【flink】 flink入门教程demo 初识flink
文章目录
- 通俗解释什么是flink及其应用场景
- flink处理流程及核心API
- flink代码快速入门
- flink重要概念
什么是flink? 刚接触这个词的同学 可能会觉得比较难懂,网上搜教程 也是一套一套的官话, 如果大家熟悉stream流,那或许会比较好理解 就是流式处理。博主也是刚学习,简单做了个入门小结,后续学习 文章也会不断完善
通俗解释什么是flink及其应用场景
flink是一个流式处理框架,且高性能。说通俗点就是把数据转成流的形式进行处理,可以在多进程中执行,而且是分布式架构 支持集群部署
那么实际应用场景是怎么样的呢?还是通俗点举例,我们可以将文本文件中的内容,通过flink流式读取、统计等操作,这是最基础的操作;也可以监听服务器端口,不断从端口获取数据 并进行处理;还可以把消息队列中的消息进行读取; 此外,用于IOT场景也是没有问题的。比如某社交网站,要实时统计点赞排行榜,就可以通过flink进行处理。换句话说,有数据的地方,都可以用flink处理。
flink是基于内存的,所以高效;
与大多数组件一样,内存不安全,所以会有持久化的功能 checkPoint
flink本身就是为大数据服务的,所以避免宕机风险 能够支持集群部署
当然 杀鸡焉用牛刀 ,flink一般是在大数据量的情况下,才会使用的。
flink处理流程及核心API
在此之前,我们看看在flink出现之前的上一代架构:
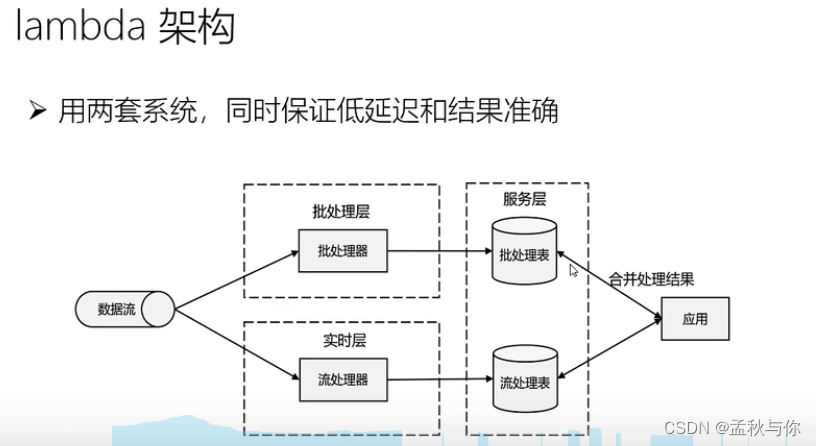
批处理:有序 低速
流处理:无序 高速
lambda架构是有两套处理方式的,而flink的出现,可以实现批流处理。
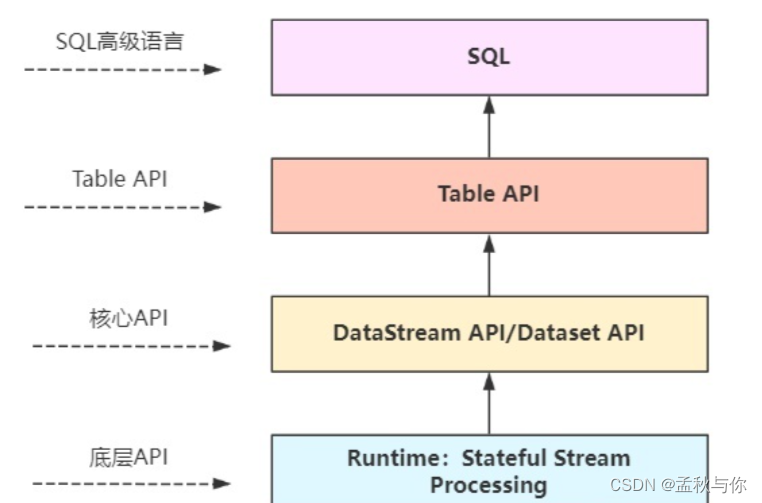
flink的四层API
- 流处理和批处理 都是基于DataStream和DataSet
- 早期flink批处理都是基于DataSet API ,在1.12版本开始 统一使用 DataStream 就可实现批流处理
flink代码快速入门
下面快速入门 在springboot环境中flink的应用 , 注意导包不要导错了。
我们的demo业务场景是 统计words.txt中 每个单词出现的次数。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.PostConstruct;/*** DataSet API 批处理 (有序 低速)**//*** flink 分层api** SQL 最高层语言* table API 声明式领域专用语言* DataStream / DataSet API 核心Apis* (流处理和批处理 基于这两者 早期flink批处理都是基于DataSet API 在1.12版本开始 统一使用 DataStream 就可实现批流处理)* 有状态流处理 底层APIs*/
@RestController
public class DataSetAPIBatchWordCount {@PostConstructpublic void test() throws Exception {// 1. 创建一个执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件中读取数据// 继承自Operator Operator 继承自DataSet , DataSource基于DataSetDataSource<String> lineDataSource = env.readTextFile("input/words.txt");// 3. 逻辑处理: 将每行数据进行分词 转换成二元组类型FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap(// 将每行打散 放到一个收集器里(String line, Collector<Tuple2<String, Long>> out) -> {// 将一行文本进行分词String[] words = line.split(" ");// 将每个单词转换成二元组分组for (String word : words) {// 每来一个单词 计数1out.collect(Tuple2.of(word, 1L));}// 因为有泛型擦除 所以需要指定回类型}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 按照word进行分组 groupBy可以传入索引位置 0表示索引 of(word 0)UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);// 5. 分组内 进行累加 1表示索引 of(word 索引0 , 1L 索引1);AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);// 6. 打印输出sum.print();}}
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.PostConstruct;/*** DataStream API 批处理* (启动jar包时 指定模式)*/
@RestController
public class DataStreamAPIBatchWordCount {@PostConstructpublic void test() throws Exception {// 1. 创建流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文件 (有界流)DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");// 3. 转换计算SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 分组操作 wordAndOneTuple.keyBy(0) 根据0索引位置分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(item -> item.f0);// 5. 求和SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);// 6. 打印sum.print();// 7. 启动执行 上面步骤只是定义了流的执行流程env.execute();// 数字表示子任务编号 (默认是cpu的核心数 同一个词会出现在同一个子任务上进行叠加)
// 3> (java,1)
// 9> (test,1)
// 5> (hello,1)
// 3> (java,2)
// 5> (hello,2)
// 9> (test,2)
// 9> (world,1)
// 9> (test,3)}
}文本文件位于根目录的input目录下
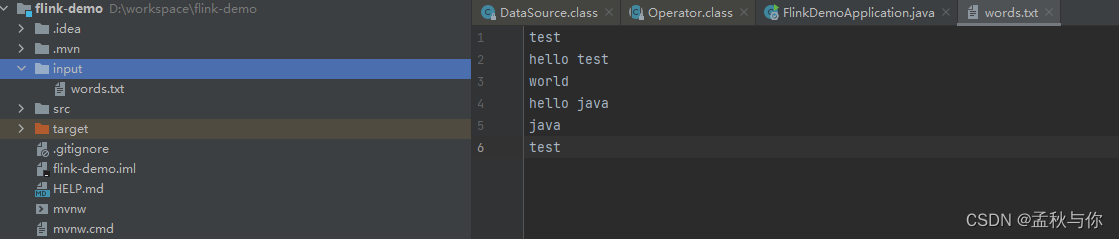
test
hello test
world
hello java
java
test
运行:启动application中的main方法即可
flink重要概念
JobManger
TaskManger
JobManger是调度中心,将客户端的数据收集成任务,分发给TaskManger执行,
TaskManger是真正执行任务的地方。
JobManger可以理解为master, TaskManger可以理解为worker (slaver)
相关文章:
【flink】 flink入门教程demo 初识flink
文章目录通俗解释什么是flink及其应用场景flink处理流程及核心APIflink代码快速入门flink重要概念什么是flink? 刚接触这个词的同学 可能会觉得比较难懂,网上搜教程 也是一套一套的官话, 如果大家熟悉stream流,那或许会比较好理解…...

LeetCode 1487. 保证文件名唯一
【LetMeFly】1487.保证文件名唯一 力扣题目链接:https://leetcode.cn/problems/making-file-names-unique/ 给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。 由于两个…...

详细剖析|袋鼠云数栈前端框架Antd 3.x 升级 4.x 的踩坑之路
袋鼠云数栈从2016年发布第⼀个版本开始,就始终坚持着以技术为核⼼、安全为底线、提效为⽬标、中台为战略的思想,坚定不移地⾛国产化信创路线,不断推进产品功能迭代、技术创新、服务细化和性能升级。 在数栈过去的产品迭代中受限于当前组件的…...

【C++PrimerPlus】第三章 处理数据
文章目录前言内容目录3.1 简单变量3.1.2 变量名3.1.2 整形3.1.3 整形short,int,long,long long3.1.4 无符号类型3.1.5 选择整形类型3.1.6 整形字面值3.1.7 C如何确定常量的类型3.1.8 char类型:字符和小整数3.1.9 bool类型3.2 const修饰符3.3浮点数3.3.1 书写浮点数3…...

【基础算法】单链表的OJ练习(1) # 反转链表 # 合并两个有序链表 #
文章目录前言反转链表合并两个有序链表写在最后前言 上一章讲解了单链表 -> 传送门 <- ,后面几章就对单链表进行一些简单的题目练习,目的是为了更好的理解单链表的实现以及加深对某些函数接口的熟练度。 本章带来了两个题目。一是反转链表&#x…...
命题逻辑)
离散数学笔记(1)命题逻辑
文章目录1.命题符号化及联结词基本概念本节题型2.命题公式及分类基本概念本节题型1.命题符号化及联结词 基本概念 命题的定义:能够判断真假的陈述句称为命题。 备注:感叹句、疑问句、祈使句和类似于xy>5之类真值不唯一的句子都不是命题。 真值的真假…...
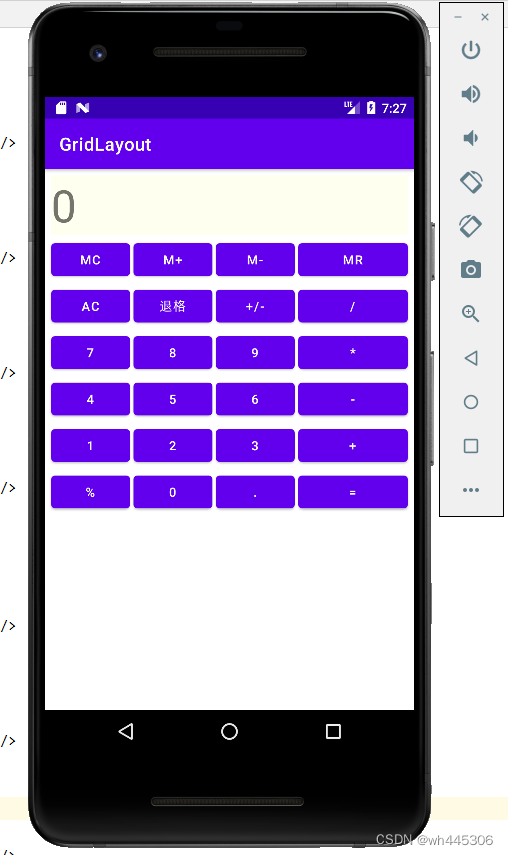
IDEA Android 网格布局(GridLayout)示例(计算器界面布局)
网格布局(GridLayout) 示例程序效果(实现类似vivo手机自带计算器UI) 真机和模拟器运行效果: 简述: GridLayout(网格布局)和TableLayout(表格布局)有类似的地方,通俗来讲可以理解为…...

【蓝桥杯嵌入式】拓展板之数码管显示
文章目录硬件电路连接方式函数实现文章福利硬件电路 通过上述原理图,可知拓展板上的数码管是一个共阴数码管,也就是说某段数码管接上高电平时,就会点亮。 上述原理图还给出一个提示,即:三个数码管分别与三个74HC59…...
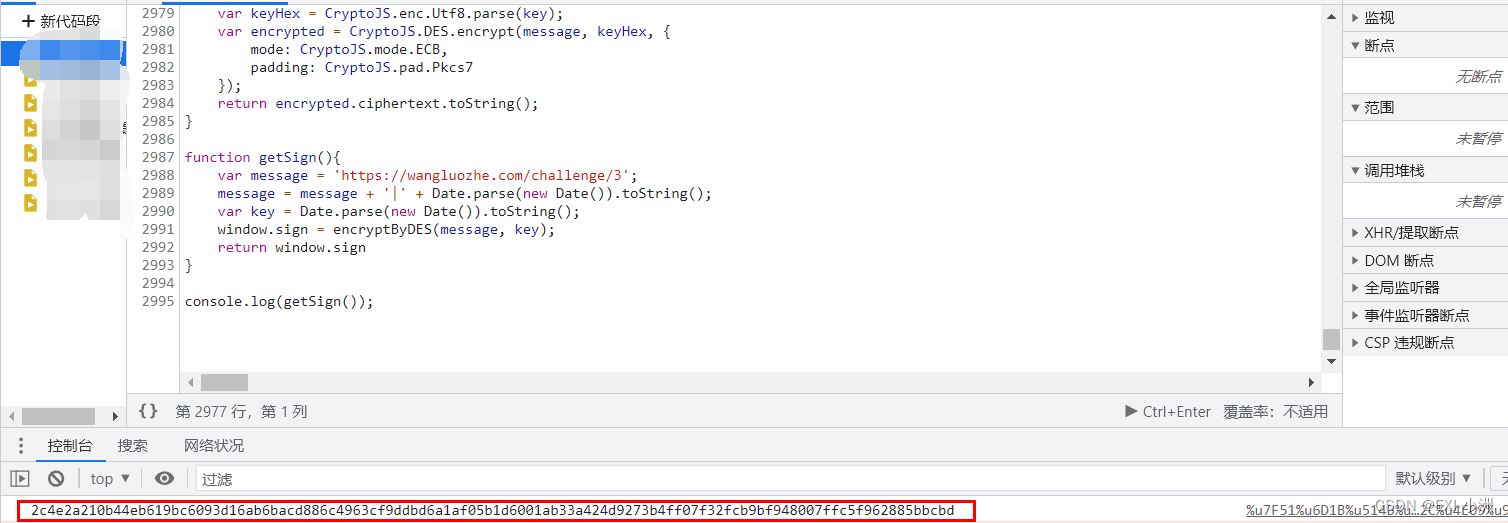
Web Spider案例 网洛克 第三题 AAEncode加密 练习(七)
声明 此次案例只为学习交流使用,抓包内容、敏感网址、数据接口均已做脱敏处理,切勿用于其他非法用途; 文章目录声明一、资源推荐二、逆向目标三、抓包分析 & 下断分析逆向3.1 抓包分析3.2 下断分析逆向拿到混淆JS代码3.3 AAEncode解决方…...
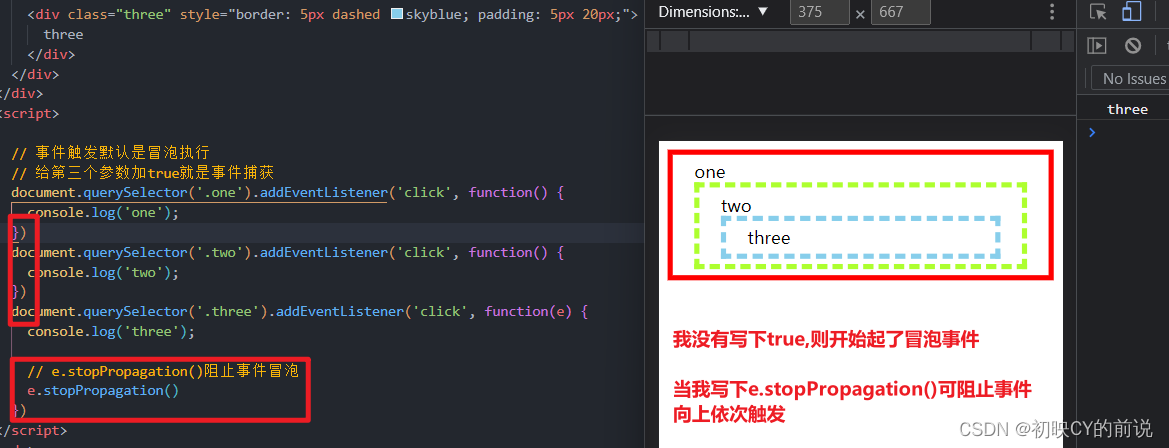
【javaScript面试题】2023前端最新版javaScript模块,高频24问
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的关于javaScript的面试题 目录 一、2023javaScript面试题精选 1.js的数据类型…...

Hadoop集群启动从节点没有DataNode
一、问题背景 之前启动hadoop集群的时候都没有问题,今天启动hadoop集群的时候,从节点的DataNode没有启动起来。 二、解决思路 遇见节点起不来的情况,可以去看看当前节点的日志文件 我进入当前从节点的hadoop安装目录的Logs文件下去查看日…...
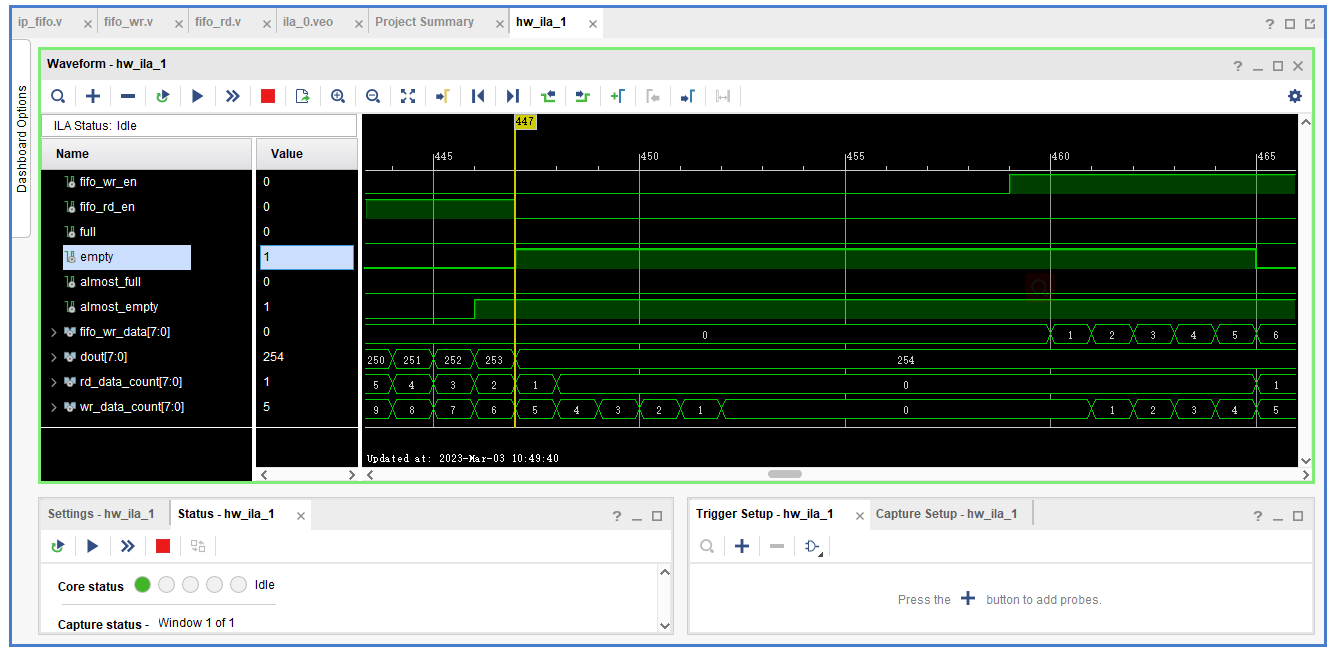
FIFO IP Core
FIFO IP Core 先进先出的缓存器常常被用于数据的缓存,或者高速异步数据交互(跨时钟信号传递)和RAM和ROM的区别是没有地址线,无法指定地址 写时钟(Write Clock Domain),读时钟写复位(wr_rst),读…...

从FPGA说起的深度学习(四)
这是新的系列教程,在本教程中,我们将介绍使用 FPGA 实现深度学习的技术,深度学习是近年来人工智能领域的热门话题。在本教程中,旨在加深对深度学习和 FPGA 的理解。用 C/C 编写深度学习推理代码高级综合 (HLS) 将 C/C 代码转换为硬…...
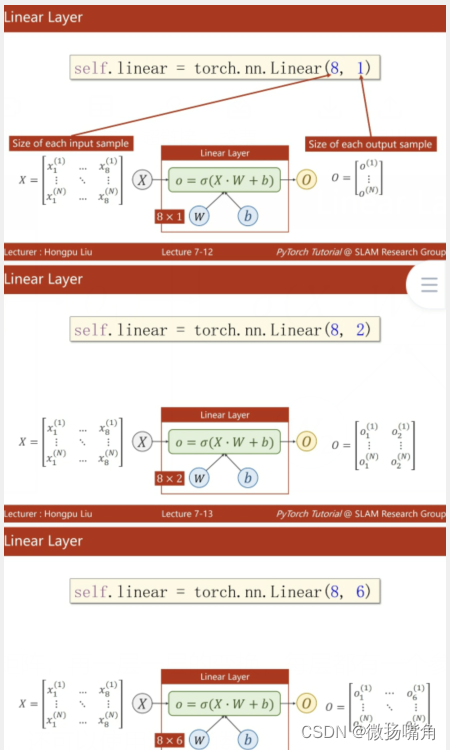
pytorch入门7--自动求导和神经网络
深度学习网上自学学了10多天了,看了很多大神的课总是很快被劝退。终于,遇到了一位对小白友好的刘二大人,先附上链接,需要者自取:https://b23.tv/RHlDxbc。 下面是课程笔记。 一、自动求导 举例说明自动求导。 torch中的…...

QT 之wayland 事件处理分析基于qt5wayland5.14.2
1. Qt wayland 初始化 接收鼠标/案件,触摸屏等事件事件 QWaylandNativeInterface : public QPlatformNativeInterface 在QWaylandNativeInterface 继承qpa 接口类QPlatformNativeInterface; 1.1 初始化鼠标: void *QWaylandNativeInterface::nativeR…...

【this 和 super 的区别】
在 Java 中,this 和 super 都是关键字,表示当前对象和父类对象。 this 关键字可以用于以下几种情况: 引用当前对象的成员变量,方法和构造方法,用于区分局部变量和成员变量重名的情况; 调用当前类的另外一…...
K8s:Monokle Desktop 一个集Yaml资源编写、项目管理、集群管理的 K8s IDE
写在前面 Monokle Desktop 是 kubeshop 推出的一个开源的 K8s IDE相关项目还有 Monokle CLI 和 Monokle Cloud相比其他的工具,Monokle Desktop 功能较全面,涉及 k8s 管理的整个生命周期博文内容:Monokle Desktop 下载安装,项目管理…...

自动化测试实战篇(8),jmeter并发测试登录接口,模拟从100到1000个用户同时登录测试服务器压力
首先进行使用jmeter进行并发测试之前就需要搞清楚线程和进程的区别还需要理解什么是并发、高并发、并行。还需要理解高并发中的以及老生常谈的,TCP三次握手协议和TCP四次握手协议**TCP三次握手协议指:****TCP四次挥手协议:**进入Jmeter&#…...

ATTCK v12版本战术实战研究—持久化(二)
一、前言前几期文章中,我们介绍了ATT&CK中侦察、资源开发、初始访问、执行战术、持久化战术的知识。那么从前文中介绍的相关持久化子技术来开展测试,进行更深一步的分析。本文主要内容是介绍攻击者在运用持久化子技术时,在相关的资产服务…...

python函数式编程
1 callable内建函数判断一个名字是否为一个可调用函数 >>> import math >>> x 1 >>> y math.sqrt >>> callable(x) False >>> callable(y) True 2 记录函数(文档字符串) >>> def square(x): …...

从ANSI到EBCDIC:跨越地域与时代的字符编码全景解析
1. 字符编码的前世今生:从ASCII到EBCDIC 第一次在Windows记事本里保存文件时,看到"ANSI"这个选项我就懵了——这玩意儿和ASCII有什么关系?后来在跨国项目里处理日文数据时,更被SJIS和EUC-JP搞得焦头烂额。字符编码就像…...

【开发实战】【memtester】嵌入式系统内存稳定性保障:从工具原理到压力测试场景全解析
1. 为什么嵌入式系统需要内存稳定性测试 在嵌入式产品量产前,内存稳定性测试是硬件验证中最容易被忽视却至关重要的环节。我曾参与过一个智能家居网关项目,设备在实验室运行一切正常,但批量部署后却频繁出现随机重启。经过两周的排查…...

完整指南:3分钟解锁你的加密音乐文件
完整指南:3分钟解锁你的加密音乐文件 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经遇到过这样的情况:从音乐平台下载的歌曲只能在特定应…...

为什么Windows界面定制工具能让你找回高效工作节奏?
为什么Windows界面定制工具能让你找回高效工作节奏? 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 当我们习惯了多年的Windows操作…...

3天搞定中文API大全:从菜鸟到高手的完整指南
3天搞定中文API大全:从菜鸟到高手的完整指南 嘿,开发者!你是不是经常为找一个好用的API而烦恼?项目做到一半,突然发现某个API文档全是英文,看得头大?别担心,今天我要给你介绍一个超级…...

从‘监控谁’到‘如何查’:手把手教你用Prometheus标签玩转K8s监控数据筛选
从‘监控谁’到‘如何查’:手把手教你用Prometheus标签玩转K8s监控数据筛选 在Kubernetes集群监控领域,数据洪流是每个运维人员必须面对的挑战。当数百个Pod不断创建销毁时,传统静态配置的监控方式显得力不从心。这正是Prometheus标签系统大显…...

微信AI机器人搭建全攻略:基于WeChatFerry与ChatGPT的自动化消息回复
1. 项目概述与核心思路 最近在折腾一个挺有意思的玩意儿:一个能帮你自动回复微信消息的AI机器人。这项目叫 wechat-bot ,虽然原作者已经暂停维护,但它的核心思路和实现方式,对于想自己动手搞点自动化工具的朋友来说,…...

茉莉花插件:重塑你的中文文献研究新范式
茉莉花插件:重塑你的中文文献研究新范式 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 作为一名学术研究者ÿ…...

别埋头苦选了!用对方法,俄罗斯的爆款就是你的货源!
标题建议(任选其一):🔥 扒光了同行底裤:跨境电商“无货源拿货”的顶级神操作,原来他们都在这么干!别再傻乎乎囤货了!一张图看懂“Ozon爆品 ➡️ 1688源头”的极速变现闭环。跨境圈不…...

AI助手配置同步工具:解决多工具MCP服务器与指令文件统一管理难题
1. 项目概述与核心痛点如果你和我一样,日常开发中同时使用多个AI编程助手——比如主力用Claude Code,但偶尔也会切到Gemini CLI、Codex CLI、Cursor、Kimi CLI这些工具,去蹭蹭它们的免费额度或者体验下不同的模型能力——那你一定深有体会&am…...