redis基础知识
学一点,整一点,基本都是综合别人的,弄成我能理解的内容
https://blog.csdn.net/liqingtx/article/details/60330555
https://blog.csdn.net/u014723137/article/details/125658176
https://redis.io/commands/ 官方命令
📌导航小助手📌
- 数据结构
- String(字符串)
- Hash(哈希)
- List(列表)
- Set(集合)
- zset (有序集合)
- Redis 的三种特殊数据类型
- redis持久化
- 主从同步
- 事务
- 缓存穿透、雪崩、击穿
- redis为什么快
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
数据结构
Redis有以下这五种基本类型:
String(字符串)、Hash(哈希)、List(列表)、Set(集合)、zset(有序集合)
它还有三种特殊的数据结构类型
Geospatial、Hyperloglog、Bitmap
String(字符串)
- 简介:String是Redis最基础的数据结构类型,它是二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M
- 简单使用举例: set key value、get key等
- 应用场景:共享session、分布式锁,计数器、限流。
- 内部编码有3种,int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
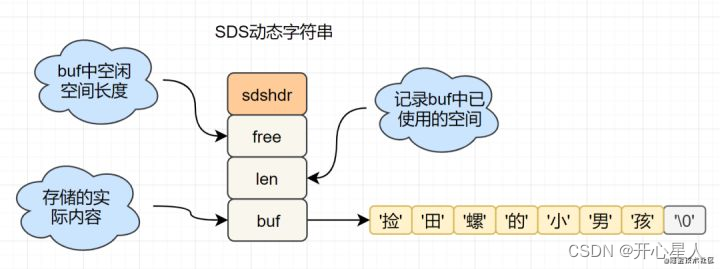
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{ unsigned int len; // 标记buf的长度 unsigned int free; //标记buf中未使用的元素个数 char buf[]; // 存放元素的坑 }
SDS 结构图如下:
可以通过字符串类型进行数值操作:
127.0.0.1:6379> set mynum "2"
OK
127.0.0.1:6379> get mynum
"2"
127.0.0.1:6379> incr mynum
(integer) 3
127.0.0.1:6379> get mynum
"3"
在遇到数值操作时,redis会将字符串类型转换成数值。
由于INCR等指令本身就具有原子操作的特性,所以我们完全可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果,假如,在某种场景下有3个客户端同时读取了mynum的值(值为2),然后对其同时进行了加1的操作,那么,最后mynum的值一定是5。不少网站都利用redis的这个特性来实现业务上的统计计数需求。
Hash(哈希)
- 简介:在Redis中,哈希类型是指v(值)本身又是一个键值对(k-v)结构
- 简单使用举例:hset key field value 、hget key field
- 内部编码:ziplist(压缩列表) 、hashtable(哈希表) (当field-value长度较短且个数较少时使用ziplist,否则使用hashtable)
- 应用场景:缓存用户信息等。
- 注意点:如果开发使用hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan。而如果只是获取部分field,建议使用hmget。
<key>都是具体的某个表
hset <key> <field> <value> 给<key>集合中的 <field>键赋值<value>
hget <key1> <field> 从key1中取出指定的field对应的value
hmset <key1> <filed1> <value1> <filed3> <value2> .. 批量插入key1的filed-value对
hexists <key1> <field> 查看哈希表key1中,给定的field是否存在
hkeys <key> 列出该key的所有field
hvals <key> 列出该hash集合的所有value
hincrbu <key> <field> <incerment> 为哈希表key中的域field的值加上<incerment>
hsetnx <key><field> <value> 给哈希表key添加field-value对,当且仅当域field不存在

注意,这里的<user:001>整体是一个key,":"不是一定要存在的
List(列表)
https://blog.csdn.net/m0_60867520/article/details/132327698
- 简介:列表(list)类型是用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。
- 简单实用举例:lpush key value [value …] 、lrange key start end
- 内部编码:ziplist(压缩列表)、linkedlist(链表)
- 应用场景:消息队列,文章列表,
redis中的lists在底层实现上并不是数组,而是链表
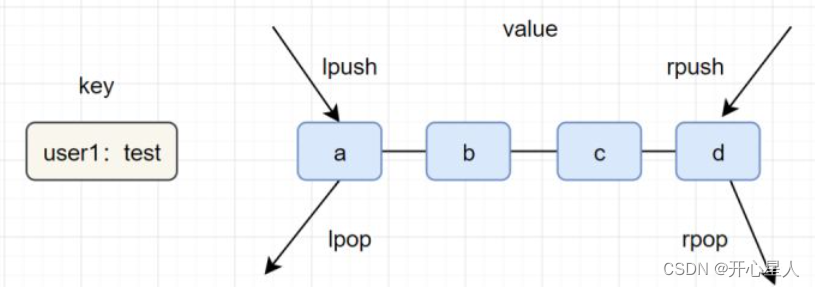
ist应用场景
lpush+lpop=Stack(栈)
lpush+rpop=Queue(队列)
lpsh+ltrim=Capped Collection(有限集合)
lpush+brpop=Message Queue(消息队列)
lpushx 当key不存在,用法和lpush一致,当key存在,则插入失败,返回0
lindex 获取到指定位置的元素,时间复杂度为O(N),如果下标非法则返回nil
linsert 在list的指定处插入元素,如果是before就插入在基准值前面,如果是after就插入到基准值后面,基准值是在list中存在的值而非下标,时间复杂度是O(N)。如果存在多个相同的基准值,那么只插入到第一个基准值处
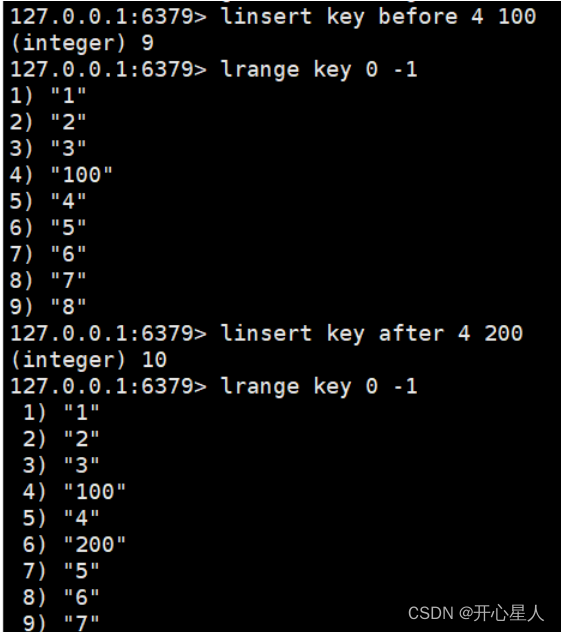
llen 获取列表的长度,如果key不存在则返回0
lrem key count value 删除指定的值,count为要删除的个数
ltrim key start end 保留列表中start和stop之间的元素,删除两边的元素
lset key index value 根据指定的下标,修改元素,如果下标越界,则报错
blpop/brpop 类似于阻塞队列,如果队列为空,尝试出队列,阻塞队列根据阻塞时间产生阻塞,期间Redis可以执行其他命令,直到队列不空,返回元素(如果超时了就返回nil)
Set(集合)
- 简介:集合(set)类型也是用来保存多个的字符串元素,但是不允许重复元素
- 简单使用举例:sadd key element [element …]、smembers key
- 内部编码:intset(整数集合)、hashtable(哈希表)
- 注意点:smembers和lrange、hgetall都属于比较重的命令,如果元素过多存在阻塞Redis的可能性,可以使用sscan来完成。
- 应用场景:用户标签,生成随机数抽奖、社交需求。
SADD key member1 [member2] 向集合中添加一个或者多个元素,并且自动去重。
SCARD key 返回集合中元素的个数。
SDIFF key1 [key2] 求两个或多个集合的差集。
SDIFFSTORE destination key1 [key2] 求两个集合或多个集合的差集,并将结果保存到指定的集合中。
SINTER key1 [key2] 求两个或多个集合的交集。
SINTERSTORE destination key1 [key2] 求两个或多个集合的交集,并将结果保存到指定的集合中。
SISMEMBER key member s is member查看指定元素是否存在于集合中,存在为1、不存在为0。
SMEMBERS key 查看集合中所有元素。
SMOVE source destination member 将集合中的元素移动到指定的集合中。
SPOP key [count] 弹出指定数量的元素。
SRANDMEMBER key [count] 随机从集合中返回指定数量的元素,默认返回 1个。
SREM key member1 [member2] 删除一个或者多个元素,若元素不存在则自动忽略。
SUNION key1 [key2] 求两个或者多个集合的并集。
SUNIONSTORE destination key1 [key2] 求两个或者多个集合的并集,并将结果保存到指定的集合中。
SSCAN key cursor [match pattern] [count count] 该命令用来迭代的集合中的元素。
zset (有序集合)
- 简介:已排序的字符串集合,同时元素不能重复
- 简单格式举例:zadd key score member [score member …],zrank key member
- 底层内部编码:ziplist(压缩列表)、skiplist(跳跃表)
- 应用场景:排行榜,社交需求(如用户点赞)。
zadd <key> <score1> <value1> <score2> <value2>... 将一个或多个member元素及其score值加入到有序集key当中。
zrange <key> <start> <stop>[WITHSCORES] 返回有序集key中,下标在<start><stop>之间的元素
zrangebyscore key min max [withscores] [limit offset count] 返回有序集 key 中,所有score值介于min和max 之间(包括等于min或max )的成员
zincrby <key> <increment><value> 为元素的score加上增量
zrem <key> <value> 删除该集合下,指定值的元素v
zcount <key> <min> <max> 统计该集合,分数区间内的元素个数。
zrank <key> <value> 返回该值在集合中的排名,从0开始。
Redis 的三种特殊数据类型
Geo:Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
HyperLogLog:用来做基数统计算法的数据结构,如统计网站的UV。
Bitmaps :用一个比特位来映射某个元素的状态,在Redis中,它的底层是基于字符串类型实现的,可以把bitmaps成作一个以比特位为单位的数组
redis持久化
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
RDB,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库,就像memcache一样。
RDB
redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
AOF
AOF,英文是Append Only File,即只允许追加不允许改写的文件。
通过配置redis.conf中的appendonly yes就可以打开AOF功能
默认的AOF持久化策略是每秒钟fsync一次(fsync是指把缓存中的写指令记录到磁盘中),因为在这种情况下,redis仍然可以保持很好的处理性能,即使redis故障,也只会丢失最近1秒钟的数据。
因为采用了追加方式,如果不做任何处理的话,AOF文件会变得越来越大,为此,redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超过所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。举个例子或许更形象,假如我们调用了100次INCR指令,在AOF文件中就要存储100条指令,但这明显是很低效的,完全可以把这100条指令合并成一条SET指令,这就是重写机制的原理。
在同样数据规模的情况下,AOF文件要比RDB文件的体积大。而且,AOF方式的恢复速度也要慢于RDB方式。
AOF重写:
在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
主从同步
https://blog.csdn.net/Mr_VK/article/details/132353177
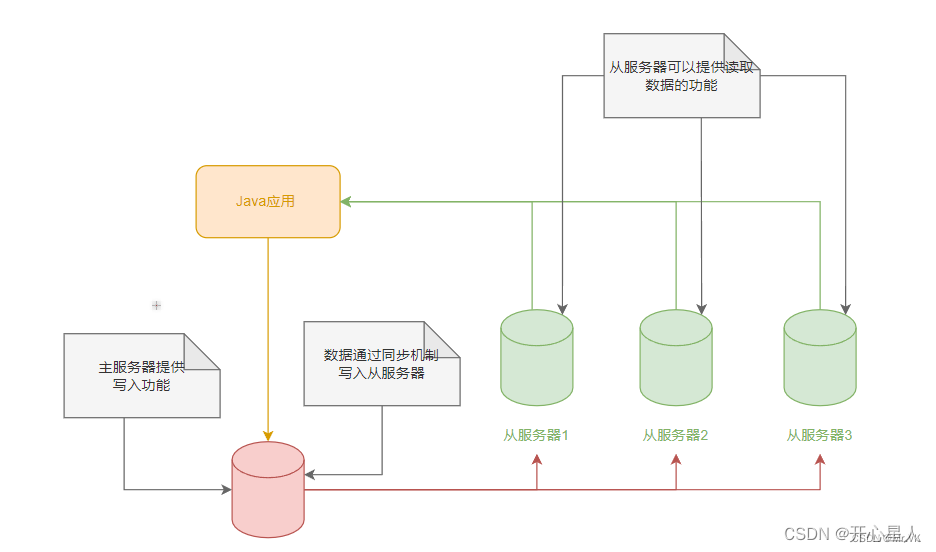
像MySQL一样,redis是支持主从同步的,而且也支持一主多从以及多级从结构。
主从结构,一是为了纯粹的冗余备份,二是为了提升读性能,比如很消耗性能的SORT就可以由从服务器来承担。
redis的主从同步是异步进行的,这意味着主从同步不会影响主逻辑,也不会降低redis的处理性能。
主从架构中,可以考虑关闭主服务器的数据持久化功能,只让从服务器进行持久化,这样可以提高主服务器的处理性能。
在主从架构中,从服务器通常被设置为只读模式,这样可以避免从服务器的数据被误修改。但是从服务器仍然可以接受CONFIG等指令,所以还是不应该将从服务器直接暴露到不安全的网络环境中。如果必须如此,那可以考虑给重要指令进行重命名,来避免命令被外人误执行。
很多企业都没有使用 Redis 的集群,但是至少都做了主从。有了主从,当主节点(Master) 挂掉的时候,运维让从节点 (Slave) 过来接管,服务就可以继续,否则主节点需要经过数据恢复和重启的过程,这就可能会拖延很长的时间,从而影响线上业务的持续服务。
互联网系统一般以主从架构为基础,所谓主从架构设计的思路大概如下。
- 在多台数据服务器中,只有一台主服务器,而主服务器只负责写入数据,不负责让外部程序读取数据。
- 存在多台从服务器,从服务器不写入数据,只负责同步主服务器的数据,并让外部程序读取数据。
- 主服务器在写入数据后,即刻将写入数据的命令发送给从服务器,从而使得主从数据同步。
- 应用程序可以随机读取某一台从服务器的数据,这样就分摊了读数据的压力。
- 当从服务器不能工作的时候,整个系统将不受影响;当主服务器不能工作的时候,可以方便地从从服务器中选取一台来当主服务器。
cap理论
C:Consistent,一致性
A:Availability,可用性
P:Partition tolerance ,分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫作网络分区。
在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点进行的修改操作将无法同步到另外一个节点,所以数据的一致性将无法满足,因为两个分布式节点的数据不再保持一致。除非我们牺牲可用性,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复正常再继续对外提供服务。
用一句话概括 CAP 原理就是: 当网络分区发生时,一致性和可用性两难全
最终一致
Redis的主从数据是异步同步的,所以分布式的 Redis系统并不满足一致性要求当客户端在 Redis的主节点修改了数据后,立即返回,即使在主从网络断开的情况下主节点依旧可以正常对外提供修改服务,所以 Redis 满足可用性。
Redis 保证最终一致性,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,但一旦网络恢复,从节点会采用多种策略努力追赶,继续尽力保持和主节点一致。
主从同步过程
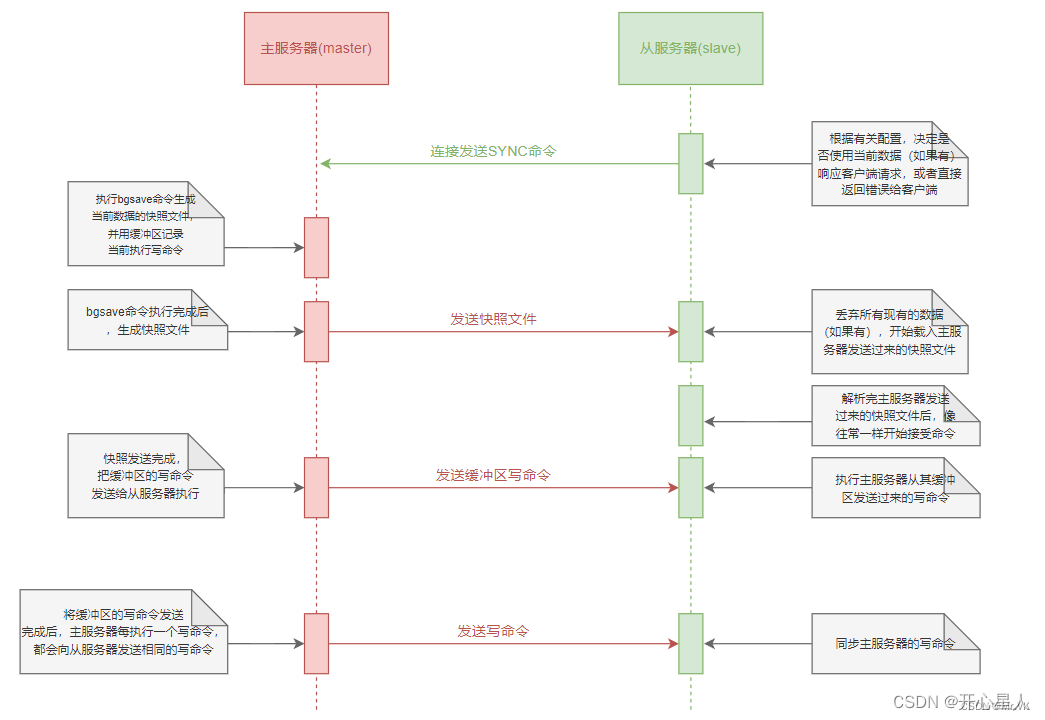
事务
MULTI、EXEC、DISCARD、WATCH
1.MULTI用来组装一个事务;
2.EXEC用来执行一个事务;
3.DISCARD用来取消一个事务;
4.WATCH WATCH key [key …] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。则取消事务的执行。
watch乐观锁:添加watch关键字,监测redis相应的值,如key1,开启事务(MULTI),然后对key1执行相应的操作指令,操作命令首先存入事务的队列,此时在另一个线程同时操作key1,然后我们这边执行(EXEC)这个对key1操作的事务就会失败,保证了数据的完整性,类似于数据库事务的回滚操作;如果没有watch乐观锁,即使有另一个线程同时操作了key1,正常的事务执行是直接可以执行成功的,就会出现脏数据等情况;
redis> MULTI //标记事务开始
OK
redis> INCR user_id //多条命令按顺序入队
QUEUED
redis> INCR user_id
QUEUED
redis> INCR user_id
QUEUED
redis> PING
QUEUED
redis> EXEC //执行
1) (integer) 1
2) (integer) 2
3) (integer) 3
4) PONG
如果redis开启了AOF持久化的话,那么一旦事务被成功执行,事务中的命令就会通过write命令一次性写到磁盘中去,如果在向磁盘中写的过程中恰好出现断电、硬件故障等问题,那么就可能出现只有部分命令进行了AOF持久化,这时AOF文件就会出现不完整的情况,这时,我们可以使用redis-check-aof工具来修复这一问题,这个工具会将AOF文件中不完整的信息移除,确保AOF文件完整可用。
缓存穿透、雪崩、击穿
① 缓存穿透:大量请求根本不存在的key(下文详解)
② 缓存雪崩:redis中大量key集体过期(下文详解)
③ 缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)

redis为什么快
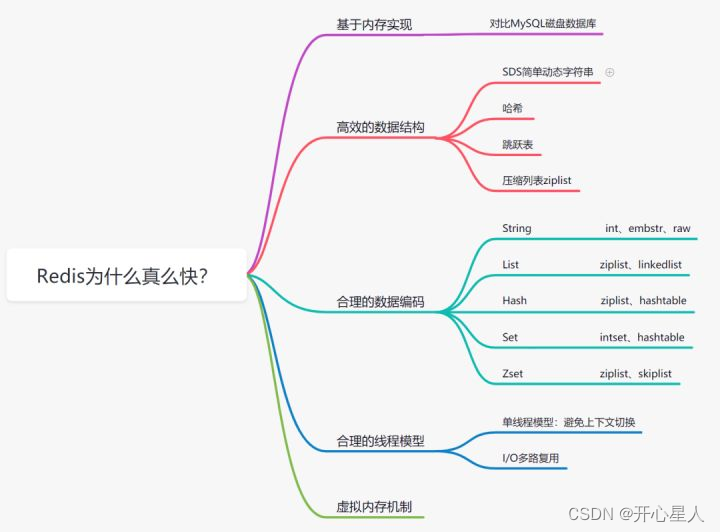
相关文章:
redis基础知识
学一点,整一点,基本都是综合别人的,弄成我能理解的内容 https://blog.csdn.net/liqingtx/article/details/60330555 https://blog.csdn.net/u014723137/article/details/125658176 https://redis.io/commands/ 官方命令 📌导航小助…...
最短路径(数据结构实训)(难度系数100)
最短路径 描述: 已知一个城市的交通路线,经常要求从某一点出发到各地方的最短路径。例如有如下交通图: 则从A出发到各点的最短路径分别为: B:0 C:10 D:50 E:30 F:60 输…...
基于SSM实现的电动汽车充电网点管理系统
一、系统架构 前端:jsp | jquery | bootstrap | css 后端:spring | springmvc | jdbc 环境:jdk1.8 | mysql 二、代码及数据库 三、功能介绍 01. web端-首页 02. web端-登录 03. web端-注册 04. web端-我要充电 05. web端-个人中心-消…...
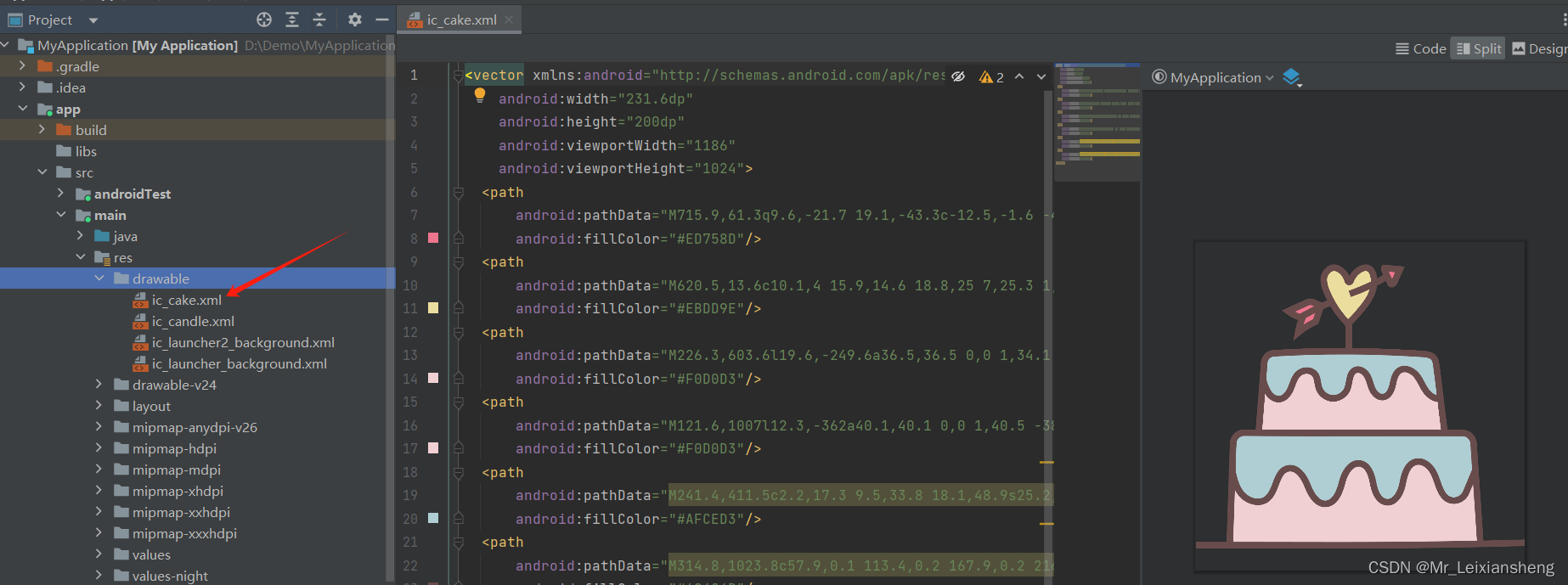
Android ImageView如何使用.svg格式图片
我们知道imageview常用的图片格式是.jpg/.png或者drawable里的部分.xml文件。但有时UI会给过来.svg格式的文件,下面讲解如何使用.svg格式图片文件 step1:AS点击File -> New -> Vector Asset step2:选中要使用的.svg文件,按需要命名和调整&#x…...

力扣热题100道-子串篇
字串 560.和为K的子数组 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1], k 2 输出:2示例 2: 输入&a…...

day3--Shell
1.shell语法 概论 概论 shell是我们通过命令行与操作系统沟通的语言。shell脚本可以直接在命令行中执行,也可以将一套逻辑组织成一个文件,方便复用。 AC Terminal中的命令行可以看成是一个“shell脚本在逐行执行”。Linux中常见的shell脚本有很多种&…...

【数据结构】插入排序、选择排序、冒泡排序、希尔排序、堆排序
前言:生活中我们总是会碰到各种各样的排序,今天我们就对部分常用的排序进行总结和学习,今天的内容还是相对比较简单的一部分,各位一起加油哦! 💖 博主CSDN主页:卫卫卫的个人主页 💞 ὄ…...

TiDB 7.5 LTS 发版丨提升规模化场景下关键应用的稳定性和成本的灵活性
互联网时代,数据的迅猛增长给数据库带来了可扩展性的挑战,Gen AI 带来的数据暴增更加剧了这种挑战。传统的数据分片已经不能承载新时代数据暴增的需求,更简单且具有前瞻性的方法则是采用原生分布式数据库来解决扩展性问题。在这种规模化场景的…...
服务器数据恢复-误操作导致xfs分区数据丢失的数据恢复案例
服务器数据恢复环境: 某品牌OceanStorT系列某型号存储MD1200磁盘柜,组建的raid5磁盘阵列。上层分配了1个lun,安装的linux操作系统,划分两个分区,分区一通过lvm进行扩容,分区二格式化为xfs文件系统。 服务器…...
安装Kubernetes1.23、kubesphere3.4、若依项目自动打包部署到K8S记录
1.安装kubernetes1.23详细教程 kubernetes(k8s)集群超级详细超全安装部署手册 - 知乎 2.安装rancher动态存储 kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml3.安装kubesphere3.4 准备工作 您…...
 `MaterializedMySQL`同步机制解读)
(三) `MaterializedMySQL`同步机制解读
当使用 ClickHouse 的 MaterializedMySQL 引擎进行全量同步时,它主要依赖于两个关键机制:初始全量数据导入和随后的增量更新。以下是这些机制的详细解释: 初始全量数据导入 读取现有数据: 当您在 ClickHouse 中创建一个 MaterializedMySQL 类…...
)
使用 stream 流构建树(不使用递归)
你知道的越多,你不知道的越多 点赞再看,养成习惯 如果您有疑问或者见解,欢迎指教: 企鹅:869192208 文章目录 前言代码实现定义测试实体类实现方法 前言 最近遇到一个地区数据需要转换成树的需求,研究了一种…...

docker 部署 个人网页版 wps office
先声明一下,这个是用的linux桌面,然后安装了一个wps软件 安装好之后,通过我们自己的浏览器进行操作。。。。。 我只是试了一下,目前发现只能一个人用,里面还有谷歌浏览器,就是一个远程linux桌面 docker …...
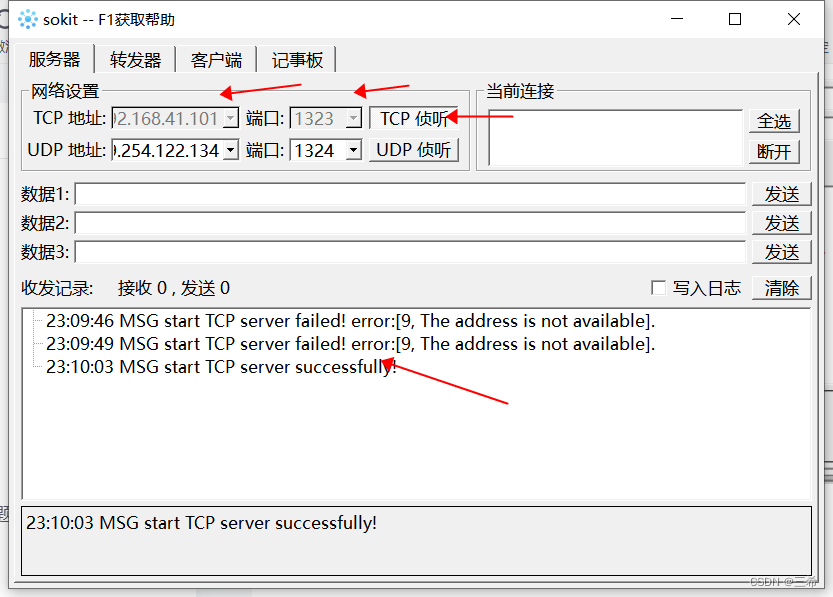
windows进行udp端口转发,解决项目中服务器收不到组播数据的问题
说明 windows7的netsh interface portproxy命令只支持tcp端口转发 如果要进行udp端口转发可以使用sokit 运行sokit 端口转发(以为tcp作为讲解,udp类似) 选择转发器 输入监听地址(SRC地址)和端口 输入转发地址&am…...

抖音、小红书、视频号是如何判定是否限流的?
在这个新媒体营销的时代,抖音、小红书和视频号作为中国最受欢迎的社交媒体平台,为品牌和内容创作者提供了极具潜力的展示空间。然而,无论在哪个平台,限流成为很多人的苦恼。 抖音的推荐算法基于人群画像和初始流量池,同…...
)
frida native hook 技术( frida hook so层函数)
什么是hook: hook,中文译作”钩子“,”挂钩“,看起来好像和钓鱼有点关系,其实它更像一张网。想象这样一个场景:我们在河流上筑坝,只留一个狭窄的通道让水流通过,在这个通道上设一张网…...
-- 多环境开发(yml多文件版))
SpringBoot运维(三)-- 多环境开发(yml多文件版)
目录 引言: 1. 多环境开发的配置 2. 多环境开发--根据功能拆分配置文件 引言: 多环境? 其实就是说你的电脑上写的程序最终要放到别人的服务器上去运行。每个计算机环境不一样...

Vue 修饰符有哪些
事件修饰符 .stop 阻止事件继续传播.prevent 阻止标签默认行为.capture 使用事件捕获模式, 即元素自身触发的事件先在此处处理,然后才交由内部元素进行处理.self 只当在 event.target 是当前元素自身时触发处理函数.once 事件将只会触发一次.passive 告诉浏览器你不…...
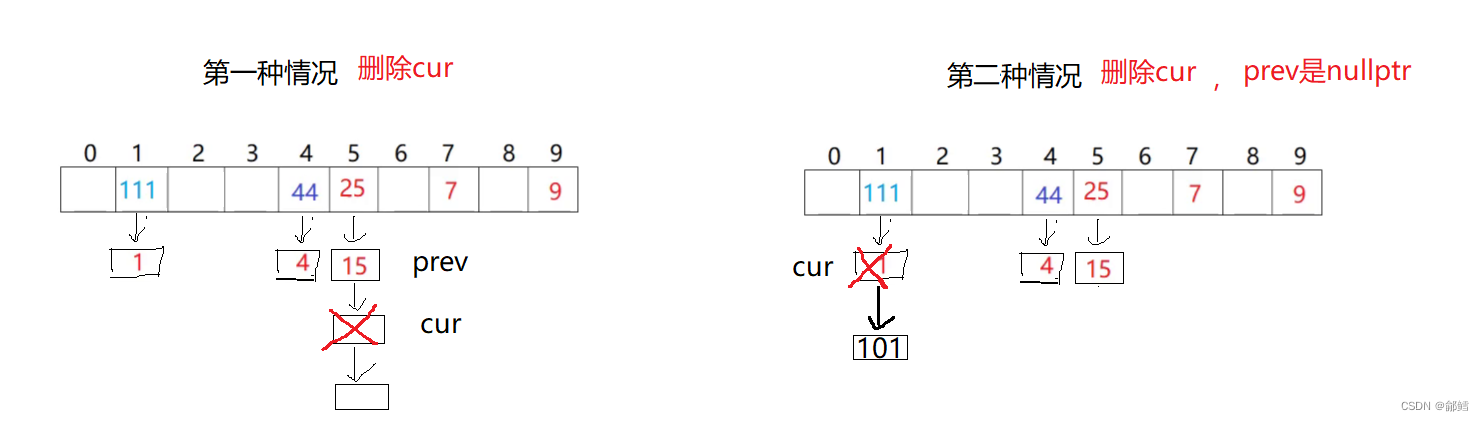
哈希桶的模拟实现【C++】
文章目录 哈希冲突解决闭散列 (开放定址法)开散列 (链地址法、哈希桶)开散列实现(哈希桶)哈希表的结构InsertFindErase 哈希冲突解决 闭散列 (开放定址法) 发生哈希冲突时…...
磁盘相关知识
一、硬盘数据结构 1.扇区: 盘片被分为多个扇形区域,每个扇区存放512字节的数据(扇区越多容量越大) 存放数据的最小单位 512字节 (硬盘最小的存储单位是扇区,512 个字节,八个扇区组成一块&…...

2026主流远控软件综合横测:4款工具全方位测试,谁更适合你?
用心测评,全程无广2026主流远控软件综合横测:4款工具全方位测试,谁更适合你?远程控制已成为个人办公、家庭协助、企业运维、游戏串流的刚需工具。本次横测聚焦ToDesk、向日葵、TeamViewer、网易 UU 远程四款主流产品,从连接性能、…...

基于OpenClaw协议的轻量级AI代理网关MiniClaw实战指南
1. 项目概述:一个轻量级的AI代理网关如果你正在开发一个基于OpenClaw协议的AI应用客户端,或者想快速搭建一个能与现有OpenClaw生态工具(比如各种仪表盘、集成插件)兼容的独立AI代理服务,那么你很可能需要一个能完整实现…...

多说话人场景下的设备定向语音检测技术解析
1. 多说话人场景下的设备定向语音检测技术解析在智能语音交互系统中,准确识别用户何时在对设备说话(设备定向语音)而非与他人交谈,是提升用户体验的关键技术挑战。这项技术被称为设备定向语音检测(Device-Directed Spe…...

规范驱动开发:基于OpenAPI与LLM的现代API构建实践
1. 项目概述:一个基于规范驱动的现代API开发实践最近在GitHub上看到一个挺有意思的项目,叫izzymsft/spec-driven-dev-backend-apis,它是一个用FastAPI构建的客户管理后端REST API。这个项目本身的功能——客户和地址的CRUD操作,结…...

C++ 时间戳实战:从GetTickCount64到std::chrono的跨平台精度选择
1. 为什么我们需要精确的时间戳? 在开发高性能应用时,时间戳的精度往往决定了程序的可靠性。想象一下,你在开发一个在线游戏服务器,玩家A声称自己先击中了玩家B,但服务器记录的两次命中时间差只有几毫秒。如果使用秒级…...

ComfyUI-Impact-Pack完整安装指南:为什么你的V8版本功能不全?终极解决方案
ComfyUI-Impact-Pack完整安装指南:为什么你的V8版本功能不全?终极解决方案 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, …...
的安全与应用)
别再只复制粘贴了!深入理解阿里云IoT设备三元组(ProductKey/DeviceName/DeviceSecret)的安全与应用
阿里云IoT设备三元组安全实践指南:从基础认知到高级防护策略 在物联网项目开发中,设备身份认证是保障系统安全的第一道防线。许多开发者虽然能够快速完成设备接入,但对认证核心——设备三元组(ProductKey/DeviceName/DeviceSecret…...

终极跨平台Steam创意工坊下载指南:WorkshopDL让你的模组之旅更简单
终极跨平台Steam创意工坊下载指南:WorkshopDL让你的模组之旅更简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store或GOG平台购买了心仪的…...

从CelebA数据集到落地应用:一份给新手的MTCNN训练数据制作与模型训练全指南
从CelebA数据集到落地应用:MTCNN训练数据制作与模型训练全指南 人脸检测作为计算机视觉的基础任务,其精度直接影响后续的人脸识别、表情分析等应用效果。MTCNN(Multi-task Cascaded Convolutional Networks)作为经典的多任务级联人…...

STM32H750调试KSZ8863翻车实录:从F4经验到H7的坑,硬件配置避雷指南
STM32H7与KSZ8863实战避坑指南:从F4经验到H7的硬件设计差异 调试以太网PHY芯片KSZ8863时,许多工程师会带着STM32F4的成功经验直接迁移到STM32H7平台,结果往往遭遇意想不到的硬件兼容性问题。本文将深入剖析两个平台在RMII接口设计上的关键差…...