Spring Boot日志:从Logger到@Slf4j的探秘
写在前面
Hello大家好,今日是2024年的第一天,祝大家元旦快乐🎉 2024第一篇文章从SpringBoot日志开始


文章目录
- 一、前言
- 二、日志有什么用?
- 三、日志怎么用?
- 四、自定义日志打印
- 💬 常见日志框架说明
- 4.1 在程序中得到⽇志对象【Logger】
- 4.2 使⽤⽇志对象打印⽇志
- 4.3 ⽇志格式解读
- 五、日志级别
- 5.1 日志级别的作用
- 5.3 日志级别分类和使用
- 六、日志持久化【将日志保存下来】
- 6.1 设置日志的保存路径
- 6.2 配置⽇志⽂件的⽂件名
- 七、更简单的⽇志输出 — lombok
- 7.1 添加 lombok 依赖
- 7.2 使用 @slf4j 输出日志
- 7.3 lombok 原理解释
- 7.4 lombok 更多注解说明
- 八、总结与提炼
一、前言
在我们日常的公司开发中,难免都会存在着大大小小的BUG,不可能会有公司说我们的项目做出来是没有BUG的,那既然或多或少会BUG的话,要如何去发现BUG呢?
- 那对于我们程序员来说,首先会想到的就是DeBug调试,有关IDEA的一些调试技巧,读者可以看看和这个视频 链接
- 但是除了调试之外,其实我们还有其他的方法,既然我们在学习SpringBoot的话,那就要知道它里面其实有个东西叫做 日志文件,对于【日志】来说相信对大部分的开发者来说也是不陌生的,因为我们日常的开发中如果遇到一些问题的话,其实第一时间就会去查找日志,因为有些错误仅仅通过调试是排查不出来的,甚至是专业的排查工具也做不到,但是【日志】却记录了很多程序运行过程中的种种细节
💬 接下去就让我们来看看日志到底是个什么东西?
二、日志有什么用?
-
记录错误日志和警告日志(发现和定位问题):
- 在交了钱之后却没有这位同学的记录了,后期只能靠错误日志去排查
-
记录用户的登录日志:
- 通过记录同学们的登录时间,教务系统更新的时间
- 如果发现有恶意的用户,就将其IP加入到黑名单中
-
记录系统的操作日志:
- 比方说在教务系统不小心将一个同学的班级转错了,那就需要操作日志来进行数据恢复
- 还可以通过这个操作日志才定位到操作人,是谁误操作了,防止推卸责任
-
程序执行日志:
三、日志怎么用?
Spring Boot 项⽬在启动的时候默认就有⽇志输出,如下图所示:

💬 那有同学就会说,既然都有日志了,为什么还要再去学习呢?
此时我便提出了以下几个问题
- 既然SpringBoot已经内置了日志,那就要去明白它内置的日志究竟是什么?
- 默认情况下,输出的⽇志并⾮是开发者定义和打印的,那开发者怎么在程序中⾃定义打印⽇志呢?
- ⽇志默认是打印在控制台上的,⽽控制台的⽇志是不能被保存的,那么怎么把⽇志永久的保存下来呢?
- 既然它已经内置了日志框架了,那这个框架应该怎么用?
下⾯我们⼀起来找寻这些问题的答案🔍
四、自定义日志打印
有的同学认为我们日常在写代码时使用
System.out.println()输出的内容就是日志,那我们可以用这个方法来打印看看
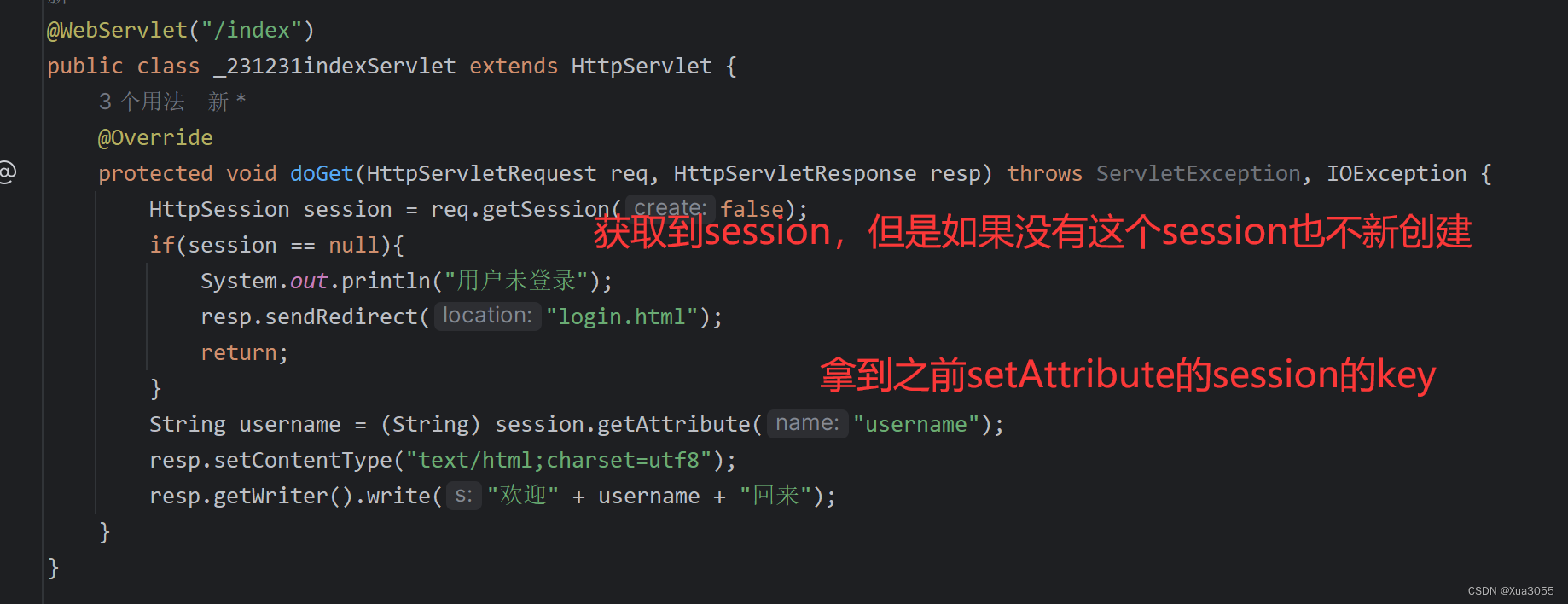
@RequestMapping("/sayhi")
public String sayHi(){System.out.println("打印日志");return "hello world ->" + myconfig;
}
- 可以看到,只是在这个方法调用之后打印了对应的语句,但是这却不是我们想要看到的相关程序信息
💬 那么接下来我来介绍如何通过得到日志对象来打印日志
💬 常见日志框架说明
在这之前呢,我们要先来聊聊前面所提到的【日志框架】,首先你要知道的一点是:SpringBoot是内置了日志框架的
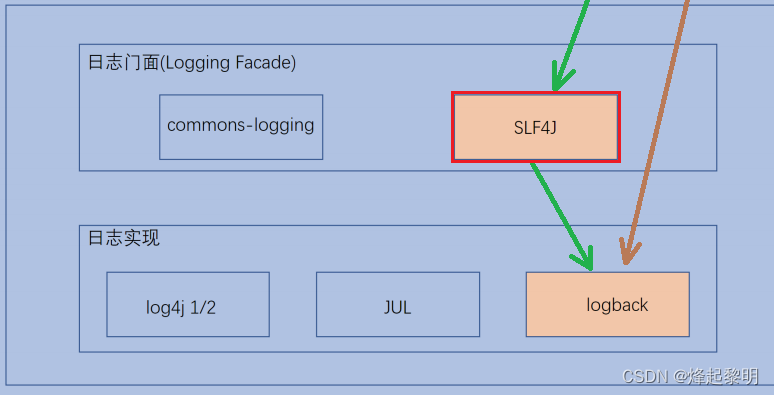
- 我们可以来讲讲用户获取日志的调用流程:
- 用户在去写日志的时候不是直接具体去操作某个框架的,而是会先来到一个 日志门面 叫做
Slf4j - 然后
Slf4j再根据系统的配置决定要调用的具体框架是什么
- 用户在去写日志的时候不是直接具体去操作某个框架的,而是会先来到一个 日志门面 叫做
👉这个Slf4j呢就类似于 房产中介🏠,我们在买房的时候不可能一家家地去找,而是通过房产中介来进行对接以此可以看到不同的户型
- 我们在最早的时候使用这个
log4j 1是比较多的,后面就慢慢升级成log4j 2了
⚠ 注意:在去年log4j 被报出了漏洞,而且漏洞很严重,它可以通过这个漏洞直接把你的应用服务给关掉。那这个其实对许多公司来说是很大的一个问题,这里的话就不细讲了,有兴趣的同学可以去了解一下 链接
- 所以到后面我们都换成了
logback这个日志框架了,它就有人维护比较稳定一些,不过它的写法就不太一样了,类名、方法名都不一样了,所以我们直接去对接这个框架的话成本是非常高的,但如果此时我们有了Slf4j这个门面就不一样了💡 - 就和我们之前在讲解 JDBC连接数据库 的时候一样,为什么要有JDBC呢?就是因为不同的数据库有不同的驱动,如果当一个项目突然要换数据库的话(MySQL —> Oracle),就会很麻烦了。所以我们才有了JDBC这个东西,程序员直接去操作JDBC就可以了,它就是一套规范,就是一个【门面】,程序员们通过JDBC去适配不同的数据库,就可以做到很好地
解耦了
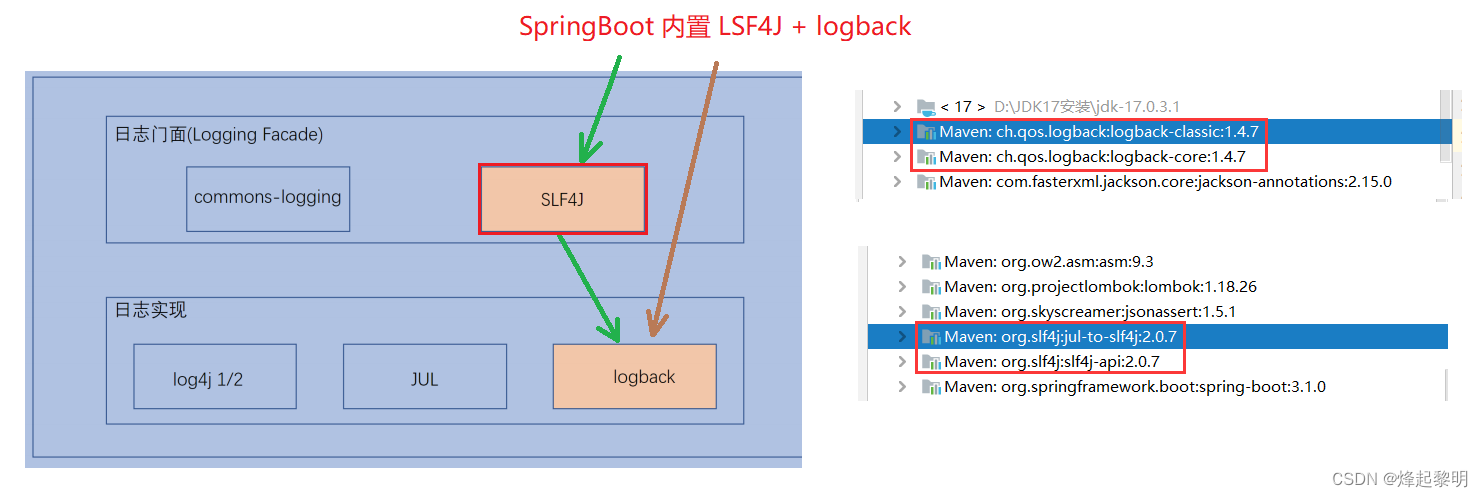
💬 我们也可以去验证一下SpringBoot是否真的内置了这两个框架,那可以观察到确实是有的
4.1 在程序中得到⽇志对象【Logger】
在大致了解了SpringBoot中内置的框架后,我们就可以去试试看要如何获取到当前程序的日志
⭐不过对于个日志对象的定义可以非常有讲究的
- 首先要明白我们这个日志对象是:
- 方法级别(只能在某一个方法中去使用)
- 类级别(可以在整个类的任何地方都能使用)
👉 那可以很清楚地知道,我们和这个日志对象一定是类级别的,因为要在整个类的任何方法都能获取到
- 那还要看的是这个日志对象是
共有的还是私有的,那可以很明确,每个类都有自己的日志对象,所以它肯定是私有的,所以要用private来进行修饰 - 并且这个还得是 静态的,让其可以在方法中直接调用,那么就要用
static来进行修饰 - 还有一点:你期望这个日志对象在某个方法中被修改吗?当然不想!所以我们还要再加上
final关键字作为修饰
那么再加上一步步的修饰后,我们就要通过
Slf4j所提供的接口去新建出一个日志对象了,注意在这里我们要选择org.slf4j这个包下的,不要导⼊错包!
- 那我们知道,对于一个接口来说是我们在获取⽇志对象还需要使⽤⽇志⼯⼚ LoggerFactory,然后使用到里面的
getLogger这个方法,这里一共有两种重写方法,我们先选择Class<?> clazz
以下是它的源码,我们后面通过查看打印出来日志的形式来进行观察:
public static Logger getLogger(Class<?> clazz) {Logger logger = getLogger(clazz.getName());if (DETECT_LOGGER_NAME_MISMATCH) {Class<?> autoComputedCallingClass = Util.getCallingClass();if (autoComputedCallingClass != null && nonMatchingClasses(clazz, autoComputedCallingClass)) {Util.report(String.format("Detected logger name mismatch. Given name: \"%s\"; computed name: \"%s\".", logger.getName(), autoComputedCallingClass.getName()));Util.report("See https://www.slf4j.org/codes.html#loggerNameMismatch for an explanation");}}return logger;
}
4.2 使⽤⽇志对象打印⽇志
- 接下去我们就将这个日志对象给打印出来吧
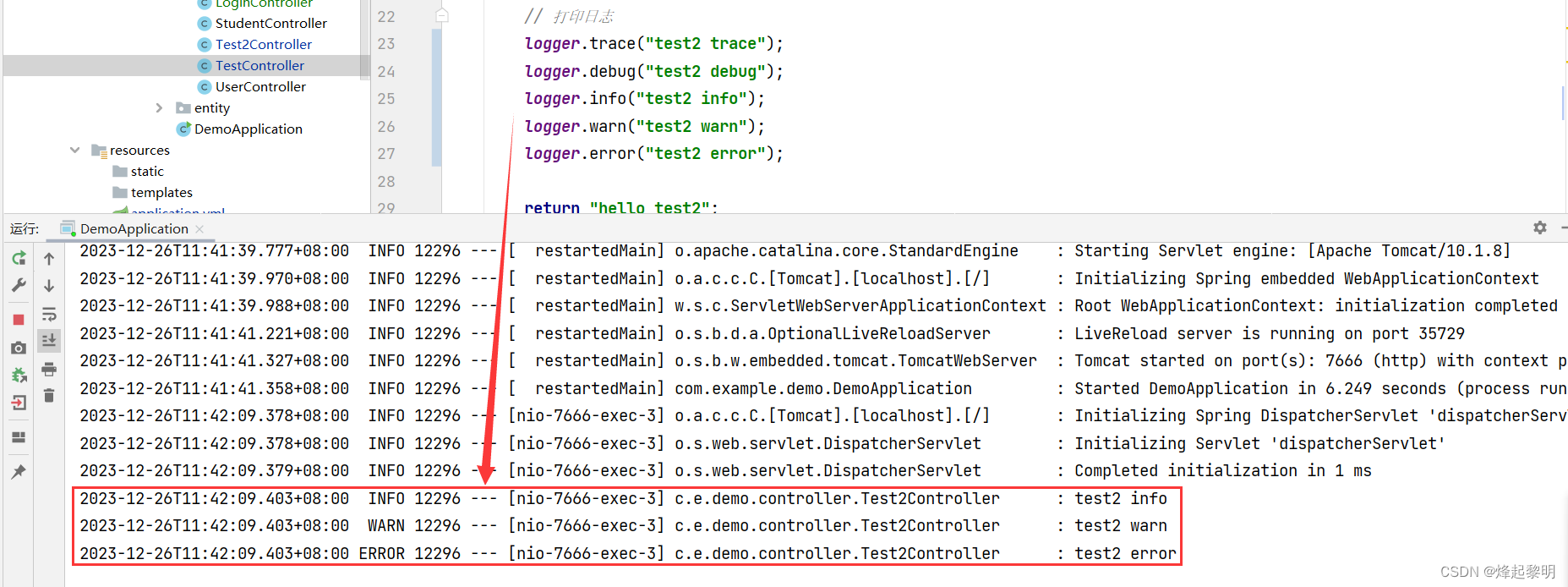
// 打印日志
logger.trace("test2 trace");
logger.debug("test2 debug");
logger.info("test2 info");
logger.warn("test2 warn");
logger.error("test2 error");
- 通过运行并访问路由,我们可以发现当前程序的日志信息被打印出来了,但是呢却不是从
trace开始打印的,而是从info开始打印的,这个的话就要追溯到 日志等级的优先级 和 默认级别 了,这个我们在下一模块会展开详细讲解
4.3 ⽇志格式解读
看到了打印出来的日志信息后,相信有很多读者并不是很了解每一条日志信息到底想告诉我们什么,现在就让我们来分析一下这些日志信息吧

- 这里我们主要来关注两块地方:
- 第一个是这边的包名,你是否觉得
c.e.controller这个名称有点熟悉呢?没错,它就是我们在这个包下创建类的时候自动导入的包名,前面两个c和e即为缩写
package com.example.demo.controller;- 第二块的话就是后面的类名
Test2Controller了,这个的话就要去回忆我们上面为 工厂类LoggerFactory 中的getLogger这个方法所传入的当前类类名,所以SpringBoot靠着这些很好地识别到并打印出了相应的日志信息
- 第一个是这边的包名,你是否觉得
还记得我们在上面所谈到的
getLogger这个方法的第二种形式吗,我们一起再来看看
- 此时我们再创建一个类,然后采取不同的
getLogger方法
- 以下是具体的测试代码
@RestController // = @Controller + @ResponseBody
public class StudentController {private static final Logger logger = LoggerFactory.getLogger("StudentController");@RequestMapping("/stu/sayhi")public String sayhi(){logger.info("student info");logger.error("student error");return "student sayhi";}
}
- 然后我们来观察一下结果并与之前的方法进行一个对比就可以发现所打印出来的日志信息有着很大的不同,对于传入
name来说所并不会展现出完整的包名路径,而是只有一个类名,所以想看到怎么样的日志信息读者可以自己来进行控制

以下是它的源码,供阅读参考
public static Logger getLogger(String name) {ILoggerFactory iLoggerFactory = getILoggerFactory();return iLoggerFactory.getLogger(name);
}
五、日志级别
整体地介绍完日志消息后,我们再来详细地介绍一下其中的一个东西叫做【日志级别】
5.1 日志级别的作用
- ⽇志级别可以帮你筛选出重要的信息,⽐如设置⽇志级别为
error,那么就可以只看程序的报错⽇志了,对于普通的调试⽇志和业务⽇志就可以忽略了,从⽽节省开发者信息筛选的时间。 - ⽇志级别可以控制不同环境下,⼀个程序是否需要打印⽇志,如【开发环境】我们需要很详细的信息,⽽【⽣产环境】为了保证性能和安全性就会输⼊尽量少的⽇志,⽽通过⽇志的级别就可以实现此需求。
5.3 日志级别分类和使用
-
trace:微量,少许的意思,级别最低; -
debug:需要调试时候的关键信息打印; -
info:普通的打印信息(默认⽇志级别); -
warn:警告,不影响使⽤,但需要注意的问题; -
error:错误信息,级别较⾼的错误⽇志信息; -
fatal:致命的,因为代码异常导致程序退出执⾏的事件。
⽇志级别的顺序:
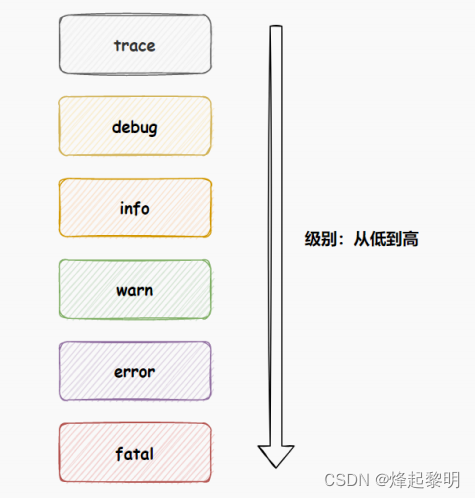
💬 级别越高所能接收到的消息就越少了,比如说error只能接收到error和fatal级别的日志
清楚各个日志级别后,我们就来配置文件中实际地来操作一下吧💻
- ⽇志级别配置只需要在配置⽂件中设置
“logging.level”配置项即可,如下所示:
# 日志级别设置
logging:level:root: error
- 然后我们通过去访问不同的路由地址就可以看到,即使我们选择打印不同的日志级别,但是打印出来的内容只有
error
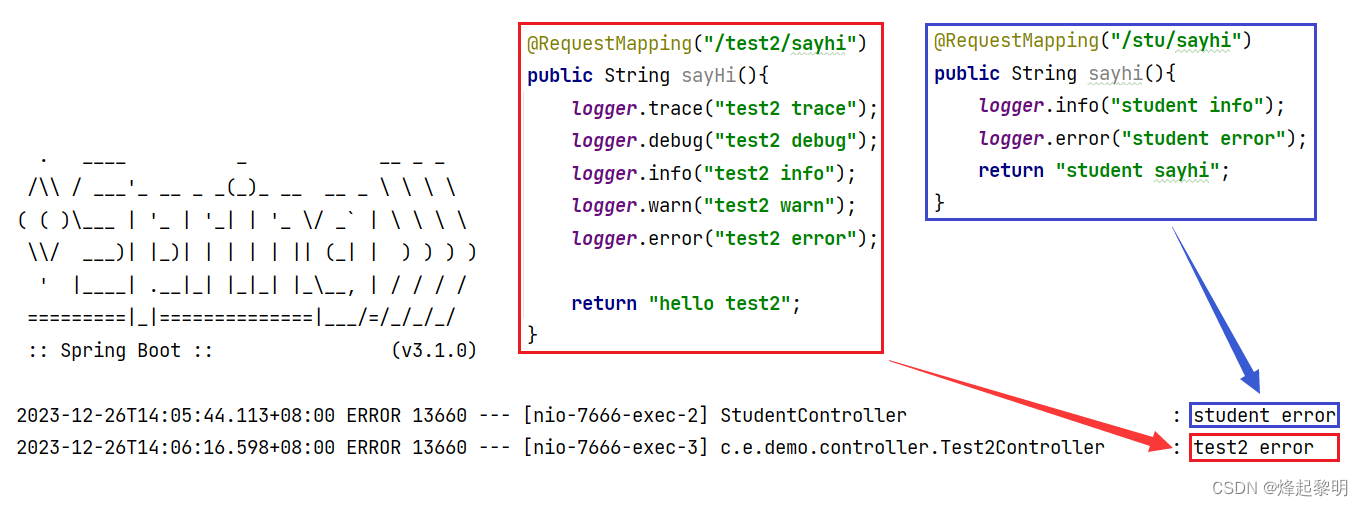
- 我们还可以做进一步更加严格的设置,只打印我们当前项目中
controller层中的所触发的日志信息
# 日志级别设置
logging:level:root: errorcom:example:demo:controller: trace
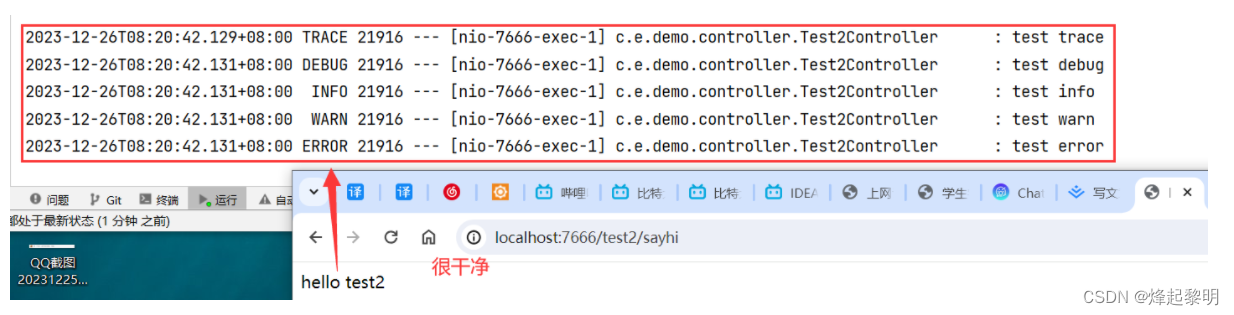
先把项目重启一下我们可以看到,任何多余的日志都没有看到,就等待我们去访问

接着去访问一下就可以看到打印出来了相关的日志信息,而且很干净,并没有任何杂志
💬 所以在学习了日志级别后我们就可以清除掉配置⽂件中的原先⽇志设置,从而随心地去控制日志的打印内容
六、日志持久化【将日志保存下来】
以上的⽇志都是直接输出在控制台上的,然⽽在⽣产环境上咱们需要将⽇志保存下来,以便出现问题之后追溯问题,把⽇志保存下来的过程就叫做【持久化】
想要将⽇志进⾏持久化,只需要在配置⽂件中 指定⽇志的存储⽬录 或者是 指定⽇志保存⽂件名 之后,Spring Boot 就会将控制台的⽇志写到相应的⽬录或⽂件下了
6.1 设置日志的保存路径
- 首先我们来看看如何设置日志的保存路径,这里在对于路径的设置要注意以下两点:
- 尽量不要将保存的路径写在系统盘
- 路径中不要出现中文和空格
- 比方说我现在将日志文件的输出路径放到了D盘下的
home文件夹下
# 日志保存路径
logging:file:path: D:\\home
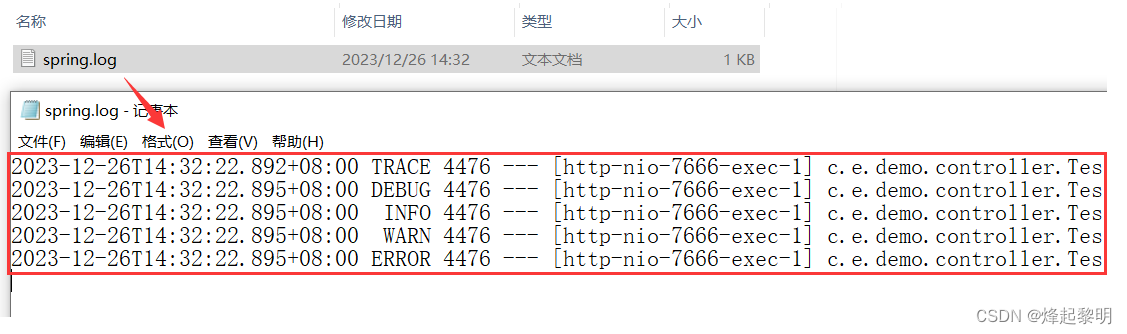
- 然后我们将项目重启并访问相关路由就可以看到,名为
spring.log的文件就出现了,点进去一看确实出现了我们上面在控制台中所出现的日志信息
我们来看看几位同学的问题(・∀・(・∀・(・∀・*)
💬 那有同学就说,那在项目重启之后会不会丢失呢?
- 答案是:不会的。日志文件一旦产生,那么日志文件及其内容就会永久得保存,不会出现文件或内容的丢失,无论任何操作都会保持以上的特性
💬 那在重启项目后再去运行,存储的日志会不会将之前的日志覆盖掉呢?
- 答案是:不会的。对于日志的记录是一个
append追加的过程,而不会产生一个覆盖的现象
我们可以将项目重启后再来访问一下看看,便可以观察到上一次的日志信息确实还存留,并且追加上了这一次的日志信息📰

💬 如果一直像上面那样追加,如果文件变得越来越大怎么办呢?
- 这个不需要担心,有最大文件大小限制,如果超过了的话就会重新去创建一个,可以看 Spring的官方文档

6.2 配置⽇志⽂件的⽂件名
那么除了可以设置日志的保存路径外呢,我们还可以去配置⽇志⽂件的⽂件名,可以不用系统默认的,自己也可以起名哦~
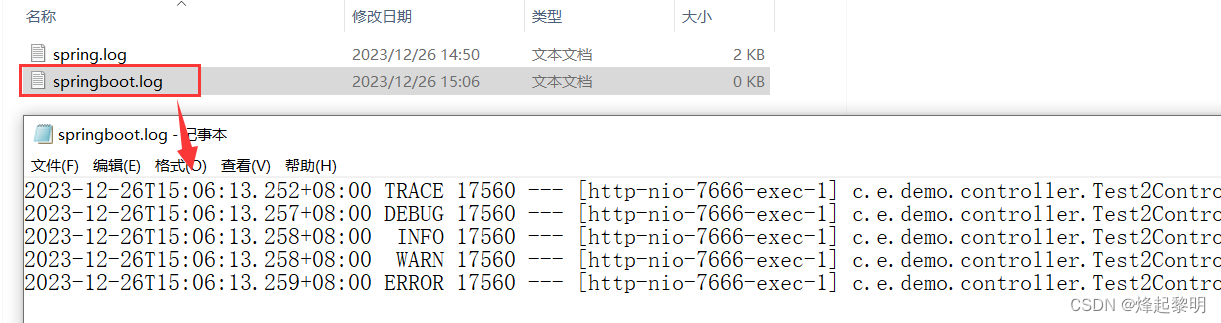
- 比方说我在这里将名字取为
springboot.log,不过要记得取名字的同时也要带上路径哦,否则就就无法输出到指定的路径了,就会直接保存在当前项目中
# 日志保存名称
logging:file:name: D:\\home\\springboot.log
来运行一下看看,确实可以看到出现了一个名为springboot.log的文件
💬 那这个时候又有同学问了:什么东西都存在文件里,万一系统被入侵了文件不是很容易丢失吗?
- 这个问题问得很好👍 在公司中做大项目的时候,我们并不是所有的日志信息都放在文件中,对于有些文件我们则是选择存放在【数据库】 中
对于生产级别日志分类 —— 根据业务场景来定
- 程序运行日志(存放在文件中)
- 属于边缘性的东西,简单看一下
- 业务日志(存放到数据库中)
- 记录系统关键操作的关键人,以及其修改前后的操作
📚 【综合练习】:将 controller 包下 error 级别以上的⽇志保存到 log_all.log 下,将 service 下warn 级别以上的⽇志保存到 log_all.log 下
七、更简单的⽇志输出 — lombok
每次都使⽤ LoggerFactory.getLogger(xxx.class) 很繁琐,且每个类都添加⼀遍,也很麻烦,这⾥讲⼀种更好⽤的⽇志输出⽅式,使⽤ lombok 来更简单的输出。
7.1 添加 lombok 依赖
- 首先我们要在IDEA中去安装一个插件,叫做
EditStarters
- 接下去就要在
pom.xml依赖文件中通过这个插件去生成相关的lombok依赖
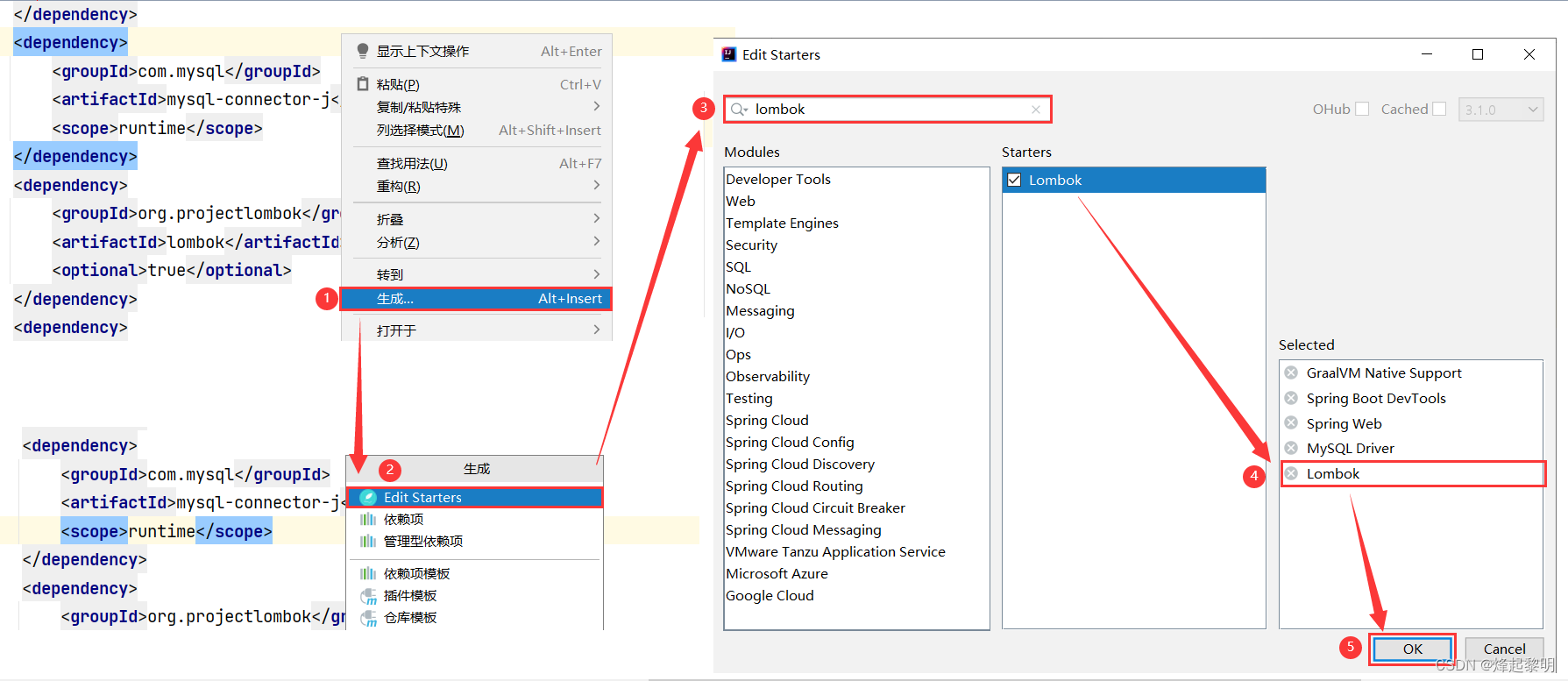
然后在文件中就会多出来以下依赖了
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
7.2 使用 @slf4j 输出日志
- 有了依赖的支持,接下去我们就可以通过
@slf4j这个注解去代替前面繁琐的日志对象创建过程了,这个注解会给当前的类提供一个log对象,使用这个对象就可以去调用对应日志级别了
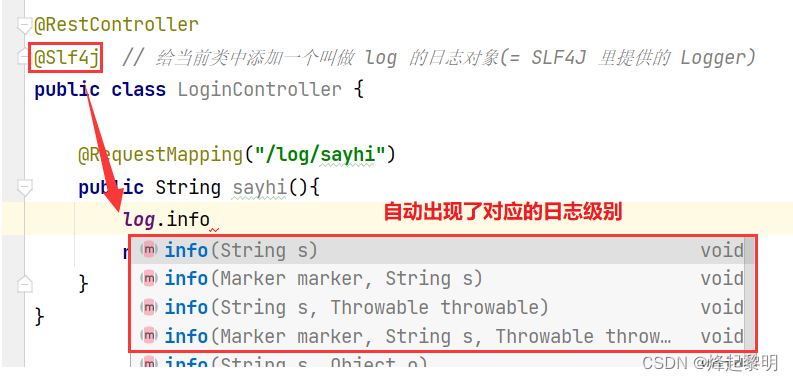
@RequestMapping("/log/sayhi")
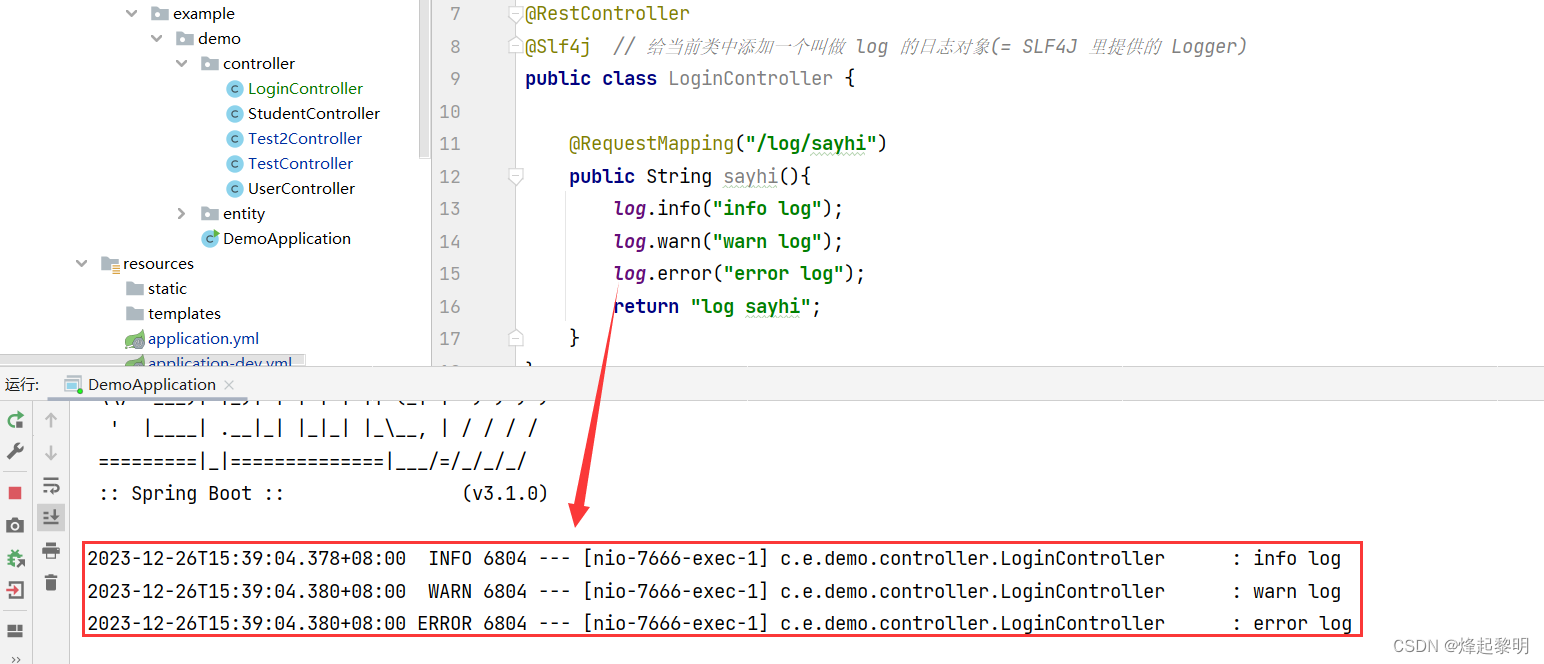
public String sayhi(){log.info("info log");log.warn("warn log");log.error("error log");return "log sayhi";
}
然后我们来运行一下试试,便可以观察到与前面获取到的日志信息是一样的~
7.3 lombok 原理解释
但是光这样子是不够的,我们要做到的是 知其然,知其所以然。对于
lombok来说,它呢是编译期间的一个框架
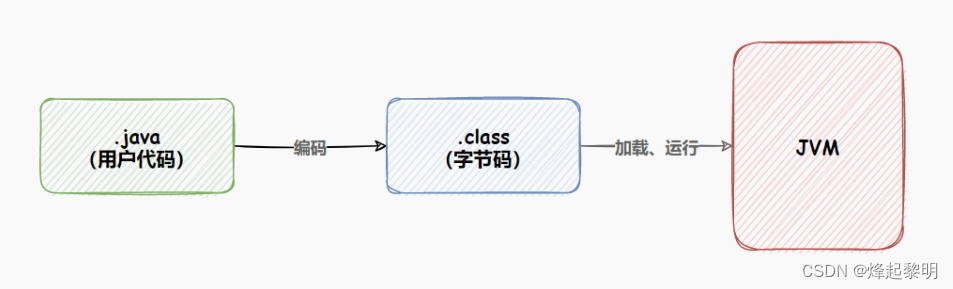
- 通过我们之前的学习可以知道,对于一个普通的Java程序来说,当用户写好代码之后进行编译,然后生成一个
.class为后缀的字节码文件,将其放到JVM虚拟机上去运行就可以让程序跑起来了
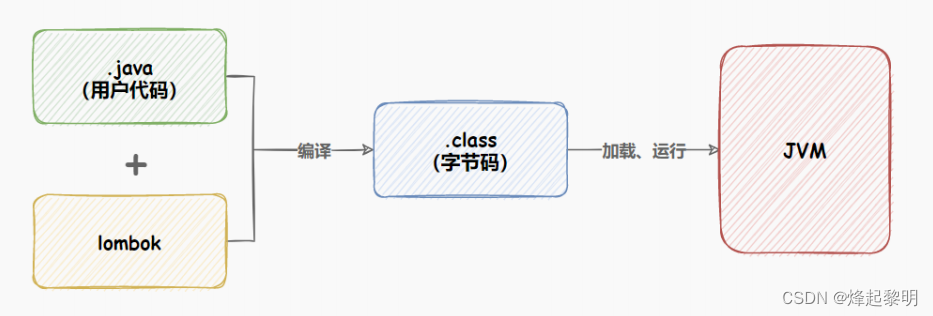
- 但是对于
lombok框架支持后,它就会与普通的java程序一同进行编译,然后生成.class为后缀的字节码文件
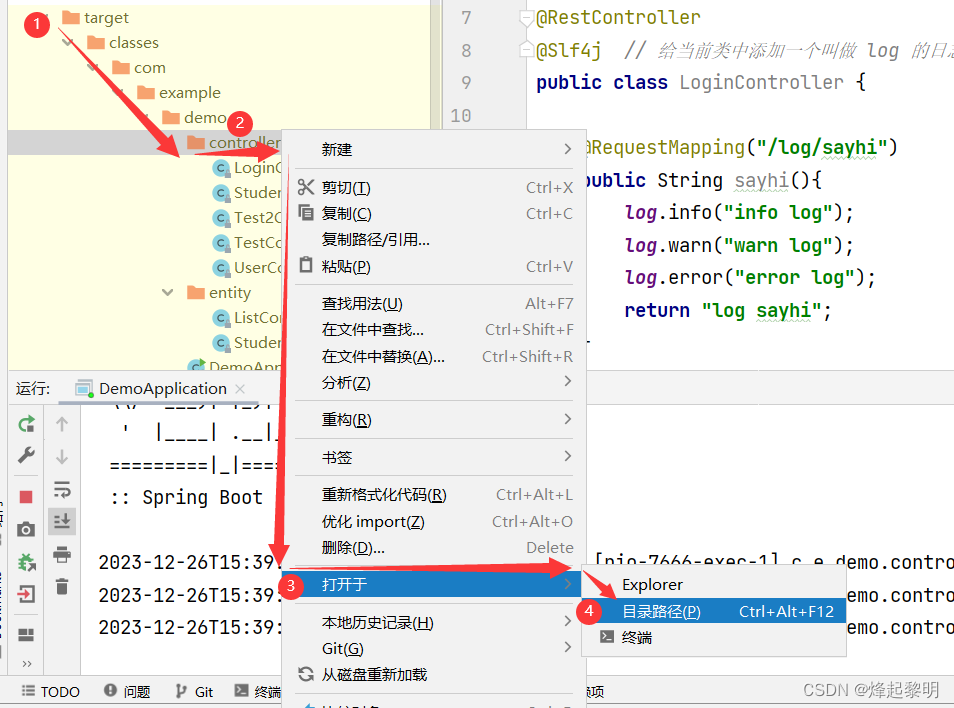
那怎么去证实呢?我们一起来看看
- 首先我们在启动项目后到
target文件中去进行查看,然后打开内部的controller文件
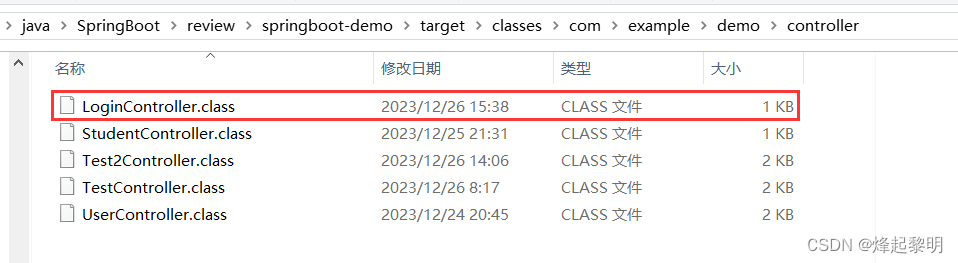
- 在其内部我们看到了编译好的
.class为后缀的字节码文件,将其拖入到IDEA中观察一下🔍
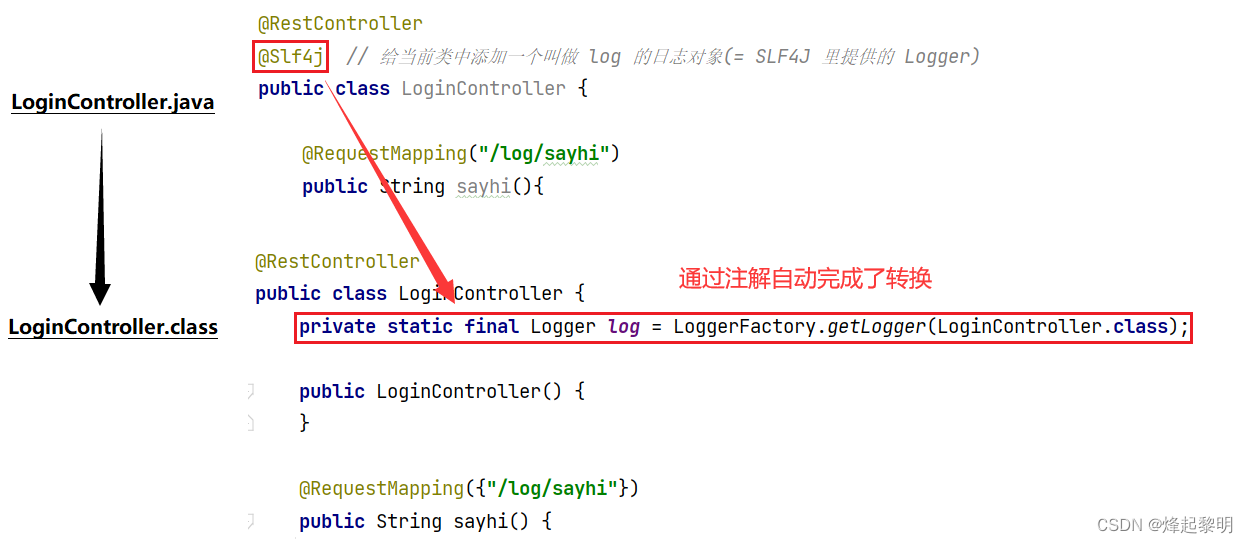
- 将编译前后的文件进行对比我们可以发现,因为
@Slf4j注解的缘故,出现了我们在前面所学习的Logger接口所新建出来的对象,不过这里叫做log - 那其实我们就看得很明确了,其实 lombok 的这个注解所做的工作其实就是在做生成日志对象的转换工作,这就是为何说 Spring面向注解开发 的原因了
7.4 lombok 更多注解说明
当然,lombok 这个框架可不知那么一个注解,它的功能还是很强大的,其中的很多注解都可以帮助我们快速地去进行开发
- 基本注解:
| 注解 | 作用 |
|---|---|
| @Getter | ⾃动添加 getter ⽅法 |
| @Setter | ⾃动添加 setter ⽅法 |
| @ToString | ⾃动添加 toString⽅法 |
| @EqualsAndHashCode | ⾃动添加 equals 和 hashCode ⽅法 |
| @NoArgsConstructor | ⾃动添加⽆参构造⽅法 |
| @AllArgsConstructor | ⾃动添加全属性构造⽅法,顺序按照属性的定义顺序 |
| @NonNull | 属性不能为 null |
| @RequiredArgsConstructor | ⾃动添加必需属性的构造⽅法,final + @NonNull 的属性为必需 |
- 组合注解:
| 注解 | 作用 |
|---|---|
| @Data | @Getter + @Setter + @ToString +@EqualsAndHashCode +@RequiredArgsConstructor +@NoArgsConstructor |
- ⽇志注解
| 注解 | 作用 |
|---|---|
| @Slf4j | 添加⼀个名为 log 的⽇志,使⽤ slf4j |
八、总结与提炼
接下去来总结一下本文所学习的内容📖
- 首先我们简单地来聊了聊日志是什么:⽇志是程序中的重要组成部分,使⽤⽇志可以快速的发现和定位问题,SpringBoot 内容了⽇志框架:SLF4J 与 logback 是我们最常用的两个,其二者通过 SLF4J 这个日志门面可以实现很好的解耦,方便后期的替换维护,与我们之前所讲的
JDBC有着异曲同工之妙 - 然后我们又讲到了如何去获取日志对象:在这一块首先我们讲到了使用一个 工厂类LoggerFactory 去实现
Logger接口,然后通过调用其中的方法并传入对应的参数来获取到对应的日志对象,接着再通过这个对象去调用【日志级别】来进行输出 - 然后我们便详细地说到了【日志级别】:其包含 6 个级别:
trace:微量,少许的意思,级别最低;debug:需要调试时候的关键信息打印;info:普通的打印信息(⭐默认⽇志级别⭐);warn:警告,不影响使⽤,但需要注意的问题;error:错误信息,级别较⾼的错误⽇志信息;fatal:致命的,因为代码异常导致程序退出执⾏的事件。
- 然后呢我们又学了什么是日志持久化: 通过去设置 日志的保存路径 以及 ⽇志⽂件的⽂件名 便可以控制我们所观察到的日志信息
- 最后呢我们又学了一个很棒的框架: 它叫做 lombok,通过 lombok 提供的
@Slf4j注解和log对象我们可以实现快速的打印⾃定义⽇志,当然我们还去好好地探究了一番这个注解究竟怎么一回事,做到了 “知其然,知其所以然”
以上就是本文要介绍的所有内容,诚挚感谢您对本文的观看🌹🌹🌹

相关文章:
Spring Boot日志:从Logger到@Slf4j的探秘
写在前面 Hello大家好,今日是2024年的第一天,祝大家元旦快乐🎉 2024第一篇文章从SpringBoot日志开始 文章目录 一、前言二、日志有什么用?三、日志怎么用?四、自定义日志打印💬 常见日志框架说明4.1 在程序…...
如何实现GTM与VADC关联的配置)
英飞凌TC3xx之一起认识GTM系列(六)如何实现GTM与VADC关联的配置
英飞凌TC3xx之一起认识GTM系列(六)如何实现GTM与VADC关联的配置 1 GTM与ADC的接口2 GTM与VADC的连接2.1 VADC 到 GTM 的连接2.1.1 简要介绍2.1.2 应用举例2.2 EVADC到 GTM的连接2.2.1 应用举例3 总结本文介绍实现GTM与VADC的连接性的相关寄存器配置。 1 GTM与ADC的接口 由英…...
(建议收藏))
【基础】【Python网络爬虫】【6.数据持久化】Excel、Json、Csv 数据保存(附大量案例代码)(建议收藏)
Python网络爬虫基础 数据持久化(数据保存)1. Excel创建数据表批量数据写入读取表格数据案例 - 豆瓣保存 Excel案例 - 网易新闻Excel保存 2. Json数据序列化和反序列化中文指定案例 - 豆瓣保存Json案例 - Json保存 3. Csv写入csv列表数据案例 - 豆瓣列表保…...

王道考研计算机网络——应用层
如何为用户提供服务? CS/P2P 提高域名解析的速度:local name server高速缓存:直接地址映射/低级的域名服务器的地址 本机也有告诉缓存:本机开机的时候从本地域名服务器当中下载域名和地址的对应数据库,放到本地的高…...
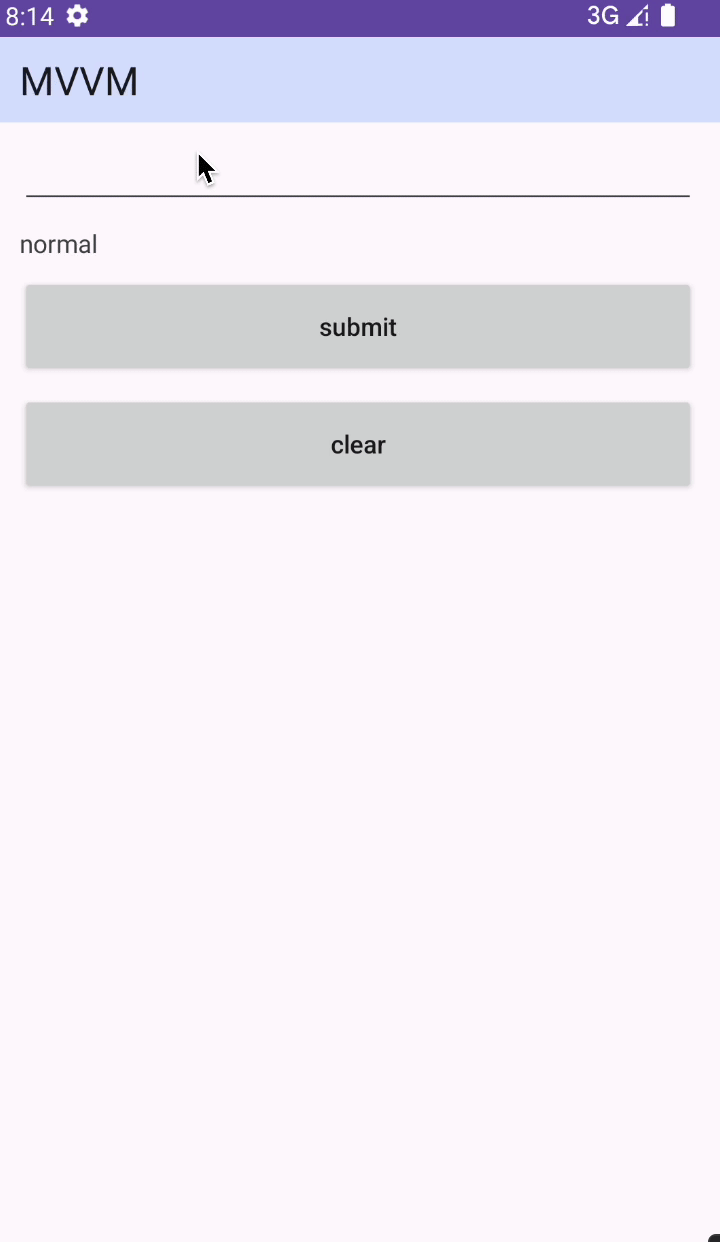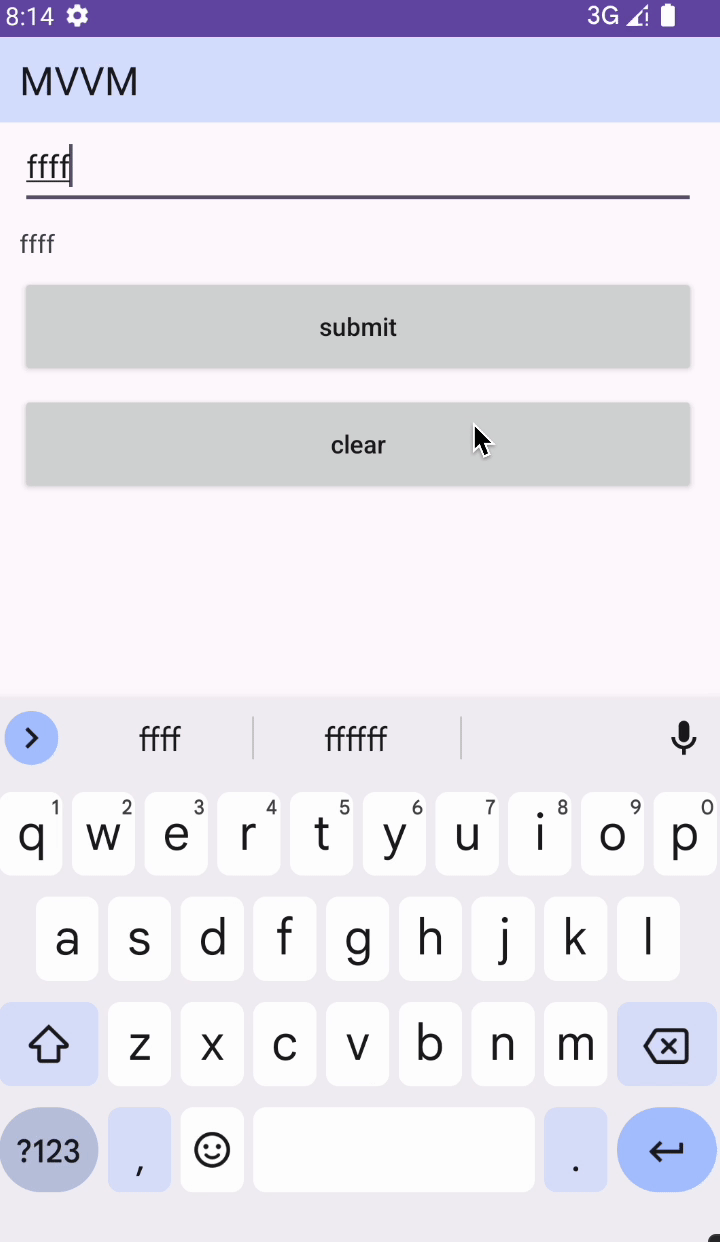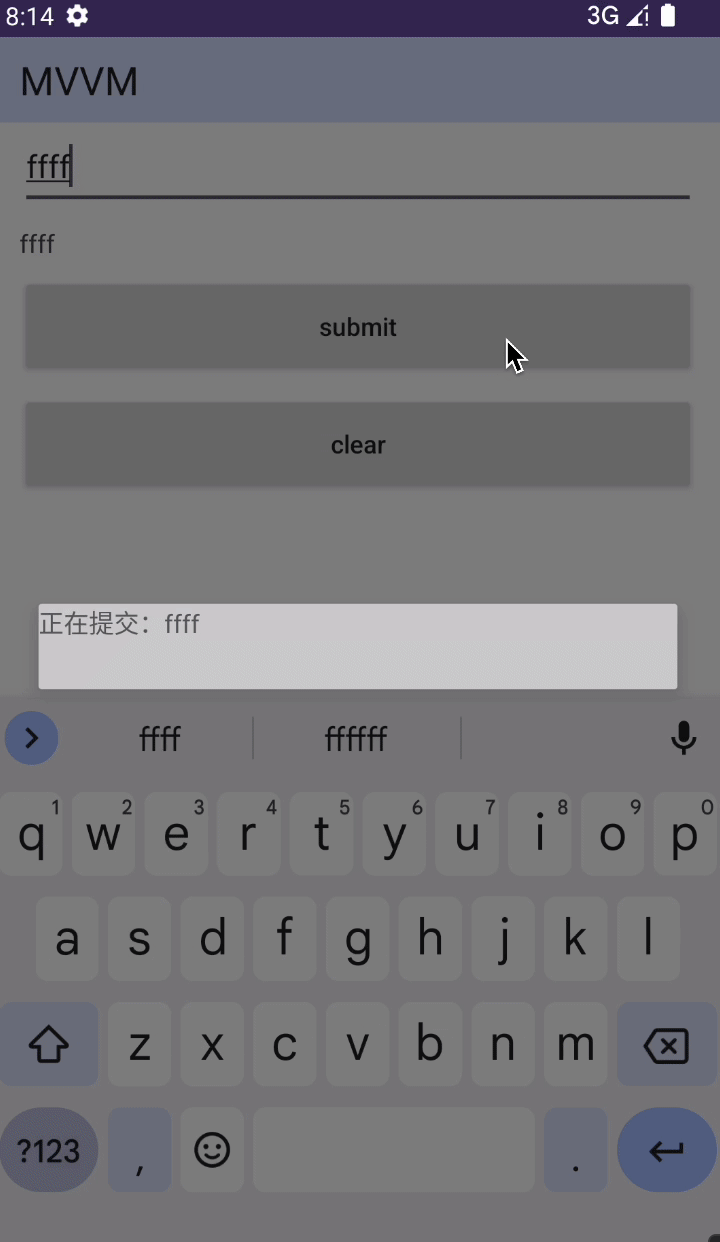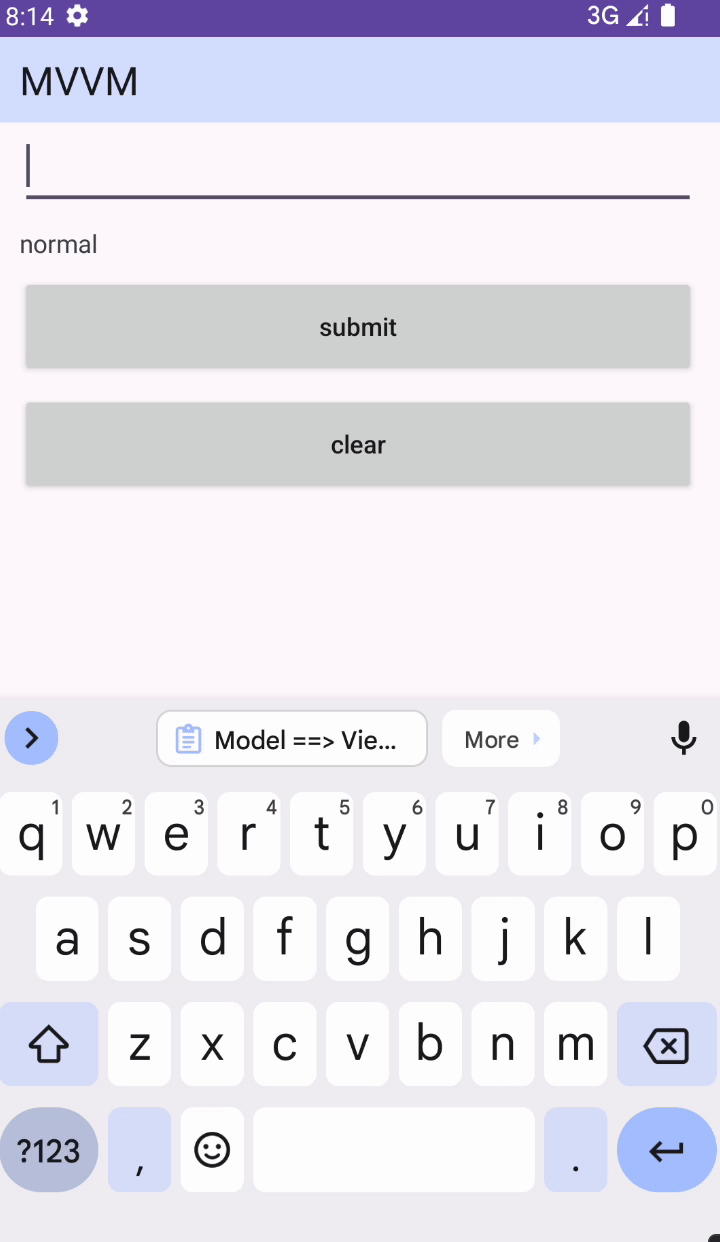
Android MVVM 写法
前言 Model:负责数据逻辑 View:负责视图逻辑 ViewModel:负责业务逻辑 持有关系: 1、ViewModel 持有 View 2、ViewModel 持有 Model 3、Model 持有 ViewModel 辅助工具:DataBinding 执行流程:View &g…...

LeetCode 热题 100——283. 移动零
283. 移动零 提示 简单 2.3K 相关企业 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12] 输出: [1,…...

neovim调试xv6-riscv过程中索引不到对应头文件问题
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com,github地址为https://github.com/jintongxu。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 和这篇文章neovim调试linux内核过程中索…...

轻量应用服务器与云服务器CVM对比——腾讯云
腾讯云轻量服务器和云服务器CVM该怎么选?不差钱选云服务器CVM,追求性价比选择轻量应用服务器,轻量真优惠呀,活动 https://curl.qcloud.com/oRMoSucP 轻量应用服务器2核2G3M价格62元一年、2核2G4M价格118元一年,540元三…...
-游戏AI控制)
骑砍战团MOD开发(31)-游戏AI控制
一.骑砍单机模式下AI控制 骑砍战团中野外战斗,训练场中小兵和地方小兵的行为统称为场景AI. 骑砍大地图中敌军追踪和遭遇追击统称为大地图AI. 二.骑砍场景AI 骑砍引擎通过header_mission_templates,py定制AI常量控制小兵位置,动作和朝向.可实现自定义阵型和攻击动作。 # Agen…...

flutter学习-day21-使用permission_handler进行系统权限的申请和操作
文章目录 1. 介绍2. 环境准备2-1. Android2-2. iOS 3. 使用 1. 介绍 在大多数操作系统上,权限不是在安装时才授予应用程序的。相反,开发人员必须在应用程序运行时请求用户的许可。在 flutter 开发中,则需要一个跨平台(iOS, Android)的 API 来…...

虹科方案丨L2进阶L3,数据采集如何助力自动驾驶
来源:康谋自动驾驶 虹科方案丨L2进阶L3,数据采集如何助力自动驾驶 原文链接:https://mp.weixin.qq.com/s/qhWy11x_-b5VmBt86r4OdQ 欢迎关注虹科,为您提供最新资讯! 12月14日,宝马集团宣布,搭载…...

Kubernetes 学习总结(42)—— Kubernetes 之 pod 健康检查详解
Kubernetes 入门 回想 2017 年刚开始接触 Kubernetes 时,碰到 Pod一直起不来的情况,就开始抓瞎。后来渐渐地掌握了一些排查方法之后,这种情况才得以缓解。随着时间推移,又碰到了问题。有一天在部署某个 springboot 微服务时&…...
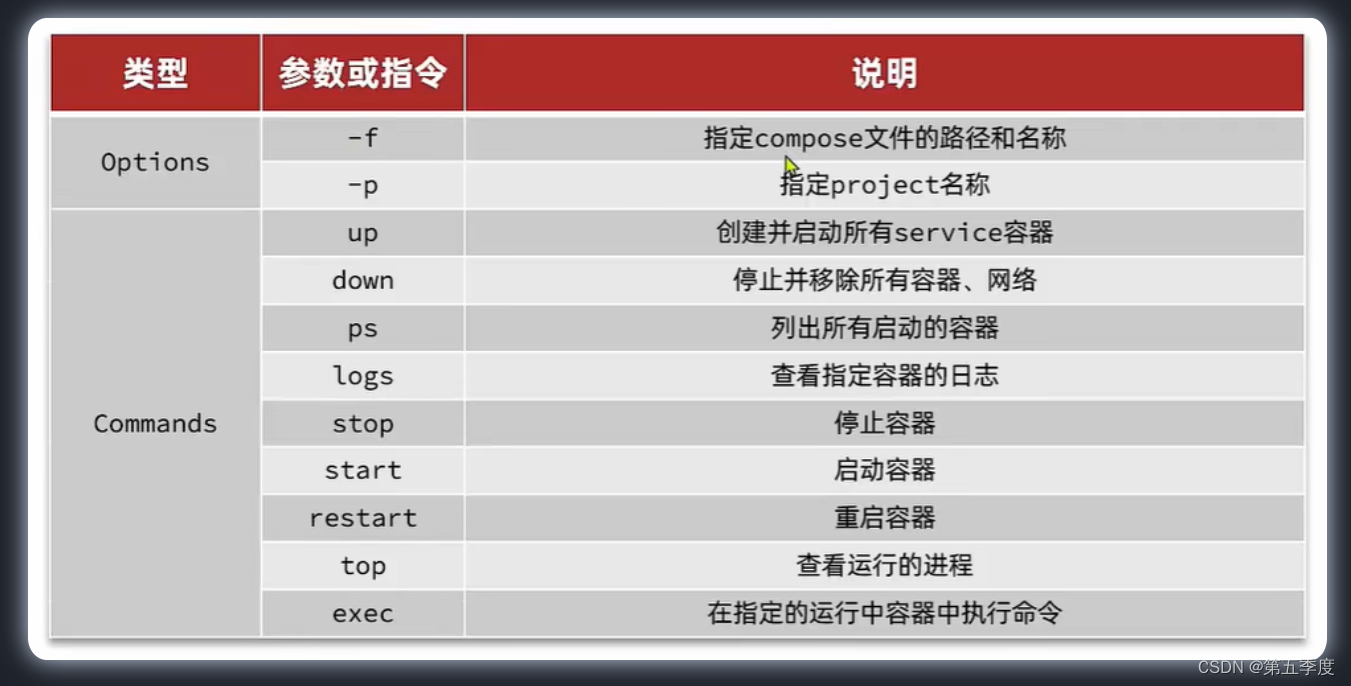
【后端】Docker学习笔记
文章目录 Docker一、Docker安装(Linux)二、Docker概念三、Docker常用命令四、数据卷五、自定义镜像六、网络七、DockerCompose Docker Docker是一个开源平台,主要基于Go语言构建,它使开发者能够将应用程序及其依赖项打包到一个轻…...
UE5.1_Gameplay Debugger启用
UE5.1_Gameplay Debugger启用 重点问题: Gamplay Debugger启用不知道? Apostrophe、Tilde键不知道是哪个? Gameplay调试程序 | 虚幻引擎文档 (unrealengine.com) Gameplay Debugger...

【论文阅读+复现】SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
SparseCtrl:在文本到视频扩散模型中添加稀疏控制。 (AnimateDiff V3,官方版AnimateDiffControlNet,效果很丝滑) code:GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff. paper:htt…...

速盾cdn:ddos防护手段
速盾CDN采用多种手段来进行DDoS防护,以确保网络和网站的正常运行。以下是速盾CDN可能采用的一些主要DDoS防护手段: 实时监测和分析: 速盾CDN实时监测网络流量,通过分析流量模式来检测异常行为,以迅速发现潜在的DDoS攻击…...
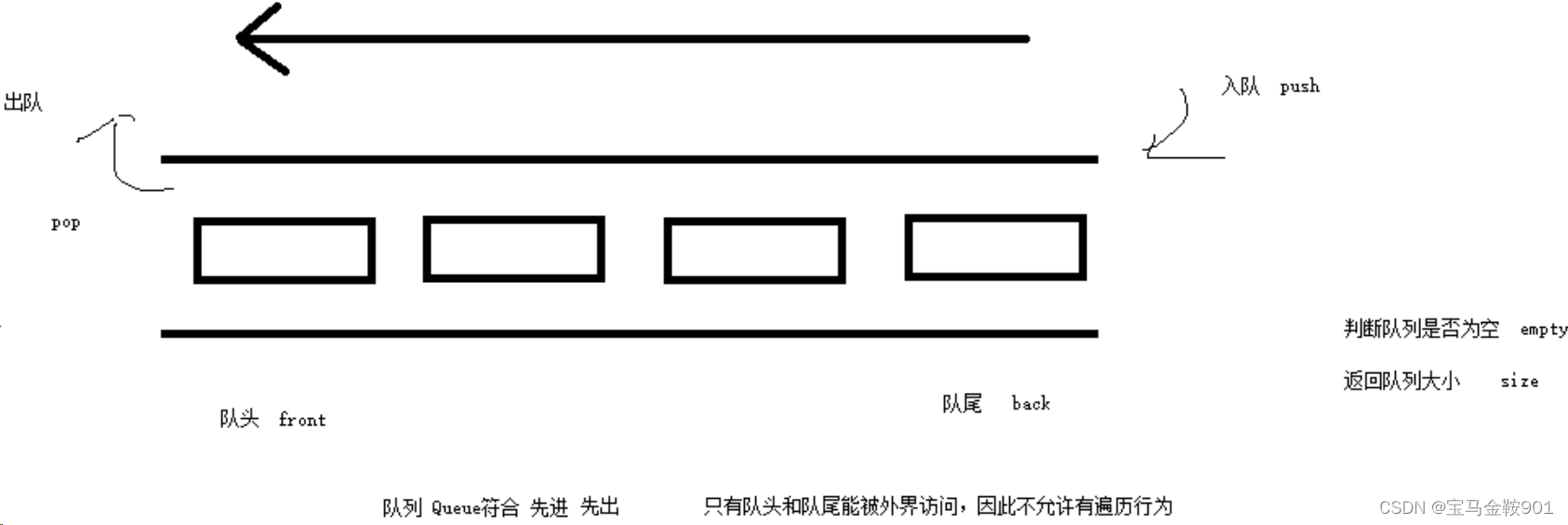
STL——queue容器
1.queue基本概念 概念:queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口。 队列容器允许从一端新增元素,从另一端移除元素。 队列中只有队头和队尾才可以被外界使用,因此队列不允许…...

gitLab页面打tag操作步骤
作者:moical 链接:gitLab页面打tag简单使用 - 掘金 (juejin.cn) 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 ---------------------------------------------------------------------…...
神秘的Cookie和Session
Cookie 1.Cookie是什么? Cookie是浏览器提供的持久化储存数据的方式。 2.从哪里来? Cookie从服务器中来,存储到客户端中。一个客户端就对应着一个浏览器。 服务器代码中决定了什么样的数据会储存到客户端中,通过HTTP相应的Se…...

springboot接口文档
Swagger 在Spring Boot中生成和维护接口文档的一个常用方法是使用Swagger。Swagger是一个开源软件框架,它帮助开发者设计、构建、记录和使用RESTful Web服务。下面是在Spring Boot项目中使用Swagger来创建接口文档的详细步骤:1. 添加Swagger依赖 在你的Spring Boot项目的pom…...

第07章 FastMCP 把检索封装成 Agent 工具
第07章 FastMCP 把检索封装成 Agent 工具 工单知识库已经能在 Python 进程内被普通函数调用,但要让外部 Agent、Web 后端或其他语言的客户端使用这份能力,函数级别的接口不够:缺少协议、缺少描述、缺少跨进程通讯。MCP(Model Cont…...

Zotero插件市场:三步快速上手的插件管理神器
Zotero插件市场:三步快速上手的插件管理神器 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 想象一下&a…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

通用框架操作系统:统一异构应用框架的运行时与治理平台
1. 项目概述:一个面向未来的通用框架操作系统最近在开源社区里,一个名为TELLEBO/universal-framework-os的项目引起了我的注意。乍一看这个标题,可能会觉得有点“大词”堆砌的感觉——“通用”、“框架”、“操作系统”,每一个词单…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

AI驱动工作流自动化:从原理到实践,构建智能效率引擎
1. 项目概述:当AI遇上工作流,一场效率革命正在发生最近在GitHub上看到一个名为“WorkflowAI/WorkflowAI”的项目,这个名字本身就充满了想象空间。作为一个长期与各种自动化工具和效率方法论打交道的人,我立刻意识到,这…...

基于Helm Chart的JupyterHub生产级部署与运维实战指南
1. 项目概述:为什么我们需要一个可扩展的JupyterHub部署方案?如果你在团队里负责过数据科学或机器学习平台的搭建,大概率会为Jupyter Notebook的部署和管理头疼过。单个Jupyter Notebook服务给一两个人用还行,一旦团队规模扩大到十…...