Python+Yolov5+Qt交通标志特征识别窗体界面相片视频摄像头
程序示例精选
Python+Yolov5+Qt交通标志特征识别窗体界面相片视频摄像头
如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!
前言
这篇博客针对《Python+Yolov5+Qt交通标志特征识别窗体界面相片视频摄像头》编写代码,代码整洁,规则,易读。 学习与应用推荐首选。
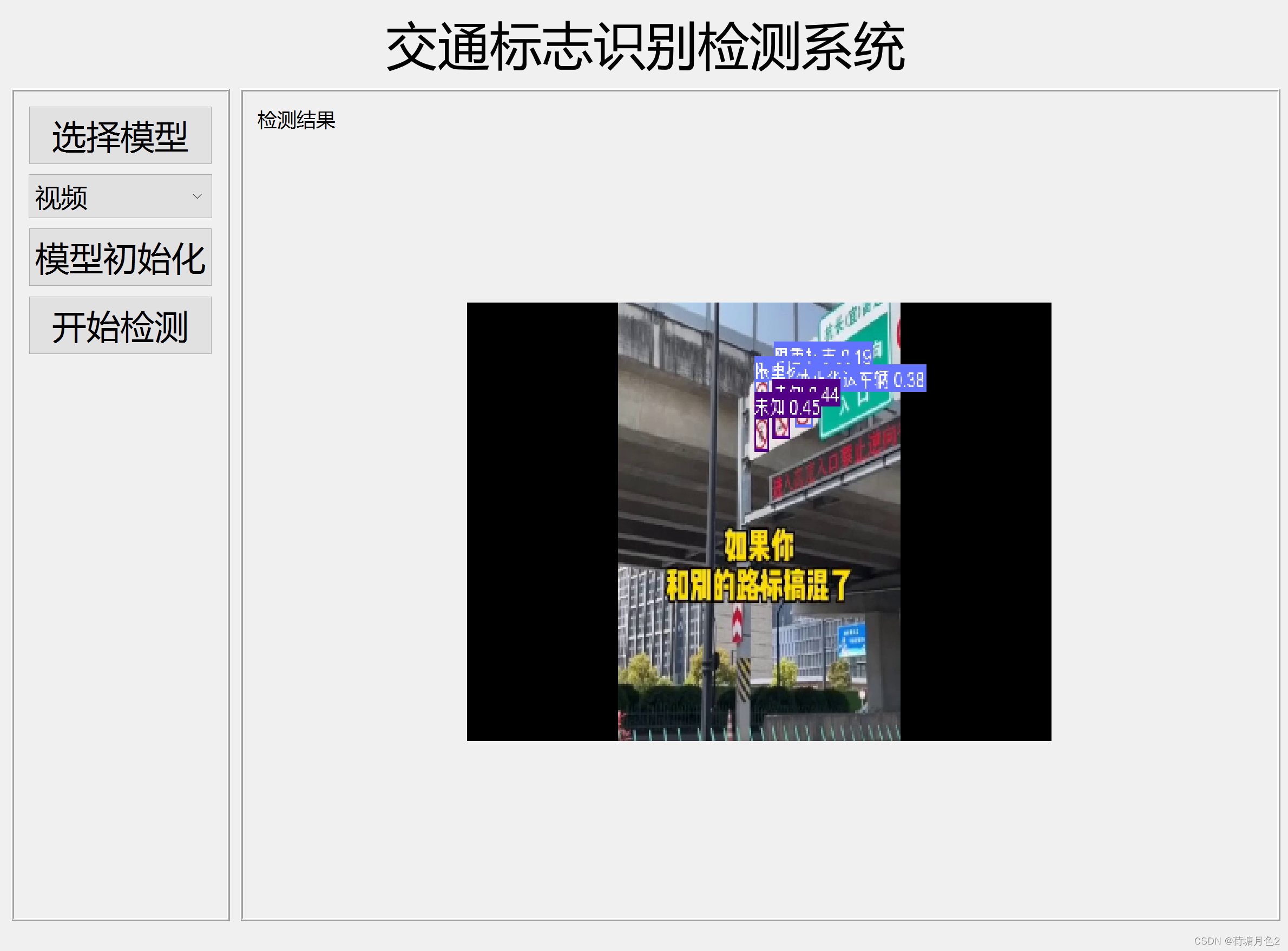
运行结果
文章目录
一、所需工具软件
二、使用步骤
1. 主要代码
2. 运行结果
三、在线协助
一、所需工具软件
1. Python
2. Pycharm
二、使用步骤
代码如下(示例):
def detect(save_img=False):source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_sizewebcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(('rtsp://', 'rtmp://', 'http://'))# Directoriessave_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir# Initializeset_logging()device = select_device(opt.device)half = device.type != 'cpu' # half precision only supported on CUDA# Load modelmodel = attempt_load(weights, map_location=device) # load FP32 modelstride = int(model.stride.max()) # model strideimgsz = check_img_size(imgsz, s=stride) # check img_sizeif half:model.half() # to FP16# Second-stage classifierclassify = Falseif classify:modelc = load_classifier(name='resnet101', n=2) # initializemodelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()# Set Dataloadervid_path, vid_writer = None, Noneif webcam:view_img = check_imshow()cudnn.benchmark = True # set True to speed up constant image size inferencedataset = LoadStreams(source, img_size=imgsz, stride=stride)else:save_img = Truedataset = LoadImages(source, img_size=imgsz, stride=stride)# Get names and colorsnames = model.module.names if hasattr(model, 'module') else model.namescolors = [[random.randint(0, 255) for _ in range(3)] for _ in names]# Run inferenceif device.type != 'cpu':model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run oncet0 = time.time()# Apply NMSpred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)t2 = time_synchronized()# Apply Classifierif classify:pred = apply_classifier(pred, modelc, img, im0s)# Process detectionsfor i, det in enumerate(pred): # detections per imageif webcam: # batch_size >= 1p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.countelse:p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)p = Path(p) # to Pathsave_path = str(save_dir / p.name) # img.jpgtxt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txts += '%gx%g ' % img.shape[2:] # print stringgn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwhif len(det):# Rescale boxes from img_size to im0 sizedet[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print resultsfor c in det[:, -1].unique():n = (det[:, -1] == c).sum() # detections per classs += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string# Write resultsfor *xyxy, conf, cls in reversed(det):if save_txt: # Write to filexywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhline = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label formatwith open(txt_path + '.txt', 'a') as f:f.write(('%g ' * len(line)).rstrip() % line + '\n')if save_img or view_img: # Add bbox to imagelabel = f'{names[int(cls)]} {conf:.2f}'plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)# Print time (inference + NMS)print(f'{s}Done. ({t2 - t1:.3f}s)')# Stream resultsif view_img:cv2.imshow(str(p), im0)cv2.waitKey(1) # 1 millisecond# Save results (image with detections)if save_img:if dataset.mode == 'image':cv2.imwrite(save_path, im0)else: # 'video'if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerfourcc = 'mp4v' # output video codecfps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))vid_writer.write(im0)if save_txt or save_img:s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''print(f"Results saved to {save_dir}{s}")print(f'Done. ({time.time() - t0:.3f}s)')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='yolov5_crack_wall_epoach150_batchsize5.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcamparser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--view-img', action='store_true', help='display results')parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--update', action='store_true', help='update all models')parser.add_argument('--project', default='runs/detect', help='save results to project/name')parser.add_argument('--name', default='exp', help='save results to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')opt = parser.parse_args()print(opt)check_requirements()with torch.no_grad():if opt.update: # update all models (to fix SourceChangeWarning)for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:detect()strip_optimizer(opt.weights)else:detect()运行结果
三、在线协助:
如需安装运行环境或远程调试,见文章底部个人 QQ 名片,由专业技术人员远程协助!
{kind=link}
1)远程安装运行环境,代码调试
2)Visual Studio, Qt, C++, Python编程语言入门指导
3)界面美化
4)软件制作
5)云服务器申请
6)网站制作
当前文章连接:https://blog.csdn.net/alicema1111/article/details/132666851
个人博客主页:https://blog.csdn.net/alicema1111?type=blog
博主所有文章点这里:https://blog.csdn.net/alicema1111?type=blog
博主推荐:
Python人脸识别考勤打卡系统:
https://blog.csdn.net/alicema1111/article/details/133434445
Python果树水果识别:https://blog.csdn.net/alicema1111/article/details/130862842
Python+Yolov8+Deepsort入口人流量统计:https://blog.csdn.net/alicema1111/article/details/130454430
Python+Qt人脸识别门禁管理系统:https://blog.csdn.net/alicema1111/article/details/130353433
Python+Qt指纹录入识别考勤系统:https://blog.csdn.net/alicema1111/article/details/129338432
Python Yolov5火焰烟雾识别源码分享:https://blog.csdn.net/alicema1111/article/details/128420453
Python+Yolov8路面桥梁墙体裂缝识别:https://blog.csdn.net/alicema1111/article/details/133434445
相关文章:
Python+Yolov5+Qt交通标志特征识别窗体界面相片视频摄像头
程序示例精选 PythonYolov5Qt交通标志特征识别窗体界面相片视频摄像头 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《PythonYolov5Qt交通标志特征识别窗体界面相片视频摄像头》编写代码&a…...
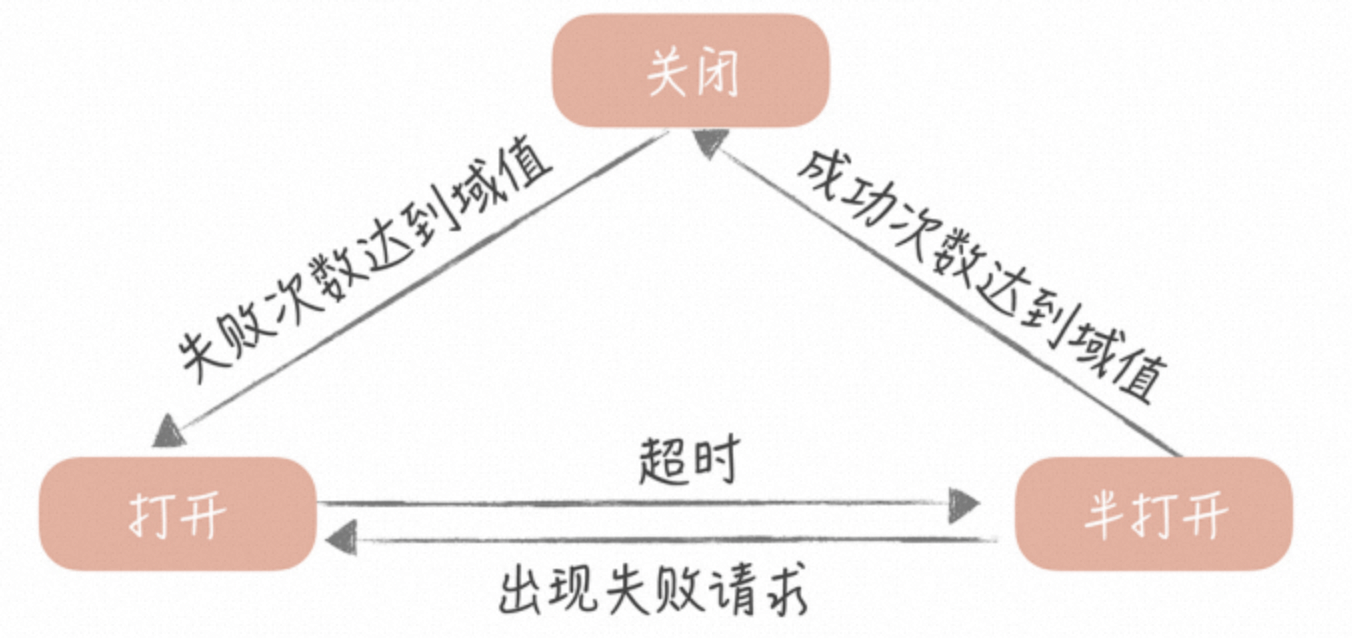
浅谈高并发以及三大利器:缓存、限流和降级
引言 高并发背景 互联网行业迅速发展,用户量剧增,系统面临巨大的并发请求压力。 软件系统有三个追求:高性能、高并发、高可用,俗称三高。三者既有区别也有联系,门门道道很多,全面讨论需要三天三夜&#…...
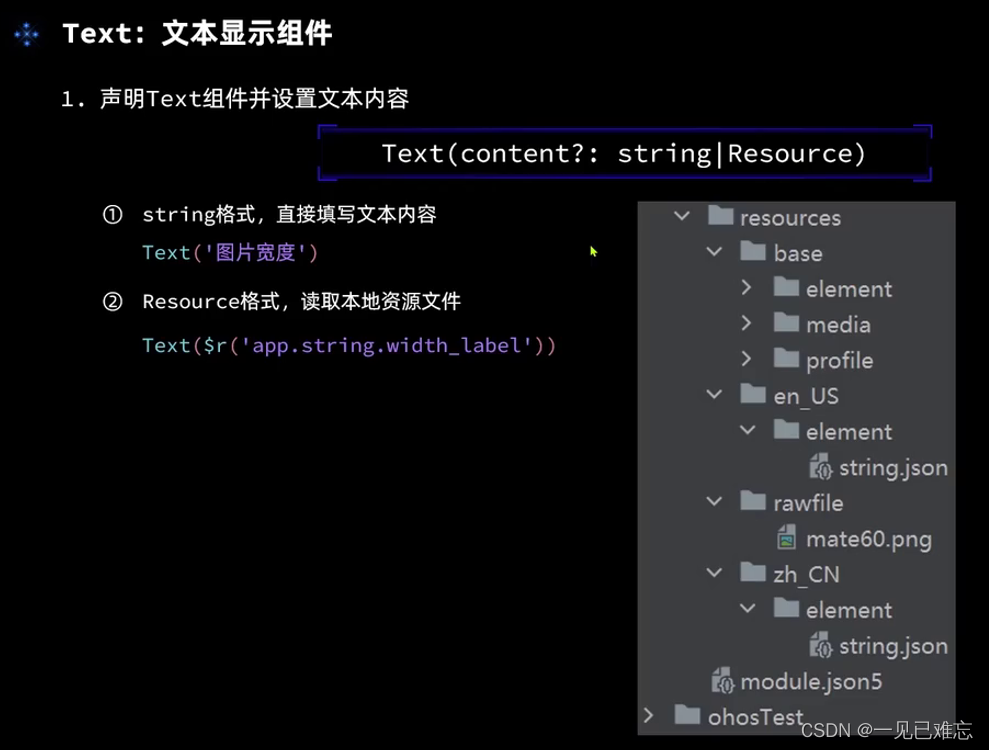
深入ArkUI:深入实战组件text和text input
文章目录 Text组件介绍Text组件的属性方法Text:文本显示组件4.3TextInput组件实战案例:图片宽度控制页面本文总结要点回顾在今天的课程中,我们将深入学习ArkUI提供的基础组件,着重探讨text和text input两个组件。 Text组件介绍 Text组件是一个用于显示文本的组件,其主要作…...
)
WPF 基础(Binding 二)
续接上文,本章继续讲解WPF Binding相关知识,主要内容是绑定的模式和绑定源(Source) 5绑定模式 在使用Binding类的时候有4中绑定模式可以选择 BindingMode TwoWay导致对源属性或目标属性的更改可自动更新对方。此绑定类型适用于…...

限制el-upload组件的上传文件大小
限制el-upload组件的上传文件大小 <el-upload :before-upload"handleBeforeUpload"><!-- 其他组件内容 --> </el-upload>Vue实例中定义handleBeforeUpload方法来进行文件大小的验证。你可以使用file.size属性来获取文件的大小,并与你期…...
什么是爬虫,为什么爬虫会导致服务器负载跑满
在我们日常使用服务器的过程中,经常会有遇到各种各样的问题。今天就有遇到用户来跟德迅云安全反馈自己服务器负载跑满,给用户详细排查后也未发现异常,抓包查看也没有明显攻击特征,后续查看发现是被爬虫爬了,调整处理好…...

线上隐私保护的未来:分布式身份DID的潜力
在日益数字化的世界中,人们的生活越来越多地依赖于互联网,数字身份也因而变得越来越重要。根据法律规定,互联网应用需要确认用户的真实身份才能提供各种服务,而用户则希望在进行身份认证的同时能够尽量保护他们的个人隐私…...
服务器被入侵后如何查询连接IP以及防护措施
目前越来越多的服务器被入侵,以及攻击事件频频的发生,像数据被窃取,数据库被篡改,网站被强制跳转到恶意网站上,网站在百度的快照被劫持等等的攻击症状层出不穷,在这些问题中,如何有效、准确地追…...

【开源】基于Vue+SpringBoot的公司货物订单管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 客户管理模块2.2 商品维护模块2.3 供应商管理模块2.4 订单管理模块 三、系统展示四、核心代码4.1 查询供应商信息4.2 新增商品信息4.3 查询客户信息4.4 新增订单信息4.5 添加跟进子订单 五、免责说明 一、摘要 1.1 项目…...
2023-12-29 服务器开发-Centos部署LNMP环境
摘要: 2023-12-29 服务器开发-Centos部署LNMP环境 centos7.2搭建LNMP具体步骤 1.配置防火墙 CentOS 7.0以上的系统默认使用的是firewall作为防火墙, 关闭firewall: systemctl stop firewalld.service #停止firewall systemctl disable fire…...
CEC2017(Python):五种算法(DE、RFO、OOA、PSO、GWO)求解CEC2017
一、5种算法简介 1、差分进化算法DE 2、红狐优化算法RFO 3、鱼鹰优化算法OOA 4、粒子群优化算法PSO 5、灰狼优化算法GWO 二、CEC2017简介 参考文献: [1]Awad, N. H., Ali, M. Z., Liang, J. J., Qu, B. Y., & Suganthan, P. N. (2016). “Problem defini…...

数字身份验证:跨境电商如何应对账户安全挑战?
在数字化时代,随着跨境电商的蓬勃发展,账户安全问题逐渐成为行业和消费者关注的焦点。随着网络犯罪日益猖獗,用户的数字身份安全面临着更加复杂的威胁。本文将深入探讨数字身份验证在跨境电商中的重要性,并探讨各种创新技术和策略…...

Nature | 大型语言模型(LLM)能够发现和产生新知识吗?
大型语言模型(LLM)是基于大量数据进行预训练的超大型深度学习模型。底层转换器是一组神经网络,这些神经网络由具有自注意力功能的编码器和解码器组成。编码器和解码器从一系列文本中提取含义,并理解其中的单词和短语之间的关系。通…...

C# 使用ZXing.Net生成二维码和条码
写在前面 条码生成是一个经常需要处理的功能,本文介绍一个条码处理类库,ZXing用Java实现的多种格式的一维二维条码图像处理库,而ZXing.Net是其.Net版本的实现。 在WinForm下使用该类库需要从NuGet安装两个组件: ZXing.Net ZXing…...
Windows系统配置pytorch环境,Jupyter notebook编辑器安装使用(深度学习本地篇)
如今现在好一点的笔记本都自带英伟达独立显卡,对于一些简单的深度学习项目,是不需要连接服务器的,甚至数据量不大的话,cpu也足够进行训练学习。我把电脑上一些以前的笔记整理一下,记录起来,方便自己35岁事业…...

详解“量子极限下运行的光学神经网络”——相干伊辛机
量子计算和量子启发计算可能成为解答复杂优化问题的新前沿,而经典计算机在历史上是无法解决这些问题的。 当今最快的计算机可能需要数千年才能完成高度复杂的计算,包括涉及许多变量的组合优化问题;研究人员正在努力将解决这些问题所需的时间缩…...
)
uniapp通过蓝牙传输数据 (安卓)
在uni-app中,可以通过原生插件的方式来实现蓝牙传输数据的功能。以下是一般的步骤: 1. 创建一个原生插件 在uni-app项目的根目录下,创建一个原生插件的目录,比如"uni-bluetooth"。然后在该目录下创建一个"Androi…...
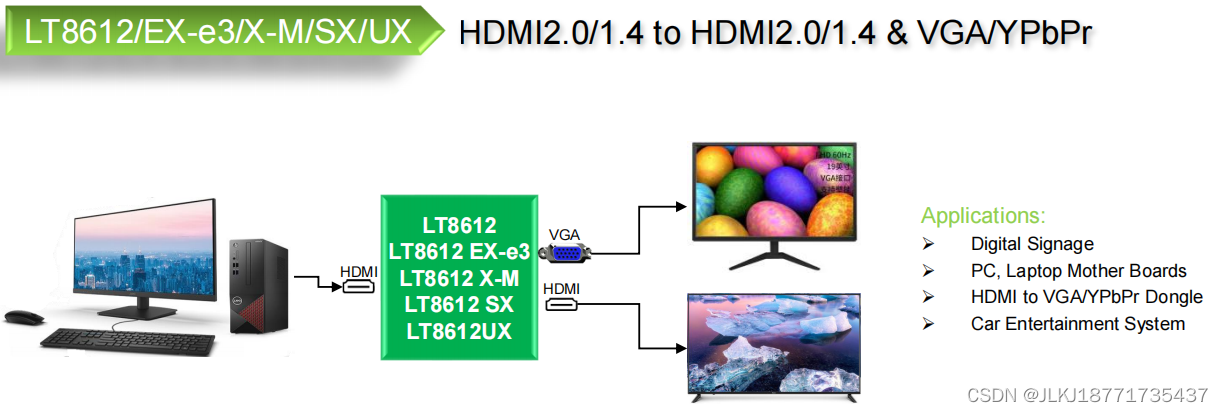
LT8612UX-HDMI2.0 to HDMI2.0 and VGA Converter with Audio,支持三通道视频DAC
HDMI2.0 to HDMI2.0 and VGA Converter with Audio 1. 描述 LT8612UX是一个HDMI到HDMI和vga转换器,它将HDMI2.0数据流转换为HDMI2.0信号和模拟RGB信号。 它还输出8通道I2S和SPDIF信号,使高质量的7.1通道音频。 LT8612UX支持符合HDMI2.0/ 1.4规范的…...
python gui programming cook,python gui视频教程
大家好,给大家分享一下python gui programming cook,很多人还不知道这一点。下面详细解释一下。现在让我们来看看! Source code download: 本文相关源码 前言 上一节我们实现了明细窗体GUI的搭建,并且设置了查看、修改、添加三种不…...

亚马逊bsr排名的影响因素,如何提高BSR排名?-站斧浏览器
亚马逊BSR排名的影响因素有哪些? 销售速度:BSR排名主要基于产品的销售速度,即最近一段时间内的销售量。销售速度越快,BSR排名越高。 销售历史:亚马逊会考虑产品的历史销售数据,新上架的产品可能需要一段时…...

大语言模型本地化部署利器:Synaptic-Link 模型文件管理工具详解
1. 项目概述与核心价值最近在折腾一些AI相关的本地化部署和模型管理,发现一个挺有意思的项目,叫dlxeva/synaptic-link。乍一看这个名字,可能有点摸不着头脑,“突触链接”?听起来像是神经科学或者生物信息学的东西。但如…...

不只是安装:在龙芯2k1000LA上为Loongnix配置WiFi、蓝牙与触摸屏驱动的完整流程
龙芯2k1000LA开发板外设驱动深度配置指南:从WiFi到触摸屏的全栈解决方案 在国产化硬件开发领域,龙芯2k1000LA开发板凭借其完全自主的LoongArch架构,正成为物联网和嵌入式设备开发者的重要选择平台。不同于x86架构的"开箱即用"体验&…...

Arm Ethos-U85 NPU架构解析与边缘AI优化实践
1. Arm Ethos-U85 NPU架构解析:边缘AI的算力引擎在嵌入式AI领域,算力与功耗的平衡始终是核心挑战。Arm Ethos-U85 NPU的诞生,为Cortex-M/A系列处理器提供了专用的神经网络加速方案。这款NPU采用独特的微架构设计,支持TOSA标准指令…...

【DeepSeek Chat功能测试全链路指南】:20年AI工程师亲测的7大核心场景验证法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试的底层逻辑与验证哲学 DeepSeek Chat 的功能测试并非仅面向接口响应的“黑盒点击”,而是建立在模型行为可解释性、推理路径可追溯性与系统边界可控性三重基石之上的验…...

基于Claude的代码库感知工具:智能编程助手的设计与实战
1. 项目概述:当Claude遇上代码库,一个智能编程助手的诞生最近在GitHub上看到一个挺有意思的项目,叫openclaw-claude-code。光看名字,你可能会觉得这又是一个基于某个大语言模型的代码生成工具,但实际深入了解后&#x…...

零中频接收机技术演进与动态范围优化方案
1. 零中频接收机技术演进与核心挑战零中频架构(Zero-IF)在移动通信领域已发展超过二十年,最早可追溯至1990年代的GSM手机设计。这种直接将射频信号下变频至基带的技术,相比传统超外差架构省去了中频处理环节,理论上具有…...

Linux下Vivado安装卡死解决方案:手动配置与深度排查指南
1. 问题定位:为什么Vivado安装会“卡”在最后一步?如果你在Linux系统上安装Xilinx Vivado时,遇到了安装程序进度条走到最后,却迟迟不结束,甚至界面卡死、无响应的情况,先别急着砸键盘。这几乎是每一位从Win…...

基于MCP协议构建阿里云SLS日志AI查询助手:原理、部署与实战
1. 项目概述:当阿里云SLS遇上MCP如果你正在用阿里云日志服务(SLS)做日志分析,同时又想用上像Claude、Cursor这类AI编程助手来帮你写查询、分析数据,那你可能已经感受到了一个痛点:如何在AI助手和你的日志数…...

Git Common Errors
Git Common Errors 1. 这篇文章解决什么问题? Git 报错时,最容易让人慌的不是错误本身,而是不知道它在说哪一层出了问题。 常见错误包括: 1. not a git repository 2. remote origin already exists 3. failed to push some r…...

紫光Pango EDA工具链实战:从License申请到Synplify避坑,一个FPGA工程师的踩坑笔记
紫光Pango EDA工具链实战:从License申请到Synplify避坑指南 第一次接触紫光Pango工具链时,我像大多数FPGA工程师一样,以为这不过是又一个需要熟悉的开发环境。直到在项目deadline前三天,Synplify突然报出"exit code 4"错…...