2023年12月27日学习记录_加入噪声
目录
- 1、今日计划学习内容
- 2、今日学习内容
- 1、add noise to audio clips
- signal to noise ratio(SNR)
- 加入 additive white gaussian noise(AWGN)
- 加入 real world noises
- 2、使用kaggel上的一个小demo:CNN模型
- 运行时出现的问题
- 调整采样率时出现bug
- 3、明确90dB下能否声纹识别
- 4、流量预测
- 3、实际完成的任务
1、今日计划学习内容
- 明确90dB下能否进行声纹识别
- 流量预测模型对比学习
- 学习时不玩手机 🤡
开始今日学习😄

2、今日学习内容
1、add noise to audio clips
学习如何将噪声加入到audio data中,后续可以将不同SNR的噪声加入原始信号样本,评估不同噪声条件下的模型性能
首先读取原始audio.wav(里面是一段话:“leave my dog alone”)
import librosa
signal, sr = librosa.load(“path/to/audio.wav”)
绘制信号图:
import matplotlib.pyplot as plt
plt.plot(signal)

signal to noise ratio(SNR)

RMS是均方根
计算信号的RMS:
import numpy as np
RMS=math.sqrt(np.mean(signal**2))
dB = 20 × log 10 ( RMS ) \text{dB} = 20 \times \log_{10}(\text{RMS}) dB=20×log10(RMS)
加入 additive white gaussian noise(AWGN)
- how to generate AWGN
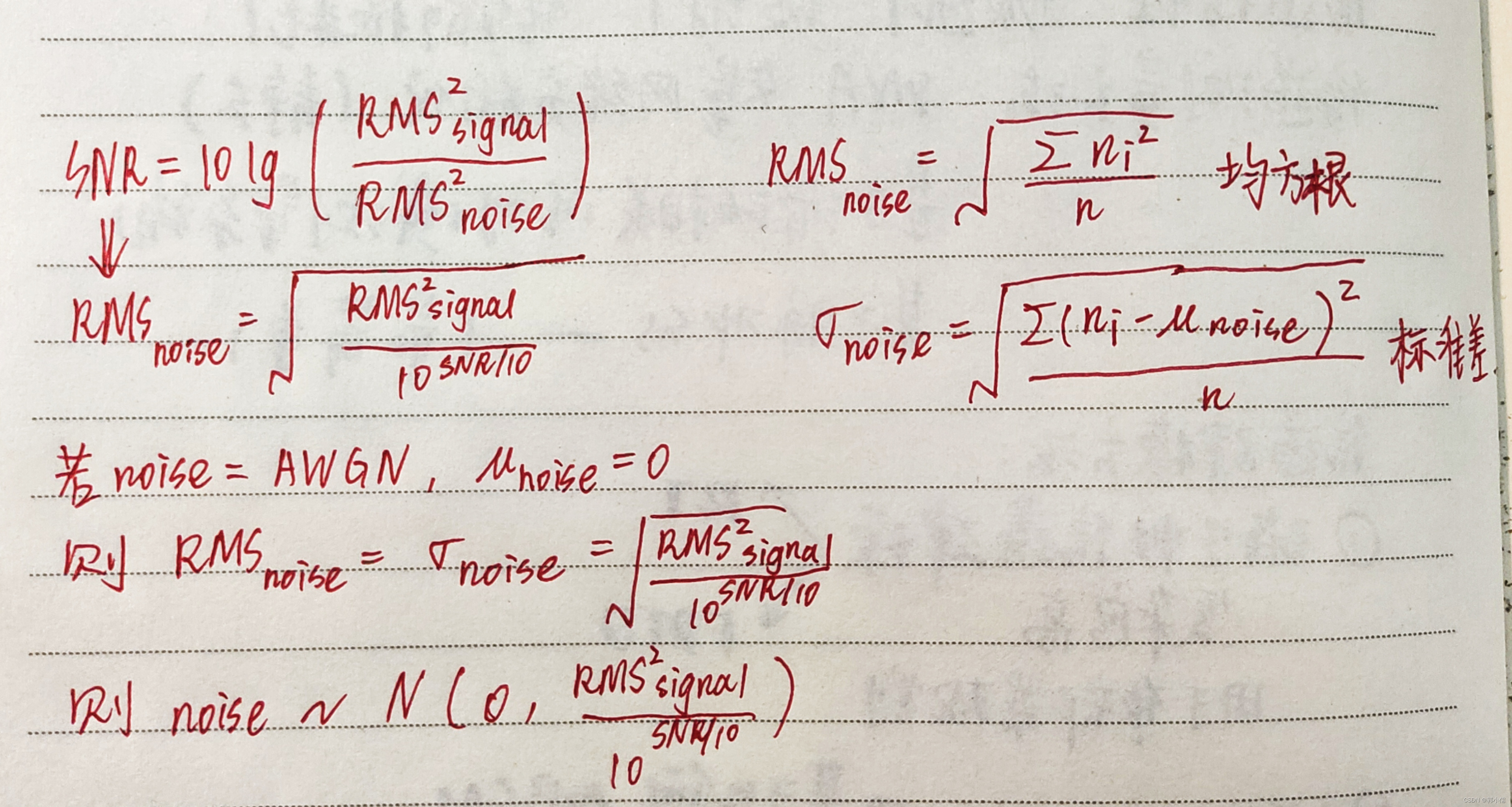
噪声是服从高斯分布,均值为0,标准差是 R M S n o i s e RMS_{noise} RMSnoise
noise=np.random.normal(0, STD_n, signal.shape[0])
# np.random.normal() 函数用于生成服从正态分布的随机数
# 生成一个形状与输入信号(signal)相同的数组,其中每个元素都服从均值为 0、方差为 STD_n 的正态分布。
生成的噪声图:

2. AWGN的频率分析
使用快速傅里叶变化来分析噪声的频率部分
X=np.fft.rfft(noise)
radius,angle=to_polar(X)

频率分布非常平稳,符合“白”的特征
3. 加入噪声
signal_noise = signal+noise
SNR=10dB

加入噪声的完整代码
#SNR in dB
#given a signal and desired SNR, this gives the required AWGN what should be added to the signal to get the desired SNR
def get_white_noise(signal,SNR) :#RMS value of signalRMS_s=math.sqrt(np.mean(signal**2))#RMS values of noiseRMS_n=math.sqrt(RMS_s**2/(pow(10,SNR/10)))#Additive white gausian noise. Thereore mean=0#Because sample length is large (typically > 40000)#we can use the population formula for standard daviation.#because mean=0 STD=RMSSTD_n=RMS_nnoise=np.random.normal(0, STD_n, signal.shape[0])return noise
#***convert complex np array to polar arrays (2 apprays; abs and angle)
def to_polar(complex_ar):return np.abs(complex_ar),np.angle(complex_ar)#**********************************
#*************add AWGN noise******
#**********************************
signal_file='/home/sleek_eagle/research/emotion/code/audio_processing/signal.wav'
signal, sr = librosa.load(signal_file)
signal=np.interp(signal, (signal.min(), signal.max()), (-1, 1))
noise=get_white_noise(signal,SNR=10)
#analyze the frequency components in the signal
X=np.fft.rfft(noise)
radius,angle=to_polar(X)
plt.plot(radius)
plt.xlabel("FFT coefficient")
plt.ylabel("Magnitude")
plt.show()
signal_noise=signal+noise
plt.plot(signal_noise)
plt.xlabel("Sample number")
plt.ylabel("Amplitude")
plt.show()
加入 real world noises
将有噪声的音频加入到原始音频中
我们需要计算原始音频的RMS和噪声音频的RMS,为了能得到规定的SNR,我们需要修改噪声的RMS值,办法就是将每个噪声元素都乘上一个常数,这样就能使得噪声的RMS值也乘上一个常数,达到需要的噪声RMS。

噪声音频(水流的声音):
加入噪声的音频:
To listen to the signal and noise I used and also to the noise-added audio files that were created by adding noise to the signal, go to
#given a signal, noise (audio) and desired SNR, this gives the noise (scaled version of noise input) that gives the desired SNR
def get_noise_from_sound(signal,noise,SNR):RMS_s=math.sqrt(np.mean(signal**2))#required RMS of noiseRMS_n=math.sqrt(RMS_s**2/(pow(10,SNR/10)))#current RMS of noiseRMS_n_current=math.sqrt(np.mean(noise**2))noise=noise*(RMS_n/RMS_n_current)return noise
#**********************************
#*************add real world noise******
#**********************************signal, sr = librosa.load(signal_file)
signal=np.interp(signal, (signal.min(), signal.max()), (-1, 1))
plt.plot(signal)
plt.xlabel("Sample number")
plt.ylabel("Signal amplitude")
plt.show()noise_file='/home/sleek_eagle/research/emotion/code/audio_processing/noise.wav'
noise, sr = librosa.load(noise_file)
noise=np.interp(noise, (noise.min(), noise.max()), (-1, 1))#crop noise if its longer than signal
#for this code len(noise) shold be greater than len(signal)
#it will not work otherwise!
if(len(noise)>len(signal)):noise=noise[0:len(signal)]noise=get_noise_from_sound(signal,noise,SNR=10)signal_noise=signal+noiseprint("SNR = " + str(20*np.log10(math.sqrt(np.mean(signal**2))/math.sqrt(np.mean(noise**2)))))plt.plot(signal_noise)
plt.xlabel("Sample number")
plt.ylabel("Amplitude")
plt.show()参考链接:
click here
2、使用kaggel上的一个小demo:CNN模型
link here
运行时出现的问题
调整采样率时出现bug
- 代码:
import subprocesscommand = ("for dir in `ls -1 " + noise_path + "`; do ""for file in `ls -1 " + noise_path + "/$dir/*.wav`; do ""sample_rate=`ffprobe -hide_banner -loglevel panic -show_streams ""$file | grep sample_rate | cut -f2 -d=`; ""if [ $sample_rate -ne 16000 ]; then ""ffmpeg -hide_banner -loglevel panic -y ""-i $file -ar 16000 temp.wav; ""mv temp.wav $file; ""fi; done; done")subprocess.run(command, shell=True)
-
bug:
2023-12-26 10:44:38.782251: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
作为一个纯小白,问题非常非常的多
- subprocess.run是在干嘛?通过 Python 来调用 Shell 脚本
- shell脚本是什么?Shell脚本是一种用于编写、执行和自动化操作系统命令和任务的脚本语言。它是一种解释性语言,常用于Unix、Linux和类Unix系统中。
- subprocess.run()函数:
- 函数介绍:
subprocess.run(args, *, stdin=None, input=None, stdout=None,
stderr=None, capture_output=False, shell=False, cwd=None,
timeout=None, check=False, encoding=None, errors=None, text=None,
env=None, universal_newlines=None)
别怕,这个run()函数很长、很长,但并不是所有都需要的,我们必要设置的只有第一项args,也就是shell命令
-args:args参数传入一个列表或者元组,如[‘ls’,‘-l’],python会自动拼接成shell命令.[第一个参数是执行的程序,其余的是参数];也可以直接就是一个str命令行,如果如果传入的是shell命令,则需要另外添加一个参数shell=True
- 函数返回:class subprocess.CompletedProcess

实在是不知道怎么改这种代码了,我的选择是:换方法,直接使用别的方法实现重采样
3、明确90dB下能否声纹识别
论文:添加链接描述

-5dB就相当低了,感觉不大可能
4、流量预测
-
代码链接:LTE Cell Traffic Grow and Congestion Forecasting
没有给数据集 -
后续学习链接:How to Use the TimeDistributed Layer in Keras
-
后续学习方向:后续要保证每天一篇相关论文,先从有复现的论文读起,同时要对流量预测的模型进行学习,建模的时候学习pytorch库和keras库
3、实际完成的任务
- 声纹识别增加噪声的学习

明天继续加油吧!
有没有研究生学习搭子或者大佬呀呜呜呜呜

相关文章:
2023年12月27日学习记录_加入噪声
目录 1、今日计划学习内容2、今日学习内容1、add noise to audio clipssignal to noise ratio(SNR)加入 additive white gaussian noise(AWGN)加入 real world noises 2、使用kaggel上的一个小demo:CNN模型运行时出现的问题调整采样率时出现bug 3、明确90dB下能否声…...

Java面试题86-95
86. Java代码查错(4)public class Something { public int addOne(final int x) { return x; }}此代码有错误吗?答案: 错。int x被修饰成final,意味着x不能在addOne method中被修改。87. Java代码查错(5&…...

看完谁再说搞不定上下角标?
一、需求 开发中有一些需要用到上下角标的地方,比如说化学式、数学式、注释。。。除了可以使用上下角标的标签,还可以通过css样式和CV大法实现,以下是具体实现方式。 二、实现方法 (1)标签写法: <sup…...

在 Python 中使用装饰器decorator的 7 个层次
在 Python 中使用装饰器的 7 个层次(7 Levels of Using Decorators in Python) 文章目录 在 Python 中使用装饰器的 7 个层次(7 Levels of Using Decorators in Python)导言Level 0: 了解基本概念Basic Concepts和用法Usages什么是装饰器decorator?我们为什么需要装…...

Vue.js项目部署至Linux服务器的详细步骤
引言 在现代Web开发中,Vue.js作为一款流行的前端框架,为开发者提供了灵活且高效的工具。然而,在将Vue.js项目成功部署到Linux服务器上,可能需要一些额外的步骤和注意事项。本文将深入介绍在Linux服务器上部署Vue.js项目的详细步骤…...

Java三层架构/耦合/IOC/DI
一.三层架构 controller/web 控制层。接收前端发送的请求,对请求进行处理,并响应数据。 service 业务逻辑层,处理具体的业务逻辑。 dao 数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、…...

[调试]stm32使用过程debug记录,持续更新ing
遇到的bug:无法在串口助手接收到stm32向主机输出的数据,串口-USB RX灯不闪烁; 分析:闪烁灯实际上为一个二极管,CH 插入电脑USB接口时,RX处于高电平,当数据传输时,拉低电平导致其闪烁…...

知识付费小程序如何搭建?
随着互联网的发展和人们对知识的渴求,知识付费行业正逐渐崭露头角。而其中,知识付费小程序因其便捷性、个性化等特点,成为了越来越多人的首选。那么,如何搭建一个知识付费小程序呢?本文将为你揭秘从零到一的全过程&…...
springboot整合minio做文件存储
一,minio介绍 MinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小&…...

拥抱鸿蒙 - 在展讯T606平台上的探索与实践
前 言 自OpenHarmony 问世后受到了社会各界的广泛关注,OpenHarmony 的生态系统在如火如荼的发展。 酷派作为一家积极拥抱变化的公司,经过一段时间的探索与实践,成功实现将OpenHarmony 系统接入到展讯平台上,我们相信这是一个重要…...
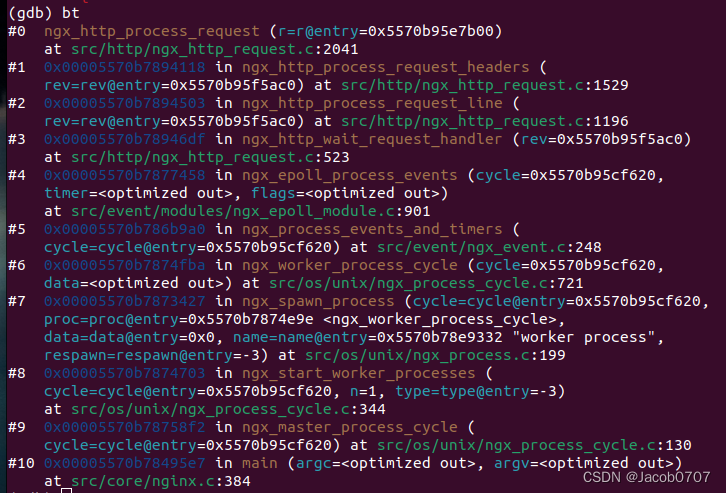
nginx源码分析-1
使用gdb查看函数上下文: gdb attach nginx的work线程 监听端口状态时: 断点打在ngx_http_process_request 并通过浏览器触发请求时:...
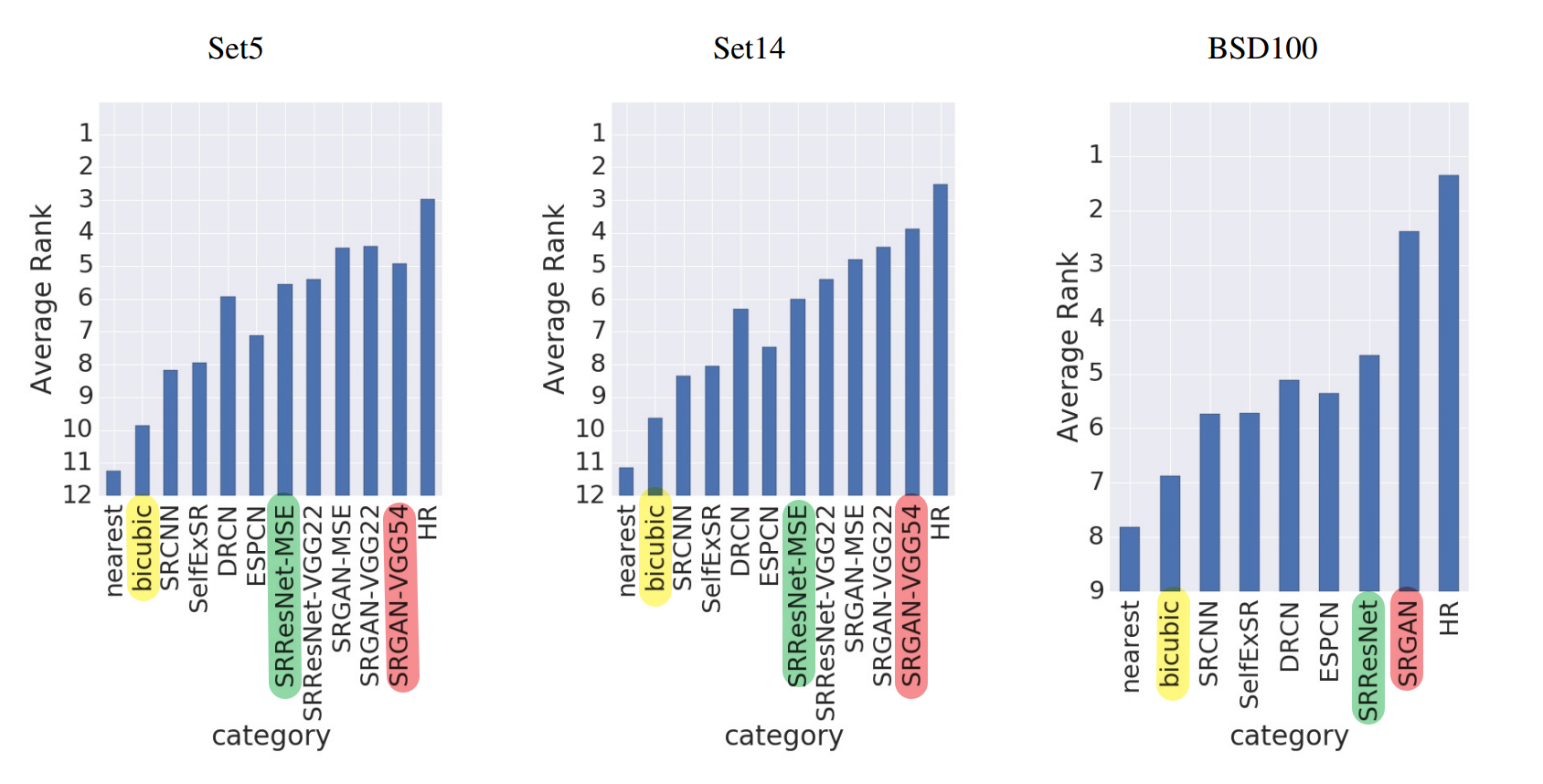
超分之SRGAN
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network使用生成对抗网络的逼真单图像超分辨率一作:Christian Ledig是Twitter2017年的一篇论文。 文章目录 0. 摘要1. 引言1.1 相关工作1.1.1 介绍了SR技术的发展历程1.1.2 介绍了SR…...
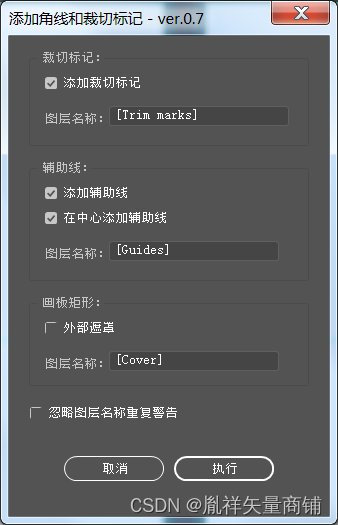
Illustrator脚本 #015 自动角线
这是一个在画板上自动生成辅助线和角线的脚本,只要单击最右边按钮运行脚本即可。 绿色的为参考线及出血线。 #target "Illustrator" var settings = {addTrim : true,addBleedGuide : true,addCenterGuide : true,addCover : false,overlapAlert : false,trimma…...
)
使用Vite创建React + TypeScript(pro和mobile,含完整的空项目结构资源可供下载)
PC端 安装指令: npm create vitelatest react-ts-pro -- --template react-tsVite是一个框架无关的前端工具链,可以快速的生成一个React TS的开发环境,并且可以提供快速的开发体验说明: 1. npm create vitelatest固定写法&#…...
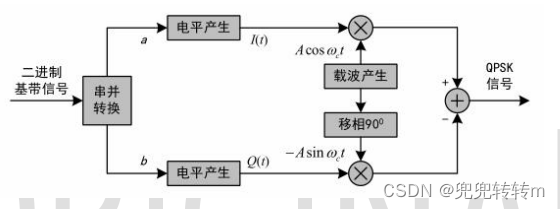
第一次记录QPSK,BSPK,MPSK,QAM—MATLAB实现
最近有偶然的机会学习了一次QPSK防止以后忘记又得找资料,这里就详细的记录一下 基于 QPSK 的通信系统如图 1 所示,QPSK 调制是目前最常用的一种卫星数字和数 字集群信号调制方式,它具有较高的频谱利用率、较强的抗干扰性、在电路上实现也较为…...
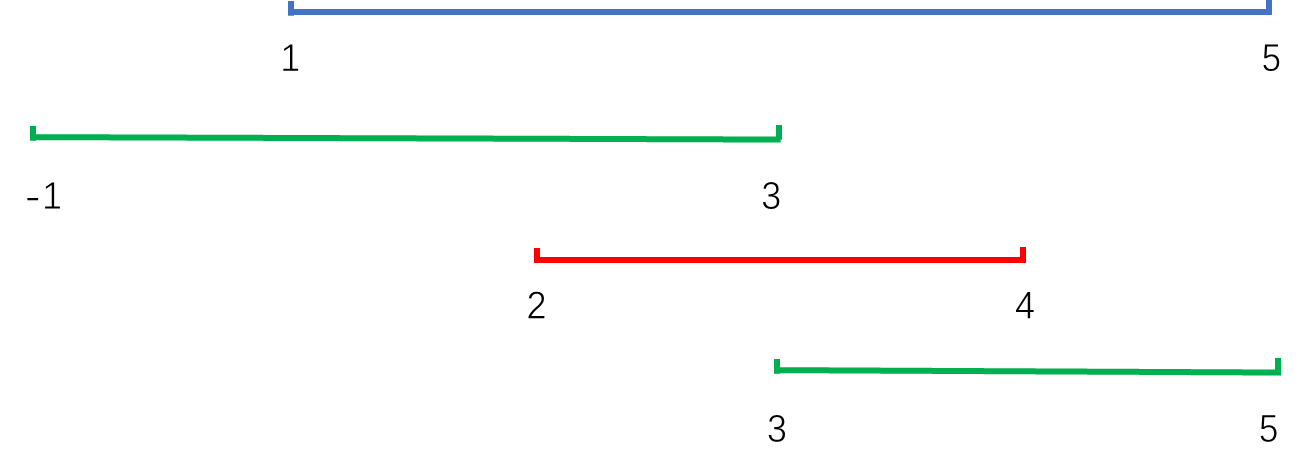
每周一算法:区间覆盖
问题描述 给定 N N N个闭区间 [ a i , b i ] [a_i,b_i] [ai,bi],以及一个线段区间 [ s , t ] [s,t] [s,t],请你选择尽量少的区间,将指定线段区间完全覆盖。 输出最少区间数,如果无法完全覆盖则输出 − 1 -1 −1。 输入格式…...

im6ull学习总结(二)Framebuffer 应用编程
1 LCD操作原理 linux中通过framebuffer驱动程序来控制LCD。framebuffer中包含LCD的参数,大小为LCD分辨率xbpp。framebuffer 是一块内存 内存中保存了一帧图像。 关于图像的帧指的是在图像处理中,一帧(Frame)是指图像序列中的单个…...

数据仓库 基本信息
数据仓库基本理论 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)…...

仓储革新:AR技术引领物流进入智慧时代
根据《2022年中国物流行业研究:深度探析行业现状(智能设备及智能软件)》,报告中提及:“中国社会物流总额依然保持着较为良好的增长态势,年增速已恢复至常年平均水平。2021年社会物流总额细分中工业物流总额…...

软件仓库部署及应用
随着某公司内部的Linux服务器不断增多,软件更新,系统升级等需求也逐渐凸显。为了提高软 件包管理效率,减少重复下载,公司要求部署一台软件仓库服务器,面向内网提供安装源。 需求描述 > 服务器使用CentOS7操作系统I…...

5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南
5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 你…...

在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用 对于构建AI功能的后端Node.js开发者而言,直接对接单一模型供…...

Spinach印相紧急修复方案:当--v 6.2输出突然丢失青橙分离感时,立即执行的4步CLI热补丁与config.json强制回滚指令
更多请点击: https://intelliparadigm.com 第一章:Spinach印相紧急修复方案:当--v 6.2输出突然丢失青橙分离感时,立即执行的4步CLI热补丁与config.json强制回滚指令 Spinach 6.2 版本在部分 GPU 加速路径下会因色彩空间映射缓存污…...

PetaLinux下为ZynqMP配置GMII2RGMII驱动:从设备树修改到内核编译的完整指南
PetaLinux下为ZynqMP配置GMII2RGMII驱动的实战指南 在嵌入式Linux开发中,以太网驱动的配置往往是系统集成的关键环节。对于使用Xilinx ZynqMP芯片的开发者来说,当硬件设计采用GMII2RGMII IP核实现PL端以太网功能时,如何在PetaLinux环境下正确…...

基于AI与胎心监护信号预测胎儿生物年龄:技术实现与临床价值
1. 项目概述:从胎心监护到胎儿“数字时钟” 在产科临床和围产期医学领域,评估胎儿宫内健康状况,尤其是其发育成熟度,一直是一项核心且充满挑战的任务。传统的评估方法,如通过超声测量胎儿双顶径、股骨长等生物参数来估…...

独立开发者如何利用 Taotoken 的模型广场为不同产品功能匹配合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的模型广场为不同产品功能匹配合适模型 对于独立开发者而言,运营多个小型产品是常态。这…...

小熊猫Dev-C++:5个理由让你爱上这款轻量级C++开发工具
小熊猫Dev-C:5个理由让你爱上这款轻量级C开发工具 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 在C编程的世界里,寻找一个既功能强大又简单易用的开发环境常常让初学者望而却步。…...

Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包?
Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包? 每次在Linux服务器上部署FTP客户端时,我都会面临一个选择:是直接apt install filezilla,还是去官网下载tar包手动安装?五年前我可能…...
 的剪辑软件合集来啦)
实测好用、真正免费(无水印/无强制付费) 的剪辑软件合集来啦
剪辑小白看过来!2026年实测好用、真正免费(无水印/无强制付费) 的剪辑软件合集来啦!????不管你是学生党、自媒体新人,还是电脑配置不高,这篇笔记帮你按设备(手机/电脑/网页) 精准…...

无人机雷达与LiDAR协同监测土壤湿度技术解析
1. 无人机雷达与LiDAR协同监测土壤湿度的技术原理在精准农业领域,土壤湿度监测一直面临着植被遮挡带来的技术挑战。传统的地面传感器网络虽然精度较高,但存在部署成本高、维护困难等问题;而光学遥感又难以穿透茂密的作物冠层。无人机载雷达与…...