SparkStreaming_window_sparksql_reids
1.5 window
滚动窗口+滑动窗口
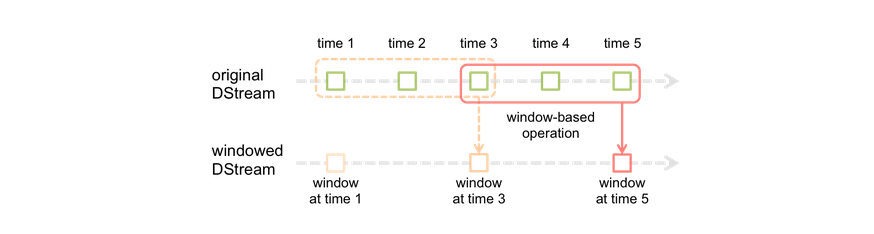
window操作就是窗口函数。Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
-
红色的矩形就是一个窗口,窗口hold的是一段时间内的数据流。
-
这里面每一个time都是时间单元,在官方的例子中,每隔window size是3 time unit, 而且每隔2个单位时间,窗口会slide一次。
所以基于窗口的操作,需要指定2个参数:
window length - The duration of the window (3 in the figure)
slide interval - The interval at which the window-based operation is performed (2 in the figure).
-
窗口大小,个人感觉是一段时间内数据的容器。
-
滑动间隔,就是我们可以理解的cron表达式吧。
案例实现
package com.qianfeng.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*** 统计,截止到目前为止出现的每一个key的次数* window窗口操作,每个多长M时间,通过过往N长时间内产生的数据* M就是滑动长度sliding interval* N就是窗口长度window length*/
object Demo05_WCWithWindow {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("WordCountUpdateStateByKey").setMaster("local[*]")val batchInterval = 2val duration = Seconds(batchInterval)val ssc = new StreamingContext(conf, duration)val lines:DStream[String] = ssc.socketTextStream("qianfeng01", 6666)val pairs:DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_, 1))
val ret:DStream[(String, Int)] = pairs.reduceByKeyAndWindow(_+_,windowDuration = Seconds(batchInterval * 3),slideDuration = Seconds(batchInterval * 2))
ret.print()
ssc.start()ssc.awaitTermination()}
}
1.6 SparkSQL和SparkStreaming的整合案例
Spark最强大的地方在于,可以与Spark Core、Spark SQL整合使用,之前已经通过transform、foreachRDD等算子看到,如何将DStream中的RDD使用Spark Core执行批处理操作。现在就来看看,如何将DStream中的RDD与Spark SQL结合起来使用。
案例:top3的商品排序: 最新的top3
这里就是基于updatestateByKey,统计截止到目前为止的不同品类下的商品销量top3
代码实现
package com.qianfeng.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/*** SparkStreaming整合SparkSQL的案例之,热门品类top3排行* 输入数据格式:* id brand category* 1 huwei watch* 2 huawei phone**/
object Demo06_SQLWithStreaming {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("StreamingIntegerationSQL").setMaster("local[*]")val batchInterval = 2val duration = Seconds(batchInterval)val spark = SparkSession.builder().config(conf).getOrCreate()val ssc = new StreamingContext(spark.sparkContext, duration)ssc.checkpoint("/Users/liyadong/data/sparkdata/streamingdata/chk-1")val lines:DStream[String] = ssc.socketTextStream("qianfeng01", 6666)//001 mi moblieval pairs:DStream[(String, Int)] = lines.map(line => {val fields = line.split("\\s+")if(fields == null || fields.length != 3) {("", -1)} else {val brand = fields(1)val category = fields(2)(s"${category}_${brand}", 1)}}).filter(t => t._2 != -1)
val usb:DStream[(String, Int)] = pairs.updateStateByKey(updateFunc)
usb.foreachRDD((rdd, bTime) => {if(!rdd.isEmpty()) {//category_brand countimport spark.implicits._val df = rdd.map{case (cb, count) => {val category = cb.substring(0, cb.indexOf("_"))val brand = cb.substring(cb.indexOf("_") + 1)(category, brand, count)}}.toDF("category", "brand", "sales")
df.createOrReplaceTempView("tmp_category_brand_sales")val sql ="""|select| t.category,| t.brand,| t.sales,| t.rank|from (| select| category,| brand,| sales,| row_number() over(partition by category order by sales desc) rank| from tmp_category_brand_sales|) t|where t.rank < 4|;""".stripMarginspark.sql(sql).show()}})
ssc.start()ssc.awaitTermination()}
def updateFunc(seq: Seq[Int], option: Option[Int]): Option[Int] = {Option(seq.sum + option.getOrElse(0))}
}
1.7 SparkStreaming整合Reids
//将实时结果写入Redis中
dStream.foreachRDD((w,c)=>{val jedis = new Jedis("192.168.10.101", 6379) //抽到公共地方即可jedis.auth("root")jedis.set(w.toString(),c.toString()) //一个key对应多个值,可以考虑hset
})Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客
相关文章:
SparkStreaming_window_sparksql_reids
1.5 window 滚动窗口滑动窗口 window操作就是窗口函数。Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会…...

爬虫工作量由小到大的思维转变---<第二十四章 Scrapy的`统计数据`收集stats collection ---12月26日补>
前言: 前两篇是讲的数据诊断分析,还有一篇深挖解决内存泄漏的文章,目前我还没整理汇编出来;但是,想到分析问题的时候,忽然觉得爬虫的数据统计好像也挺重要;于是,心血来潮准备来插一篇这个------让大家对日常scrapy爬的数据,做到心里有数!不必自己去搅破脑汁捣腾日志,敲计算器了…...
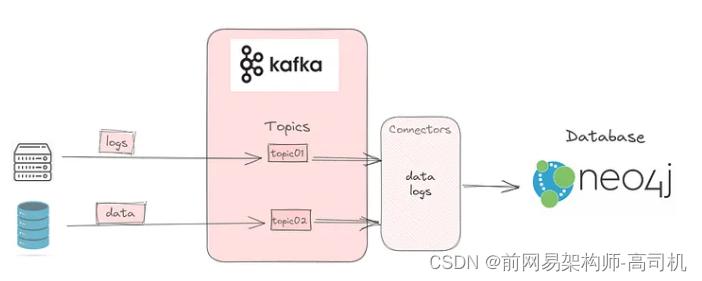
Kafka:本地设置
这是设置 Kafka 将数据从 Elasticsearch 发布到 Kafka 主题的三部分系列的第一部分;该主题将被 Neo4j 使用。第一部分帮助您在本地设置 Kafka。第二部分将讨论如何设置Elasticsearch将数据发布到Kafka主题。最后 将详细介绍如何使用连接器订阅主题并使用数据。 Kafka Kafka 是…...
.NetCore NPOI 读取excel内容及单元格内图片
由于数据方提供的数据在excel文件中不止有文字内容还包含图片信息,于是编写相关测试代码,读取excel文件内容及图片信息. 本文使用的是 NPOI-2.6.2 版本,此版本持.Net4.7.2;.NetStandard2.0;.NetStandard2.1;.Net6.0。 测试文档内容…...

TCP/UDP协议
1. 请解释TCP和UDP的主要区别。 TCP和UDP都是位于传输层的协议,具有不同的特点和应用场景。以下是它们的主要区别: 连接方式:TCP是面向连接的协议,这意味着在数据传输之前需要先建立连接。这通常通过三次握手来建立连接ÿ…...

3D 渲染如何帮助电商促进销售?
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 3D 渲染图像因其高转化率而成为亚马逊卖家的最新趋势。它是电子商务平…...

使用栈求表达式的值【数据结构】
中缀表达式转后缀表达式 转换流程: 初始化一个运算符栈。自左向右扫描中缀表达式,当扫描到操作数时直接连接到后缀表达式上。当扫描到操作符时,和运算符栈栈顶的操作符进行比较。如果比栈顶运算符高,则入栈。如果比栈顶运算符低…...
{MySQL}索引事务和JDBC
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、索引1.1索引是什么1.2作用1.3代码 二、事务2.1什么是事务2.2使用 三.JDBC总结 前言 接着上次,继续讲下MySQL 提示:以下是本篇文章正…...

Qt designer界面和所有组件功能的详细介绍(全!!!)
PyQt5和Qt designer的详细安装教程:https://blog.csdn.net/qq_43811536/article/details/135185233?spm1001.2014.3001.5501 目录 1. 界面介绍2. Widget Box 常用组件2.1 Layouts(布局)2.2 Spacers(间隔器)2.3 Item V…...

mysql_存储过程
举例子 createdefiner root% procedure insert_batch_test(IN START int(10), IN max_num int(10)) BEGINDECLAREi INT DEFAULT 0;SET autocommit 0;REPEATSET i i 1;INSERT INTO test (std, score)VALUES (CEILING(RAND() * 10 100), CEILING(RAND() * 50 50));UNTIL i …...

uboot学习及内核更换_incomplete
官方文档 在前面 文章目录 uboot常见命令学习环境变量网络控制台uboot标准启动其他 升级uboot或内核bin和uimg以及booti和bootm的区别制作uImage更换内核更换uboot后续计划 uboot常见命令学习 环境变量 Environment Variables环境变量 autostart 如果值为yes,则会…...
KVM 自动化脚本的使用及热/冷迁移
一、介绍 目录结构介绍 [rootkvm-server kvm]# tree -L 2 . ├── control # 控制脚本目录 │ ├── KVMInstall.sh # kvm服务安装脚本 │ ├── VMHost.sh # kvm虚拟机克隆脚本 │ └── VMTemplate.sh # kvm模板机安装脚本 ├── mount # 此目录保持为空&…...
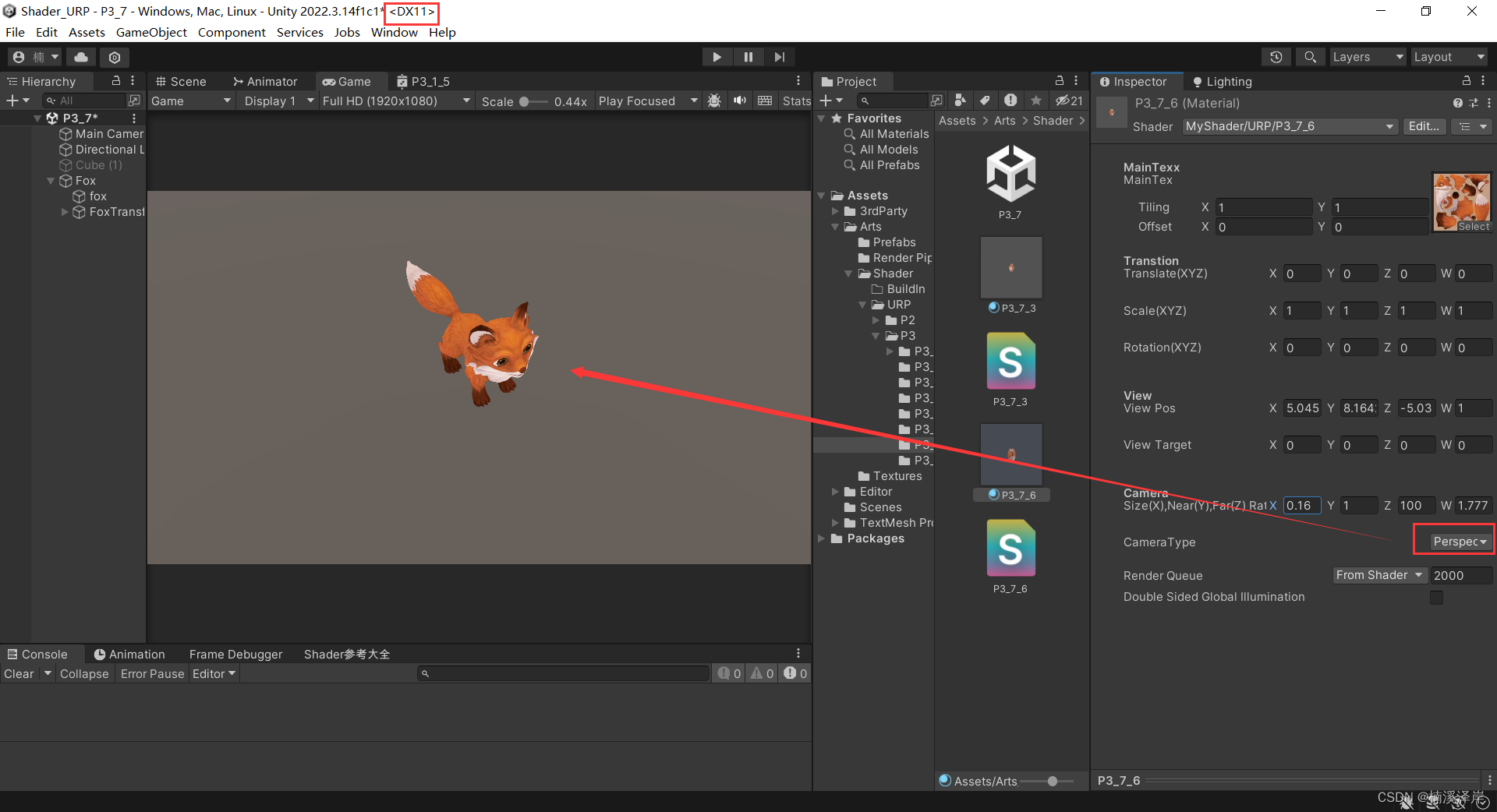
Unity中Shader裁剪空间推导(在Shader中使用)
文章目录 前言一、在Shader中使用转化矩阵1、在顶点着色器中定义转化矩阵2、用 UNITY_NEAR_CLIP_VALUE 区分平台矩阵3、定义一个枚举用于区分当前是处于什么相机 二、我们在DirectX平台下,看看效果1、正交相机下2、透视相机下3、最终代码 前言 在上一篇文章中&…...
ES的使用(Elasticsearch)
ES的使用(Elasticsearch) es是什么? es是非关系型数据库,是分布式文档数据库,本质上是一个JSON 文本 为什么要用es? 搜索速度快,近乎是实时的存储、检索数据 怎么使用es? 1.下载es的包(环境要…...

车牌识别技术,如何用python识别车牌号
目录 一.前言 二.运行环境 三.代码 四.识别效果 五.参考 一.前言 车牌识别技术(License Plate Recognition, LPR)在交通计算机视觉(Computer Vision, CV)领域具有非常重要的研究意义。以下是该技术的一些扩展说明࿱…...
>)
爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>
爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>-CSDN博客 爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>-CSDN博客 前言: 之前提到过,很多scrapy写出来之后,不…...
Servlet入门
目录 1.Servlet介绍 1.1什么是Servlet 1.2Servlet的使用方法 1.3Servlet接口的继承结构 2.Servlet快速入门 2.1创建javaweb项目 2.1.1创建maven工程 2.1.2添加webapp目录 2.2添加依赖 2.3创建servlet实例 2.4配置servlet 2.5设置打包方式 2.6部署web项目 3.servl…...

【C#与Redis】--高级主题--Redis 哨兵
一、简介 1.1 哨兵的概述 哨兵(Sentinel)是 Redis 分布式系统中用于监控和管理多个 Redis 服务器的组件。它的主要目标是确保 Redis 系统的高可用性,通过实时监测主节点和从节点的状态,及时发现并自动处理故障,保证系…...

linux安装python
文章目录 前言一、下载安装包二、安装1.安装依赖2.解压3.安装4.软链接5.验证 总结 前言 本篇文章介绍linux环境下安装python。 一、下载安装包 下载地址:官方网站 我们以最新的标准版为例 二、安装 1.安装依赖 yum -y install openssl-devel ncurses-devel li…...

【如何破坏单例模式(详解)】
✅如何破坏单例模式 💡典型解析✅拓展知识仓✅反射破坏单例✅反序列化破坏单例✅ObjectlnputStream ✅总结✅如何避免单例被破坏✅ 避免反射破坏单例✅ 避免反序列化破坏单例 💡典型解析 单例模式主要是通过把一个类的构造方法私有化,来避免重…...

暗黑破坏神II终极角色编辑器:Diablo Edit2完全使用指南
暗黑破坏神II终极角色编辑器:Diablo Edit2完全使用指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit Diablo Edit2是暗黑破坏神II玩家必备的角色存档编辑器,这款开源工具…...

Mac运行CORE Keygen受阻?巧用UPX与brew轻松解包
1. 当Mac遇到CORE Keygen无法运行时该怎么办? 最近有不少朋友在Mac上运行CORE Keygen时遇到了问题,双击应用图标后要么毫无反应,要么直接弹出"无法打开"的提示。这种情况其实很常见,特别是对于一些特殊用途的应用程序。…...
)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板) 在快节奏的商业决策中,市场调研的可靠性往往取决于一个关键数字——样本量。产品经理小张最近就踩了坑:耗时两周完成的500份用户问卷&…...

鼠标点击也能如此惊艳!ClickShow让你的Windows操作充满视觉魔力 ✨
鼠标点击也能如此惊艳!ClickShow让你的Windows操作充满视觉魔力 ✨ 【免费下载链接】ClickShow 鼠标点击特效 项目地址: https://gitcode.com/gh_mirrors/cl/ClickShow 还在为枯燥的鼠标点击操作感到乏味吗?每天重复的点击、拖拽、选择࿰…...

ANNA框架:构建AI原生应用的智能体开发指南
1. 项目概述:一个面向未来的AI原生应用框架最近在GitHub上闲逛,发现了一个让我眼前一亮的项目:ANNA。这个项目由开发者NikolaiGL发起,乍一看名字,你可能会联想到某个AI模型或者工具库,但深入研究后你会发现…...

纺织行业智能化升级进入深水区:AI验布机从“可选项”变为“必选项”
过去三年,走访过数十家纺织服装企业的行业观察者会发现一个明显的变化:2023年时,AI验布机还是展会上引人驻足的新奇设备;到了2025年,它已经成为越来越多工厂标准配置的一部分。这一转变背后,折射出整个纺织…...

2026届最火的十大降重复率网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,学术创作效率需求持续提升,智能一键论文生成类工具,…...

GEE入门实战:从云端概念到首个遥感分析
1. 初识Google Earth Engine(GEE) 第一次接触GEE时,我完全被它的云端处理能力震撼到了。想象一下,你不需要在本地安装任何软件,打开浏览器就能调用PB级别的遥感数据,还能直接在上面跑分析——这简直就是遥感…...

解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学
解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx作为一款基于C#开发的Nintendo Switch模拟器&#x…...

Infinity Router:构建统一流量网关的架构设计与生产实践
1. 项目概述:一个面向未来的路由聚合器 最近在折腾一个很有意思的项目,叫“Infinity Router”。这名字听起来挺唬人的,但说白了,它就是一个 路由聚合器 。不过,它和我们平时在项目里用的那些路由库(比如 …...