雪花算法snowflake
snowflake中文的意思是 雪花,雪片,所以翻译成雪花算法。它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。
雪花算法产生的背景当然是twitter高并发环境下对唯一ID生成的需求,得益于twitter内部高超的技术,雪花算法流传至今并被广泛使用。它至少有如下几个特点:
能满足高并发分布式系统环境下ID不重复
基于时间戳,可以保证基本有序递增(有些业务场景对这个又要求)
不依赖第三方的库或者中间件
生成效率极高
雪花算法原理

10位的数据机器位,所以可以部署在1024个节点。
12位的序列,在毫秒的时间戳内计数。支持每个节点每毫秒产生4096个ID序号,所以最大可以支持单节点大概四百万的并发量,这个妥妥的够用了。
雪花算法java实现
public class SnowflakeIdWorker {/** 开始时间截 (这个用自己业务系统上线的时间) */private final long twepoch = 1575365018000L;/** 机器id所占的位数 */private final long workerIdBits = 10L;/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */private final long maxWorkerId = -1L ^ (-1L << workerIdBits);/** 序列在id中占的位数 */private final long sequenceBits = 12L;/** 机器ID向左移12位 */private final long workerIdShift = sequenceBits;/** 时间截向左移22位(10+12) */private final long timestampLeftShift = sequenceBits + workerIdBits;/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */private final long sequenceMask = -1L ^ (-1L << sequenceBits);/** 工作机器ID(0~1024) */private long workerId;/** 毫秒内序列(0~4095) */private long sequence = 0L;/** 上次生成ID的时间截 */private long lastTimestamp = -1L;//==============================Constructors=====================================/*** 构造函数* @param workerId 工作ID (0~1024)*/public SnowflakeIdWorker(long workerId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("workerId can't be greater than %d or less than 0", maxWorkerId));}this.workerId = workerId;}// ==============================Methods==========================================/*** 获得下一个ID (该方法是线程安全的)* @return SnowflakeId*/public synchronized long nextId() {long timestamp = timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}//如果是同一时间生成的,则进行毫秒内序列if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if (sequence == 0) {//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}//时间戳改变,毫秒内序列重置else {sequence = 0L;}//上次生成ID的时间截lastTimestamp = timestamp;//移位并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) //| (workerId << workerIdShift) //| sequence;}/*** 阻塞到下一个毫秒,直到获得新的时间戳* @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间* @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}
}上面第一部分说到雪花算法的性能比较高,接下来我们测试下性能:
public static void main(String[] args) {SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1);long start = System.currentTimeMillis();int count = 0;for (int i = 0; System.currentTimeMillis()-start<1000; i++,count=i) {idWorker.nextId();}long end = System.currentTimeMillis()-start;System.out.println(end);System.out.println(count);}其可以产生400w+的id,效率还是相当高的。
调整比特位分布
很多公司会根据 snowflake 算法,根据自己的业务做二次改造。举个例子。你们公司的业务评估不需要运行69年,可能10年就够了。但是集群的节点可能会超过1024个,这种情况下,你就可以把时间戳调整成39bit,然后workerid调整为12比特。同时,workerid也可以拆分下,比如根据业务拆分或者根据机房拆分等。类似如下:
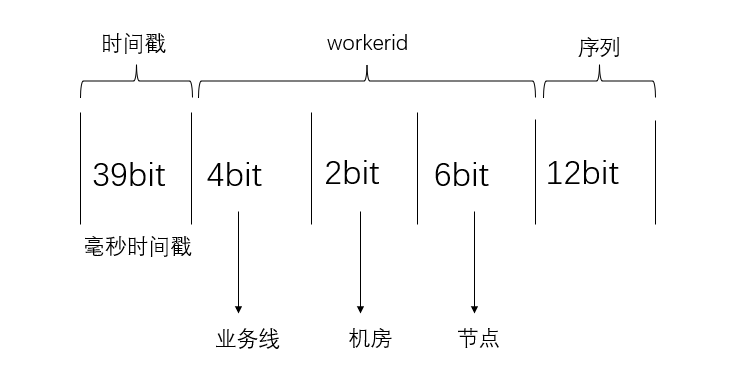
源码
twitter的雪花算法:https://github.com/twitter-archive/snowflake
相关文章:
雪花算法snowflake
snowflake中文的意思是 雪花,雪片,所以翻译成雪花算法。它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。雪花算法产生的背景当然是twitter高并发环境下对唯一ID生成的需求,得益于twitter内部高超的技术,雪…...

Part 4 描述性统计分析(占比 10%)——上
文章目录【后续会持续更新CDA Level I&II备考相关内容,敬请期待】【考试大纲】【考试内容】【备考资料】1、统计基本概念1.1、统计学的含义及应用1.1.1、统计学的含义1.2.1、统计学的应用1.2、统计学的基本概念1.2.1、数据及数据的分类1.2.2、总体和样本1.2.3、…...
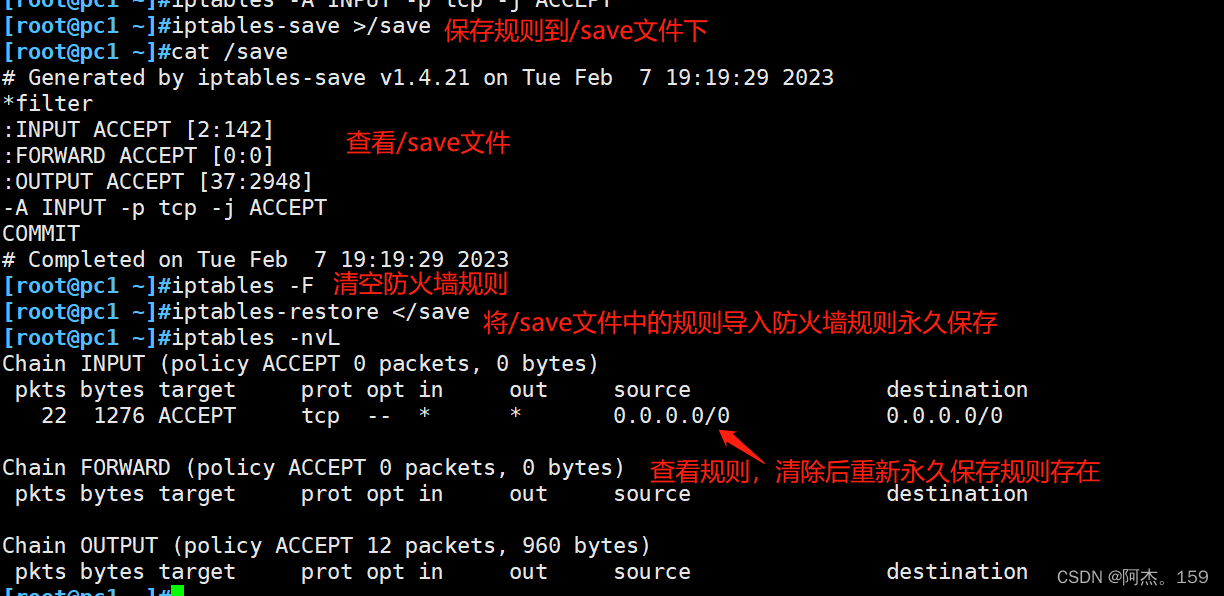
Linux系统安全:安全技术和防火墙
目录 一、安全技术 1、安全技术 2、防火墙分类 二、防火墙 1、iptables五表五链 2、黑白名单 3、iptables基本语法 4、iptables选项 5、控制类型 6、隐藏扩展模块 7、显示扩展模块 8、iptables规则保存 9、自定义链使用 一、安全技术 1、安全技术 ①入侵检测系统…...

【干货】Python:turtle库的用法
【干货】Python:turtle库的用法1. turtle库概述2. turtle库与基本绘图2.1 导入库的三种方式2.1.12.1.22.1.32.2 窗体函数2.2 画笔状态函数2.2.1 seed(s)2.2.2 random()2.2.3 randint(a, b)2.2.4 getrandbits(k)2.2.5 randrange(start, stop[ , step])2.2.6 uniform(…...

信息安全与网络安全有什么区别?
生活中我们经常会听到要保障自己的或者企业的信息安全。那到底什么是信息安全呢?信息安全包含哪些内容?与网络安全又有什么区别呢?今天我们就一起来详细了解一下。什么叫做信息安全?信息安全定义如下:为数据处理系统建…...

花了5年时间,用过市面上95%的工具,终于找到这款万能报表工具
经常有粉丝问我有“哪个报表工具好用易上手?”或者是“有哪些适合绝大多数普通职场人的万能报表工具?” 从这里我大概总结出了大家选择报表工具最期望满足的3点: (1)简单易上手:也就是所谓的学习门槛要低…...

ESP32S3系列--SPI主机驱动详解(一)
一、目的SPI是一种串行同步接口,可用于与外围设备进行通信。ESP32S3自带4个SPI控制器外设,其中SPI0/SPI1内部专用,共用一组信号线,通过一个仲裁器访问外部Flash和PSRAM;SPI2/3各自使用一组信号线;开发者可以使用SPI2/3控制外部SPI…...

2023开工开学火热!远行的人们,把淘特箱包送上顶流
春暖花开,被疫情偷走的三年在今年开学季找补回来了。多个数据反馈,居民消费意愿大幅提升。在淘特上,开工开学节点就很是明显:1月30日以来,淘特箱包品类甚至远超2022年双11,成为开年“第一爆品”。与此同时&…...
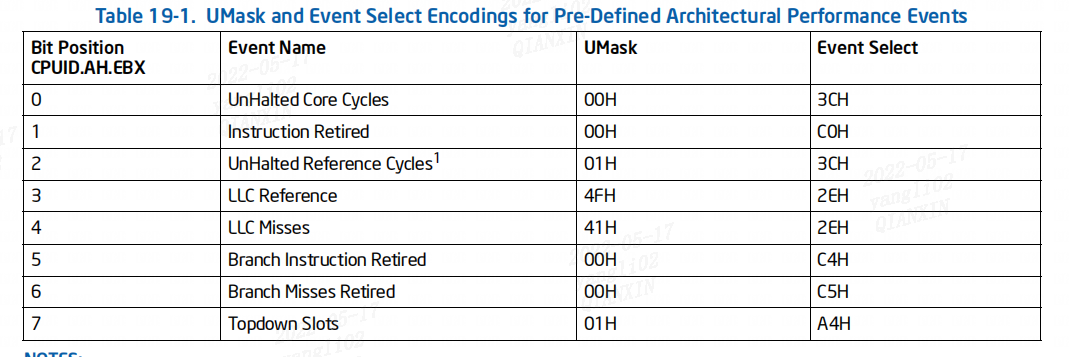
Intel x86_64 PMU简介
文章目录前言一、性能监控概述二、CPUID information三、架构性能监控3.1 架构性能监控 Version 13.1.1 架构性能监控 Version 1 Facilities3.1.2 预定义的体系结构性能事件3.1.3 cmask demo测试参考资料前言 Intel 64 和 IA-32 架构提供了 PMU(Performance Monito…...
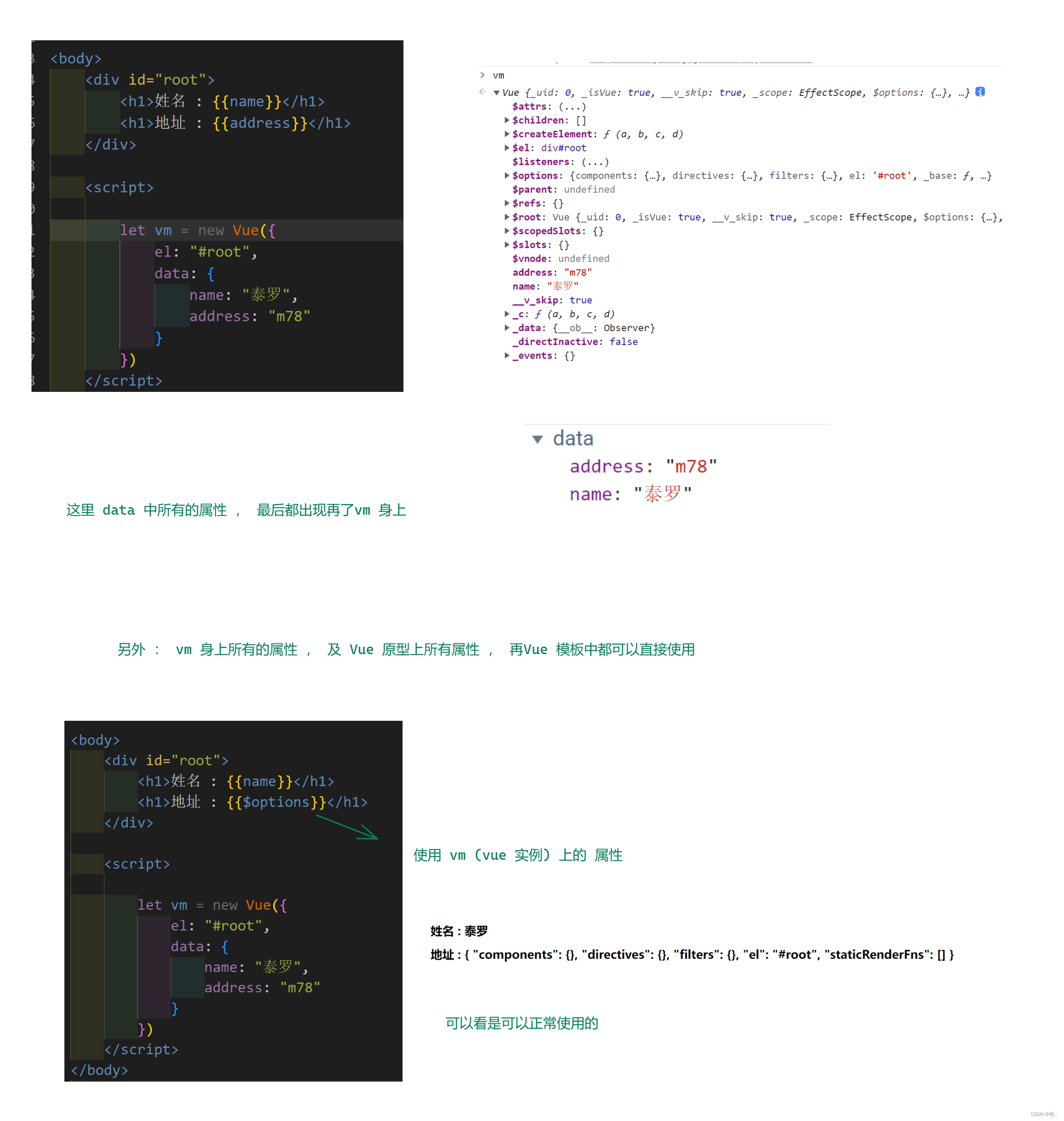
Vue (2)
文章目录1. 模板语法1.1 插值语法1.2 指令语法2. 数据绑定3. 穿插 el 和 data 的两种写法4. MVVM 模型1. 模板语法 root 容器中的代码称为 vue 模板 1.1 插值语法 1.2 指令语法 图一 : 简写 : v-bind: 是可以简写成 : 的 总结 : …...

ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间
ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间 如果纯粹拿32位的ESP8266模块给8位的单片机仅供授时工具使用,有点大材小用了。这里不讨论这个拿esp8266来单独开发使用。本案例只是通过学习esp8266 AT指令功能来验证方案的可行性。 🔖STC15 单片机采用的是:STC15F2K60S…...

谈谈Spring中Bean的生命周期?(让你瞬间通透~)
目录 1.Bean的生命周期 1.1、概括 1.2、图解 2、代码示例 2.1、初始化代码 2.2、初始化的前置方法和后置方法(重写) 2.3、Spring启动类 2.4、执行结果 2.5、经典面试问题 3.总结 1.Bean的生命周期 1.1、概括 Spring中Bean的生命周期就是Bean在…...
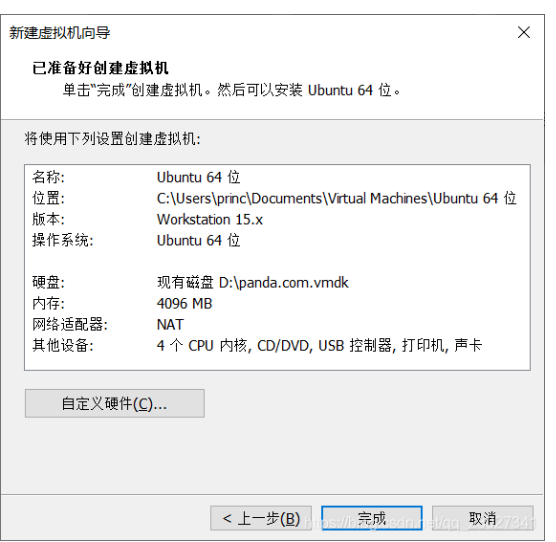
如何将VirtualBox虚拟机转换到VMware中
转换前的准备 首先需要你找到你的virtualbox以及VM安装到哪个文件夹里了,需要将这两个文件夹添加进环境变量Path中。 如果你记不清了,可以用everything全局搜索一下“VBoxManage.exe’以及“vmware-vdiskmanager.exe”,看一眼这个程序放到哪…...
)
洞庭龙梦(开发技巧和结构理论集)
1、经验来源,单一获取方式。进行形态等级展示。唯一游戏系统经验来源。无主线和支线剧情。2、玩家使用流通货币(充值货币),到玩家空间商城充值游戏,两人以上玩家进行游戏,掉落道具。交易系统游戏玩法&#…...

【23种设计模式】创建型模式详细介绍
前言 本文为 【23种设计模式】创建型模式详细介绍 相关内容介绍,下边具体将对单例模式,工厂方法模式,抽象工厂模式,建造者模式,原型模式,具体包括它们的特点与实现等进行详尽介绍~ 📌博主主页&…...

@Bean的处理流程,源码分析@Bean背后发生的事
文章目录写在前面关键类ConfigurationClassPostProcessor1、ConfigurationClassPostProcessor的注册2、ConfigurationClassPostProcessor的处理过程(1)parse方法中,Bean方法的处理(2)注册解析Bean标注的方法写在前面 …...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...