【C++】30h速成C++从入门到精通(内存管理、函数/类模板)
C++内存分布
我们先来看一下下面的一段代码相关问题
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{static int staticVar = 1;int localVar = 1;int num1[10] = {1, 2, 3, 4};char char2[] = "abcd";char* pChar3 = "abcd";int* ptr1 = (int*)malloc(sizeof (int)*4);int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int)*4);free (ptr1);free (ptr3);
}
1. 选择题:选项: A.栈 B.堆 C.数据段 D.代码段globalVar在哪里?__c__ staticGlobalVar在哪里?__c__staticVar在哪里?__c__ localVar在哪里?__a__num1 在哪里?__a__char2在哪里?__a__ *char2在哪里?__d__pChar3在哪里?__a__ *pChar3在哪里?__d__ptr1在哪里?__a__ *ptr1在哪里?__b__
2. 填空题:sizeof(num1) = __40__; sizeof(char2) = __5__; strlen(char2) = __4__;sizeof(pChar3) = __8__; strlen(pChar3) = __4__;sizeof(ptr1) = __8__;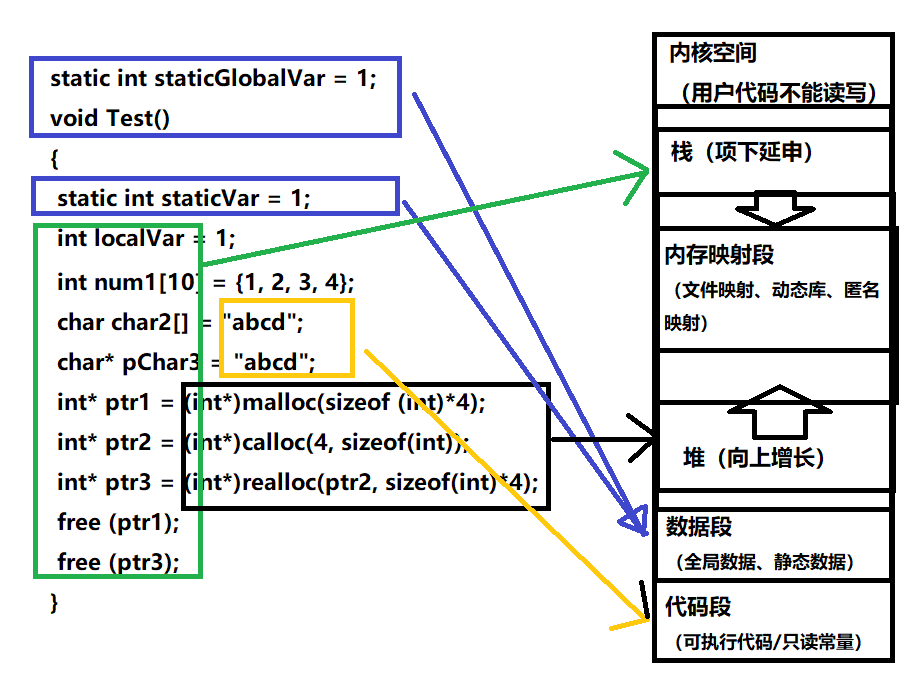
【说明】
堆又叫堆栈,非静态局部变量/函数参数/返回值等等,栈是向下增长的。
内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)。
堆用于程序运行时动态内存分配,堆是可以上增长的。
数据段--存储全局数据和静态数据。
代码段--可执行的代码/只读常量。
C语言当中动态内存管理方式
malloc/calloc/realloc/free
void Test ()
{int* p1 = (int*) malloc(sizeof(int));free(p1);// 1.malloc/calloc/realloc的区别是什么?int* p2 = (int*)calloc(4, sizeof (int));int* p3 = (int*)realloc(p2, sizeof(int)*10);// 这里需要free(p2)吗?free(p3 );
}【面试题分享】
malloc/calloc/realloc的区别?
C++内存管理方式
C语言内存管理方式在C++当中可以继续使用,但是有些地方就无能为力而且使用起来比较繁琐,因此C++又提出了自己的内存管理方式:通过new和delete操作符来进行动态内存管理。
new/delete操作内置类型
void Test()
{// 动态申请一个int类型的空间int* ptr4 = new int;// 动态申请一个int类型的空间并初始化为10int* ptr5 = new int(10);// 动态申请10个int类型的空间int* ptr6 = new int[10];delete ptr4;delete ptr5;delete[] ptr6;
}
【注意】申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[]。
new和delete操作自定义类型
class Test
{
public:Test(): _data(0){cout<<"Test():"<<this<<endl;}~Test(){cout<<"~Test():"<<this<<endl;}private:int _data;
};
void Test2()
{// 申请单个Test类型的空间Test* p1 = (Test*)malloc(sizeof(Test));free(p1);// 申请10个Test类型的空间Test* p2 = (Test*)malloc(sizoef(Test) * 10);free(p2);
}void Test2()
{// 申请单个Test类型的对象Test* p1 = new Test;delete p1;// 申请10个Test类型的对象Test* p2 = new Test[10];delete[] p2;
}【注意】
在申请自定义类型的空间时,new会调用构造函数,delete会调用析构函数,而malloc和free不会。
operator new与operator delete函数(重要)
operator new与operator delete函数(重点)
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,
尝试执行空 间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。
*/
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{// try to allocate size bytesvoid *p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}return (p);
}
/*
operator delete: 该函数最终是通过free来释放空间的
*/
void operator delete(void *pUserData)
{_CrtMemBlockHeader * pHead;RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));if (pUserData == NULL)return;_mlock(_HEAP_LOCK); /* block other threads */__TRY/* get a pointer to memory block header */pHead = pHdr(pUserData);/* verify block type */_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));_free_dbg( pUserData, pHead->nBlockUse );__FINALLY_munlock(_HEAP_LOCK); /* release other threads */__END_TRY_FINALLYreturn;
}
/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)通过上述两个全局函数的实现知道,operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
operator new与operator delete的类专属重载(了解)
下面代码演示了,针对链表的节点ListNode通过重载类专属 operator new/ operator delete,实现链表节点使用内存池申请和释放内存,提高效率。
struct ListNode
{ListNode* _next;ListNode* _prev;int _data;void* operator new(size_t n){void* p = nullptr;p = allocator<ListNode>().allocate(1);cout << "memory pool allocate" << endl;return p;}void operator delete(void* p){allocator<ListNode>().deallocate((ListNode*)p, 1);cout << "memory pool deallocate" << endl;}
};
class List
{
public:List(){_head = new ListNode;_head->_next = _head;_head->_prev = _head;}~List(){ListNode* cur = _head->_next;while (cur != _head){ListNode* next = cur->_next;delete cur;cur = next;}delete _head;_head = nullptr;}
private:ListNode* _head;
};
int main()
{List l;return 0;
}new和delete的实现原理
内置类型
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是:new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间,而且new在申请空间失败时会抛异常,malloc会返回NULL。
自定义类型
new的原理
1. 调用operator new函数申请空间
2. 在申请的空间上执行构造函数,完成对象的构造
delete的原理
1. 在空间上执行析构函数,完成对象中资源的清理工作
2. 调用operator delete函数释放对象的空间
new T[N]的原理
1. 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
2. 在申请的空间上执行N次构造函数
delete[]的原理
1. 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
2. 调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释放空间
定位new表达式(placement-new)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
使用格式:
new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
使用场景:
定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
class Test
{
public:Test(): _data(0){cout<<"Test():"<<this<<endl;}~Test(){cout<<"~Test():"<<this<<endl;}private:int _data;
};
void Test()
{// pt现在指向的只不过是与Test对象相同大小的一段空间,还不能算是一个对象,因为构造函数没有执行Test* pt = (Test*)malloc(sizeof(Test));new(pt) Test; // 注意:如果Test类的构造函数有参数时,此处需要传参
}常见面试题
malloc/free和new/delete的区别
mallo/free和new/delete的共同点:
都从堆上申请空间,并且需要用户手动释放。
不同点:
1.malloc和free是函数,new和delete是操作符;
2.malloc申请的空间不会初始化,new可以初始化;
3.malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间类型就行;
4.malloc的返回值为void*,在使用时必须强转,new不需要,因为new后跟的是控件类型;
5.malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常;
6.申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造析构函数,而new会在申请空间后调用构造函数完成对对象的初始化,delete在释放空间钱会调用析构函数完成空间中资源的清理。
内存泄露
1.什么是内存泄漏:
内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
2.内存泄露的危害:
长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
3.内存泄漏的分类(了解):
堆内存泄漏(heap leak):
堆内存指的是程序执行中依据须要分配通过malloc / calloc / realloc / new等从堆中分配的一块内存,用完后必须通过调用相应的 free或者delete 删掉。假设程序的设计错误导致这部分内存没有被释放,那么以后这部分空间将无法再被使用,就会产生Heap Leak。
系统资源泄漏:
指程序使用系统分配的资源,比方套接字、文件描述符、管道等没有使用对应的函数释放掉,导致系统资源的浪费,严重可导致系统效能减少,系统执行不稳定。
3.如何避免内存泄漏:
工程前期良好的设计规范,养成良好编码规范,申请内存空间记得匹配的去释放;
采用RAII思想或者智能指针来管理资源;
有些公司内部规范使用内部实现的私有内存管理库,这套库自带内存泄露检测的功能选项;
出问题了使用内存泄露工具检测。
4.总结:
内存泄漏非常常见,解决方案分为两种:
一是事前预防型,如智能指针等;二是事后差错型,如泄漏检测工具。
如何一次在堆上申请4G的内存
// 将程序编译成x64的进程,运行下面的程序试试?
#include <iostream>
using namespace std;
int main()
{void* p = new char[0xfffffffful];cout << "new:" << p << endl;return 0;
}泛型编程
如何实现一个通用函数的交换呢?
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
void Swap(double& left, double& right)
{double temp = left;left = right;right = temp;
}
void Swap(char& left, char& right)
{char temp = left;left = right;right = temp;
}
......虽然函数重载可以实现,但是有以下几个不好的地方:
重载的函数仅仅是类型不同,代码的复用率比较低,只要有新类型出现,就需要增加对应的函数;
代码的维护性可能比较低,一个出错所有重载均出错!
那么能都告诉编译器一个模子,让编译器根据不同类型利用这个模子来生成代码呢?
如果在C++中也能够存在这样一个模子,通过给这个模子不断填充不同材料(类型),来获得不同的成品(生成具体类型的代码),那将会节省许多头发,巧的是前人早已将树栽好。
函数模板
函数模板的概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参型产生函数的特定类型版本。
函数模板格式
template<typename T1,typename T2, ... ... ,typename Tn>
返回值类型 函数名(参数列表){}
template<typename T>
void Swap( T& left, T& right)
{T temp = left;left = right;right = temp;
}注意:typrname是用来定义模板参数的关键字,也可以使用class(切记:不能使用struct代替class)
函数模板原理
函数模板是一个蓝图,它本身并不是函数,是编译器有使用方式生产特定具体类型函数的模具,所以其实模板就是将本来应该我们做的重复的事情交给了编译器。
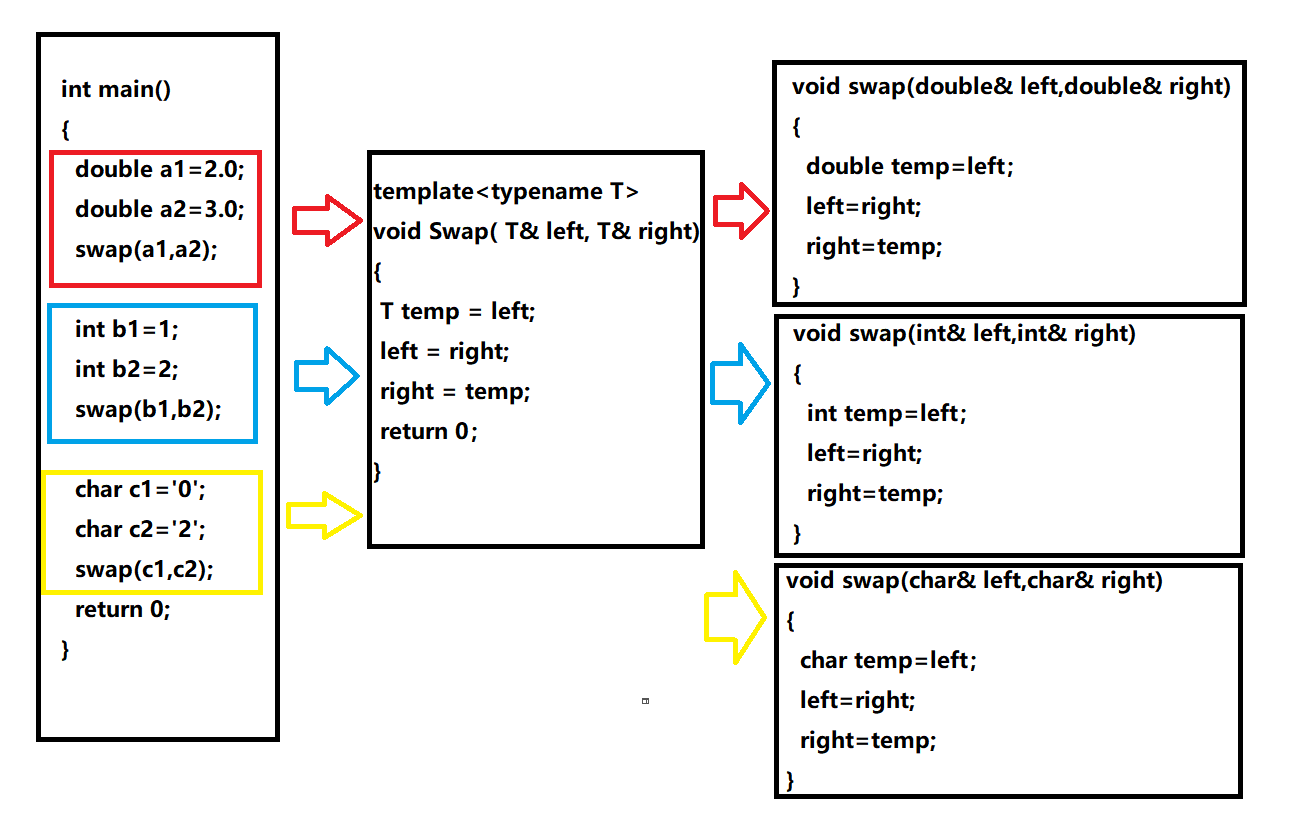
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}
int main()
{int a1 = 10, a2 = 20;double d1 = 10.0, d2 = 20.0;Add(a1, a2);Add(d1, d2);/*该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅Add(a1, d1);*/// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化Add(a1, (int)d1);return 0;
}显式实例化:在函数名后的<>中指定模板参数的实际类型
int main(void)
{int a = 10;double b = 20.0;// 显式实例化Add<int>(a, b);return 0;
}如果类型不匹配,编译器会尝试进行隐式转换,如果无法转换成功就会报错。
模板参数的匹配原则
1、一个非模板函数可以和一个同名的函数模板同时存在,而且改模板函数还可以被实例化这个非模板函数:
// 专门处理int的加法函数
int Add(int left, int right)
{cout << "非模板" << endl;return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{cout << "模板" << endl;return left + right;
}
void Test()
{Add(1, 2); // 与非模板函数匹配,编译器不需要特化Add<int>(1, 2); // 调用编译器特化的Add版本
}2、对于非模板函数和同名函数模板,如果其他条件都相同,会在调用时优先调用非模板函数,而不会从模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数,那么将选择模板。
// 专门处理int的加法函数
int Add(int left, int right)
{return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{return left + right;
}
void Test()
{Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}3、模板函数不允许自动类型转换,但普通函数可以进行自动类型转换。
类模板
类模板的定义格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{// 类内成员定义
}; // 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template<class T>
class Vector
{
public :Vector(size_t capacity = 10): _pData(new T[capacity]), _size(0), _capacity(capacity){}// 使用析构函数演示:在类中声明,在类外定义。~Vector();void PushBack(const T& data);void PopBack();// ...size_t Size() {return _size;}T& operator[](size_t pos){assert(pos < _size);return _pData[pos];}private:T* _pData;size_t _size;size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{if(_pData)delete[] _pData;_size = _capacity = 0;
}类模板的实例化
类模板的实例化与函数模板实例化不同,类模板实例化需要在类模板名字后面跟<>,然后将实例化放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
// Vector类名,Vector<int>才是类型
Vector<int> s1;
Vector<double> s2;非类型模板参数
模板参数分类类型形参与非类型形参
类型形参即:出现在模板参数列表中,跟class或者typename之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
namespace bite
{// 定义一个模板类型的静态数组template<class T, size_t N = 10>class array{public:T& operator[](size_t index){return _array[index];}const T& operator[](size_t index)const{return _array[index];}size_t size()const{return _size;}bool empty()const{return 0 == _size;}private:T _array[N];size_t _size;};
}注意:
浮点数、类对象以及字符串是不允许作为非类型模板参数的。
非类型的模板参数必须在编译期就能确认结果。
模板的特化
概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,比如:
template<class T>
bool IsEqual(T& left, T& right)
{return left == right;
}
void Test()
{const char* p1 = "hello";const char* p2 = "world";if(IsEqual(p1, p2))cout<<p1<<endl;elsecout<<p2<<endl;
}此时,就需要对模板进行特化,即在原模板类的基础上,针对特殊类型所进行特殊化的实现方式,模板特化中分为函数模板特化与类模板特化。
函数模板的特化
函数模板特化的步骤:
必须要现有一个基础的函数模板
关键字template后接一对空的尖括号<>
函数名后跟一对尖括号,尖括号中指定需要特化的类型
函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误
template<>
bool IsEqual<char*>(char*& left, char*& right)
{if(strcmp(left, right) > 0)return true;return false;
}注意:
一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
bool IsEqual(char* left, char* right)
{if(strcmp(left, right) > 0)return true;return false;
}类模板的特化
全特化:
全特化即是将模板参数列表中所有的参数都确定化
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};
template<>
class Data<int, char>
{
public:Data() {cout<<"Data<int, char>" <<endl;}
private:T1 _d1;T2 _d2;
};
void TestVector()
{Data<int, int> d1;Data<int, char> d2;
} 偏特化:
任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};部分特化:
将模板参数类表中的一部分参数特化。
// 将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:Data() {cout<<"Data<T1, int>" <<endl;}
private:T1 _d1;int _d2;
}; 参数更进一步的限制
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data() {cout<<"Data<T1*, T2*>" <<endl;}private:T1 _d1;T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:Data(const T1& d1, const T2& d2): _d1(d1), _d2(d2){cout<<"Data<T1&, T2&>" <<endl;}private:const T1 & _d1;const T2 & _d2; };
void test2 ()
{Data<double , int> d1; // 调用特化的int版本Data<int , double> d2; // 调用基础的模板 Data<int *, int*> d3; // 调用特化的指针版本Data<int&, int&> d4(1, 2); // 调用特化的指针版本
}模板分离编译
什么是模板分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// a.h
template<class T>
T Add(const T& left, const T& right);
// a.cpp
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}
// main.cpp
#include"a.h"
int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}分析:

解决方法
将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。推荐使用这种。
模板定义的位置显式实例化。这种方法不实用,不推荐使用。
模板总结
优点
模板服用了代码,节省资源,更快的迭代开发。
增强了代码的灵活性。
缺点
模板会导致代码膨胀的问题。
出现模板编译错误时,错误信息会非常凌乱,不易定位。
相关文章:
【C++】30h速成C++从入门到精通(内存管理、函数/类模板)
C内存分布我们先来看一下下面的一段代码相关问题int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";char* pChar3 "abcd";int* ptr1 (int*)mal…...
自动驾驶决策概况
文章目录1. 第一章行为决策在自动驾驶系统架构中的位置2. 行为决策算法的种类2.1 基于规则的决策算法2.1.1 决策树2.1.2 有限状态机(FSM)2.1.3 基于本体论(Ontologies-based)2.2 基于统计的决策算法2.2.1 贝叶斯网络(B…...

金山轻维表项目进展自动通知
项目经理作为项目全局把控者,经常要和时间“赛跑”。需要实时了解到目前进展如何,跟进人是那些?哪些事项还未完成?项目整体会不会逾期?特别是在一些大型公司中,优秀的项目经理已经学会使用金山轻维表做项目…...

基于上下文分析的 Python 实时 API 推荐
原文来自微信公众号“编程语言Lab”:基于上下文分析的 Python 实时 API 推荐 搜索关注 “编程语言Lab”公众号(HW-PLLab)获取更多技术内容! 欢迎加入 编程语言社区 SIG-程序分析 参与交流讨论(加入方式:添加…...

软件测试-接口测试-代码实现接口测试
文章目录 1.request1.1 request介绍1.2 发送get请求1.3 发送set请求1.4 其他请求方式1.5 传递url参数1.6 响应内容解析1.7 cookie1.8 设置session2.集成UnitTest2.1 接口测试框架开发2.2 案例:使用TPShop项目完成对登录功能的接口测试1.request 1.1 request介绍 概念 基于py…...
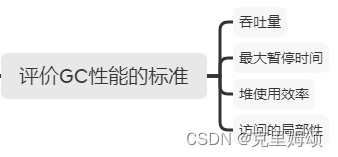
中村成洋《垃圾回收的算法与实现》PDF 读书笔记
观前提醒 为了能够锻炼自己,我会查阅大量外文不停的修改内容,少部分会提示成中文。 可能有误,请见谅 提示:若是觉得阅读困难,可以看如下内容 脚本之家可获取,若失效可私信浏览器的沙拉查词扩展…...

docker 网络模式
docker 网络模式主要分为四种,可以通过docker network ls 查看 ~$ docker network ls NETWORK ID NAME DRIVER SCOPE a51d97d72f10 bridge br…...
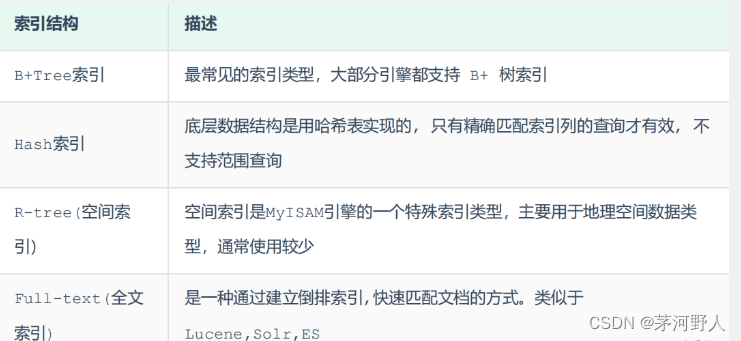
数据库开发(一文概括mysql基本知识)
Mysql 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 关系型数据库(Relational Database Management System:关系数据库管理系统)应用软件之一。mysql在问开发中,几乎必不可少,因为其他的可能是要收费的&#x…...
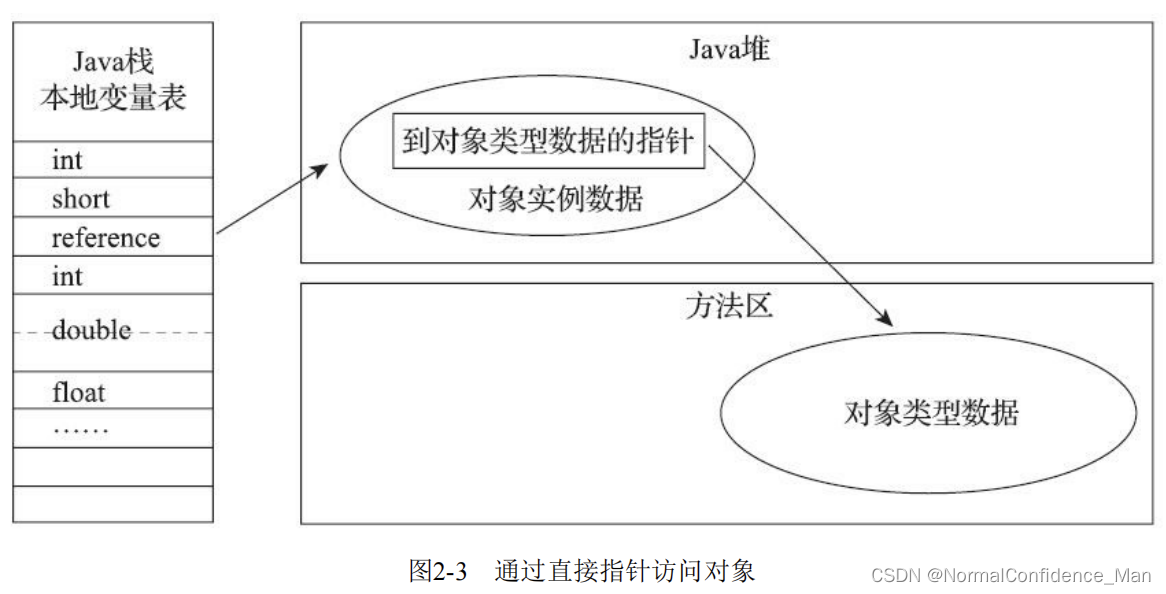
【JVM】详解Java内存区域和分配
这里写目录标题一、前言二、运行时数据分区2.1程序计数器(PC)2.2 Java虚拟机栈2.3 本地方法栈2.4 Java堆2.5 方法区2.5.1 运行时常量池2.6 直接内存三、HotSpot虚拟机对象探秘3.1 对象的创建3.2 对象的内存布局3.3 对象的访问定位一、前言 C/C需要自行回收和释放已经没用的对象…...
JAVA开发(史上最完整追本溯源JAVA历史、发展和学习)
(第二次世界大战1931-1945) 世界上最先进的技术往往是由于战争催生,在第二次世界大战中除了飞机,坦克和大炮的武器较量外,在隐秘战线的情报工作其实更为重要,在军队将领来往的电报中,为了防止军事情报的泄漏ÿ…...

Qt 防止程序退出
文章目录摘要QWidgetQML方法 1方法 2关键字: Qt、 eventFilter、 Close、 键盘、 任务管理器摘要 今天要聊得内容还是怎么防止别人关闭我的程序,之前都是在win下面,一般都是用过钩子连捕获键盘事件,完了吧对应的事件忽略&#x…...

【校验码 - 循环冗余校验码CRC】
水善利万物而不争,处众人之所恶,故几于道💦 目录 循环冗余校验码 1.多项式 2.CRC编码的组成 3.校验码的生成 4.例题: 循环冗余校验码 广泛地在网络通信及磁盘存储时采用。 1.多项式 在循环冗余校验(CRC)码中,无一例…...

【Rust】一文讲透Rust中的PartialEq和Eq
前言 本文将围绕对象:PartialEq和Eq,以及PartialOrd和Ord,即四个Rust中重点的Compare Trait进行讨论并解释其中的细节,内容涵盖理论以及代码实现。 在正式介绍PartialEq和Eq、以及PartialOrd和Ord之前,本文会首先介绍…...

Vulnhub靶场----9、DC-9
文章目录一、环境搭建二、渗透流程三、思路总结一、环境搭建 DC-9下载地址:https://download.vulnhub.com/dc/DC-9.zip kali:192.168.144.148 DC-9:192.168.144.158 二、渗透流程 1、信息收集nmap -T5 -A -p- -sV -sT 192.168.144.158思路&am…...
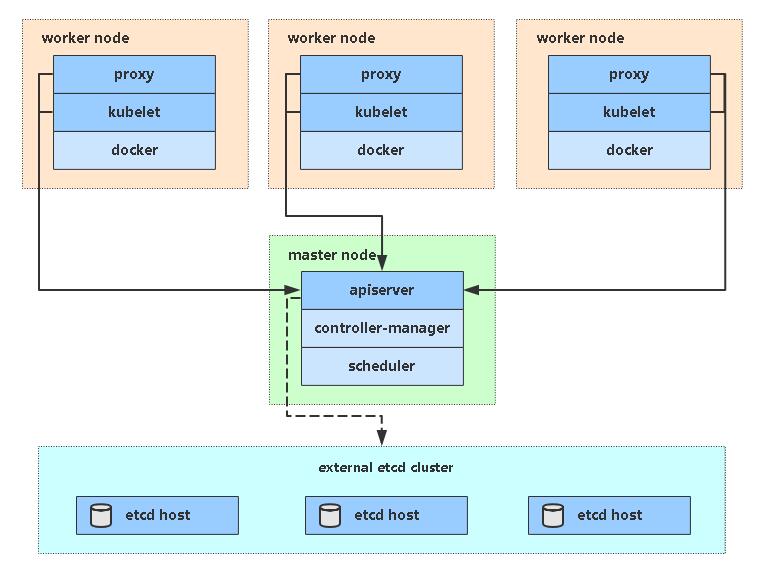
使用Containerd搭建K8s集群【v1.25】
[toc] 一、安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多集群中所有机器之间网络互通可以访问外网,需要拉取镜像禁止swap分区二、准备环境 角色IP…...
)
NMT - 构建双语概率词典(Probabilistic dictionaries)
文章目录一、安装依赖包mosesdecoder安装 mgiza二、数据预处理三、训练本文参考:How to train your Bicleaner https://github.com/bitextor/bicleaner/wiki/How-to-train-your-Bicleaner 一、安装依赖包 这个过程主要依赖于 mosesdecodermgiza mosesdecoder git…...
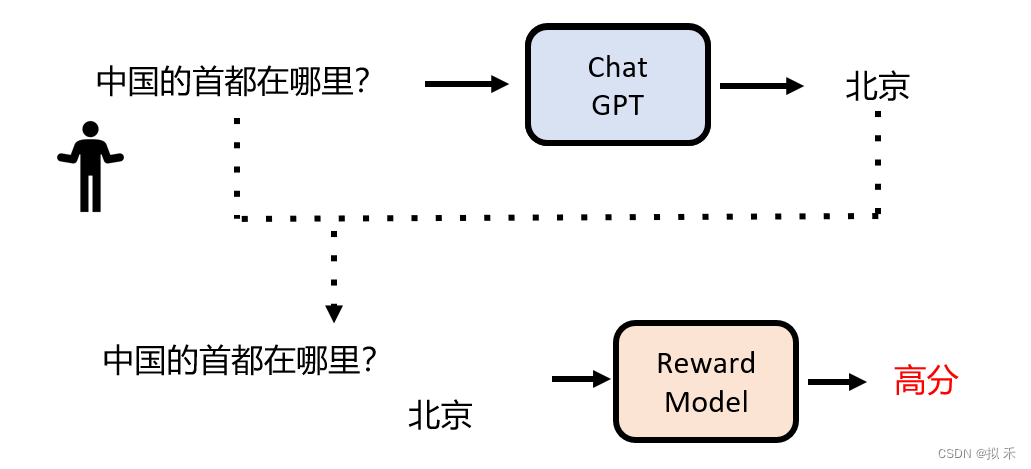
《ChatGPT是怎样炼成的》
ChatGPT 在全世界范围内风靡一时,我现在每天都会使用 ChatGPT 帮我回答几个问题,甚至有的时候在一天内我和它对话的时间比和正常人类对话还要多,因为它确实“法力无边,功能强大”。 ChatGPT 可以帮助我解读程序,做翻译…...
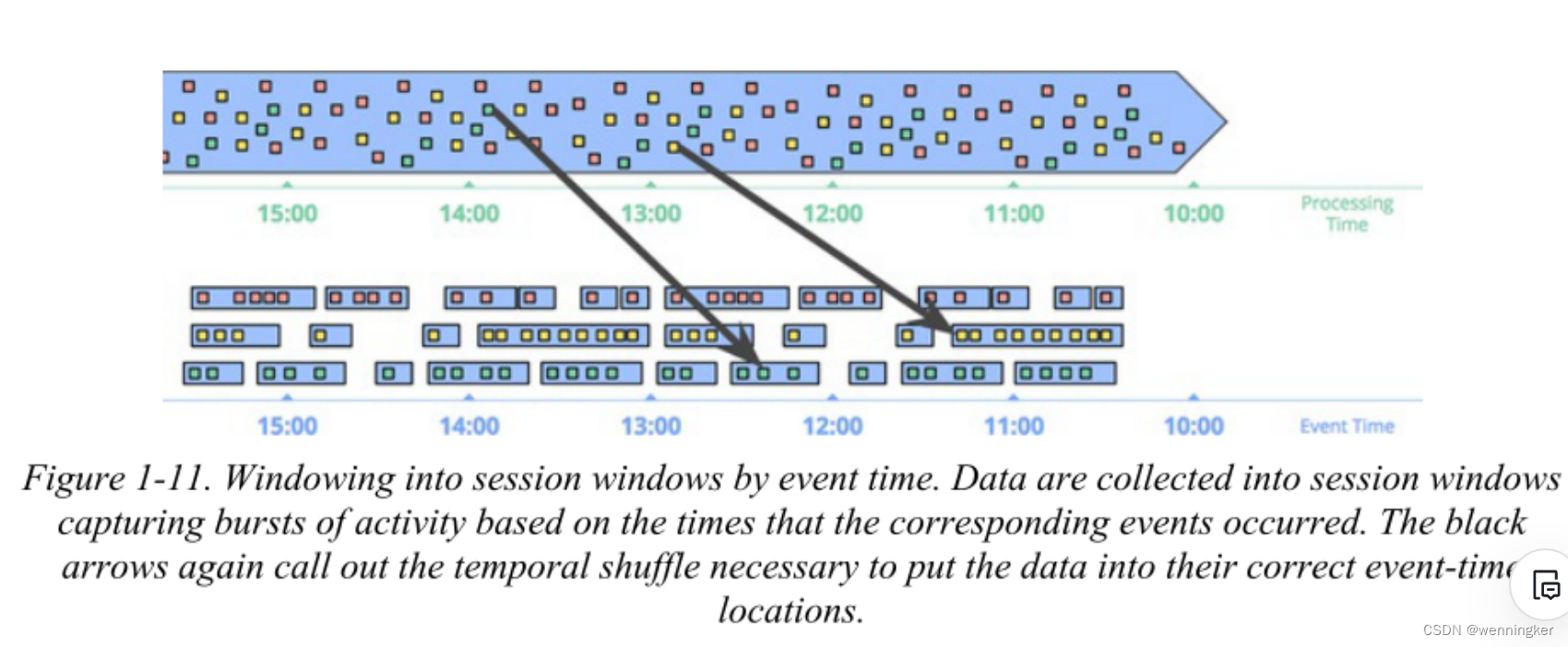
Streaming System是第一章翻译
GIthub链接,欢迎志同道合的小伙伴一起翻译 Chapter 1.Streaming101 如今,流数据处理在大数据中是非常重要的,其主要原因是: 企业渴望对他们的数据有更及时的了解,而转换到流处理是实现更低延迟的一个好方法…...
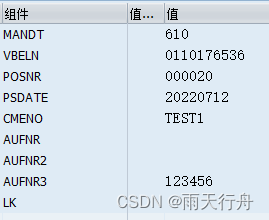
abap MODIFY常用语法解析
MODIFY 是既可以操作数据又可以操作内表的一个语法, 实现的逻辑都一样. 如果你内表或数据库中存在该行数据会对该行数据进行更新. 如果不存在,就会插入数据. , 1.如果it_tab是带有标题行的内表,是可以忽略FROM wa_tab工作区的 MODIFY it_tab .2.把工作区wa_tab中的数据更新…...

[媒体分流直播]媒体直播和传统直播的区别,以及媒体直播的特点
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 直播毋庸置疑已经融入到了我们生活的方方面面,小到才艺,游戏,大到政策的发布,许多企业和机构也越来越重视直播,那么一场活动怎…...

基于MCP的AI智能体:自动化与优化亚马逊DSP广告实战指南
1. 项目概述:用AI智能体管理亚马逊DSP广告如果你正在寻找一种更高效、更智能的方式来管理亚马逊需求方平台(Amazon DSP)的广告活动,那么这个项目可能就是为你准备的。作为一个在程序化广告领域摸爬滚打了十多年的从业者࿰…...

别再写循环了!ABAP SQL聚合函数COUNT/AVG/MAX实战指南,5分钟搞定数据统计
ABAP SQL聚合函数实战:告别低效循环,5分钟掌握高阶统计技巧 每次看到ABAP报表里那些嵌套三层的LOOP和SORT语句,我的血压就会悄悄升高。上周review同事代码时,发现一个统计物料库存的报表竟然用了三个嵌套循环——外层遍历工厂、中…...

别再算错了!等保2.0 2021版测评新规下,多系统/多机房得分计算保姆级教程
等保2.0 2021版多系统测评得分计算实战指南 当企业拥有多个机房或业务系统时,等保测评得分计算往往成为安全负责人最头疼的问题。2021版测评新规对多对象场景的计算方式进行了重要调整,这些变化直接影响最终得分和整改策略。本文将用真实案例拆解新旧计算…...

ATPG技术革新:从传统测试到单元感知与智能并行
1. 从“可靠的老黄牛”到“敏捷的赛马”:ATPG技术为何必须革新在芯片设计这个行当里干了十几年,Automatic Test Pattern Generation,也就是我们常说的ATPG,一直是个让人又爱又恨的角色。爱它,是因为它就像产线上那位最…...

CSS 容器查询完全指南
CSS 容器查询完全指南 引言 CSS 容器查询(Container Queries)是 CSS 规范中的一项革命性特性,它允许开发者根据容器的尺寸而非视口尺寸来应用样式。本文将深入探讨容器查询的各种用法和高级技巧。 基础概念回顾 容器查询 vs 媒体查询 特…...

如何快速掌握ComfyUI图像修复插件:终极完整使用指南
如何快速掌握ComfyUI图像修复插件:终极完整使用指南 【免费下载链接】comfyui-inpaint-nodes Nodes for better inpainting with ComfyUI: Fooocus inpaint model for SDXL, LaMa, MAT, and various other tools for pre-filling inpaint & outpaint areas. 项…...
)
从寄存器到库函数:手把手拆解STM32的RCC时钟树(以F103C8T6为例)
从寄存器到库函数:手把手拆解STM32的RCC时钟树(以F103C8T6为例) 在嵌入式开发领域,STM32系列微控制器因其出色的性能和丰富的外设资源而广受欢迎。然而,对于许多开发者来说,STM32的时钟系统(RCC…...

NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换
NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他播放器使用而烦恼吗?ncmdump解密工具让你轻松突破格式限制&…...

告别玄学调参:用Python+NumPy手把手复现MIMO信道SVD分解与注水算法
告别玄学调参:用PythonNumPy手把手复现MIMO信道SVD分解与注水算法 在无线通信领域,MIMO(多输入多输出)技术通过利用空间维度显著提升了系统容量和可靠性。然而,许多工程师在实际应用中常陷入"玄学调参"的困境…...
:比特的手术刀,镜像翻转与空间缝合)
【运算篇】算术与逻辑律令(3):比特的手术刀,镜像翻转与空间缝合
在 4-bit 的逻辑地牢里,如果说算术指令提供了“肌肉”,逻辑指令开启了“感官”,那么接下来我们要聊的,则是这台机器最细腻的形态手术。如果说 AND/OR 是在判定“存在”,那么 NOT 和移位指令(SHL/SHR&#x…...