深入理解C语言中冒泡排序(优化)
目录
引言:
冒泡排序概述:
优化前:
优化后(注意看注释):
解析优化后:
原理(先去了解qsort):
引言:
排序算法是计算机科学中的基础问题之一。在本篇博客中,我们将深入研究C语言中排序算法的实现原理,特别关注优化过的冒泡排序。此外,我们会详细讨论函数指针的概念,以及如何使用函数指针实现通用的排序函数。
冒泡排序概述:
冒泡排序是一种简单而直观的排序算法。其基本思想是通过多次遍历待排序数组,比较相邻元素并交换,直到整个数组有序。下面是优化前/优化后的冒泡排序的实现:
优化前:
// 定义一个冒泡排序函数,参数为一个整数指针和数组大小
int paixu(int* arr, int sz) {// 外层循环控制遍历次数,每次遍历都会将最大(或最小)的元素移动到末尾for (int i = 0; i < sz - 1; i++) {// 内层循环用于比较和交换相邻的元素for (int j = 0; j < sz - 1 - i; j++) {// 如果前一个元素小于后一个元素,则交换它们的位置if (arr[j] < arr[j + 1]) {// 使用异或操作实现无临时变量的交换arr[j] = arr[j] ^ arr[j + 1];arr[j + 1] = arr[j] ^ arr[j + 1];arr[j] = arr[j] ^ arr[j + 1];}}}
}int main() {// 初始化一个包含10个元素的数组int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };// 计算数组的大小int sz = sizeof(arr) / sizeof(arr[0]);// 调用冒泡排序函数对数组进行排序paixu(arr, sz);// 输出排序后的数组元素for (int i = 0; i < sz; i++) {printf("%d ", arr[i]);}return 0;
}这个程序定义了一个冒泡排序函数`paixu`,并在一个`main`函数中使用该函数对一个整数数组进行排序。冒泡排序通过不断地比较和交换相邻的元素,将最大的(或最小的)元素逐步移动到数组的末尾。这里使用了异或操作来实现元素的交换,无需额外的临时变量。在主函数中,我们初始化了一个数组,计算其大小,并调用`paixu`函数进行排序,最后输出排序后的数组元素。
这个程序只能排序数组下面我们优化一下这个冒泡排序让他可以排序其他的数据
优化后(注意看注释):
// 定义一个比较函数,接收两个void*类型的指针作为参数,返回它们指向的int值的差
int compare(const void* a, const void* b)
{// 解引用指针并进行减法操作return (*(int*)b - *(int*)a);
}// 定义一个stu结构体,包含姓名和年龄
struct stu
{char name[20];int age;
};// 定义一个新的比较函数,用于比较stu结构体的年龄成员
int compar(const void* p1, const void* p2)
{// 解引用指针并获取age成员,然后进行减法操作return ((struct stu*)p1)->age - ((struct stu*)p2)->age;// 如果需要按照姓名升序排序,可以使用strcmp函数(注意:这将按ASCII值排序,不适用于非ASCII字符)// return strcmp(((struct stu*)p2)->name, ((struct stu*)p1)->name);
}// 定义一个交换函数,用于交换两个内存区域的内容
void exchange(char* a1, char* a2, int sz)
{//char(一个字节),把sz(元素大小)传过来就可以确定有多少个char* 如果传过来的是4个字节char*接收一个字节,所以把宽度传过来利用循环一个一个的交换// 使用循环,根据元素大小sz逐个交换元素for (int i = 0; i < sz; i++){char tmp = *a1;*a1 = *a2;*a2 = tmp;a1++;a2++;}
}// 定义一个优化的冒泡排序函数
void effervescence(void* base, int num, int sz, int (*pa)(void* p1, void* p2))
{// 使用两层循环进行冒泡排序for (int i = 0; i < num - 1; i++){for (int j = 0; j < num - 1 - i; j++) {// 根据元素大小sz计算索引,并调用比较函数if (pa((char*)base + j * sz, (char*)base + (j + 1) * sz) > 0){// 如果前一个元素大于后一个元素,交换它们 //(char*)base+sz -- 将起始强制转换(char*)+sz(元素大小)exchange((char*)base + j * sz, (char*)base + (j + 1) * sz, sz);如果j是[0 -- 0,1] [1 -- 1,2] [2 -- 2,3] }}}
}// 测试结构体数组排序
void text1()
{struct stu s1[3] = { {"mdxx",10},{"mxxmm5",20},{"sss",25} }; // 初始化结构体int num = sizeof(s1) / sizeof(s1[0]); // 计算结构体数组长度int sz = sizeof(s1[0]); // 计算元素长度effervescence(s1, num, sz, compar); // 对结构体数组进行排序for (int i = 0; i < num; i++) {printf("Name: %s, Age: %d\n", s1[i].name, s1[i].age);}
}// 测试整数数组排序
void text2()
{int arr[] = { 2,5,4,7,8,9,0,1,6 };int num = sizeof(arr) / sizeof(arr[0]); // 计算数组长度int sz = sizeof(arr[0]); // 计算元素长度effervescence(arr, num, sz, compare); // 对整数数组进行排序for (int i = 0; i < num; i++) {printf("%d ", arr[i]);}printf("\n");
}int main()
{text1(); // 调用结构体数组排序测试text2(); // 调用整数数组排序测试return 0;
}这段代码包含了两个比较函数(compare和compar)、一个交换函数(exchange)和一个优化的冒泡排序函数(effervescence)。通过传入不同的比较函数和数据类型,可以对不同类型的数组或结构体数组进行排序。
解析优化后:
首先,我们来看一下基础的比较函数。这里有两个比较函数:compare 和 compar。
int compare(const void* a, const void* b)
{return (*(int*)b - *(int*)a);
}struct stu
{char name[20];int age;
};int compar(const void* p1, const void* p2)
{return ((struct stu*)p1)->age - ((struct stu*)p2)->age;} compare 函数用于比较两个整数值,而 compar 函数用于比较两个 stu 结构体的年龄成员。
我们定义一个交换函数 exchange,用于交换两个内存区域的内容:
void exchange(char* a1, char* a2, int sz)
{for (int i = 0; i < sz; i++){char tmp = *a1;*a1 = *a2;*a2 = tmp;a1++;a2++;}
} 这个函数接收两个指针 a1 和 a2 以及元素大小 sz,然后逐个交换这两个内存区域的元素
我们来看看优化的冒泡排序函数 effervescence:
void effervescence(void* base, int num, int sz, int (*pa)(void* p1, void* p2))
{for (int i = 0; i < num - 1; i++){for (int j = 0; j < num - 1 - i; j++) {if (pa((char*)base + j * sz, (char*)base + (j + 1) * sz) > 0){exchange((char*)base + j * sz, (char*)base + (j + 1) * sz, sz);}}}
} 这个函数接收一个基础指针 base、元素数量 num、元素大小 sz 以及一个指向比较函数的指针 pa。它通过两层循环进行冒泡排序,并在需要时调用 exchange 函数交换元素。
最后,我们编写两个测试函数 text1 和 text2,分别用于测试结构体数组和整数数组的排序:
void text1()
{struct stu s1[3] = { {"mdxx",10},{"mxxmm5",20},{"sss",25} };int num = sizeof(s1) / sizeof(s1[0]);int sz = sizeof(s1[0]);effervescence(s1, num, sz, compar);for (int i = 0; i < num; i++) {printf("Name: %s, Age: %d\n", s1[i].name, s1[i].age);}
}void text2()
{int arr[] = { 2,5,4,7,8,9,0,1,6 };int num = sizeof(arr) / sizeof(arr[0]);int sz = sizeof(arr[0]);effervescence(arr, num, sz, compare);for (int i = 0; i < num; i++) {printf("%d ", arr[i]);}printf("\n");
}这个优化的冒泡排序算法可以根据传入的不同比较函数和数据类型,对不同类型的数组或结构体数组进行排序。
原理(先去了解qsort):
冒泡排序的基本原理是通过不断地遍历待排序的列表,并在每次遍历时比较相邻的元素,如果它们的顺序错误(即,前一个元素大于后一个元素),则交换这两个元素的位置。这个过程会重复进行,直到整个列表都被排序。
在原始的冒泡排序算法中,每一轮遍历都会确保最大的元素被“冒泡”到当前未排序部分的末尾。但是,当列表已经部分排序时,这种简单的冒泡方法效率较低,因为它仍然会对已排序的部分进行不必要的比较和交换。为了优化冒泡排序,我们可以引入一个额外的变量来记录最后一次发生交换的位置。在后续的遍历中,我们可以忽略已排序的部分,只需要遍历到上次发生交换的位置即可。这样可以减少不必要的比较和交换,从而提高排序效率。
在我们的 `effervescence` 函数中,我们使用了两层循环来实现冒泡排序:
1. 外层循环:控制总共需要进行多少轮遍历。初始情况下,我们需要进行 n-1 轮遍历,其中 n 是列表的长度。
2. 内层循环:在每一轮遍历中,比较相邻的元素并进行必要的交换。如果发生了交换,我们将更新上次发生交换的位置。通过使用指向比较函数的指针,我们可以根据不同的数据类型和排序需求提供相应的比较逻辑。在 `text1` 和 `text2` 测试函数中,我们分别提供了对结构体数组和整数数组进行排序的比较函数。
在 `compar` 函数中,我们比较了两个 `stu` 结构体的年龄成员,以按照年龄从小到大进行排序。而在 `compare` 函数中,我们直接比较了两个整数值的大小,实现了整数数组的升序排序。
注意看代码的注释,其中原理和qsort函数一样 和一些函数回调,大家慢慢理解其中逻辑,我的文章不解释过多的基础,谅解
相关文章:
)
深入理解C语言中冒泡排序(优化)
目录 引言: 冒泡排序概述: 优化前: 优化后(注意看注释): 解析优化后: 原理(先去了解qsort): 引言: 排序算法是计算机科学中的基础问题之一。在本篇博客中,…...

低代码选型注意事项
凭借着革命性的生产力优势,低代码技术火爆了整个IT圈。面对纷繁复杂的低代码和无代码产品,开发者该如何选择? 在研究低代码平台的年数上,本人已有3年,也算是个低代码资深用户了,很多企业面临低代码选型上的…...

Caffeine--缓存组件
Caffeine 概念缓存手动加载自动加载手动异步加载自动异步加载 驱逐策略基于容量基于时间基于引用 移除显式移除 概念 Caffeine是一个基于Java8开发的提供了近乎最佳命中率的高性能的缓存库。与ConcurrentMap有点相似。最根本的区别是ConcurrentMap将会持有所有加入到缓存当中的…...
Centos7:Jenkins+gitlab+node项目启动(1)
Centos7:Jenkinsgitlabnode项目启动(1) Centos7:Jenkinsgitlabnode项目启动(1)-CSDN博客 Centos7:Jenkinsgitlabnode项目启动(2) Centos7:Jenkinsgitlabnode项目启动(2)-CSDN博客 Centos7:Jenkinsgitlabnode项目启…...

starrocks集群fe/be节点进程守护脚本
自建starrocks集群,有时候服务会挂掉,无法自动拉起服务,于是采用supervisor进行进程守护。可能是版本的原因,supervisor程序总是异常,无法对fe//be进行守护。于是写了个简易脚本。 #!/bin/bash AppNameFecom.starrock…...

奇富科技跻身国际AI学术顶级会议ICASSP 2024,AI智能感知能力迈入新纪元
近日,2024年IEEE声学、语音与信号处理国际会议ICASSP 2024(2024 IEEE International Conference on Acoustics, Speech, and Signal Processing)宣布录用奇富科技关于语音情感计算的最新研究成果论文“MS-SENet: Enhancing Speech Emotion Re…...

如何在Android Termux中使用SFTP实现远程传输文件
文章目录 1. 安装openSSH2. 安装cpolar3. 远程SFTP连接配置4. 远程SFTP访问5. 配置固定远程连接地址6、结语 SFTP(SSH File Transfer Protocol)是一种基于SSH(Secure Shell)安全协议的文件传输协议。与FTP协议相比,SFT…...
高频知识汇总 | 【操作系统】面试题汇总(万字长博通俗易懂)
前言 这篇我亲手整理的【操作系统】资料,融入了我个人的理解。当初我在研习八股文时,深感复习时的困扰,网上资料虽多,却过于繁杂,有的甚至冗余。例如,文件管理这部分,在实际面试中很少涉及&…...

【前端框架】NPM概述及使用简介
什么是 NPM npm之于Node,就像pip之于Python,gem之于Ruby,composer之于PHP。 npm是Node官方提供的包管理工具,他已经成了Node包的标准发布平台,用于Node包的发布、传播、依赖控制。npm提供了命令行工具,使你可以方便地下载、安装、升级、删除包,也可以让你作为开发者发布…...
C# LINQ
一、前言 学习心得:C# 入门经典第8版书中的第22章《LINQ》 二、LINQ to XML 我们可以通过LINQ to XML来创造xml文件 如下示例,我们用LINQ to XML来创造。 <Books><CSharp Time"2019"><book>C# 入门经典</book><…...
云原生机器学习平台cube-studio开源项目及代码简要介绍
1. cube-studio介绍 云原生机器学习平台cube-studio介绍:https://juejin.cn/column/7084516480871563272 cube-studio是开源的云原生机器学习平台,目前包含特征平台,支持在/离线特征;数据源管理,支持结构数据和媒体标…...

大小端存储是什么鬼?
以下内容为本人的著作,如需要转载,请声明原文链接 微信公众号「ENG八戒」https://mp.weixin.qq.com/s/htYGddzO2xPl9kDN4lANpQ 大小端存储的划分是为了解决长度大于一个字节的数据类型内容在存储地址上以不同顺序分布的问题。 比如16位的short整形&…...

WEB:探索开源PDF.js技术应用
1、简述 PDF.js 是一个由 Mozilla 开发的开源 JavaScript 库,用于在浏览器中渲染 PDF 文档。它的目标是提供一个纯粹的前端解决方案,摆脱了依赖插件或外部程序的束缚,使得在任何支持 JavaScript 的浏览器中都可以轻松地显示 PDF 文档。 2、…...

数据分析之词云图绘制
试验任务概述:如下为所给CSDN博客信息表,分别汇总了ai, algo, big-data, blockchain, hardware, math, miniprog等7个标签的博客。对CSDN不同领域标签类别的博客内容进行词频统计,绘制词频统计图,并根据词频统计的结果绘制词云图。…...

【赠书第13期】边缘计算系统设计与实践
文章目录 前言 1 硬件架构设计 2 软件框架设计 3 网络结构设计 4 安全性、可扩展性和性能优化 5 推荐图书 6 粉丝福利 前言 边缘计算是一种新兴的计算模式,它将计算资源推向网络边缘,以更好地满足实时性、低延迟和大规模设备连接的需求。边缘计算…...
数据库01_增删改查
1、什么是数据?什么是数据库? 数据:描述事物的符号记录称为数据。数据是数据库中存储的基本对象。数据库:存放数据的仓库,数据库中可以保存文本型数据、二进制数据、多媒体数据等数据 2、数据库的发展 第一阶段&…...
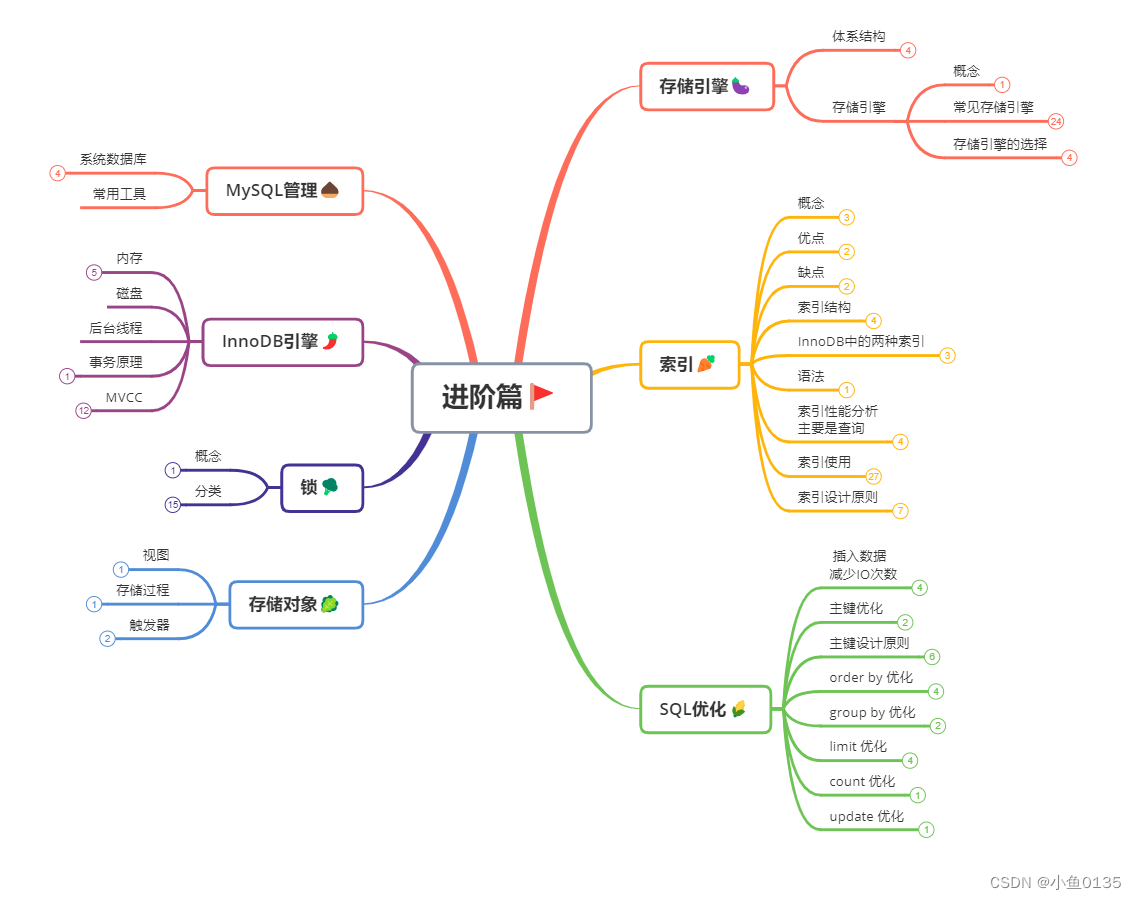
MySQL——进阶篇
二、进阶篇🚩 1. 存储引擎🍆 1.1 MSQL体系结构 连接层: 连接处理,连接认证,每个客户端的权限 服务层: 绝大部分核心功能,可跨存储引擎 可插拔存储引擎: 需要的时候可以添加或拔掉…...

Python 网络编程之搭建简易服务器和客户端
用Python搭建简易的CS架构并通信 文章目录 用Python搭建简易的CS架构并通信前言一、基本结构二、代码编写1.服务器端2.客户端 三、效果展示总结 前言 本文主要是用Python写一个CS架构的东西,包括服务器和客户端。程序运行后在客户端输入消息,服务器端会…...

往年面试精选题目(前50道)
常用的集合和区别,list和set区别 Map:key-value键值对,常见的有:HashMap、Hashtable、ConcurrentHashMap以及TreeMap等。Map不能包含重复的key,但是可以包含相同的value。 Set:不包含重复元素的集合&#…...

解决服务器Tab键不能补全问题
编辑~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml 命令:vim ~/.config/xfce4/xfconf/xfce-perchannel-xml/xfce4-keyboard-shortcuts.xml替换:<property name“<Super>Tab” type“string” value“switch_window…...

Folcolor:让你的Windows文件夹告别“黄脸婆“,用色彩提升3倍工作效率
Folcolor:让你的Windows文件夹告别"黄脸婆",用色彩提升3倍工作效率 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 想象一下这样的场景:你的电…...

打通飞书与GitLab:基于Webhook的事件通知与精准@实践指南
1. 为什么需要打通飞书与GitLab的通知系统 在软件开发团队中,代码仓库的每一次变更都可能影响整个项目进度。传统的做法是开发人员手动在群里相关同事,或者依赖邮件通知,这种方式效率低下且容易遗漏重要信息。我曾经参与过一个跨时区协作项目…...
)
保姆级教程:用YOLOv8和Pyside6从零搭建一个火焰烟雾检测桌面应用(附完整源码和数据集)
从零构建火焰烟雾检测桌面应用:YOLOv8与Pyside6实战指南 在工业安全、家庭监控和实验室防护场景中,火焰与烟雾的早期检测至关重要。传统监控系统依赖人工值守或简单传感器,难以实现精准的实时预警。本文将带你用Python生态中最前沿的YOLOv8目…...

告别虚拟机卡顿:在Ubuntu 18.04上为ARM板交叉编译Qt5.12.9的完整配置流程
突破虚拟机性能瓶颈:Ubuntu 18.04下高效交叉编译Qt5.12.9的工程实践 当你在40GB磁盘空间的Ubuntu虚拟机上尝试编译Qt5.12.9时,解压后的2.8GB源码目录和漫长的编译等待时间可能已经让你抓狂。这不是个例——嵌入式开发工程师经常面临这样的困境࿱…...

贝壳季报图解:营收189亿 经调整净利16亿同比增15.7%
雷递网 雷建平 5月19日贝壳(纽交所代码:BEKE;香港联交所代号:2423)今日公布其截至2026年3月31日止第一季度未经审计财务业绩。财报显示,贝壳2026年第一季度贝壳实现净收入189亿元,净利润12.55亿…...

别只盯着波特率!深入理解英飞凌MCMCAN的报文过滤与优先级处理机制
别只盯着波特率!深入理解英飞凌MCMCAN的报文过滤与优先级处理机制 在嵌入式系统开发中,CAN总线通信的稳定性和效率往往决定了整个系统的性能表现。许多工程师在配置CAN模块时,常常将注意力集中在波特率设置等基础参数上,却忽略了报…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...
)
别再死记0.7V了!用Multisim仿真带你玩转二极管三种等效模型(附实战电路分析)
用Multisim仿真破解二极管模型的三大迷思:从理论到实战的深度探索 在电子工程的学习道路上,二极管总是那个让人又爱又恨的元件。它看似简单,却藏着无数让初学者抓狂的细节。你是否也曾困惑:为什么教科书总说硅管压降是0.7V&#x…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

别再死磕流程图了!用PAD图搞定详细设计,代码自动生成不是梦
别再死磕流程图了!用PAD图搞定详细设计,代码自动生成不是梦 如果你还在用传统流程图做详细设计,每次修改需求都要重画半张图;如果你受够了N-S图方框套方框的视觉折磨,连个简单循环都要画成俄罗斯套娃——是时候认识PAD…...