Python初学者必须吃透的69个内置函数!


所谓内置函数,就是Python提供的, 可以直接拿来直接用的函数,比如大家熟悉的print,range、input等,也有不是很熟,但是很重要的,如enumerate、zip、join等,Python内置的这些函数非常精巧且强大的,对初学者来说,经常会忽略,但是偶尔会碰到,我也是用了一段时间python之后才发现,哇还有这么好的函数,每个函数都非常经典,而且经过严格测试,使用内置函数,不用自己闭门造车,并且代码简洁易读了很多,真是方便又实用,值得花时间进行体系化研究学习。
初学者的代码之所以写的不简洁,不是因为学的不够好,而是学的不够多,很多内置的东西都没学透。(初学者一定要买一本基础书籍了解语言的基本框架,推荐下面这一本,当然其他任何的书都可以)

一、数字相关
01 数据类型
bool()
描述: 测试一个对象是True, 还是False.bool 是 int 的子类。
语法: class bool([x])
参数: x – 要进行转换的参数。
bool([0,0,0])
Truebool([])
Falseissubclass(bool, int) # bool 是 int 子类
TrueTrue+True
212/True
12.0
int()
描述: int() 函数用于将一个字符串或数字转换为整型。 x可能为字符串或数值,将x 转换为一个普通整数。如果参数是字符串,那么它可能包含符号和小数点。如果超出了普通整数的表示范围,一个长整数被返回。
语法: int(x, base =10)
参数:
- x – 字符串或数字。
- base – 进制数,默认十进制。
int('12',16)
18int('12',10)
12
float()
描述: 将一个字符串或整数转换为浮点数
语法: class float([x])
参数: x – 整数或字符串
float(3)
3.0float('123') 123.0
complex()
描述:创建一个复数
语法:class complex([real[, imag]])
参数:
- real – int, long, float或字符串;
- imag – int, long, float;
complex(1,2)
(1+2j) complex('1')
(1+0j)
complex("1+2j")
(1+2j)
02 进制转换
bin()
描述:bin() 返回一个整数 int 或者长整数 long int 的二进制表示。将十进制转换为二进制
语法:bin(x)
参数:x – int 或者 long int 数字
bin(2)
'0b10'bin(20)
'0b10100'
oct()
描述: 将十进制转换为八进制 otc() 将给的参数转换成八进制
语法: oct(x)
参数: x – 整数。
oct(8)
'0o10'oct(43)
'0o53'
hex()
描述:hex() 函数用于将10进制整数转换成16进制,以字符串形式表示。
语法: hex(x)
参数: x – 10进制整数。
将十进制转换为十六进制
hex(43)
'0x2b'#43等于2Bhex(15)
'0xf'
03 数学运算
abs()
描述: 返回数字绝对值或复数的模
语法: abs( x )
参数: x 数值表达式。
abs(-6)
6
abs(5j+4)
6.4031242374328485
divmod()
描述: divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
语法: divmod(a, b)
参数: a: 数字–被除数
b: 数字–除数
divmod(11,3)
(3, 2)divmod(20,4)
(5, 0)
round()
描述: round() 函数返回浮点数x的四舍五入值。
语法: round( x [, n] )
参数:
- x – 数值表达式。
- n --代表小数点后保留几位
round(10.0222222, 3)
10.022
pow()
描述:pow( x,y ) 方法返回x的y次方的值,等价于x**y。函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
语法: pow(x, y[, z])
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
pow(10, 2)
10010**2
100pow(4,3,5)4
等价于4**3%
sum()
描述: sum() 方法对系列进行求和计算。
语法: sum(iterable[, start])
参数:
- iterable – 可迭代对象,如:列表、元组、集合。
- start – 指定相加的参数,如果没有设置这个值,默认为0。
a = [1,4,2,3,1]
sum(a)
11sum(a,10) #求和的初始值为10
21
min()
描述: min() 方法返回给定参数的最小值,参数可以为序列。
语法: min( x, y, z, … )
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
min(80, 100, 1000)
80
min([80, 100, 1000])
80
max()
描述: max() 方法返回给定参数的最大值,参数可以为序列。
语法: max( x, y, z, … )
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
最大值:
max(3,1,4,2,1)
4di = {'a':3,'b1':1,'c':4}
max(di)
'c'
二、数据结构相关
01 序列数据类型
1)列表和元组
list()
描述: list() 函数创建列表或者用于将序列转换为列表。
语法: list( iterable )
参数: iterable – 可迭代序列。
序列为元组时
s=(123, 'xyz', 'zara', 'abc')
list(S)
[123, 'xyz', 'zara', 'abc']
序列为字符串
s= '小伍哥真是帅,特别帅'
list(s)
['小', '伍', '哥', '真', '是', '帅', ',', '特', '别', '帅']
序列为字典
s = {'nanme':'小伍哥','age':30,'address':'Hangzhou'}
list(s)
['nanme', 'age', 'address']
tuple()
描述: 元组 tuple() 函数将列表转换为元组。
语法: tuple( iterable )
参数: iterable – 要转换为元组的可迭代序列。
tuple([1,2,3,4])
(1, 2, 3, 4)tuple({'a':2,'b':4}) #针对字典 会返回字典的key组成的tuple('a', 'b')tuple('小伍哥真是帅,特别帅')('小', '伍', '哥', '真', '是', '帅', ',', '特', '别', '帅')
2)集合数据类型
dict()
描述: 创建数据字典
语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数:
- **kwargs – 关键字
- mapping – 元素的容器。
- iterable – 可迭代对象。
#创建空字典
dict()
{}#传入关键字
dict(a='a', b='b', t='t')
{'a': 'a', 'b': 'b', 't': 't'}# 映射函数方式来构造字典
dict(zip(['one', 'two', 'three'], [1, 2, 3]))
{'three': 3, 'two': 2, 'one': 1} #可迭代对象方式来构造字典
dict([('one', 1), ('two', 2), ('three', 3)])
{'three': 3, 'two': 2, 'one':
set()
描述: set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
语法: class set([iterable])
参数: iterable – 可迭代对象对象;
#返回一个set对象,可实现去重:
a = [1,4,2,3,1]
set(a)
{1, 2, 3, 4}
frozenset()
描述: frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
语法: class frozenset([iterable])
参数: iterable – 可迭代的对象,比如列表、字典、元组等等。
创建一个不可修改的集合。
frozenset([1,1,3,2,3])
frozenset({1, 2, 3})
3)字符串
str()
描述: str() 函数将对象转化为适于人阅读的形式。将字符类型、数值类型等转换为字符串类型
语法: class str(object=‘’)
参数: object – 对象。
案例:
integ = 100
str(integ)
'100'dict = {'baidu': 'baidu.com', 'google': 'google.com'};
str(dict)
"{'baidu': 'baidu.com', 'google': 'google.com'}"
format()
描述: Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 % 。使用format()来格式化字符串时,使用在字符串中使用{}作为占位符,占位符的内容将引用format()中的参数进行替换。可以是位置参数、命名参数或者兼而有之。
format 函数可以接受不限个参数,位置可以不按顺序。
语法: format(value, format_spec)
参数:
# 位置参数
'{}:您{}购买的{}到了!请下楼取快递。'.format('快递小哥','淘宝','快递')
'快递小哥:您淘宝购买的快递到了!请下楼取快递。'#给批量客户发短息
n_list=['马云','马化腾','麻子','小红','李彦宏','二狗子']
for name in n_list:print('{0}:您淘宝购买的快递到了!请下楼取快递!'.format(name))
马云:您淘宝购买的快递到了!请下楼取快递!
马化腾:您淘宝购买的快递到了!请下楼取快递!
麻子:您淘宝购买的快递到了!请下楼取快递!
小红:您淘宝购买的快递到了!请下楼取快递!
李彦宏:您淘宝购买的快递到了!请下楼取快递!
二狗子:您淘宝购买的快递到了!请下楼取快递! #名字进行填充
for n in n_list:print('{0}:您淘宝购买的快递到了!请下楼取快递!'.format(n.center(3,'*')))*马云:您淘宝购买的快递到了!请下楼取快递!
马化腾:您淘宝购买的快递到了!请下楼取快递!
*麻子:您淘宝购买的快递到了!请下楼取快递!
*小红:您淘宝购买的快递到了!请下楼取快递!
李彦宏:您淘宝购买的快递到了!请下楼取快递!
二狗子:您淘宝购买的快递到了!请下楼取快递!'{0}, {1} and {2}'.format('gao','fu','shuai')
'gao, fu and shuai'x=3
y=5
'{0}+{1}={2}'.format(x,y,x+y)# 命名参数
'{name1}, {name2} and {name3}'.format(name1='gao', name2='fu', name3='shuai')
'gao, fu and shuai'# 混合位置参数、命名参数
'{name1}, {0} and {name3}'.format("shuai", name1='fu', name3='gao')
'fu, shuai and gao'#for循环进行批量处理
["vec_{0}".format(i) for i in range(0,5)]
['vec_0', 'vec_1', 'vec_2', 'vec_3', 'vec_4']['f_{}'.format(r) for r in list('abcde')]
['f_a', 'f_b', 'f_c', 'f_d',
bytes()
描述: 将一个字符串转换成字节类型
语法: class bytes([source[, encoding[, errors]]])
参数:
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
s = "apple"
bytes(s,encoding='utf-8')
b'apple'bytes([1,2,3,4])
b'\x01\x02\x03\x04'
bytearray()
描述: 返回一个新字节数组. 这个数字的元素是可变的, 并且每个元素的值得范围是[0,256)
语法: class bytearray([source[, encoding[, errors]]])
参数:
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
bytearray()
bytearray(b'')
bytearray([1,2,3])
bytearray(b'\x01\x02\x03')
bytearray('baidu', 'utf-8')
bytearray(b'baidu')
ord()
描述: 查看某个ascii对应的十进制数
语法: ord©
参数: c – 字符。
ord('A')
65ord('~')
126
chr()
描述: chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
语法: chr(i)
参数: i – 可以是10进制也可以是16进制的形式的数字。
查看十进制整数对应的ASCII字符
chr(65)
'A'
可以参考4案例中的表
ascii()
描述: ascii() 函数返回任何对象(字符串,元组,列表等)的可读版本。
ascii() 函数会将所有非 ascii 字符替换为转义字符:
å 将替换为 \xe5。
语法: ascii(object)
参数: object–对象,可以是元组、列表、字典、字符串、set()创建的集合。
ascii('中国')
"'\u4e2d\u56fd'"ascii('新冠肺炎')
"'\u65b0\u51a0\u80ba\uascii("My name is Ståle")
"'My name is St\xe5le'"print(ascii((1,2))) #元组
(1, 2)
print(type(ascii((1,2))))
<class 'str'>print(ascii([1,2])) #列表
[1, 2]
print(type(ascii([1,2])))
<class 'str'>print(ascii('?')) #字符串,非 ASCII字符,转义
'\uff1f'
print(type(ascii("?")))
<class 'str'>print(ascii({1:2,'name':5})) #字典
{1: 2, 'name': 5}
print(type(ascii({1:2,'name':5})))
<class '
ASCII码表具体如下所示(节选)
| Bin(二进制) | Oct(八进制) | Dec(十进制) | Hex(十六进制) | 缩写/字符 | 解释 |
|---|---|---|---|---|---|
| 0000 0000 | 00 | 0 | 0x00 | NUL(null) | 空字符 |
| 0010 0001 | 041 | 33 | 0x21 | ! | 叹号 |
| 0010 0010 | 042 | 34 | 0x22 | " | 双引号 |
| 0010 1010 | 052 | 42 | 0x2A | * | 星号 |
| … | … | … | … | … | … |
| 0111 1101 | 0175 | 125 | 0x7D | } | 闭花括号 |
| 0111 1110 | 0176 | 126 | 0x7E | ~ | 波浪号 |
| 0111 1111 | 0177 | 127 | 0x7F | DEL (delete) | 删除 |
repr()
返回一个对象的string形式
03 数据结构处理相关函数
len()
描述: len() 函数返回对象(字符、列表、元组等)长度或项目个数。
语法: len(s)
参数: s – 对象。
#字典的长度
dic = {'a':1,'b':3}
len(dic)
2#字符串长度
s='aasdf'
len(s)
5#列表元素个数
l = [1,2,3,4,5]
len(l)
sorted()
描述: sorted()函数对所有可迭代的对象进行排序操作。
语法: sorted(iterable, key=None, reverse=False)
参数:
- iterable–可迭代对象。
- key–主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse=True降序 ,reverse = False升序(默认)。
a = [5,7,6,3,4,1,2]
b = sorted(a) #保留原列表
a
[5, 7, 6, 3, 4, 1, 2]
b
[1, 2, 3, 4, 5, 6, 7]#利用key
L=[('b',2),('a',1),('c',3),('d',4)]sorted(L, key=lambda x:x[1])
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]#按年龄排序
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda s: s[2])
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]#按降序
sorted(students, key=lambda s: s[2], reverse=True)
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]#降序排列
a = [1,4,2,3,1]
sorted(a,reverse=True)
[4, 3, 2, 1, 1
sort 与 sorted 区别:
sort 是应用在list 的方法,sorted可以对所有可迭代的对象进行排序操作;list的sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数sorted方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
reversed()
描述: reversed函数返回一个反转的迭代器。
语法: reversed(seq)
参数: seq – 要转换的序列,可以是 tuple, string, list 或 range。
#反转列表
rev = reversed([1,4,2,3,1])
list(rev)
[1, 3, 2, 4, 1]#反转字符串
rev = reversed('我爱中国')
list(rev)
['国', '中', '爱', '我']''.join(rev)
'国中爱我's = '我的世界开始下雪'
''.join(reversed(s))
'雪下始开界世的
slice()
描述: slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。返回一个表示由 range(start, stop, step) 所指定索引集的 slice对象
语法:
- class slice(stop)
- class slice(start, stop[, step])
参数:
- start – 起始位置
- stop – 结束位置
- step – 间距
a = [1,4,2,3,1]
a[slice(0,5,2)] #等价于a[0:5:2]
[1, 2, 1]a = list(range(10))
a[slice(3)]
[0, 1, 2
enumerate()
描述: enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。返回一个可以枚举的对象,该对象的next()方法将返回一个元组。enumerate在字典上是枚举、列举的意思。
语法: enumerate(sequence, [start=0])
参数: sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。
L = ['Spring', 'Summer', 'Fall', 'Winter']
enumerate(L)
<enumerate at 0x226e1ee1138>#生成的额迭代器,无法直接查看list(enumerate(L))#列表形式,可以看到内部结构,默认下标从0开始
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]list(enumerate(L, start=1)) #下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]for i,v in enumerate(L):print(i,v)
0 Spring
1 Summer
2 Fall
3 Winterfor i,v in enumerate(L,1):print(i,v)1 Spring
2 Summer
3 Fall
4 Winters = ["a","b","c"]for i ,v in enumerate(s,2):print(i,v)
2 a
3 b
4 c普通的 for 循环
i = 0
seq = ['one', 'two', 'three']
for element in seq:print (i, seq[i])i+= 1
0 one
1 two
2 three在看一个普通循环的对比案例
for 循环使用 enumerateseq = ['one', 'two', 'three']
for i, element in enumerate(seq):print (i, element)0 one
1 two
2 threeseq = ['one', 'two', 'three']
for i, element in enumerate(seq,2):print (i, element)
2 one
3 two
4 three
all()
描述: 接受一个迭代器,如果迭代器(元组或列表)的所有元素都为真,那么返回True,否则返回False,元素除了是0、空、None、False外都算 True。注意: 空元组、空列表返回值为True,这里要特别注意。
语法: all(iterable)
参数: iterable – 元组或列表
案例:
all([1,0,3,6])
Falseall([1,9,3,6])
Trueall(['a', 'b', '', 'd'])
Falseall([]) #空列表为真
Trueall(()) #空元组为真
True
any()
描述: 接受一个迭代器,如果迭代器里有一个元素为真,那么返回True,否则返回False,元素除了是 0、空、None、False 外都算 True。
语法: any(iterable)
参数: iterable – 元组或列表
any([0,0,0,[]])
Falseany([0,0,1])
Trueany((0, '', False))
Falseany([]) # 空列表
Falseany(()) # 空元组
False
zip()
描述:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。 我们可以使用 list() 转换来输出列表。,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 ***** 号操作符,可以将元组解压为列表。
语法: zip([iterable, …])
参数: iterable 一个或多个迭代器
创建一个聚合了来自每个可迭代对象中的元素的迭代器:
x = [3,2,1]
y = [4,5,6]
list(zip(y,x))
[(4, 3), (5, 2), (6, 1)]#搭配for循环,数字与字符串组合
a = range(5)
b = list('abcde')
[str(y)+str(x) for x,y in zip(a,b)]
['a0', 'b1', 'c2', 'd3', 'e4']#数数相乘
list1 = [2,3,4]
list2 = [5,6,7]
for x,y in zip(list1,list2):print(x,'*',y,'--',x*y)
2 * 5 -- 10
3 * 6 -- 18
4 * 7 -- 28#元素个数与最短的列表一致
list(zip(x,b))[(3, 'a'), (2, 'b'), (1, 'c')]s#与 zip 相反,zip(* ) 可理解为解压,返回二维矩阵式
a1, a2 = zip(*zip(a,b))
a1
(0, 1, 2, 3, 4)
a2
('a', 'b', 'c', 'd',
filter()
描述: filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法: filter(function, iterable)
参数:
- function – 判断函数。
- iterable – 可迭代对象。
fil = filter(lambda x: x>10,[1,11,2,45,7,6,13])
fil<filter at 0x28b693b28c8>
list(fil)
[11, 45, 13]def is_odd(n):return n % 2 == 1newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(list(newlist))
[1, 3, 5, 7, 9]
map()
描述:map() 会根据提供的函数对指定序列做映射。返回一个将 function 应用于 iterable 中每一项并输出其结果的迭代器
语法: map(function, iterable, …)
参数:
- function – 函数
- iterable – 一个或多个序列
def square(x) : # 计算平方数return x ** 2
list(map(square, [1,2,3,4,5])) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]# 提供了两个列表,对相同位置的列表数据进行相加
list(map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]))
[3, 7, 11, 15, 19]list(map(lambda x: x%2==1, [1,3,2,4,1]))
[True, True, False, False, True]
三、和作用域相关
locals()
描述: locals() 函数会以字典类型返回当前位置的全部局部变量。对于函数, 方法, lambda 函式, 类, 以及实现了 call 方法的类实例, 它都返回 True。
语法: locals()
globals()
描述: 函数会以字典类型返回当前位置的全部全局变量。
语法: globals()
参数: 无
a='runoob'
print(globals()) # globals 函数返回一个全局变量的字典,包括所有导入的变量。
四、迭代器生成器
range()
描述: range() 函数可创建一个整数列表,一般用在 for 循环中。
语法: range(start, stop[, step])
参数:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0,5)等价于 range(0, 5, 1)
案例:
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]list(range(1, 11)) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]list(range(0, 30, 5))
[0, 5, 10, 15, 20, 25]for i in range(5):print(i)
0
1
2
3
4
next()
描述: next() 返回迭代器的下一个项目。next() 函数要和生成迭代器的iter() 函数一起使用。
语法: next(iterator[, default])
参数:
- iterator – 可迭代对象
- default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发StopIteration异常。
不加默认值的情况,最后会报错StopIteration
it = iter([5,3,4,1])
next(it)
5
next(it)
3
next(it)
4
next(it)
1
next(it)
Traceback (most recent call last):File "<ipython-input-392-bc1ab118995a>", line 1, in <module>next(it)
StopIteration
加默认值的情况,最后迭代完了,会返回默认值
it = iter([0,1,2,3,4])
next(it,'结束了')
0
next(it,'结束了')
1
next(it,'结束了')
2
next(it,'结束了')
3
next(it,'结束了')
4
next(it,'结束了')
'结束了'
iter()
描述: 返回一个 iterator 对象
语法: iter(object[, sentinel])
参数:
- object – 支持迭代的集合对象。
- sentinel – 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用 object。
iter([0,1,2,3,4])
<list_iterator at 0x2aa87d32988>for i in iter([0,1,2,3,4]):
print(i)
0
1
2
3
4
五、字符串类型代码的执行
eval()
描述: 将字符串str 当成有效的表达式来求值并返回计算结果取出字符串中内容
语法: eval(expression[, globals[, locals]])
参数:
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
s = "1 + 3 +5"
eval(s)
9#要统计图片的数量
str1 = "['https://ww1.sin5n.jpg', 'https://ww1.siqk4he.jpg']"
len(eval(str1))
2len(str1)
5
exec()
描述: 执行储存在字符串或文件中的Python语句,相比于eval,exec可以执行更复杂的Python代码。
语法: exec(object, globals, locals)
参数:
- object-- 要执行的表达式。
- globals – 可选。包含全局参数的字典。
- locals – 可选。包含局部参数的字典。
执行字符串或compile方法编译过的字符串,没有返回值
s = "print('helloworld')"
r = compile(s,"<string>", "exec")
exec(r)
helloworldx = 10
expr = """
z = 30
sum = x + y + z
print(sum)
"""
def func():y = 20exec(expr)exec(expr, {'x': 1, 'y': 2})exec(expr, {'x': 1, 'y': 2}, {'y': 3, 'z': 4})func()
60
33
34
compile()
描述: compile() 将 source 编译成代码或 AST 对象,将字符串类型的代码编码, 代码对象能够通过exec语句来执行或者eval()进行求值
语法: compile(source, filename, mode[, flags[, dont_inherit]])
参数:
- source – 字符串或者AST(Abstract Syntax Trees)对象。。
- filename – 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode – 指定编译代码的种类。可以指定为 exec, eval, single。
- flags – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。
- flags和dont_inherit是用来控制编译源码时的标志
将字符串编译成python能识别或可以执行的代码,也可以将文字读成字符串再编译。
s = "print('helloworld')"
r = compile(s,"<string>", "exec")r
<code object <module> at 0x000000000F819420, file "<string>", line 1>
exec(r)
helloworldstr = "for i in range(0,5): print(i)"
c = compile(str,'','exec') # 编译为字节代码对象
c
<code object <module> at 0x000001EB82C91ED0, file "", line 1>exec(c)
0
1
2
3
4
六、输入输出
print()
描述: print() 方法用于打印输出,最常见的一个函数。在 Python3.3 版增加了 flush 关键字参数。print 在 Python3.x 是一个函数,但在 Python2.x 版本不是一个函数,只是一个关键字。
语法: print(*objects, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False)
参数:
- objects – 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
- sep – 用来间隔多个对象,默认值是一个空格。
- end – 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file – 要写入的文件对象。
- flush – 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
print("Hello World")
Hello World#设置间隔符
print("www","baidu","com",sep=".")
www.baidu.com
input()
描述: Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。获取用户输入内容
语法: input([prompt])
参数: prompt:–提示信息
a = input("input:")
input:1234
print(a)
123
七、内存相关
hash()
描述: 返回该对象的哈希值(如果它有的话)。哈希值是整数。它们在字典查找元素时用来快速比较字典的键。相同大小的数字变量有相同的哈希值(即使它们类型不同,如 1 和 1.0),hash表.用空间换的时间 比较耗费内存,hash() 函数可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。
语法: hash(object)
参数: object – 对象
在hash()对对象使用时,所得的结果不仅和对象的内容有关,还和对象的id(),也就是内存地址有关。
class Test:def __init__(self, i):self.i = i
for i in range(10):t = Test(1)print(hash(t), id(t))
-9223371853633304640 2931543538696
-9223371853633350840 2931542799496
-9223371853633350832 2931542799624
-9223371853633350756 2931542800840
-9223371853520958964 2933341069512
-9223371853633350668 2931542802248
-9223371853633350796 2931542800200
-9223371853633350748 2931542800968
-9223371853633350856 2931542799240
-9223371853633350880 2931542798856
hash() 函数的用途: hash() 函数的对象字符不管有多长,返回的hash值都是固定长度的,也用于校验程序在传输过程中是否被第三方(木马)修改,如果程序(字符)在传输过程中被修改hash值即发生变化,如果没有被修改,则hash值和原始的hash值吻合,只要验证hash值是否匹配即可验证程序是否带木马(病毒)。
name1 = '正常程序代码'
name2 = '正常程序代码带病毒'
print(hash(name1))
-3048480827538126659
print(hash(name2))
-9065726187242961328
memoryview()
描述:memoryview() 函数返回给定参数的内存查看对象(Momory view)。返回由给定实参创建的“内存视图”对象, Python 代码访问一个对象的内部数据,只要该对象支持缓冲区协议 而无需进行拷贝
语法: memoryview(obj)
参数: obj – 对象
v = memoryview(bytearray("abcefg", 'utf-8'))
v[1]
98
v[-1]
98v[1:4]
<memory at 0x0000028B68E26AC8>
v[1:4].tobytes()
b'bce'
八、文件读写
open()
描述: open() 函数用于打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。所以open()读取文件分为两步。
语法: open(name[, mode[, buffering]])
参数:
- name : 一个包含了你要访问的文件名称的字符串值。
- mode : mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
- buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
打开文件的模式:
r: 打开一个文件用于只读,文件的指针将会放在文件的开头,这是默认模式。
w: 打开一个文件用于写入,如果文件存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
a: 打开一个文件用于追加, 如果文件已存在,文件指针将会放在文件的结尾,如果文件不存在,创建新文件进行写入。
r+: 打开一个文件用于读写,文件指针将会放在文件的开头。
w+: 打开一个文件用于读写。如果该文件已存在,删除原有内容并从开头开始编辑;如果该文件不存在,创建新文件。
a+: 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾,如果该文件不存在,创建新文件用于读写。
rb:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
rb+:以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
wb:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
ab:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
注意:当读取音视频、图片等二进制文件时,需要采用二进制的读取方法。
file对象方法
file.read([size]) :size 未指定则返回整个文件,如果文件大小>2 倍内存则有问题,f.read()读到文件尾时返回""(空字串)。
file.readline() :返回一行。
file.readlines([size]) :返回包含size行的列表, size 未指定则返回全部行。
for line in file: print(line) :通过迭代器访问。
file.write(): 如果要写入字符串以外的数据,先将他转换为字符串。
file.tell(): 返回一个整数,表示当前文件指针的位置(就是到文件头的比特数)。
file.seek(偏移量,[起始位置]): 用来移动文件指针。偏移量: 单位为比特,可正可负;起始位置: 0 - 文件头, 默认值; 1 - 当前位置; 2 - 文件尾
file.close(): 关闭文件
file = open('test.txt',encoding='utf-8') #打开文件
file.read()#直接显示文件所有内容
file.readline#显示第一行
file.close() #关闭文件
https://docs.python.org/zh-cn/3/tutorial/inputoutput.html#tut-files
test.txt存储的的内容如下
hello
python
i
love you
read()方法
file = open('test.txt')
file.read()
'hello\npython\ni\nlove you'
readline()方法
file = open('test.txt')
file.readline()
'hello\n'
readlines()方法
file= open('test.txt')
file.readlines()
['python\n', 'i\n', 'love you']
逐行读取
file = open('test.txt')
for line in file:print(line)
hello
python
i
love you
九、模块相关
__ import__()
描述: 该函数会导入 name 模块,有可能使用给定的 globals 和 locals 来确定如何在包的上下文中解读名称。 fromlist 给出了应该从由 name 指定的模块导入对象或子模块的名称。 标准实现完全不使用其 locals 参数,而仅使用 globals 参数来确定 import 语句的包上下文。level 指定是使用绝对还是相对导入。 0 (默认值) 意味着仅执行绝对导入。
语法: import(name, globals=None, locals=None, fromlist=(), level=0)
参数: object – 对象
语句 import spam的结果将为与以下代码作用相同的字节码:spam = __import__('spam.ham', globals(), locals(), [], 0)
十、获取帮助
help()
描述: 返回对象的帮助文档
语法: help(object)
参数: object – 对象
help('sys') # 查看sys模块的帮助

可以看到文档的网址:https://docs.python.org/3.7/library/sys
查看str数据类型的帮助
help('str')
可以看到,字符串相关的所有方法用法介绍
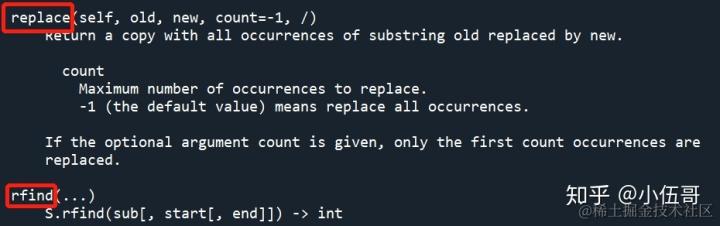
a = [1,2,3]
help(a) # 查看列表list帮助信息
help(a.append)# 显示list的append方法的帮助

十、对象调用
callable()
描述: callable() 函数用于检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象object绝对不会成功。对于函数、方法、lambda 函式、 类以及实现了 call 方法的类实例, 它都返回True。
这个函数一开始在 Python 3.0 被移除了,但在 Python 3.2 被重新加入。
语法: callable(object)
参数: object – 对象
#检查一个数字
callable(0)
False#创建一个函数
def add(x,y):return x+y
callable(add)
True#创建一个带有__call__方法的类
class Dogs:def __call__(self):return 0
callable(Dogs)
True
十一、内置属性
dir()
描述: dir() 查看对象的内置属性, 访问的是对象中的__dir__()方法,函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用,如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
语法: dir(object)
参数: object 对象、变量、类型。
#获得当前模块的属性列表
dir()
['In','Out', 'exit', 'get_ipython', 'quit']#查看列表的方法,使用dir([ ])或者dir(list())#查看列表的方法
print(dir(list()))
['__add__', ... 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
dir()访问的是对象中的__dir__()方法,因此下面的调用也能得到相同的结果:
list().__dir__()
[__repr__',, ... 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
print(dir(str))、print(dir(list))、print(dir(dict))、分别获取各个数据类型的方法,不带参数时返回当前范围内的变量,方法和定义的类型列表;带参数时返回参数的属性,方法列表。
hasattr()
描述: 函数用于判断对象是否包含对应的属性。
语法: hasattr(object, name)
参数:
- object – 对象。
- name – 字符串,属性名。
class Coordinate:x = 10y = -5z = 0point1 = Coordinate()
print(hasattr(point1, 'x'))
True
print(hasattr(point1, 'y'))
True
print(hasattr(point1, 'z'))
True
print(hasattr(point1, 'no')) # 没有该属性
False
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
Python全套学习资料

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓

相关文章:
Python初学者必须吃透的69个内置函数!
所谓内置函数,就是Python提供的, 可以直接拿来直接用的函数,比如大家熟悉的print,range、input等,也有不是很熟,但是很重要的,如enumerate、zip、join等,Python内置的这些函数非常精巧且强大的&…...
Day73力扣打卡
打卡记录 统计移除递增子数组的数目 II(双指针) 链接 class Solution:def incremovableSubarrayCount(self, a: List[int]) -> int:n len(a)i 0while i < n - 1 and a[i] < a[i 1]:i 1if i n - 1: # 每个非空子数组都可以移除return n …...

Android原生实现分段选择
六年前写的一个控件,一直没有时间总结,趁年底不怎么忙,整理一下之前写过的组件。供大家一起参考学习。废话不多说,先上图。 一、效果图 实现思路使用的是radioGroup加radiobutton组合方式。原理就是通过修改RadioButton 的backgr…...
在 Unity 中获取 Object 对象的编辑器对象
有这个需求的原因是,在编辑器的 Inspector 逻辑中,写了许多生成逻辑。 现在不想挨个在 Inspector 上都点一遍按钮,所以就需要能获取到它们的编辑器对象。 发现可以借助官方的 UnityEditor.Editor.CreateEditor 方法达到目的,如下…...
idea自动注释
前言 保存一下自己的自动注释代码 idea自动注释 前言1 创建类时,自动生成注释2 在方法上使用快捷键生成注释3 使用方法4 效果图 1 创建类时,自动生成注释 如下: #if (${PACKAGE_NAME} && ${PACKAGE_NAME} ! "")package …...

阿里云 ACK 云上大规模 Kubernetes 集群高可靠性保障实战
作者:贤维 马建波 古九 五花 刘佳旭 引言 2023 年 7 月,阿里云容器服务 ACK 成为首批通过中国信通院“云服务稳定运行能力-容器集群稳定性”评估的产品, 并荣获“先进级”认证。随着 ACK 在生产环境中的采用率越来越高,稳定性保…...
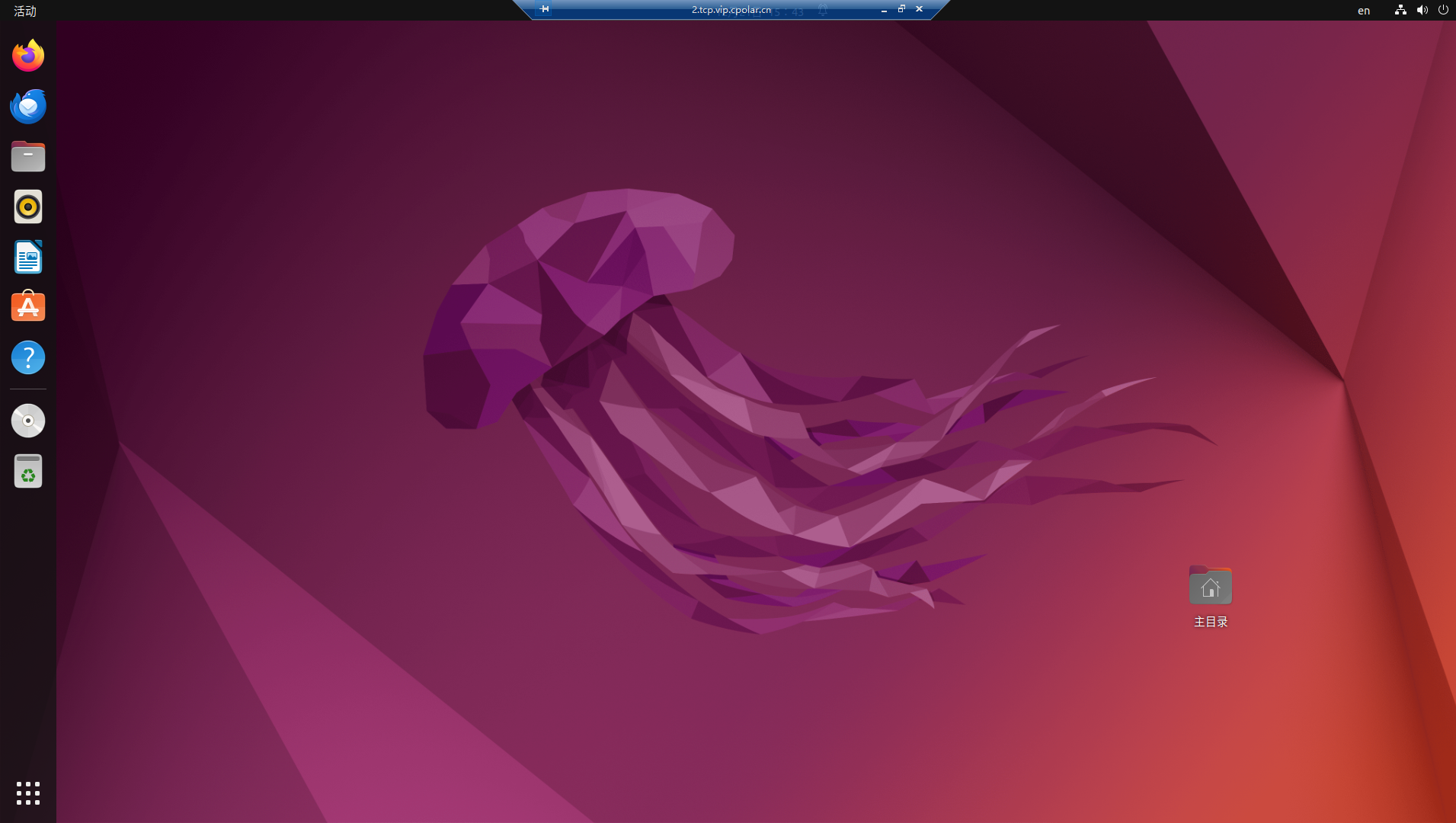
如何在无公网IP环境使用Windows远程桌面Ubuntu
文章目录 一、 同个局域网内远程桌面Ubuntu二、使用Windows远程桌面连接三、公网环境系统远程桌面Ubuntu1. 注册cpolar账号并安装2. 创建隧道,映射3389端口3. Windows远程桌面Ubuntu 四、 配置固定公网地址远程Ubuntu1. 保留固定TCP地址2. 配置固定的TCP地址3. 使用…...
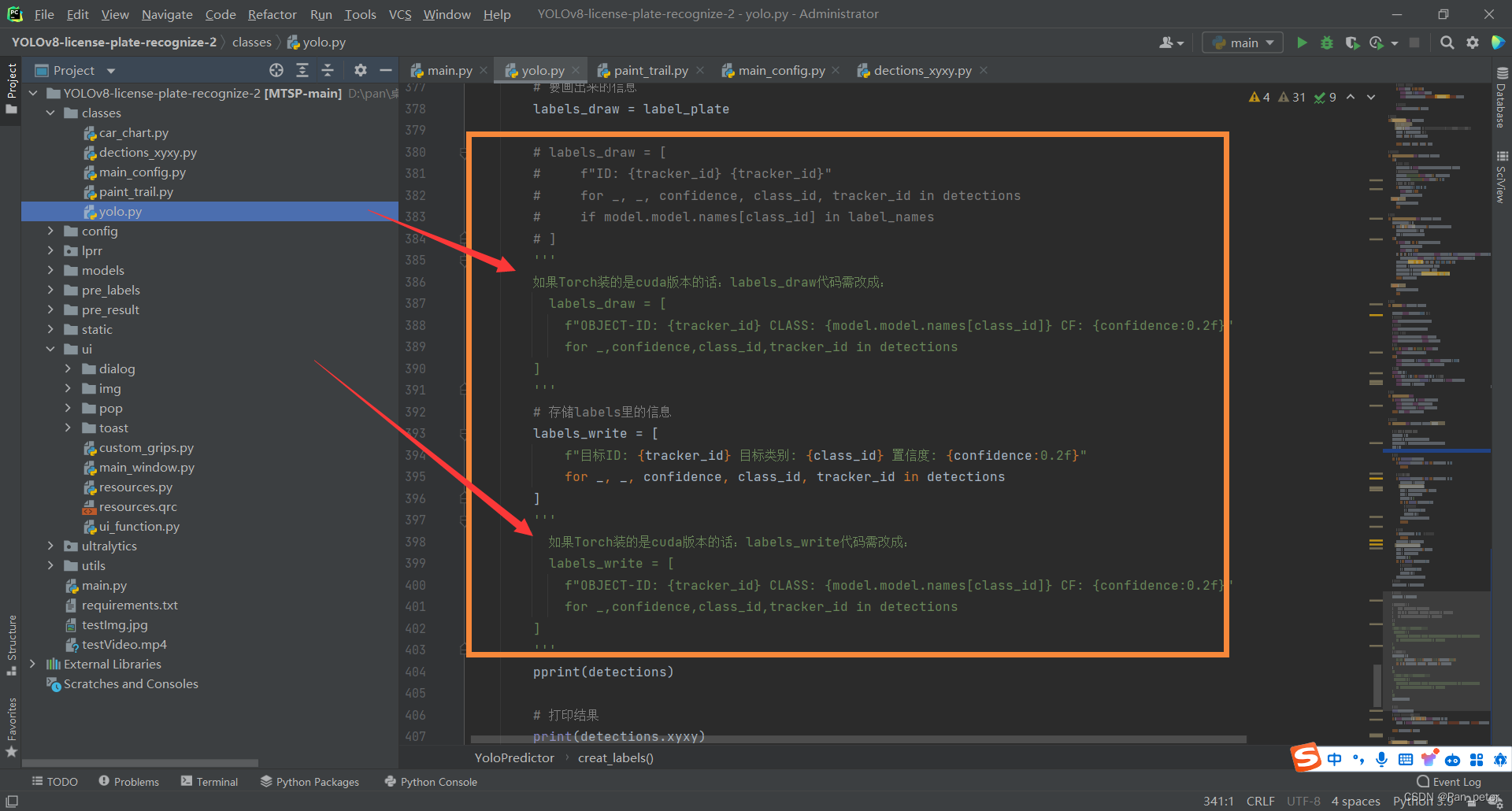
Python——yolov8识别车牌2.0
目录 一、前言 二、关于项目UI 2.1、修改界面内容的文本 2.2、修改界面的图标和图片 三、项目修改地方 四、其他配置问题 一、前言 因为后续有许多兄弟说摄像头卡顿,我在之前那个MATS上面改一下就可以了,MAST项目:基于YOLOv8的多端车流检…...
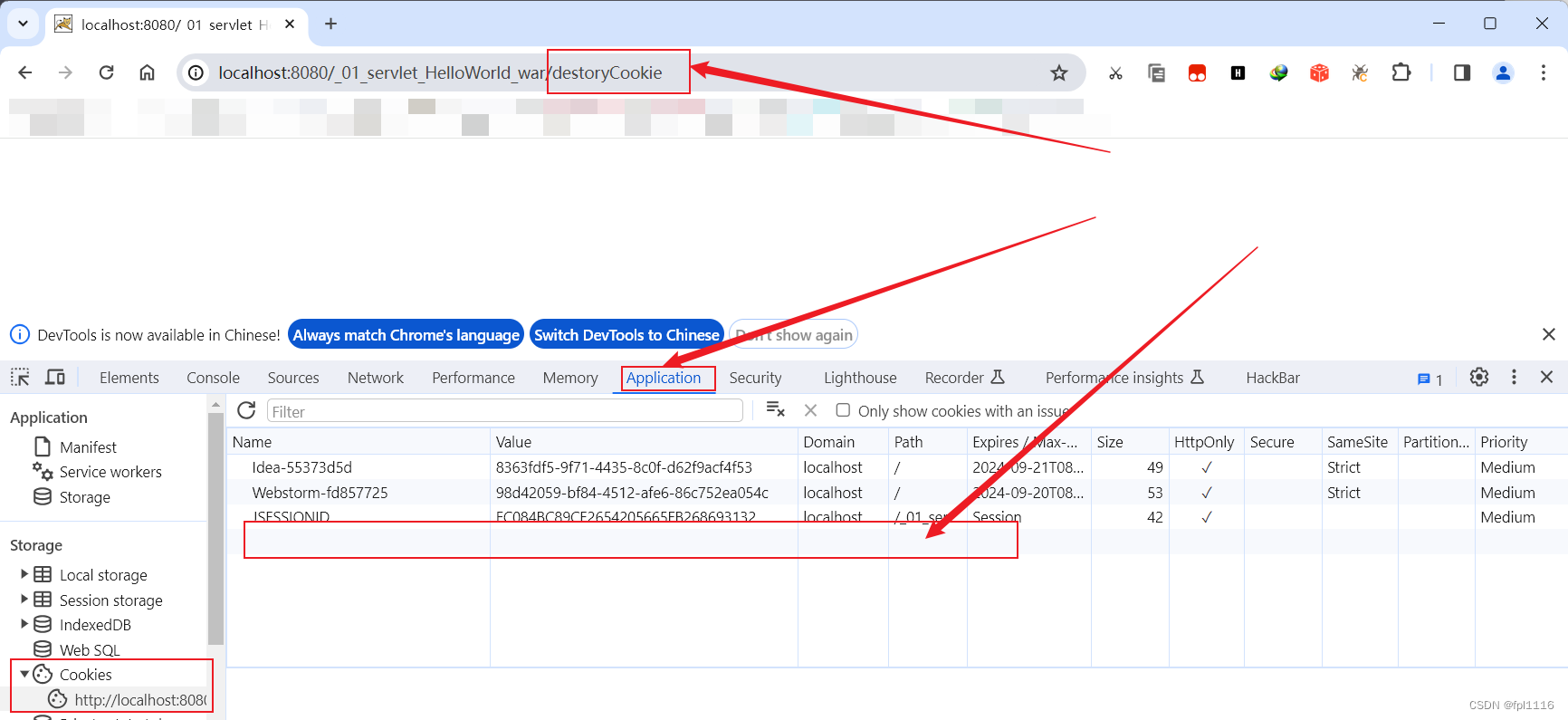
Cookie的详解使用(创建,获取,销毁)
文章目录 Cookie的详解使用(创建,获取,销毁)1、Cookie是什么2、cookie的常用方法3、cookie的构造和获取代码演示SetCookieServlet.javaGetCookieServlet.javaweb.xml运行结果如下 4、Cookie的销毁DestoryCookieServletweb.xml运行…...
)
shell脚本自动化部署Zabbix4.2(修改脚本替换版本)
#!/bin/bash # 配置无人值守的安装,定义安装过程中需要用到的一些信息 DBPasswordadmin123 CacheSize256M ZBX_SERVER_NAMEZabbix-Server http_port80 # 配置 Zabbix 防火墙 firewall-cmd --permanent --zonepublic --add-port10051/tcp firewall-cmd…...
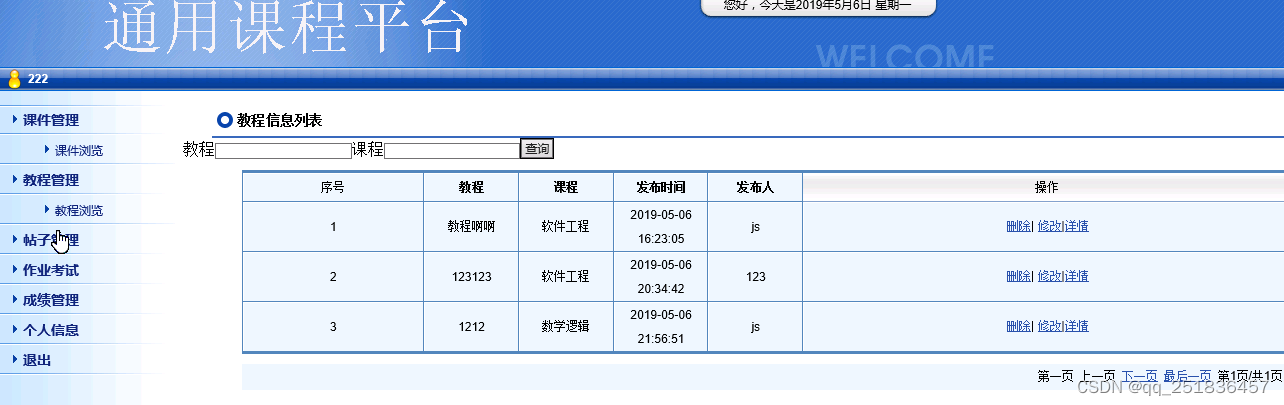
java SSM课程平台系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM课程平台系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
k8s二进制最终部署(网络 负载均衡和master高可用)
k8s中的通信模式 1、pod内部之间容器与容器之间的通信,在同一个pod 中的容器共享资源和网络,使用同一个网络命名空间,可以直接通信的 2、同一个node节点之内,不同pod之间的通信,每个pod都有一个全局的真实的IP地址&a…...
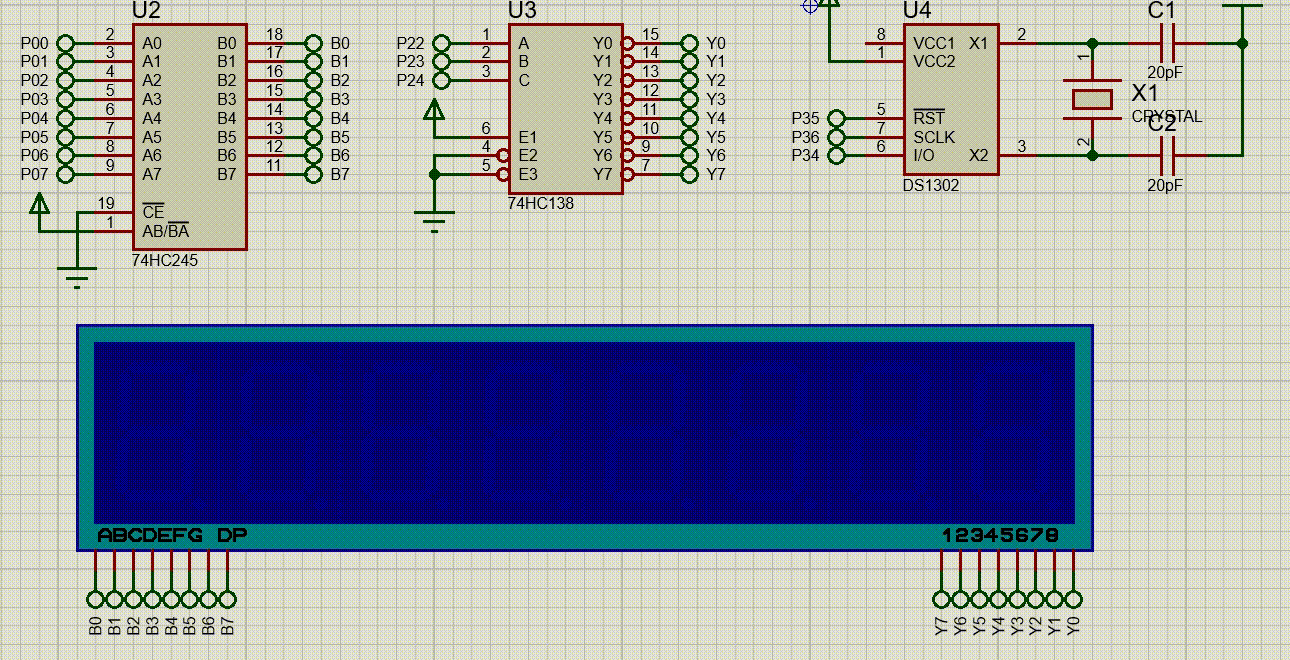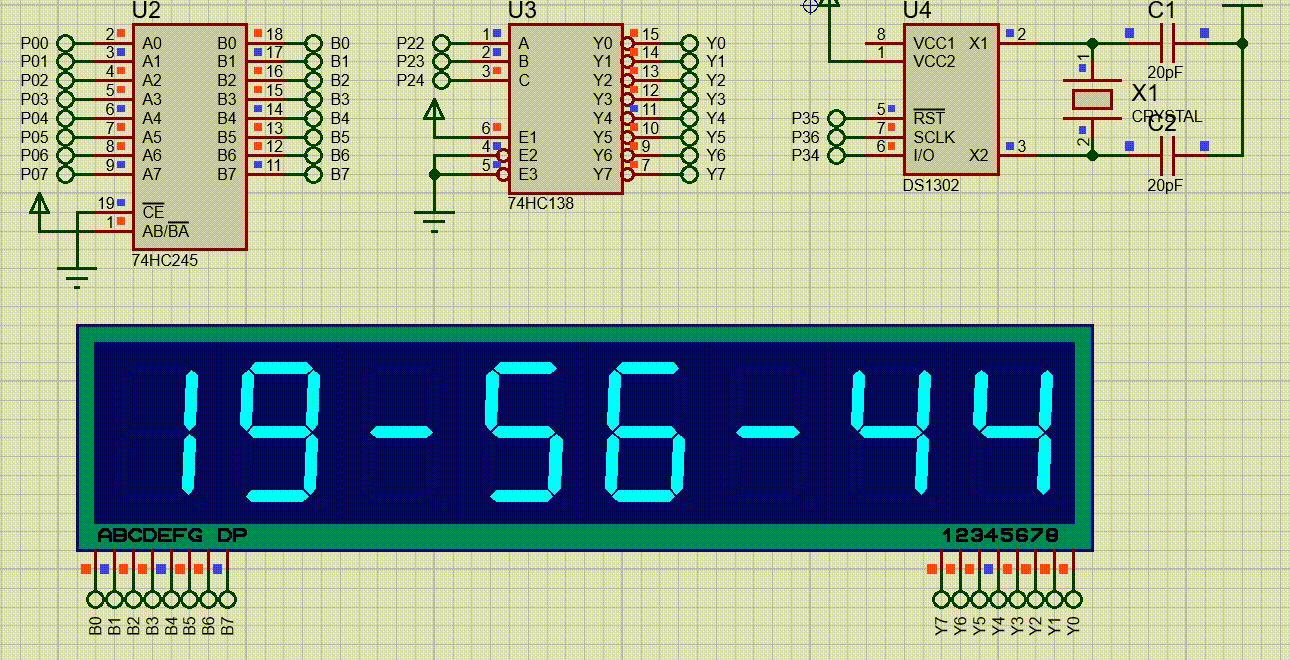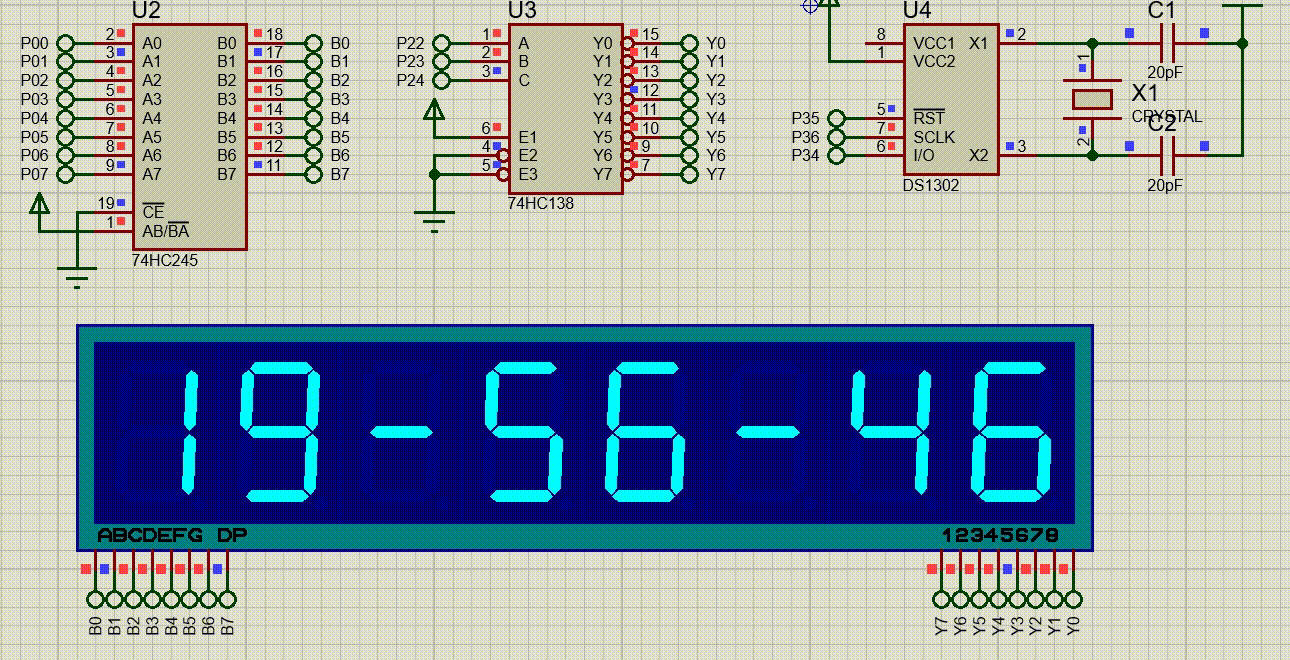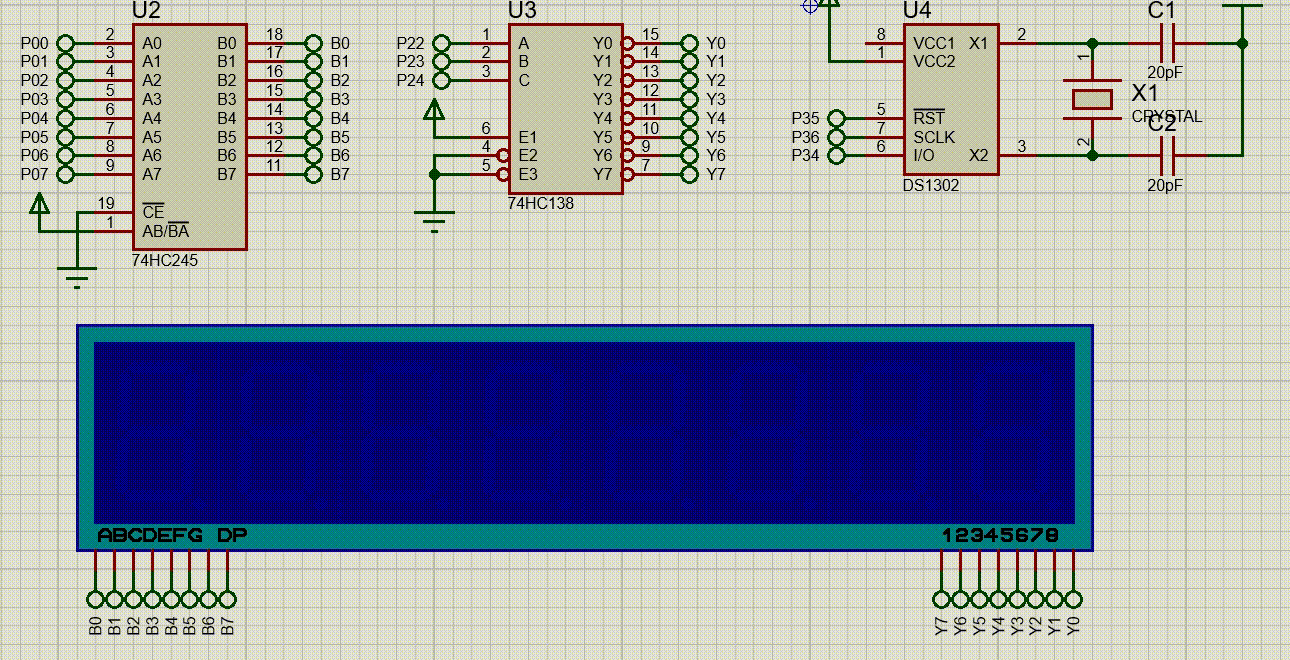
【51单片机系列】DS1302时钟模块
本文是关于DS1302时钟芯片的相关介绍。 文章目录 一、 DS1302时钟芯片介绍二、DS1302的使用2.1、DS1302的控制寄存器2.2、DS1302的日历/时钟寄存器2.3、片内RAM2.4、DS1302的读写时序 三、SPI总线介绍四、DS1302使用示例 一、 DS1302时钟芯片介绍 DS1302是DALLAS公司推出的涓流…...
)
深入理解C语言中冒泡排序(优化)
目录 引言: 冒泡排序概述: 优化前: 优化后(注意看注释): 解析优化后: 原理(先去了解qsort): 引言: 排序算法是计算机科学中的基础问题之一。在本篇博客中,…...

低代码选型注意事项
凭借着革命性的生产力优势,低代码技术火爆了整个IT圈。面对纷繁复杂的低代码和无代码产品,开发者该如何选择? 在研究低代码平台的年数上,本人已有3年,也算是个低代码资深用户了,很多企业面临低代码选型上的…...

Caffeine--缓存组件
Caffeine 概念缓存手动加载自动加载手动异步加载自动异步加载 驱逐策略基于容量基于时间基于引用 移除显式移除 概念 Caffeine是一个基于Java8开发的提供了近乎最佳命中率的高性能的缓存库。与ConcurrentMap有点相似。最根本的区别是ConcurrentMap将会持有所有加入到缓存当中的…...
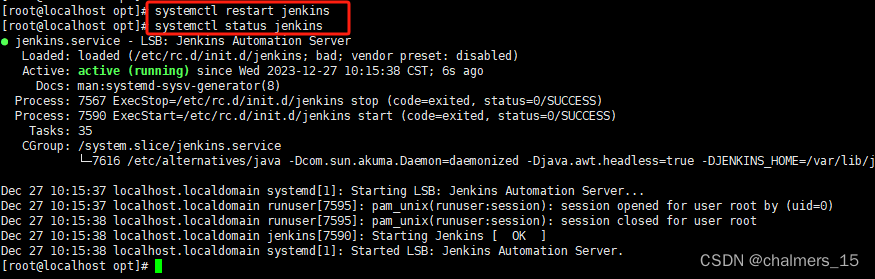
Centos7:Jenkins+gitlab+node项目启动(1)
Centos7:Jenkinsgitlabnode项目启动(1) Centos7:Jenkinsgitlabnode项目启动(1)-CSDN博客 Centos7:Jenkinsgitlabnode项目启动(2) Centos7:Jenkinsgitlabnode项目启动(2)-CSDN博客 Centos7:Jenkinsgitlabnode项目启…...

starrocks集群fe/be节点进程守护脚本
自建starrocks集群,有时候服务会挂掉,无法自动拉起服务,于是采用supervisor进行进程守护。可能是版本的原因,supervisor程序总是异常,无法对fe//be进行守护。于是写了个简易脚本。 #!/bin/bash AppNameFecom.starrock…...

奇富科技跻身国际AI学术顶级会议ICASSP 2024,AI智能感知能力迈入新纪元
近日,2024年IEEE声学、语音与信号处理国际会议ICASSP 2024(2024 IEEE International Conference on Acoustics, Speech, and Signal Processing)宣布录用奇富科技关于语音情感计算的最新研究成果论文“MS-SENet: Enhancing Speech Emotion Re…...

如何在Android Termux中使用SFTP实现远程传输文件
文章目录 1. 安装openSSH2. 安装cpolar3. 远程SFTP连接配置4. 远程SFTP访问5. 配置固定远程连接地址6、结语 SFTP(SSH File Transfer Protocol)是一种基于SSH(Secure Shell)安全协议的文件传输协议。与FTP协议相比,SFT…...

8B模型榨出极限战力!本地LLM胜率狂飙86%
今天我们要讲的是一个工程方法,通过这个Forge框架来增强本地运行的8B模型,让这个小模型可以在复杂的agent任务上面有更好的表现。Q:本地小模型在做这些复杂任务的时候,经常会出现哪些让人抓狂的问题? A:在本…...

工业视觉系统选型实战:CCD相机与镜头参数计算全解析
1. 项目概述:从“神坛”到“工具箱”的CCD相机与镜头选型 在自动化视觉检测、精密测量和机器视觉领域,CCD工业相机和镜头的选型与参数计算,常常被新手工程师视为一个“黑箱”或“玄学”问题。客户一问到“这个系统能看多清楚?”、…...

3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南
3分钟搞定B站缓存视频转换:m4s-converter无损合并完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的情…...
)
保姆级教程:用STM32F103C8T6和MAX485芯片实现稳定的一主多从RS485通讯(附完整代码)
STM32F103C8T6与MAX485构建工业级RS485总线系统实战指南 在工业自动化领域,稳定可靠的通信系统如同神经脉络般重要。想象一下,当您需要在一个大型温室中部署数十个温湿度传感器,或者在一个工厂车间监控多台设备的运行状态时,点对点…...
)
保姆级教程:在Windows上用CMake搞定Qt 6.5与WebRTC M114的集成(附完整代码)
Windows平台Qt 6.5与WebRTC M114深度集成实战指南 环境准备与工具链配置 在Windows平台上进行Qt与WebRTC的集成开发,首先需要搭建完整的工具链环境。不同于简单的库引用,这种深度集成对工具版本和系统配置有着严格要求。 必备组件清单: Visua…...

番茄小说下载器终极指南:如何轻松下载EPUB、TXT和有声小说
番茄小说下载器终极指南:如何轻松下载EPUB、TXT和有声小说 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经在番茄小说上找到一部精彩的作品,…...

影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案
影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案 一、问题场景:数据集里混入模糊图,模型效果怎么调都上不去 在图像识别、OCR、人脸识别、商品图审核、视频抽帧数据清洗中,经…...

非规则区域上空间分数阶偏微分方程的有限元方法【附仿真】
✨ 长期致力于空间分数阶导数、高维问题、有限元方法、非规则区域、非结构化网格、非光滑解研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二维非规则…...
:使用指南)
One API 部署教程(下):使用指南
导读:前面两篇讲了本地和线上部署,现在 One API 已经跑起来了,接下来就是真正的使用环节! 理解核心概念 在开始之前,咱们先搞清楚几个关键概念,不然后面容易晕。 渠道(Channel):就是你的各个 AI 平台的 API Key。比如你有 DeepSeek 的 Key、OpenAI 的 Key、通义千问…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...