MR实战:实现数据去重
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据文件
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、Map阶段实现
- (1)创建Maven项目
- (2)添加相关依赖
- (3)创建日志属性文件
- (4)创建去重映射器类
- 2、Reduce阶段实现
- 创建去重归并器类
- 3、Driver程序主类实现
- 创建去重驱动器类
- 4、运行去重驱动器类,查看结果
- 四、拓展练习
- (一)原始问题
- (二)简单化处理
一、实战概述
-
本次实战任务目标是使用Hadoop MapReduce技术对两个包含重复数据的文本文件
file1.txt和file2.txt进行去重操作,并将结果汇总到一个文件。首先启动Hadoop服务,然后在虚拟机上创建这两个文本文件并上传到HDFS的/dedup/input目录。 -
在Map阶段,我们创建自定义Mapper类
DeduplicateMapper,将TextInputFormat默认组件解析的键值对修改为需要去重的数据作为key,value设为空。在Reduce阶段,我们创建自定义Reducer类DeduplicateReducer,直接复制输入的key作为输出的key,利用MapReduce默认机制对key(即文件中的每行内容)进行自动去重。 -
我们还编写MapReduce程序运行主类
DeduplicateDriver,设置工作任务的相关参数,对HDFS上/dedup/input目录下的源文件进行去重处理,并将结果输出到HDFS的/dedup/output目录。最后,运行DeduplicateDriver类,查看并下载结果文件,确认去重操作成功完成。此实战任务展示如何运用Hadoop MapReduce进行大数据处理和去重操作,提升我们对分布式计算的理解和应用能力。
二、提出任务
-
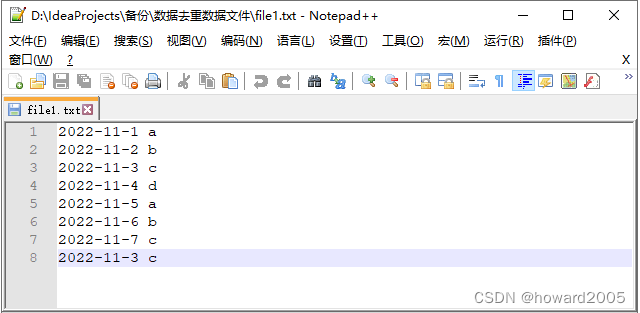
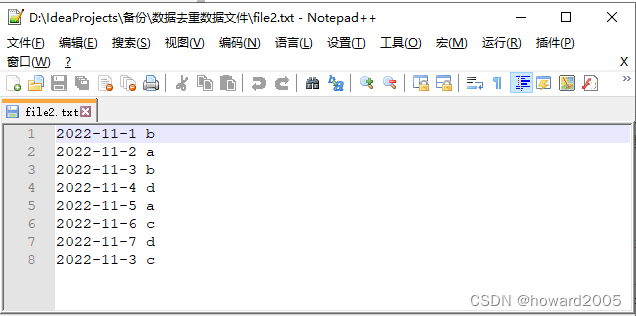
文件file1.txt本身包含重复数据,并且与file2.txt同样出现重复数据,现要求使用Hadoop大数据相关技术对以上两个文件进行去重操作,并最终将结果汇总到一个文件中。
-
编写MapReduce程序,在Map阶段采用Hadoop默认作业输入方式后,将key设置为需要去重的数据,而输出的value可以任意设置为空。
-
在Reduce阶段,不需要考虑每一个key有多少个value,可以直接将输入的key复制为输出的key,而输出的value可以任意设置为空,这样就会使用MapReduce默认机制对key(也就是文件中的每行内容)自动去重。
三、完成任务
(一)准备数据文件
- 启动hadoop服务
1、在虚拟机上创建文本文件
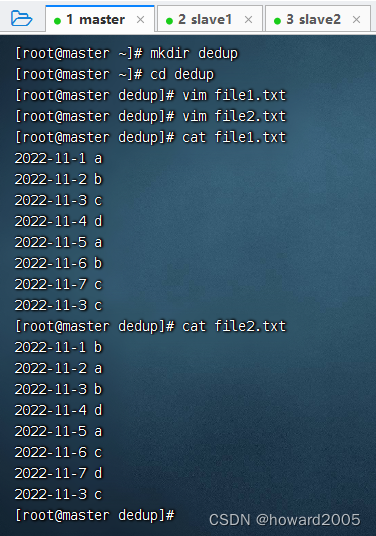
- 创建两个文本文件 -
file1.txt、file2.txt
2、上传文件到HDFS指定目录
-
创建
/dedup/input目录,执行命令:hdfs dfs -mkdir -p /dedup/input
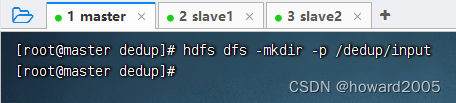
-
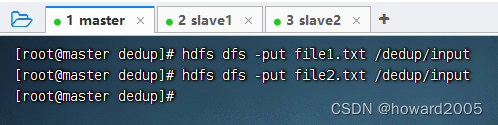
将两个文本文件
file1.txt与file2.txt,上传到HDFS的/dedup/input目录
(二)实现步骤
1、Map阶段实现
- 使用IntelliJ开发工具创建Maven项目
Deduplicate,并且新创建net.hw.mr包,在该路径下编写自定义Mapper类DeduplicateMapper,主要用于读取数据集文件将TextInputFormat默认组件解析的类似<0,2022-11-1 a >键值对修改为<2022-11-1 a,null>。
(1)创建Maven项目
- Maven项目 -
Deduplicate
- 单击【Finish】按钮
(2)添加相关依赖
- 在
pom.xml文件里添加hadoop和junit依赖
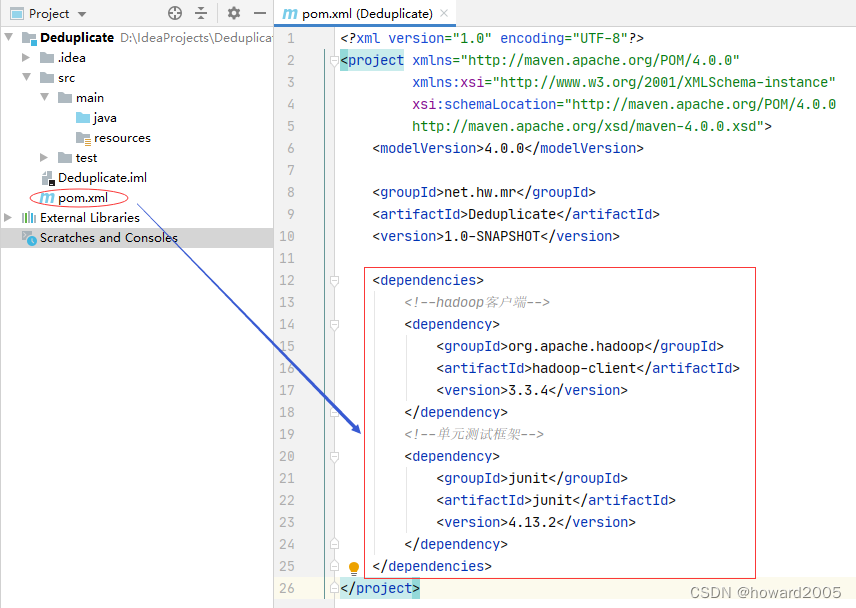
<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
(3)创建日志属性文件
- 在
resources目录里创建log4j.properties文件

log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/deduplicate.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(4)创建去重映射器类
- 创建
net.hw.mr包,在包里创建DeduplicateMapper类
package net.hw.mr;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 功能:去重映射器类* 作者:华卫* 日期:2022年11月30日*/
public class DeduplicateMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private static Text field = new Text();// <0,2022-11-3 c> --> <2022-11-3 c,null>@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {field = value;context.write(field, NullWritable.get());}
}
2、Reduce阶段实现
- 根据Map阶段的输出结果形式,同样在
net.hw.mr包下,自定义Reducer类DeduplicateReducer,主要用于接受Map阶段传递来的数据,根据Shuffle工作原理,键值key相同的数据就会被合并,因此输出数据就不会出现重复数据了。
创建去重归并器类
- 在
net.hw.mr包里创建DeduplicateReducer类
package net.hw.mr;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** 功能:去重归并器类* 作者:华卫* 日期:2022年11月30日*/
public class DeduplicateReducer extends Reducer<Text, NullWritable, Text, NullWritable> {// <2022-11-3 c,null> <2022-11-4 d,null><2022-11-4 d,null>@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context)throws IOException, InterruptedException {context.write(key, NullWritable.get());}
}
3、Driver程序主类实现
- 编写MapReduce程序运行主类
DeduplicateDriver,主要用于设置MapReduce工作任务的相关参数,对HDFS上/dedup/input目录下的源文件实现去重,并将结果输入到HDFS的/dedup/output目录下。
创建去重驱动器类
- 在
net.hw.mr包里创建DeduplicateDriver类
package net.hw.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 功能:去重驱动器类* 作者:华卫* 日期:2022年11月30日*/
public class DeduplicateDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(DeduplicateDriver.class);// 设置Mapper类job.setMapperClass(DeduplicateMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(NullWritable.class);// 设置Reducer类job.setReducerClass(DeduplicateReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(Text.class);// 设置reduce任务输出值类型job.setOutputValueClass(NullWritable.class);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/dedup/input");// 创建输出目录Path outputPath = new Path(uri + "/dedup/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录fs.delete(outputPath, true);// 给作业添加输入目录FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
4、运行去重驱动器类,查看结果
- 运行
DeduplicateDriver类

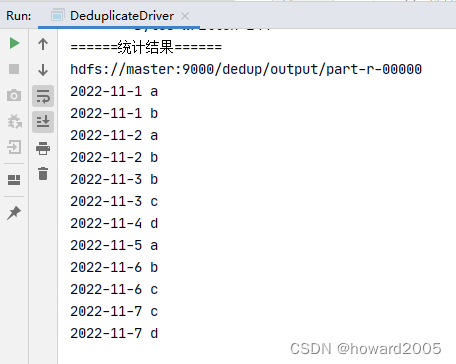
- 下载结果文件 -
part-r-00000

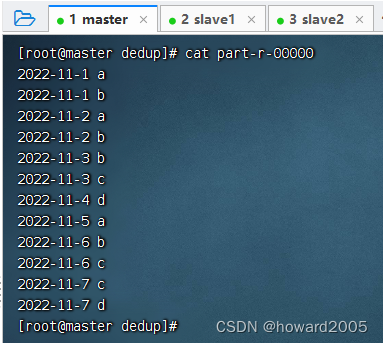
- 查看结果文件 -
part-r-00000
四、拓展练习
- 形式:单独完成
- 题目:实现数据去重
- 要求:让学生自己按照步骤实现数据去重的功能,以此来巩固本节的学习内容。写一篇CSDN博客,记录操作过程。
(一)原始问题
- 某人今天访问很多不同的网站,移动或电信日志都会记录在案,有些网站访问次数多,有些网站访问次数少,此人,今天访问了多少个不同的网站?
(二)简单化处理
- 假如有如下一些IP地址,分别保存在三个文件里,如何去掉重复地址?
- ips01.txt
192.168.234.21
192.168.234.22
192.168.234.21
192.168.234.21
192.168.234.23
192.168.234.21
192.168.234.21
192.168.234.21
- ips02.txt
192.168.234.25
192.168.234.21
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.27
192.168.234.21
- ips03.txt
192.168.234.29
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.25
192.168.234.25
192.168.234.21
192.168.234.22
192.168.234.21
相关文章:
MR实战:实现数据去重
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、Map阶段实现(1)创建Maven项目(2)添加相关依赖…...
JVM 常用知识和面试题
1. 什么是JVM内存结构? jvm将虚拟机分为5大区域,程序计数器、虚拟机栈、本地方法栈、java堆、方法区; 程序计数器:线程私有的,是一块很小的内存空间,作为当前线程的行号指示器,用于记录当前虚拟…...

【教3妹学编程-算法题】一年中的第几天
3妹:“太阳当空照,花儿对我笑,小鸟说早早早,你为什么背上炸药包” 2哥 :3妹,什么事呀这么开森。 3妹:2哥你看今天的天气多好啊,经过了一周多的寒潮,天气总算暖和些了。 2哥ÿ…...

ramdump 中的memory统计
0. 前言 ramdump是指某个时刻系统或者子系统发生crash等异常,系统将内存中的数据通过一定的方式保存下来,相当于一个系统内存快照,用以开发者离线分析系统异常问题。 ramdump 工具中有很多内存统计的脚本,本文逐一剖析内存相关的…...

Element-Ui树形数据懒加载,删除到最后一个空数组不刷新问题
使用elemenui树形删除数据的时候刷新页面,我在网上找了好多方法,要么没用,要么都是部分代码,自己又看不懂,不得不硬着头皮看源码,发现了有个方法可以刷新。 使用elemenui树形删除数据的时候刷新页面。源码里…...

基于NASM搭建一个能编译汇编语言的汇编软件工具环境(利用NotePad++)
文章目录 一、创建汇编语言源程序二、Notepad的下载、安装、使用三、下载和安装编译器NASM3.1 下载NASM编译器3.2 安装并配置环境变量 四、编译汇编语言源程序(使用命令)五、下载和使用配套源码及工具六、将编译功能集成到Notepad 一、创建汇编语言源程序…...
使用setoolkit制作钓鱼网站并结合dvwa靶场储存型XSS漏洞利用
setoolkit是一款kali自带的工具 使用命令启动 setoolkit 1) Social-Engineering Attacks 1) 社会工程攻击 2) Penetration Testing (Fast-Track) 2) 渗透测试(快速通道) 3) Third Party Module…...

计算机组成原理-总线概述
文章目录 总线简图总线的物理实现总览总线定义总线的特性总线的分类按数据格式分类串行总线并行总线 按总线功能分类注意系统总线的进一步分类 总线的结构单总线的机构双总线的结构三总线的结构四总线的结构 小结 总线简图 总线的物理实现 如果该为数据总线,那么当…...
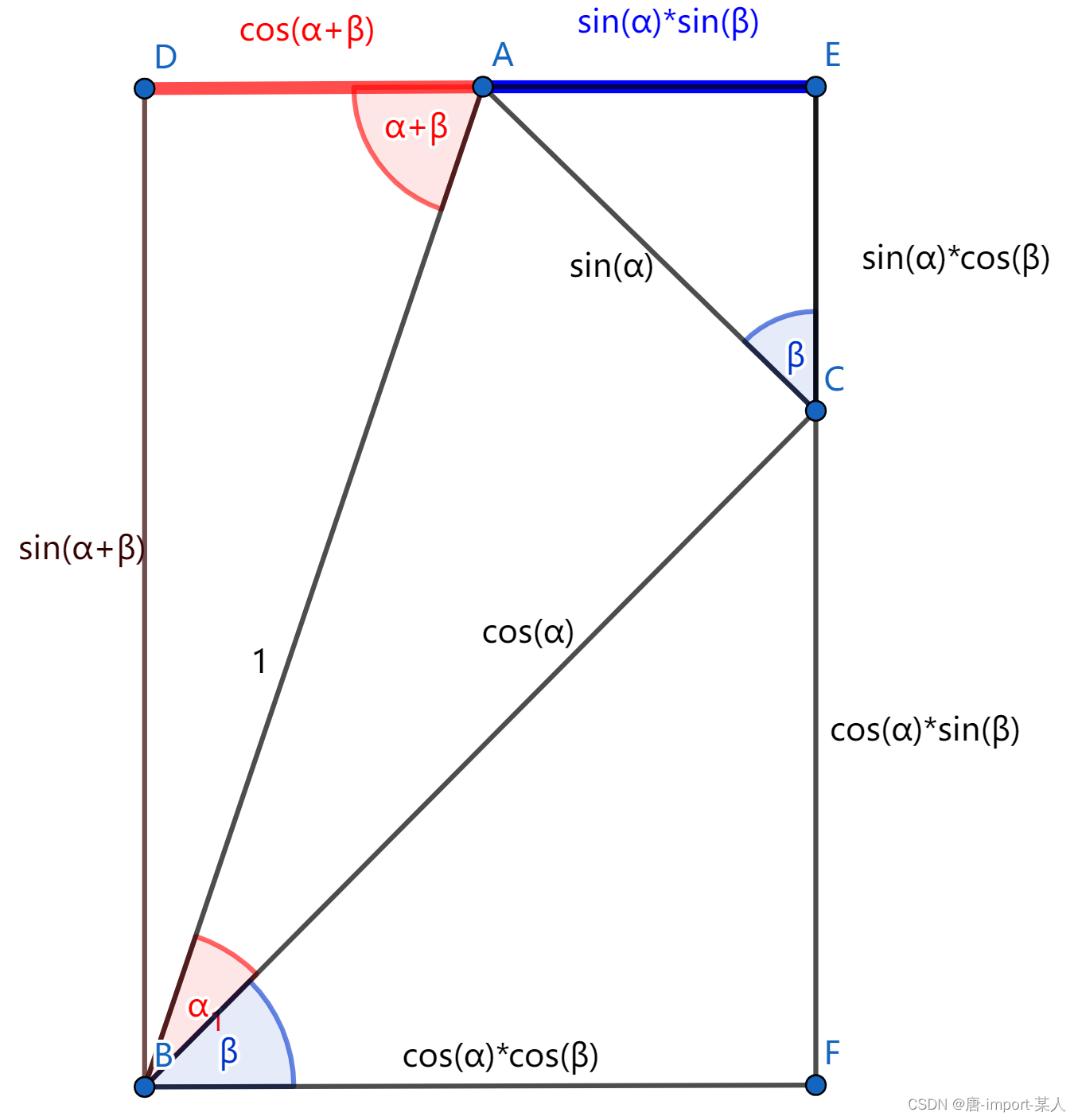
三角函数两角和差公式推导
一.几何推理 1.两角和公式 做一斜边为1的直角△ABC,任意旋转非 k Π , k N kΠ,kN kΠ,kN,补充如图,令 ∠ A B C ∠ α , ∠ C B F ∠ β ∠ABC∠α,∠CBF∠β ∠ABC∠α,∠CBF∠β ∴ ∠ D B F ∠ D B A ∠ α ∠ β 90 , ∠ D A …...
HarmonyOS page生命周期函数讲解
下面 我们又要看一个比较重要的点了 页面生命周期 页面组件有三个生命周期 onPageShow 页面显示时触发 onPageHide 页面隐藏时触发 onBackPress 页面返回时触发 这里 我们准备两个组件 首先是 index.ets 参考代码如下 import router from ohos.router Entry Component struc…...
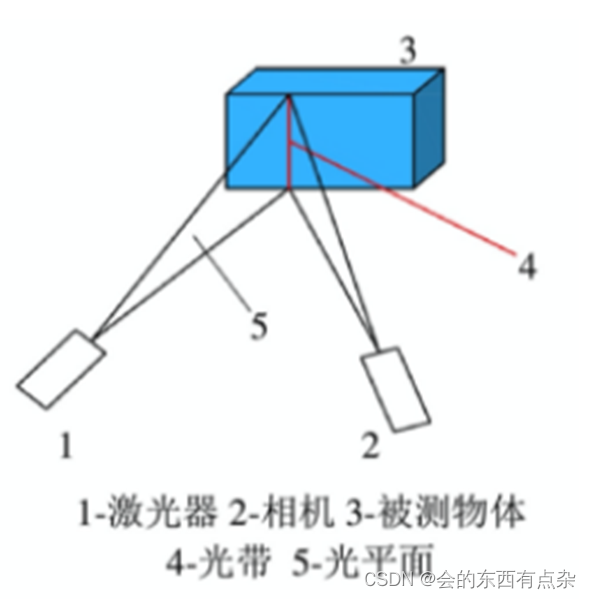
3D视觉-结构光测量-线结构光测量
概述 线结构光测量中,由激光器射出的激光光束透过柱面透镜扩束,再经过准直,产生一束片状光。这片光束像刀刃一样横切在待测物体表面,因此线结构光法又被成为光切法。线结构光测量常采用二维面阵 CCD 作为接受器件,因此…...
ssm基于web的马病管理系统设计与实现+jsp论文
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,马病信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广大…...
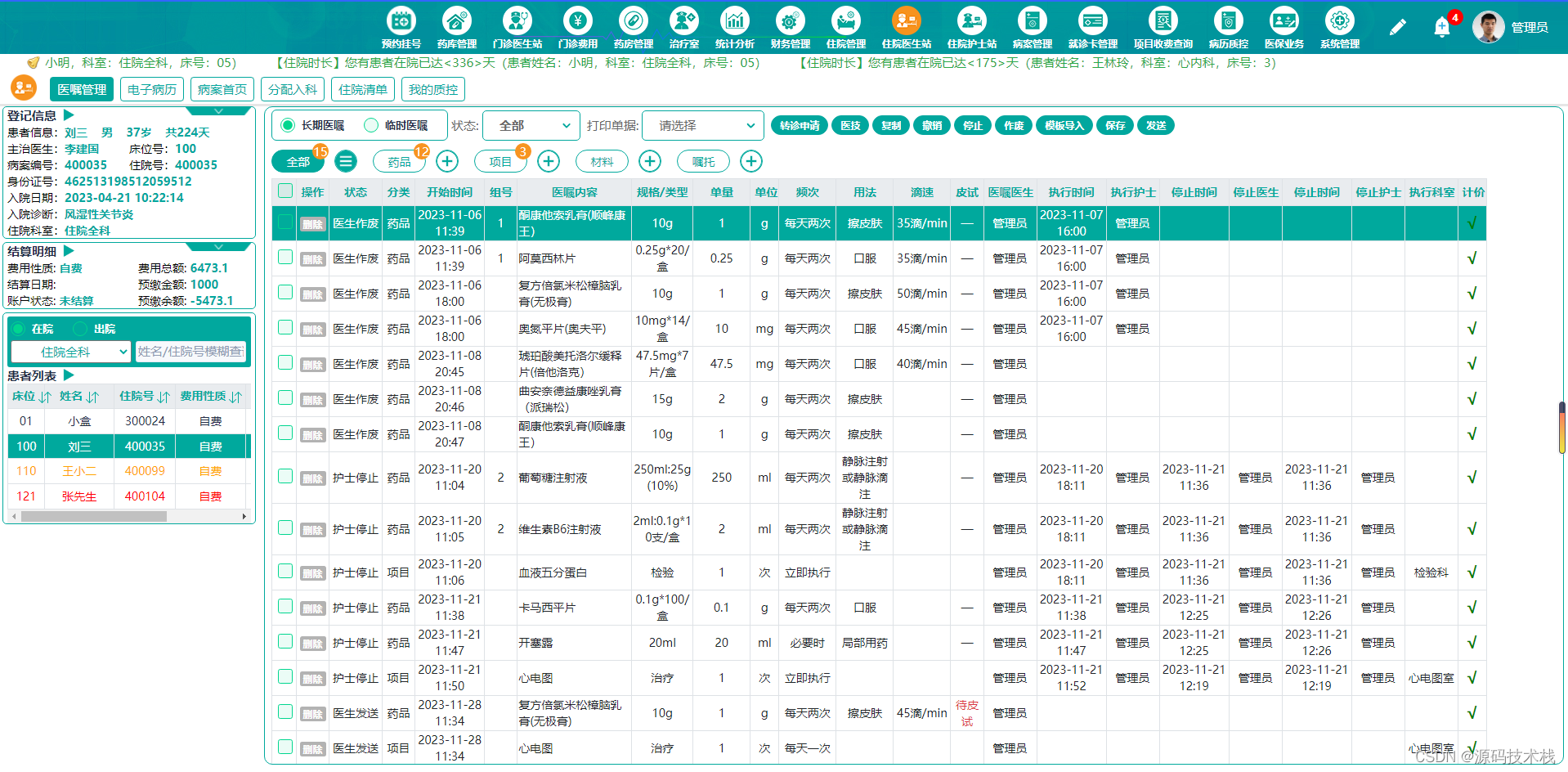
SaaS版Java基层健康卫生云HIS信息管理平台源码(springboot)
云his系统源码,系统采用主流成熟技术开发,B/S架构,软件结构简洁、代码规范易阅读,SaaS应用,全浏览器访问,前后端分离,多服务协同,服务可拆分,功能易扩展。多集团统一登录…...
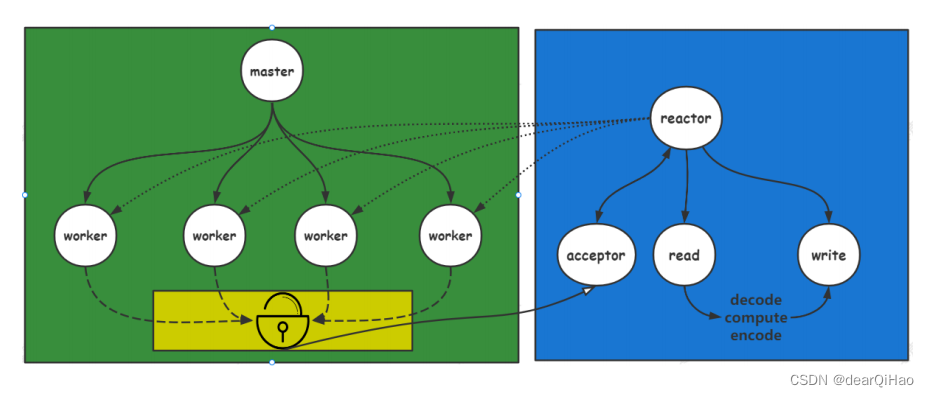
redis,memcached,nginx网络组件,网络编程——reactor的应用
目录 目标网络编程关注的问题连接的建立连接的断开消息的到达消息发送完毕 网络 IO 职责检测 IO检测 io剖析 操作 IO 阻塞IO 和 非阻塞IOIO 多路复用epoll结构以及接口 reactor编程连接建立连接断开数据到达数据发送完毕 reactor 应用:后续补充源码解析单 reacrtor多…...
)
【机电、机器人方向会议征稿|不限专业|见刊快】2024年机械、 图像与机器人国际会议(IACMIR 2024)
【机电、机器人方向会议征稿|不限专业|见刊快】2024年机械、 图像与机器人国际会议(IACMIR 2024) 2024 International Academic Conference on Machinery, Images, and Robotics 会议将聚焦“机械、成像和机器人”相关的最新研究领域,为国内…...

uniapp学习之路
uniapp 学习之路 1. 下载HBuilderX2. 下载uView初始框架3. 开始学习1.更改页面背景色,渐变色 1. 下载HBuilderX https://www.dcloud.io/hbuilderx.html?ivk_sa1024320u2. 下载uView初始框架 https://ext.dcloud.net.cn/plugin?id15933. 开始学习 1.更改页面背景…...
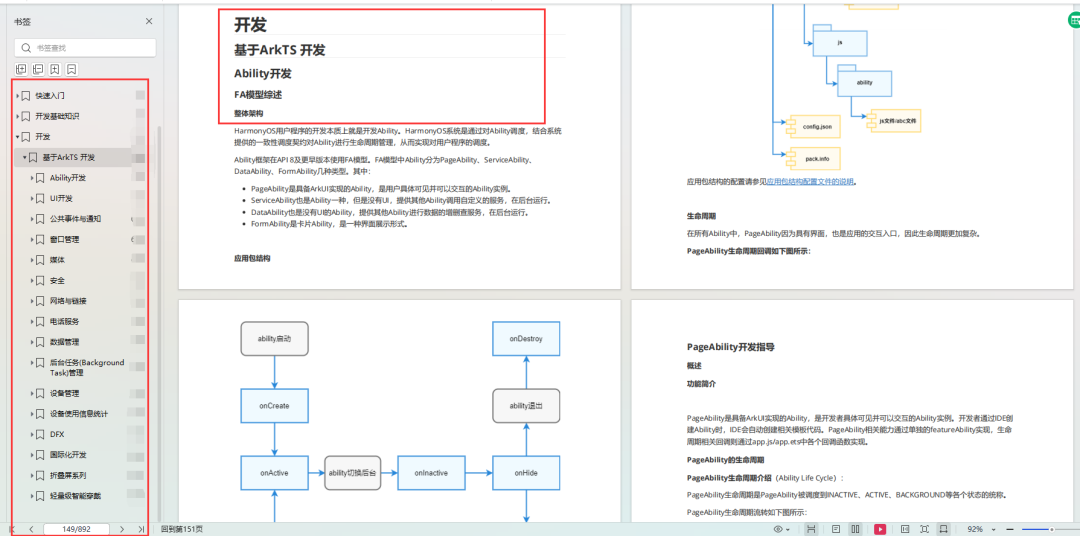
移动开发新的风口?Harmony4.0鸿蒙应用开发基础+实践案例
前段时间鸿蒙4.0引发了很多讨论,不少业内人士认为,鸿蒙将与iOS、安卓鼎足而三了。 事实上,从如今手机操作系统竞赛中不难看出,安卓与iOS的形态、功能逐渐趋同化,两大系统互相取长补短,综合性能等差距越来越…...
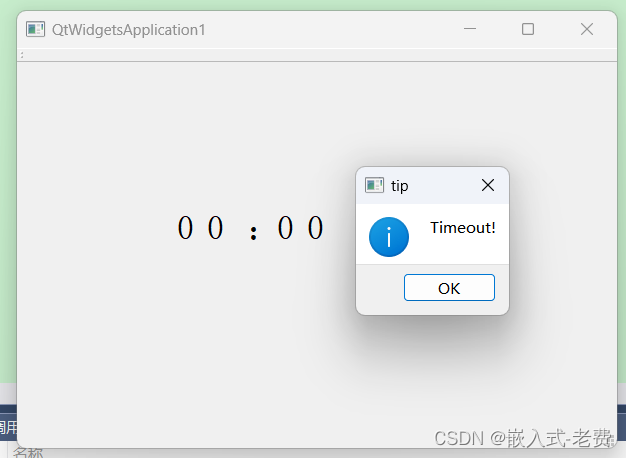
QT上位机开发(倒计时软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 倒计时软件是生活中经常遇到的一种场景。比如运动跑步,比如学校考试,比如论文答辩等等,只要有时间限制规定的地…...

2023 楚慧杯 --- Crypto wp
文章目录 初赛so large e 决赛JIGE 初赛 so large e 题目: from Crypto.Util.number import * from Crypto.PublicKey import RSA from flag import flag import randomm bytes_to_long(flag)p getPrime(512) q getPrime(512) n p*q e random.getrandbits(1…...
Python+OpenCV 零基础学习笔记(1-3):anaconda+vscode+jupyter环境配置
文章目录 前言相关链接环境配置:AnacondaPython配置OpenCVOpencv-contrib:Opencv扩展 Notebook:python代码笔记vscode配置配置AnacondaJupyter文件导出 前言 作为一个C# 上位机,我认为上位机的终点就是机器视觉运动控制。最近学了会Halcon发现机器视觉还…...

汽车电子安全:从CAN总线到纵深防御的嵌入式安全实战
1. 从“汽车黑客”到“数字堡垒”:一位嵌入式工程师的十年安全观演进十多年前,当EE Times那场关于“汽车黑客是否值得担忧”的在线聊天发起时,我正埋头于一个汽车ECU(电子控制单元)的底层驱动开发。彼时,“…...

ExifToolGUI:如何轻松批量管理照片元数据的完整指南
ExifToolGUI:如何轻松批量管理照片元数据的完整指南 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾经面对成百上千张照片,想要批量修改拍摄时间、添加版权信息或调整GPS坐标…...

【博安通BW16模组专题②】实战TCP客户端:从指令到云端数据透传
1. 认识BW16模组的TCP客户端功能 博安通BW16模组作为一款高性价比的物联网通信模块,其TCP客户端功能在实际项目中应用广泛。简单来说,TCP客户端就是能够主动连接服务器的终端设备,比如我们常见的智能家居设备连接云端服务器,就是典…...

从“能用”到“可靠”:基于SonarQube与Jenkins的代码质量防线构建实战
当测试覆盖率不再只是一串数字,而是合并代码前的“一票否决权” 1. 为什么你的“质量门禁”只是个摆设? 在很多团队的CI/CD流水线中,SonarQube的集成往往停留在“能跑就行”的阶段。流水线里确实有代码扫描这一步,日志里也打印出…...

Prompt工程实战:从CRISPE框架到垂直应用,解锁AI模型高效协作
1. 项目概述与核心价值 如果你正在寻找一套能真正“榨干”ChatGPT、Midjourney、Stable Diffusion等主流AI模型潜力的中文提示词(Prompt)集合,那么你找对地方了。 langgptai/wonderful-prompts 这个开源项目,正是由《ChatGPT中文…...

KouriChat + DeepSeek + 微信接入:本地 AI 角色聊天机器人搭建实录
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 文章目录: 前言1 KouriChat项目简介2 环境准备3 环境安装及项目部署3.1 Python3.11 安装3.2 启动KouriC…...
)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点) 在工业自动化领域,老旧产线升级改造往往面临新旧设备通讯协议不兼容的难题。当传统S7-300系统需要与现代化S7-400或带PN接口的PLC进行数据交互时…...
)
HDFS源码(二)
DataNode启动源码 创建HttpServer 初始化DataNode Rpc服务 获取NameNode Rpc代理 Datanode向NameNode注册 DataNode与NameNode周期心跳及block块汇报 数据上传源码 创建文件系统及初始化DFSClient 连接NN创建目录 启动DataStreamer线程 向dataQueue队列中写入packet 设置副本写…...

第1篇:认识Go——我的第一个程序 Go中文编程
第1篇:认识Go——我的第一个程序**作者:**中文编程倡导者—— 李金雨 联系方式: wbtm2718qq.com目标:让你成功运行第一个Go程序,建立学习信心! 预计时间:2课时(90分钟) 难…...

别再手动下载了!用Chocolatey在Windows上一键安装Zookeeper 3.8.0
告别繁琐配置:用Chocolatey在Windows上极速部署Zookeeper 每次在Windows环境下部署Zookeeper,你是否还在重复下载压缩包、配置环境变量、修改配置文件的传统流程?对于追求效率的开发者而言,这种手动操作不仅耗时耗力,还…...