哈希桶的模拟实现【C++】
文章目录
- 哈希冲突解决
- 闭散列 (开放定址法)
- 开散列 (链地址法、哈希桶)
- 开散列实现(哈希桶)
- 哈希表的结构
- Insert
- Find
- Erase
哈希冲突解决
闭散列 (开放定址法)
发生哈希冲突时,如果哈希表未被装满,说明在哈希表种必然还有空位置,那么可以把产生冲突的元素存放到冲突位置的“下一个”空位置中去
如何寻找“下一个位置”
1、线性探测
发生哈希冲突时,从发生冲突的位置开始,依次向后探测,直到找到下一个空位置为止
Hi=(H0+i)%m ( i = 1 , 2 , 3 , . . . )
H0:通过哈希函数对元素的关键码进行计算得到的位置。
Hi:冲突元素通过线性探测后得到的存放位置
m:表的大小。
举例:
用除留余数法将序列{1,111,4,7,15,25,44,9}插入到表长为10的哈希表中,当发生哈希冲突时我们采用闭散列的线性探测找到下一个空位置进行插入,插入过程如下:
使用除留余数法
1%10 =1 ,111 %10 =1
即111和1发生了哈希冲突 ,所以111找到1的下一个空位置插入

将数据插入到有限的空间,那么空间中的元素越多,插入元素时产生冲突的概率也就越大,冲突多次后插入哈希表的元素,在查找时的效率必然也会降低。
介于此,哈希表当中引入了负载因子(载荷因子):
负载因子 = 表中有效数据个数 / 空间的大小
不难发现:
负载因子越大,产出冲突的概率越高,查找的效率越低
负载因子越小,产出冲突的概率越低,查找的效率越高
负载因子越小,也就意味着空间的利用率越低,此时大量的空间都被浪费了。对于闭散列(开放定址法)来说,负载因子是特别重要的因素,一般控制在0.7~0.8以下
采用开放定址法的hash库,如JAVA的系统库限制了负载因子为0.75,当超过该值时,会对哈希表进行增容
线性探测的缺点:一旦发生冲突,所有的冲突连在一起,容易产生数据“堆积”,即不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要多次比较(踩踏效应),导致搜索效率降低
2、二次探测
二次探测为了避免该问题,找下一个空位置的方法为
Hi=(H0+i ^2 )%m ( i = 1 , 2 , 3 , . . . )
H0:通过哈希函数对元素的关键码进行计算得到的位置
Hi:冲突元素通过二次探测后得到的存放位置
m:表的大小
相比线性探测而言,二次探测i是平方,采用二次探测的哈希表中元素的分布会相对稀疏一些,不容易导致数据堆积
template <class K>
struct DefaultHashFunc
{size_t operator() (const K& key){return (size_t)key;}
};template <>
struct DefaultHashFunc<string>
{size_t operator() (const string& str){//BKDR,将输入的字符串转换为哈希值size_t hash = 0;for (auto ch : str){hash *= 131;hash += ch;}return hash;}
};namespace open_address
{enum STATE{EXIST,EMPTY,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;STATE _state = EMPTY;};struct StringHashFunc{size_t operator()(const string& str){return str[0];}};//template<class K, class V>template<class K, class V, class HashFunc = DefaultHashFunc<K>>class HashTable{public:HashTable(){_table.resize(10);}bool insert(const pair<K, V> kv){//扩容 if ((double)_n / (double)_table.size() >= 0.7){HashTable<K, V> newHT;size_t newSize = _table.size() * 2;newHT._table.resize(newSize);//遍历旧表的数据,将旧表的数据重新映射到新表中for (size_t i = 0; i < _table.size(); i++){if (_table[i]._state == EXIST){newHT.insert(_table[i]._kv);//插入的写成kv不行?}}_table.swap(newHT._table);}//线性探测HashFunc hf;size_t hashi = hf(kv.first) % _table.size();//如果该位置没有元素,则直接插入元素 ,如果该位置有元素,找到下一个空位置,插入新元素while (_table[hashi]._state == EXIST)//不是EMPTY和DELETE这两种情况{++hashi;hashi %= _table.size();}//是EMPTY和DELETE这两种情况_table[hashi]._kv = kv;_table[hashi]._state = EXIST;++_n;return true;}HashData<const K, V>* Find(const K& key){HashFunc hf;//线性探测 //如果该位置没有元素,则直接插入元素 ,如果该位置有元素,找到下一个空位置,插入新元素size_t hashi = hf(key) % _table.size();while (_table[hashi]._state != EMPTY) //DELETE和EXIST{if (_table[hashi]._state == EXIST && _table[hashi]._kv.first == key){return (HashData<const K, V>*) & _table[hashi];}}return nullptr;}bool Erase(const K& key){//先找到HashData<const K, V>* ret = Find(key);//再删除 if (ret != nullptr){ret->_state = DELETE;_n--;return true;}//没找到 return false;}public:vector<HashData<K, V>> _table;size_t _n = 0; //存储有效数据的个数};}
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
开散列 (链地址法、哈希桶)
开散列,又叫哈希桶,首先对关键码集合用哈希函数计算哈希地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
举例:
用除留余数法将序列{1,111,4,7,15,25,44,9}插入到表长为10的哈希表中,当发生哈希冲突时我们采用开散列的方式进行插入,插入过程如下:

将相同哈希地址的元素通过单链表链接起来,然后将链表的头结点存储在哈希表中的方式,不会影响与自己哈希地址不同的元素的增删查改的效率,因此开散列的负载因子相比闭散列而言,可以稍微大一点
闭散列的开放定址法,负载因子不能超过1,一般建议控制在[0.0, 0.7]
开散列的哈希桶,负载因子可以超过1,一般建议控制在[0.0, 1.0]
在实际中,开散列的哈希桶结构比闭散列更实用,主要原因有两点:
哈希桶的负载因子可以更大,空间利用率高
哈希桶在极端情况下还有可用的解决方案
开散列实现(哈希桶)
哈希表的结构
struct HashNode{pair<K, V> _kv;HashNode<K,V>* _next;HashNode( const pair<K, V> & kv):_kv(kv),_next(nullptr){}};
Insert
bool Insert(const pair<K,V> & kv){size_t hashi = kv.first % _table.size();//负载因子到1就扩容 if (_n == _table.size()){size_t newsize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newsize, nullptr);//遍历旧表,将原哈希表当中的结点插入到新哈希表for (int i = 0; i <= _table.size(); i++){Node* cur = _table[i];//插入到新哈希表while (cur != nullptr){Node* next = cur->_next;// 重新分配hashisize_t hashi = cur->_kv.first % _table.size();cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}}}//头插 Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;return true;}
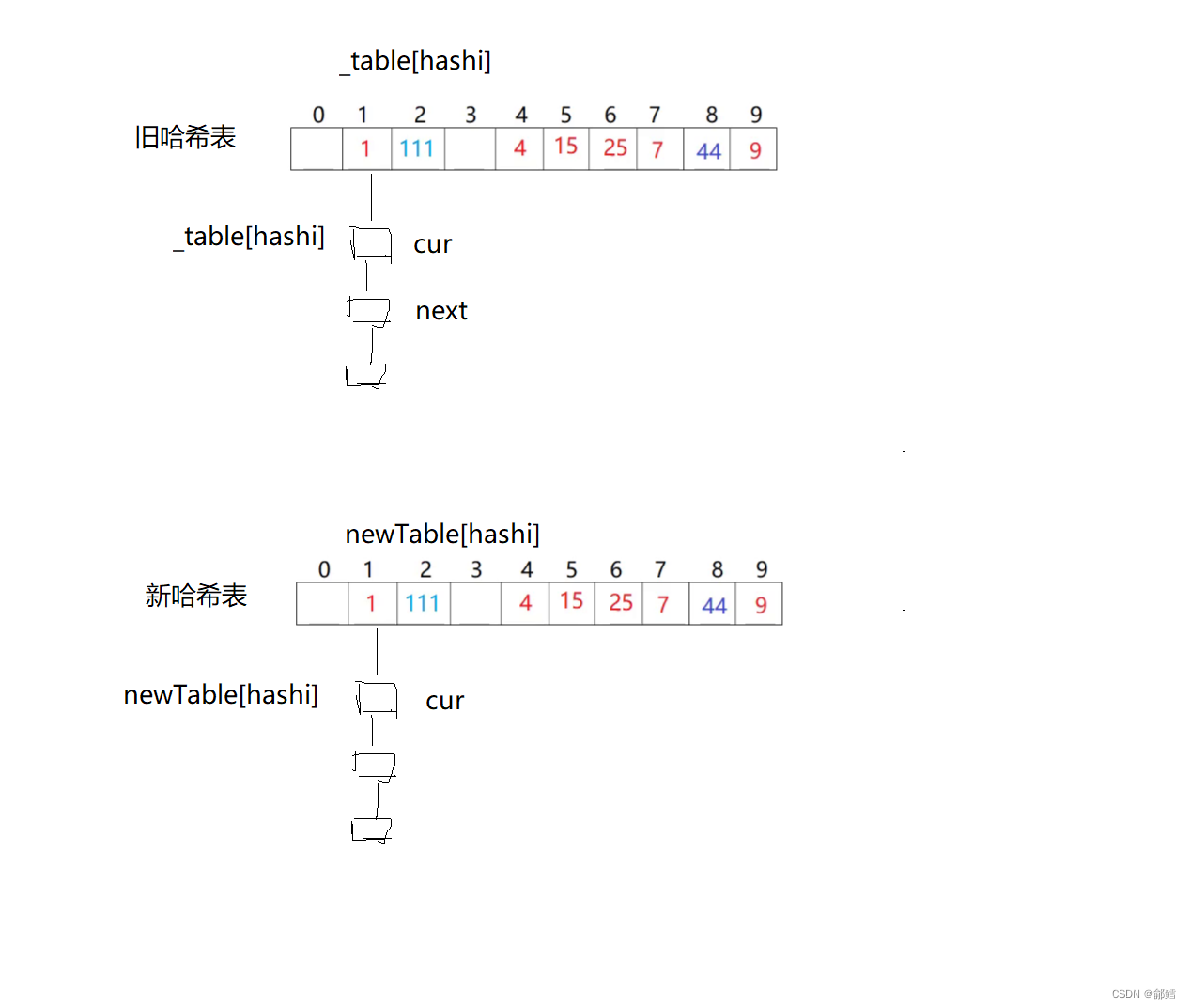
Find
Node * Find(const K & key){size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur != nullptr){if (key == cur->_kv.first){return cur;}cur = cur->_next;}return nullptr;}
Erase
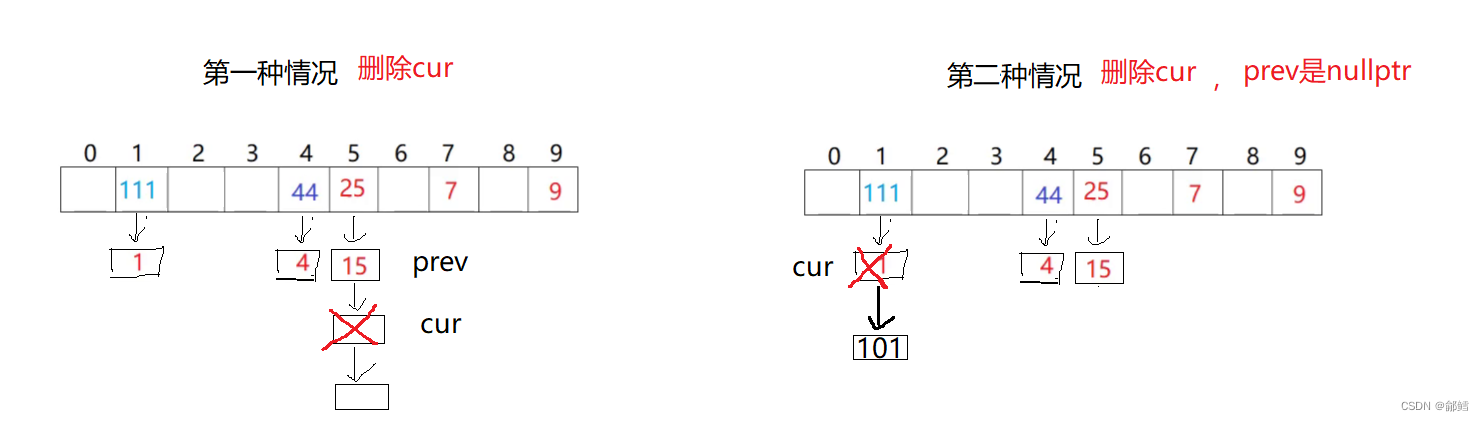
bool Erase(const K & key){size_t hashi = key % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur != nullptr){if (key == cur->_kv.first){if(prev==nullptr)//第二种情况 ,prev是nullptr ,就是头删{_table[hashi] = cur->_next;}else//第一种情况 ,cur是头节点{prev->_next = cur->_next;}delete cur;return true; }prev = cur;cur = cur->_next;}//没找到 return false;}
namespace hash_bucket
{template <class K ,class V> struct HashNode{pair<K, V> _kv;HashNode<K,V>* _next;HashNode( const pair<K, V> & kv):_kv(kv),_next(nullptr){}};template<class K,class V> class HashTable{public:typedef HashNode<K,V> Node;//iterator begin()//{//}//iterator end()//{//}//const_iterator begin()//{//}//const_iterator end()//{//}//GetNextPrime()//{//}HashTable(){_table.resize(10, nullptr);}~HashTable(){}//bool Insert(const pair<K, V> kv)//{// //负载因子到1就扩容 // if (_n == _table.size())// {// size_t newsize = _table.size() * 2;// vector<Node*> newtable;// newtable.resize(newsize, nullptr);// }// size_t hashi = kv.first % _table.size();// //头插 // Node* newnode = new Node(key);// newnode->_next = _table[hashi];// _table[hashi] = newnode;// ++_n;// return true;//}bool Insert(const pair<K,V> & kv){size_t hashi = kv.first % _table.size();//负载因子到1就扩容 if (_n == _table.size()){size_t newsize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newsize, nullptr);//遍历旧表,将原哈希表当中的结点插入到新哈希表for (int i = 0; i <= _table.size(); i++){Node* cur = _table[i];//插入到新哈希表while (cur != nullptr){Node* next = cur->_next;// 重新分配hashisize_t hashi = cur->_kv.first % _table.size();cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}}}//头插 Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;return true;}Node * Find(const K & key){size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur != nullptr){if (key == cur->_kv.first){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K & key){size_t hashi = key % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur != nullptr){if (key == cur->_kv.first){if(prev==nullptr)//第二种情况 ,prev是nullptr ,就是头删{_table[hashi] = cur->_next;}else//第一种情况 ,cur是头节点{prev->_next = cur->_next;}delete cur;return true; }prev = cur;cur = cur->_next;}//没找到 return false;}void Print(){for (size_t i = 0; i < _table.size(); i++){printf("[%d]->", i);Node* cur = _table[i];while (cur != nullptr){cout << cur->_kv.first << "->";cur = cur->_next;}printf("NULL\n");}cout << endl;}private:vector<Node*> _table;//指针数组size_t _n = 0;//存储有效数据};
}
如果你觉得这篇文章对你有帮助,不妨动动手指给点赞收藏加转发,给鄃鳕一个大大的关注
你们的每一次支持都将转化为我前进的动力!!
相关文章:
哈希桶的模拟实现【C++】
文章目录 哈希冲突解决闭散列 (开放定址法)开散列 (链地址法、哈希桶)开散列实现(哈希桶)哈希表的结构InsertFindErase 哈希冲突解决 闭散列 (开放定址法) 发生哈希冲突时…...
磁盘相关知识
一、硬盘数据结构 1.扇区: 盘片被分为多个扇形区域,每个扇区存放512字节的数据(扇区越多容量越大) 存放数据的最小单位 512字节 (硬盘最小的存储单位是扇区,512 个字节,八个扇区组成一块&…...

FTP原理与配置
FTP是用来传送文件的协议。使用FTP实现远程文件传输的同时,还可以保证数据传输的可靠性和高效性。 FTP的应用 FTP 提供了一种在服务器和客户机之间上传和下载文件的有效方式。在企业网络中部署一台FTP服务器,将网络设备配置为FTP客户端,则可…...
ios环境搭建_xcode安装及运行源码
目录 1 xcode 介绍 2 xcode 下载 3 xocde 运行ios源码 1 xcode 介绍 Xcode 是运行在操作系统Mac OS X上的集成开发工具(IDE),由Apple Inc开发。Xcode是开发 macOS 和 iOS 应用程序的最快捷的方式。Xcode 具有统一的用户界面设计࿰…...

C++ 151. 反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:输入字符串 s中可能会存在前导空格、尾随…...
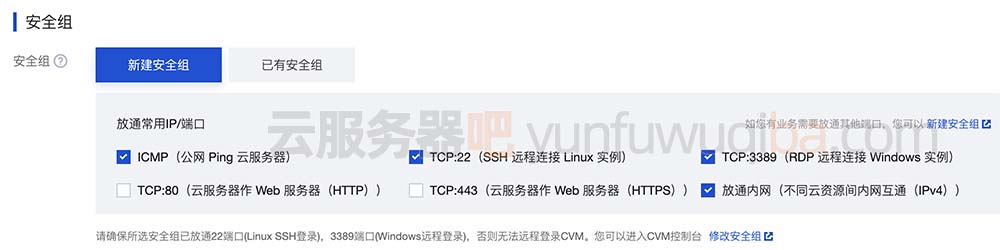
腾讯云服务器如何买(购买腾讯云服务器的详细步骤)
腾讯云服务器购买流程直接在官方秒杀活动上购买比较划算,在云服务器CVM或轻量应用服务器页面自定义购买价格比较贵,但是自定义购买云服务器CPU内存带宽配置选择范围广,活动上购买只能选择固定的活动机,选择范围窄,但是…...

48道Linux面试题
本博客将汇总 Linux 面试中常见的题目,并提供详细的解答。 文章目录 1、绝对路径用什么[符号表](https://so.csdn.net/so/search?q符号表&spm1001.2101.3001.7020)示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命…...

(13)Linux 进程的优先级、进程的切换以及环境变量等
前言:我们先讲解进程的优先级。然后讲解进程的切换,最后我们讲解环境变量,并且做一个 "让自己的可执行程序不带路径也能执行"的实践,讲解环境变量的到如何删除,最后再讲几个常见的环境变量。 一、进程优先级…...
C卷 (JavaPythonNode.jsC++))
数的分解(100%用例)C卷 (JavaPythonNode.jsC++)
给定一个正整数n,如果能够分解为m(m >1)个连续正整数之和,请输出所有分解中,m最小的分解。 如果给定整数无法分解为连续正整数,则输出字符串"N" 输入描述 输入数据为一整数,范围为 (1,2^30] 输出描述 比如输入为: 21 输出: 21=10+11 示例1 输入输出示例…...
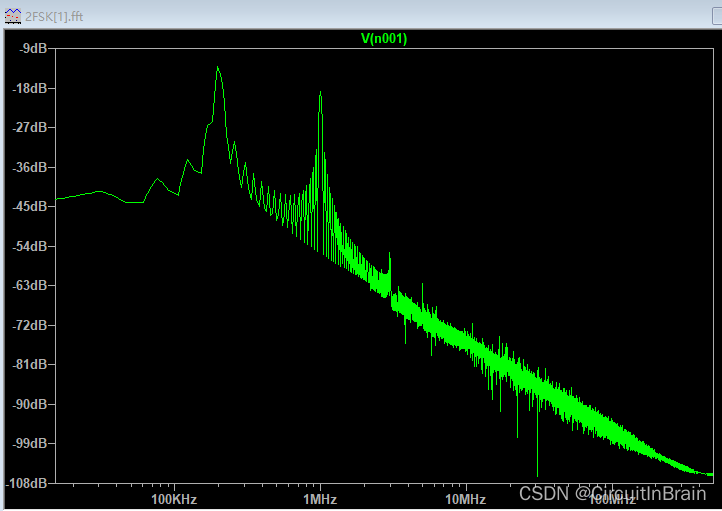
数字调制学习总结
调制:将基带的信号的频谱搬移到指定的信道通带内的过程。 解调:把指定信号通带内的信号还原为基带的过程。 1、2ASK调制 原理如下图所示,基带信号为单极不归零码,与载波信号相乘,得到调制信号。 调制电路可以用开关…...
AcWing 1129. 热浪(单源最短路)
题目链接 https://www.acwing.com/problem/content/1131/https://www.acwing.com/problem/content/1131/ 题解 此题属于单源最短路问题,根据数据范围,可以使用Dijkstra算法、堆优化版的Dijkstra算法、SPFA算法。本例采用SPFA算法,使用手写循…...
)
Mybatis Mapper XML文件-缓存(cache)
MyBatis包含一个强大的事务查询缓存特性,可以进行灵活的配置和自定义。在MyBatis 3的缓存实现中进行了许多改进,使其更加强大且更易于配置。 默认情况下,仅启用了本地会话缓存,该缓存仅用于缓存会话期间的数据。要启用全局的第二…...
电子科大软件系统架构设计——设计模式
设计模式概述 设计模式的背景 设计面向对象软件比较困难,而设计可以复用的面向对象软件更加困难不是解决任何问题都需要从头做起,最好能复用以往的设计方案经验面向对象软件设计经验需要有一定的模式记录下来,以提供给其他设计者使用&#…...

ubuntu20 安装缺失的字体
在/usr/share/fonts创建文件夹winfonts sudo mkdir winfonts 下载缺失的字体后,复制命令到对应的文件夹。 刷新字体库 sudo mkfontscale sudo mkfontdir sudo fc-cache...

2023年12月27日学习记录_加入噪声
目录 1、今日计划学习内容2、今日学习内容1、add noise to audio clipssignal to noise ratio(SNR)加入 additive white gaussian noise(AWGN)加入 real world noises 2、使用kaggel上的一个小demo:CNN模型运行时出现的问题调整采样率时出现bug 3、明确90dB下能否声…...

Java面试题86-95
86. Java代码查错(4)public class Something { public int addOne(final int x) { return x; }}此代码有错误吗?答案: 错。int x被修饰成final,意味着x不能在addOne method中被修改。87. Java代码查错(5&…...

看完谁再说搞不定上下角标?
一、需求 开发中有一些需要用到上下角标的地方,比如说化学式、数学式、注释。。。除了可以使用上下角标的标签,还可以通过css样式和CV大法实现,以下是具体实现方式。 二、实现方法 (1)标签写法: <sup…...

在 Python 中使用装饰器decorator的 7 个层次
在 Python 中使用装饰器的 7 个层次(7 Levels of Using Decorators in Python) 文章目录 在 Python 中使用装饰器的 7 个层次(7 Levels of Using Decorators in Python)导言Level 0: 了解基本概念Basic Concepts和用法Usages什么是装饰器decorator?我们为什么需要装…...

Vue.js项目部署至Linux服务器的详细步骤
引言 在现代Web开发中,Vue.js作为一款流行的前端框架,为开发者提供了灵活且高效的工具。然而,在将Vue.js项目成功部署到Linux服务器上,可能需要一些额外的步骤和注意事项。本文将深入介绍在Linux服务器上部署Vue.js项目的详细步骤…...

Java三层架构/耦合/IOC/DI
一.三层架构 controller/web 控制层。接收前端发送的请求,对请求进行处理,并响应数据。 service 业务逻辑层,处理具体的业务逻辑。 dao 数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、…...

word删除空白页
行距固定值,1磅...

PADS VX2.7 光绘文件实战:从CAM配置到Gerber输出的全链路解析
1. PADS VX2.7光绘文件生成的核心逻辑 第一次用PADS VX2.7输出Gerber文件时,我被它和其他EDA软件的区别惊到了。不像某些软件一键导出所有层,PADS需要像搭积木一样逐层配置,这种看似繁琐的设计其实暗藏玄机——它让工程师对每层光绘文件的生成…...
)
Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版)
更多请点击: https://codechina.net 第一章:Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版) Gemini Nano 是 Google 推出的首个专为端侧设备设计的轻量级大语言模型,支持在 Android 14 设备上本地运行&…...
)
告别手动点点点:用pywinauto给微信做个自动化小助手(Python实战)
告别手动点点点:用pywinauto打造微信自动化小助手 微信作为日常高频使用的通讯工具,每天重复的"文件传输助手"转发、消息发送等操作消耗着大量时间。本文将带你用pywinauto构建一个能自动完成这些任务的Python脚本,解放双手的同时深…...
)
告别抓瞎:手把手教你解读usbmon抓到的原始数据(附字段含义详解)
USB数据解码实战:从usbmon原始输出到可读通信分析 当你第一次看到usbmon捕获的原始数据时,那串由十六进制数字和神秘符号组成的"天书"确实令人望而生畏。作为一名曾经同样困惑的技术探索者,我完全理解这种面对海量数据却无从下手的…...

别再手动贴图了!LOD1.3建模的智能纹理库怎么用?手把手教你配置大势智慧材质模板
LOD1.3建模革命:智能纹理库的实战配置指南 当清晨的第一缕阳光透过窗户洒在建模师的工作台上,那些曾经需要数小时手动贴图的建筑模型,如今只需几分钟就能自动完成纹理匹配。这不是未来场景,而是LOD1.3建模中智能纹理库技术带来的…...
)
Labelme版本不兼容报错?手把手教你修改源码和JSON文件(附3.18.0与4.5.6对比)
Labelme版本兼容性实战:从源码修改到JSON批量处理的完整指南 当你正专注于一个重要的数据标注项目,突然遭遇"Error opening file lineColor"的红色报错框,整个团队的标注进度被迫停滞——这种场景对于使用Labelme进行图像标注的开发…...

用C++模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析
用C模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析 堆宝塔游戏是一个有趣的逻辑挑战,它不仅能锻炼编程思维,还能帮助我们深入理解数据结构中的栈操作。本文将带你从零开始,用C实现这个游戏,并逐行解析代码逻辑&a…...

接入Taotoken多模型路由后服务端响应稳定性提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken多模型路由后服务端响应稳定性提升感受 1. 背景:生产环境对AI服务稳定性的需求 在构建依赖大模型API的生…...

基于Adafruit Trinket与旋转编码器制作USB物理音量旋钮
1. 项目概述与核心价值作为一个常年泡在电脑前,需要频繁切换音乐、会议和视频的开发者,我发现自己每天点击系统音量图标的次数多得离谱。那种在关键时刻需要快速调低音量,却不得不移动鼠标、寻找小图标的操作,不仅打断了工作流&am…...