postgreSQL单机部署
一、环境准备
| 架构 | 操作系统 | IP | 主机名 | PG版本 | 端口 | 磁盘空间 | 内存 | CPU |
|---|---|---|---|---|---|---|---|---|
| single 单机 | centos7 | 192.168.1.10 | pgserver01 | PostgreSQL 14.7 | 5433 | 50G | 4G | 2 |
1、官网下载源码包
https://www.postgresql.org/download/
2、操作系统参数修改
2.1 sysctl.conf配置
vi /etc/sysctl.conf
kernel.sysrq = 1
#basic setting
#net.ipv6.conf.all.disable_ipv6 = 1
#net.ipv6.conf.default.disable_ipv6 = 1
kernel.pid_max = 524288
fs.file-max = 76724200
fs.aio-max-nr = 40960000
kernel.sem = 10000 10240000 10000 1024
net.ipv4.ip_local_port_range = 9000 65000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
#net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_retries2 = 5
net.core.rmem_default = 262144
net.core.rmem_max = 16777216
net.core.wmem_default = 262144
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_max_syn_backlog = 8192
net.core.somaxconn = 4096
net.core.netdev_max_backlog = 3000
vm.swappiness = 10
kernel.shmmni = 4096
kernel.shmmax = 1930648
kernel.shmall = 471
vm.dirty_ratio=20
vm.dirty_background_ratio=3
vm.dirty_writeback_centisecs=100
vm.dirty_expire_centisecs=500
vm.min_free_kbytes=524288
sysctl -p 生效配置
注意:
设置最大内存共享段大小bytes kernel.shmmax设置为内存的一半。
kernel.shmall设置为 kernel.shmmax/page_size
在操作系统执行getconf PAGESIZE可以获取,一般为4096
[root@pgserver01 ~]# cat /proc/meminfo | grep MemTotal
MemTotal: 3861296 kB
[root@pgserver01 ~]# bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty’.
3861296/2
1930648
[root@pgserver01 ~]# getconf PAGESIZE
4096
[root@pgserver01 ~]# bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty’.
1930648/4096
471
2.2 用户limits配置
vi /etc/security/limits.conf
将以下内容添加到文件尾部
postgres soft nofile 1048576
postgres hard nofile 1048576
postgres soft nproc 131072
postgres hard nproc 131072
postgres soft stack 10240
postgres hard stack 32768
postgres soft core 6291456
postgres hard core 6291456
postgres soft memlock -1
postgres hard memlock -1
2.3 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2.4 创建组、用户、目录
groupadd -g 3001 postgres
useradd -u 3001 -g postgres postgres
mkdir -p /data/{pgsql,soft,repmgr}
mkdir -p /data/pgsql/install
mkdir -p /data/pgsql/data
mkdir -p /data/pgsql/archive
二、开始部署PG单机环境
1、安装依赖包
yum -y install openssl-devel libxml2-devel libxslt-devel python-devel cmake gcc-c++ \
zlib-devel bzip2 readline-devel expect git uuid-devel systemd-devel gcc automake autoconf libtool make vim wget bison flex
注意:
安装完成需要确认下是否安装了这个包:rpm -qa|grep uuid-devel 如果安装后有,则不需要手动安装了。
下面这个包系统自带,所以无需手工安装了
# wget http://mirror.centos.org/centos/7/os/x86_64/Packages/uuid-devel-1.6.2-26.el7.x86_64.rpm
#rpm -ivh uuid-devel-1.6.2-26.el7.x86_64.rpm
2、 解压软件包
tar -zxvf /data/soft/postgresql-14.7.tar.gz -C /data/pgsql/install/
2.1 编译安装
[root@pgserver01 soft]# cd /data/pgsql/install/postgresql-14.7/
[root@pgserver01 postgresql-14.7]# ./configure --prefix=/data/pgsql/install \--with-openssl \--disable-float4-byval \--disable-float8-byval \--with-libxml \--with-libxslt \--with-ossp-uuid \--with-systemd
注意
编译14.3版本时候会报错
configure: WARNING: unrecognized options: --disable-float4-byval, --disable-float8-byval
2.2 重新编译
[root@pgserver01 postgresql-14.7]# ./configure --prefix=/data/pgsql/install \--with-openssl \--with-libxml \--with-libxslt \--with-ossp-uuid \--with-systemd
[root@pgserver01 postgresql-14.7]# gmake world
多核可以开启并行 gmake world -j4
3、编译完成后进行安装
[root@pgserver01 postgresql-14.7]# gmake install-world
4、查看版本
[root@pgserver01 postgresql-14.7]# /data/pgsql/install/bin/postgres --version
postgres (PostgreSQL) 14.7
5、目录授权
[root@pgserver01 postgresql-14.7]# chown -R postgres:postgres /data
[root@pgserver01 postgresql-14.7]# chmod -R 755 /data
6、数据库初始化
/data/pgsql/install/bin/initdb --wal-segsize=256 -D /data/pgsql/data
-E UTF8 --locale=en_US.utf8 -U postgres -W
–wal-segsize=256 指定了单个wal日志的大小,单位MB。 提示输入密码时,可先设置为空,回车即可
[postgres@pgserver01 ~]$ su - postgres
[postgres@pgserver01 ~]$ /data/pgsql/install/bin/initdb --wal-segsize=256 -D /data/pgsql/data -E UTF8 --locale=en_US.utf8 -U postgres -W
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.The database cluster will be initialized with locale "en_US.utf8".
The default text search configuration will be set to "english".Data page checksums are disabled.Enter new superuser password:
Enter it again:fixing permissions on existing directory /data/pgsql/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Asia/Shanghai
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... okinitdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.Success. You can now start the database server using:/data/pgsql/install/bin/pg_ctl -D /data/pgsql/data -l logfile start
7、启动/关闭命令
[postgres@pgserver01 ~]$ /data/pgsql/install/bin/pg_ctl -D /data/pgsql/data -l logfile start
waiting for server to start.... done
server started
[postgres@pgserver01 ~]$ /data/pgsql/install/bin/pg_ctl stop -D /data/pgsql/data
waiting for server to shut down.... done
server stopped
8、环境变量配置
将以下内容添加到bash_profile文件中,(删除文件中原来的“export PATH”一行内容)
su - postgres
vi ~/.bash_profile
#export PATH
export PGPORT=5433
export PGUSER=postgres
export PGHOST=127.0.0.1
export PGHOME=/data/pgsql/install
export PGDATA=/data/pgsql/data
export MANPATH=$PGHOME/share/man:$MANPATH
export LD_LIBRARY_PATH=$PGHOME/lib
export PATH=$PGHOME/bin:$PATH
export PGPASSFILE=/home/postgres/.pgpass
生效
source ~/.bash_profile
9、登录验证
环境变量配置完成后可以直接用 pg_ctl 命令启停数据库
[postgres@pgserver01 ~]$ pg_ctl start
waiting for server to start....2023-12-25 14:54:51.528 CST [33983] LOG: starting PostgreSQL 14.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
2023-12-25 14:54:51.529 CST [33983] LOG: listening on IPv6 address "::1", port 5433
2023-12-25 14:54:51.529 CST [33983] LOG: listening on IPv4 address "127.0.0.1", port 5433
2023-12-25 14:54:51.529 CST [33983] LOG: listening on Unix socket "/tmp/.s.PGSQL.5433"
2023-12-25 14:54:51.530 CST [33984] LOG: database system was shut down at 2023-12-25 14:49:31 CST
2023-12-25 14:54:51.533 CST [33983] LOG: database system is ready to accept connectionsdone
server started
[postgres@pgserver01 ~]$ psql
psql (14.7)
Type "help" for help.postgres=# select version();version
---------------------------------------------------------------------------------------------------------PostgreSQL 14.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
(1 row)postgres=#
10、配置参数文件 postgres.conf、pg_hba.conf
修改参数文件需要先停库
[postgres@pgserver01 pgsql]$ pg_ctl stop
waiting for server to shut down....2023-12-25 15:26:24.546 CST [33983] LOG: received fast shutdown request
2023-12-25 15:26:24.547 CST [33983] LOG: aborting any active transactions
2023-12-25 15:26:24.548 CST [33983] LOG: background worker "logical replication launcher" (PID 33990) exited with exit code 1
2023-12-25 15:26:24.548 CST [33985] LOG: shutting down
2023-12-25 15:26:24.552 CST [33983] LOG: database system is shut downdone
server stopped其中以下参数需要根据机器配置和项目修改 :
cluster_name=‘repmgr01’ #实例名称
port=5433 shared_buffers=4GB # 物理内存的1/4
effective_cache_size=12GB # 调整为与内存一样大, 或者略小(减去shared_buffer)
vi /data/pgsql/data/postgres.conf
#-------------------------------------------
# 一、连接认证 CONNECTIONS AND AUTHENTICATION
#-------------------------------------------#若要允许其他IP地址访问该主机数据库,则必须listen_addresses为*
listen_addresses = '*'
port = 5433
cluster_name = 'node01'
max_connections = 3000
superuser_reserved_connections = 20
unix_socket_directories = '.'
unix_socket_permissions = 0700
#bonjour = off
#bonjour_name = ''
idle_session_timeout=300000
# - TCP settings -
tcp_keepalives_idle = 30 #51cto:60
tcp_keepalives_interval = 10 #51cto:10
tcp_keepalives_count = 10 #51cto:6
#tcp_user_timeout = 0# - Authentication -
#authentication_timeout = 1min # 1s-600s
#password_encryption = md5 #默认为md5加密,
#db_user_namespace = off# GSSAPI using Kerberos
#krb_server_keyfile = 'FILE:${sysconfdir}/krb5.keytab'
#krb_caseins_users = off# - SSL -
#ssl = off
#ssl_ca_file = ''
#ssl_cert_file = 'server.crt'
#ssl_crl_file = ''
#ssl_key_file = 'server.key'
#ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers
#ssl_prefer_server_ciphers = on
#ssl_ecdh_curve = 'prime256v1'
#ssl_min_protocol_version = 'TLSv1'
#ssl_max_protocol_version = ''
#ssl_dh_params_file = ''
#ssl_passphrase_command = ''
#ssl_passphrase_command_supports_reload = off#----------------------------------------
# 二、资源使用 RESOURCE USAGE (except WAL)
#----------------------------------------# - Memory -
shared_buffers = 1GB # 物理内存的1/4
#huge_pages = try # on, off, or try
#temp_buffers = 8MB #保持默认
work_mem = 32MB #建议32M或者64M
maintenance_work_mem = 512MB #索引维护或者ddl时用到,建议512M或者1G
autovacuum_work_mem = 512MB
#max_stack_depth = 2MB # min 100kB# - Disk -
#temp_file_limit = -1 # limits per-process temp file space# in kB, or -1 for no limit
# - Kernel Resources -
#max_files_per_process = 1000 # min 25# - Cost-Based Vacuum Delay -
#vacuum_cost_delay = 0 # 0-100 milliseconds (0 disables)
#vacuum_cost_page_hit = 1 # 0-10000 credits
#vacuum_cost_page_miss = 10 # 0-10000 credits
#vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 credits# - Background Writer -
bgwriter_delay = 10ms # 10-10000ms,默认200ms,
bgwriter_lru_maxpages = 1000 # 默认100,
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disables# - Asynchronous Behavior -
#effective_io_concurrency = 1 # 1-1000; 0 disables prefetching
max_worker_processes = 20 #默认8,性能不足时增加
#max_parallel_maintenance_workers = 2 # taken from max_parallel_workers
#max_parallel_workers_per_gather = 2 # taken from max_parallel_workers
#parallel_leader_participation = on
#max_parallel_workers = 8 # maximum number of max_worker_processes that# can be used in parallel operations
#old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate
#backend_flush_after = 0 # measured in pages, 0 disables#--------------------------
# 三、WAL(WRITE-AHEAD LOG)
#--------------------------# - Settings -
wal_level = logical # 默认replica,修改为logical,便于逻辑复制
#fsync = on
synchronous_commit = off # off,local,remote_write, or on
wal_sync_method = open_datasync # 使用pg_test_fsync测试wal所在磁盘的fsync接口, ���用性能好的。默认值为fsync,后期在关注。
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
wal_log_hints = on # 默认off,# (change requires restart)
#wal_init_zero = on # zero-fill new WAL files
#wal_recycle = on # recycle WAL files
wal_buffers = 16MB # -1 sets based on shared_buffers# (change requires restart)
wal_writer_delay = 10ms # 默认200ms
#wal_writer_flush_after = 1MB # measured in pages, 0 disables#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000# - Checkpoints -
checkpoint_timeout = 20min # range 30s-1d,默认5min,
max_wal_size = 2GB #最大保留的wal文件,51cto建议10GB
min_wal_size = 512MB
checkpoint_completion_target = 0.8 # 默认0.5,日志文件达到1GB*0.8时触发checkpoint。即max_wal_size * checkpoint_completion_target的值
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables# - Archiving -
#archive_mode = on
#archive_command = '/bin/true'
#archive_timeout = 0# - Archive Recovery -
#restore_command = '' # command to use to restore an archived
#archive_cleanup_command = '' # command to execute at every restartpoint
#recovery_end_command = '' # command to execute at completion of recovery# - Recovery Target -# Set these only when performing a targeted recovery.#recovery_target = '' # 'immediate' to end recovery as soon as a# consistent state is reached# (change requires restart)
#recovery_target_name = '' # the named restore point to which recovery will proceed# (change requires restart)
#recovery_target_time = '' # the time stamp up to which recovery will proceed# (change requires restart)
#recovery_target_xid = '' # the transaction ID up to which recovery will proceed# (change requires restart)
#recovery_target_lsn = '' # the WAL LSN up to which recovery will proceed# (change requires restart)
#recovery_target_inclusive = on # Specifies whether to stop:# just after the specified recovery target (on)# just before the recovery target (off)# (change requires restart)
#recovery_target_timeline = 'latest' # 'current', 'latest', or timeline ID# (change requires restart)
#recovery_target_action = 'pause' # 'pause', 'promote', 'shutdown'# (change requires restart)#---------------------
# 四、复制 REPLICATION
#---------------------# - Sending Servers -
# Set these on the master and on any standby that will send replication data.max_wal_senders = 32 # 默认10
wal_keep_size=20000 #所有redo文件总大小设置为20G
#wal_sender_timeout = 60s # in milliseconds; 0 disables
max_replication_slots = 32 # 默认10,逻辑复制相关
#track_commit_timestamp = off # collect timestamp of transaction commit# - Master Server - 主库
# These settings are ignored on a standby server.synchronous_standby_names = '*'
#vacuum_defer_cleanup_age = 0 #默认0# - Standby Servers - 从库
# These settings are ignored on a master server.#primary_conninfo = '' # connection string to sending server
#primary_slot_name = '' # replication slot on sending server
#promote_trigger_file = ''
#hot_standby = on #默认开启,
max_standby_archive_delay = 300s #默认30s,
max_standby_streaming_delay = 300s #默认30s,
wal_receiver_status_interval = 1s #默认10s,
hot_standby_feedback = on
#以上参数的意义,从库在执行一个大查询时,主库突然在该表执行delete,此时从库会发现事务ID给主库,master延迟进行autocuum操作。
#wal_receiver_timeout = 60s # time that receiver waits for# communication from master# in milliseconds; 0 disables
#wal_retrieve_retry_interval = 5s # time to wait before retrying to# retrieve WAL after a failed attempt
#recovery_min_apply_delay = 0 # minimum delay for applying changes during recovery# - Subscribers -
# These settings are ignored on a publisher.#max_logical_replication_workers = 4 # taken from max_worker_processes# (change requires restart)
#max_sync_workers_per_subscription = 2 # taken from max_logical_replication_workers#-------------------------
# 五、查询优化 QUERY TUNING
#-------------------------# - Planner Method Configuration -
#enable_bitmapscan = on
#enable_hashagg = on
#enable_hashjoin = on
#enable_indexscan = on
#enable_indexonlyscan = on
#enable_material = on
#enable_mergejoin = on
#enable_nestloop = on
#enable_parallel_append = on
#enable_seqscan = on
#enable_sort = on
#enable_tidscan = on
#enable_partitionwise_join = off
#enable_partitionwise_aggregate = off
#enable_parallel_hash = on
#enable_partition_pruning = on# - Planner Cost Constants -
#seq_page_cost = 1.0 # measured on an arbitrary scale
random_page_cost = 1.3 #默认4.0
#cpu_tuple_cost = 0.01 # same scale as above
#cpu_index_tuple_cost = 0.005 # same scale as above
#cpu_operator_cost = 0.0025 # same scale as above
#parallel_tuple_cost = 0.1 # same scale as above
#parallel_setup_cost = 1000.0 # same scale as above#jit_above_cost = 100000 # perform JIT compilation if available# and query more expensive than this;# -1 disables
#jit_inline_above_cost = 500000 # inline small functions if query is# more expensive than this; -1 disables
#jit_optimize_above_cost = 500000 # use expensive JIT optimizations if# query is more expensive than this;# -1 disables#min_parallel_table_scan_size = 8MB
#min_parallel_index_scan_size = 512kB
effective_cache_size = 4GB # 调整为与内存一样大, 或者略小(减去shared_buffer)# - Genetic Query Optimizer -
#geqo = on
#geqo_threshold = 12
#geqo_effort = 5 # range 1-10
#geqo_pool_size = 0 # selects default based on effort
#geqo_generations = 0 # selects default based on effort
#geqo_selection_bias = 2.0 # range 1.5-2.0
#geqo_seed = 0.0 # range 0.0-1.0# - Other Planner Options -
#default_statistics_target = 100 # range 1-10000
#constraint_exclusion = partition # on, off, or partition
#cursor_tuple_fraction = 0.1 # range 0.0-1.0
#from_collapse_limit = 8
#join_collapse_limit = 8 # 1 disables collapsing of explicit# JOIN clauses
#force_parallel_mode = off
#jit = on # allow JIT compilation
#plan_cache_mode = auto # auto, force_generic_plan or# force_custom_plan#---------------------------------------
# 六、错误报告和日志 REPORTING AND LOGGING
#---------------------------------------# - Where to Log -
log_destination = 'stderr' #默认stderr
logging_collector = on #默认off# These are only used if logging_collector is on:
#log_directory = 'log'
log_filename = 'postgresql-%a.log' #每天生成一个,保存最近7天的日志
#log_file_mode = 0600
log_truncate_on_rotation = on #默认off
log_rotation_age = 1d #日志文件每天截断一次
log_rotation_size = 0 #日志截断不限大小# These are relevant when logging to syslog:
#syslog_facility = 'LOCAL0'
#syslog_ident = 'postgres'
#syslog_sequence_numbers = on
#syslog_split_messages = on# This is only relevant when logging to eventlog (win32):
# (change requires restart)
#event_source = 'PostgreSQL'# - When to Log -
#log_min_messages = warning #info、warning、error
#log_min_error_statement = error #info、warning、error
log_min_duration_statement = 1000 #记录超过1s的慢日志,单位毫秒
#log_transaction_sample_rate = 0.0 # Fraction of transactions whose statements# are logged regardless of their duration. 1.0 logs all# statements from all transactions, 0.0 never logs.# - What to Log -
#debug_print_parse = off
#debug_print_rewritten = off
#debug_print_plan = off
#debug_pretty_print = on
log_checkpoints = on
log_connections = on
log_disconnections = on
#log_duration = off
log_error_verbosity = verbose # terse, default, or verbose messages
#log_hostname = off
#log_line_prefix = '%m [%p] ' #
log_lock_waits = on #记录锁等待
log_statement = 'ddl' # none, ddl, mod, all
#log_replication_commands = off
log_temp_files = 0
log_timezone = 'PRC'#-------------------------
# 七、运行统计 STATISTICS
#-------------------------# - Query and Index Statistics Collector -
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
track_activity_query_size = 2048 #默认为1024
#stats_temp_directory = 'pg_stat_tmp'# - Monitoring -
#log_parser_stats = off
#log_planner_stats = off
#log_executor_stats = off
#log_statement_stats = off#----------------
# 八、AUTOVACUUM
#----------------#autovacuum = on
log_autovacuum_min_duration = 0 # 默认-1,即关闭
autovacuum_max_workers = 10 #默认3
autovacuum_naptime = 30s #默认1min
#autovacuum_vacuum_threshold = 50 # min number of row updates before
#autovacuum_analyze_threshold = 50 # min number of row updates before
autovacuum_vacuum_scale_factor = 0.1 #默认0.2
autovacuum_analyze_scale_factor = 0.2 #默认0.1
autovacuum_freeze_max_age = 1600000000 #默认200000000
autovacuum_multixact_freeze_max_age = 1600000000 #默认400000000
#autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for# autovacuum, in milliseconds;# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for# autovacuum, -1 means use# vacuum_cost_limit#----------------------------------------------
# 九、客户端连接默认值 CLIENT CONNECTION DEFAULTS
#----------------------------------------------# - Statement Behavior -
#client_min_messages = notice # notice、warning、error
#search_path = '"$user", public' # schema names
#row_security = on
#default_tablespace = '' # a tablespace name, '' uses the default
#temp_tablespaces = '' # a list of tablespace names, '' uses# only default tablespace
#default_table_access_method = 'heap'
#check_function_bodies = on
#default_transaction_isolation = 'read committed'
#default_transaction_read_only = off
#default_transaction_deferrable = off
#session_replication_role = 'origin'
#statement_timeout = 0 # in milliseconds, 0 is disabled
#lock_timeout = 0 # in milliseconds, 0 is disabled
#idle_in_transaction_session_timeout = 0 # in milliseconds, 0 is disabled
#vacuum_freeze_min_age = 50000000
vacuum_freeze_table_age = 1500000000 #默认150000000
#vacuum_multixact_freeze_min_age = 5000000
vacuum_multixact_freeze_table_age = 1500000000 #默认150000000
#vacuum_cleanup_index_scale_factor = 0.1
#bytea_output = 'hex' # hex, escape
#xmlbinary = 'base64'
#xmloption = 'content'
#gin_fuzzy_search_limit = 0
#gin_pending_list_limit = 4MB# - Locale and Formatting -datestyle = 'iso, mdy'
#intervalstyle = 'postgres'
timezone = 'Asia/Shanghai' #默认PRC
#timezone_abbreviations = 'Default' # Select the set of available time zone# abbreviations. Currently, there are# Default# Australia (historical usage)# India# You can create your own file in# share/timezonesets/.
#extra_float_digits = 1 # min -15, max 3; any value >0 actually# selects precise output mode
#client_encoding = sql_ascii # actually, defaults to database# encoding# These settings are initialized by initdb, but they can be changed.
lc_messages = 'en_US.utf8' # locale for system error message# strings
lc_monetary = 'en_US.utf8' # locale for monetary formatting
lc_numeric = 'en_US.utf8' # locale for number formatting
lc_time = 'en_US.utf8' # locale for time formatting# default configuration for text search
default_text_search_config = 'pg_catalog.english'# - Shared Library Preloading -
# 第三方共享库,如repmgr
shared_preload_libraries = 'auth_delay,passwordcheck,pg_stat_statements,auto_explain'
#local_preload_libraries = ''
#session_preload_libraries = ''
#jit_provider = 'llvmjit' # JIT library to use# - Other Defaults -#dynamic_library_path = '$libdir'#---------------------------
# 十、锁管理 LOCK MANAGEMENT
#---------------------------#deadlock_timeout = 1s
#max_locks_per_transaction = 64 # min 10# (change requires restart)
#max_pred_locks_per_transaction = 64 # min 10# (change requires restart)
#max_pred_locks_per_relation = -2 # negative values mean# (max_pred_locks_per_transaction# / -max_pred_locks_per_relation) - 1
#max_pred_locks_per_page = 2 # min 0###第三方插件库
# pg_stat_statements SQL性能统计
shared_preload_libraries = 'passwordcheck,pg_stat_statements,auto_explain'#auto_explain模块记录慢日志,详细配置如下
auto_explain.log_min_duration = 5000
auto_explain.log_analyze = true
auto_explain.log_verbose = true
auto_explain.log_buffers = true
auto_explain.log_nested_statements = true################# 需要调整的参数 ###################
###基础配置
cluster_name='repmgr01' #实例名称
port=5433
shared_buffers=4GB # 物理内存的1/4
effective_cache_size=12GB # 调整为与内存一样大, 或者略小(减去shared_buffer)###流复制
archive_mode='on'
archive_command='test ! -f /data/pgsql/archive/%f && cp %p /data/pgsql/archive/%f'
restore_command='cp /data/pgsql/archive/%f %p'synchronous_commit=off # 异步流
recovery_target_timeline='latest' #存档中找到的最新时间轴
pg_hba.conf 文件
vi /data/pgsql/data/pg_hba.conf
......
#allow login ips
host all all 192.168.0.0/24 md5
#reject super user remote login
host all postgres 0.0.0.0/0 md5
10.1 pg 服务启动
[postgres@pgserver01 ~]$ pg_ctl start
waiting for server to start....2023-12-25 15:49:05.269 CST [34151] LOG: 00000: redirecting log output to logging collector process
2023-12-25 15:49:05.269 CST [34151] HINT: Future log output will appear in directory "log".
2023-12-25 15:49:05.269 CST [34151] LOCATION: SysLogger_Start, syslogger.c:674done
server started
10.2 查看实例进程
[postgres@pgserver01 ~]$ ps -aux | grep postgres
root 34127 0.0 0.0 192044 2460 pts/0 S 15:48 0:00 su - postgres
postgres 34128 0.0 0.0 115668 2140 pts/0 S 15:48 0:00 -bash
postgres 34151 0.0 5.3 4649140 208040 ? Ss 15:49 0:00 /data/pgsql/install/bin/postgres
postgres 34152 0.0 0.0 189100 1680 ? Ss 15:49 0:00 postgres: repmgr01: logger
postgres 34154 0.0 0.0 4649140 1732 ? Ss 15:49 0:00 postgres: repmgr01: checkpointer
postgres 34155 0.0 0.9 4649920 36536 ? Ss 15:49 0:00 postgres: repmgr01: background writer
postgres 34156 0.0 0.4 4649140 18052 ? Ss 15:49 0:00 postgres: repmgr01: walwriter
postgres 34157 0.0 0.0 4651884 2952 ? Ss 15:49 0:00 postgres: repmgr01: autovacuum launcher
postgres 34158 0.0 0.0 4649140 1732 ? Ss 15:49 0:00 postgres: repmgr01: archiver
postgres 34159 0.0 0.0 191360 1844 ? Ss 15:49 0:00 postgres: repmgr01: stats collector
postgres 34160 0.0 0.0 4651836 2488 ? Ss 15:49 0:00 postgres: repmgr01: logical replication launcher
postgres 34172 0.0 0.0 155448 1876 pts/0 R+ 15:53 0:00 ps -aux
postgres 34173 0.0 0.0 112828 992 pts/0 S+ 15:53 0:00 grep --color=auto postgres
10.3 超级用户登录
[postgres@pgserver01 ~]$ psql -U postgres -h 127.0.0.1 -p 5433
psql (14.7)
Type "help" for help.postgres=#
因为环境变量配置了 PGUSER=postgres, PGPORT=5433,PGHOST=127.0.0.1 ,所以可以使用下面命令登录
psql
10.4 登录验证
postgres=# select version();version
---------------------------------------------------------------------------------------------------------PostgreSQL 14.7 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
(1 row)postgres=# select current_date;current_date
--------------2023-12-25
(1 row)postgres=# select current_user;current_user
--------------postgres
(1 row)postgres=# show port;port
------5433
(1 row)postgres=# select * from pg_database;oid | datname | datdba | encoding | datcollate | datctype | datistemplate | datallowconn | datconnlimit | datlastsysoid | datfrozenxid | datminmxid | dattablespace | datacl-------+-----------+--------+----------+------------+------------+---------------+--------------+--------------+---------------+--------------+------------+---------------+----------------------------------
---13892 | postgres | 10 | 6 | en_US.utf8 | en_US.utf8 | f | t | -1 | 13891 | 727 | 1 | 1663 |1 | template1 | 10 | 6 | en_US.utf8 | en_US.utf8 | t | t | -1 | 13891 | 727 | 1 | 1663 | {=c/postgres,postgres=CTc/postgre
s}13891 | template0 | 10 | 6 | en_US.utf8 | en_US.utf8 | t | f | -1 | 13891 | 727 | 1 | 1663 | {=c/postgres,postgres=CTc/postgre
s}
(3 rows)10.5 创建数据库、表以及用户测试
postgres=# create database test;
CREATE DATABASE
postgres=# select datname from pg_database;datname
-----------postgrestesttemplate1template0
(4 rows)postgres=# \c test;
You are now connected to database "test" as user "postgres".
test=# create table testtbs(name varchar(30));
CREATE TABLE
test=# insert into testtbs values('测试');
INSERT 0 1
test=# select * from testtbs;name
------测试
(1 row)test=#
删除操作
test=# drop table testtbs;
DROP TABLE
test=# \c postgres;
You are now connected to database "postgres" as user "postgres".
postgres=# drop database test;
DROP DATABASE
postgres=# select datname from pg_database;datname
-----------postgrestemplate1template0
(3 rows)postgres=#
11、至此PG单机环境部署完成。
相关文章:

postgreSQL单机部署
一、环境准备 架构操作系统IP主机名PG版本端口磁盘空间内存CPUsingle 单机centos7192.168.1.10pgserver01PostgreSQL 14.7543350G4G2 1、官网下载源码包 https://www.postgresql.org/download/2、操作系统参数修改 2.1 sysctl.conf配置 vi /etc/sysctl.conf kernel.sysrq …...

思维逻辑题3
题目1: 如果所有A都是B,且某个对象是B,那么它一定是A吗? 答案:不一定,尽管所有A都是B,但还有其他的对象可能也是B。 题目2: 如果A和B都是真,那么以下哪个选项是真&…...

强大的音乐乐谱控件库
2023 Conmajia, 2018 Ajcek84 SN: 23C.1 本中文翻译已获原作者首肯。 简介 PSAM 控件库——波兰音乐文档系统——是用于显示、排版乐谱的强大 WinForm 库,包含用于绘制乐谱的名为 IncipitViewer 控件,乐谱内容可以从 MusicXml 文件读取,或者…...
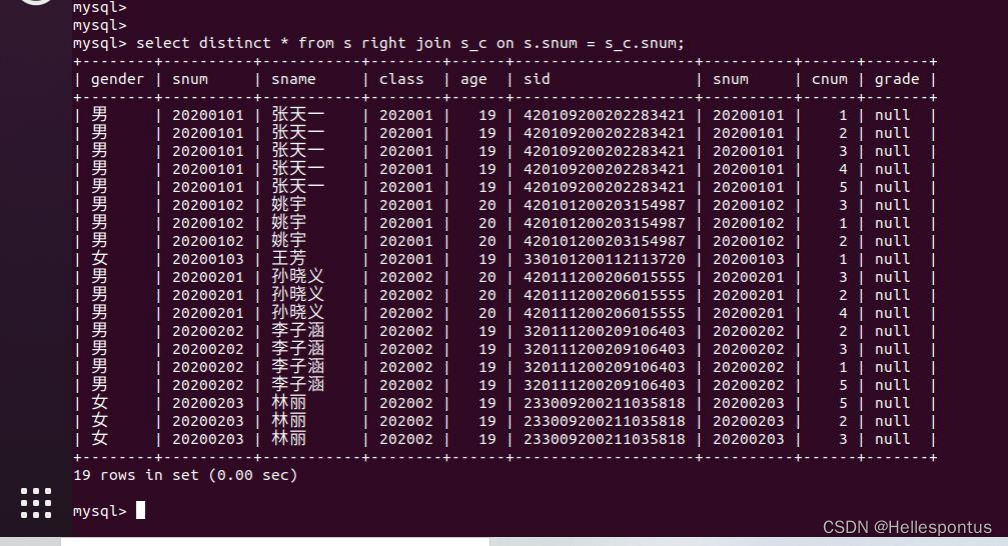
数据库——简单查询复杂查询
1.实验内容及原理 1. 在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,并在 Ubuntu 中搭建 LAMP 实验环境。 2. 使用 MySQL 进行一些基本操作: (1)登录 MySQL,在 MySQL 中创建用户,…...
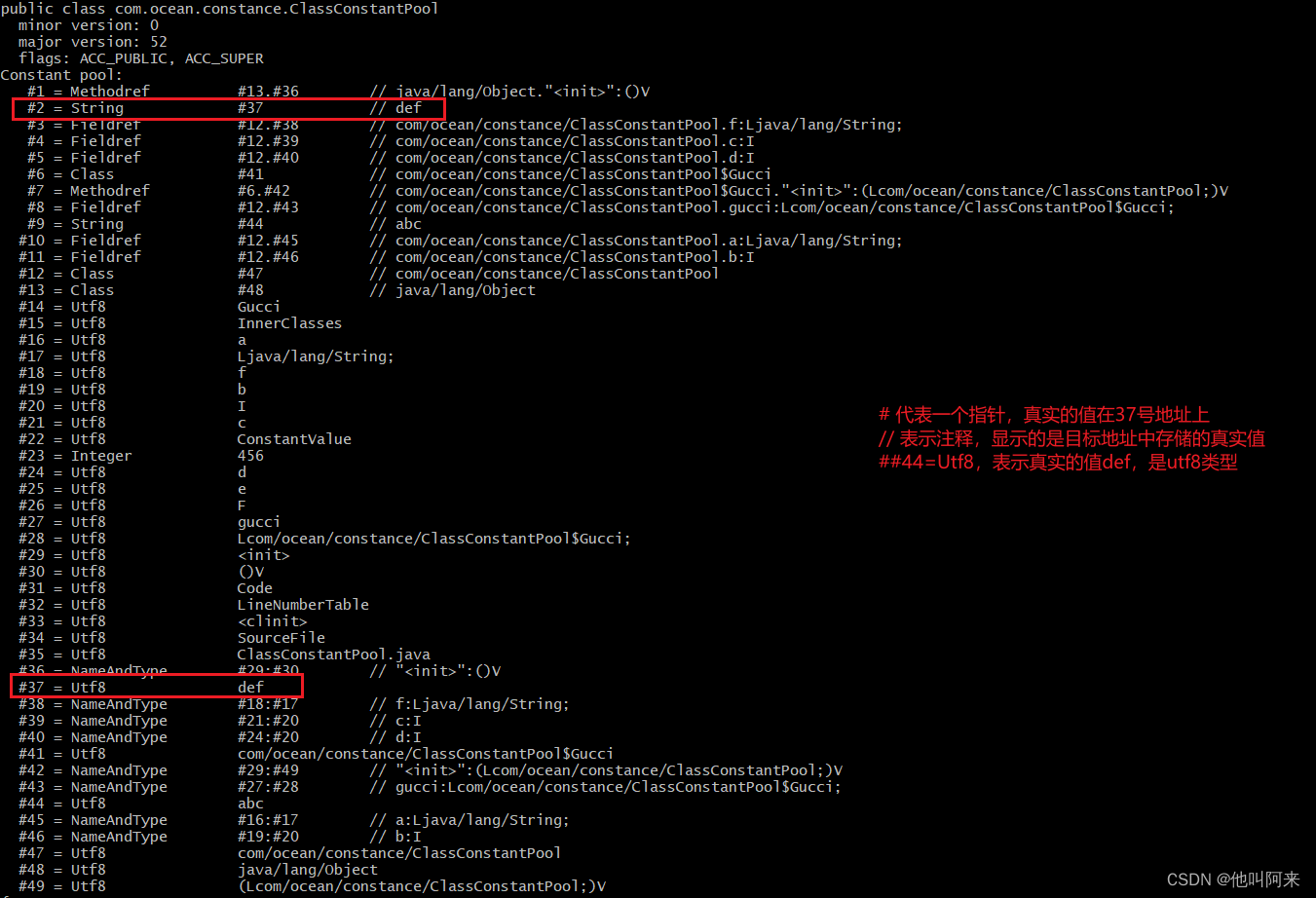
java虚拟机内存管理
文章目录 概要一、jdk7与jdk8内存结构的差异二、程序计数器三、虚拟机栈3.1 什么是虚拟机栈3.2 什么是栈帧3.3 栈帧的组成 四、本地方法栈五、堆5.1 堆的特点5.2 堆的结构5.3 堆的参数配置 六、方法区6.1 方法区结构6.2 运行时常量池 七、元空间 概要 根据 JVM 规范࿰…...
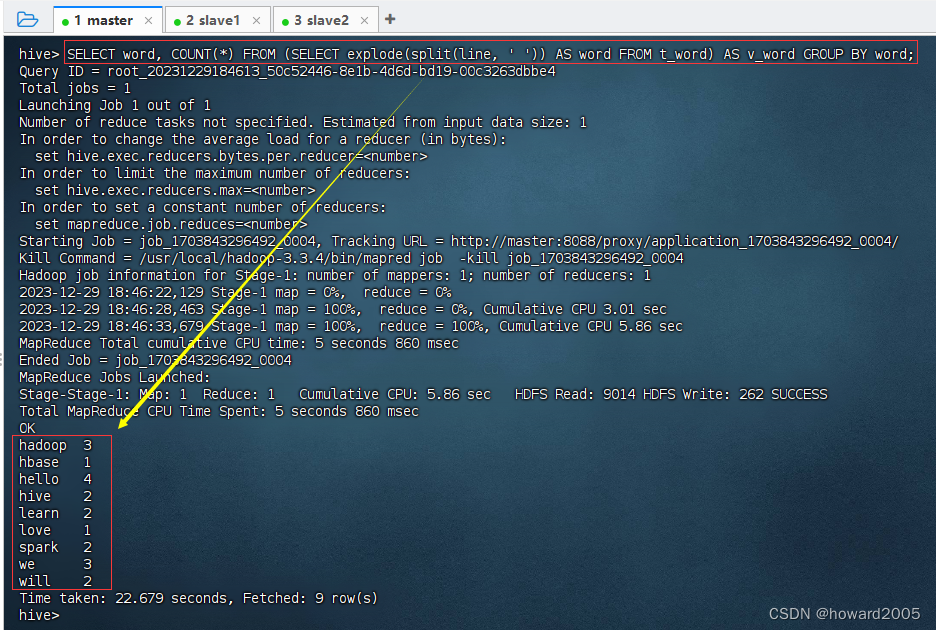
Hive实战:词频统计
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS文件创建外部表4、查询单词表&a…...
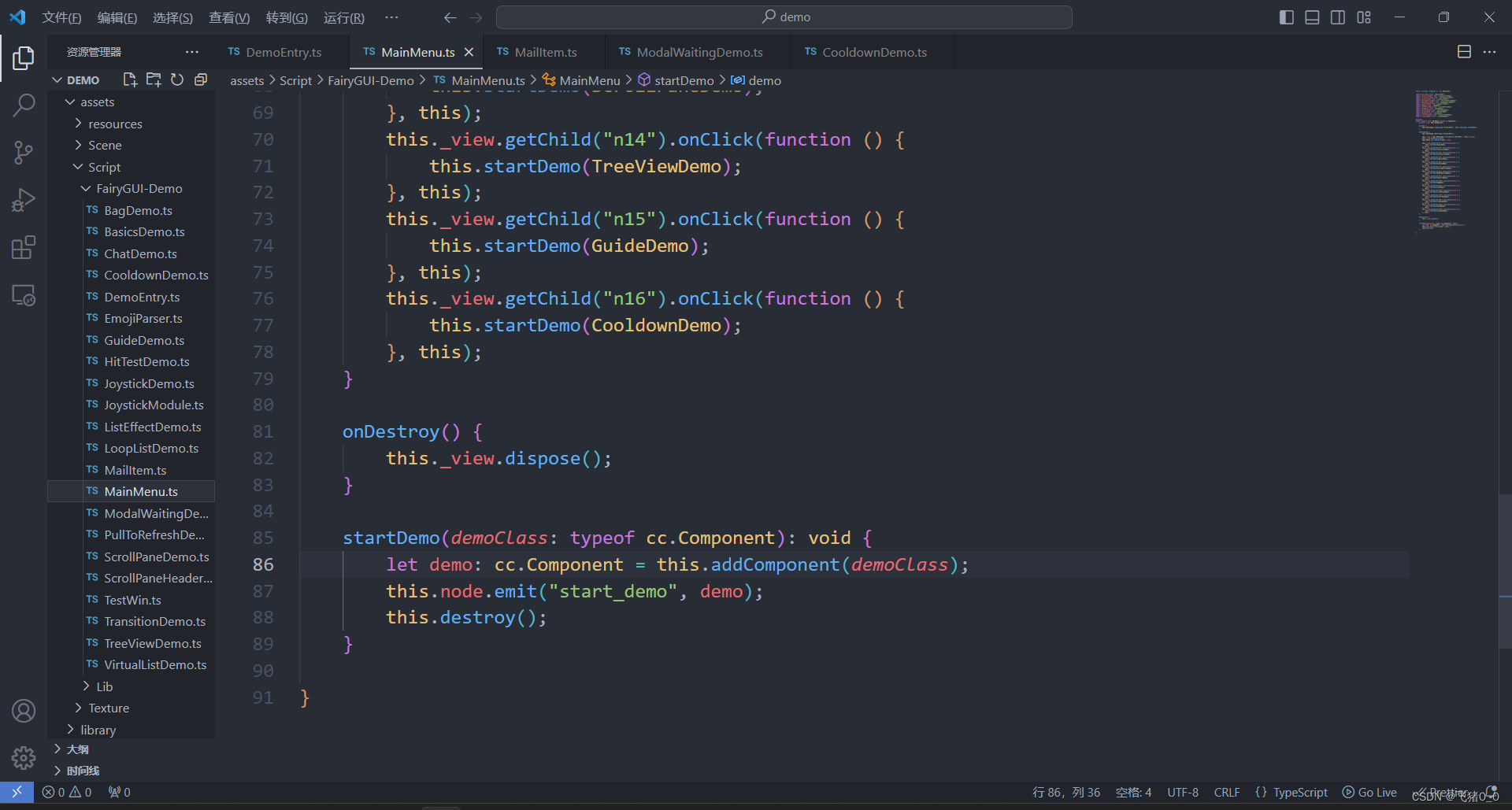
FairyGUI-Cocos Creator官方Demo源码解读
博主在学习Cocos Creator的时候,发现了一款免费的UI编辑器FairyGUI。这款编辑器的能力十分强大,但是网上的学习资源比较少,坑比较多,主要学习方式就是阅读官方文档和练习官方Demo。这里博主进行官方Demo的解读。 从gitee上克隆项目…...
LabVIEW利用视觉引导机开发器人精准抓取
LabVIEW利用视觉引导机开发器人精准抓取 本项目利用单目视觉技术指导多关节机器人精确抓取三维物体的技术。通过改进传统的相机标定方法,结合LabVIEW平台的Vision Development和Vision Builder forAutomated Inspection组件,优化了摄像系统的标定过程&a…...

【Linux】指令(本人使用比较少的)——笔记(持续更新)
文章目录 ps -axj:查看进程ps -aL:查看线程echo $?:查看最近程序的退出码jobs:查看后台运行的线程组fd 任务号:将后台任务提到前台bg 任务号:将暂停的后台程序重启netstat -nltp:查看服务及监听…...

032 - STM32学习笔记 - TIM基本定时器(一) - 定时器基本知识
032 - STM32学习笔记 - TIM定时器(一) - 基本定时器知识 这节开始学习一下TIM定时器功能,从字面意思上理解,定时器的基本功能就是用来定时,与定时器相结合,可以实现一些周期性的数据发送、采集等功能&#…...
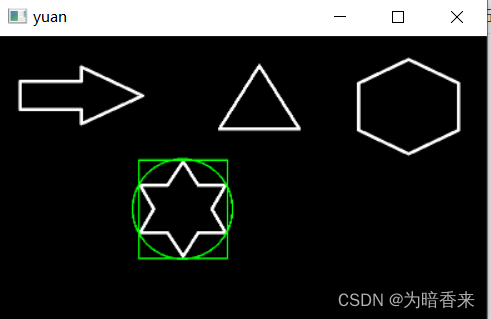
轮廓检测与处理
轮廓检测 先将图像转换成二值 gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图 ret, thresh cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 变为二值,大于127置为255,小于100置为0.使用cv2.findContours(thresh, cv2.RETR_TREE, cv2.…...

跟着LearnOpenGL学习11--材质
文章目录 一、材质二、设置材质三、光的属性四、不同的光源颜色 一、材质 在现实世界里,每个物体会对光产生不同的反应。 比如,钢制物体看起来通常会比陶土花瓶更闪闪发光,一个木头箱子也不会与一个钢制箱子反射同样程度的光。 有些物体反…...
Java guava partition方法拆分集合自定义集合拆分方法
日常开发中,经常遇到拆分集合处理的场景,现在记录2中拆分集合的方法。 1. 使用Guava包提供的集合操作工具栏 Lists.partition()方法拆分 首先,引入maven依赖 <dependency><groupId>com.google.guava</groupId><artifa…...
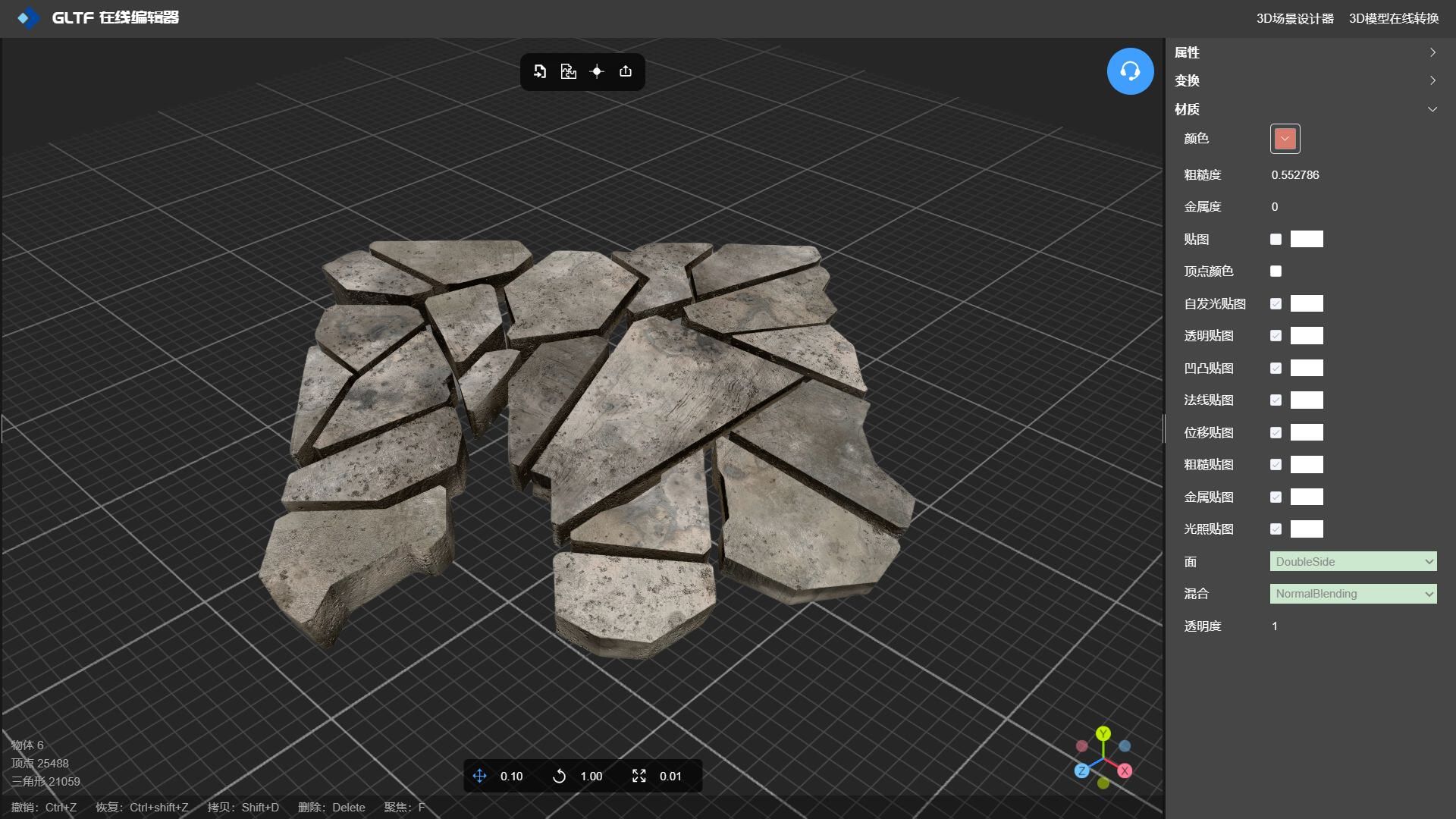
GLTF编辑器-位移贴图实现破碎的路面
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 位移贴图是一种可以用于增加模型细节和形状的贴图。它能够在渲染时针…...

多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测
多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现SSA-BiLSTM麻雀算法优化…...

docker安装Nacos和Rabbitmq
一、安装Nacos 首先需要拉取对应的镜像文件:(切换版本加上对应版本号即可,默认最新版) docker pull nacos/nacos-server 接着挂载目录: mkdir -p /mydata/nacos/logs/ #新建logs目录 mkdir -p …...
Android MVC 写法
前言 Model:负责数据逻辑 View:负责视图逻辑 Controller:负责业务逻辑 持有关系: 1、View 持有 Controller 2、Controller 持有 Model 3、Model 持有 View 辅助工具:ViewBinding 执行流程:View >…...
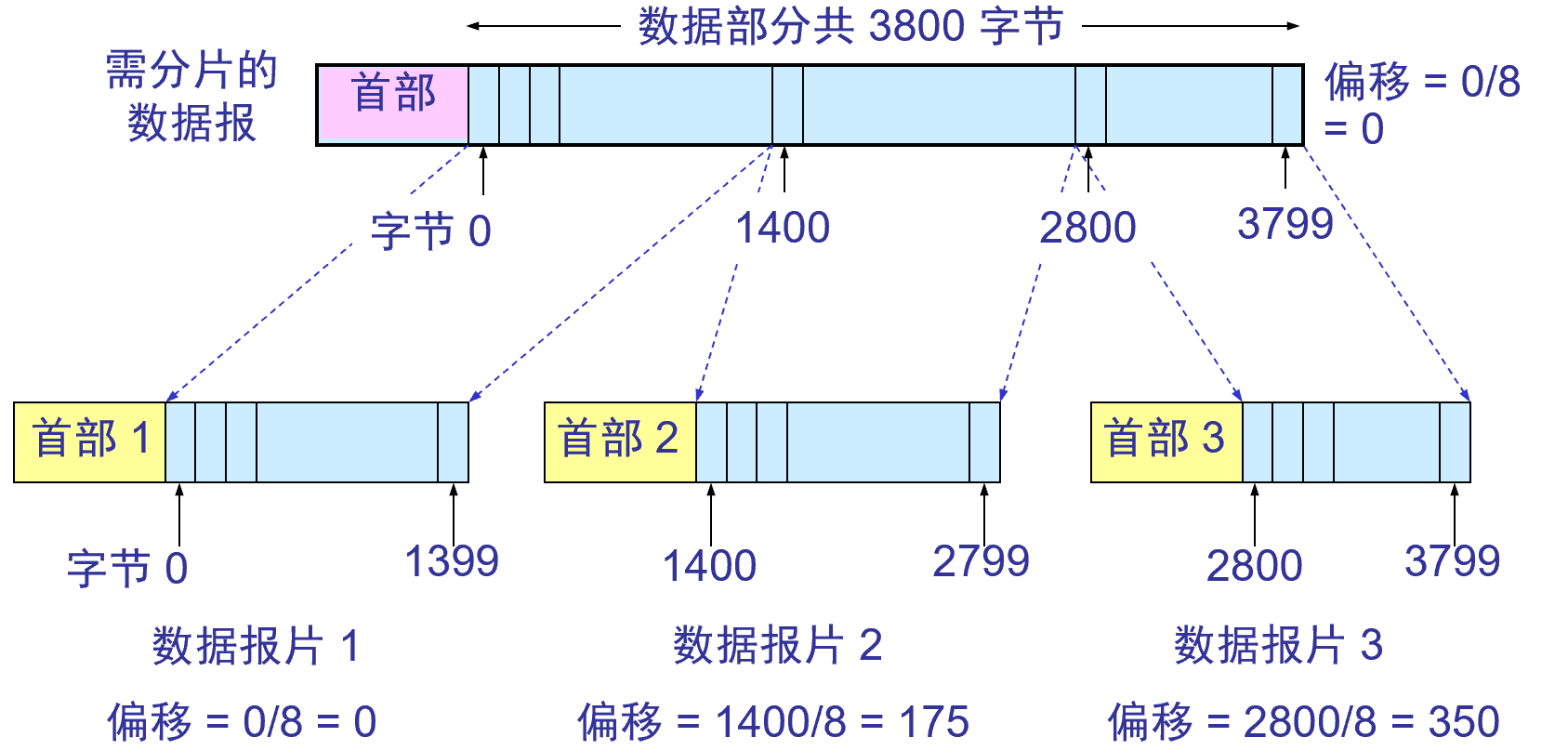
网络层解读
基本介绍 概述 当两台主机之间的距离较远(如相隔几十或几百公里,甚至几千公里)时,就需要另一种结构的网络,即广域网。广域网尚无严格的定义。通常是指覆盖范围很广(远超过一个城市的范围)的长距离的单个网络。它由一些结点交换机以及连接这些…...
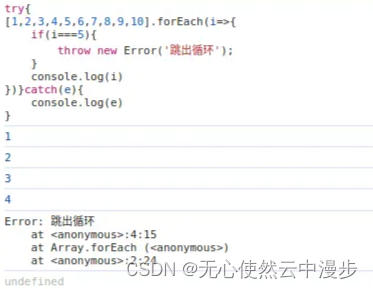
js for和forEach 跳出循环 替代方案
1 for循环跳出 for(let i0;i<10;i){if(i5){break;}console.log(i) }在函数中也可以return跳出循环 function fn(){for(let i0;i<10;i){if(i5){return;}console.log(i)} } fn()for ... of效果同上 2 forEach循环跳出 break会报错 [1,2,3,4,5,6,7,8,9,10].forEach(i>…...
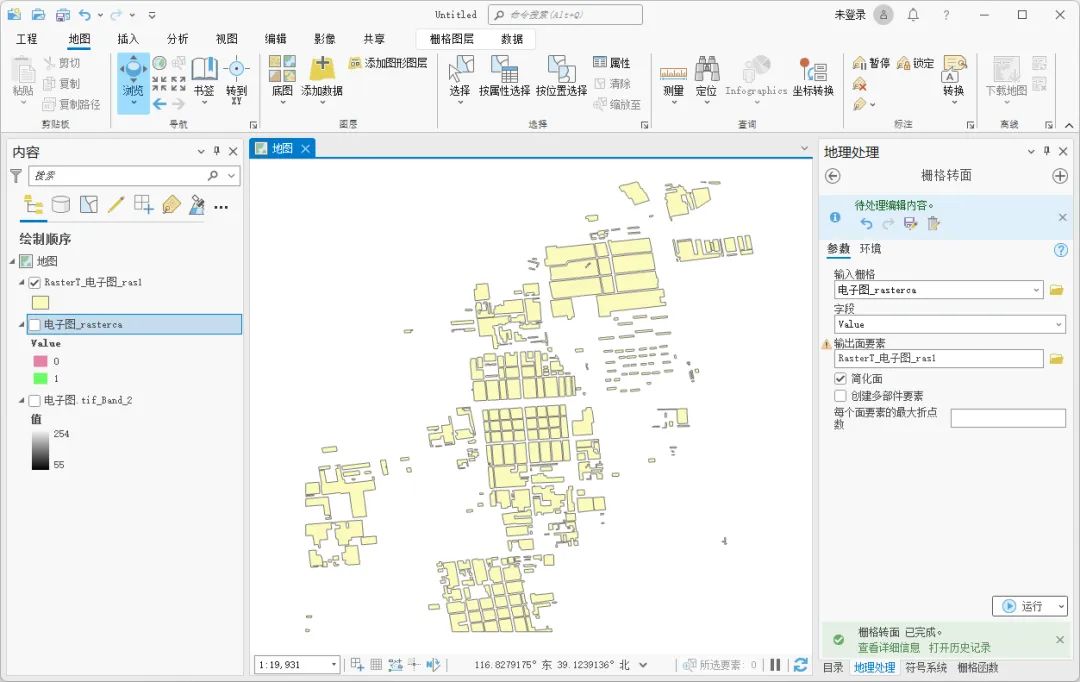
如何使用ArcGIS Pro自动矢量化建筑
相信你在使用ArcGIS Pro的时候已经发现了一个问题,那就是ArcGIS Pro没有ArcScan,在ArcGIS Pro中,Esri确实已经移除了ArcScan,没有了ArcScan我们如何自动矢量化地图,从地图中提取建筑等要素呢,这里为大家介绍…...

3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南
3个步骤让AMD显卡也能运行CUDA程序:ZLUDA终极指南 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 你是否曾经因为手头只有AMD显卡,却想运行那些需要CUDA加速的深度学习框架而感到无奈&…...

工业物联网实战启示:从14万亿预测看价值闭环与组织变革
1. 从一份价值14万亿美元的预测报告中,我们能学到什么?最近在整理一些行业旧闻时,翻到了2015年EE Times上的一篇老文章,讲的是埃森哲(Accenture)对工业物联网(Industrial IoT, IIoT)…...
)
基于深度学习的YOLOv8瞳孔识别+眼球识别与直径计算(代码+数据集+教程)
编写一个完整的从训练到推理YOLOv8瞳孔眼球识别与直径计算的指南,并包括模型转化和web界面交互式的实现,是一个相当庞大的项目。 1. 数据准备收集数据 对于瞳孔和眼球的检测,您需要收集大量的标注图像,这些图像应该包含不同光照条…...

Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南
Adobe Illustrator智能填充神器:Fillinger脚本的终极使用指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾经在Adobe Illustrator中面对数百个需要均匀分布的…...

基于Claude的多智能体代码编排框架:原理、实战与优化
1. 项目概述:当Claude遇上代码编排最近在GitHub上看到一个挺有意思的项目,叫0ldh/claude-code-agents-orchestra。光看名字,就能嗅到一股“组合拳”的味道——Claude、Code、Agents、Orchestra,这几个词凑在一起,指向性…...

QtScrcpy终极指南:高效实现Android投屏控制
QtScrcpy终极指南:高效实现Android投屏控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy QtScr…...

Halo Cursor:轻量级框架无关的动画光标库设计与实践
1. 项目概述:一个轻量、无框架绑定的动画光标库最近在重构一个前端项目,想给用户界面增加一点微妙的动态反馈,提升交互的精致感。我第一个想到的就是自定义光标效果。市面上这类库不少,但要么体积臃肿,要么和特定框架&…...

在Serv00共享主机上部署SOCKS5代理:原理、部署与优化指南
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的自托管服务时,遇到了一个经典难题:如何在资源受限的共享主机环境里,搭建一个轻量、稳定且可控的网络代理通道。这让我想起了之前在社区里看到的一个项目——cmliu/socks5-for-serv00。…...

MUMmer4 v4.0.0技术升级:基因组比对工具标准化与容器化部署深度解析
MUMmer4 v4.0.0技术升级:基因组比对工具标准化与容器化部署深度解析 【免费下载链接】mummer Mummer alignment tool 项目地址: https://gitcode.com/gh_mirrors/mu/mummer MUMmer4作为生物信息学领域广泛使用的基因组比对工具,最新发布的v4.0.0版…...
:降级策略与熔断保护,保证高峰期服务不被大图请求拖垮)
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮
Pytorch图像去噪实战(八十):降级策略与熔断保护,保证高峰期服务不被大图请求拖垮 一、问题场景:高峰期几个大图请求,把整个服务拖慢 图像去噪服务在高峰期最怕两类请求: 超大图片 高质量模型请求 它们会占用大量 CPU/GPU 时间,导致普通小图请求也变慢。 这时如果没有…...