数据分析之词云图绘制
试验任务概述:如下为所给CSDN博客信息表,分别汇总了'ai', 'algo', 'big-data', 'blockchain', 'hardware', 'math', 'miniprog'等7个标签的博客。对CSDN不同领域标签类别的博客内容进行词频统计,绘制词频统计图,并根据词频统计的结果绘制词云图。
数据表链接:https://download.csdn.net/download/m0_52051577/88669409?spm=1001.2014.3001.5503
import pandas as pd
data=pd.read_csv(open('D://实训课//实训课数据csdn.csv'),sep=',') //导入数据
data //数据预览
如图,数据信息包括class、url、title、content四个类标签,分别表示博客所属领域类别、对应链接、博文题目和博客内容。下面第一步对这些博文按类别进行分类。
session=data.loc[:,'class'].values
set(session)//对数据表的class类别列切分
def classma(i):class1=data.loc[data['class']==class_list[i],:]print(class1)return class1
//定义切分函数,按类别列作为索引返回每一类别对应的数据信息class_list=['ai', 'algo', 'big-data', 'blockchain', 'hardware', 'math', 'miniprog']
# for i in range(len(class_list)):
# classma(i)
ai=classma(0)分类结果如下图所示:

导入停用词表,对所分类数据进行停用词处理。
file_path='D:/..csv'
def getStopword(file_path):stop_list=[line[:-1] for line in open(file_path+'/哈工大停用词表 .txt','r',encoding='UTF-8')]return stop_list
getStopword(file_path)import jieba
def preProcess(all_data,stop_list):xdata=all_data['content']result_data=list(xdata)result=[]for doc in result_data:doc=doc.strip()cut_list=jieba.lcut(doc)doc_result=[word for word in cut_list if word not in stop_list]result.append(doc_result)return result# getStopword(file_path)
result1=preProcess(ai,getStopword(file_path))
print(result1)导入jieba库,对去除停用词后的数据进行分词处理,并返回分词后的结果。

后续是对分词后的词频进行统计,并计算每个分词的tf-idf值,这里引入一个tf-idf值的概念:
TF(词频)指的是一个词语在文档中出现的频率,它认为在一个文档中频繁出现的词语往往与文档的主题相关性更高。
from gensim.models.tfidfmodel import TfidfModel
from gensim import corpora
def calculate(resultx):dictionary=corpora.Dictionary(resultx)corpus=[dictionary.doc2bow(text) for text in resultx]tf_idf_model = TfidfModel(corpus, normalize=False)word_tf_tdf = list(tf_idf_model[corpus])print('词典:', dictionary.token2id)print('词频:', corpus)print('词的tf-idf值:', word_tf_tdf)return dictionary.token2id,corpus,word_tf_tdf
idic,corpus,word_tf_tdf=calculate(result1)

如上图,找出每个分词和与之相关联的词对应的下标。
max_pic=[]
max_fre=[]
def search(resultx,a):maxmum=[]idic,corpus,word_tf_tdf=calculate(resultx)for row in word_tf_tdf[a]:maxmum.append(row[1])for col in word_tf_tdf[a]:if col[1]==max(maxmum):print(max(maxmum))max_fre.append(max(maxmum))max_sig=col[0]max_pic.append(max_sig)return max_pic,max_fre
for i in range(len(word_tf_tdf)):search(result1,i)
print(max_pic)
print(max_fre)对所有相关联的数对进行检索,采用特征提取方法对数据排序。并采用最大关联分析,找出每一个标签中与属性相关最大的词。 返回的是对应词的下标和对应的tf-idf值。

dictionary_s=idic
key_words=[]
for key,value in dictionary_s.items():if value in max_pic:key_words.append(key)
key_words.pop(-1)
print(key_words)构造关键词列表,根据之前返回的关联度最大词汇对应的下标,回到原数据表中定位,找出对应的词汇。
# 构造词频字典
dict_zip=dict(zip(key_words,max_fre))
print(dict_zip)
最后,根据词汇、词频列表绘制词云图。
# 绘制词云
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def draw(y):my_cloud = WordCloud(background_color='white', # 设置背景颜色 默认是blackwidth=900, height=600,max_words=100, # 词云显示的最大词语数量font_path='simhei.ttf', # 设置字体 显示中文max_font_size=99, # 设置字体最大值min_font_size=16, # 设置子图最小值random_state=50 # 设置随机生成状态,即多少种配色方案).generate_from_frequencies(y)# 显示生成的词云图片plt.imshow(my_cloud, interpolation='bilinear')# 显示设置词云图中无坐标轴plt.axis('off')plt.show()
draw(dict_zip)
注:以上为AI标签列对应的词云图,其他标签列词云图绘制的实现方式同此方法。就不再赘述。
相关文章:
数据分析之词云图绘制
试验任务概述:如下为所给CSDN博客信息表,分别汇总了ai, algo, big-data, blockchain, hardware, math, miniprog等7个标签的博客。对CSDN不同领域标签类别的博客内容进行词频统计,绘制词频统计图,并根据词频统计的结果绘制词云图。…...

【赠书第13期】边缘计算系统设计与实践
文章目录 前言 1 硬件架构设计 2 软件框架设计 3 网络结构设计 4 安全性、可扩展性和性能优化 5 推荐图书 6 粉丝福利 前言 边缘计算是一种新兴的计算模式,它将计算资源推向网络边缘,以更好地满足实时性、低延迟和大规模设备连接的需求。边缘计算…...
数据库01_增删改查
1、什么是数据?什么是数据库? 数据:描述事物的符号记录称为数据。数据是数据库中存储的基本对象。数据库:存放数据的仓库,数据库中可以保存文本型数据、二进制数据、多媒体数据等数据 2、数据库的发展 第一阶段&…...
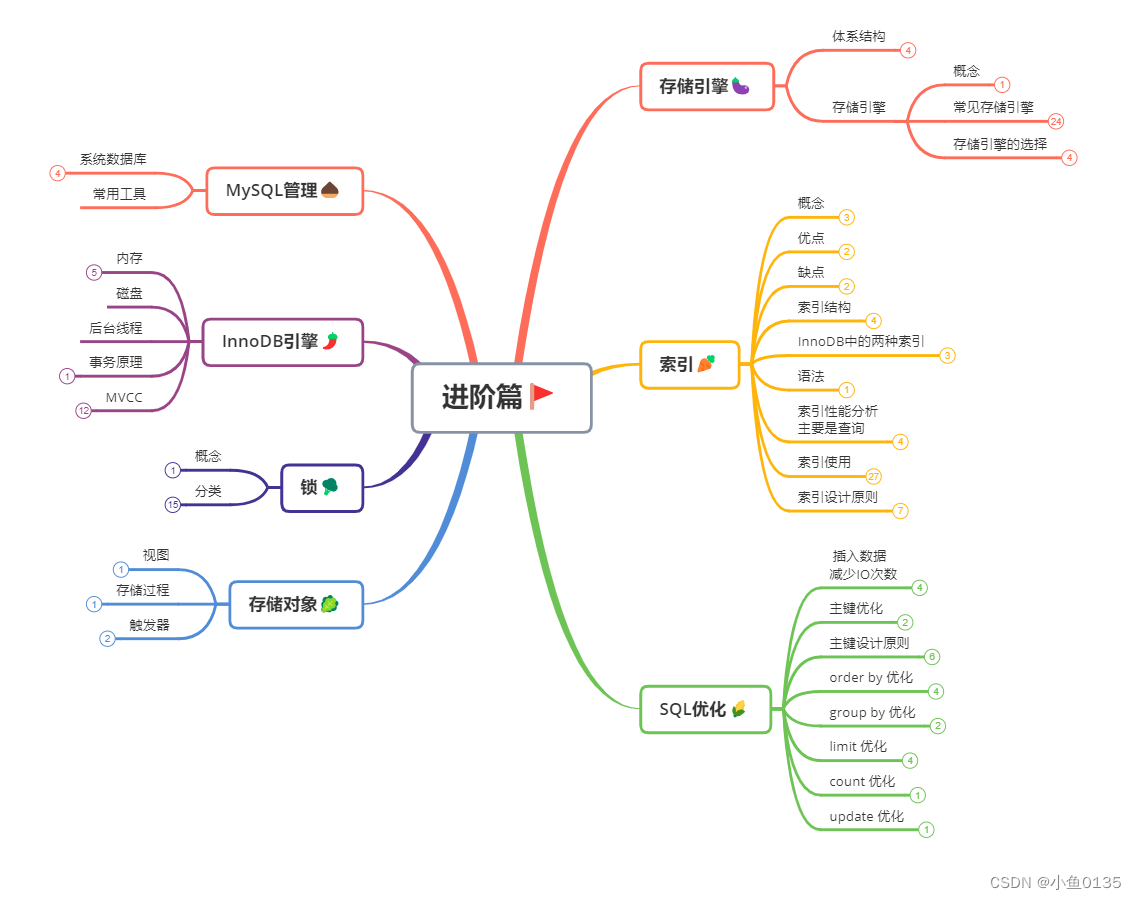
MySQL——进阶篇
二、进阶篇🚩 1. 存储引擎🍆 1.1 MSQL体系结构 连接层: 连接处理,连接认证,每个客户端的权限 服务层: 绝大部分核心功能,可跨存储引擎 可插拔存储引擎: 需要的时候可以添加或拔掉…...

Python 网络编程之搭建简易服务器和客户端
用Python搭建简易的CS架构并通信 文章目录 用Python搭建简易的CS架构并通信前言一、基本结构二、代码编写1.服务器端2.客户端 三、效果展示总结 前言 本文主要是用Python写一个CS架构的东西,包括服务器和客户端。程序运行后在客户端输入消息,服务器端会…...

往年面试精选题目(前50道)
常用的集合和区别,list和set区别 Map:key-value键值对,常见的有:HashMap、Hashtable、ConcurrentHashMap以及TreeMap等。Map不能包含重复的key,但是可以包含相同的value。 Set:不包含重复元素的集合&#…...

解决服务器Tab键不能补全问题
编辑~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml 命令:vim ~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml替换:<property name“<Super>Tab” type“string” value“switch_window…...

人工智能 机器学习 深度学习:概念,关系,及区别说明
如果过去几年,您读过科技主题的文章,您可能会遇到一些新词汇,如人工智能(Artificial Intelligence)、机器学习(Machine Learning)和深度学习(Deep Learning)等。这三个词…...
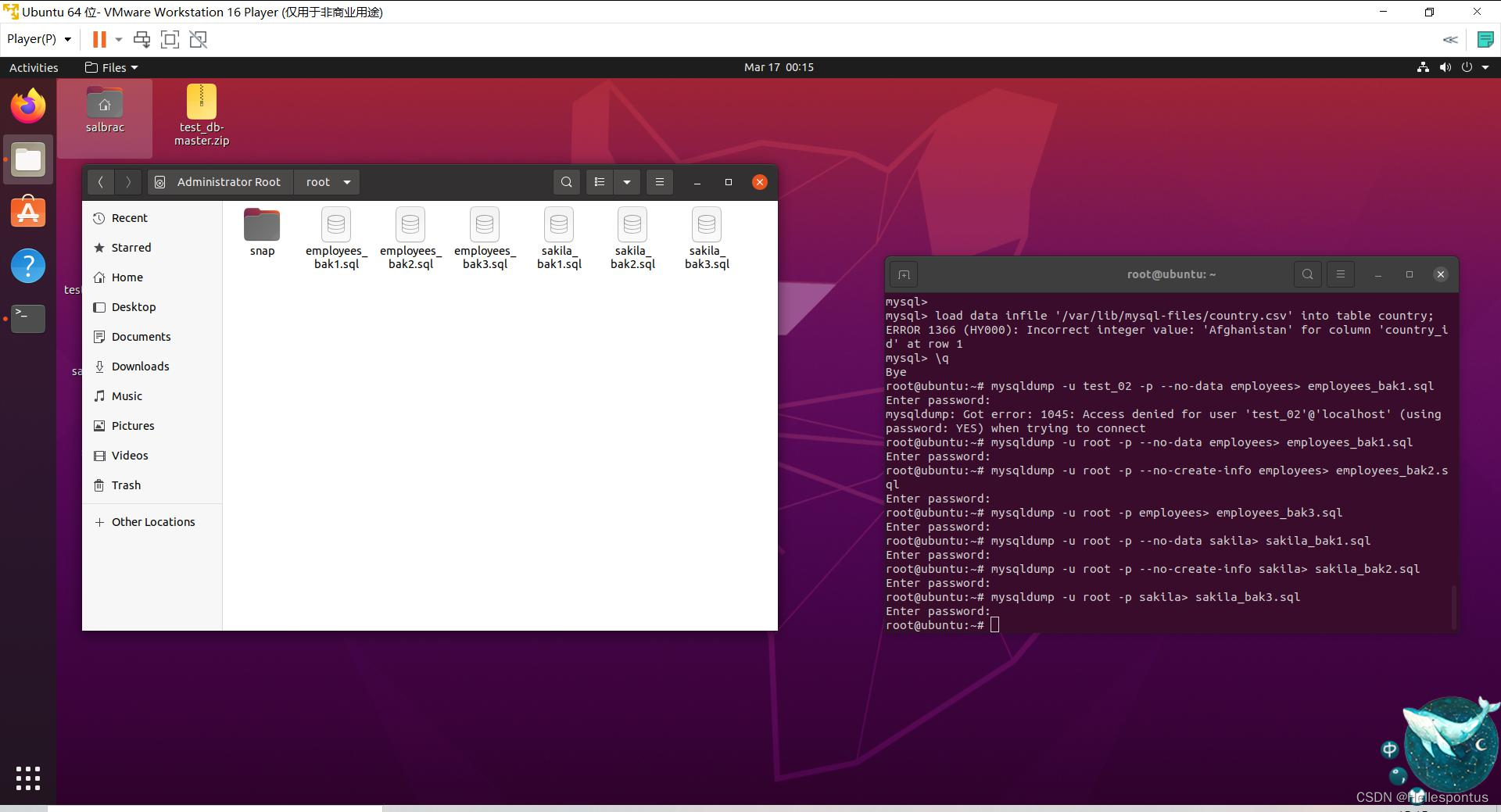
数据库——LAMP的搭建及MySQL基操
1.实验内容及原理 1. 在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,并在 Ubuntu 中搭建 LAMP 实验环境。 2. 使用 MySQL 进行一些基本操作: (1)登录 MySQL,在 MySQL 中创建用户,并对…...

抗原设计与兔单B细胞技术的结合-卡梅德生物
随着生物医学研究的不断深入,抗体疗法作为治疗疾病的有力工具逐渐成为研究的焦点。而兔单B细胞技术作为抗体研究的创新方法,其与抗原设计的有机结合为获取定制抗体打开了崭新的创新之路。本文将深入探讨抗原设计与兔单B细胞技术相互融合的原理、优势&…...

在uniapp中使用背景渐变色与背景图不生效问题
list上有文字详情以及背景图,从背景可以看出是渐变色和 背景图片的结合。 因为使用到渐变色,所以要结合 background-blend-mode 属性来实现与背景图片叠加显示,否则只通过 background: linear-gradient(); background-image: url(); 设置不会…...

Java中XML的解析
1.采用第三方开元工具dom4j完成 使用步骤 1.导包dom4j的jar包 2.add as lib.... 3.创建核心对象, 读取xml得到Document对象 SAXReader sr new SAXReader(); Document doc sr.read(String path); 4.根据Document获取根元素对象 Element root doc.getRootElement(); …...

React快速入门之交互性
响应事件 创建事件处理函数 处理函数名常以handle事件名命名 function handlePlayClick() {alert(Playing);}传递事件处理函数 函数名、匿名两种方式! function PlayButton() {function handlePlayClick() {alert(Playing);}return (<Button handleClick{handl…...

浅谈WPF之ToolTip工具提示
在日常应用中,当鼠标放置在某些控件上时,都会有相应的信息提示,从软件易用性上来说,这是一个非常友好的功能设计。那在WPF中,如何进行控件信息提示呢?这就是本文需要介绍的ToolTip【工具提示】内容…...

Android Studio 如何隐藏默认标题栏
目录 前言 一、修改清单文件 二、修改代码 三、更多资源 前言 在 Android 应用中,通常会有一个默认的标题栏,用于显示应用的名称和一些操作按钮。但是,在某些情况下,我们可能需要隐藏默认的标题栏,例如自定义标题栏…...

对于c++的总结与思考
笔者觉得好用的学习方法:模板法 1.采用原因:由于刚从c语言面向过程的学习中解脱出来,立即把思路从面向过程转到面向对象肯定不现实,加之全新的复杂语法与操作,着实给新手学习这门语言带来了不小的困难。所以ÿ…...

Flask 账号详情展示
Flask 账号详情展示 这段代码是一个基于Flask框架的Python应用程序。 它包含了两部分代码:Python代码和HTML代码。 web/templates/common/tab_account.html <div class"row border-bottom"><div class"col-lg-12"><div cla…...

软件测试/测试开发丨Pytest 参数化用例
参数化 通过参数的方式传递数据,从而实现数据和脚本分离。并且可以实现用例的重复生成与执行。 参数化应用场景 测试登录场景 测试登录成功,登录失败(账号错误,密码错误)创建多种账号: 中⽂文账号,英⽂文账号 普通测试用例方法 …...
MATLAB中./和/,.*和*,.^和^的区别
MATLAB中./和/,.*和*,.^ 和^ 的区别 MATLAB中./和/,.*和*,.^ 和^ 的区别./ 和 / 的区别.//实验实验结果 .* 和 * 的区别.**实验实验结果 .^ 和^ 的区别.^n^n实验运行结果 MATLAB中./和/,.和,.^ 和^ 的区别 …...
Flask 与微信小程序对接
Flask 与微信小程序的对接 在 web/controllers/api中增建py文件,主要是给微信小程序使用的。 web/controllers/init.py # -*- coding: utf-8 -*- from flask import Blueprint route_api Blueprint( api_page,__name__ )route_api.route("/") def ind…...

告别黑窗口:在Ubuntu上用VSCode调试你的第一个OpenGL三角形程序
告别黑窗口:在Ubuntu上用VSCode调试你的第一个OpenGL三角形程序 对于习惯现代IDE的开发者来说,在终端里反复敲入gcc -lGL -lglut编译命令就像用石器时代的工具雕刻钻石。本文将带你用VSCode重构OpenGL开发体验,从零搭建一个可调试的图形编程…...

避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南
避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南 在芯片设计领域,可测试性设计(DFT)是确保产品质量的关键环节。而作为DFT的重要组成部分,存储器内建自测试(MBIST)的实现质量直接影响着…...

C51结构体内存分配限制与解决方案
1. C51结构体成员的内存空间限制解析在8051单片机开发中,C51编译器对结构体成员的内存分配有着严格限制。这个问题困扰过不少从标准C转向嵌入式开发的工程师。让我用一个实际案例来解释这个技术细节:struct sensor_data {float data temperature; // 试…...

智能汽车人机交互与ADAS系统融合:架构、场景与工程实践
1. 项目概述:当驾驶舱的“大脑”与“眼睛”开始对话“集成人机交互和ADAS系统”——这个标题听起来像是一个纯粹的工程命题,但在我过去十多年的汽车电子开发经历中,我越来越深刻地体会到,这其实是一个关于“人、车、路”三者关系如…...

告别Keil/MDK!用Clion+插件打造STM32的现代化开发工作流
从Keil到Clion:STM32开发者的现代化工作流迁移指南 当稚晖君在B站展示他用Clion开发STM32的流畅体验时,整个嵌入式社区都为之震动。那个视频像一束光,照进了我们这些常年与Keil/MDK为伴的开发者世界——原来嵌入式开发可以如此优雅。但兴奋之…...
)
别再只会拖控件了!FastReport 实战:手把手教你用代码搞定复杂报表(含分组、过滤、合计)
代码驱动报表革命:FastReport高级开发实战指南 在电商后台系统中,销售报表往往需要处理动态分组、条件过滤和跨页合计等复杂需求。传统拖拽式设计工具虽然入门简单,但面对这类业务场景时常常捉襟见肘。本文将带你突破界面限制,通过…...

【Perplexity健身计划搜索实战指南】:20年AI搜索专家亲授3大精准检索心法,错过再等一年
更多请点击: https://codechina.net 第一章:Perplexity健身计划搜索实战指南导论 Perplexity 是一款以推理深度和引用可追溯性见长的 AI 搜索工具,特别适合需要结构化、证据支撑型信息检索的场景。在健身领域,用户常面临计划泛滥…...

SAP 梳理思路
蓝图 业务/需求背景 解决方案 配置 操作手册 程序 优化...

告别插线!用ESP32的OTA Web Updater实现无线烧录,保姆级避坑指南
ESP32无线固件更新全攻略:从零构建OTA Web Updater系统 引言:为什么需要无线更新? 想象一下,你精心设计的智能温室控制系统已经安装在屋顶的密闭箱体中,突然发现需要修复一个关键的温度传感器逻辑错误。传统方式需要…...

【VASP实战】Ubuntu 22.04 LTS 部署 vasp.6.x 指南:从Intel oneAPI编译到GPU加速测试
1. VASP 6.x与Ubuntu 22.04 LTS环境概述 VASP(Vienna Ab initio Simulation Package)是材料科学领域广泛使用的第一性原理计算软件,能够模拟原子尺度的电子结构、分子动力学等过程。最新版VASP 6.x在并行计算效率和GPU加速支持上有显著提升&a…...