NMT - 构建双语概率词典(Probabilistic dictionaries)
文章目录
- 一、安装依赖包
- mosesdecoder
- 安装 mgiza++
- 二、数据预处理
- 三、训练
本文参考:How to train your Bicleaner
https://github.com/bitextor/bicleaner/wiki/How-to-train-your-Bicleaner
一、安装依赖包
这个过程主要依赖于
- mosesdecoder
- mgiza++
mosesdecoder
- github : https://github.com/moses-smt/mosesdecoder
- 官方说明:http://www2.statmt.org/moses/?n=Development.GetStarted
官方介绍了 windows, macOS 和各版本 ubuntu 的安装细节,这里以 ubuntu 为例
1、安装依赖
sudo apt-get install [package name]
Packages:
g++ git subversionautomakelibtoolzlib1g-devlibicu-devlibboost-all-devlibbz2-devliblzma-devpython-devgraphvizimagemagickmakecmakelibgoogle-perftools-dev (for tcmalloc)autoconfdoxygen
2、安装
./bjam -j4
如果手动安装了 boost,也可以指定 boost 位置
boost 安装教程:https://blog.csdn.net/lovechris00/article/details/125423796
./bjam --with-boost=~/workspace/temp/boost_1_64_0 -j8
3、安装成功测试
cd ~/mosesdecoder
wget http://www.statmt.org/moses/download/sample-models.tgz
tar xzf sample-models.tgz
cd sample-models# 运行
~/mosesdecoder/bin/moses -f phrase-model/moses.ini < phrase-model/in > out
得到如下结果,代表安装成功
翻译结果:Translating: das ist ein kleines haus
Defined parameters (per moses.ini or switch):config: phrase-model/moses.ini
...
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
**The ARPA file is missing <unk>. Substituting log10 probability -100.000.
**************************************************************************************************
FeatureFunction: LM start: 0 end: 0
line=Distortion
...
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Created input-output object : [0.685] seconds
Translating: das ist ein kleines haus
...
Name:moses VmPeak:193088 kB VmRSS:11404 kB RSSMax:37844 kB user:0.684 sys:0.008 CPU:0.692 real:0.692
git clone https://github.com/moses-smt/mosesdecoder.git
安装 mgiza++
这里使用 linux 环境为例
# 安装 libboost (mgiza++ 的编译依赖于它)
sudo apt-get install -y cmake libboost-all-dev# 下载mgiza、安装
git clone https://github.com/moses-smt/mgiza.gitcd mgiza/mgizappcmake . && make && make installcp scripts/merge_alignment.py bin/
二、数据预处理
上文给出的方式是使用 shell,主要实现对文本 tokenize 和 lower 的过程;
这里我使用 python 实现;
假设你有两个文件:raw.zh, raw.en
处理中文
这里使用 jieba 分词
import os ,sys
import jieba def process(file_path): save_path = file_path + '_low.txt' print('\n-- start : ',file_path) for line in open(file_path):zh_toks = jieba.cut(line.strip())zh_text = ' '.join(zh_toks).lower() with open(save_path, 'a') as fa:fa.write(zh_text + '\n' )print('-- end : ', file_path, save_path) if __name__ == '__main__':file_path = sys.argv[1]print('-- ', file_path)process(file_path)
处理英文
import os ,sys
import nltk def process(file_path): save_path = file_path + '_low.txt' print('\n-- start : ',file_path) for line in open(file_path):en_toks = nltk.word_tokenize(line.strip())en_text = ' '.join(en_toks).lower() with open(save_path, 'a') as fa:fa.write(en_text + '\n' )print('-- end : ', file_path, save_path) if __name__ == '__main__':file_path = sys.argv[1]print('-- ', file_path)process(file_path)
处理后修改两个文件,以语种作为后缀;假设处理后的文件名为 clean.zh, clean.en;
除了语种后缀外,前面必须一致,方便后续处理;
三、训练
- 使用 mosesdecoder 的
train-model.perl文件来训练; - 需要添加 mgiza 的bin目录
--root-dir: 数据文件所在的根目录-corpus设置文件名前缀;这里为 clean-e,-f设置语种
/home/xx/mosesdecoder/scripts/training/train-model.perl \
--alignment grow-diag-final-and \
--root-dir /home/xx/data/230303 -\
-corpus clean -e en -f zh \
--mgiza -mgiza-cpus=16 --parallel --first-step 1 --last-step 4 \
--external-bin-dir /home/xx/scode/mgiza/mgizapp/bin
- 40万条数据可能要训练2小时以上;为了测试,可以尝试训练 1w到5w条数据即可。
- 如果报找不到 symal 之类,可能是 mosesdecoder 编译不成功导致
生成成功后,我们可以在 root-dir 下得到 model 文件夹,包含以下三个文件
- aligned.grow-diag-final-and
- lex.e2f
- lex.f2e
伊织 2023-03-03
相关文章:
)
NMT - 构建双语概率词典(Probabilistic dictionaries)
文章目录一、安装依赖包mosesdecoder安装 mgiza二、数据预处理三、训练本文参考:How to train your Bicleaner https://github.com/bitextor/bicleaner/wiki/How-to-train-your-Bicleaner 一、安装依赖包 这个过程主要依赖于 mosesdecodermgiza mosesdecoder git…...
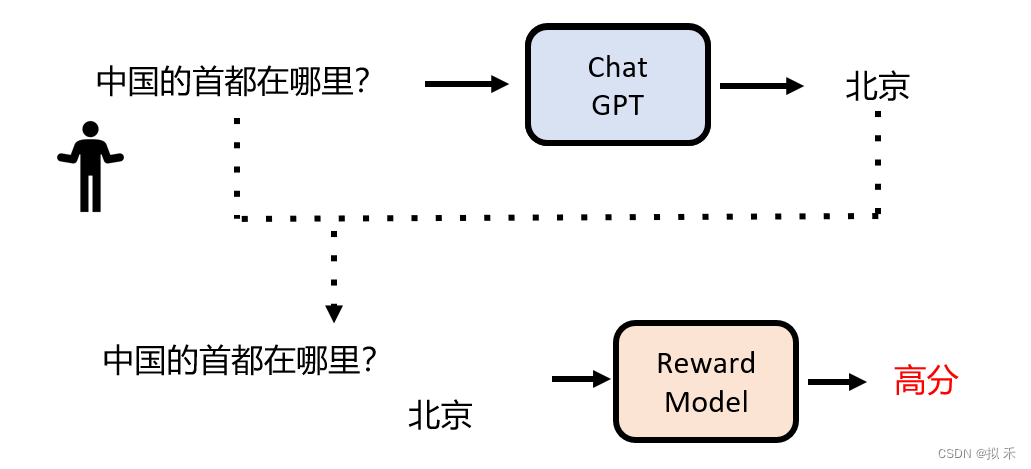
《ChatGPT是怎样炼成的》
ChatGPT 在全世界范围内风靡一时,我现在每天都会使用 ChatGPT 帮我回答几个问题,甚至有的时候在一天内我和它对话的时间比和正常人类对话还要多,因为它确实“法力无边,功能强大”。 ChatGPT 可以帮助我解读程序,做翻译…...
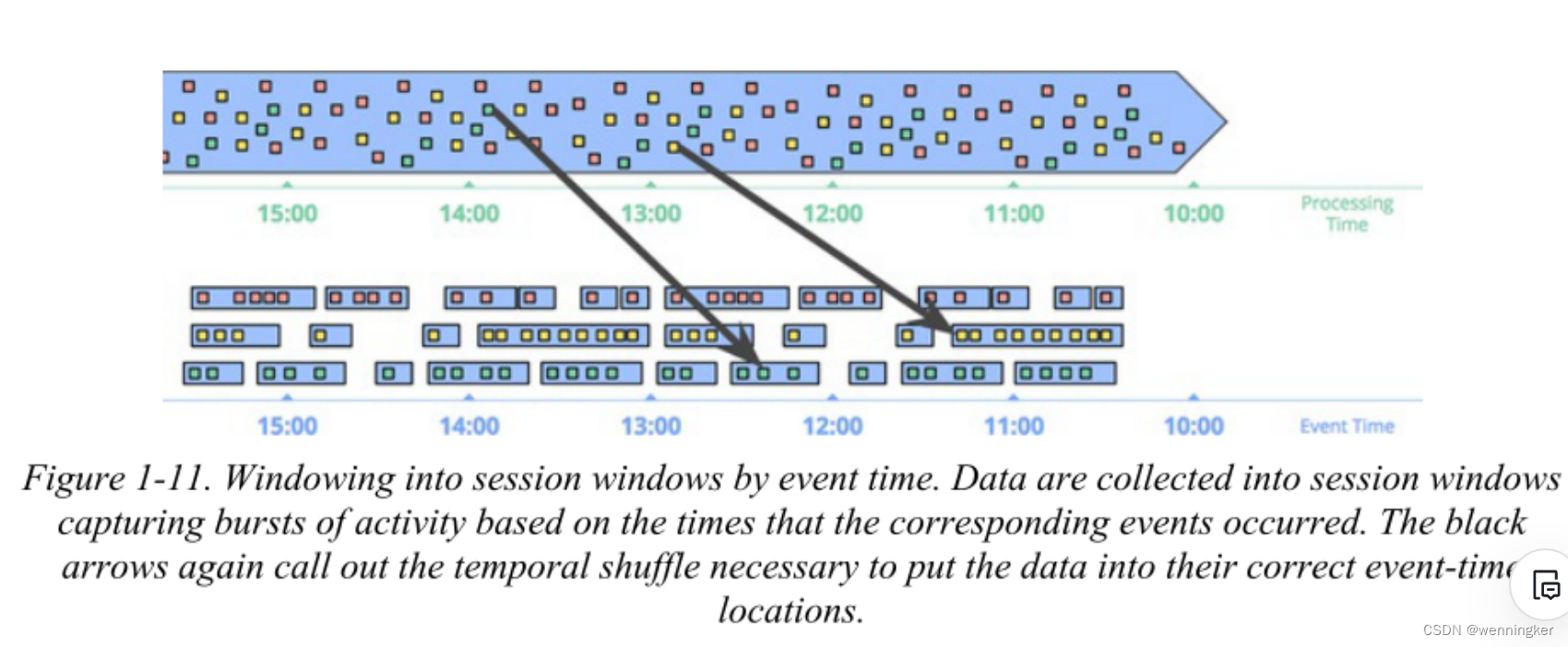
Streaming System是第一章翻译
GIthub链接,欢迎志同道合的小伙伴一起翻译 Chapter 1.Streaming101 如今,流数据处理在大数据中是非常重要的,其主要原因是: 企业渴望对他们的数据有更及时的了解,而转换到流处理是实现更低延迟的一个好方法…...
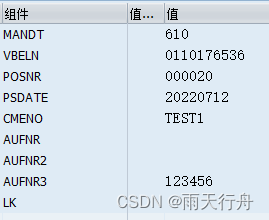
abap MODIFY常用语法解析
MODIFY 是既可以操作数据又可以操作内表的一个语法, 实现的逻辑都一样. 如果你内表或数据库中存在该行数据会对该行数据进行更新. 如果不存在,就会插入数据. , 1.如果it_tab是带有标题行的内表,是可以忽略FROM wa_tab工作区的 MODIFY it_tab .2.把工作区wa_tab中的数据更新…...

[媒体分流直播]媒体直播和传统直播的区别,以及媒体直播的特点
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 直播毋庸置疑已经融入到了我们生活的方方面面,小到才艺,游戏,大到政策的发布,许多企业和机构也越来越重视直播,那么一场活动怎…...
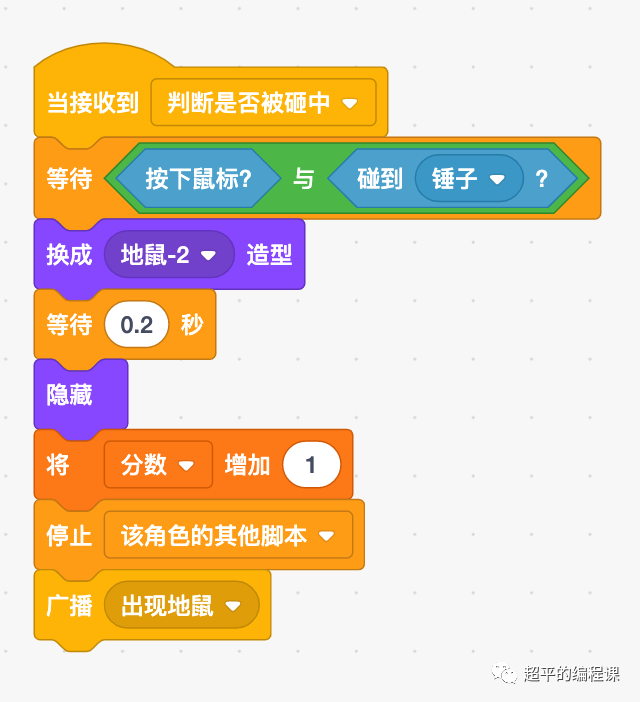
打地鼠游戏-第14届蓝桥杯STEMA测评Scratch真题精选
[导读]:超平老师的《Scratch蓝桥杯真题解析100讲》已经全部完成,后续会不定期解读蓝桥杯真题,这是Scratch蓝桥杯真题解析第102讲。 蓝桥杯选拔赛现已更名为STEMA,即STEM 能力测试,是蓝桥杯大赛组委会与美国普林斯顿多…...
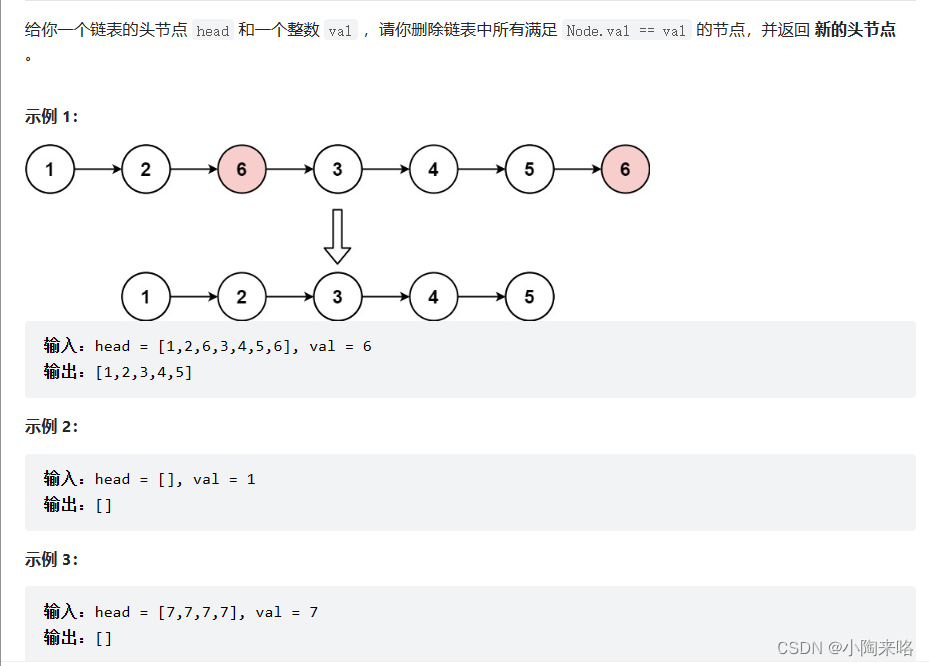
链表经典刷题--快慢指针与双指针
本篇总结链表解题思路----快慢指针,其实也就是双指针,这个快慢并不单纯指“快慢”,它更多的可以表示,速度快慢,距离长度,时间大小等等,用法很有趣也很独特,理解它的思想,…...

【Java集合框架】篇四:Set接口
1. Set及主要实现类特点 Set:无序、不可重复(去重)、存储value HashSet:底层使用HashMap,即使用 数组单项链表红黑树 结构进行存储。(jkd8中) LinkedHashSet:是HashSet的子类&…...

Python 数据库连接 + 创建库表+ 插入【内含代码实例】
人生苦短 我用python Python其他实用资料:点击此处跳转文末名片获取 数据库连接 连接数据库前,请先确认以下事项: 您已经创建了数据库 TESTDB.在TESTDB数据库中您已经创建了表 EMPLOYEEEMPLOYEE表字段为 FIRST_NAME, LAST_NAME, AGE, SEX 和 INCOME。连…...

DSS 部署环境需求清单
文章目录 DSS系统需求项目地址计算资源计算基准:计算引擎程序硬件需求表 :DSS计算及存储资源需求计算资源计算基准:计算程序硬件需求表:DSS系统需求 项目地址 https://github.com/WeBankFinTech/DataSphereStudio 计算资源计算基准: 1.日活用户10万。 2.单用户单日总…...

Python的面向对象,详细讲解Python之用处等基本常识
目录 Python 面向对象 面向对象技术简介 创建类 实例 实例 self代表类的实例,而非类 实例 创建实例对象 访问属性 实例 Python内置类属性 实例 python对象销毁(垃圾回收) 实例 实例 类的继承 实例 方法重写 实例 基础重载方法 运算符重载 实例…...
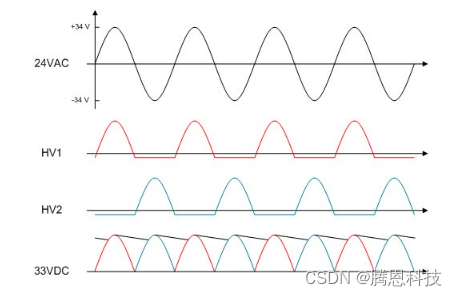
如何使用固态继电器为恒温器供电
恒温器有两种电源:电池和 24VAC。恒温器需要电池才能不间断地运行。电池消耗的能量尽可能低非常重要,但即使您最大限度地减少消耗,这仍然不是一个用户友好的选择,因为电池会不时需要更换。要降低更换频率,可以使用 24V…...
【LeetCode】剑指 Offer(14)
目录 题目:剑指 Offer 32 - I. 从上到下打印二叉树 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:剑指 Offer 32…...
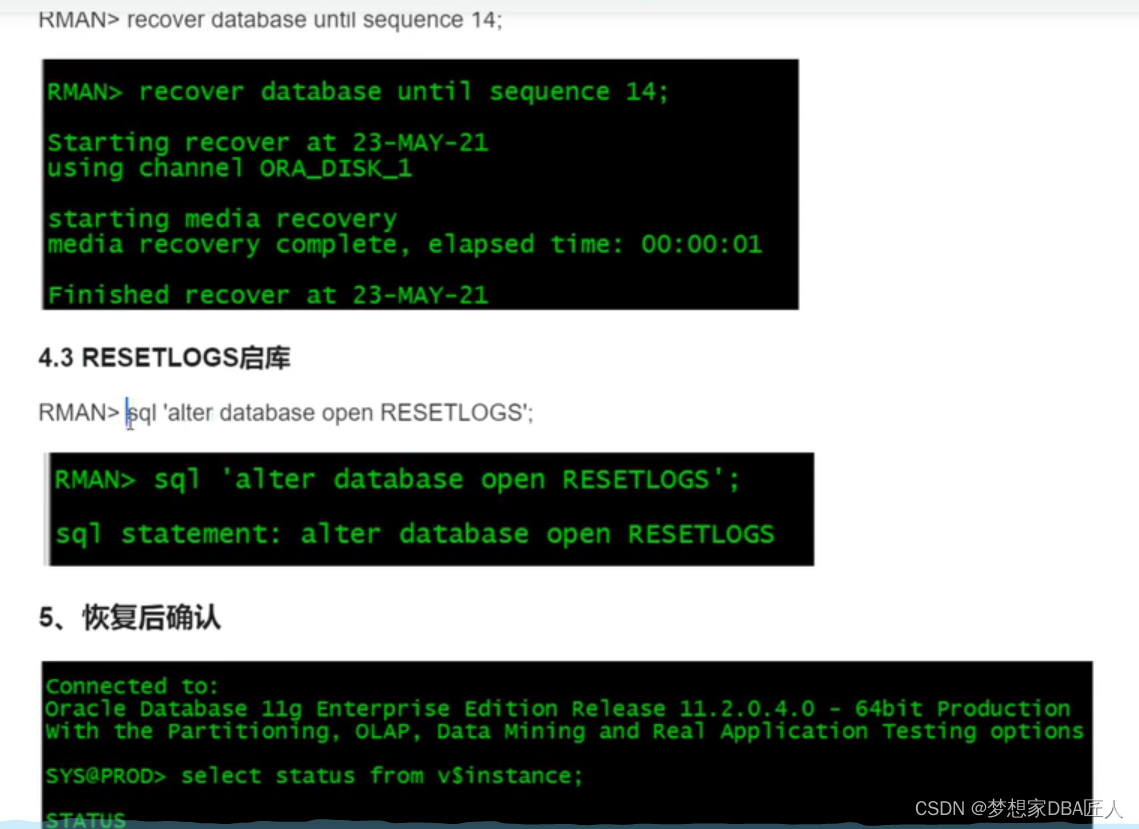
Rman单实例迁移到单实例
关于同平台同版本数据库之间的迁移操作的实验 ---Source DB[rootoracle-db-19cs ~]# cat /etc/redhat-release CentOS Stream release 8 [rootoracle-db-19cs ~]# --- Target DB[rootoracle-db-19ct ~]# cat /etc/redhat-release CentOS Stream release 8 [rootoracle-db-19ct…...

毕业设计 基于stm32舞台彩灯控制器设计app控制系统
基于stm32舞台彩灯控制器设计app控制1、项目简介1.1 系统构成1.2 系统功能2、部分电路设计2.1 STM32F103C8T6核心系统电路设计2.2 WS2812RGB彩灯电路设计3、部分代码展示3.1 控制WS2812显示颜色3.2 设置RGB灯的颜色,角度,亮度实物图1、项目简介 选题指导…...
【MyBatis】篇一.
文章目录1、MyBatis概述2、环境搭建1、MyBatis概述 认识: JavaEE开发的一个套件SSM,即: MyBatis是一个持久层的框架,是对JDBC的一个封装,是一个半自动的ORM框架。 ORM即实体类对象和数据库中的数据的一个映射关系&am…...

【JavaScript速成之路】JavaScript流程控制
📃个人主页:「小杨」的csdn博客 🔥系列专栏:【JavaScript速成之路】 🐳希望大家多多支持🥰一起进步呀! 文章目录前言1,流程控制2,分支结构2.1,if语句2.2&…...

18、基准测试,sysbench
基准测试,sysbench 1. sysbench1.1 用途1.2 安装1.3 版本1.4 查看帮助1.5 测试过程阶段2 CPU 性能测试2.1 测试原理2.2 查看帮助2.3 测试3. 内存性能测试3.1 查看帮助信息3.2 测试过程4.磁盘性能基准测试4.1 查看帮助4.2 生成文件(prepare)4.3 测试文件io(run)4.4 结果分析4.5…...

3D,点云拼接2
文章目录 点云配准方法自动配准技术PCL实现的配准算法两两配准1.关键点提取2.特征描述符3. 对应关系估计4. 对应关系去除5. 变换矩阵估算在上篇文章中对于拼接的概念、拼接精度的评价做了详细的介绍。本文是对拼接(配准)的进一步介绍,涉及更多原理层面的东西。 主要围绕以下三…...
)
jmeter学习笔记一(http基础知识)
HTTP请求:客户端同通过发送http请求向服务器请求资源的访问。http请求由三部分组成:请求行、请求头、请求正文 请求行包括:请求方法 URI 协议/版本 请求头:Content-type、Cookie、Authorization、User-Agent、Accept、Acc…...

ClawX:OpenClaw AI智能体桌面门户,图形化编排与自动化实战
1. 项目概述:ClawX,为OpenClaw AI智能体打造的桌面门户如果你和我一样,对AI智能体(AI Agent)的潜力感到兴奋,却又对在终端里敲打复杂的命令行、配置繁琐的YAML文件感到头疼,那么ClawX的出现&…...

ARM架构TLB管理机制与RVALE1指令详解
1. ARM架构中的TLB管理机制解析在ARMv8/ARMv9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,承担着加速虚拟地址到物理地址转换的关键任务。当CPU需要访问内存时,T…...

物联网标准演进与云平台破局:从M2M到IoT的实战路径
1. 从M2M到IoT:一场迟来的标准革命十多年前,当我第一次接触“机器对机器”这个概念时,感觉它就像个被锁在工厂车间里的幽灵——功能强大,但离普通人的生活无比遥远。那时的M2M,谈论的是专用网络、私有协议和封闭的垂直…...

无线充电技术:从手机标配到多场景应用的挑战与机遇
1. 无线充电市场现状:繁荣表象下的应用困境手机无线充电,现在几乎成了旗舰机的标配。从咖啡馆、机场到汽车中控台,充电垫的身影随处可见。作为一名在电源管理和消费电子领域摸爬滚打了十几年的工程师,我亲眼见证了Qi标准从实验室走…...

JAVA学习之JAVASE基础
集合列表ListArrayList利用空参创建的集合,在底层创建一个默认长度为0的数组添加第一个元素时,底层会创建一个新的长度为10的数组存满时,会扩容1.5倍一次存多个元素,1.5倍还不够,则新创建的数组长度以实际为准LinkedLi…...

Void Memory:为AI智能体构建持久记忆的轻量级解决方案
1. 项目概述:为AI智能体构建持久记忆的“记忆锚”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手并肩作战,一定对那个令人沮丧的瞬间不陌生:你花了半小时向它详细解释了一个复杂项目的架构、你的编码偏好、刚刚踩过的坑…...

dnGrep搜索结果分析与报告生成:如何导出和分享搜索数据
dnGrep搜索结果分析与报告生成:如何导出和分享搜索数据 【免费下载链接】dnGrep Graphical GREP tool for Windows 项目地址: https://gitcode.com/gh_mirrors/dn/dnGrep dnGrep是一款强大的Windows图形化GREP搜索工具,它不仅能够快速搜索文件内容…...

安全代码沙盒实践:从Docker到seccomp的多层防御架构
1. 项目概述:安全代码执行的沙盒化实践在开发、测试乃至在线教育、代码评测平台等场景中,我们经常面临一个核心挑战:如何安全地执行一段来源未知、意图不明的代码?直接在生产服务器上运行用户提交的代码,无异于敞开大门…...

Flutter中如何显示异步数据
在开发Flutter应用时,处理异步操作是非常常见的任务之一。许多时候,我们需要将异步操作的结果展示在用户界面上,比如从服务器获取数据或执行一些耗时的计算。本文将通过一个具体的实例,展示如何在Flutter中使用FutureBuilder来处理和显示异步数据。 问题背景 假设我们有一…...

截断重加权核范数低秩稀疏分解模型与RPCA应用【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)自适应对数截断核范数与变换域稀疏先验的联合模型&am…...