # 输出门 Os = runner.model.rnn_model.Os plot_tensor(inputs, Os, save_path="./images/6.13_O.pdf") # 单元状态 Cs = runner.model.rnn_model.Cs plot_tensor(inputs, Cs, save_path="./images/6.13_C.pdf", vmin=-5, vmax=5)





总结:
1、多组训练时候报错了,检查是因为load_data(data_path) 函数应该返回三个值,但实际上只返回了两个,所以做实验时,不要看到可以导入的直接无脑导入,要具体情况具体分析
相关文章:
LSTM的记忆能力实验
长短期记忆网络(Long Short-Term Memory Network,LSTM)是一种可以有效缓解长程依赖问题的循环神经网络.LSTM 的特点是引入了一个新的内部状态(Internal State) 和门控机制(Gating Mechanism)&am…...

Unity之ShaderGraph如何实现瓶装水效果
前言 有一个场景在做效果时,有一个水瓶放到桌子上的设定,但是模型只做了个水瓶,里面是空的,所以我就想办法,如何做出来瓶中装睡的效果,最好是能跟随瓶子有液体流动的效果。 如下图所示: 水面实现 水面效果 液体颜色设置 因为液体有边缘颜色和内里面颜色,所以要分开…...
【python与机器学习3】感知机和门电路:与门,或门,非门等
目录 1 电子和程序里的与门,非门,或门,与非门 ,或非门,异或门 1.1 基础电路 1.2 所有的电路情况 1.3 电路的符号 1.4 各种电路对应的实际电路图 2 各种具体的电路 2.1 与门(and gate) 2…...

关键字:extends关键字
在 Java 中,extends 是一个关键字,用于表示继承关系。当一个类使用 extends 关键字时,它表示该类是一个子类,并且继承了父类的属性和方法。 以下是 extends 关键字的解析: 语法: 描述: ChildC…...
KEPServerEX 6 之【外篇-1】PTC-ThingWorx服务端软件安装 Tomcat10本地安装
本文目标: 安装 Java 和 Apache Tomcat ,为ThingWorx安装做基础。 ----------------------------------------------------------------------- 安装重点 --------------------------------------------------------------------- 1. 安装 Java 11 / JDK 11 添加系…...
(Mac上)使用Python进行matplotlib 画图时,中文显示不出来
【问题描述】 ①报错确缺失字体: ②使用matplotlib画图,中文字体显示不出来 【问题思考】 在网上搜了好多,关于使用python进行matplotlib画图字体显示不出来的,但是我试用了下,对我来说都没有。有些仅使用于windows系…...

万能刷题小程序源码系统:功能强大+试题管理+题库分类+用户列表 附带完整的搭建教程
随着互联网技术的不断进步,线上学习已成为越来越多人的选择。刷题作为提高学习效果的重要方式,一直受到广大学生的喜爱。然而,市面上的刷题软件虽然繁多,但功能各异,质量参差不齐,使得很多用户在选择时感到…...
)
5.2 显示窗口的内容(二)
三,显示器几何形状管理 只有显示管理器被允许更改显示器的几何形状。窗口管理器也是显示管理器。 3.1 当显示器显示其自身内容时 当显示器显示其自身内容时,适用以下属性: 显示属性描述SCREEN_PROPERTY_PROTECTION_ENABLE表示显示目标窗口是否需要内容保护。只要显示器上…...
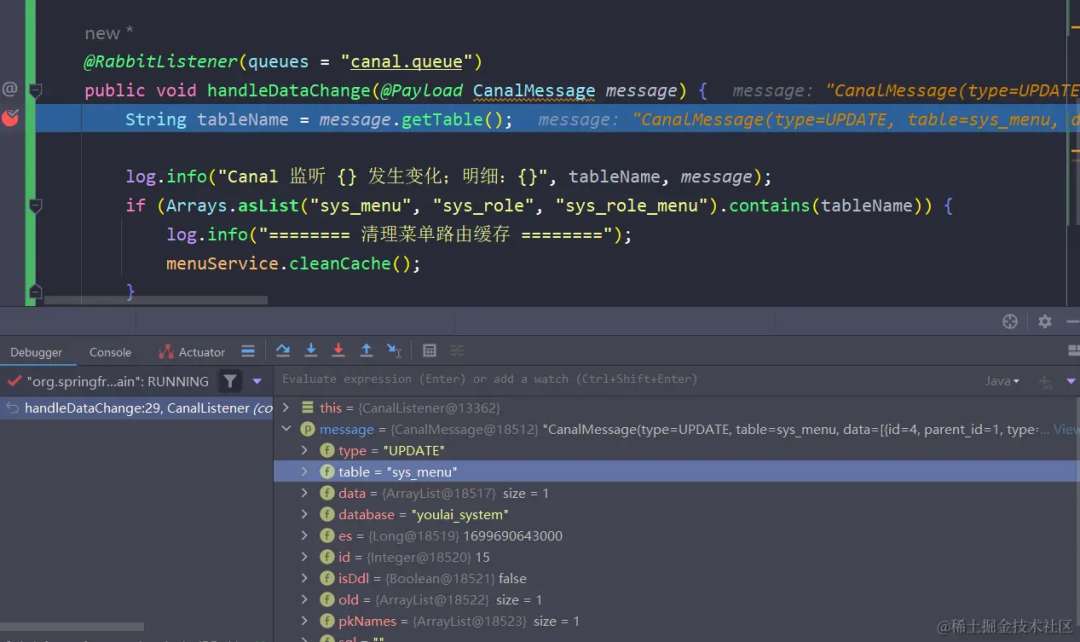
SpringCloud 整合 Canal+RabbitMQ+Redis 实现数据监听
1Canal介绍 Canal 指的是阿里巴巴开源的数据同步工具,用于数据库的实时增量数据订阅和消费。它可以针对 MySQL、MariaDB、Percona、阿里云RDS、Gtid模式下的异构数据同步等情况进行实时增量数据同步。 当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.…...

一体机定制_工控触控一体机安卓主板方案
工控一体机是一种集成化的硬件方案,采用了联发科MT8768八核芯片和12nm制程工艺。该芯片拥有2.0GHz的主频和IMG PowerVR GE8320图形处理GPU,具备强大的视频处理能力,并且兼容大部分的视频格式和解码能力。工控一体机搭载了Android 9.0操作系统…...

Android10.0 人脸解锁流程分析
人脸解锁概述 人脸解锁即用户通过注视设备的正面方便地解锁手机或平板。Android 10 为支持人脸解锁的设备在人脸认证期间添加了一个新的可以安全处理相机帧、保持隐私与安全的人脸认证栈的支持,也为安全合规地启用集成交易的应用(网上银行或其他服务&am…...

P8598 [蓝桥杯 2013 省 AB] 错误票据
题目背景 某涉密单位下发了某种票据,并要在年终全部收回。 题目描述 每张票据有唯一的 ID 号,全年所有票据的 ID 号是连续的,但 ID 的开始数码是随机选定的。因为工作人员疏忽,在录入 ID 号的时候发生了一处错误,造…...

【Android进阶篇】Android中PreferenceScreen的作用和详细用法介绍
1,PreferenceScreen的作用 在Android开发中,PreferenceScreen是一个非常重要的布局控件,主要用于创建设置界面(settings page)。它可以包含多个Preference子项,如CheckBoxPreference, ListPreference等&am…...

test-03-java 单元测试框架 testNG 入门介绍 junit/junit5/testNG 详细对比
拓展阅读 test-01-java 单元测试框架 junit 入门介绍 test-02-java 单元测试框架 junit5 入门介绍 test-03-java 单元测试框架 testNG 入门介绍 junit/junit5/testNG 详细对比 test assert-01-Google Truth 断言 test 系统学习-03-TestNG Spock testng 入门使用教程 开源…...

Maven 项目依赖仓库配置详解:pom.xml 中的 repositories 与 Maven 配置文件的调用顺序
Maven 项目依赖仓库配置详解:pom.xml 中的 repositories 与 Maven 配置文件的调用顺序 Maven(Apache Maven)是一个流行的项目管理工具,广泛用于Java项目的构建、依赖管理以及项目生命周期的管理。在Maven项目中,pom.x…...

JS深浅拷贝
区分 B复制了A的值,如果A被修改,B的值也被改变,那就是浅拷贝。 如果B的值没有跟着修改,那就是深拷贝 深浅拷贝的方式 1、遍历赋值 2、Object.create() 3、JSON.parse()和JSON.stringify() 浅拷贝-遍历 let a {name:"…...
uni-app 命令行创建
1. 首先创建项目,命令如下: npx degit dcloudio/uni-preset-vue#vite-ts uni-app-demo如果出现报错,如下图. 大概率就是没有目录C:\Users\Administrator\AppData\Roaming\npm 解决办法: 创建目录 C:\Users\Administrator\AppData\Roaming\n…...

ImageJ二值图像处理:形态学和分割
文章目录 二值化形态学处理分割 ImageJ系列: 安装与初步💎 灰度图像处理💎 图像滤波 二值化 在Process->Binary下有两个命令用于生成一个二值化图像,分别是 Make BinaryConvert to Mask 但当前图像是RGB或者灰度图时&…...
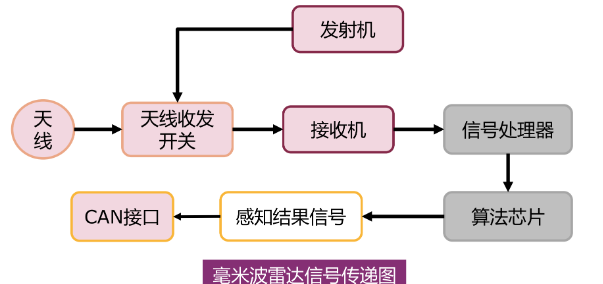
自动驾驶中的“雷达”
自动驾驶中有好几种雷达,新手可能会混淆,这里统一介绍一下它们。 首先,所有雷达的原理都是发射波,接收回波(可能是声波或电磁波),并通过发射和接收的时间差以及波的速度计算距离。只不过发射的…...

Web 3.0 是什么
第 1 章 明晰Web 3.0 从本章开始,就进入了本书的第一篇章,入门Web3.0,在第一篇章中将会让读者对Web3.0有一个整体的认知,为学习后面的章节打下基础。 在本章中,主要介绍的是Web的发展历史,包涵Web1.0、Web2.0、Web3.0的发展过程,以及资本为什么需要入场Web3.0、Web3.0…...

KMS_VL_ALL_AIO:一键激活Windows与Office的完整解决方案
KMS_VL_ALL_AIO:一键激活Windows与Office的完整解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经为Windows或Office的激活问题而烦恼?每次重装系统后都…...
)
Codex 适配国产信创环境完整部署指南(深度技术篇)
摘要随着国内信创产业全面落地推进,基于大代码模型的智能编码助手 Codex,在国产化服务器、操作系统、CPU 架构环境下的适配、编译、部署、调优成为企业数字化转型过程中的刚需技术痛点。本文从架构原理、国产硬件适配、操作系统兼容、依赖编译、容器化部…...
)
JS 异步 从零讲(大白话 + 真实场景 + 可运行案例)
按顺序:回调函数 → Promise → async/await,工作最常用,直接上手。1. 回调函数(最原始,缺点:回调地狱)2. Promise(解决回调地狱,链式调用)new Promise((reso…...

巴洛克光影建模失败率高达83%?用这7个构图锚点+12组权威艺术史关键词立即逆转
更多请点击: https://kaifayun.com 第一章:巴洛克光影建模的危机本质与历史断层 “巴洛克光影建模”并非真实存在的技术流派,而是对20世纪末至21世纪初三维渲染实践中一种高度装饰化、过度依赖手工打光与物理不一致材质叠加现象的隐喻性指称…...

协议转换网关与数据采集网关的区别与差异
摘要在工业自动化、物联网、智能建筑等领域中,“协议转换”和“数据采集网关”是两个常被提及但容易混淆的概念。它们虽有关联,却扮演着不同的角色。理解其核心差异对于构建高效、可靠的数据通信系统至关重要。1.核心定义:本质差异1.1协议转换…...

Agent_Skills_万千应用_第01篇_PDF 处理 Skill:让 Agent 真正会读、会拆、会抽取 PDF
Agent Skills 万千应用 第01篇 PDF 处理 Skill:让 Agent 真正会读、会拆、会抽取 PDF 01|场景痛点开场:PDF 是办公室里最像“黑盒”的文件 你一定遇到过这种场景:老板丢来一份 80 页行业报告,让你 10 分钟内说清楚“…...

企业内网应用如何安全合规地接入Taotoken调用外部大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网应用如何安全合规地接入Taotoken调用外部大模型能力 在企业级应用开发中,引入外部大模型能力可以显著提升产品…...

5分钟免费解决NVIDIA显卡显示器色彩过饱和的终极方案
5分钟免费解决NVIDIA显卡显示器色彩过饱和的终极方案 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novideo_srgb 你是否曾经发现…...

如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南
如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 在游戏修改工具的使用过程中&…...

[特殊字符] 零基础搭建「知识科普讲师」数字人|魔珐星云实战指南
在短视频、知识付费、自媒体赛道,知识科普、职场干货、生活常识、读书分享内容需求越来越大。真人出镜成本高、拍摄慢、文案难量产,而AI 数字人讲师可以做到:文案好写、生成快、24 小时可播、风格稳定、形象专业。 本文基于魔珐星云具身智能…...