分布式系统架构设计之分布式数据存储的分类和组合策略

在现下科技发展迅猛的背景下,分布式系统已经成为许多大规模应用和服务的基础架构。分布式架构的设计不仅仅是一项技术挑战,更是对数据存储、管理和处理能力的严峻考验。随着云原生、大数据、人工智能等技术的崛起,分布式系统对于数据的高效存储和快速访问变得尤为重要。
在当今信息化的社会背景下,数据已经成为企业和组织的核心资产,特别是随着企业业务规模和用户数量的不断增长,数据量的爆炸性增长以及业务需求的多样化,传统数据库和存储方案逐渐显露瓶颈,无法满足高性能、高可用性和可伸缩性的要求。因此,在分布式系统中,复杂数据存储架构设计成为一个关键的研究领域。
然而,分布式系统的设计和管理并非易事。在分布式环境中,数据存储不再是简单的事务处理,而是面临着更为复杂的一致性、可用性、分区容错性等方面的挑战。如何在保障数据一致性的同时实现高性能、高扩展性,成为架构设计师面临的核心问题。此外随着数据规模的增长,对数据安全性和隐私性的要求也愈发严格。
本部分内容会和大家一起探讨在分布式系统中数据存储和关键问题和解决方案,旨在帮助大家全面理解分布式环境下数据存储的复杂性,掌握对应的设计原则和技术手段。我会从关系数据库、NoSQL 数据库、缓存数据库等多个维度进行分析,同时介绍在分布式系统中实践的组合性的数据存储方案和策略设计。
希望通过这部分内容,可以帮你整理在分布式系统中进行数据存储架构设计的体系化知识,可以让大家更好地应对未来复杂多变的分布式系统数据存储设计挑战。
一、数据存储的分类
在分布式系统的设计中,合理选择和组织数据存储是确保系统高效运行的关键环节。数据存储的分类主要基于数据的性质、访问模式和应用需求,常见的数据存储可以分为关系型数据库、NoSQL 数据库和缓存数据库等多个类型,同时也增加对 NewSQL 数据库和向量数据库的介绍。
1、关系型数据库
传统的数据存储方式,采用表格的形式组织数据,通过 SQL 进行数据管理。典型的数据库有:MySQL、PostgreSQL、Oracle 等。这类数据库具有强大的事务支持、数据一致性和复杂查询的能力,适用于需要强调数据结构化和关联性的场景。
适用场景
- 需要强一致性和事务支持的业务场景
- 数据结构相对稳定,不频繁变更的应用
优势
- 数据模型清晰,支持复杂查询
- 数据一致性和完整性得到保障
- 强调 ACID 特性:原子性、一致性、隔离性、持久性
不足
- 扩展性相对有限,难以应对大规模数据和高并发访问
- 对于非结构化数据的支持较弱
2、NoSQL 数据库
指非关系型数据库,主要包括文档型数据库、列式数据库、键值型数据库和图数据库等。这类数据库强调灵活的数据模型、高可用性和横向扩展性。代表性的 NoSQL 数据库有 MongoDB(文档型)、HBase(列式)、Redis(键值)、Neo4j(图) 等。
适用场景
- 高度可伸缩和横向扩展性要求的系统
- 数据结构相对灵活,经常变化的应用
优势
- 高度灵活的数据类型,适应多变的数据结构
- 支持横向扩展,适应大规模数据和高并发场景
不足
- 缺乏对复杂查询的优化,适用于简单的查询场景
- 数据一致性相对弱一些,适用于需要高性能而可以接受一定数据不一致性的场景
3、缓存数据库
将数据存储在内存中,以提高读取速度的一种存储方式。常见的缓存数据库有 Redis、Memcached 等。缓存数据库适用于需要快速读取且能够接受一定的数据延迟和不一致性的场景。
适用场景
- 读取频繁,对数据实时性要求不是特别高的应用
- 需要快速响应的数据查询场景
优势
- 高度读取,降低后端数据库压力
- 支持分布式缓存,提高系统整体性能
- 有效应对高并发读取请求
不足
- 数据存储在内存中,受到内存容量的限制
- 对于写入操作的支持相对较弱
4、NewSQL 数据库
是一类旨在克服传统关系型数据库在大规模分布式环境下性能瓶颈的数据库。保持了传统关系型数据库的 ACID 特性,同时具备了分布式系统的高性能和横向扩展能力。代表性的有 YouTube Vitess、CockroachDB、TiDB、ClustrixDB 等。
适用场景
- 需要保持传统关系型数据库 ACID 特性的同时,追求更好的分布式性能
优势
- 兼顾 ACID 特性和分布式系统性能
- 支持水平扩展,适应大规模和高并发场景
不足
- 相对较新,生态系统可能相对不够丰富
- 部分 NewSQL 数据库可能在复杂查询优化上有待改进
5、向量数据库
是一类专门针对存储和处理向量数据的数据库,应用于机器学习、推荐系统等需要高效处理向量计算的领域,代表性的产品有 Milvus、 Transwarp Hippo、Tecent Cloud VectorDB 等。
适用场景
- 面向机器学习、推荐系统等需要大规模向量计算的应用
优势
- 高效处理向量计算,适用于大规模向量检索
- 提供向量索引和相似度搜索的支持
不足
- 面向特定场景,不适用于通用的关系型数据存储
以上是数据存储的分类及其说明,每一种都有其特定的优点和适用场景。架构师在选择数据存储时应该根据实际业务需求场景、性能要求和系统规模综合考虑。主要考虑因素可以参考以下几个方面:
- 数据的特性
- 访问模式
- 并发控制要求
- 一致性要求
- 容错性要求
在实际应用场景中,尤其对于复杂的应用场景,往往是需要多种类型的存储技术相互协作,形成混合性的数据存储方案。
二、数据存储的组合策略
在实际的分布式系统中,很少有单一的数据存储方式就可以满足所有业务需求的。因此组合不同类型的数据存储成为一种常见策略,构建混合式的数据存储架构,充分利用各种数据库的优势应对系统的多样化需求。这部分会对实际场景的解决方案和过往的一些经验借鉴总结出各种不同的组合策略。
1、关系数据库和缓存数据库的组合
面对读写比较平衡、对数据一致性要求较高的业务,将关系型数据库与缓存数据库相结合,通过缓存数据库提高读取性能,减轻关系型数据库的读取压力。关系型数据库负责处理复杂的事务逻辑,确保数据的一致性。
在这样的组合下,读取性能可以大幅度提升,缓解了关系型数据库的读取压力,同时保持数据一致性,适用于需要高度事务支持的场景。
不过在缓存数据库中的数据可能会出现和关系型数据库存在一定的延迟和不一致,不过有对应的解决方案,这里不再赘述,这也是我在面试过程中经常喜欢问的一个问题:在分布式系统中,如何保证缓存数据和关系型数据库中数据的一致性。
2、关系型数据库和 NoSQL 数据库的组合
针对结构化和非结构化数据混合存储的场景,需要使用该组合,使用关系型数据库管理结构化数据,将非结构化或变化频繁的数据存储在适合的 NoSQL 数据库中。这种组合可以充分发挥关系型数据库的事务支持和 NoSQL 数据库的高扩展性。
在这样的服务业务需求场景下,两种类型的数据库都可以发挥各自的优势,满足不同类型数据的存储需求,同时结构化数据的一致性和事务支持也得到了很好的保障。
不过需要维护两类数据库,维护成本有提升,同时也一定程度上增加了系统复杂性。
3、NoSQL 数据库的多引擎组合
面对不同数据模型和访问模式的多样化需求场景时,可以在分布式系统中使用不同类型的 NoSQL 数据库引擎,比如文档型、列族型、图数据库等。根据数据的特定选择最适合的引擎,文档型的存储半结构化数据,图型的存储关系数据等。
这样的组合场景下,充分发挥不同 NoSQL 引擎的特点,满足多样化的数据存储需求,提高了系统的灵活性和适应性。
不过该场景下,对架构师、研发者、运维者的要求较高,需要对不同引擎的特性和性能有深度掌握,同时维护成本相对较高。
4、向量数据库和 NoSQL 数据库的组合
针对诸如推荐系统一样的需要进行向量计算和相似度搜索的业务场景,可以使用向量数据库专门存储和处理向量数据,而其他结构化或半结构化数据存储在 NoSQL 中,也可以在这个组合的基础上增加结构化数据存储在关系型数据库中。
在特定的场景下,这种组合可以高效处理向量计算和相似度搜索,提高推荐系统的性能,同时这种分离存储的模式,使系统组件更加模块外。不过需要额外的技术和架构支持,不具有绝大多数业务场景的普适性。
5、数据仓库和 OLAP 系统的集成
将实时数据场景中的数据存储在事务型数据库中,同时将历史数据归档到数据仓库中进行分析。数据仓库可以支持复杂的多维分析查询,提供 BI 和报表相关功能。
6、多区块链组合
针对诸如供应链管理这样的需要分布式、不可篡改、具有高度透明性的业务场景,使用多个区块链网络,每个网络负责不同层面的数据出处,比如一个区块链网络用于存储交易数据,另一个存储合同和协议。
这样的组合可以具备高度的透明性和不可篡改性,按业务逻辑划分,降低了单一区块链的存储压力。不过区块链技术本上在性能和扩展性上就存在很多限制。
以上是不同类型数据库的常见组合策略,接下来我们再看看从存储技术上的一些组合策略:
1、主从复制
在关系型数据库和 NoSQL 数据库中,我们可以采用主从复制的方式实现读写分离,进一步提高系统的读取性能。
主节点专门负责处理写入操作,而让从节点专门用于处理读取请求。
2、分层存储
根据数据的访问频率和重要性,将数据存储在不同的层级或者介质上。通常包括内存、SSD、HDD 和冷存储等不同层次,以平衡成本和性能。
3、实时流处理和批处理的融合
使用实时流处理系统,比如 Kafka、Flink 等,处理实时事件和数据流,为业务决策提供实时洞察依据。同时,使用批处理系统,比如 Hadoop、Spark 等,对大规模历史数据进行离线分析和及其学习模型训练。
4、云存储服务的组合使用
利用云服务商提供的云存储服务能力打出基于云原生的“组合存储拳”,比如对象存储(Amazon S3、Google Cloud Storage、Alibaba OSS、Tecent COS 等)、文件存储(AWS EFS、Azure Files 等)、块存储(AWS EBS、Azure Disks 等),实现灵活、可扩展的数据存储能力。
跨数据中心的地理分布存储
在多个地理位置部署数据存储,实现容灾备份和低延迟访问。可以通过数据同步工具或者云服务商的全球分布存储功能来实现。
5、异构数据源的整合
使用数据集成工具,比如 Apache Kafka Connect、AWS Glue、Azure Data Factory 等,将来自不同的数据源,比如关系型数据库、NoSQL 数据库、API、日志文件等多数据源多类型数据整合在一起,提供统一的数据视图看板。
选择合适的组合策略需要根据具体的业务场景和需求来进行权衡决策,在设计数据存储架构时,要充分考虑数据的访问模式、一致性要求、性能指标、成本因素以及未来的扩展性需求。在本文的末尾部分我也会针对我现在所在的自动驾驶行业数据场景,用我现在的数据存储架构设计方案来给大家展示我的这套“组合拳”。

相关文章:
分布式系统架构设计之分布式数据存储的分类和组合策略
在现下科技发展迅猛的背景下,分布式系统已经成为许多大规模应用和服务的基础架构。分布式架构的设计不仅仅是一项技术挑战,更是对数据存储、管理和处理能力的严峻考验。随着云原生、大数据、人工智能等技术的崛起,分布式系统对于数据的高效存…...

javaEE -18(11000字 JavaScript入门 - 3)
一:事件 (高级) 1.1 注册事件(绑定事件) 给元素添加事件,称为注册事件或者绑定事件,注册事件有两种方式:传统方式和方法监听注册方式 传统注册方式 : 利用 on 开头的…...

LangChain.js 实战系列:入门介绍
📝 LangChain.js 是一个快速开发大模型应用的框架,它提供了一系列强大的功能和工具,使得开发者能够更加高效地构建复杂的应用程序。LangChain.js 实战系列文章将介绍在实际项目中使用 LangChain.js 时的一些方法和技巧。 LangChain.js 是一个…...
pyCharm 打印控制台中文乱码解决办法
解决方法 在 "File" -> "Settings" 中的控制台设置: 在 "File" -> "Settings" 中,你可以找到 "Editor" -> "General" -> "Console"。在这里,你可能会找到…...

计算机基础--Linux详解
一概述 Linux是一种自由和开放源码的类UNIX操作系统。它是由林纳斯托瓦兹于1991年首次发布的,并从那时起在全球范围内得到了广泛的应用和开发。Linux具有强大的可定制性,可以运行在各种硬件平台上,包括x86、ARM、MIPS等。它不仅广泛应用于服…...
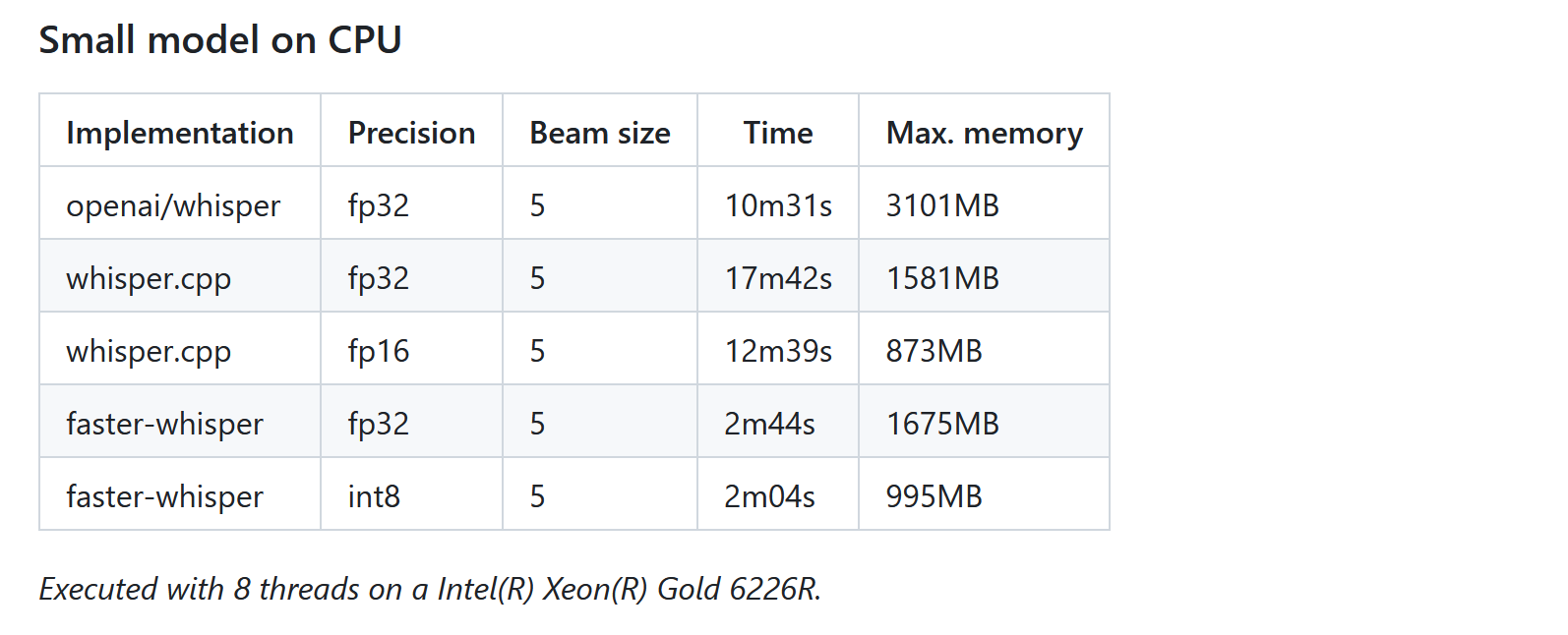
基于OpenAI的Whisper构建的高效语音识别模型:faster-whisper
1 faster-whisper介绍 faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在…...
)
cfa一级考生复习经验分享系列(十六)
写在前面:并不鼓励大家在考前一个月才开始复习,不过,既然已经逼到了绝境,灰心丧气也没有用,不如放手一搏! 首先说一下我的背景,工作金融机构的it,和cfa基本没关系,本硕计…...
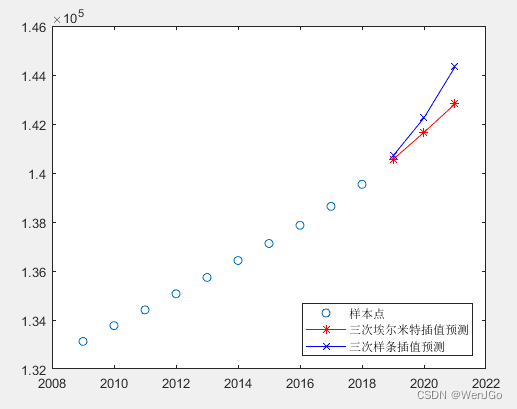
数模学习day05-插值算法
插值算法有什么作用呢? 答:数模比赛中,常常需要根据已知的函数点进行数据、模型的处理和分析,而有时候现有的数据是极少的,不足以支撑分析的进行,这时就需要使用一些数学的方法,“模拟产生”一些…...

hive中struct相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释 hive官网函数大全地址:添加链接描述 Return TypeNameDescriptionstructstruct(val1, val2, val3, …)Creates a struct with the given field values. Struct field names will be col1, col2, …structnamed_str…...
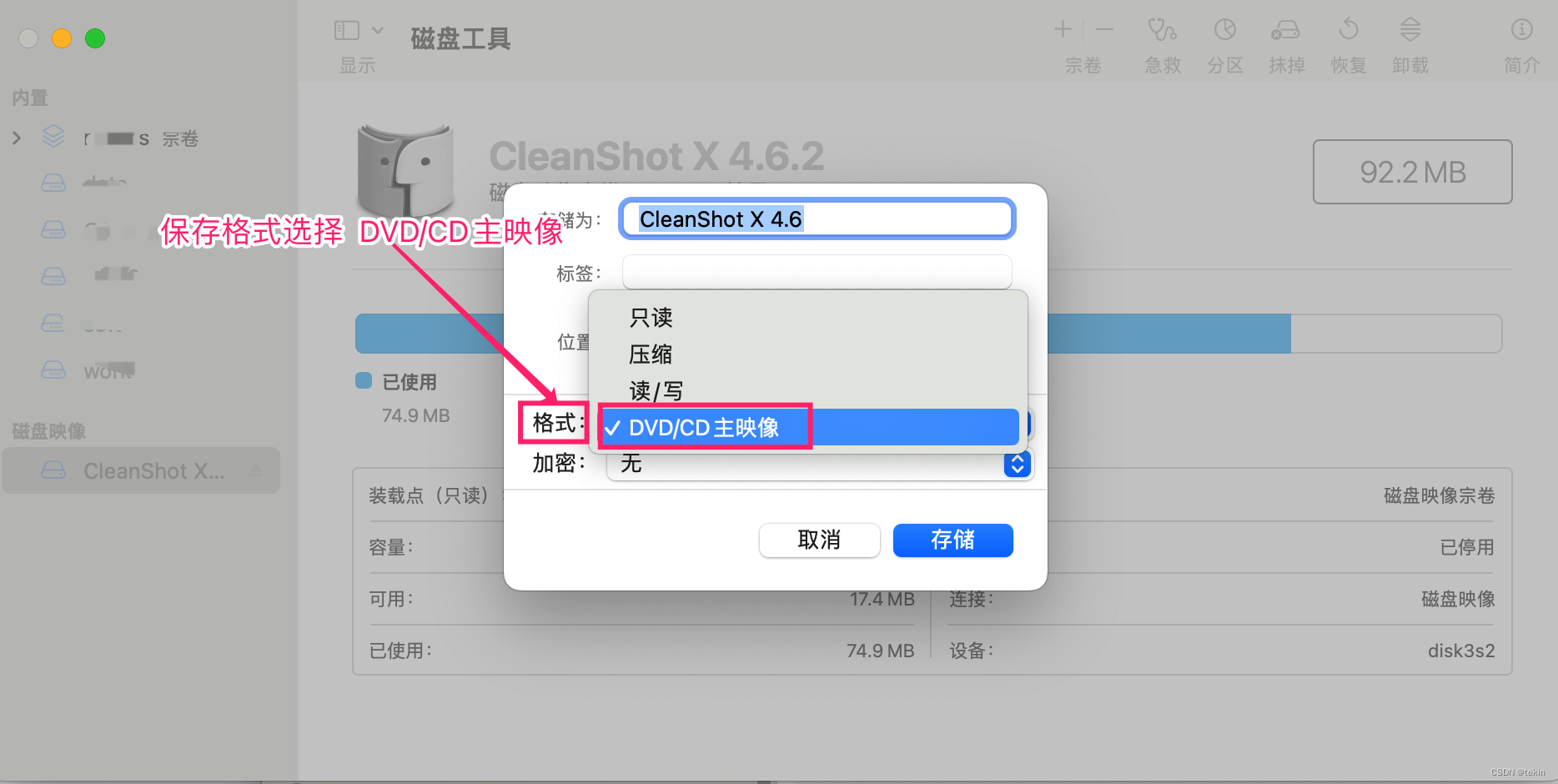
macos下转换.dmg文件为 .iso .cdr文件的简单方法
为了让镜像文件在mac 和windows平台通用, 所以需要将.dmg格式的镜像文件转换为.iso文件, 转换方法也非常简单, 一行命令即可 hdiutil convert /path/to/example.dmg -format UDTO -o /path/to/example.iso 转换完成后的文件名称默认是 example.iso.cdr 这里直接将.cdr后缀删…...
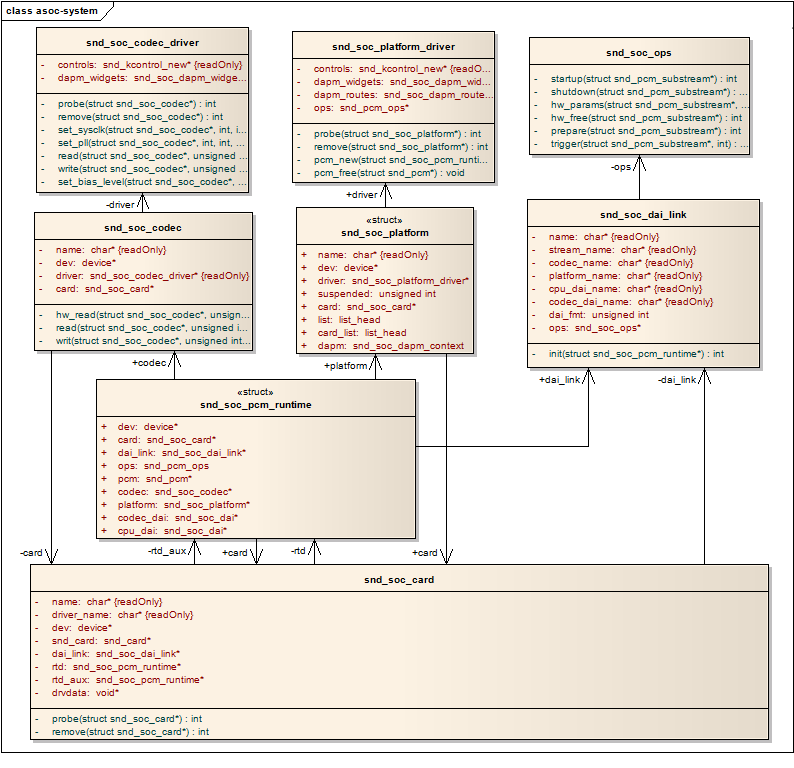
ALSA学习(5)——设备中的alsa
参考博客: https://blog.csdn.net/DroidPhone/article/details/7165482 (一下内容基本是原博主的博客转载) 文章目录 一、ASOC的由来二、硬件架构三、软件架构四、数据结构五、内核对ASoC的改进 一、ASOC的由来 ASoC–ALSA System on Chip …...

uniapp中组件库的丰富NumberBox 步进器的用法
目录 基本使用 #步长设置 #限制输入范围 #限制只能输入整数 #禁用 #固定小数位数 #异步变更 #自定义颜色和大小 #自定义 slot API #Props #Events #Slots 基本使用 通过v-model绑定value初始值,此值是双向绑定的,无需在回调中将返回的数值重…...
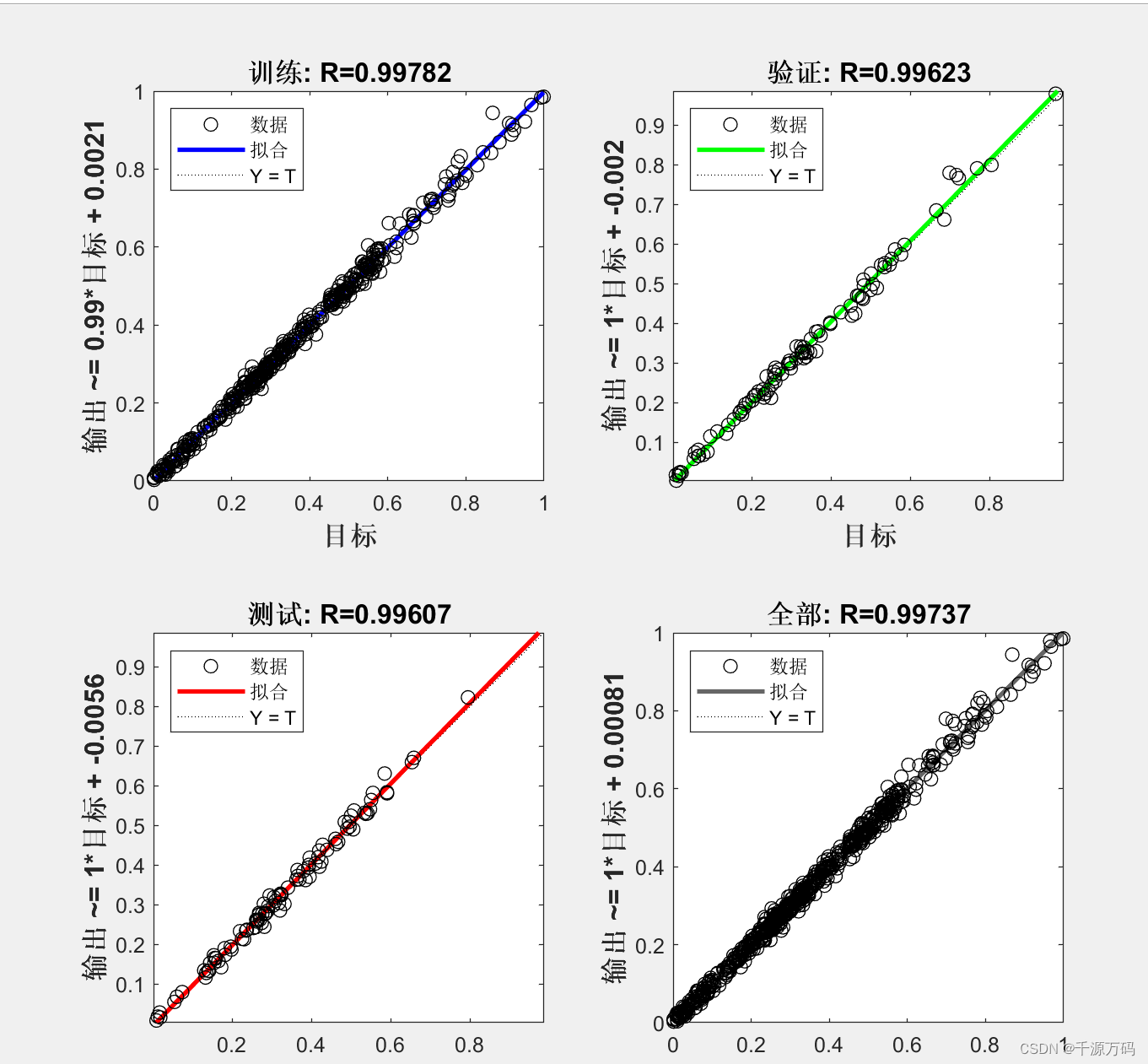
【Matlab】基于遗传算法优化BP神经网络 (GA-BP)的数据时序预测
资源下载: https://download.csdn.net/download/vvoennvv/88682033 一,概述 基于遗传算法优化BP神经网络 (GA-BP) 的数据时序预测是一种常用的机器学习方法,用于预测时间序列数据的趋势和未来值。 在使用这种方法之前,需要将时间序…...
计算机毕业设计 基于HTML5+CSS3的在线英语阅读分级平台的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
云原生|kubernetes|kubernetes资源备份和集群迁移神器velero的部署和使用
前言: kubernetes集群需要灾备吗?kubernetes需要迁移吗? 答案肯定是需要的 那么,如何做kubernetes灾备和迁移呢?当然了,有很多的方法,例如,自己编写shell脚本,或者使用…...
【26.4K⭐】ShareX:一款开源免费、功能强大且丰富的截屏录屏软件
【26.4K⭐】ShareX:一款开源免费、功能强大且丰富的截屏录屏软件 在日常工作、学习和娱乐过程中,我们经常需要截取屏幕或者录制屏幕上特定区域中的内容并进行标记、编辑等操作。无论是为了记录重要的信息、分享有趣的内容,还是为了制作教程和…...

什么是ajax,为什么使用ajax?
概念:ajax是一种现有的技术集合,技术内容包括:HTML或XHTML,CSS,JavaScript,DOM,XML,XSLT,以及最重要的XMLHttpRequest。用于浏览器与服务器之间使用异步传输,做到局部请求以实现局部刷新。 作用…...

AI面板识别 - 华为OD统一考试
OD统一考试 (B卷) 分值: 100分 题解: Java / Python / C++ 题目描述 AI识别到面板上有N(1 ≤ N ≤ 100)个指示灯,灯大小一样,任意两个之间无重叠。 由于AI识别误差,每次别到的指示灯位置可能有差异,以4个坐标值描述AI识别的指示灯的大小和位置(左上角x1,y1,右下角x2…...

Linux之磁盘分区,挂载
Linux分区 分区介绍 对linux来说无论有几个分区,分给哪个目录使用,归根结底只有一个根目录,linux中每个分区都是用来组成整个文件系统的一部分。linux采用“载入"的处理方法,他的整个文件系统中包含一整套的文件和目录&…...

2核2G3M服务器上传速度多少?以阿里云和腾讯云为例
2核2G3M服务器上传速度多少?上传是按10M带宽算,上传速度是1280KB/秒,即1.25M/秒;下载速度按3M带宽计算,下载速度是384KB/秒。本文是以阿里云为例的,阿里云服务器当公网带宽小于10M及10M以下时,上…...

LingBot-Depth部署教程:Docker Compose编排+模型缓存卷自动初始化
LingBot-Depth部署教程:Docker Compose编排模型缓存卷自动初始化 1. 引言:从稀疏数据到精准3D测量 你有没有遇到过这样的场景?手头有一个深度摄像头,但采集到的深度图总是零零散散,像一张被撕破的旧地图,…...

「5 个 Markdown 文件 + 1 句提示词」让 AI 精准重构你的 React 组件 | 附完整模板
这个场景你一定经历过: 你给 ChatGPT/Claude 一个又臭又长的 React 组件,说:"帮我重构一下,让它更清晰。" 结果要么: 改错了交互逻辑,导致功能崩溃改变了接口契约,后端完全适配不了代…...

基于carsim Simulink联合仿真和预瞄PID算法的轨迹跟踪模型】车辆路径跟踪包括主车...
基于carsim Simulink联合仿真和预瞄PID算法的轨迹跟踪模型】车辆路径跟踪包括主车的纵向和横向运动控制,纵向控制是通过调整轮毂电机的扭矩,使得车辆以期望的速度行驶;横向控制是通过调整主车的转向,使主车沿预期的轨迹行驶。 本模…...
)
Houdini VEX实战:5步搞定变形管道的中心线生成(附常见问题修复)
Houdini VEX实战:5步搞定变形管道的中心线生成(附常见问题修复) 在三维动画制作中,处理变形管道的中心线是许多技术美术师面临的常见挑战。无论是角色动画中的血管、机械装置中的电缆,还是科幻场景中的能量管道&#x…...

5步精通OpenPose:从环境评估到人体姿态检测全流程
5步精通OpenPose:从环境评估到人体姿态检测全流程 【免费下载链接】openpose 项目地址: https://gitcode.com/gh_mirrors/op/openpose 环境评估:系统兼容性与硬件要求 在开始OpenPose的安装之旅前,需要确保你的系统环境满足以下条件…...

Video2X:让你的老旧视频焕发新生的AI魔法工具
Video2X:让你的老旧视频焕发新生的AI魔法工具 【免费下载链接】video2x A lossless video/GIF/image upscaler achieved with waifu2x, Anime4K, SRMD and RealSR. Started in Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trending/vi/video…...

Bing Wallpaper自动化部署:GitHub Actions与持续集成
Bing Wallpaper自动化部署:GitHub Actions与持续集成 【免费下载链接】bing-wallpaper 项目地址: https://gitcode.com/gh_mirrors/bi/bing-wallpaper Bing Wallpaper项目是一个专注于收集和展示Bing每日壁纸的开源项目,通过自动化部署可以确保壁…...

几何完备扩散模型GCDM:从理论突破到SBDD实战评测与部署指南
1. 几何完备扩散模型GCDM的核心突破 第一次看到GCDM论文时,我被它解决3D分子生成痛点的思路惊艳到了。传统方法就像用2D积木搭3D建筑——EDM等模型依赖的EGNN网络只能处理距离信息,而GCDM引入的GCPNET架构彻底改变了游戏规则。这个改进相当于给模型装上了…...

Jaspersoft Studio 动态字体颜色设置实战指南
1. 为什么需要动态字体颜色? 在报表开发中,数据可视化是提升信息传达效率的关键手段。想象一下,当你的老板查看月度销售报表时,如果所有数字都是千篇一律的黑色,他需要花费多少时间才能找到异常数据?而如果…...

AI 培训报名:主流机构专业度对比分析
引言 随着人工智能技术的快速发展,AI 培训市场也日益火爆。无论是企业还是个人,都希望通过专业的培训来提升对 AI 技术的应用能力。然而,当前 AI 培训市场鱼龙混杂,机构众多,质量参差不齐。企业和个人在选择 AI 培训机…...