【Spring】SpringBoot日志

文章目录
- 什么是日志
- 日志的用途
- 日志的使用
- 如何打印日志
- 日志级别
- 日志框架
- 门面模式(外观模式)
- 日志级别的使用
- 配置日志级别
- 日志持久化
- 配置日志的存储目录
- 配置日志文件名
- 配置日志文件分割
- 更简单的日志输出
什么是日志
在计算机领域,日志是一个记录了发生在运行中的操作系统或其他软件中的事件,或者记录了在网络聊天软件的用户之间发送的消息。
通常情况下,系统日志是用户可以直接阅读的文本文件,其中包含了一个时间戳和一个信息或者子系统所特有的其他信息。任何系统中,日志都是非常重要的组成部分,它是反映系统运行情况的重要依据,也是排查问题时的必要线索。
前面我们多多少少都用过日志,并且通过日志来解决我们代码中遇到的问题。像 System.out.println 打印信息就可以看作是一种简单的日志,通过日志我们可以很快的定位到错误出现的位置或者问题出现的详细信息,日志对我们排查问题来说是非常重要的。
虽然 System.out.println 这种形式的日志可以解决问题,但是随着项目复杂度的提升,我们对于日志的打印也有了更高的需求,而不仅仅是定位排查问题。
一些情况,我们往往需要知道程序运行的过程和操作记录,通过这些记录往往能够帮助我们快速的解决遇到的问题。
日志的用途
通过前⾯的学习,我们知道⽇志主要是为了发现问题,分析问题,定位问题的,但除此之外,⽇志还有很多⽤途:
- 系统监控
监控现在⼏乎是⼀个成熟系统的标配,我们可以通过⽇志记录这个系统的运⾏状态,每⼀个⽅法的响应时间,响应状态等,对数据进⾏分析,设置不同的规则,超过阈值时进⾏报警。⽐如统计⽇志中关键字的数量,并在关键字数量达到⼀定条件时报警,这也是⽇志的常⻅需求之⼀ - 数据采集
数据采集是⼀个⽐较⼤的范围,采集的数据可以作⽤在很多⽅⾯,⽐如数据统计,推荐排序等
- 数据统计:统计⻚⾯的浏览量(PV),访客量(UV),点击量等,根据这些数据进⾏数据分析,优化公司运营策略
- 推荐排序:⽬前推荐排序应⽤在各个领域,我们经常接触的各⾏各业很多也都涉及推荐排序,⽐如购物,⼴告,新闻等领域。数据采集是推荐排序⼯作中必须做的⼀环,系统通过⽇志记录用户的浏览历史,停留时⻓,算法⼈员通过分析这些数据,训练模型,给用户做推荐
- 日志审计
随着互联⽹的发展,众多企业的关键业务越来越多的运⾏于⽹络之上。⽹络安全越来越受到⼤家的关注,系统安全也成为了项⽬中的⼀个重要环节,安全审计也是系统中⾮常重要的部分。国家的政策法规、⾏业标准等都明确对⽇志审计提出了要求。通过系统⽇志分析,可以判断⼀些⾮法攻击,⾮法调⽤,以及系统处理过程中的安全隐患
日志的使用
当我们启动 SpringBoot 项目的时候其实就会存在日志。
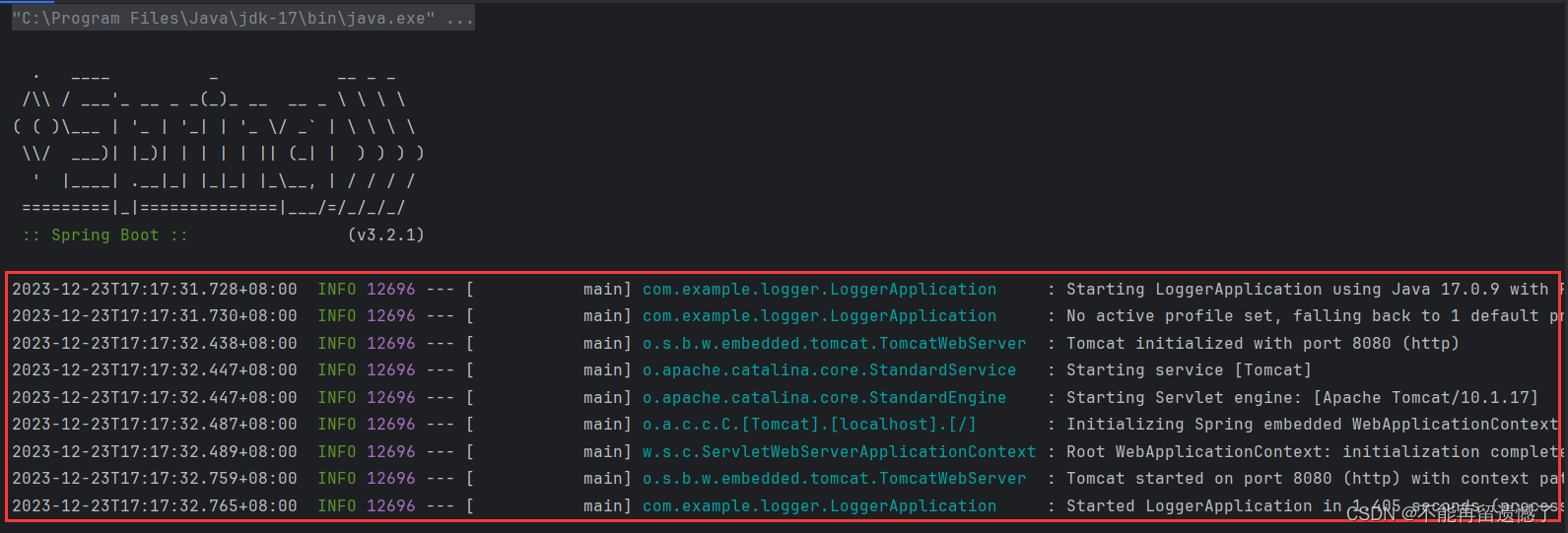
并且通过观察我们可以发现:日志的输出内容包含很多信息,包括时间、在哪个类中打印的和描述信息等等。
就是通过这些日志,我们能根据时间和所属类很快的定位到问题出现的位置。这些是默认存在的会打印的日志,那么我们如何打印出我们自己想要的日志呢?
如何打印日志
Spring 中默认内置了一个日志框架——Slf4j,我们可以通过这个框架来打印出我们想要的日志。
要想打印日志,首先需要获取到日志对象。
Logger 对象的所属包是 org.slf4j 包。
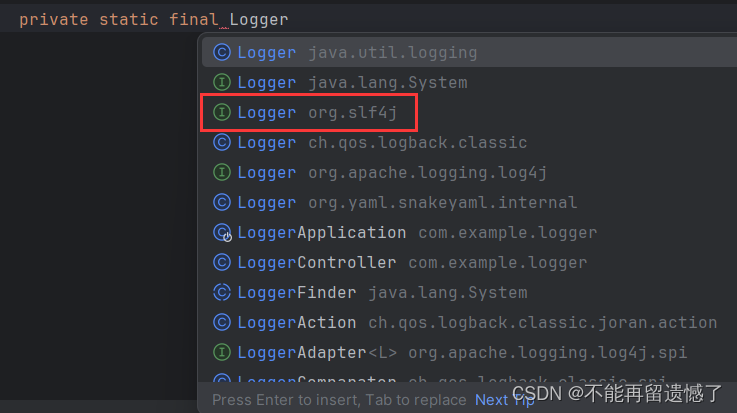
这个 Logger 对象是通过 LoggerFactory 工厂类中的 getLoger获取的。
private static final Logger logger = LoggerFactory.getLogger(LoggerController.class);
注意:getLogger 方法中的参数需要传递一个类对象,用来知道是哪个类输出的日志,当遇到问题时,我们可以根据这个所属类更快的定位到问题所在位置。
当获取到 Logger 日志对象之后,我们就可以通过 Logger 类当中的方法打印出对应的日志。
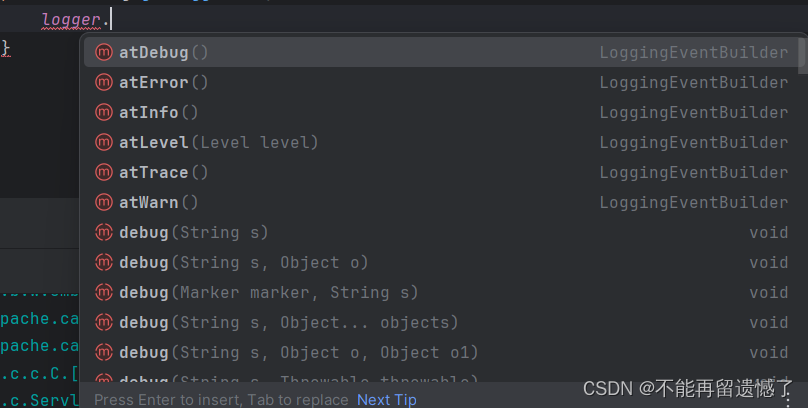
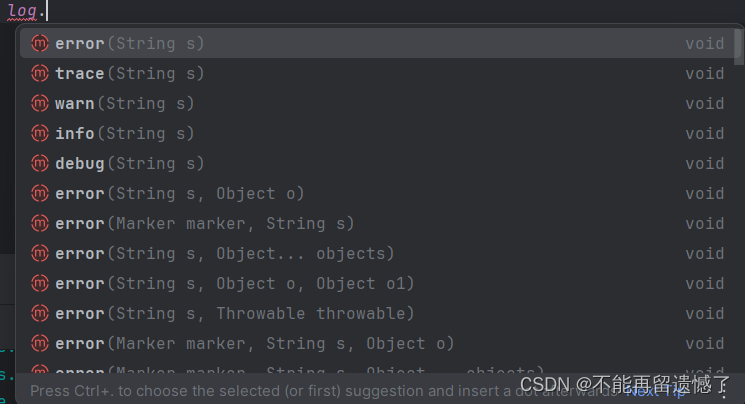
logger 类中有很多方法,但是主要打印日志的方法就是 trace()、deBug()、info()、warn()、error()方法,那么这些方法有什么区别呢?后面再为大家解释,这里我们先使用。一个方法会有很多种的重载方法,我们可以根据需要选择使用哪种传递参数的方法。

package com.example.logger;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class LoggerController {private static final Logger logger = LoggerFactory.getLogger(LoggerController.class);@RequestMapping("/getLogger")public String getLogger() {logger.trace("我是 trace");logger.debug("我是 deBug");logger.info("我是 info");logger.warn("我是 warn");logger.error("我是 error");return "hello logger";}
}

当使用网页访问这个程序的时候,可以发现:虽然控制台中有添加的日志输出,但是可以发现只有 info、warn、error 方法的日志被输入了,那么这是为什么呢?
这里就需要了解什么是日志级别了?
日志级别
日志级别是用于控制程序日志输出内容的一种方式,不同的级别对应不同的方法。日志级别代表着日志信息对应问题的严重性。其主要意义在于:
- 帮助开发者快速定位问题。针对不同级别的日志信息,开发者可以针对性地分析和定位问题,从而更快地解决问题。
- 排除不必要的日志信息。通过设置适当的日志级别,可以避免记录过多的无用信息,从而节约系统资源,提高应用程序的性能。
- 监控系统运行状态。应用程序在运行时会产生大量的信息,这些信息有助于开发者对系统状态进行监控和分析,从而确保应用程序能够稳定运行。
- 保护系统安全。
⽇志的级别从⾼到低依次为:FATAL、ERROR、WARN、INFO、DEBUG、TRACE。
- FATAL:致命信息,表⽰需要立即被处理的系统级错误
- ERROR:错误信息,级别较⾼的错误⽇志信息,但仍然不影响系统的继续运⾏
- WARN:警告信息,不影响使⽤,但需要注意的问题
- INFO:普通信息,⽤于记录应⽤程序正常运⾏时的⼀些信息,例如系统启动完成、请求处理完成等
- DEBUG:调试信息,需要调试时候的关键信息打印
- TRACE:追踪信息,⽐DEBUG更细粒度的信息事件(除⾮有特殊⽤意,否则请使⽤DEBUG级别替代)
如果我们不设置日志级别的话,所有级别的日志信息都会被打印,这样的话控制台就会出现非常多的日志信息,就会导致我们不容易找到具体的需要的日志信息。一些 trace、deBug、info 级别的日志信息,在我们的生产环境是用不到的,这些级别的信息就是在开发环境中会使用到,在生产环境中我们主要使用 warn、error 级别的日志。
⽇志级别是开发⼈员设置的,⽤来给开发⼈员看的。⽇志级别的正确设置,也与开发⼈员的⼯作经验有关。如果开发⼈员把error级别的⽇志设置成了info,就很有可能会影响开发⼈员对项⽬运⾏情况的判断。出现error级别的⽇志信息较多时,可能也没有任何问题。测试的bug级别更多是依据现象和影响范围来判断。

日志框架
在使用日志框架之前,我们还需要了解 Spring 中的日志框架。

Spring 中日志框架分为两层,与我们程序员直接交接的是日志门面,日志的实际打印是日志实现完成的,这个日志门面层相当于中间层。这种模式叫做门面模式。
门面模式(外观模式)
门面模式(Facade Pattern),也叫外观模式,是一种软件设计模式,它为子系统中的一组接口提供一个统一的高层接口,使得子系统更容易使用。
门面模式的主要特征包括:
- 提供一个统一的接口,用来访问子系统中的一群接口。
- 定义了一个高层接口,让子系统更容易使用。
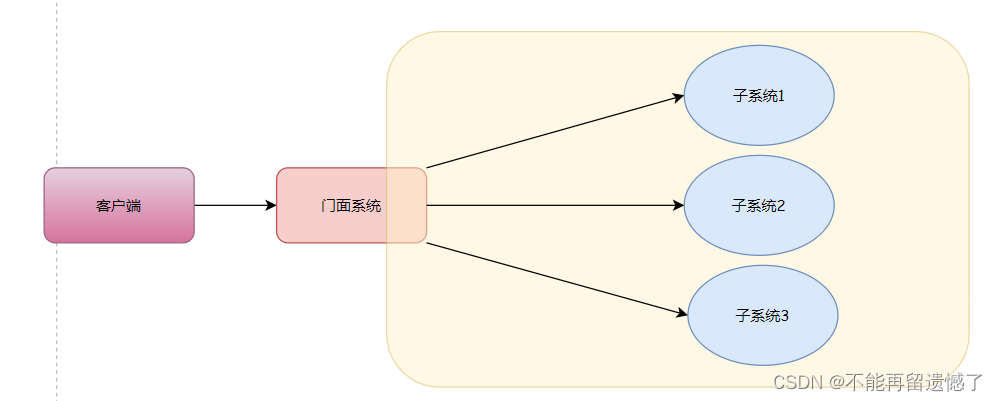
外观⻆⾊(Facade):也称门面角,系统对外的统⼀接⼝
⼦系统⻆⾊(SubSystem):可以同时有⼀个或多个 SubSystem。每个SubSytem 都不是⼀个单独的类,⽽是⼀个类的集合。SubSystem 并不知道 Facade 的存在,对于 SubSystem ⽽⾔,Facade 只是另⼀个
客户端⽽已(即 Facade 对 SubSystem 透明)
对于我们的日志框架来说,为什么会使用门面模式呢?其实关键的原因是为了解耦合。如果我们直接使用日志实现中的接口的话,假设 log4j 1/2 打印日志时使用的是 logger.logger(),那么我们在打印日志的时候调用的方法就是logger.logger()方法,如果后面有一天 log4j 1/2 出现了漏洞,为了安全,公司决定不再使用这个接口,而是改用 logback 接口,但是呢?logback 打印日志使用的方法是 log.log()方法,那么我们之前项目中的 logger.logger() 方法都要修改成 log.log() 方法,如果这代码使用的少还好,如果是一千、一万行呢?这样我们程序员的工作量就会很大,通过使用门面模式,也就是相当于添加了一个中介,我们只告诉中介我们需要干什么,具体的中介安排谁来做,我们呢不关心,由中介来安排,这样就算底层日志实现的接口更换了,因为有这个日志门面也就是中介在,我们还是不需要做出改变的。
这里给大家用代码演示一下:
//这是我们程序员调用log打印日志方法,通过调用slf4j类中的log()方法
slf4j.log("xxxxxx");
//这是slf4j类中的log方法
public void log(String str) {//假设日志门面slf4j使用的日志实现是log4j 1/2log4j.log(str);
}
这里 log4j 12 的具体实现我们先不关心,假设调用 log4j.log() 可以实现日志的打印,如果日志的实现因为漏洞等安全问题需要更改日志实现接口的话,我们程序员的代码是不需要更改的,只需要在 slf4j的 log() 方法中更改调用的接口就行了。
public void log(String str) {//日志实现的接口更换为logbacklogback.log(str);
}
通过门面模式能够解耦合,很大程度的减少我们程序员的负担。
日志级别的使用
SpringBoot 默认使用的门面日志是 SLF4J,默认日志实现是 logback,logback 没有 fatal 级别,它是被映射到 eror 中的。
出现fatal⽇志,表⽰服务已经出现了某种程度的不可⽤,需要需要系统管理员紧急介⼊处理。通常情况下,⼀个进程⽣命周期中应该最多只有⼀次FATAL记录。
打印日志的时候只会打印默认日志级别以及默认日志级别之上的日志级别的日志。
SpringBoot 默认的日志级别是 info 级别,也就是说,只会打印出 info、warn、error的日志级别的日志,那么我们如何修改默认日志级别呢?
配置日志级别
前面我们学习了 SpringBoot 配置文件,配置日志级别就是在配置文件中配置的。
在 properties 配置文件中这样设置 logging.lever.root=debug,yml 配置文件中这样设置:
logging:level:root: debug # root 表示当前项目的所有文件的默认日志级别
再次启动项目可以发现出现了 debug 日志级别以及 debug 日志级别之上的日志级别的日志。
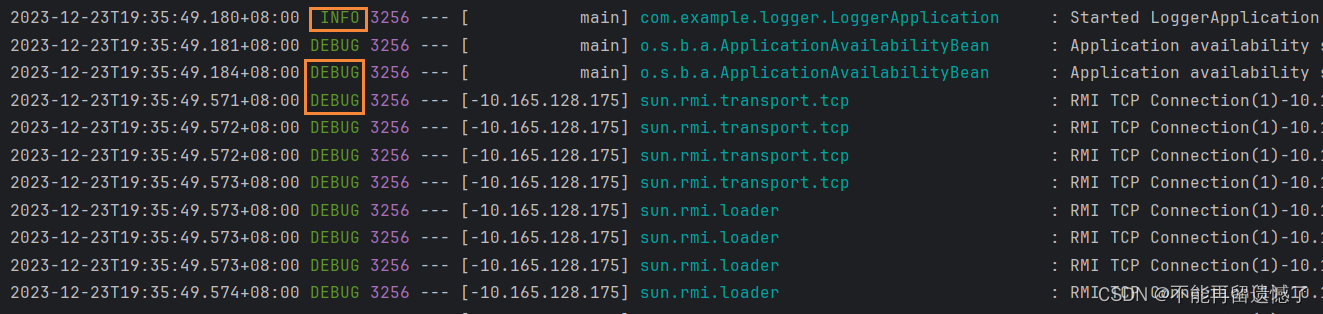
root 表示设置当前项目所有文件的默认日志级别,那么如果我们想要不同文件具有不同的默认日志级别该怎么办呢?其实也不难。我们只需要在配置文件中为指定文件配置默认日志级别就可以达到不同文件配置不同默认日志级别的功能了。
# 这里我们将controller包下的默认日志级别设置为trace
logging:level:root: debugcom:example:logger:controller: trace
那么这样设置的话,除了controller包下的默认日志级别为trace,其他的文件的默认日志级别就是debug了。

日志持久化
出现在控制台的日志是保存在内存中的,当我们重启程序或者重启 idea 的时候,之前的日志就会被丢掉,在实际生活中我们往往需要将日志保存在磁盘上永久保存,这种方式就叫做日志的持久化。
日志持久化有两种方式:
- 配置日志的存储目录
- 配置日志文件名
配置日志的存储目录
当我们使用配置日志的存储目录实现日志的持久化的话,spring 会使用默认的文件名来命名文件。如果指定的文件目录不存在,也会自动创建。
配置日志的存储目录在 properties 配置文件中使用 logging.file.path=xxx配置,在 yml 配置文件中这样配置。
logging:file:path: d://logs
配置文件存储目录,spring 默认的日志文件名是 spring.log,如果日志内容太多操作一个文件的存储大小限制的话,spring 会再创建一个新的文件
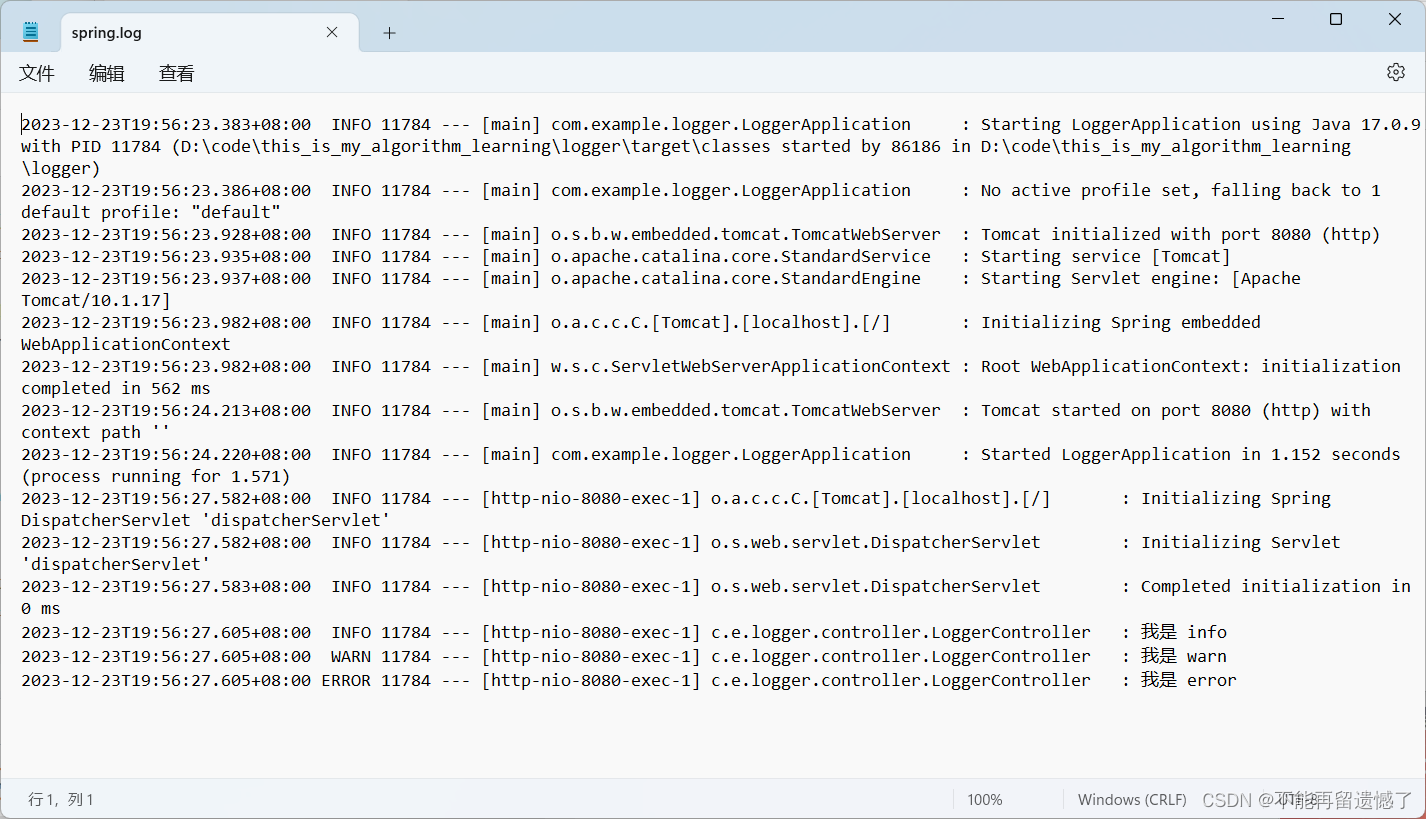
配置日志文件名
保存日志我们也可以指定文件的文件名,在 properties 配置文件中使用 logging.file.name=xxx,在 yml 配置文件中使用:
logging:file:name: springboot-log.log
当访问这个程序之后,会在我们的项目下生成一个指定文件名的文件。
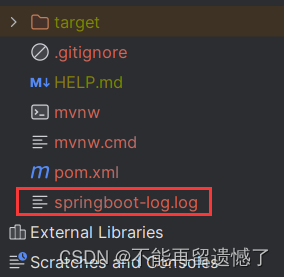
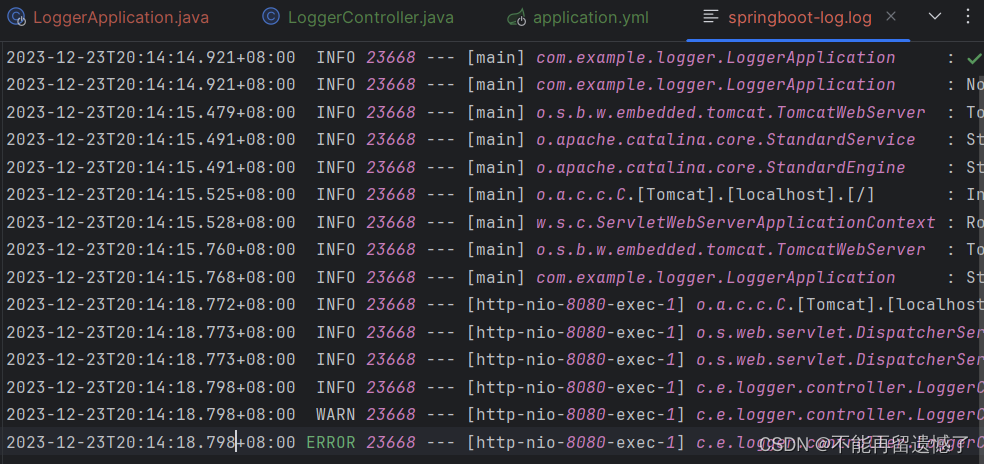
以配置日志文件名的方式保存日志,如果日志的内容过多超出最大限制的话,spring 会在你指定日志文件名的基础上再创建出一个日志文件来做区别。
配置日志文件分割
如果我们将日志都放在一个文件的话,那么随着项目运行时间的增长,文件中的内容会越来越多,如果文件中的数据达到一定数量之后,那么我们想要在这个文件中查找指定日志的话就会显得非常麻烦,那么如何解决这个问题呢?
解决这个问题可以实现对日志文件的分割,当日志文件达到一定大小之后,会再创建出一个日志文件,将后面的日志保存在这个新创建的文件中。
关于更多的 SpringBoot 日志的配置项,大家可以去官网看看SpeingBoot配置
这里日志文件分割主要与这两个配置有关。

第一个配置是日志文件分割的名称定义规则,第二个则是日志文件的最大容量,当日志文件的大小大于这个最大容量的话,那么就会根据这个日志文件分割的名称定义规则创建出新的文件存储后面的日志信息。
logging.logback.rollingpolicy.file-name-pattern配置的默认值是 ${LOG_FILE}.%d{yyyy-MM-dd}.%i
也就是这种形式:
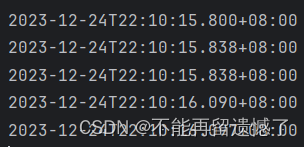
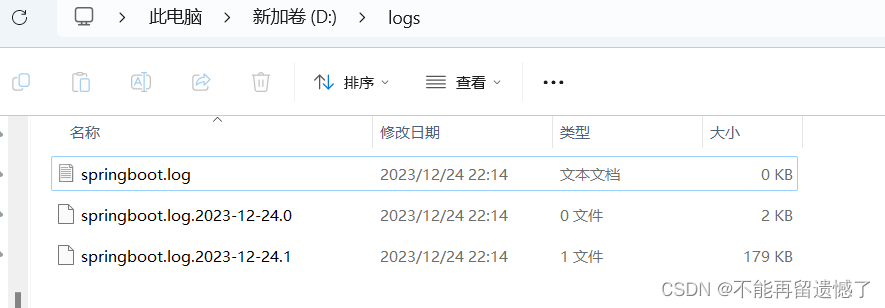
然后我们设置日志文件的最大容量为 1KB 来看看效果:
logging:file:name: d://logs/springboot.loglogback:rolling policy:file-name-pattern: ${LOG_FILE}.%d{yyyy-MM-dd}.%imax-file-size: 1KBlevel:root: debug
更简单的日志输出
这里简单主要是简单在日志对象的创建上,使用上面的方法创建文件对象的话,每次都需要这样创建。
private static final Logger logger = LoggerFactor.getLogger(Main.class)
每个类中创建日志对象的代码百分之其实都是相同的,所以为了节省这个创建日志对象的代码,我们就可以使用一个工具类 Lombok,在这篇文章中为大家说明了如何下载 Lombok SpringMVC案例
使用 Lombok 工具类之后我们只需要在类上加上一个 slf4j 注解,那么这个类中就会默认创建出一个 Logger 类的实例 log,可以直接使用。
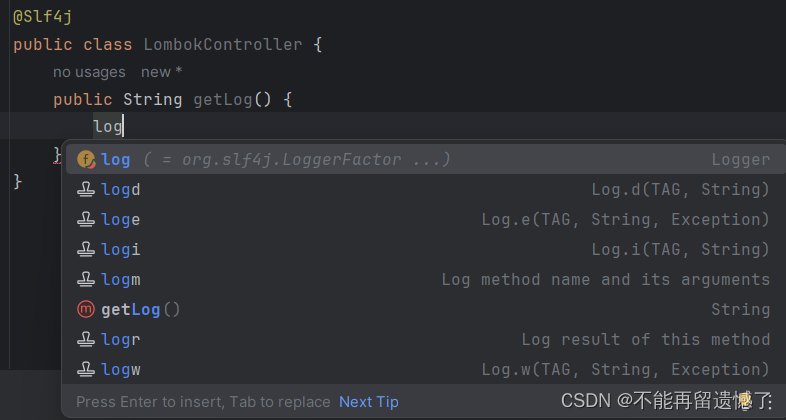
package com.example.logger.controller;import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@Slf4j
public class LombokController {@RequestMapping("/getLombok")public String getLog() {log.trace("我是 trace");log.debug("我是 deBug");log.info("我是 info");log.warn("我是 warn");log.error("我是 error");return "hi lombok";}
}
那么为什么加了 @Slf4j 之后就会自动创建出一个 Logger 对象呢?其实 Lombok 在代码编译阶段做了“手脚”。
Java程序运行原理

Lombok 作用:

我们来看看编译形成的.class文件,看看跟正常的创建 Logger 对象有什么区别。
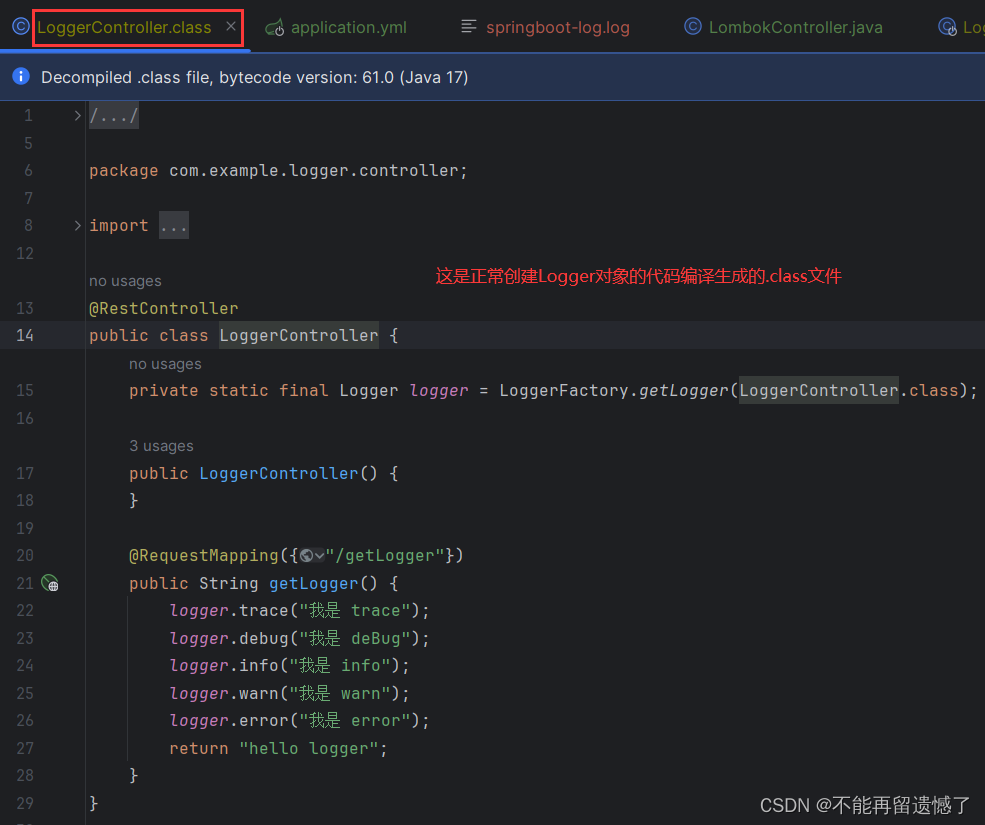

可以看到,Lombok作用在代码的编码期间,在这个过程在 @Slf4j 注解会被替换为 private static final Logger log = LoggerFactory.getLogger(LombokController.class)这个创建 Logger 的代码,因此,当我们加上这个注解之后,该类中就会自动创建一个 Logger 对象 log。通过这个注解可以简化我们的创建过程。
相关文章:
【Spring】SpringBoot日志
文章目录 什么是日志日志的用途日志的使用如何打印日志日志级别日志框架门面模式(外观模式)日志级别的使用配置日志级别日志持久化配置日志的存储目录配置日志文件名配置日志文件分割 更简单的日志输出 什么是日志 在计算机领域,日志是一个记…...

HTML+CSS制作动漫绿巨人
🎀效果展示 🎀代码展示 <!DOCTYPE html> <html lang="en" > <head>...

AGV智能搬运机器人-替代人工工位让物流行业降本增效
在当今快速发展的世界中,物流业面临着巨大的挑战,包括提高效率、降低成本和优化工作流程。为了应对这些挑战,一种新型的自动化设备——智能搬运机器人正在崭露头角。本文将通过一个具体的案例来展示富唯智能转运机器人在实际应用中的价值。 案…...
【办公技巧】怎么批量提取文件名到excel
Excel是大家经常用来制作表格的文件,比如输入文件名,如果有大量文件需要输入,用张贴复制或者手动输入的方式还是很费时间的,今天和大家分享如何批量提取文件名。 打开需要提取文件名的文件夹,选中所有文件,…...

uniapp实现前端银行卡隐藏中间的数字,及隐藏姓名后两位
Vue 实现前端银行卡隐藏中间的数字 主要应用了 filters过滤器 来实现效果 实现效果,如图: <template><div><div style"background-color: #f4f4f4;margin:50px 0 0 460px;width:900px;height:300px;"><p>原来&#…...

HPCC:高精度拥塞控制
HPCC:高精度拥塞控制 文章目录 HPCC:高精度拥塞控制摘要1 引言1.1 背景1.2 现有CC的局限性1.3 HPCC的提出 2 研究动机2.1 大型RDMA部署2.2 RDMA目标2.3 当前RDMA CC中的权衡DCQCNTIMELY 2.4 下一代高速CC 3 技术方案3.1 INT3.2 HPCC设计3.3 HPPC的参数 4…...

centos 配置 git 连接 github
centos 配置 git 连接 github 首先安装 git 创建 ssh key ssh-keygen -t rsa复制公钥 cat ~/.ssh/id_rsa.pub # 打印出公钥内容然后复制配置 github 登录网页 github 账号;进入 setting;点击 SSH and GPG keys,点击 New SSH keytitile 随便填…...
SpringBoot发布项目到docker
Dockerfile FROM openjdk:11 # 作者 MAINTAINER chenxiaodong<2774398338qq.com># 安装 vim # RUN yum -y install vim# 环境变量 # 进入容器后的默认工作目录 ENV WORKPATH /usr/local/webapp ENV EXECFILE Docker2Application-0.0.1-SNAPSHOT.jarRUN mkdir -p $WORKPA…...
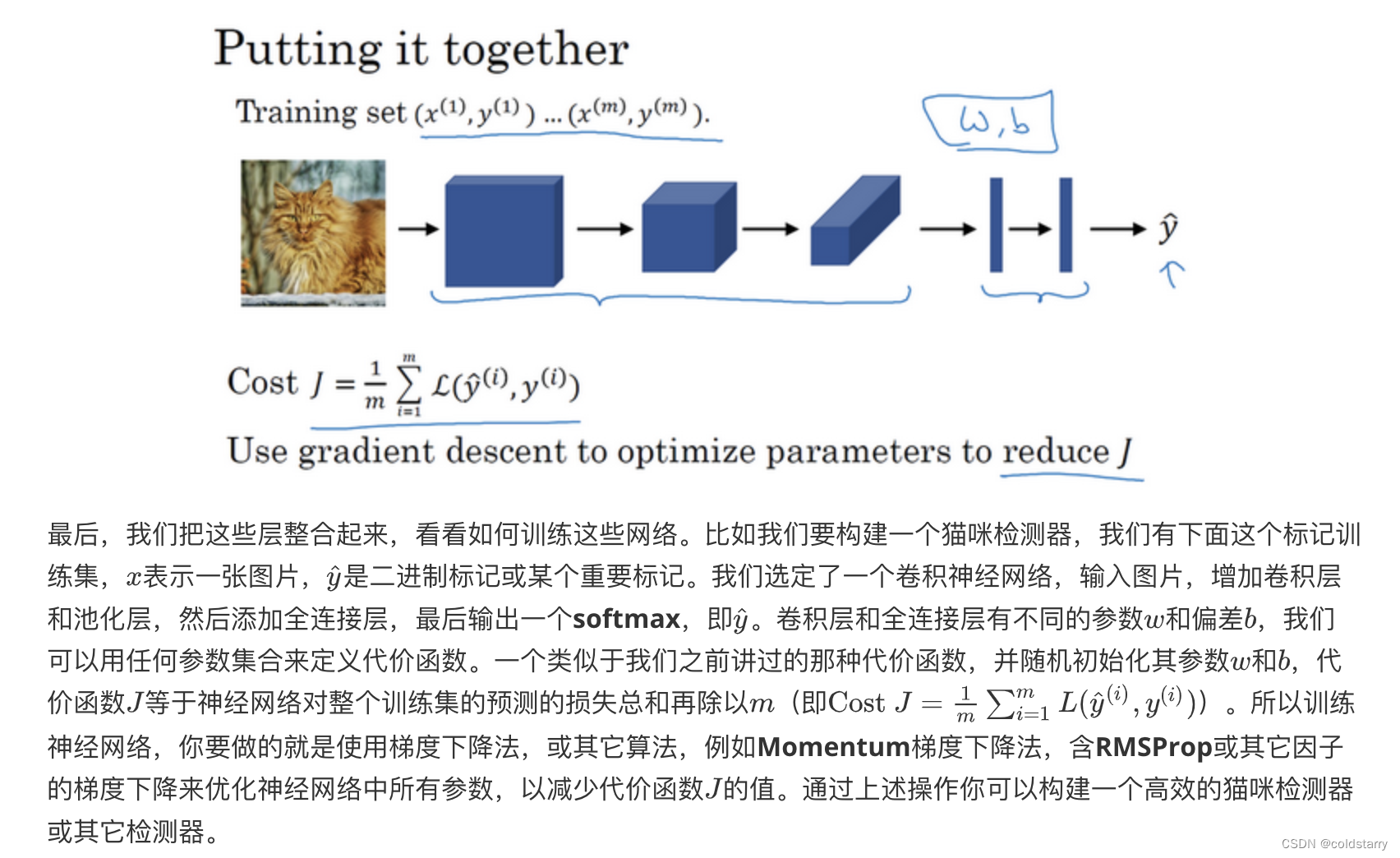
sheng的学习笔记-卷积神经网络
源自吴恩达的深度学习课程,仅用于笔记,便于自行复习 导论 1)什么是卷积神经网络 卷积神经网络,也就是convolutional neural networks (简称CNN),使用卷积算法的神经网络,常用于计…...
)
数据库:园林题库软件(《中国古代园林史》答题卷一 )
《中国古代园林史》答题卷一 填空题 1、中国古代园林曾被誉为“世界园林之母”。国际风景园林师联合会(IFLA)的创始人、著名风景园林师和教育家杰里柯爵士( Sir Geoffrey Alan Jellicoe)把中国古代园林和西亚园林以及古希腊园林列为世界三大园林体系之首。 2、中国古代园林是…...
upset 绘制
好久没有更新,今天来一个upset图的绘制 1.1 安装包 #绘制upset的包现在看来有三个 ## UpSet ### 最基本的upsetR包,使用方便,但是扩展不方便 devtools::install_github("hms-dbmi/UpSetR") ## complex-upset ### UpSet的升级款 支持ggplot2 devtools::install_git…...
声明 | 为打击假冒账号、恶意抄袭账号等诈骗活动,提升本账号权威,本博主特此郑重声明
声明 | 为打击假冒账号、恶意抄袭账号诈骗活动,提升本账号权威,本博主特此郑重声明 一、本账号为《机器学习之心》博主CSDN唯一官方账号,唯一联系方式见文章底部。 二、《机器学习之心》博主未授权任何第三方账号进行模型合作、程序设计、源…...

云计算:OpenStack 配置二层物理网卡为三层桥的接口
目录 一、理论 1.OpenStack 二、实验 1. Linux系统修改网卡 2.OpenStack 配置二层物理网卡为三层桥的接口 一、理论 1.OpenStack (1)概念 OpenStack是一个开源的云计算管理平台项目,是一系列软件开源项目的组合。由NASA(美国国家航空…...

Python sanic框架钉钉和第三方打卡机实现
同样还是需要开通钉钉应用这里就不错多说了 第一步:梳理逻辑流程 前提:打卡的机器是使用postgres数据库,由于因为某些原因,钉钉userId 我已经提前获取到了存放到数据库里。 1.用户打卡成功后,我们应该监听数据库进行查询…...

微信小程序性能优化
1. 代码包不包含插件大小超过 1.5 M 建议:小程序代码包单个包大小限制为2M。因此我们建议开发者在开发时,如果遇到单包体积大于1.5M的情况,可以采取分包的方式,把部分代码拆分到分包去,降低单个包的体积,提…...
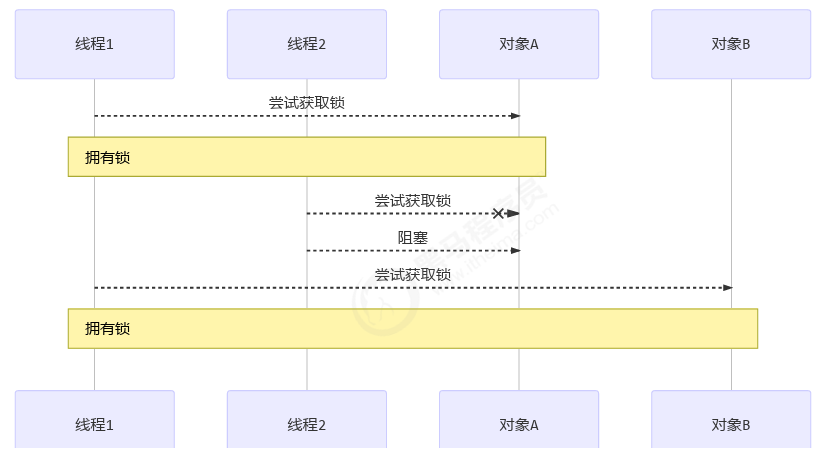
java并发编程六 ReentrantLock,锁的活跃性
多把锁 一间大屋子有两个功能:睡觉、学习,互不相干。 现在小南要学习,小女要睡觉,但如果只用一间屋子(一个对象锁)的话,那么并发度很低 解决方法是准备多个房间(多个对象锁…...
深度学习 | DRNN、BRNN、LSTM、GRU
1、深度循环神经网络 1.1、基本思想 能捕捉数据中更复杂模式并更好地处理长期依赖关系。 深度分层模型比浅层模型更有效率。 Deep RNN比传统RNN表征能力更强。 那么该如何引入深层结构呢? 传统的RNN在每个时间步的迭代都可以分为三个部分: 1.2、三种深层…...

代理模式:中间者的故事
代理模式:中间者的故事 介绍需求分析代理模式代码实现代理模式整理和用途第一种用途第二种用途第三种用途第四种用途 总结 介绍 本文引用《大话设计模式》第七章节的内容进行学习分析,仅供学习使用 需求:小明拜托自己好朋友小王给他朋友小美…...

中间件系列 - Redis入门到实战(高级篇-多级缓存)
前言 学习视频: 黑马程序员Redis入门到实战教程,深度透析redis底层原理redis分布式锁企业解决方案黑马点评实战项目 中间件系列 - Redis入门到实战 本内容仅用于个人学习笔记,如有侵扰,联系删除 学习目标 JVM进程缓存Lua语法入…...

是德科技E9304A功率传感器
是德科技E9304A二极管功率传感器测量频率范围为9 kHz至6 GHz的平均功率,功率范围为-60至20 dBm。该传感器非常适合甚低频(VLF)功率测量。E系列E9304A功率传感器有两个独立的测量路径,设计用于EPM系列功率计。功率计自动选择合适的功率电平路径。为了避免…...

告别手动提交!用Bash脚本批量处理VASP+ShengBTE热输运计算的700+任务
计算材料学自动化革命:Bash脚本驱动的高通量热输运计算实践 在计算材料学领域,研究者常常需要处理数百甚至上千个相似的计算任务。以硅材料热输运性质计算为例,当使用VASP结合ShengBTE进行三阶力常数计算时,可能产生700多个独立的…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》005、DEIM模型架构总览——编码器-解码器与动态门控设计
CVPR2025-DEIM创新改进项目实战:DEIM模型架构总览——编码器-解码器与动态门控设计 从一次诡异的梯度爆炸说起 去年冬天调DEIM的早期原型,模型在训练到第47个epoch时突然loss飙到NaN。检查了三天,最后发现是门控模块的sigmoid输出在极端情况下饱和,导致梯度回传时门控信号…...

Vue3 表单深度解析
Vue3 表单深度解析 引言 随着前端技术的发展,Vue.js 已经成为最受欢迎的前端框架之一。Vue3 作为 Vue.js 的最新版本,带来了许多改进和新特性。其中,表单处理是 Vue3 中一个非常重要的部分。本文将深入解析 Vue3 表单的用法、特点以及最佳实践。 Vue3 表单概述 在 Vue3 …...

operation backup
operation & backup 运维备份(多地)...

3个步骤让你的Mac原生支持200+视频格式预览
3个步骤让你的Mac原生支持200视频格式预览 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcode.com/gh_mirrors/ql/Qu…...

Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告 实测方法论:三维度穿透式评估框架 我们对全国37所高校(含985/2…...

Kubernetes核心知识点
1.ca-certificates,gnupg,lsb-release三个包的解释. ca-certificates是系统内置的权威根整数数据包,可以让系统正常识别并信任各类网站,避免出现证书异常与访问失败问题。 gnupg是开源的加密与签名校验工具,可用于导入第三方软件源公钥&#…...

当贝盒子H5 64G版618首销TOP1!多平台登顶,凭什么这么火?
2026年5月14日,当贝官方发布了618抢先购首日当贝盒子H5 64G版的首销战报。据官方数据显示,这款重磅升级的电视盒子在京东、天猫、抖音三大主流电商平台的电视盒子类目热销榜中,全部拿下TOP1席位,成为今年618大促第一天的现象级爆款…...

电力线路保护原理与整定计算实战解析:从电流、距离到差动保护
1. 项目概述:从“黑匣子”到“透明逻辑”在电力系统这个庞大而精密的网络中,输电线路如同人体的动脉血管,承担着输送能量的核心使命。然而,这条“动脉”时刻面临着雷击、外力破坏、绝缘老化、过负荷等各类风险的威胁。一旦发生故障…...

万物智联城市:TurMass™ Mesh 打造稳定可靠的物联底座
随着数字中国建设深入推进,智慧城市已从概念落地为城市治理与民生服务的现实场景。从市政设施智能运维、公共安全全域感知,到环境监测精准布控、便民服务高效触达,城市运行的每一环都离不开稳定、高效、低成本的物联网连接支撑。然而…...