SpringBoot整合Canal
一 linux + docker compose版本
1.第一步:基础环境
(1)第1步:安装jak、maven、git、nodejs、npm
yum install maven mvn -v 安装maven时会帮安装jdkyum install git git --version 2.27.0yum install nodejs node -v v12.22.11yum install npm npm -v 6.14.16(2)第2步:安装docker
# 第1步:创建docker配置目录
mkdir /etc/docker# 第2步:创建配置文件
tee /etc/docker/daemon.json <<-'EOF'
{"debug": true,"storage-driver": "overlay2","storage-opts":["overlay2.override_kernel_check=true"],"graph":"/opt/docker","registry-mirrors": ["https://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://registry.docker-cn.com"]
}
EOF# 第3步:使用镜像源安装docker
dnf install docker# 第4步:启动docker
systemctl start docker# 第5步:开机自动启动
systemctl enable docker# 第6步:查看docker版本信息
docker info(3)第3步:安装docker compose
dnf install docker-compose(4)第四步:创建docker-compose.yml文件,并上传到linux
# 第一步:创建文件夹
mkdir test-canal# 第二步:创建docker-compose.yml文件
vim docker-compose.yml# 附:文件代码
version: "3"
services: mysql: network_mode: mynetwork container_name: mymysql ports: - 3306:3306 restart: always volumes: - /etc/localtime:/etc/localtime - /home/mycontainers/mymysql/data:/data - /home/mycontainers/mymysql/mysql:/var/lib/mysql - /home/mycontainers/mymysql/conf:/etc/mysql environment: - MYSQL_ROOT_PASSWORD=root command: --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --log-bin=/var/lib/mysql/mysql-bin --server-id=1 --binlog-format=ROW --expire_logs_days=7 --max_binlog_size=500M image: mysql:5.7.20 rabbitmq: container_name: myrabbit ports: - 15672:15672 - 5672:5672 restart: always volumes: - /etc/localtime:/etc/localtime - /home/mycontainers/myrabbit/rabbitmq:/var/lib/rabbitmq network_mode: mynetwork environment: - RABBITMQ_DEFAULT_USER=admin - RABBITMQ_DEFAULT_PASS=123456 image: rabbitmq:3.8-management canal-server: container_name: canal-server restart: always ports: - 11110:11110 - 11111:11111 - 11112:11112 volumes: - /home/mycontainers/canal-server/conf:/home/admin/canal-server/conf - /home/mycontainers/canal-server/logs:/home/admin/canal-server/logs network_mode: mynetwork depends_on: - mysql - rabbitmq # - canal-admin image: canal/canal-server:v1.1.5 2.第二步:配置Canal
我们需要修改下Canal环境的配置文件:canal.properties和instance.properties,映射Canal中的以下两个路径:
-
/home/admin/canal-server/conf/canal.properties。其中canal.destinations意思是server上部署的instance列表, -
/home/admin/canal-server/conf/example/instance.properties。这里的/example是指instance即实例名,要和上面canal.properties内instance配置对应,canal会为实例创建对应的文件夹,一个Client对应一个实例
以下是我们需要准备的两个配置文件具体内容:
(1)第1步:创建canal.properties,并上传到指定位置
# 第一步:创建配置文件所在的目录
mkdir -p /home/admin/canal-server/conf# 第二步:把配置文件上传到下面的目录
cd /home/admin/canal-server/conf附:文件内容
################################################
######## common argument ############
################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # canal admin config
# canal.admin.manager = canal-admin:8089 # canal.admin.port = 11110
# canal.admin.user = admin
# canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 # admin auto register 自动注册
# canal.admin.register.auto = true
# 集群名,单机则不写
# canal.admin.register.cluster =
# Canal Server 名字
# canal.admin.register.name = canal-admin canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
# memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
# memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
# meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true # detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 # network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30 # binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false # binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation
canal.instance.get.ddl.isolation = false # parallel parser config
canal.instance.parser.parallel = true
# concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
canal.instance.parser.parallelThreadSize = 16
# disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360 ################################################
######## destinations ############
################################################
canal.destinations = canal-exchange
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml #################################################
######## MQ Properties ############
#################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid= canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8 #################################################
######## RabbitMQ ############
#################################################
rabbitmq.host = myrabbit
rabbitmq.virtual.host = /
rabbitmq.exchange = canal-exchange
rabbitmq.username = admin
rabbitmq.password = RabbitMQ密码 此时canal.serverMode = tcp,即TCP直连,我们先开启这个服务,然后手写Java客户端代码去连接它,等下再改为RabbitMQ。
通过注释可以看到,canal支持的服务模式有:tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ,即主流的消息队列都支持
(2)第2步:创建instance.properties,并上传到指定位置
# 第一步:创建配置文件所在的目录
mkdir -p /home/admin/canal-server/conf/example# 第二步:把配置文件上传到下面的目录
cd /home/admin/canal-server/conf/example附:文件内容
################################################
# mysql serverId , v1.0.26+ will autoGen
#canal.instance.mysql.slaveId=123 # enable gtid use true/false
canal.instance.gtidon=false # position info
canal.instance.master.address=mymysql:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid= # rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId= # table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid= # username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex
canal.instance.filter.regex=.*\..*
# table black regex
canal.instance.filter.black.regex=mysql\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config
canal.mq.topic=canal-routing-key
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\..*,.*\..*
canal.mq.partition=0 把这两个配置文件映射好,再次提醒,注意实例的路径名,默认是:/example/instance.properties
(3)第3步:修改canal配置文件
我们需要修改这个实例配置文件,去连接MySQL,确保以下的配置正确:
canal.instance.master.address=mymysql:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
mymysql是同为docker容器的MySQL环境,端口3306是指内部端口。
这里多说明一下,docker端口配置时假设为:13306:3306,那么容器对外的端口就是13306,内部是3306,在本示例中,MySQL和Canal都是容器环境,所以Canal连接MySQL需要满足以下条件:
-
处于同一网段(docker-compose.yml中的mynetwork)
-
访问内部端口(即3306,而非13306)
dbUsername和dbPassword为MySQL账号密码,为了开发方便可以使用root/root,但是我仍建议自行创建用户并分配访问权限:
# 进入docker中的mysql容器
docker exec -it mymysql bash
# 进入mysql指令模式
mysql -uroot -proot # 编写MySQL语句并执行
> ...
-- 选择mysql
use mysql;
-- 创建canal用户,账密:canal/canal
create user 'canal'@'%' identified by 'canal';
-- 分配权限,以及允许所有主机登录该用户
grant SELECT, INSERT, UPDATE, DELETE, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%'; -- 刷新一下使其生效
flush privileges; -- 附带一个删除用户指令
drop user 'canal'@'%';
用navicat或者shell去登录canal这个用户,可以访问即创建成功
(4)第4步:启动,它将尝试自动完成包括构建镜像,(重新)创建服务,启动服务,并关联服务相关容器的一系列操作。
# 第一步:仓库网络
docker network create mynetwork
# 第二步:启动
sudo docker-compose -f /home/test-canal/docker-compose.yml up -d
(5)第5步:开放端口
最近使用 OpenEuler 部署项目,发现防火墙放通端口的方法找不到,因此在这里记录:
# firewall-cmd --query-port=8084/tcp --permanent
no
# firewall-cmd --add-port=8084/tcp --permanent
success
# firewall-cmd --reload
success
# firewall-cmd --query-port=8084/tcp --permanent
3.第三步:整合SpringBoot Canal实现客户端
(1)第1步:idea新建一个spring boot项目


有必要的话降低spring boot的版本:
(2)第2步:Maven依赖:
<canal.version>1.1.5</canal.version> <!--canal-->
<dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>${canal.version}</version>
</dependency>
<dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.protocol</artifactId> <version>${canal.version}</version>
</dependency> (3)第3步:新增组件并启动:
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component; import java.net.InetSocketAddress;
import java.util.List; @Component
public class CanalClient { private final static int BATCH_SIZE = 1000; public void run() { // 创建链接 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "canal-exchange", "canal", "canal"); try { //打开连接 connector.connect(); //订阅数据库表,全部表 connector.subscribe(".*..*"); //回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿 connector.rollback(); while (true) { // 获取指定数量的数据 Message message = connector.getWithoutAck(BATCH_SIZE); //获取批量ID long batchId = message.getId(); //获取批量的数量 int size = message.getEntries().size(); //如果没有数据 if (batchId == -1 || size == 0) { try { //线程休眠2秒 Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } else { //如果有数据,处理数据 printEntry(message.getEntries()); } //进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。 connector.ack(batchId); } } catch (Exception e) { e.printStackTrace(); } finally { connector.disconnect(); } } /** * 打印canal server解析binlog获得的实体类信息 */ private static void printEntry(List<CanalEntry.Entry> entrys) { for (CanalEntry.Entry entry : entrys) { if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) { //开启/关闭事务的实体类型,跳过 continue; } //RowChange对象,包含了一行数据变化的所有特征 //比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等 CanalEntry.RowChange rowChage; try { rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR # parser of eromanga-event has an error , data:" + entry.toString(), e); } //获取操作类型:insert/update/delete类型 CanalEntry.EventType eventType = rowChage.getEventType(); //打印Header信息 System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); //判断是否是DDL语句 if (rowChage.getIsDdl()) { System.out.println("================》;isDdl: true,sql:" + rowChage.getSql()); } //获取RowChange对象里的每一行数据,打印出来 for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) { //如果是删除语句 if (eventType == CanalEntry.EventType.DELETE) { printColumn(rowData.getBeforeColumnsList()); //如果是新增语句 } else if (eventType == CanalEntry.EventType.INSERT) { printColumn(rowData.getAfterColumnsList()); //如果是更新的语句 } else { //变更前的数据 System.out.println("------->; before"); printColumn(rowData.getBeforeColumnsList()); //变更后的数据 System.out.println("------->; after"); printColumn(rowData.getAfterColumnsList()); } } } } private static void printColumn(List<CanalEntry.Column> columns) { for (CanalEntry.Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); } }
} (4)第4步:启动类Application:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class CanalDemoApplication extends CommandLineRunner {@Autowiredprivate CanalClient canalClient;@Overridepublic void run(String... args) throws Exception {canalClient.run();}public static void main(String[] args) {SpringApplication.run(CanalDemoApplication.class, args);}}
4.第四步:测试
启动程序,此时新增或修改数据库中的数据,我们就能从客户端中监听到
5.报错
(1)【gpt】ERROR: for mymysql Cannot start service mysql: network mynetwork not found
这个错误提示表明 Docker 容器无法找到名为 "mynetwork" 的网络。可能是由于以下几个原因导致的:
-
你没有创建名为 "mynetwork" 的 Docker 网络。在运行容器之前,需要先创建一个自定义网络。你可以使用以下命令创建一个自定义网络:
docker network create mynetwork然后再尝试启动
mysql服务。 -
如果你已经创建了 "mynetwork" 网络,但是它位于不同的 Docker 主机上,或者由于某种原因被删除了,那么容器将无法找到该网络。请确保网络存在,并且与运行
mysql容器的主机关联。 -
可能是 Docker daemon 没有正确配置网络驱动程序,导致无法创建网络。你可以尝试重启 Docker 服务,或者检查 Docker 配置文件以确保网络驱动程序配置正确。
如果以上方法都没有解决问题,可以提供更多关于你的环境和具体操作的信息,以便更好地帮助你解决问题。
(2)ERROR: for canal-server Cannot start service canal-server: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error mounting "/home/mycontainers/canal-server/conf/canal.properties" to rootfs at "/home/admin/canal-server/conf/canal.properties": mount /home/mycontainers/canal-server/conf/canal.properties:/home/admin/canal-server/conf/canal.properties (via /proc/self/fd/6), flags: 0x5000: not a directory: unknown: Are you trying to mount a directory onto a file (or vice-versa)? Check if the specified host path exists and is the expected type
volumes:
- /home/mycontainers/canal-server/conf/canal.properties:/home/admin/canal-server/conf/canal.properties
- /home/mycontainers/canal-server/conf/instance.properties:/home/admin/canal-server/conf/example/instance.properties
- /home/mycontainers/canal-server/logs:/home/admin/canal-server/logs
改为
volumes:
- /home/mycontainers/canal-server/conf:/home/admin/canal-server/conf
- /home/mycontainers/canal-server/logs:/home/admin/canal-server/logs
参考:
1. SpringBoot整合Canal+RabbitMQ监听数据变更~ (qq.com)
2. 实战!基于canal同步mysql数据到elasticsearch - 知乎 (zhihu.com)
相关文章:
SpringBoot整合Canal
一 linux docker compose版本 1.第一步:基础环境 (1)第1步:安装jak、maven、git、nodejs、npm yum install maven mvn -v 安装maven时会帮安装jdkyum install git git --version 2.27.0yum in…...

用 Python 提取某一个公众号下的所有文章
当我们想要提取某一个公众号下的所有文章时,我们可以借助微信公众平台的开放接口,通过Python编写一个爬虫程序来实现。下面是一个示例代码,以及如何将其转化为一篇详细的微信公众号推文文章。 1. 导入所需库 首先,我们需要导入所…...
鸿蒙4.0实战教学—基础ArkTS(简易视频播放器)
构建主界面 主界面由视频轮播模块和多个视频列表模块组成,效果图如图: VideoData.ets中定义的视频轮播图数组SWIPER_VIDEOS和视频列表图片数组HORIZONTAL_VIDEOS。 // VideoData.ets import { HorizontalVideoItem } from ./HorizontalVideoItem; impo…...

4. 深入 Python 流程控制
4. 深入 Python 流程控制 除了前面介绍的 while 语句,Python 还从其它语言借鉴了一些流程控制功能,并有所改变。 4.1. if 语句 也许最有名的是 if 语句。例如: >>> x int(raw_input("Please enter an integer: "))…...

2000-2022年上市公司股票流动性指标数据/股票流动性Amihud(原始数据+计算代码+计算结果)
2000-2022年上市公司股票流动性指标数据/股票流动性Amihud(原始数据计算代码计算结果) 1、时间:2000-2022年 3、指标:证券代码_没有单位、交易日期_没有单位、日个股交易金额_元、考虑现金红利再投资的日个股回报率_没有单位、交…...

Unity 数据存储PlayerPrefs管理类
Unity 数据存储PlayerPrefs管理类 Unity 数据存储PlayerPrefs管理类实现存取实体类对象存储格式为Json格式Singleton.csInventoryEntity.csDataManager.cs用法如下 Unity 数据存储PlayerPrefs管理类 实现存取实体类对象 存储格式为Json格式 源码如下: Singleton…...

一篇文章学会如何使用 NestJS 过滤器处理系统全局异常情况
前言 在实际的应用开发中,你或许遇到过异常处理机制不统一或错误信息展示混乱的现象。为了解决这些问题,NestJS提供了一个优雅的解决方案:过滤器(Filter)。本文将从实际出发,向你介绍NestJS过滤器的基本概…...

ubuntu 守护进程 supervisor
# 安装 apt-get install supervisor# 检查 echo_supervisord_conf# 查看配置文件所在位置 # [include] # files /etc/supervisor/conf.d/*.conf ps -ef | grep supervisorcd /etc/supervisor/conf.d/lscat frp.conf[program:frp] command /data/work/frp/frpc -c /data/work/…...
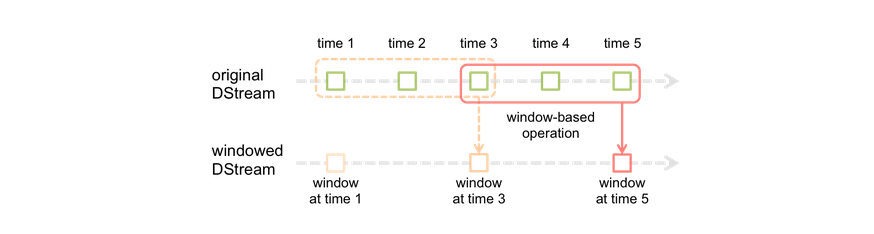
SparkStreaming_window_sparksql_reids
1.5 window 滚动窗口滑动窗口 window操作就是窗口函数。Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会…...

爬虫工作量由小到大的思维转变---<第二十四章 Scrapy的`统计数据`收集stats collection ---12月26日补>
前言: 前两篇是讲的数据诊断分析,还有一篇深挖解决内存泄漏的文章,目前我还没整理汇编出来;但是,想到分析问题的时候,忽然觉得爬虫的数据统计好像也挺重要;于是,心血来潮准备来插一篇这个------让大家对日常scrapy爬的数据,做到心里有数!不必自己去搅破脑汁捣腾日志,敲计算器了…...
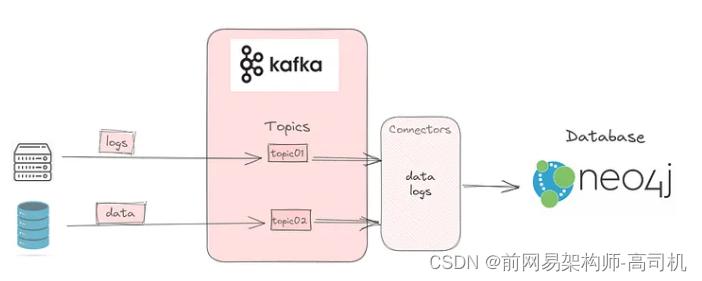
Kafka:本地设置
这是设置 Kafka 将数据从 Elasticsearch 发布到 Kafka 主题的三部分系列的第一部分;该主题将被 Neo4j 使用。第一部分帮助您在本地设置 Kafka。第二部分将讨论如何设置Elasticsearch将数据发布到Kafka主题。最后 将详细介绍如何使用连接器订阅主题并使用数据。 Kafka Kafka 是…...
.NetCore NPOI 读取excel内容及单元格内图片
由于数据方提供的数据在excel文件中不止有文字内容还包含图片信息,于是编写相关测试代码,读取excel文件内容及图片信息. 本文使用的是 NPOI-2.6.2 版本,此版本持.Net4.7.2;.NetStandard2.0;.NetStandard2.1;.Net6.0。 测试文档内容…...

TCP/UDP协议
1. 请解释TCP和UDP的主要区别。 TCP和UDP都是位于传输层的协议,具有不同的特点和应用场景。以下是它们的主要区别: 连接方式:TCP是面向连接的协议,这意味着在数据传输之前需要先建立连接。这通常通过三次握手来建立连接ÿ…...

3D 渲染如何帮助电商促进销售?
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 3D 渲染图像因其高转化率而成为亚马逊卖家的最新趋势。它是电子商务平…...

使用栈求表达式的值【数据结构】
中缀表达式转后缀表达式 转换流程: 初始化一个运算符栈。自左向右扫描中缀表达式,当扫描到操作数时直接连接到后缀表达式上。当扫描到操作符时,和运算符栈栈顶的操作符进行比较。如果比栈顶运算符高,则入栈。如果比栈顶运算符低…...
{MySQL}索引事务和JDBC
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、索引1.1索引是什么1.2作用1.3代码 二、事务2.1什么是事务2.2使用 三.JDBC总结 前言 接着上次,继续讲下MySQL 提示:以下是本篇文章正…...

Qt designer界面和所有组件功能的详细介绍(全!!!)
PyQt5和Qt designer的详细安装教程:https://blog.csdn.net/qq_43811536/article/details/135185233?spm1001.2014.3001.5501 目录 1. 界面介绍2. Widget Box 常用组件2.1 Layouts(布局)2.2 Spacers(间隔器)2.3 Item V…...

mysql_存储过程
举例子 createdefiner root% procedure insert_batch_test(IN START int(10), IN max_num int(10)) BEGINDECLAREi INT DEFAULT 0;SET autocommit 0;REPEATSET i i 1;INSERT INTO test (std, score)VALUES (CEILING(RAND() * 10 100), CEILING(RAND() * 50 50));UNTIL i …...

uboot学习及内核更换_incomplete
官方文档 在前面 文章目录 uboot常见命令学习环境变量网络控制台uboot标准启动其他 升级uboot或内核bin和uimg以及booti和bootm的区别制作uImage更换内核更换uboot后续计划 uboot常见命令学习 环境变量 Environment Variables环境变量 autostart 如果值为yes,则会…...
KVM 自动化脚本的使用及热/冷迁移
一、介绍 目录结构介绍 [rootkvm-server kvm]# tree -L 2 . ├── control # 控制脚本目录 │ ├── KVMInstall.sh # kvm服务安装脚本 │ ├── VMHost.sh # kvm虚拟机克隆脚本 │ └── VMTemplate.sh # kvm模板机安装脚本 ├── mount # 此目录保持为空&…...

软件开发加速安全审查滞后:“查找 - 修复”与“防御 - 推迟”难敌新风险!
ZDNET的关键要点持续部署让旧安全模型过时,漏洞积压令开发团队不堪重负,应用程序安全需向代码创建阶段转移。锻炼时在跑步机上反复踏步,付出努力却原地不动,毫无成就感,第二天再重复就更觉沮丧。应用程序安全也类似&am…...

Python内置模块:io、file、json、csv
一、io StringIO - 文本字符串的缓冲区 from io import StringIO# 创建StringIO对象 sio StringIO() # 空缓冲区 sio StringIO("initial text") # 带初始数据# 常用方法 sio.write("Hello ") # 写入字符串&…...

React Native跨平台AI聊天应用开发实战:架构设计与性能优化
1. 项目概述:一个全功能的跨平台AI聊天伴侣如果你和我一样,既是移动端开发者,又是AI应用的深度用户,那么你肯定经历过这样的困境:想在手机上随时随地、流畅地和ChatGPT对话,却发现官方App要么功能受限&…...

开源项目metabase-mcp-server:用MCP协议连接Metabase与AI智能体,实现对话式数据分析
1. 项目概述:当开源BI工具遇上AI智能体如果你和我一样,在日常工作中既要用Metabase做数据可视化看板,又要和Claude、Cursor这类AI助手打交道,那你肯定也遇到过这样的痛点:想问问AI“上个月华东区的销售额趋势”&#x…...

高速SerDes设计中BER预测的智能应力输入方法
1. 高速串行链路设计中的BER预测挑战在当今高速数字系统设计中,SerDes(串行器/解串器)技术已成为主流接口方案,数据传输速率已突破10Gbps大关。随着速率提升,信号完整性(SI)问题日益突出,其中误码率(BER)预…...

芯片晶圆平面度如何测量?半导体制造中的光学形貌检测方案
晶圆作为集成电路的核心承载基片,表面形貌的精度直接关系到光刻聚焦质量、芯片电学性能及最终良率。从8英寸到12英寸的大尺寸晶圆制造中,平面度、翘曲度(Warp)、总厚度变化(TTV)及局部平面度(SF…...
研究(Matlab代码实现))
【CPO三维路径规划】豪猪算法CPO多无人机协同集群避障路径规划(目标函数:最低成本:路径、高度、威胁、转角)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

网安信息收集
声明:任何个人和组织不得从事非法侵入他人网络、干扰他人网络正常功能、窃取网络数据等危害网络安全 的活动;不得提供专门用于从事侵入网络、干扰网络正常功能及防护措施、窃取网络数据等危害网络安全活动的程序、工具;明知他人从事危害网络安…...

Cursor Pro免费升级完整指南:3分钟突破使用限制的实用教程
Cursor Pro免费升级完整指南:3分钟突破使用限制的实用教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

STM32F103C8T6与DHT11单总线通信:从时序解析到数据校验的实战指南
1. 认识STM32F103C8T6与DHT11这对黄金搭档 第一次接触嵌入式开发的朋友可能会觉得,让单片机读取温湿度数据是个复杂的事情。但当你用STM32F103C8T6这颗性价比超高的Cortex-M3内核芯片,搭配DHT11这个经典温湿度传感器时,事情就变得简单多了。…...