数据结构--二叉搜索树的实现
目录
1.二叉搜索树的概念
2.二叉搜索树的操作
二叉搜索树的插入
中序遍历(常用于排序)
二叉搜索树的查找
二叉搜索树的删除
完整二叉树代码:
二叉搜索树的应用
key/value搜索模型整体代码
1.二叉搜索树的概念
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子树也分别 为二叉搜索树

#include<iostream>
using namespace std;template<class K>//搜索二叉树的结点
struct BSTreeNode
{K _key;BSTreeNode<K>* _left;BSTreeNode<K>* _right;BSTreeNode(const K& s = K()):_key(s), _left(nullptr), _right(nullptr){}
};template<class K>//搜索二叉树
class BSTree
{
public:BSTree():_root(nullptr){}//...各种操作二叉搜索树方法的实现//...
private:typedef BSTreeNode<K> Node;Node* _root;
};2.二叉搜索树的操作
二叉搜索树的插入
这里根据二叉搜索树的概念分两种情况:
a. 树为空,则直接新增节点,赋值给 root 指针b. 树不空,按二叉搜索树性质查找插入位置,插入新节点
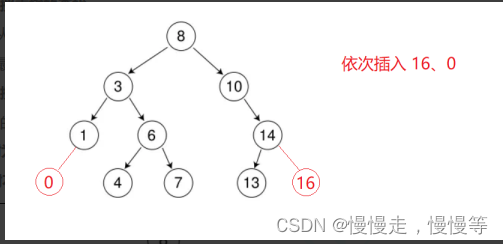
非递归
bool Insert(const K & key){if (_root == nullptr)//情况a{_root = new Node(key);}else//情况b{Node* parent = nullptr;//记录当前节点的父结点Node* cur = _root;while (cur){if (cur->_key > key)//小于当前节点的值,向左走{parent = cur;cur = cur->_left;}else if (cur->_key < key)//大于当前结点的值,向右走{parent = cur;cur = cur->_right;}else //数字重复插入失败{return false;}}cur = new Node(key);if (parent->_key > key)//判断插入结点是在parent的左子树还是右子树{parent->_left = cur;}else{parent->_right = cur;}return true;}}为什么要定义parent变量记录cur的父节点?
这里我们要知道,cur=new Node(key)这行代码的真正意义是给cur赋值,并没有把结点插入到树中。
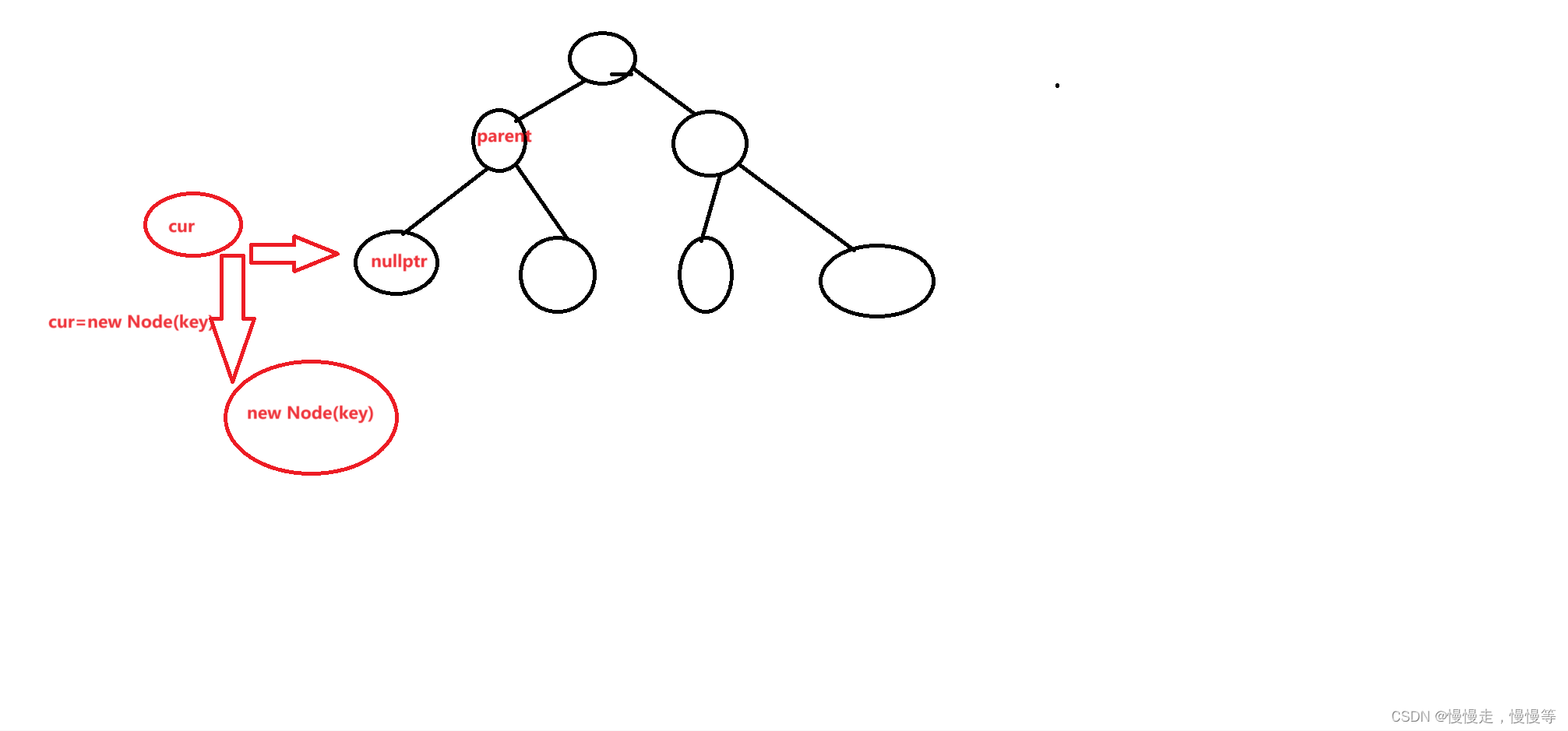
注:在向二叉搜索树插入时,一定要判断是在父节点的左子树还是右子树。
递归:
public:
bool InsertR(const K& key)
{return _insertR(_root, key);
}private:
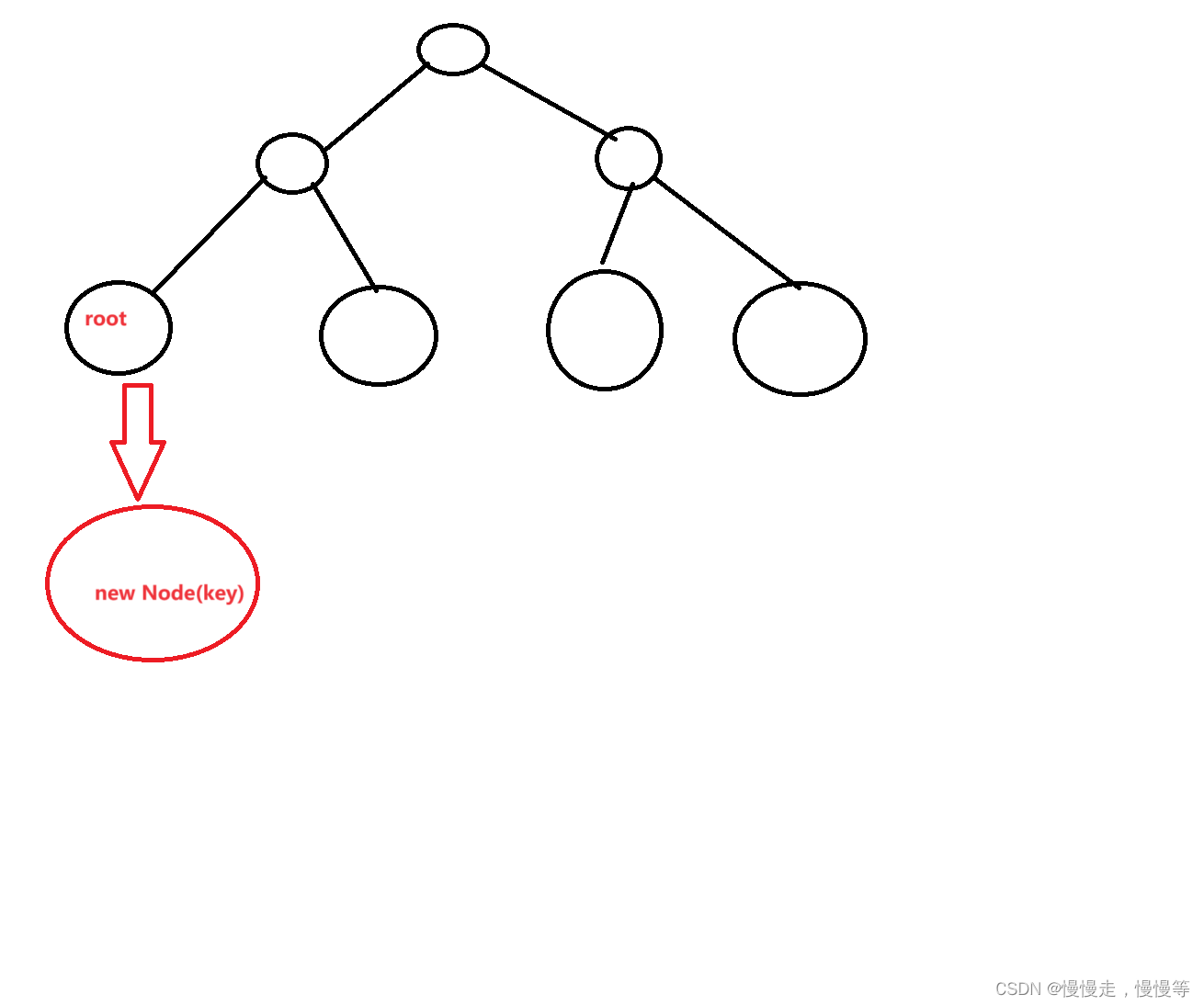
bool _insertR(Node*& root, const K& key)
{if (root == nullptr){root = new Node(key);return true;}else{if (root->_key > key){return _insertR(root->_left, key);}else if (root->_key < key){return _insertR(root->_right, key);}else{return false;}}
}注:由于使用递归时,需要用到成员变量_root作为实参,但是在类外面无法直接调用,因此,将递归调用的函数封装到了InsertR()里面。
为什么这里不用记录父节点,就可以插入到树中。
这里我们要注意函数的第一个变量,我们使用了引用!
这里的root就是父节点的左孩子或有孩子。
中序遍历(常用于排序)
public:
void Inorder()
{_Inorder(_root);
}private:
void _Inorder(Node* root)
{if (root == nullptr)return;_Inorder(root->_left);cout << root->_key << " ";_Inorder(root->_right);
}这里根据二叉搜索树的概念我们清楚,其中序遍历相当于将树里面的数据按从小到大排序输出。
二叉搜索树的查找
查找方法:
a 、从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。b 、最多查找高度次,走到到空,还没找到,这个值不存在。
注意:
为完全二叉树时间复杂度最好,为O(log n)
树的结点全部为左孩子或右孩子时,时间复杂度最坏,为O(n)
非递归
bool Find(const K& key)
{if (_root == nullptr)//树为空return false;Node* cur = _root;while (cur){if (cur->_key > key){cur = cur->left;// _key>key.左走}else if (cur->_key < key){cur = cur->_right;//_key<key.右走}else{return true;//相等,找到}}return false;//没有一个相等
}递归:
public:
Node* FindR(const K& key)
{return _FindR(_root, key);
}private:
Node* _FindR(Node* root, const K& key)
{if (root == nullptr)return nullptr;if (root->_key > key){_FindR(root->_left, key);}else if (root->_key < key){_FindR(root->_right, key);}else{return root;}
}二叉搜索树的删除
a. 要删除的结点无孩子结点b. 要删除的结点只有左孩子结点c. 要删除的结点只有右孩子结点d. 要删除的结点有左、右孩子结点
情况 b :删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点 -- 直接删除情况 c :删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点 -- 直接删除情况 d :在它的右子树中寻找中序下的第一个结点 ( 关键码最小 ) ,用它的值填补到被删除节点中,再来处理该结点的删除问题 -- 替换法删除
bool Erase(const K& key)
{if (_root == nullptr)return false;Node* cur = _root;Node* parent = nullptr;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = nullptr;cur = cur->_right;}else{if (cur->_left == nullptr)//情况a{if (cur == _root)//特殊条件,等于根节点{_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->right == nullptr)//情况b{if (cur == _root) //特殊条件,等于根节点{_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else //情况c{Node* parent = cur;Node* subnode = cur->_right;while (subnode->_left){parent = subnode;subnode = subnode->_left;}swap(cur->_key, subnode->_key);if (parent->_right == subnode) //当cur->_right->left==nullptr{parent->_right = subnode->_right;}else{parent->_left = subnode->_right;}delete subnode;}return true;}}return false;
}递归:
public:bool EraseR(const K& key)
{_EraseR(_root,key);
}private:bool _EraseR(Node*& root, const K& key)
{if (root == nullptr){return false;}if (root->_key > key){return _EraseR(root->_left, key);}else if (root->_key < key){return _EraseR(root->_right, key);}else{if (root->_left == nullptr){Node* temp = root;root = root->_right;delete temp;}else if (root->right){Node* temp = root;root = root->_left;delete temp;}else{Node* subnode = root->_right;while (subnode->left){subnode = subnode->_left;}swap(root->_key, subnode->_key);return _EraseR(root - right, key);}}
}完整二叉树代码:
#include<iostream>
using namespace std;template<class K>//搜索二叉树的结点
struct BSTreeNode
{K _key;BSTreeNode<K>* _left;BSTreeNode<K>* _right;BSTreeNode(const K& s = K()):_key(s), _left(nullptr), _right(nullptr){}
};template<class K>//搜索二叉树
class BSTree
{
public:BSTree():_root(nullptr){}bool Insert(const K & key){if (_root == nullptr)//情况a{_root = new Node(key);}else//情况b{Node* parent = nullptr;//记录当前节点的父结点Node* cur = _root;while (cur){if (cur->_key > key)//小于当前节点的值,向左走{parent = cur;cur = cur->_left;}else if (cur->_key < key)//大于当前结点的值,向右走{parent = cur;cur = cur->_right;}else //数字重复插入失败{return false;}}cur = new Node(key);if (parent->_key > key)//判断插入结点是在parent的左子树还是右子树{parent->_left = cur;}else{parent->_right = cur;}return true;}}bool Find(const K& key){if (_root == nullptr)//树为空return false;Node* cur = _root;while (cur){if (cur->_key > key){cur = cur->left;// _key>key.左走}else if (cur->_key < key){cur = cur->_right;//_key<key.右走}else{return true;//相等,找到}}return false;//没有一个相等}Node* FindR(const K& key){return _FindR(_root, key);}void Inorder(){_Inorder(_root);}bool InsertR(const K& key){return _insertR(_root, key);cout << endl;}bool Erase(const K& key){if (_root == nullptr)return false;Node* cur = _root;Node* parent = nullptr;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if(cur->_key<key){parent = nullptr;cur = cur->_right;}else{if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if(cur->right==nullptr){if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{Node* parent = cur;Node* subnode = cur->_right;while (subnode->_left){parent = subnode;subnode = subnode->_left;}swap(cur->_key, subnode->_key);if (parent->_right == subnode){parent->_right = subnode->_right;}else{parent->_left = subnode->_right;}delete subnode;}return true;}}return false;}bool EraseR(const K& key){return _EraseR(_root, key);}private:typedef BSTreeNode<K> Node;Node* _root;bool _insertR(Node*& root, const K& key){if (root == nullptr){root = new Node(key);return true;}else{if (root->_key > key){return _insertR(root->_left, key);}else if (root->_key < key){return _insertR(root->_right, key);}else{return false;}}}void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_key<<" ";_Inorder(root->_right);}Node*_FindR(Node* root, const K& key){if (root == nullptr)return nullptr;if (root->_key > key){_FindR(root->_left, key);}else if (root->_key < key){_FindR(root->_right, key);}else{return root;}}bool _EraseR(Node*& root, const K& key){if (root == nullptr){return false;}if (root->_key > key){return _EraseR(root->_left, key);}else if (root->_key < key){return _EraseR(root->_right, key);}else{if (root->_left == nullptr){Node* temp = root;root = root->_right;delete temp;}else if (root->right){Node* temp = root;root = root->_left;delete temp;}else{Node* subnode = root->_right;while (subnode->left){subnode = subnode->_left;}swap(root->_key, subnode->_key);return _EraseR(root - right, key);}}}
};二叉搜索树的应用
key/value搜索模型整体代码
#pragma once
// 改造二叉搜索树为KV结构
template<class K, class V>
struct BSTNode
{BSTNode(const K& key = K(), const V& value = V()): _pLeft(nullptr), _pRight(nullptr), _key(key), _Value(value){}BSTNode<T>* _pLeft;BSTNode<T>* _pRight;K _key;V _value
};template<class K, class V>
class BSTree
{typedef BSTNode<K, V> Node;
public:bool Insert(const K& key,const V& value){if (_root == nullptr)//情况a{_root = new Node(key,value);}else//情况b{Node* parent = nullptr;//记录当前节点的父结点Node* cur = _root;while (cur){if (cur->_key > key)//小于当前节点的值,向左走{parent = cur;cur = cur->_left;}else if (cur->_key < key)//大于当前结点的值,向右走{parent = cur;cur = cur->_right;}else //数字重复插入失败{return false;}}cur = new Node(key,value);if (parent->_key > key)//判断插入结点是在parent的左子树还是右子树{parent->_left = cur;}else{parent->_right = cur;}return true;}}bool Find(const K& key){if (_root == nullptr)//树为空return false;Node* cur = _root;while (cur){if (cur->_key > key){cur = cur->left;// _key>key.左走}else if (cur->_key < key){cur = cur->_right;//_key<key.右走}else{return true;//相等,找到}}return false;//没有一个相等}bool Erase(const K& key){if (_root == nullptr)return false;Node* cur = _root;Node* parent = nullptr;while (cur){if (cur->_key > key){parent = cur;cur = cur->_left;}else if (cur->_key < key){parent = nullptr;cur = cur->_right;}else{if (cur->_left == nullptr){if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->right == nullptr){if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{Node* parent = cur;Node* subnode = cur->_right;while (subnode->_left){parent = subnode;subnode = subnode->_left;}swap(cur->_key, subnode->_key);if (parent->_right == subnode){parent->_right = subnode->_right;}else{parent->_left = subnode->_right;}delete subnode;}return true;}}return false;}void Inorder(){_Inorder(_root);}private:Node* _root;void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_key << ":"<<root->_value<<endl;_Inorder(root->_right);}
};相关文章:

数据结构--二叉搜索树的实现
目录 1.二叉搜索树的概念 2.二叉搜索树的操作 二叉搜索树的插入 中序遍历(常用于排序) 二叉搜索树的查找 二叉搜索树的删除 完整二叉树代码: 二叉搜索树的应用 key/value搜索模型整体代码 1.二叉搜索树的概念 二叉搜索树又称二叉排序树,它或者是一…...

《微信小程序开发从入门到实战》学习六十八
6.6 网络API 6.6.1 网络API 使用wx.request接口可以发起网络请求。该接口接受一个Object参,参数支持属性如下所示: url(必填):开发者服务器地址 data:请求的参数,类型为string/object/ArrayBuffer header…...

阿里是如何去“O”的?
大家好,我是老猫,猫头鹰的“猫”。 今天我们来聊聊数据库这个话题。 2009年,阿里提出“去IOE化”的概念,这在当时看起来是天方夜谭,但目前来看可以说是"轻舟已过万重山"。 IOE是传统IT三大件,…...

蓝桥杯备赛 day 1 —— 递归 、递归、枚举算法(C/C++,零基础,配图)
目录 🌈前言 📁 枚举的概念 📁递归的概念 例题: 1. 递归实现指数型枚举 2. 递归实现排列型枚举 3. 递归实现组合型枚举 📁 递推的概念 例题: 斐波那契数列 📁习题 1. 带分数 2. 反硬币 3. 费解的…...

87 双指针解验证回文字符串II
问题描述:简单给定一个非空字符串s,最多删除一个字符,判断是否成为回文字符串。 双指针解法:指针1指向开头,指针2指向结尾,定义一个count记录不满足回文串的数量,若超过1,则返回fal…...

【排序算法】【二叉树】【滑动窗口】LeetCode220: 存在重复元素 III
作者推荐 【二叉树】【单调双向队列】LeetCode239:滑动窗口最大值 本文涉及的基础知识点 C算法:滑动窗口总结 题目 给你一个整数数组 nums 和两个整数 indexDiff 和 valueDiff 。 找出满足下述条件的下标对 (i, j): i ! j, abs(i - j) < indexDi…...
OS 7--DNS配置+Apache发布网站
环境准备 centOS 7 1.配置DNS 1.1 域名为lianxi.com 1.2 为WWW服务器、FTP服务器、NEWS服务器做域名解析 1)安装DNS yum -y install bind bind-utils (如果安装不上,就把磁盘在重洗挂载一下) 2)修改DNS配置文件 vim /etc/resolv.conf…...

1月2日代码随想录二叉树的最小深度及层序遍历总结
个人认为这么一个层序遍历的章节放这么多基本一样的题目算是很没意思的了 填充每个节点的下一个右侧节点和二叉树最大深度和前面的代码几乎完全一样,所以我就跳过了 代码随想录 (programmercarl.com) 代码随想录 (programmercarl.com) 111.二叉树的最小深度 给…...
RK3568平台开发系列讲解(Linux系统篇)PWM系统编程
🚀返回专栏总目录 文章目录 一、什么是PWM二、PWM相关节点三、PWM应用编程沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将介绍 PWM 的系统编程。 一、什么是PWM PWM,即脉冲宽度调制(Pulse Width Modulation)...

Linux CPU 数据 Metrics 指标解读
过去从未仔细了解过使用 top 和 htop 等命令时显式的CPU信息,本文我们详解解读和标注一下各个数据项的含义,同时和 Ganglia 显式的数据做一个映射。开始前介绍一个小知识,很多查看CPU的命令行工具都是 cat /proc/stat 里的数据,所…...
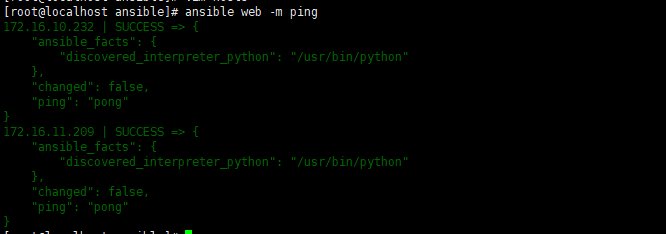
Ansible自动化运维(一)简介及部署、清单
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...

深度学习MLP_实战演练使用感知机用于感情识别_keras
目录 (1)why deep learning is game changing?(2)it all started with a neuron(3)Perceptron(4)Perceptron for Binary Classification(5)put it all toget…...
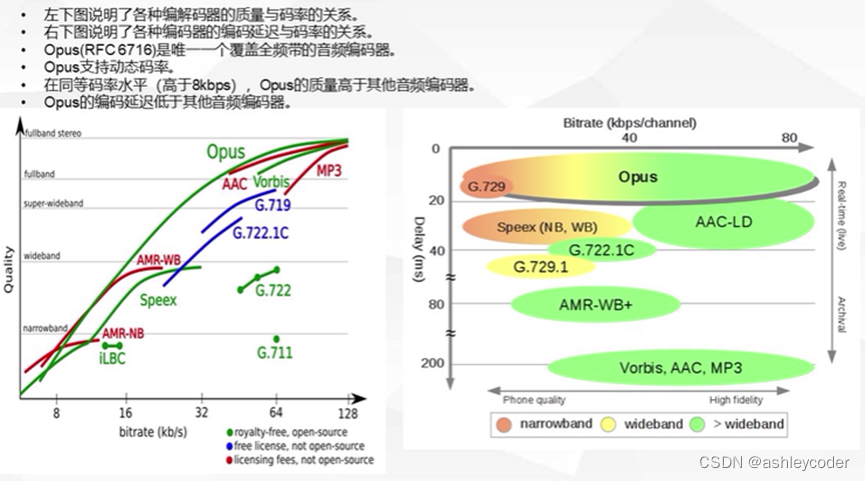
[ffmpeg系列 02] 音视频基本知识
一 视频 RGB: AV_PIX_FMT_RGB24, ///< packed RGB 8:8:8, 24bpp, RGBRGB… Y:明亮度, Luminance或luma, 灰阶图, UV:色度,Chrominance或Chroma。 YCbCr: Cb蓝色分量,Cr是红色分量。 取值范围ÿ…...

【ASP.NET Core 基础知识】--目录
介绍 1.1 什么是ASP.NET Core1.2 ASP.NET Core的优势1.3 ASP.NET Core的版本历史 环境设置 2.1 安装和配置.NET Core SDK2.2 使用IDE(Integrated Development Environment):Visual Studio Code / Visual Studio 项目结构 3.1 ASP.NET Core项…...

java数据结构与算法刷题-----LeetCode509. 斐波那契数
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 很多人觉得动态规划很难,但它就是固定套路而已。其实动态规划只…...
)
vue3 element plus el-table封装(二)
上文是对el-table的基本封装,只能满足最简单的应用,本文主要是在上文的基础上增加slot插槽,并且对col插槽进行拓展,增加通用性 // BaseTable.vue <template><el-table><template v-for"name in tableSlots&…...

cnn lstm结合网络
目录 特征处理例子: cnn 5张图片一组,提取特征后,再给lstm,进时间序列分类。 特征处理例子: import torch# 假设 tensor 是形状为 15x64 的张量 tensor torch.arange(15 * 2).reshape(15, 2) # 生成顺序编号的张量&…...

Ubuntu连接xshell
安装ssh服务器 sudo apt-get install openssh-server 重启ssh sudo service ssh restart 3.启动ssh服务 /etc/init.d/ssh start4.修改文件,允许远程登陆 sudo vi /etc/ssh/sshd_config PermitRootLogin prohibit-password #默认为禁止登录 PermitRootLogin y…...
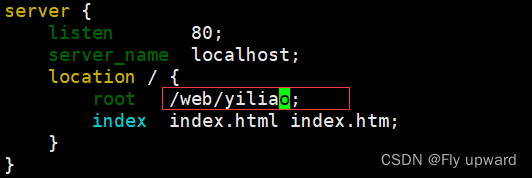
nginx安装和配置
目录 1.安装 2.配置 3.最小配置说明 4. nginx 默认访问路径 1.安装 使用 epel 源安装 先安装 yum 的扩展包 yum install epel-release -y 再安装 nginx yum install nginx -y 在启动nginx 前先关闭防火墙 systemctl stop firewalld 取消防火墙开机自启 systemctl di…...

【头歌实训】kafka-入门篇
文章目录 第1关:kafka - 初体验任务描述相关知识Kafka 简述Kafka 应用场景Kafka 架构组件kafka 常用命令 编程要求测试说明答案代码 第2关:生产者 (Producer ) - 简单模式任务描述相关知识Producer 简单模式Producer 的开发步骤Ka…...

自建密码管理器:基于Web Crypto API与Flask的零知识安全架构实践
1. 项目概述:一个基于Web的密码管理器最近在GitHub上看到一个挺有意思的项目,叫clawvault。乍一看名字,可能会联想到“爪子”和“保险库”,其实它就是一个用Python写的、基于Web界面的密码管理器。这类工具大家应该不陌生…...

AI驱动GitHub仓库分析:从数据到洞察的工程实践
1. 项目概述:一个面向开发者的AI驱动GitHub分析工具最近在GitHub上发现一个挺有意思的项目,叫instagit,来自InstalabsAI这个组织。乍一看名字,可能会联想到Instagram或者某种社交工具,但实际上,它是一个完全…...

音乐学者必看的NotebookLM冷启动指南,从乐谱OCR识别到和声进行语义建模,一步到位
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在音乐学研究中的范式革命 NotebookLM(由Google Research推出的基于用户上传文档的AI助手)正悄然重塑音乐学研究的方法论边界。它不再依赖通用知识库的模糊匹配&#…...

使用git filter-repo删除已提交到git中的敏感信息,api key,配置文件等
使用git filter-repo删除已提交到git中的敏感信息,api key,配置文件等 前提条件 Python 3.5 git > 2.22.0通过 pip 安装:pip install git-filter-repo 注意事项 官方推荐在fresh clone上修改,即clone一份远程的再做修改 操作后…...

MVDRAM技术:利用DRAM隐藏计算潜力加速LLM推理
1. MVDRAM技术背景与核心挑战在当今大语言模型(LLM)推理场景中,矩阵向量乘法(GeMV)操作占据了超过70%的计算开销。传统CPU/GPU架构面临三个根本性瓶颈:内存墙问题(数据搬运能耗是计算的200倍&am…...

基于Gemini API构建多模态视觉应用:从原理到部署实践
1. 项目概述与核心价值最近在AI多模态领域,一个名为“gemini-vision-pro”的项目在开发者社区里引起了不小的讨论。这个项目本质上是一个基于Google Gemini API的视觉识别与图像理解应用,但它并非简单的API调用封装,而是提供了一个开箱即用、…...

使用kern工具自动化构建Linux内核:从原理到实战
1. 项目概述:一个内核构建与管理的瑞士军刀如果你曾经尝试过编译Linux内核,或者需要为特定的硬件、研究项目定制一个内核,那么你大概率体验过这个过程:下载源码、配置成千上万个选项、解决依赖、漫长编译,最后可能因为…...

【SimMechanics实战】从零搭建Matlab机械臂仿真模型:模块详解与坐标系规划
1. SimMechanics入门:为什么选择它做机械臂仿真 第一次接触机械臂仿真时,我试过几种不同的工具,最后发现SimMechanics真是个好帮手。它和Matlab/Simulink无缝集成,数据处理特别方便,不像有些专业仿真软件需要频繁导入导…...
进程的状态优先级)
(二)进程的状态优先级
1进程的状态(兼容所有操作系统)1.1并行和并发CPU执行进程代码,不是把进程代码执行完毕,才开始执行下一个 而是给每一个进程预分配一个 时间片,基于时间片,进行调度轮转(单CPU下),并发。并发:多个进程在一个…...

【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由Adobe+MJ Labs联合签发的Futurism Prompt Architect证书
更多请点击: https://intelliparadigm.com 第一章:【限时开放】Midjourney未来主义风格权威认证路径:完成这5个里程碑任务,获取由AdobeMJ Labs联合签发的Futurism Prompt Architect证书 什么是未来主义Prompt架构师认证…...