【MYSQL】MYSQL 的学习教程(七)之 慢 SQL 优化思路
1. 慢 SQL 优化思路
- 慢查询日志记录慢 SQL
- explain 分析 SQL 的执行计划
- profile 分析执行耗时
- Optimizer Trace 分析详情
- 确定问题并采用相应的措施
1. 慢查询日志记录慢 SQL
如何定位慢SQL呢?
我们可以通过 慢查询日志 来查看慢 SQL。
①:开启慢查询日志:
SET global slow_query_log = ON;:设置慢查询开启的状态(ON:开启;OFF:关闭)slow_query_log_file:设置慢查询日志存放的位置SET global log_queries_not_using_indexes = ON;:记录没有使用索引的查询 SQL。前提是slow_query_log的值为 ON,否则不会奏效SET long_query_time = 10;:设置慢查询的阀值,单位秒。如果SQL执行时间超过阀值,就属于慢查询 记录到日志文件中
②:查看慢查询日志配置:
show variables like 'slow_query_log%show variables like 'long_query_time'
③:慢查询日志分析工具:
mysqldumpslow:该工具是慢查询自带的分析慢查询工具,一般只要安装了mysql,就会有该工具
# 取出使用最多的10条慢查询
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log
# 取出查询时间最慢的3条慢查询
mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log
# 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log
# 按照扫描行数最多的
mysqldumpslow -s r -t 10 -g 'left join' /var/run/mysqld/mysqld-slow.log
注意: 使用 mysqldumpslow 的分析结果不会显示具体完整的sql语句,只会显示sql的组成结构;
假如: SELECT * FROM sms_send WHERE service_id=10 GROUP BY content LIMIT 0, 1000;
Count: 1 Time=1.91s (1s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N;
工具其实还有很多,并不限制只有这一种,还有 pt-query-digest、mysqlsla 等,这些都是可以定位慢查询日志的小工具
慢查询原因:
- 全表扫描:explain分析type属性all
- 全索引扫描:explain分析type属性index
- 索引过滤性不好:靠索引字段选型、数据量和状态、表设计
- 频繁的回表查询开销:尽量少用select *,使用覆盖索引
<转>详解 慢查询 之 mysqldumpslow
2. explain 查看分析 SQL 的执行计划
当定位出查询效率低的 SQL 后,可以使用 explain 查看 SQL 的执行计划。
当 explain 与 SQL 一起使用时,MySQL 将显示来自优化器的有关语句执行计划的信息。即:MySQL 解释了它将如何处理该语句,包括有关如何连接表以及以何种顺序连接表等信息:

一般来说,我们需要重点关注 type、key、rows、extra
13.1 type
type 表示连接类型,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- NULL:表示不用访问表,速度最快
- system:这种类型要求数据库表中只有一条数据,是 const 类型的一个特例,一般情况下是不会出现的
- const:通过一次索引就能找到数据,一般用于主键或唯一索引作为条件,这类扫描效率极高,速度非常快
- eq_ref:常用于主键或唯一索引扫描,一般指使用主键的关联查询
- ref : 常用于非主键和唯一索引扫描
- ref_or_null:这种连接类型类似于 ref,区别在于 MySQL 会额外搜索包含 NULL 值的行
- index_merge:使用了索引合并优化方法,查询使用了两个以上的索引
- unique_subquery:类似于 eq_ref,条件用了 in 子查询
- index_subquery:区别于 unique_subquery,用于非唯一索引,可以返回重复值
- range:常用于范围查询,比如:between … and 或 In 等操作
- index:全索引扫描
- all:全表扫描
13.2 possible_keys
表示查询时能够使用到的索引(显示的是索引名称),只是可能用到的索引,而不是实际上用到的索引
13.3 key
该列表示实际用到的索引。一般配合 possible_keys 列一起看
13.4 rows
MySQL查询优化器会根据统计信息,估算 SQL 要查询到结果需要扫描多少行记录。原则上 rows 是越少效率越高,可以直观的了解到SQL效率高低
13.5 extra
该字段包含有关 MySQL 如何解析查询的其他信息,它一般会出现这几个值:
- Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于 order by 语句。建议优化
- Using temporary: 表示使用了临时表,性能特别差,需要重点优化。一般多见于 group by 语句,或者 union 语句
- Using index :表示用了覆盖索引
- Using where : 表示使用了 where 条件过滤,需要通过索引回表查询数据
- Using index condition:MySQL5.6 之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据
- NULL:查询的列未被索引覆盖
总结:
| extra | where 条件 | select 的字段 |
|---|---|---|
| null | where 筛选条件是索引的前导列 | 查询的列未被索引覆盖 |
| Using index | where 筛选条件是索引的前导列 | 查询的列被索引覆盖 |
| Using where; Using index | where 筛选条件是索引列之一但不是前导列或者where筛选条件是索引列前导列的一个范围 | 查询的列被索引覆盖 |
| Using where; | where 筛选条件不是索引列 | - |
| Using where; | where 筛选条件不是索引前导列、是索引列前导列的一个范围(>) | 查询列未被索引覆盖 |
| Using index condition | where 索引列前导列的一个范围(<、between) | 查询列未被索引覆盖 |
两种排序的情况:
| extra | 出现场景 |
|---|---|
| Using filesort | filesort主要用于查询数据结果集的排序操作,首先MySQL会使用sort_buffer_size大小的内存进行排序,如果结果集超过了sort_buffer_size大小,会把这一个排序后的chunk转移到file上,最后使用多路归并排序完成所有数据的排序操作。 |
| Using temporary | MySQL使用临时表保存临时的结构,以用于后续的处理,MySQL首先创建heap引擎的临时表,如果临时的数据过多,超过max_heap_table_size的大小,会自动把临时表转换成MyISAM引擎的表来使用。 |
filesort 只能应用在单个表上,如果有多个表的数据需要排序,那么MySQL会先使用using temporary保存临时数据,然后再在临时表上使用filesort进行排序,最后输出结果
13.6 select_type
select_type:表示查询的类型。
常用的值如下:
- SIMPLE : 表示查询语句不包含子查询或 UNION
- PRIMARY:表示此查询是最外层的查询
- UNION:表示此查询是 UNION 的第二个或后续的查询
- DEPENDENT UNION:UNION 中的第二个或后续的查询语句,使用了外面查询结果
- UNION RESULT:UNION 的结果
- SUBQUERY:SELECT 子查询语句
- DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果
最常见的查询类型是 SIMPLE,表示我们的查询没有子查询也没用到 UNION 查询
13.7 filtered
该列是一个百分比的值,通过查询条件最终查询记录行数和通过 type 字段扫描记录行数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例
13.8 key_len
表示查询使用了索引的字节数量(可以判断是否全部使用了组合索引)
key_len的计算规则如下:
- 字符串类型:字符串长度跟字符集有关:latin1 = 1、gbk = 2、utf8 = 3、utf8mb4 = 4
char(n):n * 字符集长度varchar(n):n * 字符集长度 + 2字节
- 数值类型
TINYINT:1个字节SMALLINT:2个字节MEDIUMINT:3个字节INT、FLOAT:4个字节BIGINT、DOUBLE:8个字节
- 时间类型
DATE:3个字节TIMESTAMP:4个字节DATETIME:8个字节
- 字段属性
- NULL 属性占用1个字节,如果一个字段设置了 NOT NULL,则没有此项
3. profile 分析执行耗时
explain 只是看到 SQL 的预估执行计划,如果要了解 SQL 真正的执行线程状态及消耗的时间,需要使用 profiling
开启 profiling 参数后,后续执行的 SQL 语句都会记录其资源开销,包括 IO,上下文切换,CPU,内存等等,我们可以根据这些开销进一步分析当前慢 SQL 的瓶颈再进一步进行优化
查看是否开启 profiling:
show variables like '%profil%'
开启 profiling :
set profiling=ON
使用 profiling :
show profiles
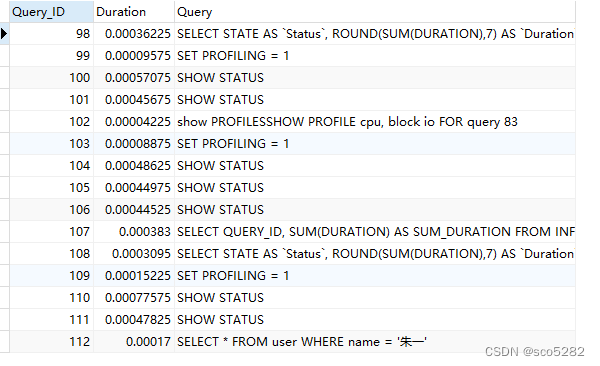
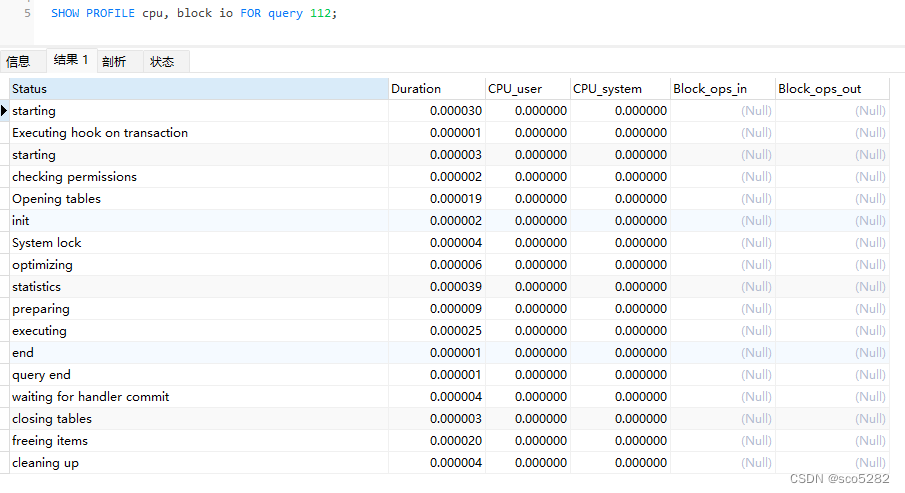
show profiles 会显示最近发给服务器的多条语句,条数由变量 profiling_history_size 定义,默认是 15。如果我们需要看单独某条 SQL 的分析,可以 show profile 查看最近一条 SQL 的分析,也可以使用 show profile for query id(其中id就是show profiles中的 QUERY_ID)查看具体一条的 SQL 语句分析:
4. Optimizer Trace 分析详情
profile 只能查看到 SQL 的执行耗时,但是无法看到 SQL 真正执行的过程信息,即不知道 MySQL 优化器是如何选择执行计划。这时候,我们可以使用 Optimizer Trace,它可以跟踪执行语句的解析优化执行的全过程
开启:
set optimizer_trace="enabled=on";
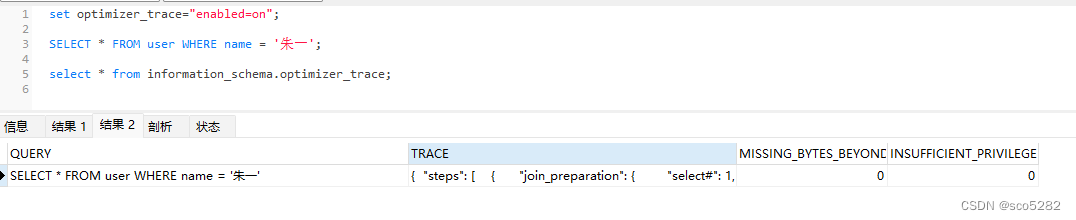
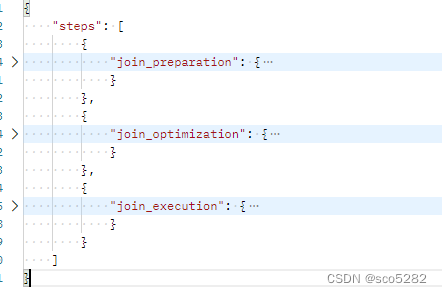
查看分析其执行树,会包括三个阶段:
- join_preparation:准备阶段
- join_optimization:分析阶段
- join_execution:执行阶段
5. 确定问题并采用相应的措施
确认问题,就采取对应的措施。
- 多数慢 SQL 都跟索引有关,比如不加索引,索引不生效、不合理等,这时候,我们可以优化索引
- 我们还可以优化 SQL 语句,比如一些in元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询
- SQL 没办法很好优化,可以改用 ES 的方式,或者数仓
- 如果单表数据量过大导致慢查询,则可以考虑分库分表
- 如果数据库在刷脏页导致慢查询,考虑是否可以优化一些参数,跟 DBA 讨论优化方案
- 如果存量数据量太大,考虑是否可以让部分数据归档
相关文章:
【MYSQL】MYSQL 的学习教程(七)之 慢 SQL 优化思路
1. 慢 SQL 优化思路 慢查询日志记录慢 SQLexplain 分析 SQL 的执行计划profile 分析执行耗时Optimizer Trace 分析详情确定问题并采用相应的措施 1. 慢查询日志记录慢 SQL 如何定位慢SQL呢? 我们可以通过 慢查询日志 来查看慢 SQL。 ①:开启慢查询日志…...
unity学习笔记----游戏练习0
一、修复植物种植的问题 1.当手上存在植物时,再次点击卡片上的植物就会在手上添加新的植物,需要修改成只有手上没有植物时才能再次获取到植物。需要修改AddPlant方法。 public bool AddPlant(PlantType plantType) { //防止手上出现多个植…...

ai概念:强人工智能介绍、迁移学习
强人工智能(Strong Artificial Intelligence,SAI)是指一种具有与人类智能相媲美或超越人类智能水平的人工智能系统。与弱人工智能(Weak Artificial Intelligence,WAI)不同,强人工智能具有更高级…...

go语言设计模式-单例模式
建造型设计模式-单例模式 是用来控制类型实例的数量的,当需要确保一个类型只有一个实例时,就需要使用单例模式。 即把实例的访问进行收口,不能谁都能 new 类,所以单例模式还会提供一个2访问该实例的全局端口,一般都会…...
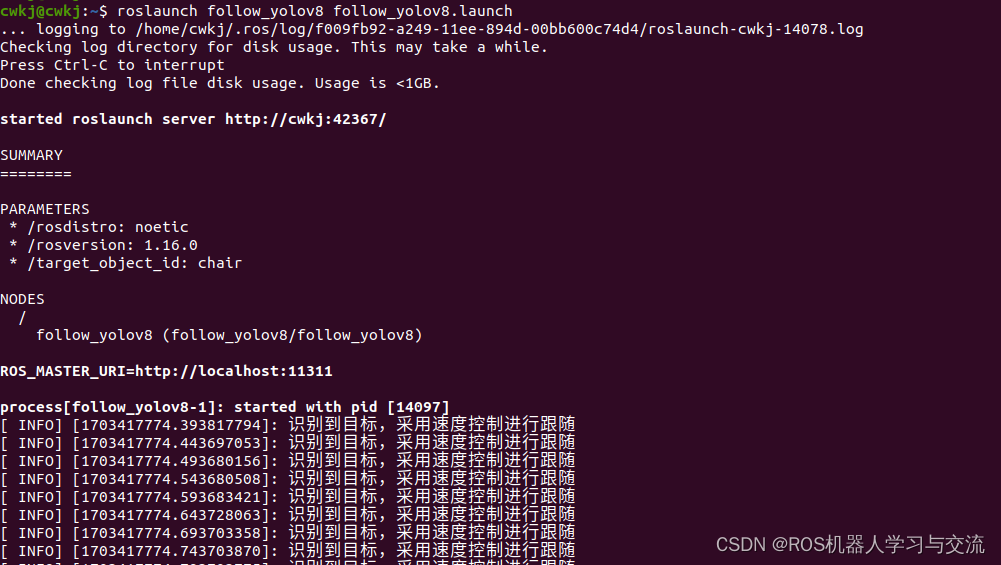
超维空间S2无人机使用说明书——51、基础版——使用yolov8进行目标跟踪
引言:为了提高yolo识别的质量,提高了yolo的版本,改用yolov8进行物体识别,同时系统兼容了低版本的yolo,包括基于C的yolov3和yolov4,以及yolov7。 简介,为了提高识别速度,系统采用了G…...

Transformer(seq2seq、self-attention)学习笔记
在self-attention 基础上记录一篇Transformer学习笔记 Transformer的网络结构EncoderDecoder 模型训练与评估 Transformer的网络结构 Transformer是一种seq2seq 模型。输入一个序列,经过encoder、decoder输出结果也是一个序列,输出序列的长度由模型决定…...
2023-12-29 服务器开发-centos部署ftp
摘要: 2023-12-29 服务器开发-centos-部署ftp 部署ftp vsftpd(very secure FTP daemon)是Linux下的一款小巧轻快、安全易用的FTP服务器软件。本教程介绍如何在Linux实例上安装并配置vsftpd。 前提条件 已创建ECS实例并为实例分配了公网IP地址。 背景…...
C卷 (JavaPythonNode.jsC语言C++))
螺旋数字阵(100%用例)C卷 (JavaPythonNode.jsC语言C++)
疫情期间,小明隔离在家,百无聊赖,在纸上写数字玩。他发明了一种写法: 给出数字个数n和行数m (0 < n <= 999,0 < m <= 999) ,从左上角的1开始,按照顺时针螺旋向内写方式,依次写出2,3...n,最终形成一个m行矩阵 小明对这个矩阵有些要求 1.每行数字的个数一样多…...
(二))
AUTOSAR从入门到精通-网络通信(UDPNm)(二)
目录 前言 原理 UdpNm工作原理 UdpNm与CanNM的区别联系 网络管理算法...
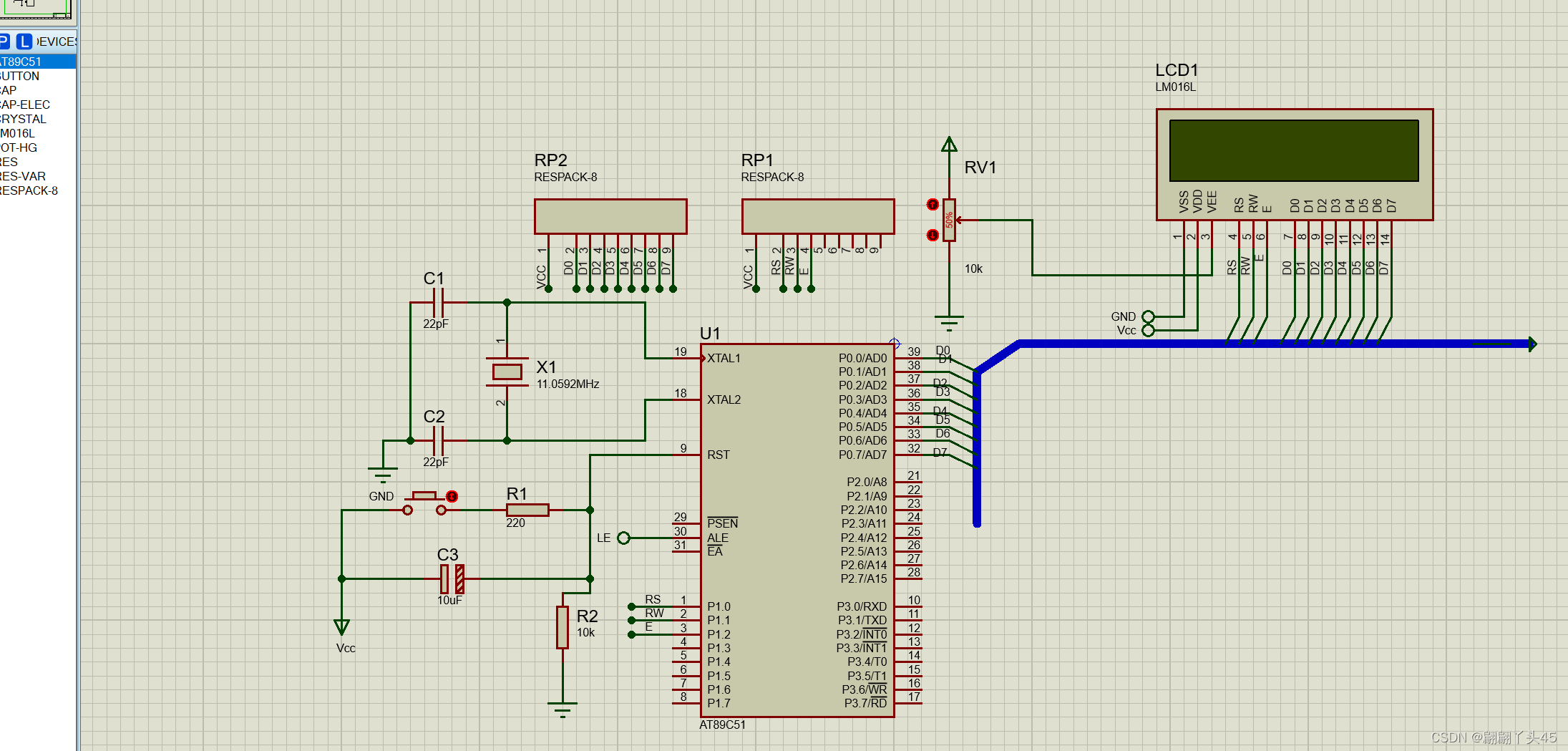
显示器与按键(LCD 1602 + button)
一、实验目的: (1)学习lcd 1602的编程与使用、 (2)机械式复位开关button软件消抖的方法。 二、实验内容: 1、必做:先显示开机画面,:在1602显示器上,分两行…...

2020年认证杯SPSSPRO杯数学建模B题(第一阶段)分布式无线广播全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 B题 分布式无线广播 原题再现: 以广播的方式来进行无线网通信,必须解决发送互相冲突的问题。无线网的许多基础通信协议都使用了令牌的方法来解决这个问题,在同一个时间段内,只有唯一一个拿到令牌…...

【CISSP学习笔记】7. 安全评估与测试
该知识领域涉及如下考点,具体内容分布于如下各个子章节: 设计和验证评估、测试和审计策略进行安全控制测试收集安全过程数据(例如,技术和管理)分析测试输出并生成报告执行或协助安全审计 7.1. 构建安全评估和测试方案…...
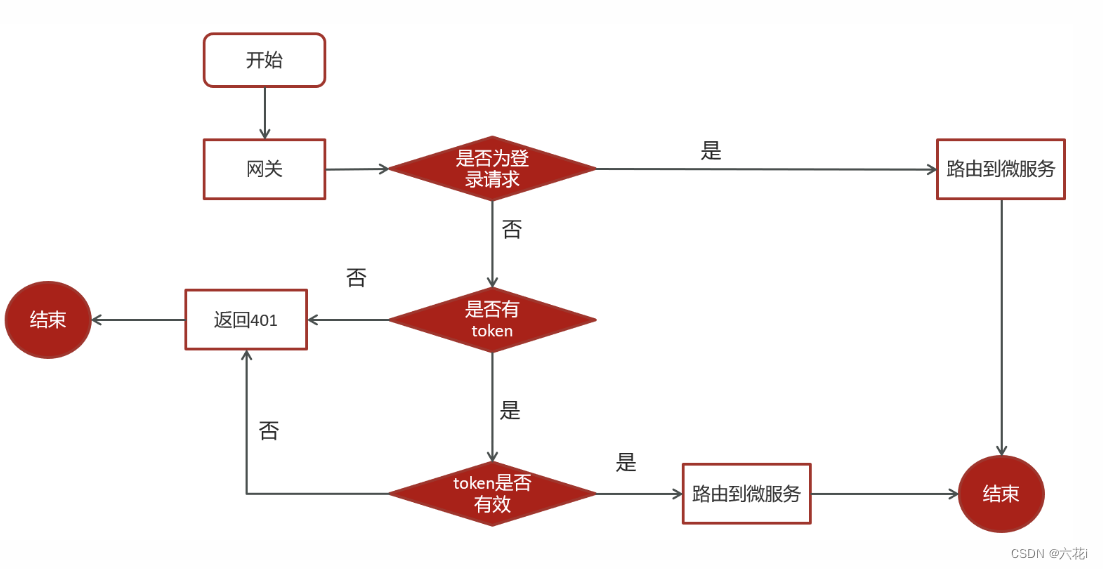
Gateway集成方法以及拦截器和过滤器的使用
前提:请先创建好一个SpringBoot项目 1. 引入依赖 SpringCloud 和 alibabaCloud 、 SpringBoot间对版本有强制要求,我使用的springboot是3.0.2的版本。版本对应关系请看:版本说明 alibaba/spring-cloud-alibaba Wiki GitHub <dependency…...

第G2周:人脸图像生成(DCGAN)
🍨 本文为[🔗365天深度学习训练营学习记录博客\n🍦 参考文章:365天深度学习训练营\n🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.co…...

【Web】Ctfshow Thinkphp5 非强制路由RCE漏洞
目录 非强制路由RCE漏洞 web579 web604 web605 web606 web607-610 前面审了一些tp3的sql注入,终于到tp5了,要说tp5那最经典的还得是rce 下面介绍非强制路由RCE漏洞 非强制路由RCE漏洞原理 非强制路由相当于开了一个大口子,可以任意调用当前框…...

python3遇到Can‘t connect to HTTPS URL because the SSL module is not available.
远程服务器centos7系统上有minicoda3,觉得太占空间,就把整个文件夹删了,原先的Python3也没了,都要重装。 我自己的步骤:进入管理员模式 1.下载Python3的源码: wget https://www.python.org/ftp/python/3.1…...

QSPI Flash xip取指同时program过程中概率性出现usb播歌时断音
项目场景: USB Audio芯片,代码放到qspi flash中,执行代码时,客户会偶尔保存一些参数,即FPGA验证过程中,每隔10ms向flash info区烧写4个byte(取指过程一直存在,且时隙软件不可控&…...

MySQL聚簇索引和非聚簇索引的区别
前言: 聚簇索引和非聚簇索引是数据库中的两种索引类型,他们在组织和存储数据时有不同的方式。 聚簇索引: 简单理解,就是将数据和索引放在了一起,找到了索引也就找到了数据。对于聚簇索引来说,他的非叶子节点上存储的是…...

【C#】蜗牛爬井问题C#控制台实现
文章目录 一、问题描述二、C#控制台代码 一、问题描述 井深30米,蜗牛在井底,每天爬3米又滑下1米,问第几天爬出来 二、C#控制台代码 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System…...

IP地址的四大类型:动态IP、固定IP、实体IP、虚拟IP的区别与应用
在网络通信中,IP地址是设备在互联网上唯一标识的关键元素。动态IP、固定IP、实体IP和虚拟IP是四种不同类型的IP地址,它们各自具有独特的特点和应用场景。 1. 动态IP地址: 动态IP地址是由Internet Service Provider(ISPÿ…...

SMP架构下RTOS裸机启动的核心挑战与优化策略
1. SMP RTOS裸机启动的核心挑战在嵌入式系统领域,对称多处理(SMP)架构正逐渐成为高性能计算的主流选择。作为一名长期从事嵌入式系统开发的工程师,我见证了从单核到多核系统的演进过程。与传统的单核系统相比,SMP架构下…...

开源AR虚拟试衣项目openclaw-genpark-ar-tryon核心技术解析与实践
1. 项目概述:当AR试衣遇见开源社区最近在逛GitHub的时候,偶然发现了一个挺有意思的项目,叫openclaw-genpark-ar-tryon。光看名字,一股浓浓的“开源”和“增强现实”味儿就扑面而来了。点进去一看,果然,这是…...

5大实战技巧:深度掌握PyQt6桌面应用开发
5大实战技巧:深度掌握PyQt6桌面应用开发 【免费下载链接】PyQt-Chinese-tutorial PyQt6中文教程 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Chinese-tutorial 在Python生态中,PyQt6作为最强大的GUI开发框架,为开发者提供了创…...

Arm调试寄存器架构详解与应用实践
1. Arm调试寄存器架构概述在Armv8/v9处理器架构中,调试寄存器是实现硬件级调试功能的核心组件。这些寄存器通过外部调试接口(External Debug Interface)为开发人员提供了对处理器内部状态的访问和控制能力。调试寄存器主要分为两类࿱…...

基于NestJS的上下文管理:从AsyncLocalStorage到微服务架构实践
1. 项目概述:从“Nest Hub”到“contextzero/nest_hub”的深度解构最近在逛一些开发者社区和开源项目托管平台时,我注意到一个挺有意思的现象:一个名为“contextzero/nest_hub”的项目开始在一些技术讨论中被提及。乍一看标题,很多…...

SEM轮廓技术在22nm以下OPC建模中的创新应用
1. SEM轮廓技术在OPC建模中的革命性突破在22nm及以下节点的半导体制造工艺中,光学邻近效应校正(OPC)面临着前所未有的挑战。传统基于CD(临界尺寸)测量的建模方法在应对复杂2D结构时显得力不从心,特别是在处…...

教育科技产品集成AI答疑功能的技术方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育科技产品集成AI答疑功能的技术方案与接入实践 在在线教育领域,为学生提供即时、准确的答疑服务是提升学习体验和效…...

通过API Key管理与审计日志功能增强企业AI应用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过API Key管理与审计日志功能增强企业AI应用安全 在将大模型能力集成到企业业务流程时,安全与合规是首要考量。直接使…...

构建本地化X内容智能引擎:从数据捕获到AI辅助创作的全流程实践
1. 项目概述:打造你的本地X内容智能引擎 如果你和我一样,每天花大量时间在X(原Twitter)上,不是为了刷屏,而是为了工作——寻找灵感、分析趋势、构思内容,那你一定体会过那种“信息过载”与“灵…...

SBQE:量子机器学习数据编码的创新方法
1. SBQE:量子机器学习数据编码的新范式量子计算领域最近迎来了一项突破性进展——SBQE(Shot-Based Quantum Encoding)数据编码方法。作为一名长期跟踪量子机器学习发展的研究者,我亲历了这项技术从理论提出到实验验证的全过程。SB…...