Hive执行计划
Hive提供了explain命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理,Hive 调优,排查数据倾斜等很有帮助。
使用语法如下:
explain query;
在 hive cli 中输入以下命令(hive 2.3.7):
explain select sum(id) from test1;
得到结果:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: test1Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: id (type: int)outputColumnNames: idStatistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(id)mode: hashoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorsort order:Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col0 (type: bigint)Reduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)mode: mergepartialoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink我们将上述结果拆分看,先从最外层开始,包含两个大的部分:
-
stage dependencies:各个stage之间的依赖性
-
stage plan:各个stage的执行计划
先看第一部分 stage dependencies ,包含两个 stage,Stage-1 是根stage,说明这是开始的stage,Stage-0 依赖 Stage-1,Stage-1执行完成后执行Stage-0。
再看第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
-
Map Operator Tree:MAP端的执行计划树
-
Reduce Operator Tree:Reduce端的执行计划树
这两个执行计划树里面包含这条sql语句的 operator:
-
TableScan:表扫描操作,map端第一个操作肯定是加载表,所以就是表扫描操作,常见的属性:
-
alias:表名称
-
Statistics:表统计信息,包含表中数据条数,数据大小等
-
-
Select Operator:选取操作,常见的属性 :
-
expressions:需要的字段名称及字段类型
-
outputColumnNames:输出的列名称
-
Statistics:表统计信息,包含表中数据条数,数据大小等
-
-
Group By Operator:分组聚合操作,常见的属性:
-
aggregations:显示聚合函数信息
-
mode:聚合模式,值有 hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
-
keys:分组的字段,如果没有分组,则没有此字段
-
outputColumnNames:聚合之后输出列名
-
Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
-
-
Reduce Output Operator:输出到reduce操作,常见属性:
-
sort order:值为空 不排序;值为 + 正序排序,值为 - 倒序排序;值为 +- 排序的列为两列,第一列为正序,第二列为倒序
-
-
Filter Operator:过滤操作,常见的属性:
-
predicate:过滤条件,如sql语句中的where id>=1,则此处显示(id >= 1)
-
-
Map Join Operator:join 操作,常见的属性:
-
condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join0 to 2
-
keys: join 的条件字段
-
outputColumnNames:join 完成之后输出的字段
-
Statistics:join 完成之后生成的数据条数,大小等
-
-
File Output Operator:文件输出操作,常见的属性
-
compressed:是否压缩
-
table:表的信息,包含输入输出文件格式化方式,序列化方式等
-
-
Fetch Operator 客户端获取数据操作,常见的属性:
-
limit,值为 -1 表示不限制条数,其他值为限制的条数。
-
定位产生数据倾斜的代码段
数据倾斜大多数都是大 key 问题导致的。
如何判断是大 key 导致的问题,可以通过下面方法:
1. 通过时间判断
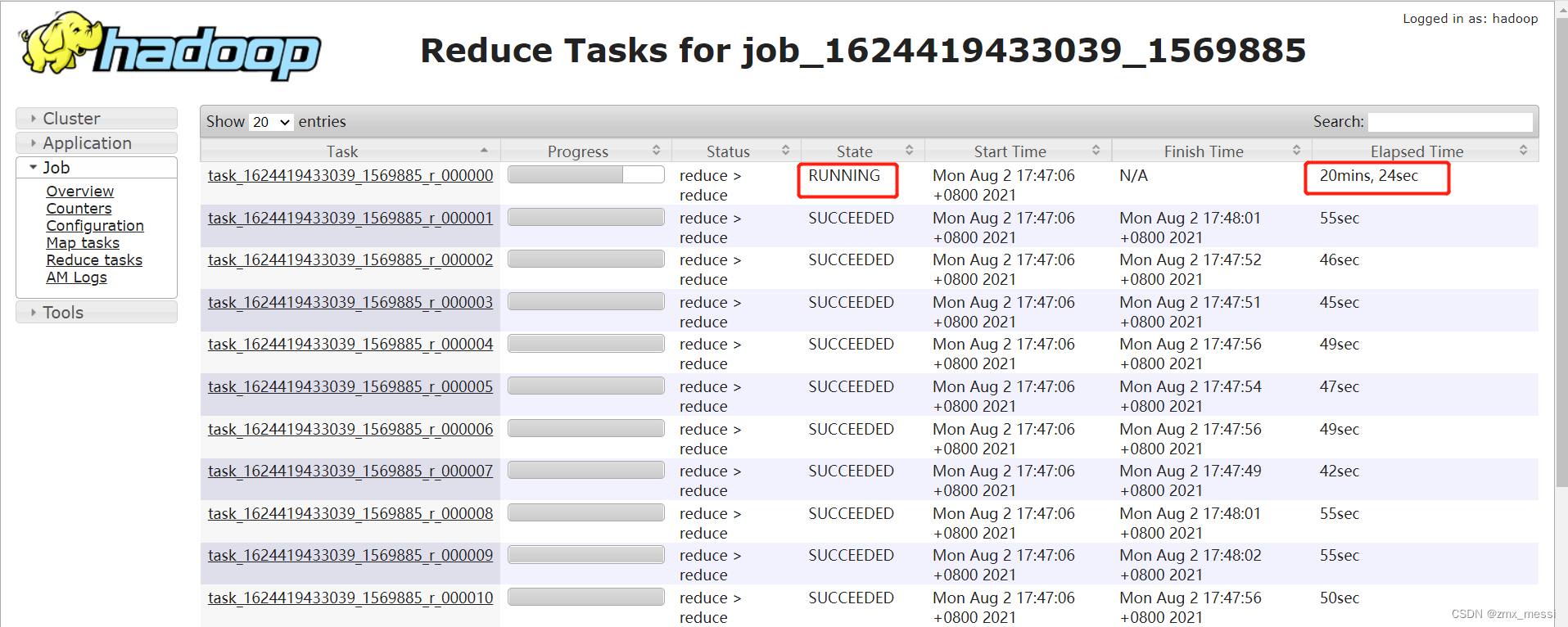
如果某个 reduce 的时间比其他 reduce 时间长的多,如下图,大部分 task 在 1 分钟之内完成,只有 r_000000 这个 task 执行 20 多分钟了还没完成。
定位 SQL 代码
确定任务卡住的 stage
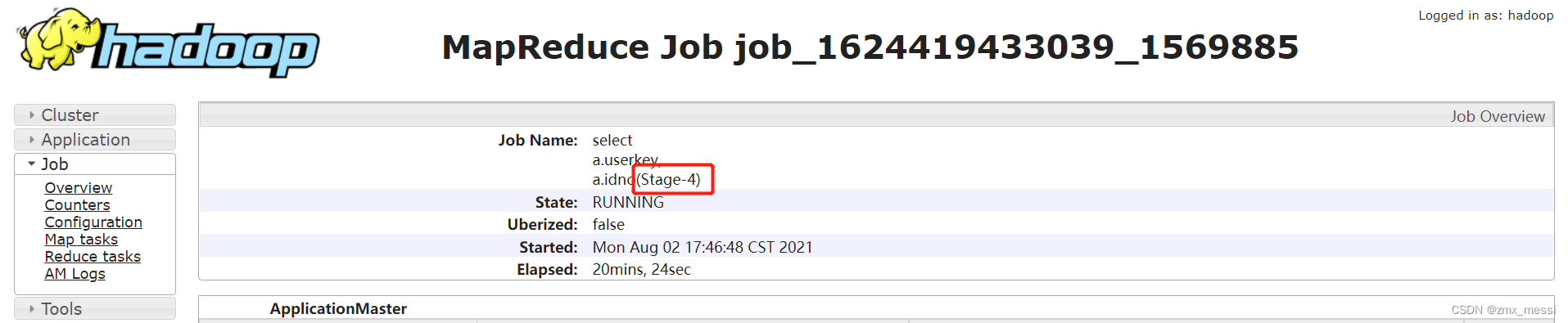
- 通过 jobname 确定 stage:
一般 Hive 默认的 jobname 名称会带上 stage 阶段,如下通过 jobname 看到任务卡住的为 Stage-4:
- 如果 jobname 是自定义的,那可能没法通过 jobname 判断 stage。需要借助于任务日志:
找到执行特别慢的那个 task,然后 Ctrl+F 搜索 “CommonJoinOperator: JOIN struct” 。Hive 在 join 的时候,会把 join 的 key 打印到日志中。如下:

上图中的关键信息是:struct<_col0:string, _col1:string, _col3:string>
这时候,需要参考该 SQL 的执行计划。通过参考执行计划,可以断定该阶段为 Stage-4 阶段:

2. 确定 SQL 执行代码
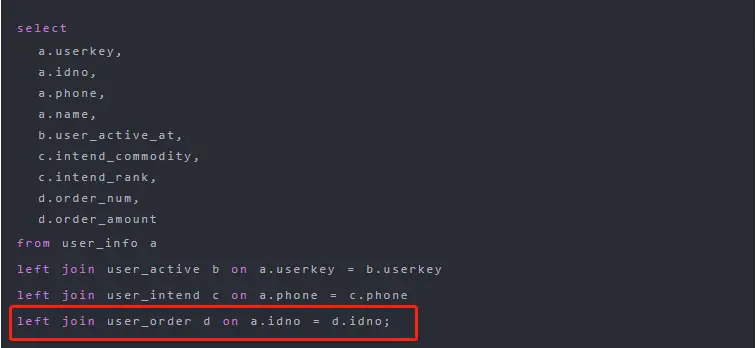
确定了执行阶段,即 Stage-4 阶段。通过执行计划,则可以判断出是执行哪段代码时出现了倾斜。还是从此图,这个 Stage-4 阶段中进行连接操作的表别名是 d:

就可以推测出是在执行下面红框中代码时出现了数据倾斜,因为这行的表的别名是 d:
以上仅列举了4个我们生产中既熟悉又有点迷糊的例子,explain 还有很多其他的用途,如查看stage的依赖情况、hive 调优等,小伙伴们可以自行尝试。
相关文章:
Hive执行计划
Hive提供了explain命令来展示一个查询的执行计划,这个执行计划对于我们了解底层原理,Hive 调优,排查数据倾斜等很有帮助。 使用语法如下: explain query;在 hive cli 中输入以下命令(hive 2.3.7): explain select s…...

Leetcode—62.不同路径【中等】
2023每日刷题(七十二) Leetcode—62.不同路径 超时dfs代码 class Solution { public:int uniquePaths(int m, int n) {int starti 1, startj 1;int ans 0;function<void(int, int)> dfs [&](int i, int j) {if(i m && j n) {a…...
【汇编笔记】初识汇编-内存读写
汇编语言的由来: CPU是计算机的核心,由于计算机只认识二进制,所以CPU执行的指令是二进制。 我们要想让CPU工作,就得给他提供它认识的指令,这一系列的指令的集合,称之为指令集。 指令集: 不同的体…...

Shell脚本通过渗透测试检测服务器安全!
以下是一个简单的 Shell 脚本通过渗透测试来发现服务器漏洞的例子: #!/bin/bash # 设置变量 server_url"http://example.com" server_port"80" script_path"/path/to/script.脚本" # 创建并打开 Web 服务器 web_server$(curl -s $se…...
数据结构--查找
目录 1. 查找的基本概念 2. 线性表的查找 3. 树表的查找 3.1 二叉排序树 3.1.1 定义: 3.1.2 存储结构: 3.1.3 二叉排序树的查找 3.1.4 二叉排序树的插入 3.1.5 二叉排序树删除 3.2 平衡二叉树(AVL 3.2.1 为什么要有平衡二叉树 3.2.2 定义 3.3 B-树 3.3.1…...
IntelliJ IDEA Apache Dubbo,IDEA 官方插件正式发布!
作者:刘军 最受欢迎的 Java 集成开发环境 IntelliJ IDEA 与开源微服务框架 Apache Dubbo 社区强强合作,给广大微服务开发者带来了福音。与 IntelliJ IDEA 2023.2 版本一起,Jetbrains 官方发布了一款全新插件 - Apache Dubbo in Spring Frame…...
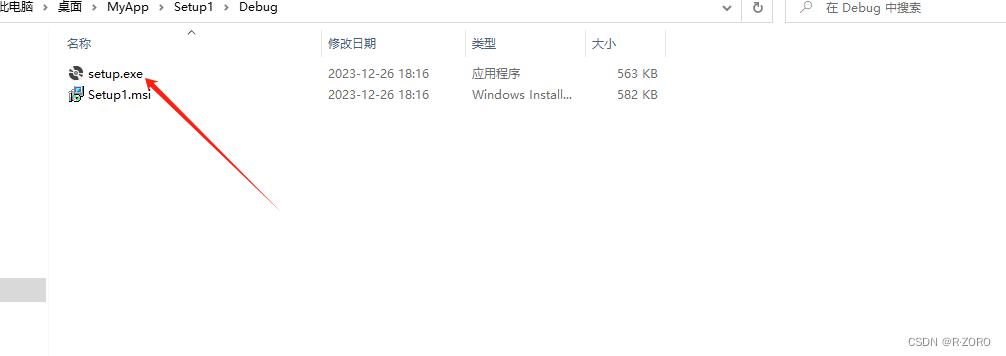
使用Visual Studio 2022 winform项目打包成安装程序.exe
winform项目打包 1.安装扩展插件 Microsoft Visual Studio Installer Projects 20222.在解决方案上新建一个setup project 项目3.新建成功如下图,之后添加你的winform程序生成之后的debug下的文件4.在Application Folder上点击右键->Add->项目输出->主输出…...
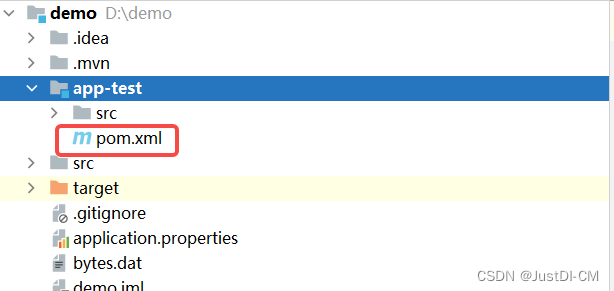
报错-idea pom.xml 有一条灰色横线
1. 背景 打开 idea 更新代码,发现有个 module 的 pom.xml 有一条灰色横线,导致这个 module 没有加载成功。 2. 原因 1) 可能本地 Remove 了这个 module 2)本地删除了这个 module ,又从远端拉取了回来 3)…...
openmediavault(OMV) (19)云相册(3)mt-photos
简介 MT Photos是一款为Nas用户量身打造的照片管理系统。通过AI技术,自动将您的照片整理、分类,包括但不限于时间、地点、人物、照片类型。可以在任何支持Docker的系统中运行它。详情可查看mtmt.tech官网,mt-photos是付费订阅使用的,也可以一次性付费永久使用,具体使用mt…...
基于openGauss5.0.0全密态数据库等值查询小案例
基于openGauss5.0.0全密态数据库等值查询小案例 一、全密态数据库简介二、环境说明三、测试步骤四、使用约束 一、全密态数据库简介 价值体现: 密态数据库意在解决数据全生命周期的隐私保护问题,使得系统无论在何种业务场景和环境下,数据在传…...

Oracle中varchar2和nvarchar2的区别
Oracle中的varchar2和nvarchar2都是可变长度的字符数据类型,这意味着它们能够根据实际存储的数据长度来动态调整占用的空间。但它们之间有以下主要区别: 1. 字符编码和存储: - VARCHAR2:存储的是字节字符串,对字符…...

linux环境下从一个服务器复制文件到另一个服务器
在Linux中使用scp命令可以将文件或目录从一台服务器复制到另外一台服务器。 # 从源服务器复制文件到目标服务器 scp /path/to/source_file usernamedestination:/path/to/destination_directory # 从源服务器复制目录及其内容到目标服务器 scp -r /path/to/source_directory us…...

JSoup 爬虫遇到的 404 错误解决方案
在网络爬虫开发中,使用JSoup进行数据抓取是一种常见的方式。然而,当我们尝试使用JSoup来爬虫抓取腾讯新闻网站时,可能会遇到404错误。这种情况可能是由于网站的反面爬虫机制检测到了我们的爬虫行为,从而拒绝了我们的请求。 假设我…...

Vue.set 方法原理
function set(target, key, value) {// 判断是否是数组,并且 key 是一个有效的索引值if (Array.isArray(target) && isValidArrayIndex(key)) {target.length Math.max(target.length, key)target.splice(key, 1, value)return value}// 判断 key 是否已经…...

CentOS 7的新特性
CentOS 7在发布时相较于CentOS 6引入了许多重要的变化和优化。以下是一些主要的改进和新特性: 系统初始化程序:CentOS 7使用了systemd作为其初始化系统,取代了之前版本的init系统。systemd提供了更快的启动时间和更好的管理服务。 内核更新&…...

Vue 模板编译原理
Vue 模板编译原理是指将 Vue 的模板转换为渲染函数的过程。在 Vue 中,模板被定义为 HTML 代码片段或者在 .vue 单文件组件中定义。当 Vue 实例化时,会将模板编译为渲染函数,该函数可以根据组件的状态生成虚拟 DOM 并更新视图。 Vue 的模板编…...
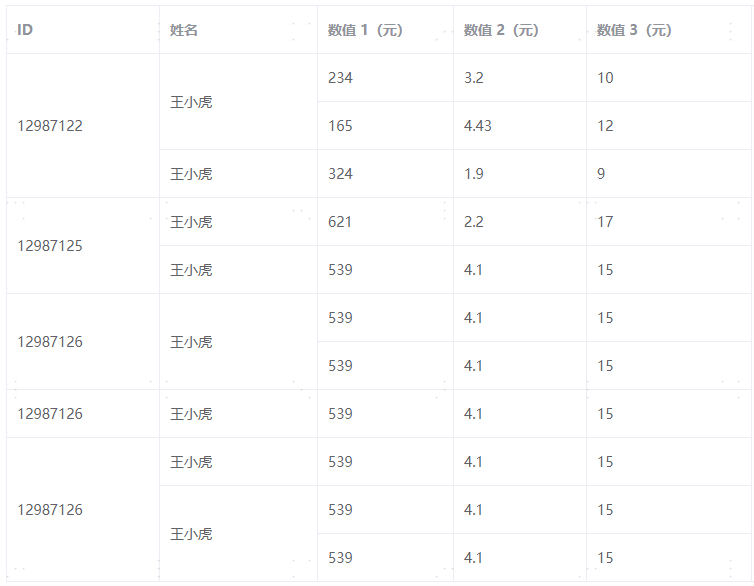
ElementUI的Table组件行合并上手指南
ElementUI的Table组件行合并 ,示例用官网vue3版的文档 <el-table :data"tableData" :span-method"objectSpanMethod" border style"width: 100%; margin-top: 20px"><el-table-column prop"id" label"ID&qu…...

【ES6】Class继承-super关键字
目录 一、前言二、ES6与ES5继承机制区别三、super作为函数1、构造函数this1)、首先要明确this指向①、普通函数②、箭头函数③、注意事项 2)、其次要明确new操作符做了哪些事情 2、super()的用法及注意点1)、用法2)、注意点 四、s…...

做亚马逊测评不知道怎么找客户?这才是亚马逊测评的正确打开方式!
如今的跨境电商内卷严重,花费大量资金做广告推广的效果却微乎其微,这也是亚马逊测评迅速崛起的最根本原因。做亚马逊测评是近年来兴起的一种方式,许多卖家都需要大量的测评来提高自己的产品排名和信誉度。很多兄弟最近来问龙哥亚马逊测评怎么…...

传感器基础:传感器使用与编程使用(三)
目录 常用传感器讲解九--雨滴传感器具体讲解电路连接代码实现 常用传感器讲解十--光传感器根据亮度安排灯具体讲解电路连接代码实现 常用传感器讲解七--light cup(KY-008)具体讲解电路连接代码实现 常用传感器讲解十二--倾斜开关传感器(KY-02…...

Google Cloud Dataflow 背后的流式处理模型
原文:towardsdatascience.com/the-stream-processing-model-behind-google-cloud-dataflow-0d927c9506a0?sourcecollection_archive---------3-----------------------#2024-04-27 在无界数据处理中的正确性、延迟和成本平衡 https://medium.com/vutrinh274?sour…...

2026年终极指南:JetBrains IDE试用期重置完整解决方案
2026年终极指南:JetBrains IDE试用期重置完整解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置是每个开发者都可能遇到的挑战,当IntelliJ IDEA、PyCharm、W…...

Agent+用药提醒:真正难的不是提醒,而是结合病情和依从性管理
用药提醒如果只做成定时推送,本质上接近一个带药品名称的闹钟。医疗健康应用里更棘手的问题是:用户是否按计划执行、漏服后如何记录、连续异常时是否需要升级提醒,以及这些规则如何被机构确认并可审计。本文只讨论技术架构和工程流程示例&…...

Skill 不是 Prompt 模板,而是 Code Agent 的领域知识接口
很多人第一次把 Code Agent 接进老项目,都会经历一个落差: Demo 里它能十分钟写完一个 CRUD;一进真实业务系统,它开始犯一些“刚入职新人”才会犯的错。 它能看懂 Controller,却不知道这个字段为什么不能改ÿ…...

指纹浏览器缓存机制原理与环境数据安全管控策略
引言绝大多数使用者在日常运用指纹浏览器搭建独立虚拟浏览环境时,重点注意力都集中在硬件指纹修改、代理网络绑定、基础参数调试等显性操作之上,往往忽略了软件内部缓存运行机制带来的各类隐性影响。虚拟环境运行过程中自动生成的页面缓存、站点数据、本…...

Head Activator ;pPPGGSKVILF
一、基础信息多肽名称:头部激活因子三字母序列:Pyr-Pro-Pro-Gly-Gly-Ser-Lys-Val-Ile-Leu-Phe单字母序列:pPPGGSKVILF氨基酸数量:11 aa分子式:C54H84N12O14分子量:1125.34结构特征:N 端 Pyr&…...

Beyond Compare 5密钥生成器终极指南:3种简单方法获取永久授权
Beyond Compare 5密钥生成器终极指南:3种简单方法获取永久授权 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期到期而烦恼吗?想要免费…...

拒绝封闭技术栈绑架:MyEMS 开源能源管理平台的架构中立性与兼容性设计
在企业数字化转型的深水区,能源管理系统正从单一的计量工具演变为支撑生产运营的核心基础设施。然而,当我们审视这一领域的技术现状时,不难发现一个令人警惕的现象:大量商业能源管理软件正通过封闭的技术栈、私有的通信协议和紧耦…...

国产ARM主板实战:从设计选型到性能优化的嵌入式开发指南
1. 项目概述:从“能用”到“好用”的国产ARM主板之路最近几年,如果你关注过硬件开发、嵌入式系统或者国产化替代的圈子,一定会频繁听到“国产ARM主板”这个词。它不再是实验室里的样品,而是越来越多地出现在工业控制、边缘计算、智…...

CBAM注意力机制:为什么它比SENet更胜一筹?深入对比通道与空间注意力设计
CBAM注意力机制:通道与空间双重视角下的性能突破 在计算机视觉领域,注意力机制已经成为提升卷积神经网络性能的关键技术之一。当我们面对ImageNet分类、目标检测等复杂任务时,网络需要学会"看重点"——自动识别图像中最相关的区域和…...