MySQL——进阶篇
二、进阶篇🚩
1. 存储引擎🍆
1.1 MSQL体系结构
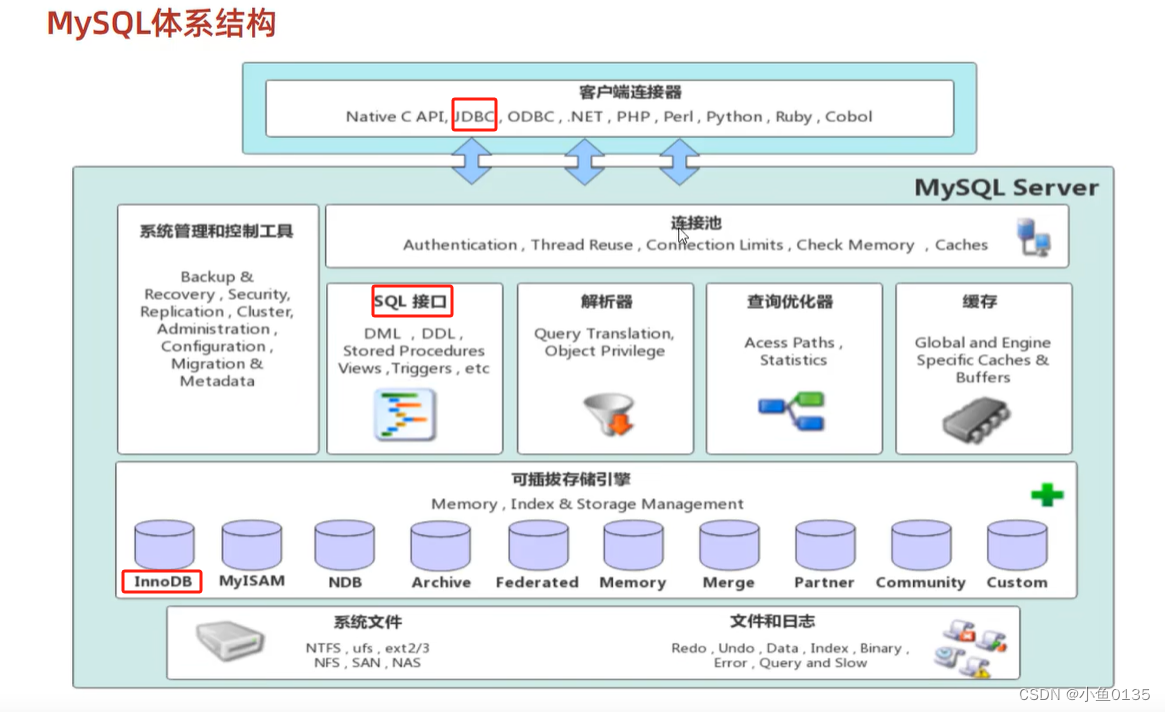
连接层: 连接处理,连接认证,每个客户端的权限
服务层: 绝大部分核心功能,可跨存储引擎
可插拔存储引擎: 需要的时候可以添加或拔掉,数据存储和提取的方式,数据库服务器通过API与其进行交互。**索引在这一层实现,不同的存储引擎有不同的索引实现方式。**InnoDB是MySQL5.5之后默认的存储引擎。
存储层: 数据存储在磁盘文件中
1.2 存储引擎
1.2.1 简介
发动机,不同的场景需要不同的引擎。**存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。**存储引擎是基于表的,不是基于库的,也可被称为表类型。
# 在创建表时指定存储引擎
creat table 表名(字段名 字段类型 [comment 字段注释],……字段名 字段类型 [comment 字段注释]
)ENGINE = INNODB [comment 表注释];# 查询当前数据库支持的存储引擎
SHOW ENGINES;
1.2.2 常见的存储引擎
InnoDB
-
1)介绍:兼顾高可靠和高性能的通用存储引擎
-
2)特点:
-
- DML操作遵循ACID模型,支持事务
- 行级锁 ,提高并发访问性能
- 支持外键 FOREIGN KEY约束,保证数据
-
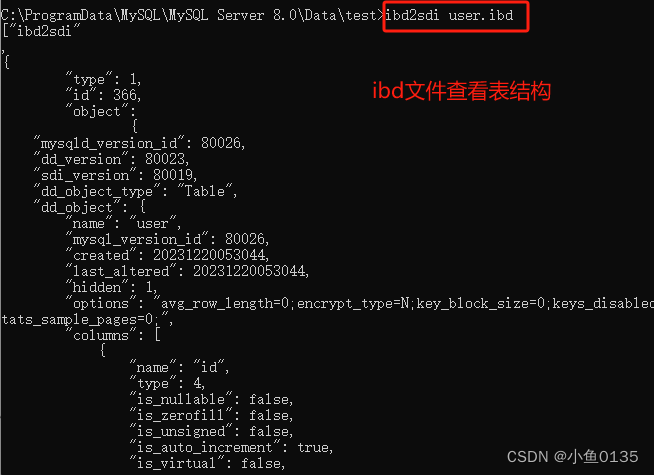
3)文件:文件名.ibd,每张表(参数:innodb_file_per_table)都会有一个表空间文件,存储表结构(frm,sdi)、数据和索引。
-
-
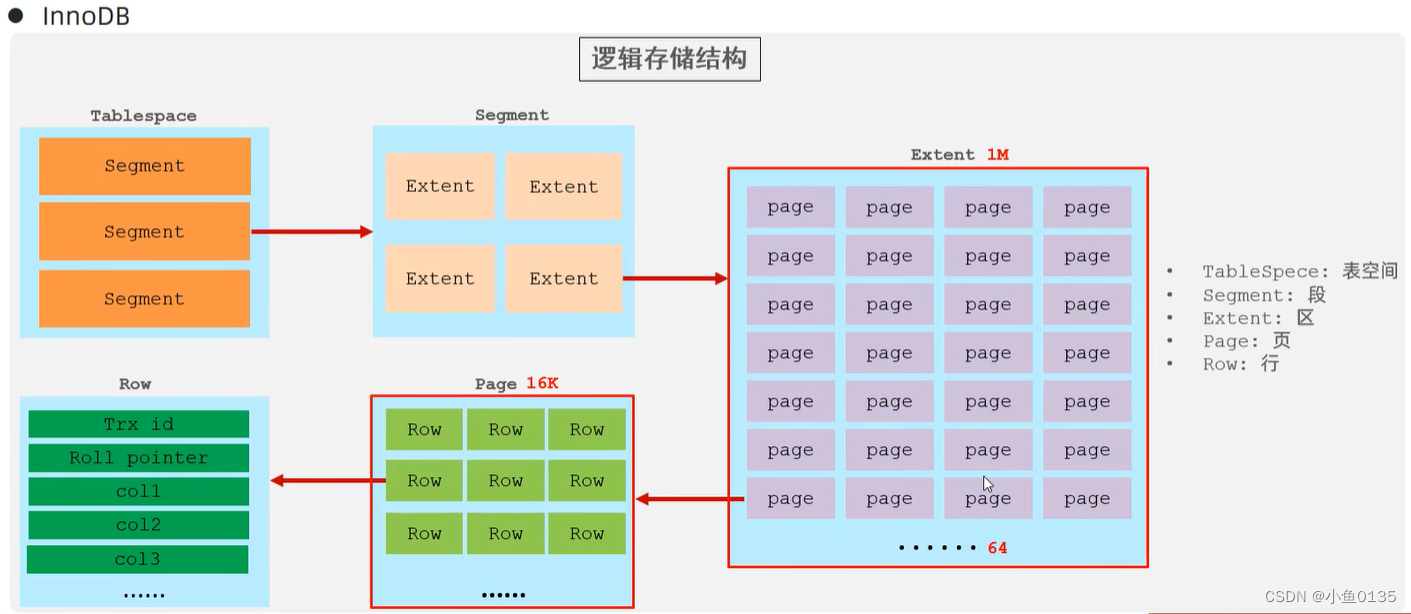
4)逻辑结构:表空间(Tablespace)-段(Segment)-区(Extent)-页(page)-行(Row);page是磁盘操作的最小单元
MYISAM
- 1)介绍:MYISAM早期MySQL的默认存储器
- 2)特点:
-
- 不支持事务
- 表锁,不支持行锁
- 不支持外键
- 3)文件:
-
- 文件名.sdi:表结构
- 文件名.MYD:数据
- 文件名.MDI:索引
MEMORY
- 1)介绍:存储在内存中,会受到硬件、断电问题的影响。只能将这些表作为临时表或缓存使用
- 2)特点:
-
- 内存存放,速度快
- hash索引
- 3)文件:
- 文件名.sdi
1.2.3 存储引擎的选择
根据特点选;对于复杂系统,可以使用多种存储引擎进行组合
InnoDB: 要求并发、数据操作有插入、查询外,还有很多更新、删除操作
MyISAM: 主要是读和插入数据——评论等——MongoDB代替
MEMORY: 访问速度快,太大的不能缓存在内存中,且无法保障数据的安全性——Redis代替
2. 索引🥕
2.1 索引概述
概念: 索引是一种数据结构,是帮助MySQL高效获取数据的
- 无索引——全表扫描
- 有索引——查找更高效
优点:
- 提高数据检索的效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序成本,降低CPU消耗
缺点:
- 占用空间
- 降低更新表的速度,对表进行插入、更新、删除时,效率低
2.2 索引结构
不同的存储引擎有不同的结构
- B+Tree索引:最常见,大部分引擎都支持——InnoDB、MyISAM
- Hash索引: 底层是哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询——Memory
- R-tree(空间索引):MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型
- Full-text(全文索引):通过建立倒排索引,快速匹配文档的方式
1)B+Tree:所有元素会出现在叶子节点,形成链表,非叶子节点只是起索引作用;MySQL中进行了优化,是双向循环链表
2)Hash:采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中
注:InnoDB中有自适应hash功能,自动根据B+Tree索引构建hash索引
2.3 索引分类
分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某列数据中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 找文本中的关键词 | 可以有多个 | FULLTEXT |
InnoDB中的两种索引
聚集索引: 索引结构的叶子节点保存了行数据——必须有,而且只有一个
二级索引: 数据与索引分开存放,索引结构的叶子节点关联的是对应的主键——可以存在多个
回表查询——根据查询条件,在二级索引找到查询的索引值,回到聚集索引中找到整行数据的信息
2.4 索引语法
# 创建索引
CREATE [UNIQUE | FULLTEXT] INDEX index_name ON table_name (index_col_name, ……); -- 索引列可以是单列也可以是多列,多列就是联合索引
-- 索引名称:idx_表名_列名# 查看索引
SHOW INDEX FROM table_name; -- 指定表的所有索引# 删除索引
DROP INDEX index_name ON table_name;
2.5 SQL索引性能分析
主要是查询
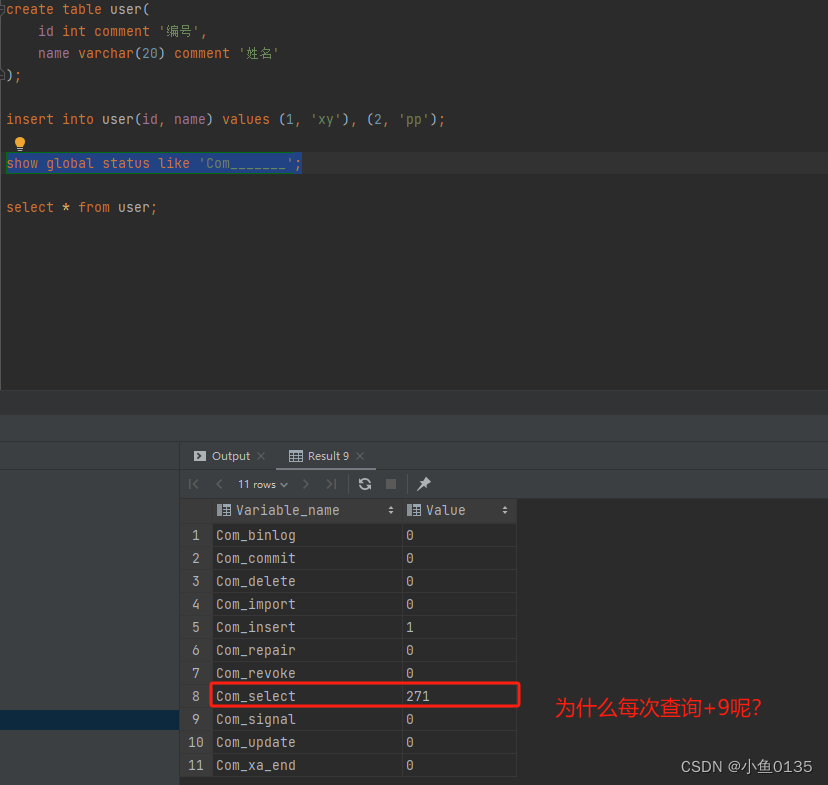
1)SQL执行频率——查看表中哪种操作的频率高
show global status like 'Com_______';
2)慢查询日志
定位哪些SQL语句的执行效率低,从而对这类型语句进行优化
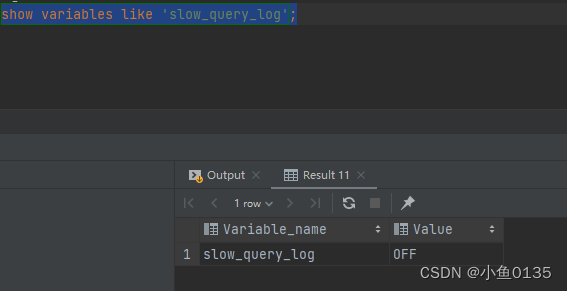
慢查询日志在/var/lib/mysql/localhost-slow.log
慢查询日志配置:
-
慢查询日志默认没有开启,配置文件存放在/etc/my.cnf中
-
systemctl restart mysqld
-
# 开启MySQL慢日志查询开关 slow_query_log=1 # 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志 long_query_time=2
注:Ubuntu中
启动MySQL:service mysqld start
停止MySQL:service mysqld stop
重启MySQL:service mysqld restart
开启慢查询:set global slow_query_log=ON;——临时开,避免在配置文件中进行修改
3)profile详情
# 在做SQL优化的时候帮助了解时间都耗费在哪里
show profiles;
# 查看当前MySQL是否支持profiles
SELECT @@have_profiling;SELECT @@profiling; # 0没有开关# 开启
set profiling = 1;
SELECT @@profiling; # 1# 查看执行的SQL语句的耗时情况
show profiles;# 查看指定query_id的SQL语句各个阶段的耗时情况
show profile fpr query query_id;# 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
4)explain执行计划
explain/desc命令获取MySQL如何执行SELECT语句的信息,包括select语句执行过程中表如何连接和连接的顺序
# 直接在select语句之前加上关键字explain / desc
explain select 字段列表 from 表名 where 条件;
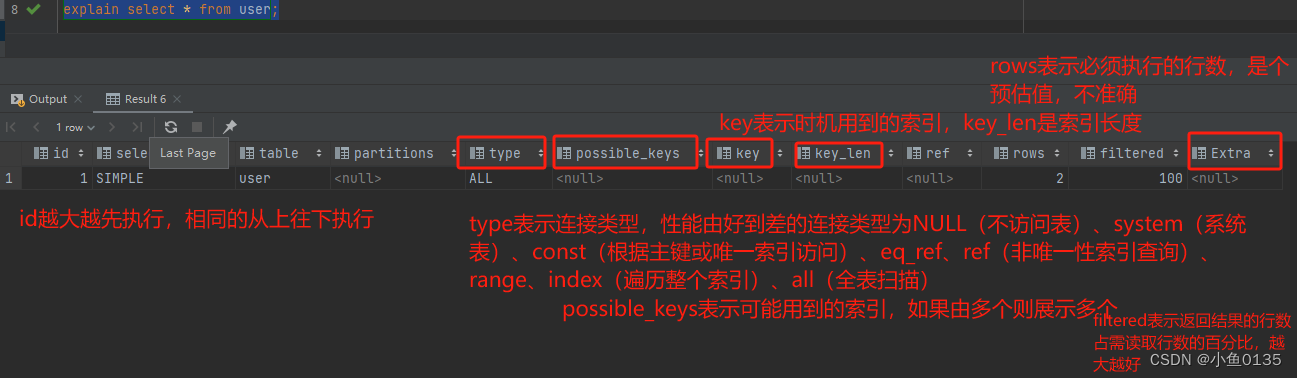
2.6 索引使用
-----where之后的-----
1)最左前缀法则——联合索引(复合索引)
查询从索引的最左列开始,并且不跳过索引中的列;如果跳过某一列,索引将部分失效(后面的字段索引失效)——创建的时候最左边的字段,只要存在就会启动索引,不考虑在selecet中字段排列的前后顺序
2)范围查询
出现>,<这样的范围查询,后面的列索引将会失效。可以使用>=或<=
3)索引列运算
不要再索引列上进行运算操作,否则索引将失效
4)字符串不加引号
字符串不加单引号,存在隐式类型转换——自动类型转换之后,索引就失效了
5)迷糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效
6)or连接的条件
or前后连接的都有索引,索引才会被用到;否则涉及的索引都不会被用到
7)数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引
-----from之后的-----
8)SQL提示——操作者提示SQL
在SQL语句中加入一些人为的提示来达到优化操作的目的
# 使用索引
explain select * from 表名 use index(索引名) where 条件判断
# 忽略索引
explain select * from 表名 ignore index(索引名) where 条件判断
# 强制索引
explain select * from 表名 force index(索引名) where 判断条件
-----select之后的-----
9)覆盖索引
查询使用了索引,并且需要返回的列在该索引中已经全部能够找到,减少select*
会在explain的最后一列Extra中显示——正常没有使用条件中包含索引的列,会显示Using where; Using index,性能比较高(不需要回表查询);否则出现Using index condition性能比较低(回表查询了);NULL是回表查询
select * 减少使用,极易出现回表查询,降低性能
10)前缀索引——空间和效率的平衡
如果字符串类型很长的时候,直接建立索引会变得非常大,查询得时候会浪费大量得磁盘IO,影响查询效率。——只将字符串得一部分前缀建立索引,节约索引空间,提高索引效率
# 前缀的长度可以根据索引的选择性来决定,而选择性是指不重复的索引值和数据表的记录总数的比值,索引的选择性越高则查询效率越高
# 不重复数/总数=选择性
# 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
create index 索引名 on 表名(column(n));
11)单列索引和联合索引的选择
看select需要的数据,如果只要一列,那单列索引就可以,否则还需要回表查询,就转战联合索引。
2.7 索引设计原则
1)针对数据量大(百万级),且查询比较频繁的表建立索引
2)针对常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
3)尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
4)如果是字符串类型的字段,字段的长度较长,可以针对字段的特点,建立前缀索引
5)尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表
6)控制索引的数量,数量越多,维护索引结构的代价就越大,会影响增删改的效率
7)如果索引列不能存储NULL,要在见表的时候使用NOT NULL进行约束。优化器知道每列是否包含NULL,可以更好地切丁哪个索引最有效地用于查询
3. SQL优化🌽
3.1 插入数据
传统一条一条插入
1)批量插入:500-1000条一次
2)手动提交事务
3)主键顺序插入
4)大批量插入数据——insert性能较低,可以使用MySQL数据库提供地load指令进行插入
# 客户端连接服务器时,加上参数--local-infile
mysql --local-infile -u root -p;# 设置全局参数local-infile为1,开启从本地加载文件导入数据地开关
set global local_infile = 1;# 执行load指令将准备好地数据,加载到表结构中
load data local infile '/root/sql/tb_sku1.sql(数据源地址)' into table `tb_sku(表明)` fields terminated by ',' lines terminated by '\n';
3.2 主键优化
顺序插入比乱序插入(页分裂,删除数据时页合并)快
InnoDB存储引擎中数据组织方式:按主键顺序组织存放,这种存储方式地表称为索引组织表(index organized table, IOT)
主键设计原则:
1)在满足业务需求的情况下,尽量降低主键的长度
- 主键作为二级索引的叶子节点,如果太长会占用空间
- 搜索时耗费磁盘IO
2)插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
3)尽量不要使用UUID(JAVA中生成随机字符串的一个类方法)做主键或者其他自然主键
4)业务操作时,避免对主键的修改
3.3 order by 优化
分类:
1)Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作——通过索引不直接返回排序结果——>创建联合索引,防止索引失效——>创建索引的时候可以指定排序方式
2)Using index:通过有序索引顺序扫描直接返回有序数据——不需要额外排序
优化:
1)根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则
2)尽量使用覆盖索引
3)多字段排序,一个升序一个降序,可以在联合索引创建时建立规则(ASC/DESC)
4)如果不可避免出现filesort,大量数据排序时,可以适当增大排序缓冲区的大小sort_buffer_size(默认256K)
3.4 group by 优化
在分组操作时,可以通过索引来提高效率
分组操作时,索引的使用也满足最左前缀法则
3.5 limit 优化
问题: 大数据量的时候,越往后,效率越低
优化:
覆盖查询——避免回表
+
子查询形式——其实也是在回表阶段给简化了
3.6 count 优化
问题: InnoDB引擎执行count(*)的时候,需要把数据一行一行地从引擎中读出来,然后累积计数
注: MyISAM引擎把一个表地总行数存在了磁盘上,没有where条件地时候,就会直接返回这个数,效率很高。
优化思路: 自己计数,在Redis中保存一个数来记录
count的几种用法:
count()会一行一行数据进行判断,如果count函数的参数不是NULL,累计值就加1,否则不加
用法:
count(*) ——总记录数,不取值直接累加
count(主键) ——直接累加,不用判断null
count(字段) ——没加NOT NUL约束,如果NULL不加
count(1) ——InnoDB引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”,直接按行进行累加。
优化: count(*) ~ count(1) > count(主键id) > count(字段)
3.7 update 优化
没有索引就会锁住整张表
优化: 根据索引字段进行更新,并且索引字段不能失效,否则行锁就会升级为表锁,影响并发性能
4. 视图/存储过程/触发器🥬——存储对象
4.1 视图
概念: 虚拟存在的表(可以像操作表一样对视图进行操作),使用视图时是动态生成的——视图只保存了查询的SQL逻辑,不保存查询结果。
操作:
# 创建视图
create or replace view 视图名[(列名列表)] as select …… [with[cascaded|local] check option];
# [with[cascaded|local] check option]
# 如果加了检查语句,通过检查语句的记录才会被添加;如果不加检查语句,任意一条记录都可以被添加# 查询
-- 查看创建视图语句
show create view 视图名称;
-- 查看视图数据
select * from 视图名称;# 修改
-- 新建或者替换
create or replace view 视图名称[(列名列表)] as select语句 [with[cascaded|local] check option];
-- 真正的修改
alter view 视图名称[(列名列表)] as select语句 [with[cascaded|local] check option];# 删除
drop view [if exists] 视图名称 [,视图名称] ……
视图的检查选项:
- cascaded(级联): 创建视图时如果指定了cascaded选项,这个视图基于的视图都会被检查;基于创建了检查选项的视图创建的心视图,如果没有设置检查选项,本条不会被检查。传递的——with cascaded check option == with check option
- local: 创建视图时如果指定了local选项,这个视图基于的视图如果定义了检查选项,那就检查一下,如果没有定义那就不检查了——不传递,不会把自己的带给自己基于的视图
视图的更新:——修改视图会对原表的数据进行修改
- 条件: 视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,视图不可更新:①聚合函数/窗口函数(SUM()、MIN()、MAX()、COUNT());②Distinct;③Group by;④having;⑤union或union all
视图作用:
- 简单: 经常使用的查询可以定义为视图,之后的操作每次就不用指定全部的条件了
- 安全: 数据库不能授权到特定的行/列上。视图可以让用户看到只让他们查询或修改的数据
- 数据独立: 屏蔽基表的结构变化对查询带来的影响
4.2 存储过程
概念: 多次操作数据库,涉及多次网络请求——>在MySQL中将多个操作放在一个集合中,用的时候去调这个集合(数据库中可以有很多个这样的集合),减少数据在数据库和应用服务器之间的传输,提高数据处理的效率。
缺点: 存储过程难以调用和扩展,更没有移植性
特点:
- 封装、复用
- 可以接收参数,也可以返回数据
- 可以见减少应用服务和数据库之间的网络交互,提升效率
存储过程:
# 创建
create procedure 存储过程名称([参数列表])
begin--SQL语句
end;# 在命令行下创建存储过程时,要通过关键字delimiter指定SQL语句的结束符
-- 因为SQL语句中包含分号,命令行会以为输入结束,但实际创建指令还没输入完成
delimiter $$ -- 会以$$为结束符
create procedure cout_user ()
beginselect count(*) from user;
end$$# 调用
call 名称([参数]);# 存储过程——计算user表中的总记录数
create procedure cout_user ()
beginselect count(*) from user;
end;-- 调用
call cout_user();-- 查看
select * from information_schema.ROUTINES where ROUTINE_SCHEMA = 'test';-- 查看定义存储过程时的SQL语句
show create procedure cout_user;-- 删除
drop procedure if exists cout_user;
存储过程中的语法
1)变量
系统变量: MySQL服务器提供的,不是用户定义的。分为全局变量(GLOBAL)、会话变量(SESSION)
# 查看
show [session|global] variables; -- 查看所有系统变量,默认是session。session就是本次会话,global就是其全部会话,但是重启后就回复默认,永久修改要修改配置文件
show [session|global] variables like '……'; -- 可以通过LIKE模糊匹配的方式查找变量
select @@[session|global] 系统变量名; -- 查看指定变量的值# 设置系统变量
set [session|global] 系统变量名 = 值;
set @@[session|global]系统变量名 = 值;
用户定义变量: 不用提前声明,在用的时候直接’@变量名‘使用,作用域为当前连接
# 赋值
-- 赋值
set @myname = 'xy';
set @myage := 18; # 推荐使用,与比较运算符==区分
set @mygender = '女', @myhobby := 'java';select @mycolor := 'blue';
select count(*) into @mycount from user;-- 使用
select @myname, @myage, @mygender, @myhobby;select @mycolor, @mycount;
局部变量: 根据需要定义的在局部生效的变量,访问前,需要declare声明。可用作存储过程内的局部变量和输入参数,作用范围是begin……end
create procedure p1()
begin# 声明declare stu_count int default 0;# 赋值set stu_count := 100;select count(*) into stu_count from user;select stu_count;
end;call p1();
2)if判断
if 条件1 then……
elseif 条件2 then……
else……
end if;
3)参数
# 参数类型
-- IN 该类参数作为输入,也就是需要调用时传入值
-- OUT 该类参数作为输出,也就是该参数可以作为返回值
-- INOUT 既可以作为输入参数,也可以作为输出参数# 用法
create procedure 存储过程名称([IN/OUT/INOUT 参数名 参数类型])
begin-- SQL语句
end;
4)case
# 语法一
case case_valuewhen 条件一 then ……else ……
end case;# 语法二
casewhen 条件一 then ……else ……
end case;
5) while
# 语法
# 先判断条件,如果条件为true,则执行逻辑,否则,不执行逻辑
WHILE 条件 DOSQL逻辑
END WHILE;
-- 计算1-n的和
create procedure p(in n int)
begindeclare total int default 0;while n > 0 doset total := total + n;set n := n - 1;end while;select total;
end;
call p(100);
6)repeat——满足条件则退出循环
repeatSQL逻辑until 条件
end repeat;
7)loop
[begin_label:] loopSQL逻辑end loop [end_label];
LEAVE label; -- 退出指定标记的循环体(相当于break)
ITERATE label; -- 直接进入下一次循环(相当于continue)
8)游标
概念: 用来存储查询结果集的数据类型 ,在存储过程和函数中可以使用游标对结果集进行循环处理。(类似集合、list)
内容: 声明、OPEN、FETCH、CLOSE
# 声明游标 注:先声明普通变量,再声明游标
declare 游标名称 cursor for 查询语句; -- 将查询语句的结果存在游标中# 打开游标
open 游标名称;# 获取游标记录
fetch 游标名称 into 变量 [, 变量]; -- 将游标中包含的多条数据记录,每次提取一条(配合while使用)# 关闭游标
close 游标名称;
9)条件处理程序
用来定义再流程控制结构执行过程中遇到问题时相应的处理步骤
# 声明
declare handler_action handler for condition_value [, condition_value] … statement;/*
handler_actioncontinue 继续执行当前程序exit 终止执行当前程序
condition_valuesqlstate '状态码'sqlwarning 所有以01开头的状态码的简写not found 所有以02开头的状态码的简写sqlexception 没有被以上两种捕获的状态
*/
10)存储函数——存储过程的特殊情况,参数为in,必须有返回值,独特的是他有自己的语法
create function 存储函数名称([参数列表])
returns type [characteristic…]
beginSQL语句return……;
end;/*
characteristic说明——必须有,否则会报错
deterministic:相同的输入参数总是产生相同的结果
no sql:不包含sql语句
reads sql data:包含读取数据的语句,但不包含写入数据的语句
*/
4.3 触发器
1)概念——数据库管理员可以监控到所有用户操作数据库的每一条操作信息
触发器是与表有关的数据库对象,在insert/update/delete之前或之后,触发并执行触发器中定义的SQL语句集合
作用: 在数据库端确保数据的完整性、日志记录、数据校验等操作
使用别名OLD和NEW来引用触发器中发生变化的记录内容
注: 现在触发器只支持行级触发器(执行一个SQL语句,影响了多少行就执行多少次),不支持语句级触发器(执行一个SQL语句,不管影响了多少行,只执行一次)

before——在操作数据前 ,对数据进行合法性检查
2)语法
# 创建
create trigger 触发器的名字
before/after insert/update/delete
on 表名 for each row -- 行级触发器
begintrigger_stmt;
end;# 查看
show trigger;# 删除
drop trigger [schema_name.]trigger_name; -- 如果没有指定schema_name,默认是当前数据库
3)应用场景
- 记录操作日志
- 数据校验
5. 锁🥦
5.1 概述
计算机协调多个进程或线程并发访问某一资源的机制,数据库中的锁也是想让共享数据能保证并发访问的一致性和有效性
锁冲突也是影响数据库并发访问性能的一个重要因素
分类——粒度
- 全局锁: 锁住数据库中的所有表
- 表级锁: 每次操作锁住整张表
- 行级锁: 每次操作锁住对应的行数据
5.2 全局锁
应用场景: 全库的逻辑备份,对所有表进行锁定,从而获取一致性视图,保证数据的完整性
# 加锁
flush tables with read lock;
# 备份操作
mysqldump -u 用户名 -p 密码 数据库名 > 备份文件名 -- 不是sql语句,命令行就行,不用在mysql中执行
# 释放锁
unlock tables;
问题:
- 如果在主库上备份,备份期间都不执行更新,业务停摆
- 如果在从库上备份,在备份期间,从库不能执行主库同步过来的二进制日志,导致主从延迟
InnoDB中不加锁实现一致性数据备份
# 在备份时加入参数--single-transaction
mysqldump --single-transaction -uroot -p 123456 数据库名 > 备份文件名
5.3 表级锁
锁定粒度大,发生锁冲突的概率最高,并发度最低
分类
1)表锁
- 表共享读锁(read lock):只能读不能写,不会阻塞其他客户端的读,会阻塞其他客户端的写,释放掉锁之后,就可以执行写
- 表独占写锁(write lock):能读能写,其他客户端不能读也不能写
# 加锁
lock tables 表名(可以是多个表) read/write;
# 释放锁
unlock tables; / 客户端断开连接
2)元数据锁(meta data lock,MDL)
系统自己加的,在有事务的时候,事务中进行查询,系统就会自动加上共享读锁SHARED_READ,另一个事务进行插入、更新、删除操作的时候,系统会自动加上共享写锁SHARED_WRITE,他俩是兼容的,事务提交后就释放掉。但是修改表结构也就是alter table的时候,系统会加上EXCLUSIVE锁,是排他锁,可以理解为修改表结构,那么增删改查都不能同时进行的。
# 查看元数据锁的语法
select object_type, object_schema, object_name, lock_type, lock_duration from performance_schema.metadata_locks;
3)意向锁
解决:在加入行锁的时候对表加上意向锁,再来一个线程想要对该表进行加锁,那么就检查想要加的锁和意向锁列表能不能是兼容的,能兼容就加,互斥的情况就阻塞等待着
意向锁分类
- 意向共享锁(IS):与表锁共享锁(read)兼容,与表锁排他锁(write)互斥
- 意向排他锁(IX):与表锁共享锁(read)及排他锁(write)都互斥。意向锁之间不会互斥
# 查看意向锁及行锁的加锁情况
select object_type, object_schema, object_name, lock_type, lock_duration from performance_schema.data_locks;
5.4 行级锁
概念: 每次操作锁住对应的行数据。锁粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中
InnoDB数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。——如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,此时会升级为表锁
分类
-
行锁(Record Lock):锁定单个行记录,防止其他事务对此行进行update和delete。在RC和RR隔离级别下都支持——事务!!开始事务自动加锁,事务提交自动释放锁。
共享锁(S):允许一个事务读一杠,其他事务不能来排他锁
排他锁(X):这一行不能有共享锁和排他锁啦,其他行请随意

-
间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持
索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁
索引上的等值查询(普通索引),最后一个值不满足查询需求,退化为间隙锁——前后都加,本条记录也加
索引上的范围查询(唯一索引),访问到第一个不满足条件的值为止
目的:防止其他事务插入间隙
-
临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持——避免幻读现象
6. InnoDB引擎🌶️
6.1 逻辑存储结构

6.2 架构
擅长事务处理,具有崩溃恢复特性
InnoDB架构
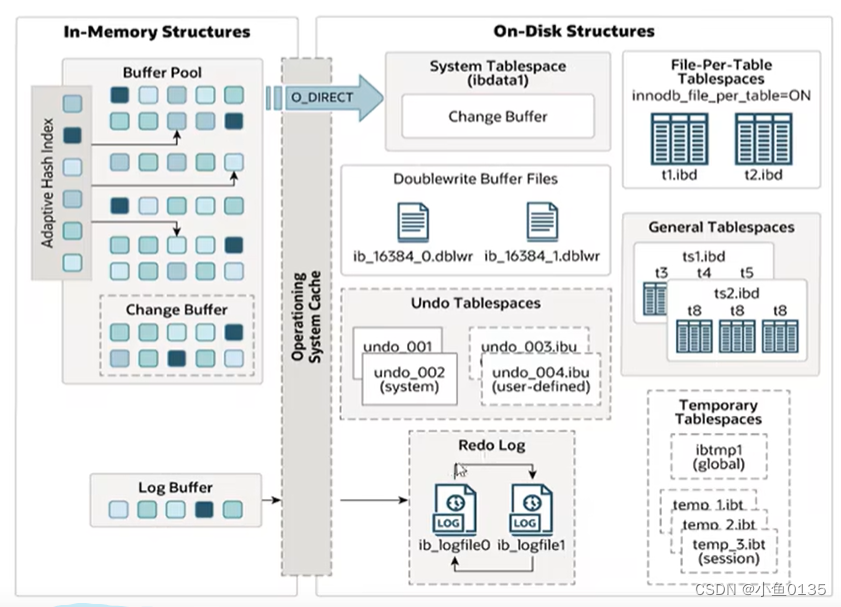
内存
Buffer Pool: 缓冲池,缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(如果缓冲池中没有,就从磁盘加载并缓存),然后再以一定的频率刷新到磁盘,从而减少磁盘IO,加快处理速度
缓冲池是以page页为单位,底层采用链表数据结构管理Page(不同小块的颜色表示不同的Page类型:free page表示空闲page,未被使用;clean page表示被使用page,数据没有被修改过;dirty page表示脏页,是被使用过的,数据被修改过,并且与磁盘数据产生了不一致)
Change Buffer: 更改缓冲区(针对于非唯一二级索引页——>插入顺序是相对随机的,删除和更新可能会影响索引树中不相邻的二级索引页)也就是如果操作的数据没在Buffer pool那就先修改到change Buffer中,等到bufferpool中有了,再一起合并到Buffer pool,然后等待机会刷新到磁盘中
Adaptive Hash Index: 自适应哈希索引,InnoDB是不支持这个索引的,他是用来优化对Buffer Pool数据的查询。InnoDB存储引擎会监控对表上各索引页的查询,如果察觉到hash可以提升速度没那就建立hash索引,无需人工干预。参数是:adaptive_hash_index
log buffer: 日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log、undo log),默认大小是16MB,日志缓冲区的日志会定期刷新到磁盘中。如果更新、插入、删除操作比较多,增加日志缓冲区的大小可以节省磁盘I/O。参数innodb_log_buffer_size:缓冲区大小;innodb_flush_log_at_trx_commit:日志刷新到磁盘的时机
磁盘
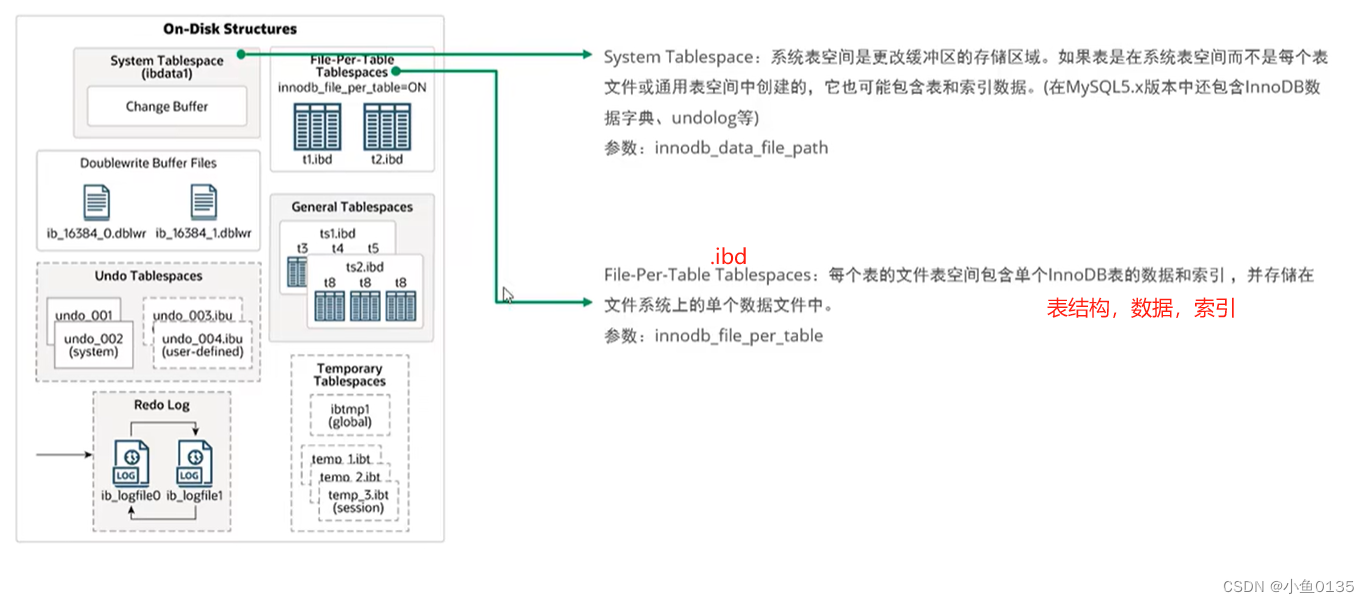
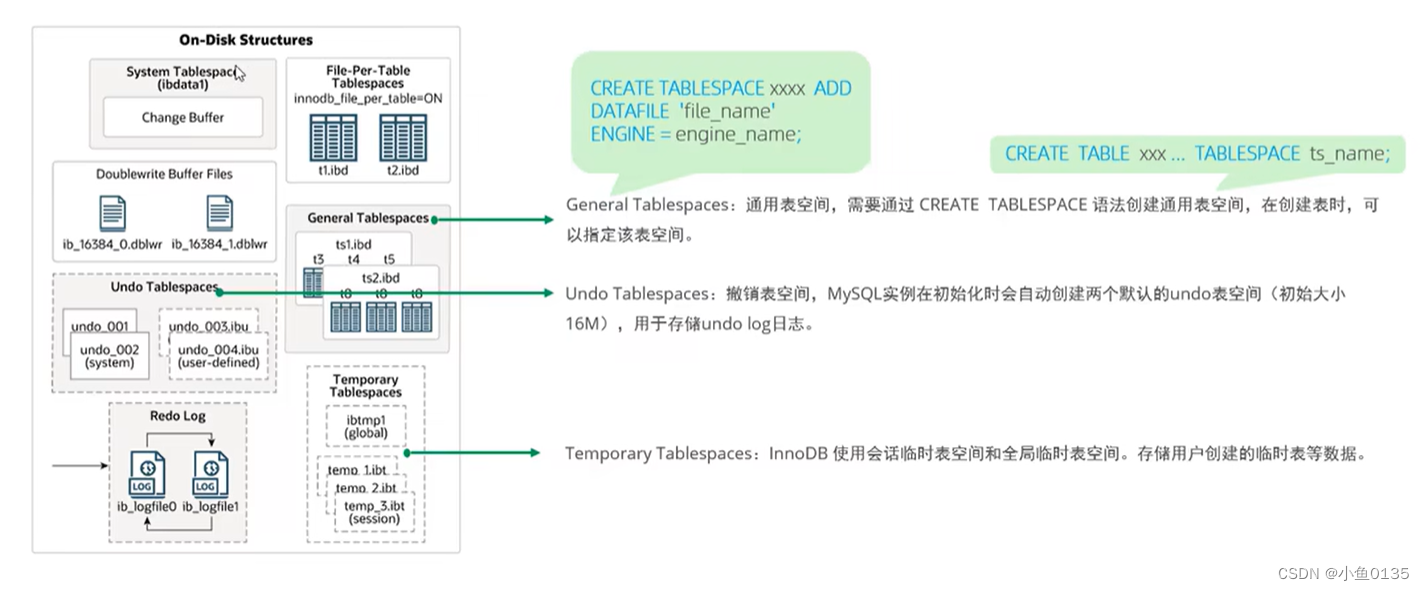
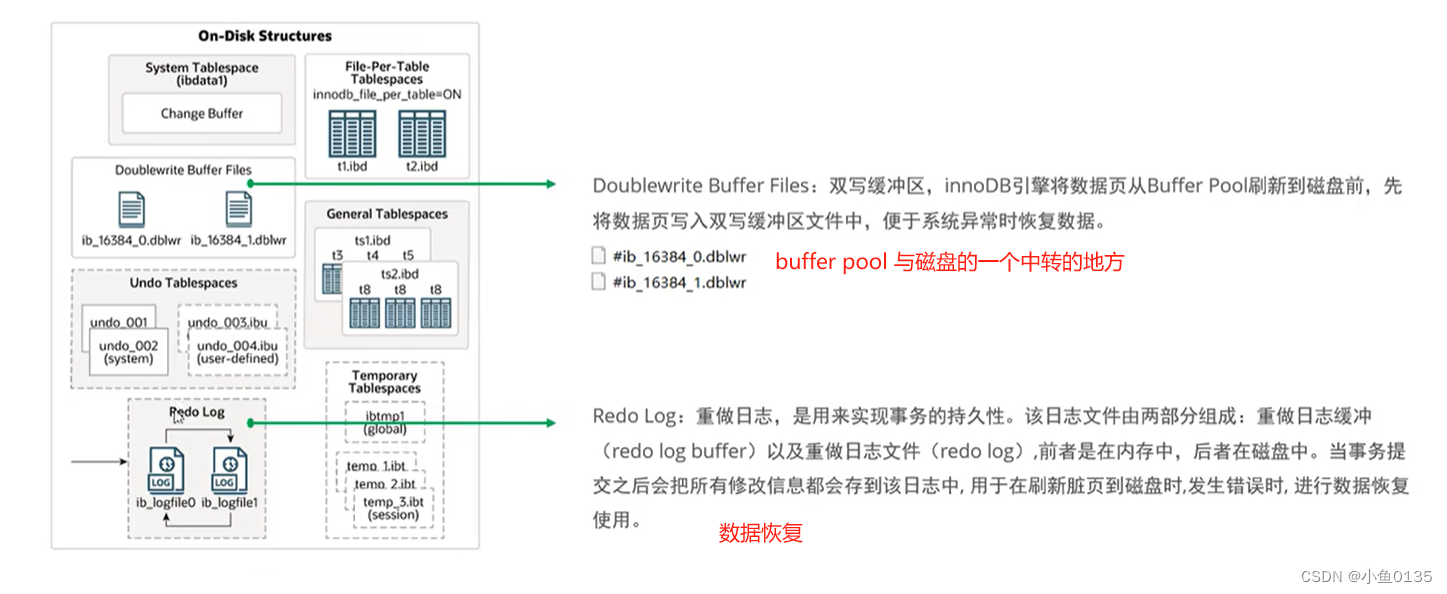
内存中的数据如何刷入磁盘——后台线程

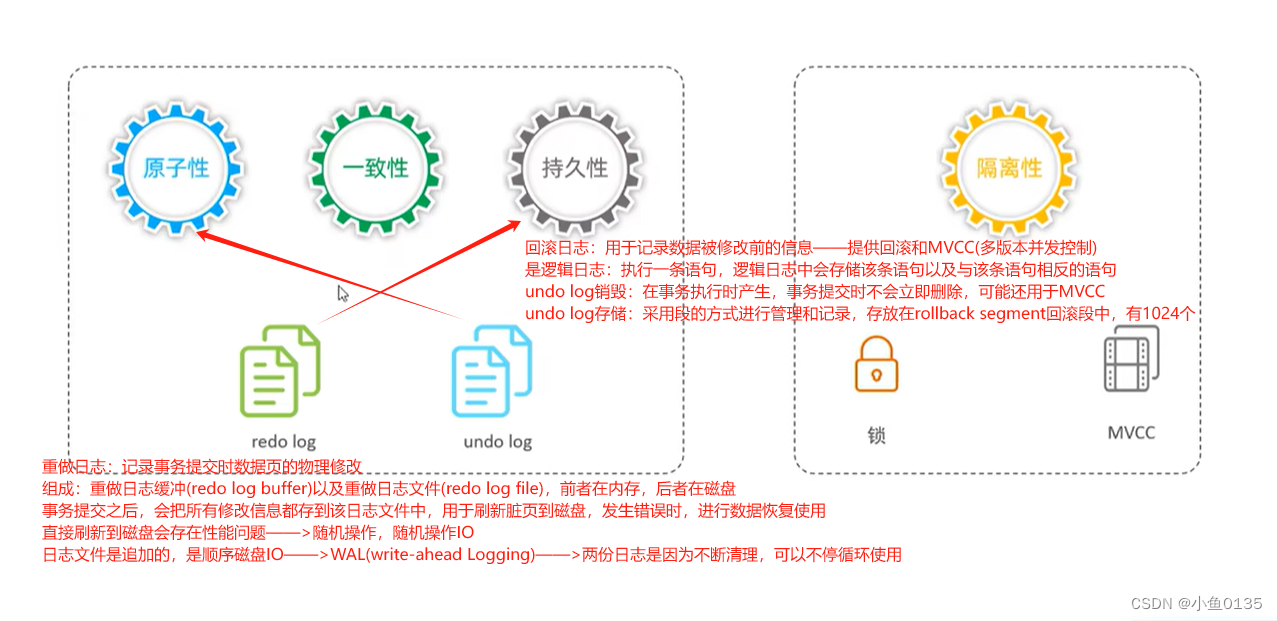
6.3 事务原理
也就是如何保证的事务的四个特性
6.4 MVCC——高频面试
基本概念
当前读: 读取的是记录的最新版本,读取时要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁(select…lock in share mode、select …for update\update\insert\delet,都是一种当前读)——如果不是当前读,另一个事务修改了数据,是读不到最新数据的
快照读: 简单的select(不加锁)就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读
- Read Committed:每次select,都生成一个快照读
- Repeatable Read:开启事务后第一个select语句是快照读的地方
- Serializable:快照读会退化为当前读
**MVCC(Multi-Version Concurrency Control, 多版本并发控制):**维护一个数据的多个版本,使读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。实现依赖于数据库中的三个隐式字段、undo log日志、readView
1)三个隐藏字段——每一条记录
DB_TRX_ID: 最近修改事务的ID,记录插入或最后一次修改该记录的事务ID
DB_ROLL_PTR: 回滚指针,指向该记录的上一个版本,用于配合undo log
DB_ROW_ID: 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段——如果表存在主键,就不会生成该隐藏字段
2)undo log日志
回滚日志是在insert、update、delete的时候产生的便于数据回滚的日志。insert的时候,产生的undo log日志只在回滚时需要,事务提交之后,可被立即删除;在update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读的时候也需要,不会被立即删除 (快照读时读取的是旧的数据)
undo log 版本链 :链表
3)readview(读视图)
是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id
四个核心字段
- m_ids: 当前活跃的事务ID集合
- min_trx_id: 最小活跃事务ID
- max_trx_id: 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的)
- creatoe_trx_id: readview创建者的事务ID
版本链数据访问规则
trx_id:代表当前事务ID
①trx_id == creator_trx_id? 可以访问该版本——>成立,说明数据是当前这个事务更改的
②trx_id < min_trx_id? 可以访问该版本——> 成立,说明数据已经提交了
③trx_id > max_trx_id ? 不可访问该版本——>成立,说明该事务时在Readview生成后才开启的
④min_trx_id <= trx_id <= max_trx_id ? 如果trx_id不在m_ids中是可以访问该版本的——> 成立,说明数据已经提交
不同的隔离级别,生成readview的时机不同
- read commited :在事务中每一次执行快照读时生成readview;在读取的时候保证读已提交
- repeatable read:尽在事务中第一次执行快照读的时候生成,后续复用该readview
7. MySQL管理🌰
7.1 系统数据库
1)mysql:存储MySQL服务器正常运行所需要的各种信息(时区、主从、用户、权限等)
2)information_schema:提供了访问数据库元数据的各种表和视图,包括数据库、表、字段类型及访问权限等
3)performance_schema:为MySQL服务器运行时状态提供了一个底层监控功能,主要用于收集数据库服务器性能参数
4)sys:包含了一系列方便DBA和开发人员利用performance_schema性能数据库进行性能调优和诊断的视图
7.2 常用工具
客户端工具
# 1. mysql
# 语法
mysql [options] [database]
# 选项
-u --user=name # 指定用户名
-p --password[=name] # 指定密码
-h --host=name # 指定服务器IP或域名
-P --port=port # 指定连接端口
-e --execute=name # 执行sql语句并退出,连接数据库的时候处理一些脚本,很方便# 2. mysqladmin 是一个执行管理操作的客户端程序,可以用它来检查服务器的配置和当前状态、创建并删除数据库等。# 3. mysqlbinlog 由于服务器生成的二进制日志文件以二进制格式保存,如果想要检查这些文本的文本格式,就会用到mysqlbinlog日志管理工具
mysqlbinlog [options] log-files1 log-files2...-d --database=name # 指定数据库名称,只列出指定的数据库相关操作
-o --offset # 忽略掉日志中前n行命令
-r --result-file=name # 将输出的文本格式日志输出到指定文件
-s --short-form # 显示简单格式,省略掉一些信息
--start-datatime=date1 --stop-datetime=date2 # 指定日期间隔内的所有日志
--start-position=pos1 --stop-position=pos2 # 指定位置间隔内的所有日志# 4. mysqlshow 客户端对象查找工具,用来很快地查找存在哪些数据库、数据库中的表、表中的列或者索引
mysqlshow [options][db_name[table_name[col_name]]]
--count # 显示数据库及表的统计信息(数据库,表均可以不指定)
-i # 显示指定数据库或指定表的状态信息# 5. mysqldump客户端工具用来备份数据库或在不同的数据库之间进行数据迁移。备份内容包含创建表以及插入表的SQL语句
# 语法
mysqldump [options] db_name[tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
# 连接选项
-u --user=name # 指定用户名
-p --password[=name] # 指定密码
-h --host=name # 指定服务器ip或域名
-P --port # 指定连接端口
# 输出选项
--add-drop-database # 在每个数据库创建语句前面加上drop database语句
--add-drop-table # 在每个表创建语句前加上drop table语句,默认开启;不要开的话(--skip -add-drop-table)
-n --no-create-info # 不包含表的创建语句
-t --no-create-db # 不包含数据库的创建语句
-d --no-data # 不包含数据
-T --tab=name # 自动生成两个文件,一个.sql文件,创建表结构的语句;一个.txt文件,数据文件# 6. mysqlimport/source数据导入工具。用于导入mysqldump加-T参数后导出的文本文件
# 语法
mysqlimport [options] db_name textfiles [textfiles2...]
# 如果需要导入sql文件,可以使用mysql中的source指令
source/root/xxx.sql
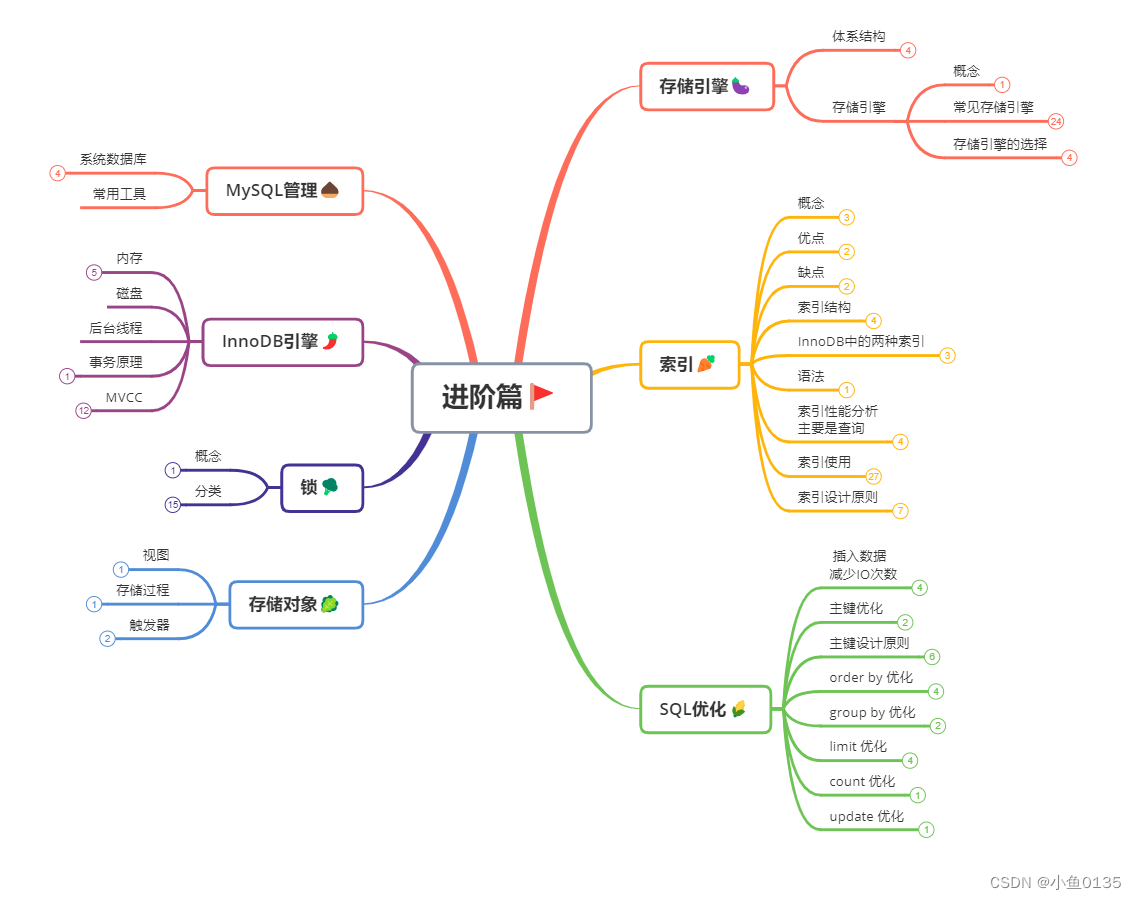
总结
相关文章:
MySQL——进阶篇
二、进阶篇🚩 1. 存储引擎🍆 1.1 MSQL体系结构 连接层: 连接处理,连接认证,每个客户端的权限 服务层: 绝大部分核心功能,可跨存储引擎 可插拔存储引擎: 需要的时候可以添加或拔掉…...

Python 网络编程之搭建简易服务器和客户端
用Python搭建简易的CS架构并通信 文章目录 用Python搭建简易的CS架构并通信前言一、基本结构二、代码编写1.服务器端2.客户端 三、效果展示总结 前言 本文主要是用Python写一个CS架构的东西,包括服务器和客户端。程序运行后在客户端输入消息,服务器端会…...

往年面试精选题目(前50道)
常用的集合和区别,list和set区别 Map:key-value键值对,常见的有:HashMap、Hashtable、ConcurrentHashMap以及TreeMap等。Map不能包含重复的key,但是可以包含相同的value。 Set:不包含重复元素的集合&#…...

解决服务器Tab键不能补全问题
编辑~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml 命令:vim ~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml替换:<property name“<Super>Tab” type“string” value“switch_window…...

人工智能 机器学习 深度学习:概念,关系,及区别说明
如果过去几年,您读过科技主题的文章,您可能会遇到一些新词汇,如人工智能(Artificial Intelligence)、机器学习(Machine Learning)和深度学习(Deep Learning)等。这三个词…...
数据库——LAMP的搭建及MySQL基操
1.实验内容及原理 1. 在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,并在 Ubuntu 中搭建 LAMP 实验环境。 2. 使用 MySQL 进行一些基本操作: (1)登录 MySQL,在 MySQL 中创建用户,并对…...

抗原设计与兔单B细胞技术的结合-卡梅德生物
随着生物医学研究的不断深入,抗体疗法作为治疗疾病的有力工具逐渐成为研究的焦点。而兔单B细胞技术作为抗体研究的创新方法,其与抗原设计的有机结合为获取定制抗体打开了崭新的创新之路。本文将深入探讨抗原设计与兔单B细胞技术相互融合的原理、优势&…...

在uniapp中使用背景渐变色与背景图不生效问题
list上有文字详情以及背景图,从背景可以看出是渐变色和 背景图片的结合。 因为使用到渐变色,所以要结合 background-blend-mode 属性来实现与背景图片叠加显示,否则只通过 background: linear-gradient(); background-image: url(); 设置不会…...

Java中XML的解析
1.采用第三方开元工具dom4j完成 使用步骤 1.导包dom4j的jar包 2.add as lib.... 3.创建核心对象, 读取xml得到Document对象 SAXReader sr new SAXReader(); Document doc sr.read(String path); 4.根据Document获取根元素对象 Element root doc.getRootElement(); …...

React快速入门之交互性
响应事件 创建事件处理函数 处理函数名常以handle事件名命名 function handlePlayClick() {alert(Playing);}传递事件处理函数 函数名、匿名两种方式! function PlayButton() {function handlePlayClick() {alert(Playing);}return (<Button handleClick{handl…...

浅谈WPF之ToolTip工具提示
在日常应用中,当鼠标放置在某些控件上时,都会有相应的信息提示,从软件易用性上来说,这是一个非常友好的功能设计。那在WPF中,如何进行控件信息提示呢?这就是本文需要介绍的ToolTip【工具提示】内容…...

Android Studio 如何隐藏默认标题栏
目录 前言 一、修改清单文件 二、修改代码 三、更多资源 前言 在 Android 应用中,通常会有一个默认的标题栏,用于显示应用的名称和一些操作按钮。但是,在某些情况下,我们可能需要隐藏默认的标题栏,例如自定义标题栏…...

对于c++的总结与思考
笔者觉得好用的学习方法:模板法 1.采用原因:由于刚从c语言面向过程的学习中解脱出来,立即把思路从面向过程转到面向对象肯定不现实,加之全新的复杂语法与操作,着实给新手学习这门语言带来了不小的困难。所以ÿ…...

Flask 账号详情展示
Flask 账号详情展示 这段代码是一个基于Flask框架的Python应用程序。 它包含了两部分代码:Python代码和HTML代码。 web/templates/common/tab_account.html <div class"row border-bottom"><div class"col-lg-12"><div cla…...

软件测试/测试开发丨Pytest 参数化用例
参数化 通过参数的方式传递数据,从而实现数据和脚本分离。并且可以实现用例的重复生成与执行。 参数化应用场景 测试登录场景 测试登录成功,登录失败(账号错误,密码错误)创建多种账号: 中⽂文账号,英⽂文账号 普通测试用例方法 …...
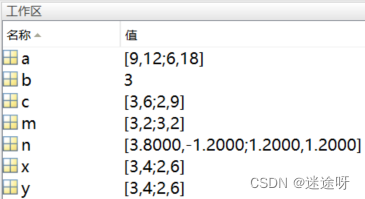
MATLAB中./和/,.*和*,.^和^的区别
MATLAB中./和/,.*和*,.^ 和^ 的区别 MATLAB中./和/,.*和*,.^ 和^ 的区别./ 和 / 的区别.//实验实验结果 .* 和 * 的区别.**实验实验结果 .^ 和^ 的区别.^n^n实验运行结果 MATLAB中./和/,.和,.^ 和^ 的区别 …...
Flask 与微信小程序对接
Flask 与微信小程序的对接 在 web/controllers/api中增建py文件,主要是给微信小程序使用的。 web/controllers/init.py # -*- coding: utf-8 -*- from flask import Blueprint route_api Blueprint( api_page,__name__ )route_api.route("/") def ind…...

node.js express框架开发入门教程
文章目录 前言一、Express 生成器(express-generator)二、快速安装1.express框架express-generator生成器安装2.使用pug视图引擎创建项目,projectName 为项目名称自定义 三、安装热更新插件 nodemon四、目录结构1. public文件夹2.routes路由其他请求方式…...
Spring系列学习二、Spring框架的环境配置
Spring框架的环境配置 一、Java环境配置二、 Spring框架的安装与配置三、Maven与Gradle环境的配置四、IDE环境配置(Eclipse与IntelliJ IDEA)五、结语 一、Java环境配置 所有编程旅程总是得从基础开始,如同乐高积木大作的基座,首先…...

基于飞浆OCR的文本框box及坐标中心点检测JSON格式保存文本
OCR的文本框box及JSON数据保存 需求说明 一、借助飞浆框出OCR识别的文本框 二、以圆圈形式标出每个框的中心点位置 三、以JSON及文本格式保存OCR识别的文本 四、以文本格式保存必要的文本信息 解决方法 一、文本的坐标来自飞浆的COR识别 二、借助paddleocr的draw_ocr画出…...

告别虚拟机卡顿:在Ubuntu 18.04上为ARM板交叉编译Qt5.12.9的完整配置流程
突破虚拟机性能瓶颈:Ubuntu 18.04下高效交叉编译Qt5.12.9的工程实践 当你在40GB磁盘空间的Ubuntu虚拟机上尝试编译Qt5.12.9时,解压后的2.8GB源码目录和漫长的编译等待时间可能已经让你抓狂。这不是个例——嵌入式开发工程师经常面临这样的困境࿱…...

从Dubbo超时到内存锯齿:高并发服务JVM调优与大对象排查实战
1. 项目背景与问题初现做后端服务开发,尤其是高并发场景下的核心服务,最怕的就是线上服务“抽风”——平时跑得好好的,一到业务高峰期就出现各种超时、失败。最近我就遇到了一个典型的案例,我们团队负责的一个音乐核心服务&#x…...

CANN ops-fft未来规划:51+接口路线图与社区发展蓝图
CANN ops-fft未来规划:51接口路线图与社区发展蓝图 【免费下载链接】ops-fft ops-fft 是 CANN (Compute Architecture for Neural Networks)算子库中提供 FFT 类计算的基础算子库,采用模块化设计,支持灵活的算子开发和…...

Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案
Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC版本以其卓越的稳…...
)
FPGA 51,基于 ZYNQ 7Z010 的 FPGA 高速路由转发加速系统架构设计(Xilinx ZYNQ-MINI 7Z010 CLG400 -1)
目录 前言 一、系统整体架构设计 1.1 设计目标与性能指标...

树莓派网页编辑器:云端开发环境革新与实战指南
1. 项目概述:一次开发体验的“降维”革新最近,树莓派基金会悄无声息地放出了一个重磅工具:一个可以直接在网页浏览器里运行的代码编辑器。这个消息乍一听,可能不如发布一块新的、性能翻倍的树莓派单板计算机那么激动人心ÿ…...

CANopen设备配置不求人:手把手教你用EDS/DCF文件玩转对象字典
CANopen设备配置实战:从EDS/DCF解析到对象字典高效配置 在工业自动化领域,CANopen协议因其开放性和灵活性成为设备互联的主流选择。而对象字典(Object Dictionary)作为CANopen设备的核心配置数据库,其管理效率直接影响项目开发周期。本文将带…...

智能视频转PPT:3分钟实现视频内容自动提取的完整方案
智能视频转PPT:3分钟实现视频内容自动提取的完整方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾为整理会议录像中的PPT内容而烦恼?手动暂停、截…...
)
告别环境冲突:用Conda+Docker在Win10上丝滑搭建MMDetection双环境(附CUDA 11.1/PyTorch 1.8配置)
深度学习环境工程化实践:Conda与Docker双方案打造MMDetection高效工作流 在Windows系统上搭建深度学习开发环境,就像在雷区跳舞——CUDA版本冲突、Python依赖不兼容、系统环境污染等问题随时可能引爆。以MMDetection为例,这个强大的目标检测工…...
云端物模型自定义)
硬件入门 + 单片机基础(第17天)云端物模型自定义
一、阿里云后台配置(添加 3 个标准属性)1. 进入物模型编辑页物联网平台 → 对应产品 → 功能定义 → 编辑物模型2. 逐个添加属性温度功能类型:设备属性功能名称:温度标识符:Temperature数据类型:浮点型&…...