机器学习系列--R语言随机森林进行生存分析(1)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF)(Ishwaran和Kogalur,2007;Ishwaraan,Kogalur、Blackstone和Lauer(2008)是Breimans射频技术的延伸从而降低了对时间到事件数据的有效非参数分析。
R语言随机森林进行生存分析需要使用到randomForestSRC包,是对Breimans随机森林的统一处理用于生存、回归和分类问题。randomForestSRC包还有一个用于做图的ggRandomForests包,搭配使用,今天咱们来介绍一下怎么使用randomForestSRC包进行随机森林生存分析,内容有点多,咱们分2章来介绍。
咱们先导入数据和R包
library(ggRandomForests)
library(randomForestSRC)
library(ggplot2)
library("dplyr")
pbc<-read.csv("E:/r/test/pbc2.csv",sep=',',header=TRUE)
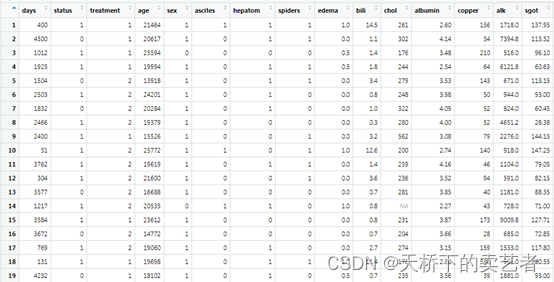
这是一个胆管炎数据(公众号回复:胆管炎数据2,可以获得数据),years:生存时间,status:结局指标,是否死亡,treatment是否DPCA治疗,age年龄,sex性别,ascites是否有腹水,hepatom是否有肝肿大,spiders是否有蜘蛛痣,edema水肿的级别,bili胆红素,chol胆固醇,albumin白蛋白,copper尿酮,alk碱性磷酸酶,sgot:SGOT评分,trig甘油三酯,platelet血小板,prothrombin凝血酶时间,stage组织学分型
我们对数据处理一下,把treatment这个变量变成因子
pbc$treatment<-factor(pbc$treatment)
接下来咱们把数据分成两组,有treatment数据的为测试组,treatment数据缺失的为对照组。
pbc.trial <- pbc %>% filter(!is.na(treatment))
pbc.test <- pbc %>% filter(is.na(treatment))
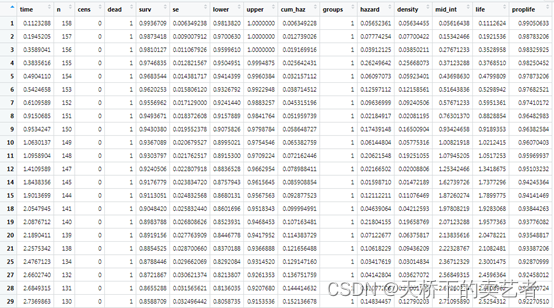
我们先用生存分析做一遍,等下可以和随机森林进行比较,接下来我们用gg_survival对测试组生成生存分析的数据,这个函数挺方便使用的,生成了生存分析的详尽数据
gg_dta <-gg_survival(interval = "years",censor = "status",by = "treatment",data = pbc.trial,conf.int = 0.95)
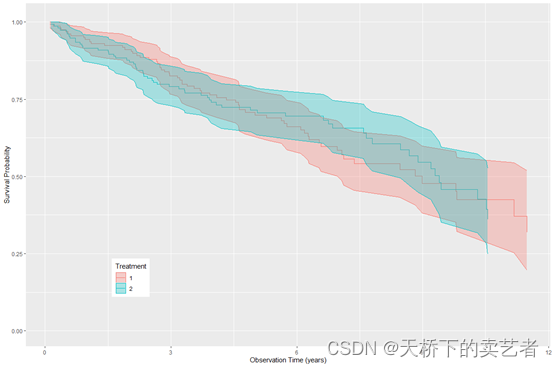
绘图
plot(gg_dta) +labs(y = "Survival Probability", x = "Observation Time (years)",color = "Treatment", fill = "Treatment") +theme(legend.position = c(0.2, 0.2)) +coord_cartesian(y = c(0, 1.01))
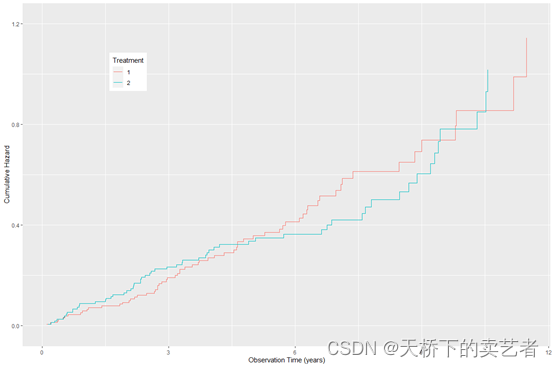
或者绘制成这种累积风险图
plot(gg_dta, type = "cum_haz") +labs(y = "Cumulative Hazard", x = "Observation Time (years)",color = "Treatment", fill = "Treatment") +theme(legend.position = c(0.2, 0.8)) +coord_cartesian(ylim = c(-0.02, 1.22))
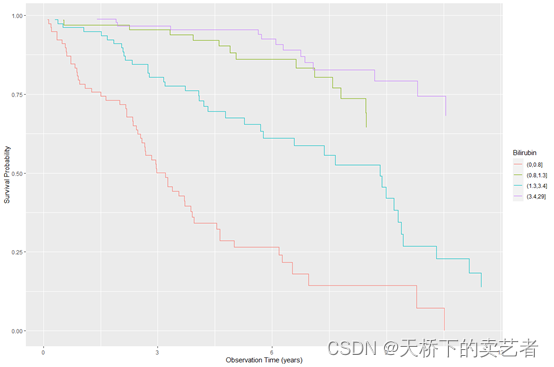
咱们还可以进行断点分层分析,假如咱们对bili这个指标分层4个层(0, 0.8, 1.3, 3.4, 29)
pbc.bili <- pbc.trial
pbc.bili$bili_grp <- cut(pbc.bili$bili, breaks = c(0, 0.8, 1.3, 3.4, 29))
plot(gg_survival(interval = "years", censor = "status", by = "bili_grp",data = pbc.bili), error = "none") +labs(y = "Survival Probability", x = "Observation Time (years)",color = "Bilirubin")
接下来咱们进行随机森林的生存分析,nsplit定义的是随机拆分数,一般默认10次,na.action这里如果选择na.impute就是对缺失数据进行插补,如果选择na.omit就是对缺失数据删除,importance = TRUE这里会计算重要的变量并且进行排序
rfsrc_pbc <- rfsrc(Surv(years, status) ~ ., data = pbc.trial,nsplit = 10, na.action = "na.impute",tree.err = TRUE,importance = TRUE)
查看下基本信息,默认ntree是1000颗数,No. of variables tried at each split: 5这里表示每次都随机取5个变量用于截点。在每个节点,当终端节点包含三个或更少的观测值时停止。Rfsrc函数采用了一个随机logrank分割规则,该规则从nsplit=10中随机选择分割点值。
rfsrc_pbc

程序选择63.2%的样本做估计,剩余36.8%作为袋外数据(OOB)用于测试。gg_error函数对随机林(rfsrc_pbc)对象进行操作以提取错误作为森林中树木数量的函数的估计。
plot(gg_error(rfsrc_pbc))
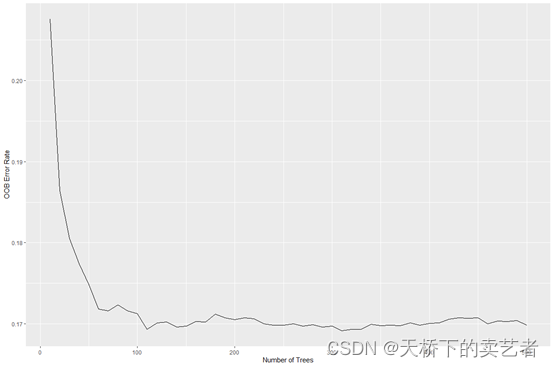
我们可以看到100颗数后,误差已经很稳定了。gg_rfsrc函数可以提取随机森林中袋外数据(OOB)的估计值
out<- gg_rfsrc(rfsrc_pbc)
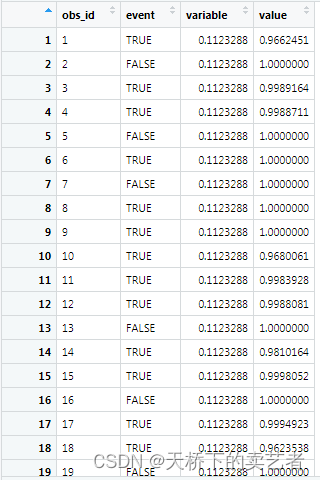
进一步绘图
ggRFsrc <- plot(gg_rfsrc(rfsrc_pbc), alpha = 0.2) +theme(legend.position = "none") +labs(y = "Survival Probability", x = "Time (years)") +coord_cartesian(ylim = c(-0.01, 1.01))
ggRFsrc
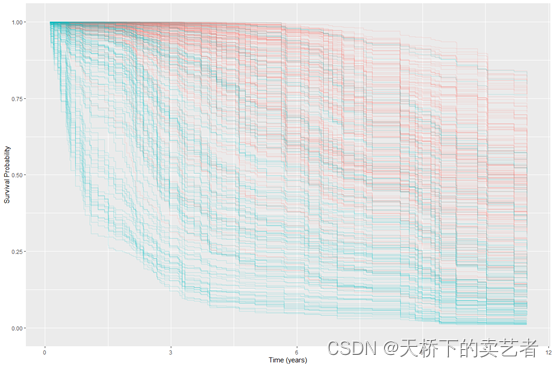
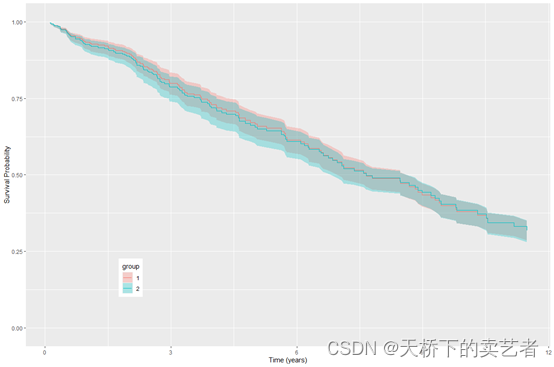
对治疗组和未治疗组进行分类绘图
plot(gg_rfsrc(rfsrc_pbc, by = "treatment")) +theme(legend.position = c(0.2, 0.2)) +labs(y = "Survival Probability", x = "Time (years)") +coord_cartesian(ylim = c(-0.01, 1.01))
使用验证组就行数据评估
rfsrc_pbc_test <- predict(rfsrc_pbc, newdata = pbc.test,na.action = "na.impute",importance = TRUE)
绘图
plot(gg_rfsrc(rfsrc_pbc_test), alpha=.2) +#scale_color_manual(values = strCol) +theme(legend.position = "none") +labs(y = "Survival Probability", x = "Time (years)") +coord_cartesian(ylim = c(-0.01, 1.01))
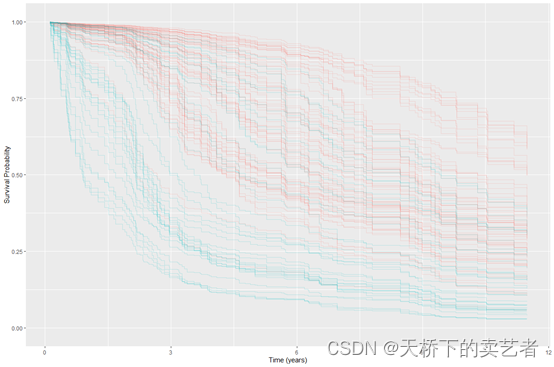
因为咱们选的是treatment缺失的为验证集,这里就不能分组了。
随机林不是一种简约方法,而是使用数据集中所有可用的变量以构建响应预测器。此外,与参数模型不同,随机森林不会要求明确说明协变量对响应的函数形式。因此对于随机森林模型的变量选择,没有明确的p值/显著性检验。相反,RF通过分割规则确定哪些变量对预测有贡献优化,最佳选择分离观察的变量。
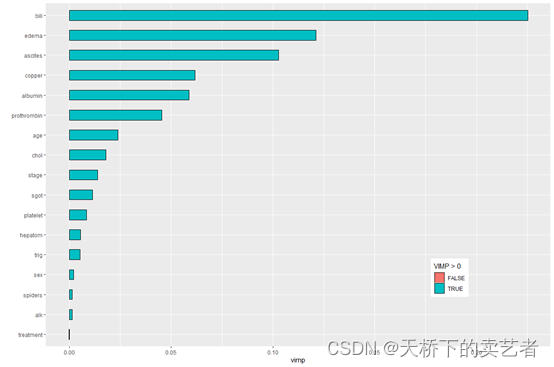
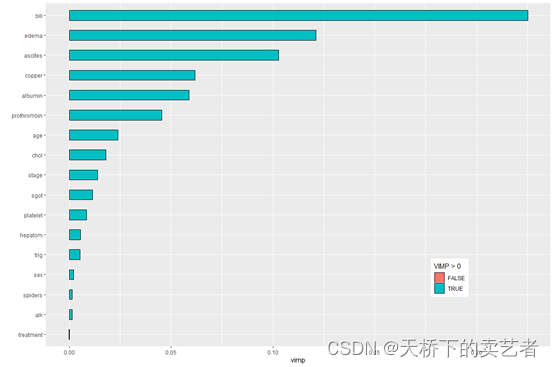
下面来做变量的重要性,VIMP方法使用一种预测误差方法,包括依次对每个变量进行“noising-up”。 由于VIMP是排列前后OOB预测误差的差异VIMP值表示错误指定会降低森林中的预测准确性。VIMP接近零表示该变量对预测准确性没有任何贡献,并且负值表示当变量被错误指定时预测精度提高。
plot(gg_vimp(rfsrc_pbc)) +theme(legend.position = c(0.8, 0.2)) +labs(fill = "VIMP > 0")
本期先介绍到这里,未完待续。
相关文章:
机器学习系列--R语言随机森林进行生存分析(1)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…...
<JavaEE> TCP 的通信机制(四) -- 流量控制 和 拥塞控制
目录 TCP的通信机制的核心特性 五、流量控制 1)什么是“流量控制”? 2)如何做到“流量控制”? 3)“流量控制”的作用 六、拥塞控制 1)什么是“拥塞控制”? 2)如何做到“拥塞…...
智慧监控平台/AI智能视频EasyCVR接口调用编辑通道详细步骤
视频监控TSINGSEE青犀视频平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,GB28181视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多路视频流,…...

Go语言实现KV存储系统:前言
文章目录 前言前提条件持久索引并发总结 前言 你好,我是醉墨居士,最近想做一些存储方面的东西玩玩,我第一时间就想到了能不能自己开发一个保存键值对的存储系统 我找了些资料,准备使用Go语言实现一下,想着有想法咱就…...

代码随想录刷题笔记(DAY1)
前言:因为学校的算法考试让我认识了卡哥,为了下学期冲击大厂实习的理想,我加入了卡哥的算法训练营,从今天开始我每天会更新自己的刷题笔记,与大家一起打卡,一起共勉! Day 1 01. 二分查找 &…...

Linux域名IP映射
本地域名IP映射 在Linux系统中,域名映射可以通过编辑/etc/hosts文件来实现。/etc/hosts文件用于将主机名映射到IP地址,从而实现本地域名解析。它通常被用于在没有DNS服务器的情况下,手动指定特定域名和IP地址的映射关系。 格式:…...

postman使用-03发送请求
文章目录 请求1.新建请求2.选择请求方式3.填写请求URL4.填写请求参数get请求参数在params中填写(填完后在url中会自动显示)post请求参数在body中填写,根据接口文档请求头里面的content-type选择body中的数据类型post请求参数为json-选择raw-选…...

【Spring实战】09 MyBatis Generator
文章目录 1. 依赖2. 配置文件3. 生成代码4. 详细介绍 generatorConfig.xml5. 代码详细总结 Spring MyBatis Generator 是 MyBatis 官方提供的一个强大的工具,它能够基于数据库表结构自动生成 MyBatis 持久层的代码,包括实体类、Mapper 接口和 XML 映射文…...

【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架
一个理解人类偏好学习的统一理论框架 《A General Theoretical Paradiam to Understand Learning from Human Preferences》 论文地址:https://arxiv.org/pdf/2310.12036.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框…...
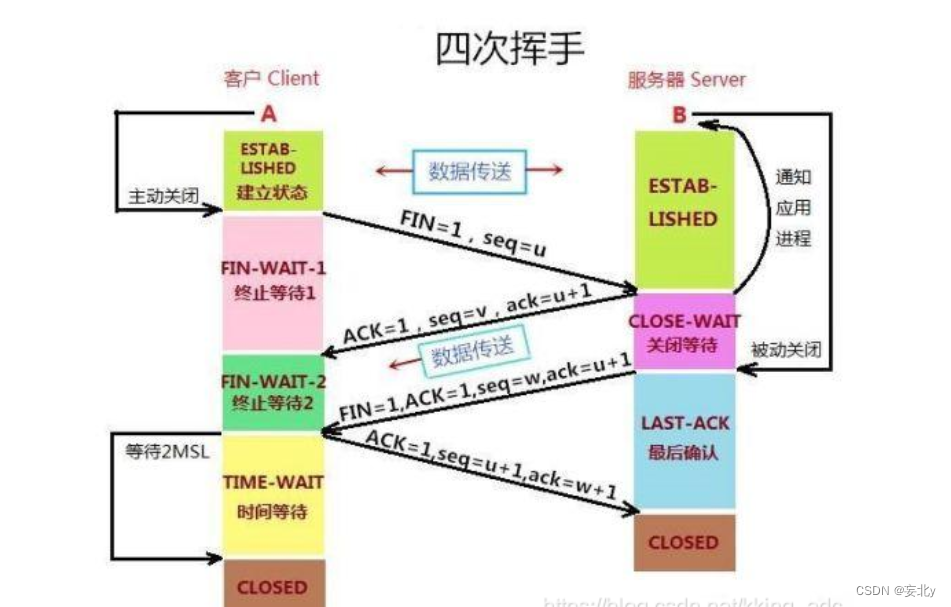
计算机网络——传输层(五)
前言: 最重要的网络层我们已经学习完了,下面让我们再往上一层,对网络层的上一层传输层进行一个学习与了解,学习网络层的基本概念和网络层中的TCP协议和UDP协议 目录 编辑一、传输层的概述: 1.传输层: …...
python3处理docx并flask显示
前言: 最近有需求处理docx文件,并讲内容显示到页面,对world进行在线的阅读,这样我这里就使用flaskDocument对docx文件进行处理并显示,下面直接上代码: Document处理: 首先下载Document的库文…...
Python:正则表达式速通,码上上手!
1前言 正则表达式(Regular Expression)是一种用来描述字符串模式的表达式。它是一种强大的文本匹配工具,可以用来搜索、替换和提取符合特定模式的文本。 正则表达式由普通字符(例如字母、数字、符号等)和元字符&#…...
centos7安装nginx并安装部署前端
目录: 一、安装nginx第一种方式(外网)第二种方式(内网) 二、配置前端项目三、Nginx相关命令 好久不用再次使用生疏,这次记录一下 一、安装nginx 第一种方式(外网) 1、下载nginx ng…...
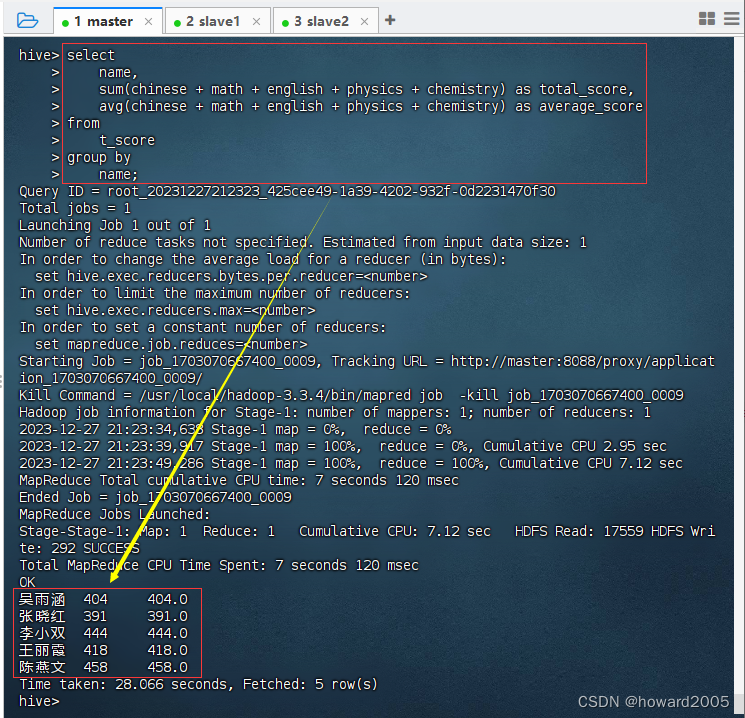
Hive实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、创建Hive表,加载HDFS数据文件…...

Linux:不同计算机使用NFS共享资源
一,安装NFS文件系统 NFS即网络文件系统(network file system),它允许网络中的计算机之间通过网络共享资源。目前,NFS只用于在Linux和UNIX主机间共享文件系统。 #使用mount命令可以将远程主机的文件系统 安装到 本地: #将远程主机…...
leetcode贪心算法题总结(一)
此系列分三章来记录leetcode的有关贪心算法题解,题目我都会给出具体实现代码,如果看不懂的可以后台私信我。 本章目录 1.柠檬水找零2.将数组和减半的最少操作次数3.最大数4.摆动序列5.最长递增子序列6.递增的三元子序列7.最长连续递增序列8.买卖股票的最…...

SQL高级:窗口函数
窗口函数,顾名思义,它的操作对象是窗口,即一个小的数据范围,而不是整个结果集。并且它是一个函数,在SQL中使用,所以一定有返回值。 窗口函数是SQL中非常有趣的部分,这一节我们就来学习一下它。 辅助表 方便我们后边的讲解,这里我们要建一张学生成绩表,建表语句如下…...
)
Excel formulas 使用总结(更新中)
最近在写task assigment的时候学习到的,记录下。 首先它所有需要写赋值formuls都要用 开头 相等赋值 a1 这个就代表这格的数据和a1是一样的。如果希望其他格和它相同的逻辑,可以直接复制该cell或者直接拖动该cell右下角,他会自动进行匹配…...

华为OD机试 - 两个字符串间的最短路径问题(Java JS Python C)
题目描述 给定两个字符串,分别为字符串 A 与字符串 B。 例如 A字符串为 "ABCABBA",B字符串为 "CBABAC" 可以得到下图 m * n 的二维数组,定义原点为(0,0),终点为(m,n),水平与垂直的每一条边距离为1,映射成坐标系如下图。 从原点 (0,0) 到 (0,A) 为水…...

强敌环伺:金融业信息安全威胁分析——钓鱼和恶意软件
门口的敌人:分析对金融服务的攻击 Akamai会定期针对不同行业发布互联网状态报告(SOTI),介绍相关领域最新的安全趋势和见解。最新的第8卷第3期报告主要以金融服务业为主,分析了该行业所面临的威胁和Akamai的见解。我们发…...
)
告别环境冲突:用Conda+Docker在Win10上丝滑搭建MMDetection双环境(附CUDA 11.1/PyTorch 1.8配置)
深度学习环境工程化实践:Conda与Docker双方案打造MMDetection高效工作流 在Windows系统上搭建深度学习开发环境,就像在雷区跳舞——CUDA版本冲突、Python依赖不兼容、系统环境污染等问题随时可能引爆。以MMDetection为例,这个强大的目标检测工…...

如何用WeChatExporter轻松备份和恢复微信聊天记录:Mac用户终极指南
如何用WeChatExporter轻松备份和恢复微信聊天记录:Mac用户终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而懊恼不已…...

终极指南:3步掌握FakeLocation应用级虚拟定位保护隐私
终极指南:3步掌握FakeLocation应用级虚拟定位保护隐私 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否担心手机应用过度获取你的真实位置?想不想为微…...

如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心
如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想在Windows电脑上无缝运行手…...

iOS 27 Siri 自动删除聊天记录:深度解析与行业启示
上周同事跟我吐槽,说他跟Siri聊了点私事,换手机时发现聊天记录全在iCloud里躺着。我跟他说,等iOS 27吧,Siri终于要加自动删除功能了。这个功能不算革命性创新,但方向是对的。下面从用户价值、技术实现和行业影响三个维…...
)
Perplexity vs ChatGPT vs Claude:用户评论情感分析对比报告(NLP模型实测,含21项维度打分)
更多请点击: https://intelliparadigm.com 第一章:Perplexity用户评论汇总 主流平台用户反馈概览 Perplexity 作为以引用驱动、实时联网为特色的AI问答工具,近期在Reddit、Product Hunt及Twitter等平台收获大量真实用户评论。高频关键词包括…...

中兴B862AV3.2M盒子救砖记:免拆机、免ADB,一根双公头USB线搞定刷机
中兴B862AV3.2M盒子救砖实战:零门槛线刷方案详解 当你的中兴B862AV3.2M电视盒子突然黑屏、卡在开机LOGO或完全无法响应时,那种焦虑感与技术无助感往往让人手足无措。不同于常规的系统升级,设备"变砖"状态下的恢复操作需要更谨慎的步…...

从信号放大器到协议感知:深入解析Retimer与Redriver在高速链路中的角色演进
1. 高速链路中的信号完整性挑战 当你把手机靠近路由器时,网速会突然变快;用Type-C线连接移动硬盘传输大文件时,偶尔会出现卡顿——这些现象背后都隐藏着信号完整性这个关键问题。在AI服务器、数据中心互连、高端显卡这些需要高速数据传输的场…...

python海龟绘图之点击屏幕事件处理
在《python海龟绘图之鼠标事件处理》中提到,onclick()函数能够对鼠标点击事件进行处理。但是该鼠标点击事件指的是鼠标点击到海龟图标上的事件,而如果要处理鼠标点击到海龟绘图窗口的任意位置事件的处理,则要用到onscreenclick()函数。通过on…...
)
别再点那个小箭头了!手把手教你用自定义按钮控制ElementUI表格展开行(Vue3 + Element Plus版)
用文字按钮重构Element Plus表格交互:让展开行操作更符合用户直觉 后台管理系统中最常见的交互痛点之一,就是默认的表格展开箭头设计。当用户面对密密麻麻的数据表格时,那个小小的三角形图标往往成为操作盲区。我曾参与过一个电商后台系统的用…...