pytorch03:transforms常见数据增强操作
目录
- 一、数据增强
- 二、transforms--Crop裁剪
- 2.1 transforms.CenterCrop
- 2.2 transforms.RandomCrop
- 2.3 RandomResizedCrop
- 2.4 FiveCrop和TenCrop
- 三、transforms—Flip翻转、旋转
- 3.1RandomHorizontalFlip和RandomVerticalFlip
- 3.2 RandomRotation
- 四、transforms —图像变换
- 4.1 transforms.Pad
- 4.2 transforms.ColorJitter
- 4.3 Grayscale和RandomGrayscale
- 4.4 RandomAffine
- 4.5 RandomErasing
- 五、transforms的操作
- 5.1 transforms.RandomChoice
- 5.2 transforms.RandomApply
- 5.3 transforms.RandomOrder
- 六、自定义transforms
- 6.1 自定义transforms要素
- 6.2 通过类实现多参数传入
- 6.3 椒盐噪声
- 6.4 自定义transforms代码实现
- 七、数据增强策略
- 数据增强代码实现
一、数据增强
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。如下是对一张图片常见的增强操作例如:旋转、裁剪、像素抖动。

二、transforms–Crop裁剪
2.1 transforms.CenterCrop
功能:从图像中心裁剪图片
• size:所需裁剪图片尺寸
2.2 transforms.RandomCrop
功能:从图片中随机裁剪出尺寸为size的图片

• size:所需裁剪图片尺寸
• padding:设置填充大小
当为a时,上下左右均填充a个像素,
当为(a, b)时,上下填充b个像素,左右填充a个像素,
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d
• pad_if_need:若图像小于设定size,则填充
• padding_mode:填充模式,有4种模式
1、constant:像素值由fill设定
2、edge:像素值由图像边缘像素决定
3、reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
4、symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
• fill:constant时,设置填充的像素值
2.3 RandomResizedCrop
功能:随机大小、长宽比裁剪图片

• size:所需裁剪图片尺寸
• scale:随机裁剪面积比例, 默认(0.08, 1)
• ratio:随机长宽比,默认(3/4, 4/3)
• interpolation:插值方法
PIL.Image.NEAREST
PIL.Image.BILINEAR
PIL.Image.BICUBIC
2.4 FiveCrop和TenCrop
功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片,TenCrop对这5张图片进行水平或者垂直镜像获得10张图片

• size:所需裁剪图片尺寸
• vertical_flip:是否垂直翻转
三、transforms—Flip翻转、旋转
3.1RandomHorizontalFlip和RandomVerticalFlip

功能:依概率水平(左右)或垂直(上下)翻转图片
• p:翻转概率
3.2 RandomRotation
功能:随机旋转图片


• degrees:旋转角度
当为a时,在(-a,a)之间选择旋转角度
当为(a, b)时,在(a, b)之间选择旋转角度
• resample:重采样方法
• expand:是否扩大图片,以保持原图
四、transforms —图像变换
4.1 transforms.Pad
功能:对图片边缘进行填充

• padding:设置填充大小
当为a时,上下左右均填充a个像素
当为(a, b)时,上下填充b个像素,左右填充a个像素
当为(a, b, c, d)时,左,上,右,下分别填充a, b, c, d
• padding_mode:填充模式,有4种模式,constant、edge、reflect和symmetric
• fill:constant时,设置填充的像素值,(R, G, B) or (Gray)
4.2 transforms.ColorJitter
功能:调整亮度、对比度、饱和度和色相

• brightness:亮度调整因子
当为a时,从[max(0, 1-a), 1+a]中随机选择
当为(a, b)时,从[a, b]中
• contrast:对比度参数,同brightness
• saturation:饱和度参数,同brightness
• hue:色相参数,当为a时,从[-a, a]中选择参数,注: 0<= a <= 0.5
当为(a, b)时,从[a, b]中选择参数,注:-0.5 <= a <= b <= 0.5
4.3 Grayscale和RandomGrayscale
功能:依概率将图片转换为灰度图

• num_ouput_channels:输出通道数只能设1或3
• p:概率值,图像被转换为灰度图的概率
4.4 RandomAffine
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转


• degrees:旋转角度设置
• translate:平移区间设置,如(a, b), a设置宽(width),b设置高(height)
图像在宽维度平移的区间为 -img_width * a < dx < img_width * a
• scale:缩放比例(以面积为单位)
• fill_color:填充颜色设置
4.5 RandomErasing
功能:对图像进行随机遮挡

• p:概率值,执行该操作的概率
• scale:遮挡区域的面积
• ratio:遮挡区域长宽比
• value:设置遮挡区域的像素值,(R, G, B) or (Gray)
五、transforms的操作
5.1 transforms.RandomChoice
功能:从一系列transforms方法中随机挑选一个
transforms.RandomChoice([transforms1, transforms2, transforms3])
5.2 transforms.RandomApply
功能:依据概率执行一组transforms操作
transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
5.3 transforms.RandomOrder
功能:对一组transforms操作打乱顺序
transforms.RandomOrder([transforms1, transforms2, transforms3])
六、自定义transforms
6.1 自定义transforms要素
1.仅接收一个参数,返回一个参数
2.注意上下游的输出与输入
当前transforms的输入是上一个transforms的输出,所以要保证数据类型匹配:

6.2 通过类实现多参数传入

在Python中,__call__是一个特殊的方法,用于使一个对象可以像函数一样被调用。如果一个类定义了__call__方法,那么实例化的对象就可以被当作函数一样调用,而调用的实际上是__call__方法。
class CallableClass:def __init__(self):print("Initializing the CallableClass")def __call__(self, *args, **kwargs):print("Calling the CallableClass with arguments:", args, kwargs)# 实例化对象
obj = CallableClass()# 调用对象,实际上调用了__call__方法
obj(1, 2, 3, keyword_arg="hello")上面的例子中,CallableClass定义了__call__方法,这意味着实例obj可以像函数一样被调用。当你调用obj(1, 2, 3, keyword_arg=“hello”)时,实际上是在调用obj.call(1, 2, 3, keyword_arg=“hello”)。
6.3 椒盐噪声
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点, 白点称为盐噪声,黑色为椒噪声
信噪比(Signal-Noise Rate, SNR)是衡量噪声的比例,图像中为图像像素的占比,从下图可以看出,信噪比越小,图片丢失的像素越多。

6.4 自定义transforms代码实现
class AddPepperNoise(object):"""增加椒盐噪声Args:snr (float): Signal Noise Rate 信噪比p (float): 概率值,依概率执行该操作Attributes:snr (float): 信噪比p (float): 操作执行的概率"""def __init__(self, snr, p=0.9):# 确保传入的snr和p是float类型assert isinstance(snr, float) and isinstance(p, float)self.snr = snrself.p = pdef __call__(self, img):"""对图像应用椒盐噪声操作。Args:img (PIL Image): PIL Image对象Returns:PIL Image: 处理后的PIL Image对象"""# 根据概率决定是否执行噪声操作if random.uniform(0, 1) < self.p:img_ = np.array(img).copy()h, w, c = img_.shapesignal_pct = self.snrnoise_pct = (1 - self.snr)# 生成噪声掩码,表示每个像素是原始图像、盐噪声还是椒噪声mask = np.random.choice((0, 1, 2), size=(h, w, 1),p=[signal_pct, noise_pct / 2., noise_pct / 2.])mask = np.repeat(mask, c, axis=2)# 根据噪声类型修改图像像素值img_[mask == 1] = 255 # 盐噪声img_[mask == 2] = 0 # 椒噪声# 将NumPy数组转换回PIL Image对象,并确保数据类型为uint8,颜色通道为RGBreturn Image.fromarray(img_.astype('uint8')).convert('RGB')else:return img

七、数据增强策略
原则:让训练集与测试集更接近可以使用下面这些方法
• 空间位置:平移
• 色彩:灰度图,色彩抖动
• 形状:仿射变换
• 上下文场景:遮挡,填充
例如我们训练集白猫比较多,可以改变白猫色彩,让白猫的颜色接近黑猫。

数据增强代码实现
要求:使用第四套RMB进行训练,要求能对第5套RMB识别正确。
我们只进行普通的图片处理训练好的模型,发现将第五套100元都识别成一元,因为第四套人民币的1元和第五套人民的100元颜色相近,所以会导致识别错误:

解决方法,将所有训练集颜色都进行灰度处理,代码修改如下:
train_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.RandomCrop(32, padding=4),transforms.RandomGrayscale(p=0.9), #图片灰度化transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),
])
修改后的预测结果如下:

训练完整代码如下:
# -*- coding: utf-8 -*-import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from lenet import LeNet
from my_dataset import RMBDataset
from common_tools import transform_invertdef set_seed(seed=1):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1# ============================ step 1/5 数据 ============================split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]train_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.RandomCrop(32, padding=4),transforms.RandomGrayscale(p=0.9),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),
])valid_transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),
])# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)# ============================ step 2/5 模型 ============================net = LeNet(classes=2)
net.initialize_weights()# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()for epoch in range(MAX_EPOCH):loss_mean = 0.correct = 0.total = 0.net.train()for i, data in enumerate(train_loader):# forwardinputs, labels = dataoutputs = net(inputs)# backwardoptimizer.zero_grad()loss = criterion(outputs, labels)loss.backward()# update weightsoptimizer.step()# 统计分类情况_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).squeeze().sum().numpy()# 打印训练信息loss_mean += loss.item()train_curve.append(loss.item())if (i+1) % log_interval == 0:loss_mean = loss_mean / log_intervalprint("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))loss_mean = 0.scheduler.step() # 更新学习率# validate the modelif (epoch+1) % val_interval == 0:correct_val = 0.total_val = 0.loss_val = 0.net.eval()with torch.no_grad():for j, data in enumerate(valid_loader):inputs, labels = dataoutputs = net(inputs)loss = criterion(outputs, labels)_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).squeeze().sum().numpy()loss_val += loss.item()valid_curve.append(loss_val)print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))train_x = range(len(train_curve))
train_y = train_curvetrain_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curveplt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()# ============================ inference ============================BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)for i, data in enumerate(valid_loader):# forwardinputs, labels = dataoutputs = net(inputs)_, predicted = torch.max(outputs.data, 1)rmb = 1 if predicted.numpy()[0] == 0 else 100img_tensor = inputs[0, ...] # C H Wimg = transform_invert(img_tensor, train_transform)plt.imshow(img)plt.title("LeNet got {} Yuan".format(rmb))plt.show()plt.pause(0.5)plt.close()
相关文章:
pytorch03:transforms常见数据增强操作
目录 一、数据增强二、transforms--Crop裁剪2.1 transforms.CenterCrop2.2 transforms.RandomCrop2.3 RandomResizedCrop2.4 FiveCrop和TenCrop 三、transforms—Flip翻转、旋转3.1RandomHorizontalFlip和RandomVerticalFlip3.2 RandomRotation 四、transforms —图像变换4.1 t…...

blob文件流前端显示pdf
首先请求需要修改 responseType: ‘blob’, 需要修改 请求头 {responseType: blob,url: url,method: get,}三种方法: 1.直接处理,在新页面打开 const blob new Blob([data],{ type:application/pdf }) let url window.URL.createObjectURL(blob) wi…...

Android 接入第三方数数科技平台
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数数科技平台是什么?二、使用步骤1.集成SDK2. 初始化3. 发送事件和设置账号id4. 验证发送事件是否成功 小结 前言 一个成熟的App必然不可缺少对…...

LVM和磁盘配额
一:LVM概述: LVM 是 Logical Volume Manager 的简称,译为中文就是逻辑卷管理。 能够在保持现有数据不变的情况下,动态调整磁盘容量,从而提高磁盘管理的灵活性 /boot 分区用于存放引导文件,不能基于LVM创建…...
uni-app uni-app内置组件
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...

C语言——格式说明符前面加修饰符
在C语言中,格式说明符前面可以添加一些修饰符来控制输出或输入的格式,主要包括宽度、精度、左对齐标志和前缀填充字符等。 1. 宽度(Width) %[width]type:这里的width是一个非负整数,表示输出字段的最小宽度…...

实验室(检验科)信息系统LIS源码,客户端:WPF+Windows Forms
lis系统源码,医学检验信息系统源码 LIS系统(Laboratory Information System)即实验室(检验科)信息系统,它将检验仪器付出的检验数据与相关信息接入计算机网络系统中,让患者、实验室、临床科室、…...
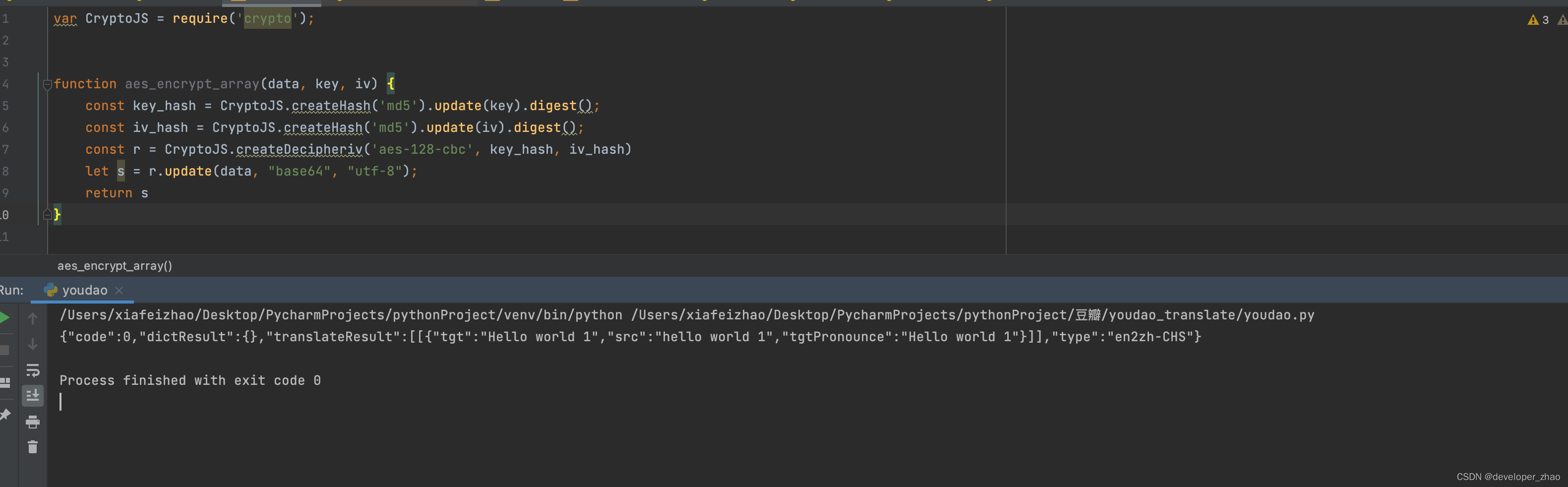
有道翻译web端 爬虫, js
以下内容写于2023-12-28, 原链接为:https://fanyi.youdao.com/index.html#/ 1 在输入框内输入hello world进行翻译,通过检查发出的网络请求可以看到翻译文字的http接口应该是: 2 复制下链接最后的路径,去js文件中搜索下: 可以看到这里是定义了一个函数B来做文字的翻译接口函数…...
uni-app API接口扩展组件(uni-ui)
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...

信息化和数字化的本质区别是什么?
信息化和数字化是两个概念的区别 它们有什么区别和联系呢?信息化:“业务数据化”,先让业务流程能被数据记录下来。信息化“业务数据化”。数字化:“数据业务化”,用已累积的业务数据去反哺优化业务流程。数字化“数据…...

发表《Nature》!美国研究团队发布可编程逻辑量子处理器
(图片来源:网络) 近期,美国研究团队开发了一款可编程的逻辑量子处理器,并展示了可靠且可扩展的量子计算所需的关键要素,该成果已发表于《Nature》期刊(doi:10.1038/s41586-023-06…...
CISSP 第1章:实现安全治理的原则和策略
作者:nothinghappend 链接:https://zhuanlan.zhihu.com/p/669881930 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 CIA CIA 三性: 机密性:和数据泄露有关。完整性…...
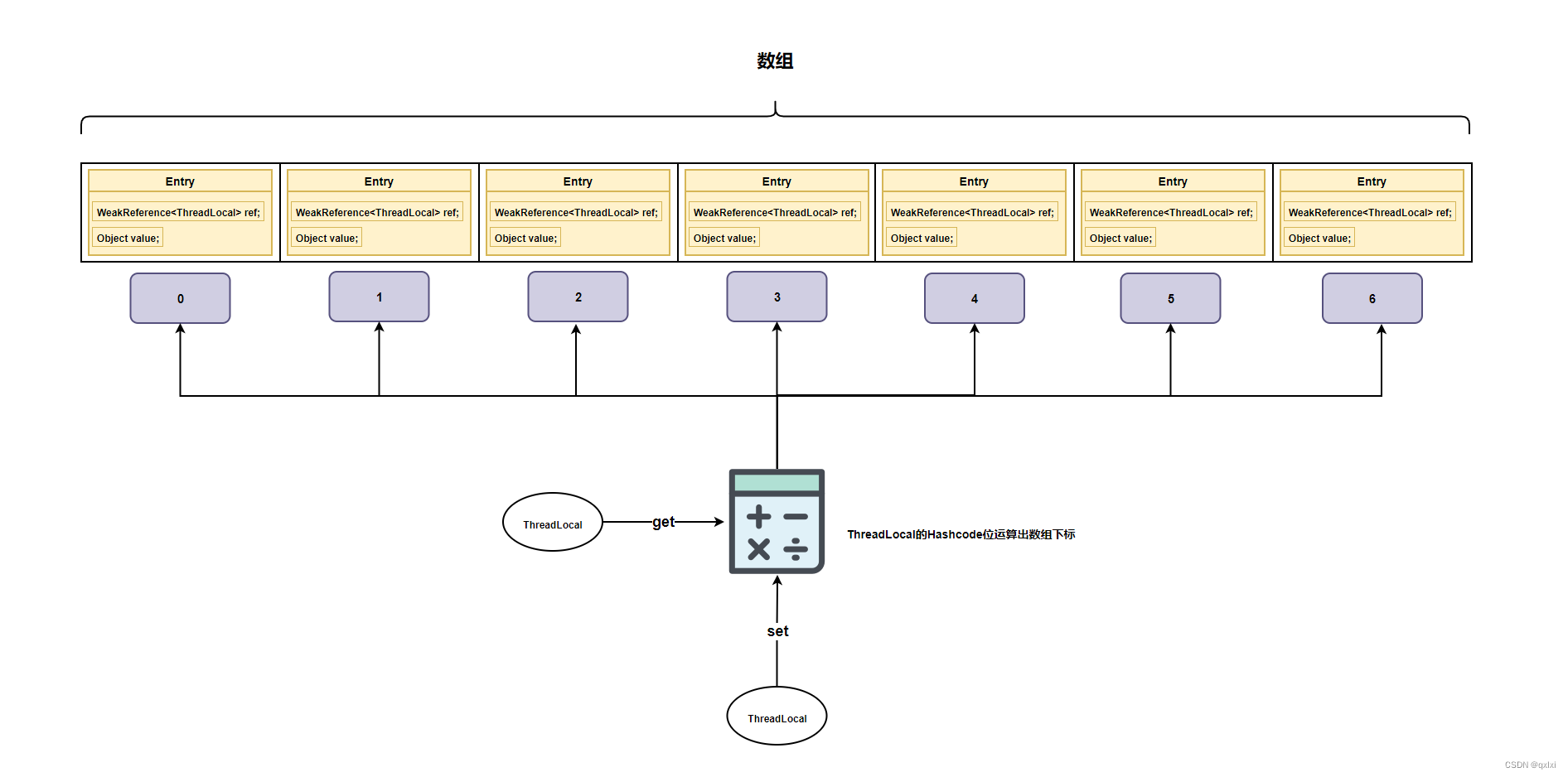
【并发设计模式】聊聊线程本地存储模式如何实现的线程安全
前面两篇文章,通过两阶段终止的模式进行优雅关闭线程,利用数据不变性的方式保证数据安全,以及基于COW的模式,保证读数据的安全。本篇我们来简述下如果利用线程本地存储的方式保证线程安全。 首先一个大前提就是并发问题ÿ…...

边缘计算网关:重新定义物联网数据处理
随着物联网(IoT)设备的爆炸式增长,数据处理和分析的需求也在迅速增加。传统的数据处理方式,将所有数据传输到中心服务器进行处理,不仅增加了网络负担,还可能导致数据延迟和安全问题。因此,边缘计…...

Linux之下载安装
rpm包管理 rpm介绍 rpm用于互联网下载包的打包及安装工具,他包含在某些linux分发版本中。他生成具有.rpm扩展名的文件。RPM是RedHat Package Manager(RedHat软件包管理工具)的缩写,类似windows的steup.exe。 rpm包的查询指令 查询已经安装…...
【HarmonyOS开发】案例-记账本开发
OpenHarmony最近一段时间,简直火的一塌糊度,学习OpenHarmony相关的技术栈也有一段时间了,做个记账本小应用,将所学知识点融合记录一下。 1、记账本涉及知识点 基础组件(Button、Select、Text、Span、Divider、Image&am…...
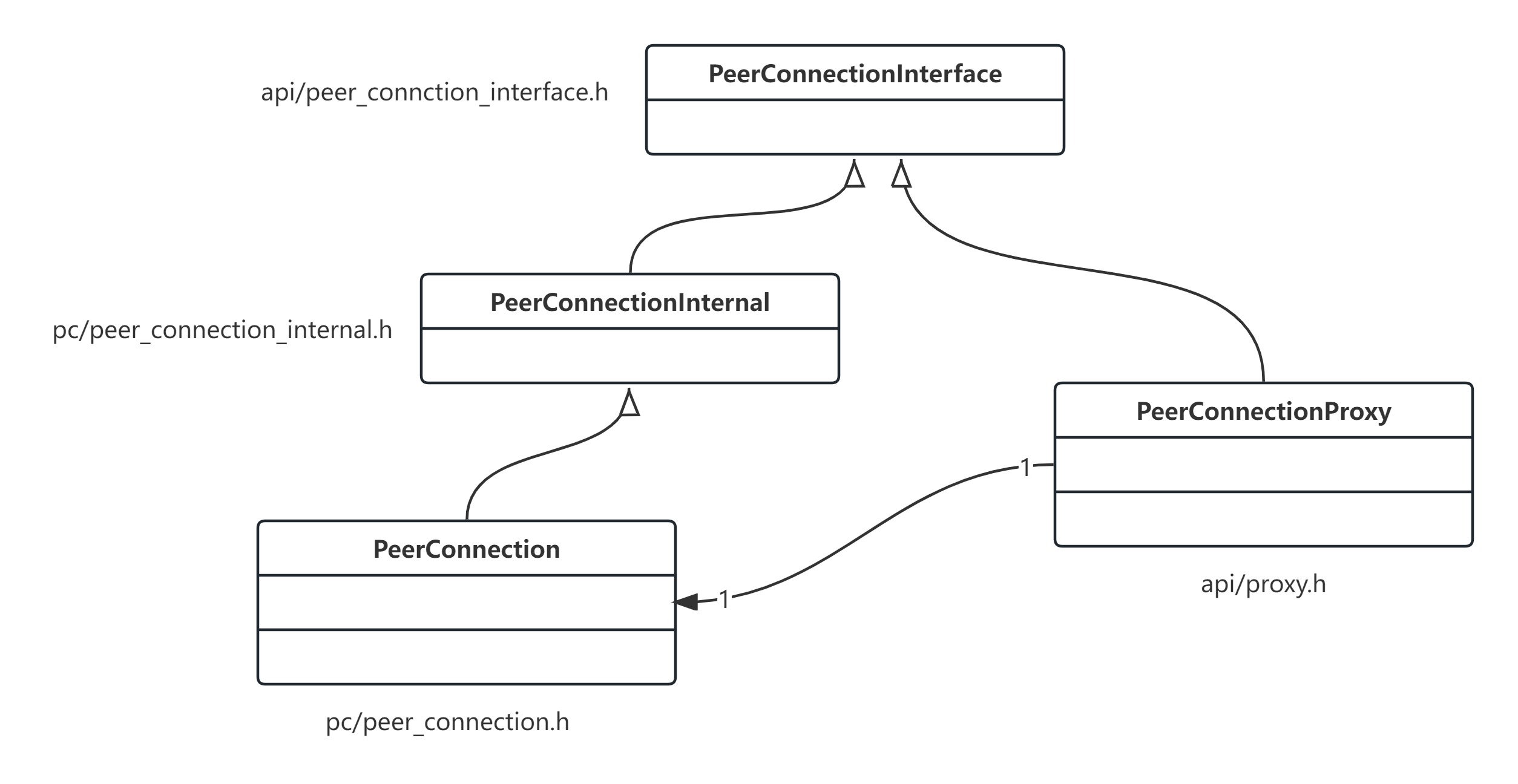
webrtc中的接口代理框架
文章目录 接口代理框架Proxy体系类结构导出接口 webrtc的实际运用PeerConnectionFactoyPeerConnection使用 接口代理框架 webrtc体系庞大,模块化极好,大多数模块都可以独立使用。模块提供接口,外部代码通过接口来使用模块功能。 在webrtc中通…...

【AIGC-图片生成视频系列-4】DreamTuner:单张图像足以进行主题驱动生成
目录 一. 项目概述 问题: 解决: 二. 方法详解 a) 整体结构 b) 自主题注意力 三. 文本控制的动漫角色驱动图像生成的结果 四. 文本控制的自然图像驱动图像生成的结果 五. 姿势控制角色驱动图像生成的结果 2023年的最后一天,发个文记录…...
Jupyter Notebook的10个常用扩展介绍
Jupyter Notebook(前身为IPython Notebook)是一种开源的交互式计算和数据可视化的工具,广泛用于数据科学、机器学习、科学研究和教育等领域。它提供了一个基于Web的界面,允许用户创建和共享文档,这些文档包含实时代码、…...
uniapp项目如何引用安卓原生aar插件(避坑指南三)
官方文档说明:uni小程序SDK 【彩带- 避坑知识点】 如果引用原生aar插件,都配置好之后,云打包,报不包含此插件,除了检查以下步骤流程外,还要检查一下是否上打包的原生插件aar流程有问题。 1.第一步在uniapp项…...

基于ESP32-S3与CircuitPython的NASA小行星追踪器项目实践
1. 项目概述:一个会“说话”的太空瞭望台如果你对头顶那片星空既充满好奇又带有一丝敬畏,想知道是否有“天外来客”正悄无声息地接近我们,那么这个项目就是为你准备的。这不是一个简单的数据看板,而是一个亲手搭建的、能实时“对话…...

【DeepSeek Chat功能测试全链路指南】:20年AI工程师亲测的7大核心场景验证法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试的底层逻辑与验证哲学 DeepSeek Chat 的功能测试并非仅面向接口响应的“黑盒点击”,而是建立在模型行为可解释性、推理路径可追溯性与系统边界可控性三重基石之上的验…...

掌握6个采购管控节点,企业采购成本可直接降低15%—30%
在企业经营管理中,采购成本是企业综合成本的核心组成部分,原材料、耗材、设备、服务等采购支出,直接决定企业利润空间。据行业数据统计,多数中小企业采购环节存在流程漏洞、管控松散、资源浪费等问题,无效成本占比高达…...

基于Council框架的多智能体协作:构建专家委员会式AI决策系统
1. 项目概述:一个智能化的团队决策引擎最近在开源社区里看到一个挺有意思的项目,叫“Cat-tj/council-tj”。这个名字乍一看有点抽象,但拆开来看,“Council”在英文里是“议会”或“委员会”的意思,而“tj”通常是“Tav…...

USB Type-C接口技术解析与工程实践
1. USB接口技术演进与Type-C核心优势USB Type-C接口自2014年发布以来,凭借其革命性的设计理念迅速成为移动设备的主流接口标准。作为从业十余年的硬件工程师,我见证了从USB 2.0 OTG到Type-C的完整迁移过程。与传统micro-A/B接口相比,Type-C最…...

别再格式化U盘了!Ubuntu 22.04 LTS下永久解决exFAT支持问题的完整配置指南
永久解决Ubuntu 22.04 LTS的exFAT兼容性问题:从原理到实践 当你在Ubuntu系统中插入一个exFAT格式的U盘或移动硬盘时,那个令人沮丧的错误提示可能已经出现过多次:"unknown filesystem type exfat"。这不是偶然现象,而是源…...

Simulink仿真PMSM时,那个神秘的‘4’和‘30/π’到底怎么来的?手把手带你算清楚
Simulink仿真PMSM时关键参数转换原理与实战解析 在永磁同步电机(PMSM)的Simulink仿真过程中,工程师们常常会遇到几个看似"神秘"的增益系数——特别是30/π和4这两个数值。这些参数并非随意设置,而是深植于电机物理本质与单位系统转换的数学表达…...

LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南
LinkSwift:九大网盘直链下载助手的终极技术解析与实践指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...
Binary Linear Equation Group)
7th grade math (2026.05.15)Binary Linear Equation Group
Binary Linear Equation Group 七年纪(下)数学第十章《二元一次方程组》作业评价参考答案-zwf 错误题型分析...

Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件
Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为无法编辑游戏音频文件而烦恼…...