爬虫工作量由小到大的思维转变---<第二十四章 Scrapy的`统计数据`收集stats collection ---12月26日补>
前言:
前两篇是讲的数据诊断分析,还有一篇深挖`解决内存泄漏`的文章,目前我还没整理汇编出来;但是,想到分析问题的时候,忽然觉得`爬虫的数据统计`好像也挺重要;于是,心血来潮准备来插一篇这个------让大家对日常scrapy爬的数据,做到心里有数!不必自己去搅破脑汁捣腾日志,敲计算器了;
正文:
在 Scrapy 中,可以使用 Stats Collection(统计信息收集)来收集和获取有关爬虫运行过程中的统计信息。Stats Collection 提供了各种默认的统计指标,例如请求数量、下载时间和爬取成功数等。
当然,也可以使用其他的,例如:
MemoryStatsCollector:默认的统计收集器,将统计数据存储在内存中。
CsvStatsCollector:将统计数据保存为 CSV 格式的文件。
JsonLinesStatsCollector:将统计数据保存为 JSON Lines 格式的文件。
XmlStatsCollector:将统计数据保存为 XML 格式的文件。
DbStatsCollector:将统计数据保存到数据库中。
LogStatsCollector:通过日志输出统计数据。-----这些其实都大同小异,我们就拿第一个来开刀!!
使用 Stats Collection 的步骤:
1. 在 Scrapy 项目的配置文件 `settings.py` 中启用 Stats Collection:
STATS_CLASS = 'scrapy.statscollectors.MemoryStatsCollector'通过配置 `STATS_CLASS` 参数,可以选择不同的 Stats Collector。在示例中,我们使用了 `MemoryStatsCollector`,该 Collector 将统计信息存储在内存中。
2. 在 Scrapy 的爬虫代码中导入 `scrapy.stats`:
from scrapy import stats3. 在爬虫代码中,可以使用 `stats` 对象来访问和处理统计信息。以下是一些常用的方法:
- - `stats.get_value(key, default=None)`:获取指定键名的统计值。如果指定的键名不存在,则返回提供的 `default` 值(默认为 `None`)。
- - `stats.inc_value(key, count=1)`:增加指定键名的统计值。`count` 参数可以指定增加的数量,默认为 1。
- - `stats.set_value(key, value)`:设置指定键名的统计值为给定的 `value`。
- - `stats.get_stats()`:返回当前所有统计信息的字典形式。
使用 Stats Collection:
from scrapy import Spiderfrom scrapy import statsclass MySpider(Spider):name = 'my_spider'start_urls = ['http://example.com']def parse(self, response):# 增加请求数量统计值self.stats.inc_value('request_count')# 获取当前请求数量的统计值request_count = self.stats.get_value('request_count', default=0)self.logger.info(f"Request Count: {request_count}")# 设置自定义统计值self.stats.set_value('custom_stat', 10)# 获取所有统计信息all_stats = self.stats.get_stats()self.logger.info(f"All Stats: {all_stats}")# ...其他处理代码...```在上述示例中,在解析函数中使用 `stats` 对象进行统计值的增加、获取和设置操作,以及获取所有统计信息。可以根据需要进行自定义的统计值操作,从而监控和分析爬虫的运行情况。
ps:Stats Collection 默认收集的统计信息可能会消耗一定的内存,如果需要更复杂的统计需求,可以考虑使用第三方库或自定义 Stats Collector 进行更高级的统计处理。
深入:
当需要进行更高级的统计处理时,可以自定义 Stats Collector 来满足特定的需求。自定义 Stats Collector 可以用于收集、处理和保存统计数据,以便后续分析和可视化。
以下是自定义 Stats Collector 的步骤:
1. 创建一个自定义的 Stats Collector 类,继承自 `scrapy.statscollectors.StatsCollector` 类,并重写需要的方法。
通常情况下,需要实现 `__init__()`、`open_spider()`、`close_spider()` 和 `get_value()` 方法。
from scrapy.statscollectors import StatsCollectorclass CustomStatsCollector(StatsCollector):def __init__(self, crawler):super().__init__(crawler)# 初始化自定义的统计数据self.custom_stats = {}def open_spider(self, spider):super().open_spider(spider)# 初始化每个爬虫的自定义统计数据self.custom_stats[spider.name] = {}def close_spider(self, spider, reason):super().close_spider(spider, reason)# 在爬虫结束时处理自定义统计数据custom_stats_data = self.custom_stats[spider.name]# 进行进一步的处理或保存操作def get_value(self, key, default=None, spider=None):# 获取自定义统计数据的值if spider:return self.custom_stats[spider.name].get(key, default)return default
2. 在 Scrapy 项目的配置文件 `settings.py` 中配置自定义的 Stats Collector 类:
STATS_CLASS = 'your_project_name.custom_stats.CustomStatsCollector'ps:`your_project_name` 需要替换为 Scrapy 项目的名称,以及其他必要的导入路径。
3. 使用自定义的 Stats Collector
在 Spider 类中,通过 `self.crawler.stats` 访问自定义的 Stats Collector 对象,并使用相应的方法进行统计值的获取、增加和设置。
from scrapy import Spiderclass MySpider(Spider):name = 'my_spider'start_urls = ['http://example.com']def parse(self, response):# 增加自定义统计值self.crawler.stats.inc_value('custom_stat', spider=self)# 获取自定义统计值custom_stat_value = self.crawler.stats.get_value('custom_stat', default=0, spider=self)self.logger.info(f"Custom Stat Value: {custom_stat_value}")# 设置自定义统计值self.crawler.stats.set_value('custom_stat', 10, spider=self)# ...其他处理代码...
创建一个自定义的 Stats Collector 类 `CustomStatsCollector`,并在 `open_spider()` 和 `close_spider()` 方法中进行自定义统计数据的初始化和处理。在 Spider 类中,使用 `self.crawler.stats` 访问自定义的 Stats Collector 对象,并用相应的方法进行自定义统计值的增加、获取和设置。
也可以根据具体需求在自定义 Stats Collector 类中添加其他统计方法和处理逻辑,并使用自定义统计数据进行进一步的分析和处理。
另一个案例:
统计每个爬虫访问 URL 的数量,并在爬虫结束时将统计数据保存到文件中。
import json
from scrapy.statscollectors import StatsCollectorclass CustomStatsCollector(StatsCollector):def __init__(self, crawler):super().__init__(crawler)# 初始化自定义统计数据self.custom_stats = {}def open_spider(self, spider):super().open_spider(spider)# 初始化每个爬虫的自定义统计数据self.custom_stats[spider.name] = {'url_count': 0}def close_spider(self, spider, reason):super().close_spider(spider, reason)# 在爬虫结束时处理自定义统计数据custom_stats_data = self.custom_stats[spider.name]# 保存自定义统计数据到文件with open(f'{spider.name}_stats.json', 'w') as file:json.dump(custom_stats_data, file)def inc_url_count(self, spider):# 增加 URL 数量统计值self.custom_stats[spider.name]['url_count'] += 1def get_url_count(self, spider):# 获取 URL 数量统计值return self.custom_stats[spider.name]['url_count']在 Spider 类中,我们可以调用自定义 Stats Collector 的 `inc_url_count()` 方法来增加 URL 数量的统计值,并使用 `get_url_count()` 方法获取统计值。
from scrapy import Spiderclass MySpider(Spider):name = 'my_spider'start_urls = ['http://example.com']def parse(self, response):# 增加 URL 数量统计值self.crawler.stats.inc_url_count(self)# 获取 URL 数量统计值url_count = self.crawler.stats.get_url_count(self)self.logger.info(f"URL Count: {url_count}")# ...其他处理代码...
在这个案例中,我们定义了 `CustomStatsCollector` 类,用于统计每个爬虫访问的 URL 数量。使用 `inc_url_count()` 方法增加统计值,并使用 `get_url_count()` 方法获取统计结果。在爬虫结束时,自定义统计数据将被保存到以爬虫名为前缀的 JSON 文件中。
(可自行在此框架上修改,自己需要的业务逻辑)
12月26日补
可以直接拿这个模版,套到自己的中间件:
(统计那么几个数,然后输出到一个txt里面)
class MyStatsMiddleware:def __init__(self, stats: StatsCollector):self.stats = stats@classmethoddef from_crawler(cls, crawler):return cls(crawler.stats)def process_response(self, request, response, spider):if response.status >= 400: # 如果响应状态码大于等于 400,表示请求失败self.stats.inc_value('html_failures') # 增加 HTML 请求失败的统计计数def spider_closed(self, spider):requests_count = self.stats.get_value("downloader/request_count", 0)items_count = self.stats.get_value("item_scraped_count", 0)elapsed_time = self.stats.get_value("finish_time") - self.stats.get_value("start_time")html_failures = self.stats.get_value("html_failures", 0) # 获取 HTML 请求失败总数data = {"爬取html总量": requests_count,"爬取html失败总量": html_failures,"存储的item总量": items_count,"一共耗时": elapsed_time #精确到秒数}with open("任务统计.txt", "w") as f:json.dump(data, f)别忘了,在setting设置里面,添加这个中间件:
DOWNLOADER_MIDDLEWARES = {"jihai_end.middlewares.DownloaderMiddleware": 543,# 正常中间件"jihai_end.middlewares.MyStatsMiddleware": 900, #统计中间件
}
相关文章:

爬虫工作量由小到大的思维转变---<第二十四章 Scrapy的`统计数据`收集stats collection ---12月26日补>
前言: 前两篇是讲的数据诊断分析,还有一篇深挖解决内存泄漏的文章,目前我还没整理汇编出来;但是,想到分析问题的时候,忽然觉得爬虫的数据统计好像也挺重要;于是,心血来潮准备来插一篇这个------让大家对日常scrapy爬的数据,做到心里有数!不必自己去搅破脑汁捣腾日志,敲计算器了…...
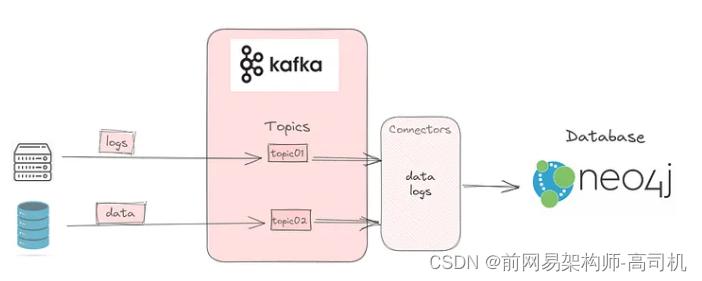
Kafka:本地设置
这是设置 Kafka 将数据从 Elasticsearch 发布到 Kafka 主题的三部分系列的第一部分;该主题将被 Neo4j 使用。第一部分帮助您在本地设置 Kafka。第二部分将讨论如何设置Elasticsearch将数据发布到Kafka主题。最后 将详细介绍如何使用连接器订阅主题并使用数据。 Kafka Kafka 是…...
.NetCore NPOI 读取excel内容及单元格内图片
由于数据方提供的数据在excel文件中不止有文字内容还包含图片信息,于是编写相关测试代码,读取excel文件内容及图片信息. 本文使用的是 NPOI-2.6.2 版本,此版本持.Net4.7.2;.NetStandard2.0;.NetStandard2.1;.Net6.0。 测试文档内容…...

TCP/UDP协议
1. 请解释TCP和UDP的主要区别。 TCP和UDP都是位于传输层的协议,具有不同的特点和应用场景。以下是它们的主要区别: 连接方式:TCP是面向连接的协议,这意味着在数据传输之前需要先建立连接。这通常通过三次握手来建立连接ÿ…...

3D 渲染如何帮助电商促进销售?
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 3D 渲染图像因其高转化率而成为亚马逊卖家的最新趋势。它是电子商务平…...

使用栈求表达式的值【数据结构】
中缀表达式转后缀表达式 转换流程: 初始化一个运算符栈。自左向右扫描中缀表达式,当扫描到操作数时直接连接到后缀表达式上。当扫描到操作符时,和运算符栈栈顶的操作符进行比较。如果比栈顶运算符高,则入栈。如果比栈顶运算符低…...
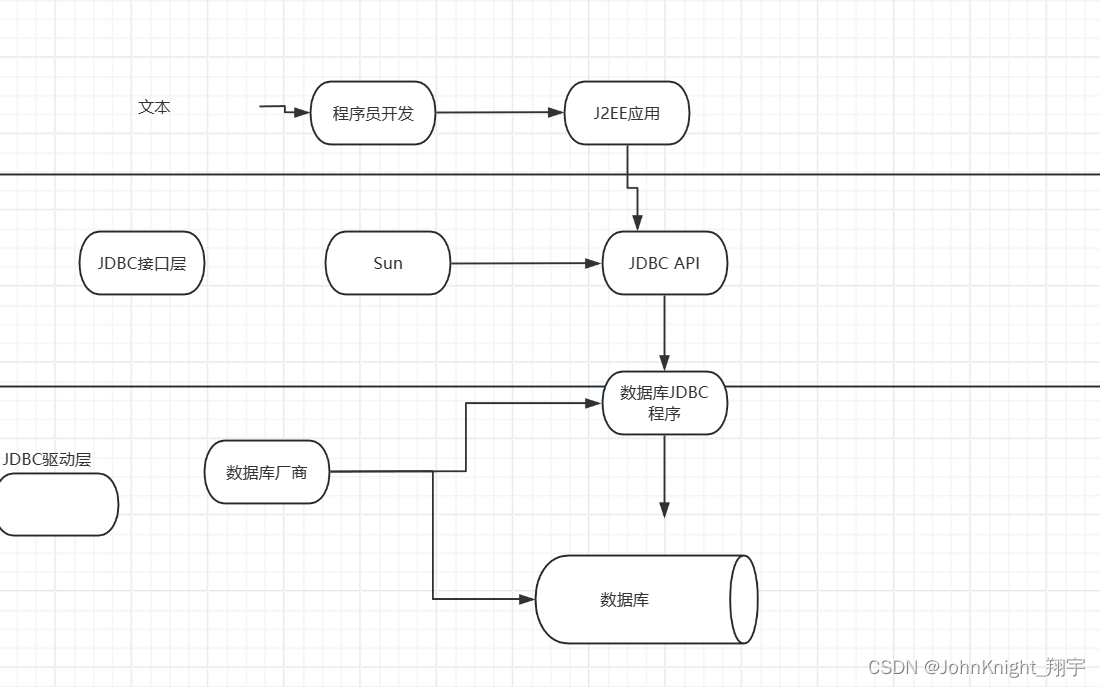
{MySQL}索引事务和JDBC
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、索引1.1索引是什么1.2作用1.3代码 二、事务2.1什么是事务2.2使用 三.JDBC总结 前言 接着上次,继续讲下MySQL 提示:以下是本篇文章正…...

Qt designer界面和所有组件功能的详细介绍(全!!!)
PyQt5和Qt designer的详细安装教程:https://blog.csdn.net/qq_43811536/article/details/135185233?spm1001.2014.3001.5501 目录 1. 界面介绍2. Widget Box 常用组件2.1 Layouts(布局)2.2 Spacers(间隔器)2.3 Item V…...

mysql_存储过程
举例子 createdefiner root% procedure insert_batch_test(IN START int(10), IN max_num int(10)) BEGINDECLAREi INT DEFAULT 0;SET autocommit 0;REPEATSET i i 1;INSERT INTO test (std, score)VALUES (CEILING(RAND() * 10 100), CEILING(RAND() * 50 50));UNTIL i …...

uboot学习及内核更换_incomplete
官方文档 在前面 文章目录 uboot常见命令学习环境变量网络控制台uboot标准启动其他 升级uboot或内核bin和uimg以及booti和bootm的区别制作uImage更换内核更换uboot后续计划 uboot常见命令学习 环境变量 Environment Variables环境变量 autostart 如果值为yes,则会…...
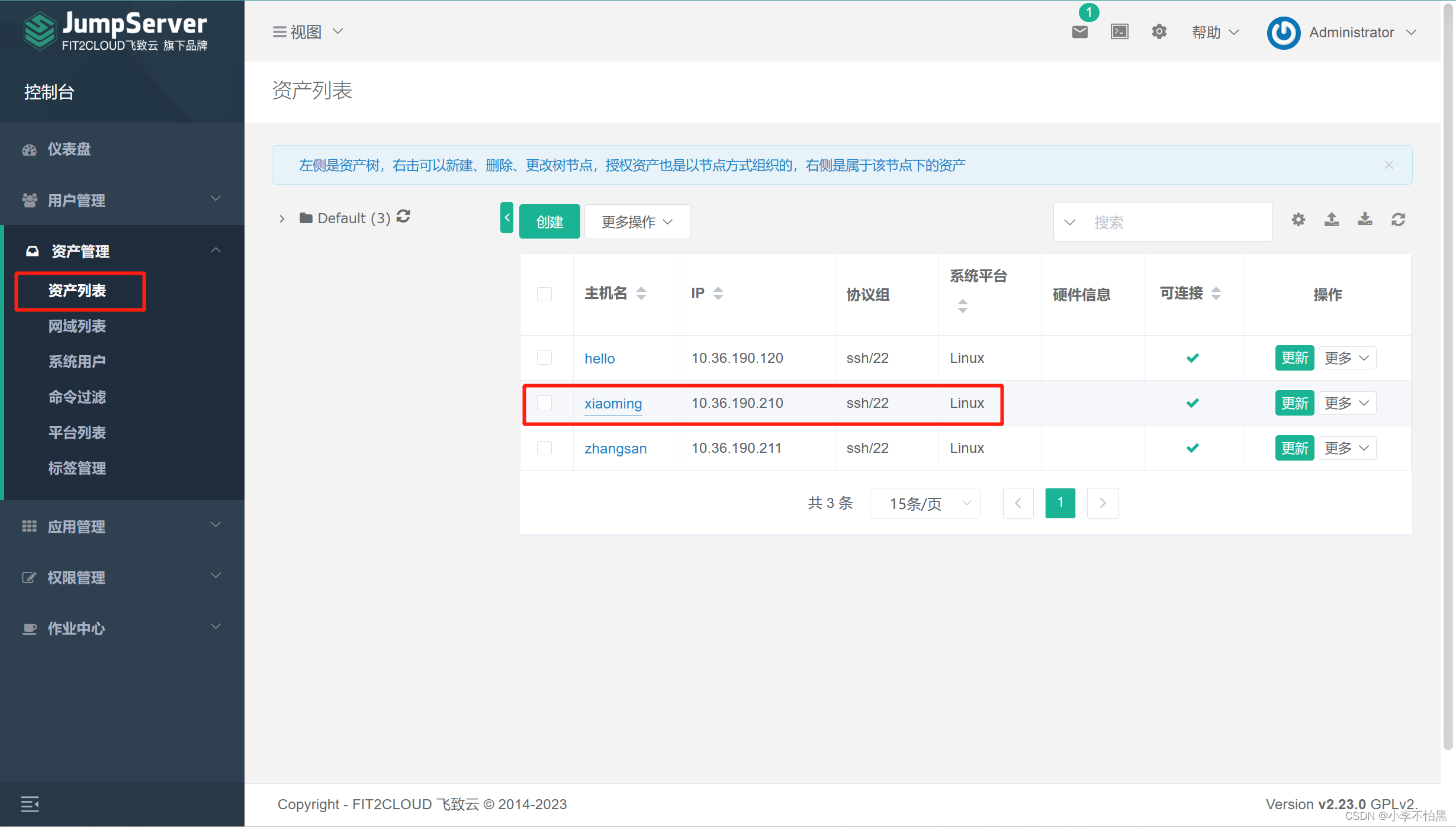
KVM 自动化脚本的使用及热/冷迁移
一、介绍 目录结构介绍 [rootkvm-server kvm]# tree -L 2 . ├── control # 控制脚本目录 │ ├── KVMInstall.sh # kvm服务安装脚本 │ ├── VMHost.sh # kvm虚拟机克隆脚本 │ └── VMTemplate.sh # kvm模板机安装脚本 ├── mount # 此目录保持为空&…...
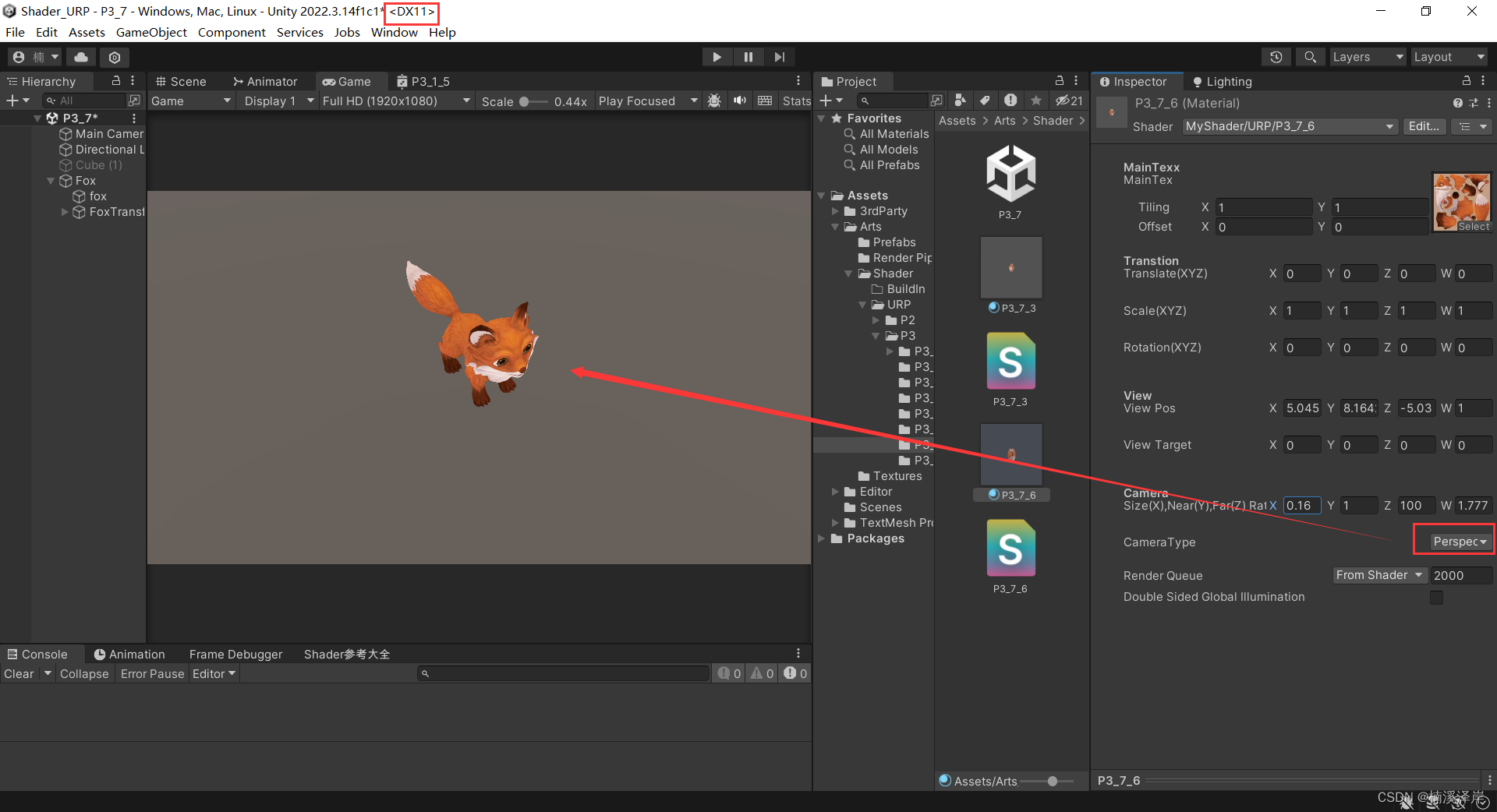
Unity中Shader裁剪空间推导(在Shader中使用)
文章目录 前言一、在Shader中使用转化矩阵1、在顶点着色器中定义转化矩阵2、用 UNITY_NEAR_CLIP_VALUE 区分平台矩阵3、定义一个枚举用于区分当前是处于什么相机 二、我们在DirectX平台下,看看效果1、正交相机下2、透视相机下3、最终代码 前言 在上一篇文章中&…...
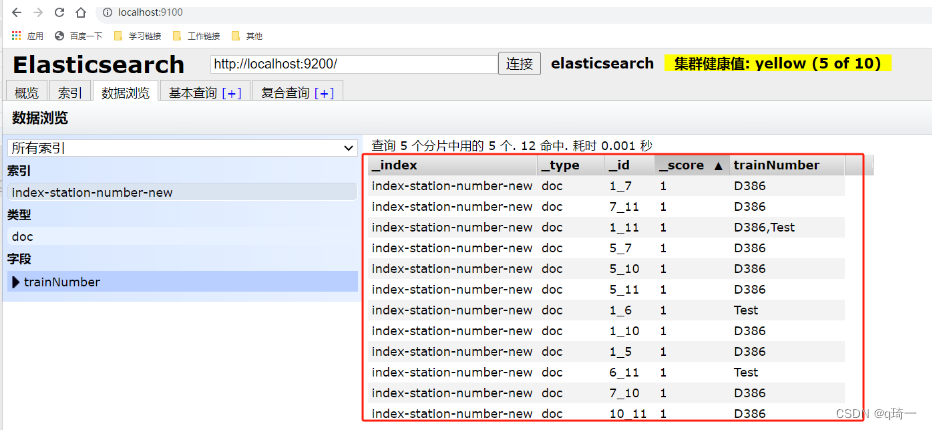
ES的使用(Elasticsearch)
ES的使用(Elasticsearch) es是什么? es是非关系型数据库,是分布式文档数据库,本质上是一个JSON 文本 为什么要用es? 搜索速度快,近乎是实时的存储、检索数据 怎么使用es? 1.下载es的包(环境要…...

车牌识别技术,如何用python识别车牌号
目录 一.前言 二.运行环境 三.代码 四.识别效果 五.参考 一.前言 车牌识别技术(License Plate Recognition, LPR)在交通计算机视觉(Computer Vision, CV)领域具有非常重要的研究意义。以下是该技术的一些扩展说明࿱…...
>)
爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>
爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>-CSDN博客 爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>-CSDN博客 前言: 之前提到过,很多scrapy写出来之后,不…...
Servlet入门
目录 1.Servlet介绍 1.1什么是Servlet 1.2Servlet的使用方法 1.3Servlet接口的继承结构 2.Servlet快速入门 2.1创建javaweb项目 2.1.1创建maven工程 2.1.2添加webapp目录 2.2添加依赖 2.3创建servlet实例 2.4配置servlet 2.5设置打包方式 2.6部署web项目 3.servl…...

【C#与Redis】--高级主题--Redis 哨兵
一、简介 1.1 哨兵的概述 哨兵(Sentinel)是 Redis 分布式系统中用于监控和管理多个 Redis 服务器的组件。它的主要目标是确保 Redis 系统的高可用性,通过实时监测主节点和从节点的状态,及时发现并自动处理故障,保证系…...

linux安装python
文章目录 前言一、下载安装包二、安装1.安装依赖2.解压3.安装4.软链接5.验证 总结 前言 本篇文章介绍linux环境下安装python。 一、下载安装包 下载地址:官方网站 我们以最新的标准版为例 二、安装 1.安装依赖 yum -y install openssl-devel ncurses-devel li…...

【如何破坏单例模式(详解)】
✅如何破坏单例模式 💡典型解析✅拓展知识仓✅反射破坏单例✅反序列化破坏单例✅ObjectlnputStream ✅总结✅如何避免单例被破坏✅ 避免反射破坏单例✅ 避免反序列化破坏单例 💡典型解析 单例模式主要是通过把一个类的构造方法私有化,来避免重…...

什么是 SPI,它有什么用?
文章目录 什么是 SPI,它有什么用? 什么是 SPI,它有什么用? SPI 全称是 Service Provider Interface ,它是 JDK 内置的一种动态扩展点的实现。 简单来说,就是我们可以定义一个标准的接口,然后第三…...

Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控
Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾为Windows右键菜单的混乱而烦…...

Kotlin原生AI Agent框架Koog:多平台、类型安全与生产级实践
1. 从零到一:为什么我们需要一个Kotlin原生的AI Agent框架?如果你是一个长期在JVM生态,特别是Kotlin世界里摸爬滚打的开发者,过去一年里,你肯定没少跟各种AI SDK打交道。无论是OpenAI的官方库,还是LangChai…...

ISSCC传感器设计启示:从高精度温度测量到低功耗系统优化
1. 从ISSCC看传感器设计的巅峰与启示每年二月的国际固态电路会议,对于像我这样泡在实验室和产线里的硬件工程师来说,就像一场技术界的“春晚”。它不发布概念,不空谈趋势,只展示过去一年里,全球顶尖研究团队在硅片上实…...

医疗AI数据偏见:从耳镜图像分类看模型泛化陷阱与实战避坑指南
1. 项目概述与核心挑战作为一名在医疗AI领域摸爬滚打了十多年的从业者,我见过太多“实验室里天花乱坠,临床上寸步难行”的模型。最近,我和团队深入剖析了一项关于利用人工智能(AI)进行中耳炎耳镜图像分类的研究&#x…...

3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力
3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方OMEN Gaming Hub的…...

SMD电阻脉冲负载能力解析与工程实践
1. SMD电阻脉冲负载能力解析:工程师必须掌握的核心知识在工业控制板卡维修现场,我曾遇到一个令人费解的案例:某型号PLC的输入保护电路在雷雨季节频繁损坏,但检查发现所有元件参数都符合设计要求。最终用热成像仪捕捉到瞬间现象——…...

美国通信业去监管趋势下的技术生态变革与产业应对策略
1. 从“去监管”信号看美国通信业格局重塑 2017年初,当阿吉特派伊(Ajit Pai)正式接任美国联邦通信委员会(FCC)主席时,他的一项早期举措——为广播公司和有线电视运营商削减文书工作规定——几乎在所有人的预…...

边缘TTS实战:本地部署高质量语音合成与性能优化指南
1. 项目概述:当TTS遇见边缘计算最近在折腾一个需要实时语音合成的项目,发现了一个挺有意思的仓库:travisvn/openai-edge-tts。这名字一看就很有料,把“OpenAI”和“Edge-TTS”这两个词组合在一起,背后指向的是一个非常…...

ARM ETE Trace ID寄存器详解与应用
1. ARM ETE Trace ID寄存器概述在ARM架构的嵌入式调试系统中,Trace ID寄存器(TRCIDR)是嵌入式跟踪宏单元(ETE)的核心组件。这些寄存器提供了非侵入式的实时程序流分析能力,对于芯片验证、性能优化和系统调试具有不可替代的价值。ETE的Trace ID寄存器从TR…...

在Android Termux中搭建轻量级Docker容器环境:原理、部署与实战
1. 项目概述与核心价值最近在折腾移动设备上的开发环境,发现一个挺有意思的项目:George-Seven/Termux-Udocker。简单来说,它是在Android平台的Termux终端模拟器里,实现一个轻量级的Docker容器运行环境。这玩意儿解决了一个挺实际的…...