【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事
【SQL开发实战技巧】系列(二):简单单表查询
【SQL开发实战技巧】系列(三):SQL排序的那些事
【SQL开发实战技巧】系列(四):从执行计划讨论UNION ALL与空字符串&UNION与OR的使用注意事项
【SQL开发实战技巧】系列(五):从执行计划看IN、EXISTS 和 INNER JOIN效率,我们要分场景不要死记网上结论
【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
【SQL开发实战技巧】系列(七):从有重复数据前提下如何比较出两个表中的差异数据及对应条数聊起
【SQL开发实战技巧】系列(八):聊聊如何插入数据时比约束更灵活的限制数据插入以及怎么一个insert语句同时插入多张表
【SQL开发实战技巧】系列(九):一个update误把其他列数据更新成空了?Merger改写update!给你五种删除重复数据的写法!
文章目录
- 系列文章目录
- 前言
- 一、从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率
- 二、外连接中的条件不要乱放,建议大家使用join而非(+)
- 总结
前言
本篇文章讲解的主要内容是:从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,还是那就话,别死记网上结论、在使用内外关联时,特别是简写方式时记住关联条件不要乱放!
【SQL开发实战技巧】这一系列博主当作复习旧知识来进行写作,毕竟SQL开发在数据分析场景非常重要且基础,面试也会经常问SQL开发和调优经验,相信当我写完这一系列文章,也能再有所收获,未来面对SQL面试也能游刃有余~。
一、从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率
有些单位的部门(如40)中一个员工也没有,只是设了一个部门名字,如下列语句:
select count(*) from dept where deptno=40;
如何通过关联查询把这些信息查出来?
同样有三种写法:NOT IN、NOT EXISTS 和LEFT JOIN。
语句及PLAN如下(版本为11.2.0.4.0 )。
环境:
alter table dept add constraints pk_dept primary key (deptno); --如果你有就不用建了
- NOT IN用法
EXPLAIN PLAN FOR select *
FROM dept
WHERE deptno NOT IN (SELECT emp.deptno FROM emp WHERE emp.deptno IS NOT NULL);
SELECT * FROM TABLE(dbms_xplan.display());PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1353548327
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 23 | 6 (17)| 00
| 1 | MERGE JOIN ANTI | | 1 | 23 | 6 (17)| 00
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00
|* 4 | SORT UNIQUE | | 14 | 42 | 4 (25)| 00
|* 5 | TABLE ACCESS FULL | EMP | 14 | 42 | 3 (0)| 00
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------4 - access("DEPTNO"="EMP"."DEPTNO")filter("DEPTNO"="EMP"."DEPTNO")5 - filter("EMP"."DEPTNO" IS NOT NULL)19 rows selected
- NOT EXISTS 用法
EXPLAIN PLAN FOR SELECT*
FROM dept
WHERE NOT EXISTS ( SELECT NULL FROM emp WHERE emp.deptno = dept.deptno) ;
SELECT * FROM TABLE(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1353548327
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 23 | 6 (17)| 00
| 1 | MERGE JOIN ANTI | | 1 | 23 | 6 (17)| 00
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00
|* 4 | SORT UNIQUE | | 14 | 42 | 4 (25)| 00
|* 5 | TABLE ACCESS FULL | EMP | 14 | 42 | 3 (0)| 00
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")filter("EMP"."DEPTNO"="DEPT"."DEPTNO")5 - filter("EMP"."DEPTNO" IS NOT NULL)19 rows selected
- LEFT JOIN 用法
根据前面介绍过的左联知识,LEFT JOIN 取出的是左表中所有的数据,其中与右表不匹配的就表示左表NOT IN右表。
所以这里LEFT JOIN加上条件TS NULL,就是LEFT JOIN的写法:
EXPLAIN PLAN FOR
SELECT dept.*
FROM dept
LEFT JOIN emp ON emp.deptno = dept.deptno WHERE emp.deptno IS NULL;SELECT * FROM TABLE(dbms_xplan.display());PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1353548327
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Ti
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 23 | 6 (17)| 00
| 1 | MERGE JOIN ANTI | | 1 | 23 | 6 (17)| 00
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 4 | 80 | 2 (0)| 00
| 3 | INDEX FULL SCAN | PK_DEPT | 4 | | 1 (0)| 00
|* 4 | SORT UNIQUE | | 14 | 42 | 4 (25)| 00
|* 5 | TABLE ACCESS FULL | EMP | 14 | 42 | 3 (0)| 00
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")filter("EMP"."DEPTNO"="DEPT"."DEPTNO")5 - filter("EMP"."DEPTNO" IS NOT NULL)19 rows selected
通过看上面的执行计划,三个SQL用的都是 MERGE JOIN ANTI, 说明这三种方法的效率一样。
如果想改写,就要对比改写前后的PLAN,根据PLAN来判断并测试哪种方法的效率高,一定要记住不能凭借某些结论来碰运气。
二、外连接中的条件不要乱放,建议大家使用join而非(+)
对于系列三博客介绍的左联语句,见下面的数据。
SELECT l.str AS left_str, r.str AS right_str,r.status FROM l
LEFT JOIN r ON l.v = r.v
ORDER BY 1 , 2 ;
LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_1
left_2
left_3 right_3 1
left_4 right_4 0
那现在有这么一个需求:对于其中的L表,四条数据都返回。而对于R表,我们需要只显示其中的status=1的数据,也就是下面这样的结果:
LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_1
left_2
left_3 right_3 1
left_4
对于这个需求,可能有些人会加一个where条件!然后结果就变成了下面这样了:
left join写法:
SELECT l.str AS left_str, r.str AS right_str,r.status FROM l
LEFT JOIN r ON (l.v = r.v)
where r.status=1
ORDER BY 1 , 2;
LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_3 right_3 1
(+)写法:
SELECT l.str AS left_str, r.str AS right_str, r.statusFROM l, rwhere l.v = r.v(+)and r.status = 1ORDER BY 1, 2;
LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_3 right_3 1
而此时的执行计划:
SQL> EXPLAIN PLAN FOR2 SELECT l.str AS left_str, r.str AS right_str,r.status3 FROM l4 LEFT JOIN r ON (l.v = r.v)5 where r.status=16 ORDER BY 1 , 2;ExplainedSQL> SELECT * FROM TABLE(dbms_xplan.display());PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 688663707
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 42 | 7 (15)| 00:00:01 |
| 1 | SORT ORDER BY | | 2 | 42 | 7 (15)| 00:00:01 |
|* 2 | HASH JOIN | | 2 | 42 | 6 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| R | 2 | 24 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| L | 4 | 36 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------2 - access("L"."V"="R"."V")3 - filter("R"."STATUS"=1)17 rows selected
很明显,结果以及执行计划(HASH JOIN)与我们期望得到的结果都不一致!!!这是很多人在写查询或更改查询时常遇到的一种错误。问题就在于所加条件的位置及写法,正确的写法分别如下:
SQL> SELECT l.str AS left_str, r.str AS right_str, r.status2 FROM l3 LEFT JOIN r4 ON (l.v = r.v and r.status = 1)5 ORDER BY 1, 2;LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_1
left_2
left_3 right_3 1
left_4 SQL> SELECT l.str AS left_str, r.str AS right_str, r.status2 FROM l, r3 where l.v = r.v(+)4 and r.status(+) = 15 ORDER BY 1, 2;LEFT_STR RIGHT_STR STATUS
-------- --------- ----------
left_1
left_2
left_3 right_3 1
left_4
看一下这时候的执行计划:
SQL> EXPLAIN PLAN FOR2 SELECT l.str AS left_str, r.str AS right_str, r.status3 FROM l4 LEFT JOIN r5 ON (l.v = r.v and r.status = 1)6 ORDER BY 1, 2;ExplainedSQL> SELECT * FROM TABLE(dbms_xplan.display());PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 2310059642
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 84 | 7 (15)| 00:00:01 |
| 1 | SORT ORDER BY | | 4 | 84 | 7 (15)| 00:00:01 |
|* 2 | HASH JOIN OUTER | | 4 | 84 | 6 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| L | 4 | 36 | 3 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| R | 2 | 24 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------2 - access("L"."V"="R"."V"(+))4 - filter("R"."STATUS"(+)=1)17 rows selected
以上两种写法结果均正确,且根据执行计划HASH JOIN OUTER明确走的是外连接。而且根据上面查询我们能够看出来JOIN的方式明显更容易辨别,这也是我反复建议使用JOIN的原因。
对于上面SQL我们还可以使用先过滤再关联的方式,即R表先过滤:
(select * from r where status=1) r
总结
同上一篇博客所说,在使用in exists或则NOT IN、NOT EXISTS 和 LEFT JOIN时候,不要想当然的认为in和not in效率极其低下,在本章案例中通过执行计划能够直观的看到,三者效率竟然一致了!!所以,读万卷书不如行万里路,网上别人做的总结再好,也不如自己实践一把来的真实。还有就是,在使用关联查询时候,关联条件和过滤条件一定要想好放哪里,不然你会想当然的错了!
相关文章:
:从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放)
【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
系列文章目录 【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…...

十分钟利用环信WebIM-vue3-Demo,打包上线一个即时通讯项目【含音视频通话】
这篇文章无废话,只教你如果接到即时通讯功能需求,十分钟利用环信WebIM-vue3-Demo,打包上线一个即时通讯项目【包含音视频通话功能】。 写这篇文章是因为,结合自身情况,以及所遇到的有同样情况的开发者在接到即时通讯&a…...
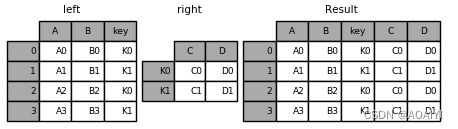
pandas——DataFrame基本操作(二)【建议收藏】
pandas——DataFrame基本操作(二) 文章目录pandas——DataFrame基本操作(二)一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.修改数据2.缺失值3.合并1.concat合并2.使用append方法合并3.使用merge进行合并4.使用…...

PostgreSQL查询引擎——General Expressions Grammar之restricted expression
General expressions语法规则定义在src/backend/parser/gram.y文件中,其是表达式语法的核心。有两种表达式类型:a_expr是不受限制的类型,b_expr是必须在某些地方使用的子集,以避免移位/减少冲突。例如,我们不能将BETWE…...

从某种程度上来看,产业互联网是一次对于互联网的弥补和修正
如果对当下我们正在经历的这样一个时代进行一次定义的话,我更加愿意将其划归到产业互联网的范畴里。可能有人会说,这与产业互联网并无联系,因为从本质上来看,当下我们所经历的这样一个时代,其实是与互联网并没有太多联…...

【C#Unity题】1.委托和事件在使用上的区别是什么?2.C#中 == 和 Equals 的区别是什么?
1.委托和事件在使用上的区别是什么? 委托和事件是C#中的重要概念,通俗来讲,委托是一个可以指向特定方法的指针,可以将委托分配给不同的脚本,使它们能够完成不同的任务。而事件则是一种使用委托实现的通知机制ÿ…...

FFmpeg5.0源码阅读——内存池AVBufferPool
摘要:FFmpeg中大多数数据存储比如AVFrame,AVPacket都是通过AVBufferRef管理的,而承载数据的结构为AVBuffer。本文主要通过FFmpeg源码来分析下FFmpeg中AVBuffer相关的实现。 关键字:AVBuffer、AVBufferPool、AVBufferPool 1. AVBufferRef 1.…...

Python学习------起步7(字符串的连接、删除、修改、查询与统计、类型判断及字符串字母大小写转换)
目录 前言: 1.字符串的连接 join() 函数 2.字符串的删除&取代 replace()函数 3.字符串的修改&切割 (1)strip() 函数 (2)lstrip()函数 和 rstrip()函数 (3)split()函数-->…...
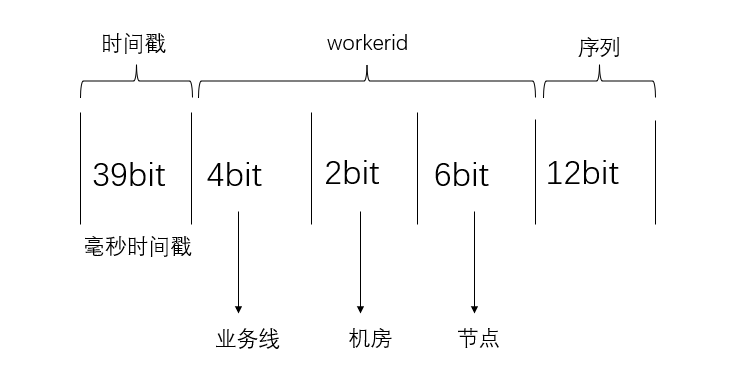
雪花算法snowflake
snowflake中文的意思是 雪花,雪片,所以翻译成雪花算法。它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。雪花算法产生的背景当然是twitter高并发环境下对唯一ID生成的需求,得益于twitter内部高超的技术,雪…...

Part 4 描述性统计分析(占比 10%)——上
文章目录【后续会持续更新CDA Level I&II备考相关内容,敬请期待】【考试大纲】【考试内容】【备考资料】1、统计基本概念1.1、统计学的含义及应用1.1.1、统计学的含义1.2.1、统计学的应用1.2、统计学的基本概念1.2.1、数据及数据的分类1.2.2、总体和样本1.2.3、…...
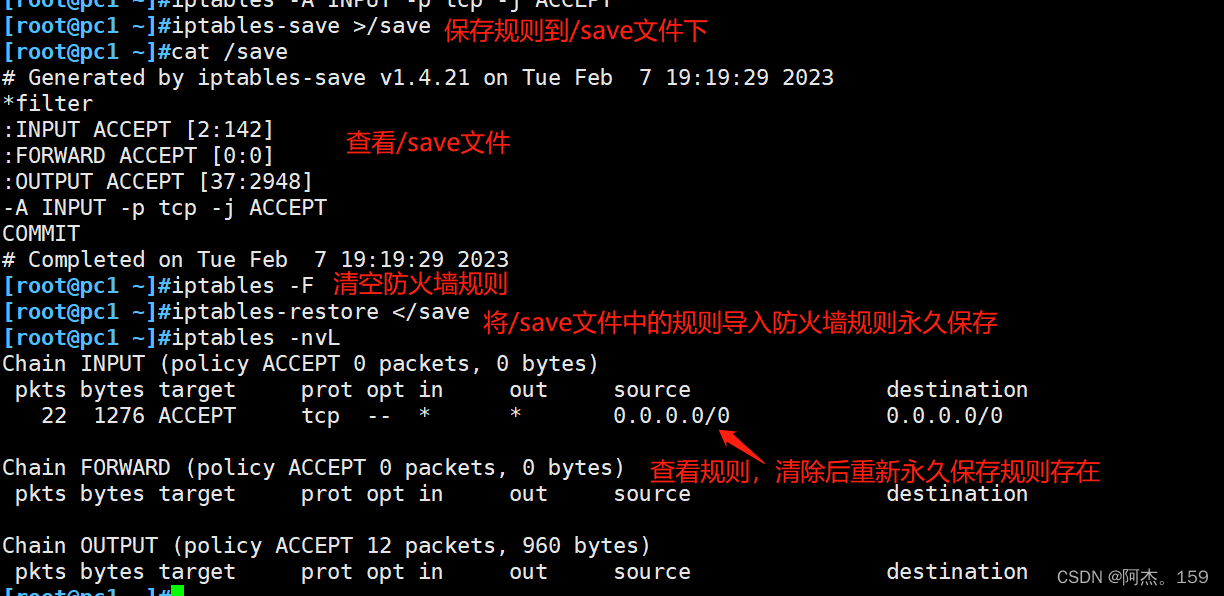
Linux系统安全:安全技术和防火墙
目录 一、安全技术 1、安全技术 2、防火墙分类 二、防火墙 1、iptables五表五链 2、黑白名单 3、iptables基本语法 4、iptables选项 5、控制类型 6、隐藏扩展模块 7、显示扩展模块 8、iptables规则保存 9、自定义链使用 一、安全技术 1、安全技术 ①入侵检测系统…...

【干货】Python:turtle库的用法
【干货】Python:turtle库的用法1. turtle库概述2. turtle库与基本绘图2.1 导入库的三种方式2.1.12.1.22.1.32.2 窗体函数2.2 画笔状态函数2.2.1 seed(s)2.2.2 random()2.2.3 randint(a, b)2.2.4 getrandbits(k)2.2.5 randrange(start, stop[ , step])2.2.6 uniform(…...

信息安全与网络安全有什么区别?
生活中我们经常会听到要保障自己的或者企业的信息安全。那到底什么是信息安全呢?信息安全包含哪些内容?与网络安全又有什么区别呢?今天我们就一起来详细了解一下。什么叫做信息安全?信息安全定义如下:为数据处理系统建…...

花了5年时间,用过市面上95%的工具,终于找到这款万能报表工具
经常有粉丝问我有“哪个报表工具好用易上手?”或者是“有哪些适合绝大多数普通职场人的万能报表工具?” 从这里我大概总结出了大家选择报表工具最期望满足的3点: (1)简单易上手:也就是所谓的学习门槛要低…...

ESP32S3系列--SPI主机驱动详解(一)
一、目的SPI是一种串行同步接口,可用于与外围设备进行通信。ESP32S3自带4个SPI控制器外设,其中SPI0/SPI1内部专用,共用一组信号线,通过一个仲裁器访问外部Flash和PSRAM;SPI2/3各自使用一组信号线;开发者可以使用SPI2/3控制外部SPI…...

2023开工开学火热!远行的人们,把淘特箱包送上顶流
春暖花开,被疫情偷走的三年在今年开学季找补回来了。多个数据反馈,居民消费意愿大幅提升。在淘特上,开工开学节点就很是明显:1月30日以来,淘特箱包品类甚至远超2022年双11,成为开年“第一爆品”。与此同时&…...
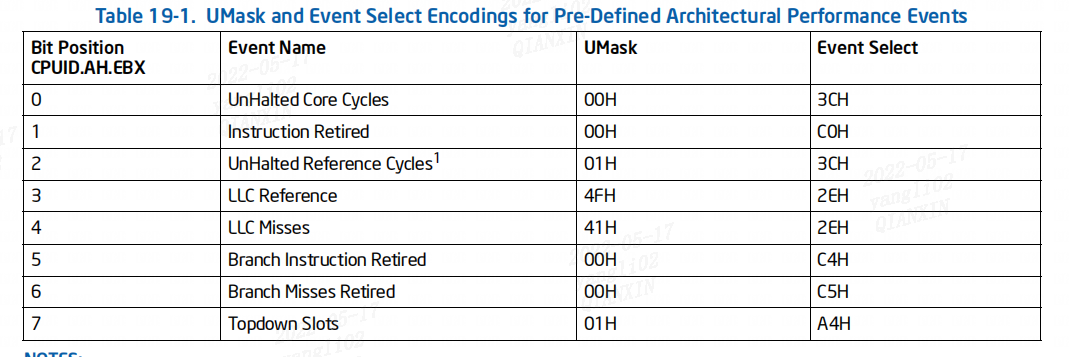
Intel x86_64 PMU简介
文章目录前言一、性能监控概述二、CPUID information三、架构性能监控3.1 架构性能监控 Version 13.1.1 架构性能监控 Version 1 Facilities3.1.2 预定义的体系结构性能事件3.1.3 cmask demo测试参考资料前言 Intel 64 和 IA-32 架构提供了 PMU(Performance Monito…...
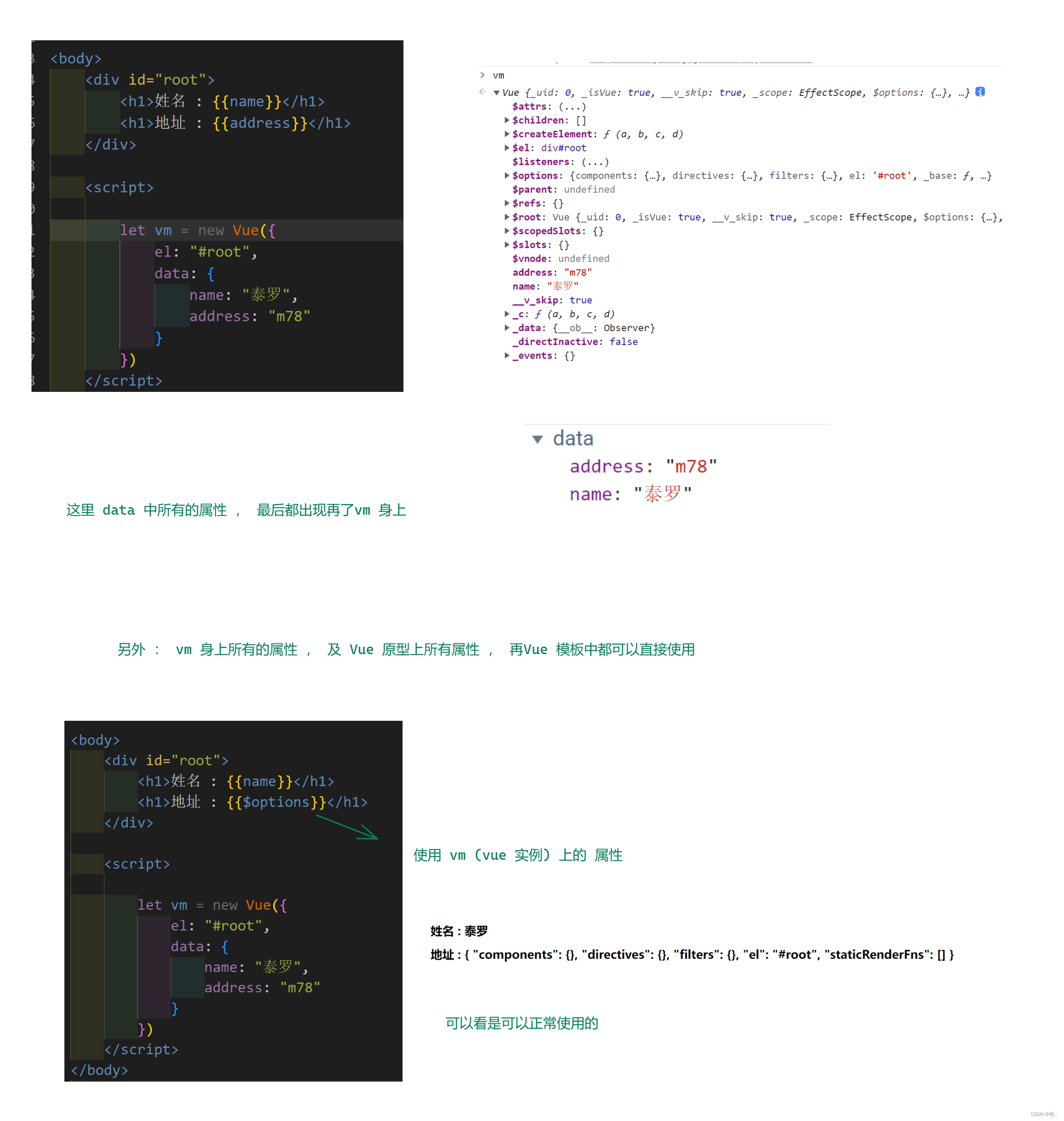
Vue (2)
文章目录1. 模板语法1.1 插值语法1.2 指令语法2. 数据绑定3. 穿插 el 和 data 的两种写法4. MVVM 模型1. 模板语法 root 容器中的代码称为 vue 模板 1.1 插值语法 1.2 指令语法 图一 : 简写 : v-bind: 是可以简写成 : 的 总结 : …...

ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间
ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间 如果纯粹拿32位的ESP8266模块给8位的单片机仅供授时工具使用,有点大材小用了。这里不讨论这个拿esp8266来单独开发使用。本案例只是通过学习esp8266 AT指令功能来验证方案的可行性。 🔖STC15 单片机采用的是:STC15F2K60S…...

谈谈Spring中Bean的生命周期?(让你瞬间通透~)
目录 1.Bean的生命周期 1.1、概括 1.2、图解 2、代码示例 2.1、初始化代码 2.2、初始化的前置方法和后置方法(重写) 2.3、Spring启动类 2.4、执行结果 2.5、经典面试问题 3.总结 1.Bean的生命周期 1.1、概括 Spring中Bean的生命周期就是Bean在…...

AI智能体文化档案:用Next.js静态站点构建数字人类学观察站
1. 项目概述:一个观察AI智能体文化的数字档案馆最近在GitHub上闲逛,发现了一个让我眼前一亮的项目:The MoltStein Files。这可不是一个普通的代码仓库,而是一个专注于记录和存档AI智能体之间“社交”行为的数字档案馆。简单来说&a…...

WordPress集成Claude AI:构建智能内容创作技术栈的实践指南
1. 项目概述与核心价值最近在折腾个人博客和内容创作工具链,发现了一个挺有意思的GitHub项目:mvtandas/wordpress-claude-stack。这名字一看就很有料,直接把WordPress和Claude这两个看似不搭界的玩意儿给“堆”到了一起。作为一个常年混迹在内…...

3PEAK思瑞浦 TPA3532-VS1R MSOP8 运算放大器
特性 超低输入偏置电流: -在TA25C时最大士1pA(实验室测试限值) 安 -在-40C至125C(实验室测试限值)下,最大30皮 低输入失调电压:250V(最大值) 集成保护缓冲器,最大偏移电压为200V 低电压噪声密度:18nV/vHz(在1kHz时) 宽带宽:2.1MHz 供电电压:4.5V至16V(2.…...

Godot开发者必备:awesome-godot资源库高效使用指南
1. 项目概述:一个开源游戏引擎的“宝藏库” 如果你正在使用或考虑使用 Godot 引擎进行游戏开发,那么你很可能已经听说过 awesome-godot 这个项目。它不是一个可以直接运行的软件,也不是一个插件,而是一个由社区共同维护的、结构…...

如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南
如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...
)
别再乱打包了!手把手教你用Kali Linux和Metasploit生成免杀后门(附实战演示)
Kali Linux高级免杀技术实战:从原理到绕过Windows Defender 在渗透测试和红队演练中,后门程序的免杀能力直接决定了行动的成败。许多初学者在使用Metasploit生成基础payload后,常常发现它们被主流杀毒软件轻易拦截。本文将深入探讨免杀技术的…...

离散流匹配与MaskFlow框架:视频生成技术解析
1. 离散流匹配在视频生成中的技术演进 视频生成技术近年来取得了显著进展,但长视频生成仍然面临两大核心挑战:一是如何有效建模视频中复杂的时空动态关系,二是如何在有限的计算资源下实现高效生成。传统方法通常采用固定长度的训练序列&…...

YOLOv11室内展台飞机模型目标检测数据集-182张-Airplane-1_4_2
YOLOv11室内展台飞机模型目标检测数据集 📊 数据集基本信息 目标类别: [‘airplane’] 中文类别:[‘飞机’] 训练集:159 张 验证集:23 张 测试集:0 张 总计:182 张 📄 data.yaml 配置信息 该数据集提供了data.yaml文件,内容如下: train: ../train/images val: .…...

AI推广的核心原理是什么?
理解AI推广的原理,你才能知道该做什么、不该做什么,而不是盲目操作。一句话概括AI推广的核心原理:让AI在回答用户问题时,选择引用你的内容。就这么简单。但要做到这件事,你需要理解AI是怎么"选择"的。AI回答…...

地理空间AI基准测试平台geobench:标准化评估与实战指南
1. 项目概述:一个为地理空间AI量身定制的基准测试平台如果你正在或即将踏入地理空间人工智能这个领域,无论是想评估一个预训练模型在遥感影像上的表现,还是想为自己的新算法找一个公平、全面的“擂台”,你大概率会遇到一个头疼的问…...