C++初阶------------------入门C++
作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言、C++和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
C++入门引入
- **作者前言**
- 命名空间(namespace)
- ::
- 命名空间里面嵌套命名空间
- 命名空间的合并
- 第一个c++代码
- 缺省参数
- 函数重载
- 为啥c++支持函数重载,而C语言不行
- 引用
- 引用的好处
- 传参
- 返回值
- 常引用
- 指针和引用的区别
- 内联函数
- auto
- 范围的for循环
- 指针空值nullptr
命名空间(namespace)
在我们学习C语言的过程中,如果我们命名一些和库函数名字相同的变量或者函数,VS编译器就会报错,怎么解决这个问题呢?C++语言就推出了一个关键字
namespace
这个关键字的作用就是解决命名冲突的
未使用关键字:
#include<stdio.h>
#include<stdlib.h>
int rand = 0;
int main()
{printf("%d", rand);return 0;
}
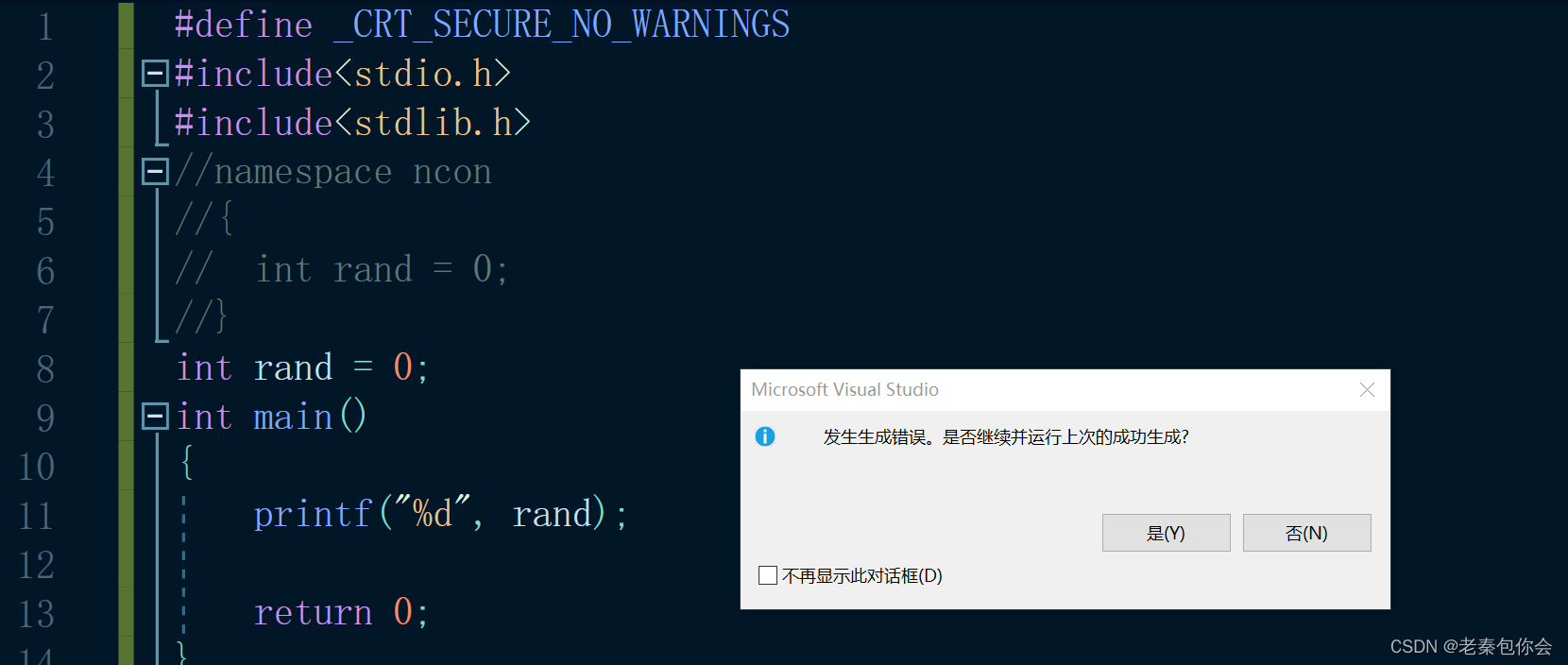
是会报错的,因为命名和库函数rand冲突了,我们在后面写的代码越多,就越容易命名冲突,
使用关键字:
#include<stdio.h>
#include<stdlib.h>
namespace ncon
{int rand = 0;
}
int main()
{printf("%d", ncon::rand);return 0;
}

::
这个符号叫域作用限定符
就是告诉VS编译器rand这个变量要在ncon命名的空间里面找,否则是找不到这个rand的
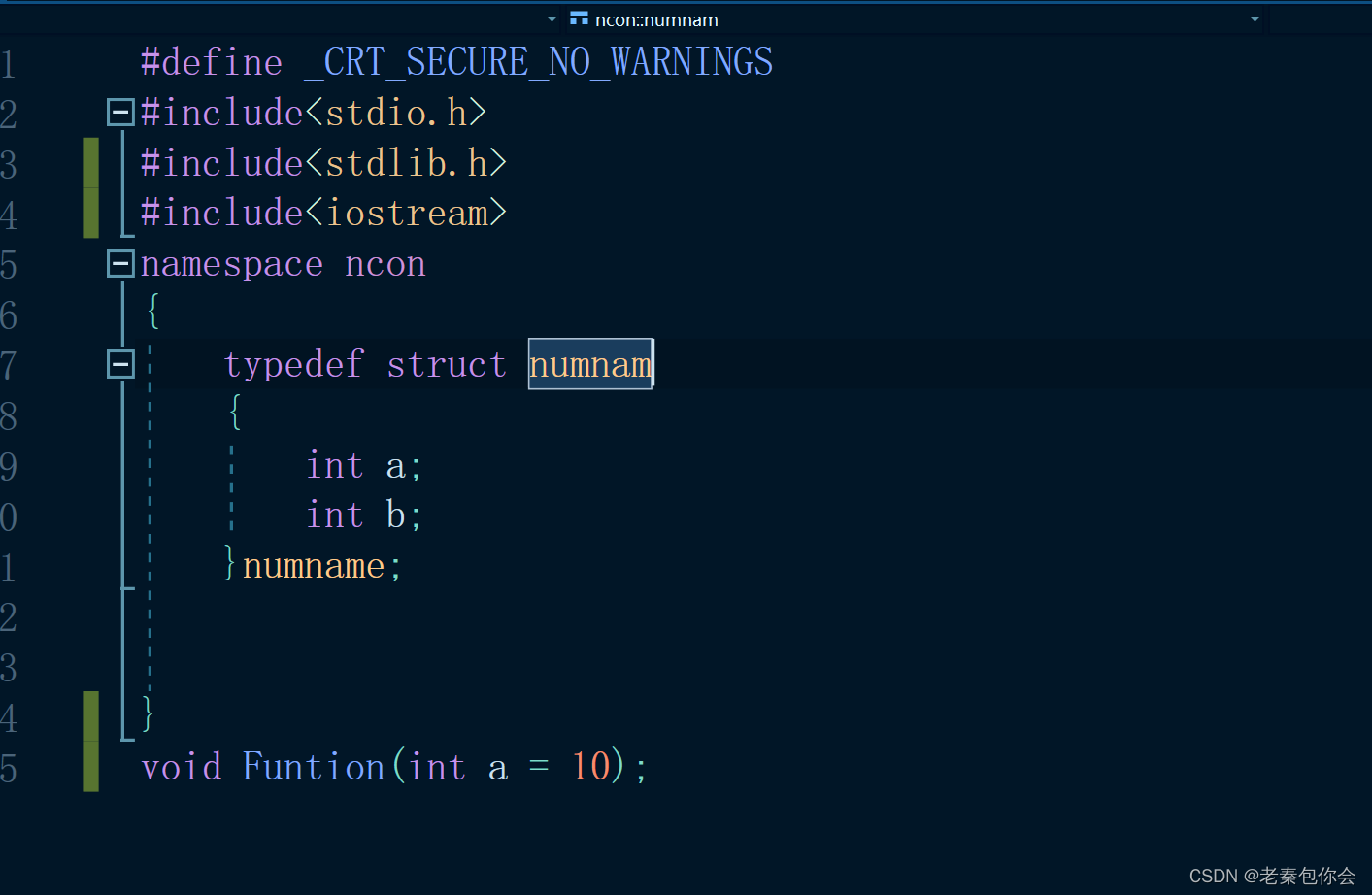
在命名空间里面可以定义函数、结构体、变量、枚举…等,
#include<stdio.h>
#include<stdlib.h>
namespace ncon
{int rand = 0;int Add(int a, int b){return a + b;}typedef struct numnam{int a;int b;}numname;
}
int main()
{printf("%d ", ncon::rand);int count = ncon::Add(1, 2);printf("%d ", count);struct ncon::numnam num = { 10,20 };printf("%d %d", num.a, num.b);return 0;
}
注意一下,结构体的写法是struct关键字在 最前面
命名空间里面嵌套命名空间
#include<stdio.h>
#include<stdlib.h>
namespace ncon
{namespace con{int nums = 10;}
}
int main()
{printf("%d ",ncon::con::nums);return 0;
}
命名空间可以嵌套命名空间,无限套娃
命名空间的合并
我们在一个源文件中可以多个位置命名空间相同的名字,是不会冲突的,会合并成一个命名空间
头文件:
#include<stdio.h>
#include<stdlib.h>
namespace ncon
{typedef struct numnam{int a;int b;}numname;
}
目标文件.c
#include"day1_1.h"
using namespace ncon;
namespace ncon
{int Add(int a, int b){return a + b;}
}
int main()
{int count = Add(1, 2);printf("%d ", count);struct ncon::numnam num = { 10,20 };printf("%d %d ", num.a, num.b);return 0;
}
有人就会发现下面这句代码
using namespace ncon;
这句代码想表达的意思就是
这行代码是C++中的语法,意思是引入命名空间 ncon 中的所有内容,使得在代码中可以直接使用该命名空间中的成员而不需要加上前缀
注意:这种方式不提倡,特别是在项目里会造成不必要的麻烦,所以日常练习可以展开
std:是C++官方库定义的命名空间
但是有时候真的很麻烦,会写很多不必要的前缀
所以我们可以指定展开
using std::cout;
using std::endl;
第一个c++代码
#include<iostream>
int main()
{std::cout << "hello world";printf("hello world");return 0;
}
<< : 流插入
如果要写入一些标识符,如\n
#include<iostream>
int main()
{std::cout << "hello world\n" << "hello " << "11111 " << "\n";printf("hello world");return 0;
}
可以写多个 << 进行拼接
但是一般不会这样写,会写成是std::endl
#include<iostream>
int main()
{std::cout << "hello world" << std::endl << "hello " << "11111 " << std::endl;printf("hello world");return 0;
}
<< :流提取
#include<iostream>
using std::cout;
using std::endl;
using std::cin;int main()
{int a = 10;int b = 20;cin >> a >> b;cout << a << endl << b;return 0;
}

std:: cin :输入
std::cout : 输出
缺省参数
我们知道在C语言中,函数的有参数就必须传参,不传参就会报错,为了解决这个问题,c++就有了可以拥有默认参数的函数
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
namespace ncon
{void Func(int a = 10){cout << a << endl;}void Func1(int a = 10, int b = 20, int c = 100){cout << a << endl;cout << b << endl;cout << c << endl;}
}
using namespace ncon;
int main()
{ncon::Func();ncon::Func(30);Func1();Func1(100);Func1(1,1,1);return 0;需要注意的是缺省值只能从右往左给,必须是连续给
还有一些是半缺省的函数
void Func(int a, int b = 10, int c = 20){cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;}
半缺省参数必须从右往左依次来给出,不能间隔着给
声明和定义不能同时给参数,只能在声明的时候给。这个是一个默认规定
在头文件中
缺省值必须是常量或者全局变量
函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
//参数类型不同
int Add(int a, int b)
{return a + b;
}
double Add(double a, double b)
{return a + b;
}
//参数个数不同
void Fun()
{cout << "Fun()" << endl;
}
void Fun(int a)
{cout << "Fun(int a)" << endl;
}
// 参数的顺序不同
void f(int a, double b)
{cout << a << endl;cout << b << endl;
}
void f(double b,int a)
{cout << a << endl;cout << b << endl;
}
int main()
{Add(1, 2);Add(1.1, 2.2);Fun();Fun(6);f(1, 2.2);f(2.2, 6);return 0;
}参数类型不同
参数个数不同
参数的顺序不同
为啥c++支持函数重载,而C语言不行
我们前面学习过C语言的编译链接,
第一步是预处理 :主要进行头文件的展开、宏替换、条件编译(#define 、 #if #endif)以及去掉注释等
生成.i文件
第二步编译:生成汇编代码(主要)或者语法错误

生成.s文件
第三步 汇编:转换成二进制的机器码
生成.o文件(Linux环境下) (在windows是obj文件)
第四步 链接: 合并到一起,链接一些没有确定函数地址、符号表的合并和重定义
C语言不能函数重载的原因:,因为C语言在链接的时候就是使用函数名去找(C语言不存在同名函数),而c++不能使用函数名去找
objdump -S test1c#test1c是一个.out文件
在Linux中C语言函数的调用是通过函数名去找对应的函数找到对应的地址

而在c++ 中
g++ test1.c -o test1cppobjdump -S test1cpp

为啥这里的会这么奇怪,这个函数调用的名字 是由Linux的函数名修饰规则决定的,
_Z3Adddd
写法为:
_Z + 函数名的字符个数 + 函数名 + 每个参数的第一个字符(int a 就取i)
通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修
饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。
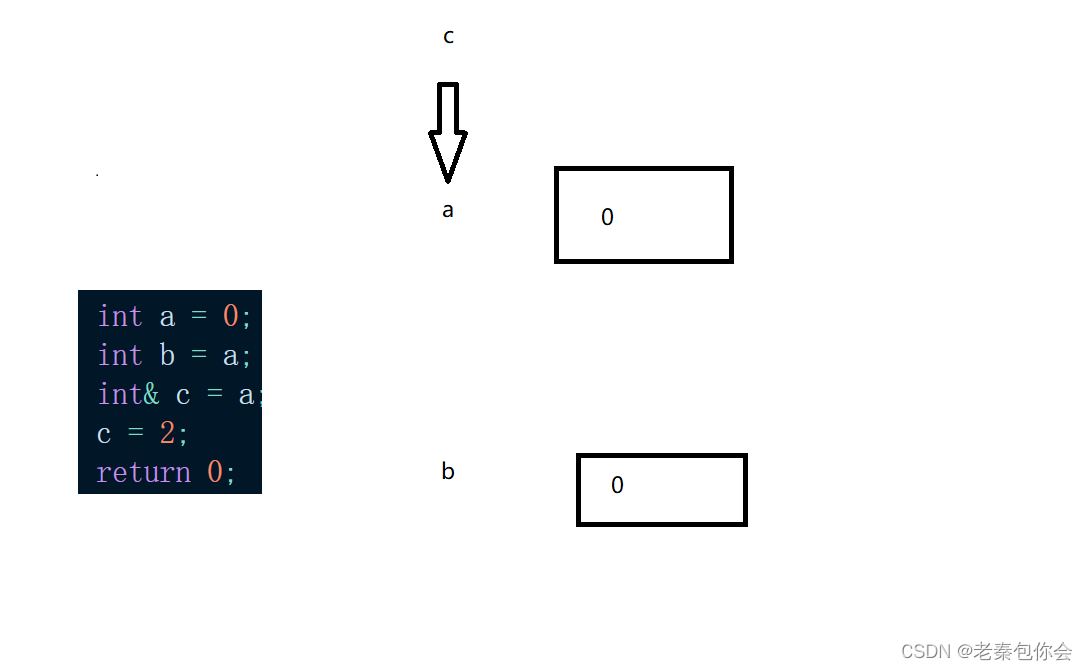
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
int main()
{int a = 0;int b = a;int& c = a;c = 2;return 0;
}int& c = a;//引用a
int& :引用类型
引用我们可以看作是取别名,改变c或者改变a 都会改变值,而b是一个变量,存储a的值,改变a或者b都不会改变对方

引用的好处
传参
前面我们学习过C语言如果要改变变量的值,要传地址
C语言版:
int exchang(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}
c++版:
int exchang(int& left, int& right)
{int temp = left;left = right;right = temp;return left;
}
引用的注意:
- 引用的时候必须初始化
- 引用的指向是唯一的,指定了就不能更改,所以说引用和指针是不能相互取代的
- 一个对象可以有多个引用,但是一个引用不能拥有多个对象
- 引用参数比直接传参的效率要高,引用参数和传地址参数的效率相似
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直
接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效
率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
#include<iostream>
#include<time.h>
using std::cout;
using std::endl;
using std::cin;
void Fun1(int& a)
{}
void Fun(int a)
{}
int main()
{int a = 12;int b = a;int i = 0;int begin1 = clock();for(i = 0; i < 1000000; i++)Fun1(a);int end1 = clock();int begin2 = clock();for (i = 0; i < 1000000; i++)Fun(a);int end2 = clock();cout << end1 - begin1 << endl;cout << end2 - begin2 << endl;return 0;
}

返回值
在C语言中我们返回一个函数的值的时候,不是返回这个变量
int exchang(int a, int b)
{int temp = a;a = *b;b = temp;return a;
}
我们知道函数栈帧的创建和销毁,知道返回值是存在寄存器里面返回的
而在c++中
int& exchang(int left, int right)
{int temp = left;left = right;right = temp;return left;
}
返回的是left的引用,因为left在函数结束的时候就销毁了,所以返回的值是随机值,这样写是错误的写法,前面我们学习过递归的实现,空间是可以重复利用的,
#include<iostream>
#include<time.h>
using std::cout;
using std::endl;
using std::cin;
int& Fun(int a)
{int c = a;c++;return c;
}
int main()
{int& num1 = Fun(6);cout << num1 << endl;cout << num1 << endl;Fun(1000);cout << num1 << endl;return 0;
}

这个代码可以看出来,num1引用的是c的原来的地址,函数结束,c销毁,但是那块内存还是存在,每次再调用,就会进行重复利用这块空间
正确的写法:
使用静态变量
前面我们知道如果使用静态变量的话,在静态区创建,而不是在栈区创建,这样就可以在函数销毁的时候静态变量不进行空间的释放
#include<iostream>
#include<time.h>
using std::cout;
using std::endl;
using std::cin;
int& Fun(int a)
{static int c = a;c++;return c;
}
int main()
{int& num1 = Fun(6);cout << num1 << endl;cout << num1 << endl;Fun(1000);cout << num1 << endl;return 0;
}

静态变量只初始化一次
某些场景
#include<iostream>
#include<time.h>
#include<assert.h>
using std::cout;
using std::endl;
using std::cin;
typedef struct Seqlist
{int a[100];int size;
}SL;
void SLModify(SL *ps, int pos, int x)
{assert(ps);assert(ps->size > pos);ps->a[pos] = x;
}int& SLModify(SL* ps, int pos)
{assert(ps);assert(ps->size > pos);return ps->a[pos];
}int main()
{SL lis = { {0},100 };int i = 0;for (i = 0; i < lis.size; i++){SLModify(&lis, i)++;}return 0;
}
这里创建一个顺序表,如果要进行顺序表的每个元素进行加1,有两种方法,要么传地址,要么引用出来
常引用
这里介绍一下
const int a = 10;
这个 在c++中是常量,在C语言中是常变量
#include<iostream>
#include<time.h>
#include<assert.h>
using std::cout;
using std::endl;
using std::cin;int main()
{//引用权限不能放大const int a = 10;//int& b = a;错误的const int& b = a;//权限可以缩小int c = 20;const int& d = c;const int& f = 10;return 0;
}
在常数中,如果对常数进行引用,就不会随便的放大权限,常数不能更改,所以对应引用也不能更改,
常性
当我们如果使用使用不同的引用类型去引用一些不同类型的变量
如
int i = 10;
double j = i;
const double& rj = i;
如果是使用 double&就会报错,为啥? 因为我们在使用不同类型进行接收的时候,i会产生一个临时变量,(类型转变才会产生临时变量)并且这个临时变量具有常性,需要用const的变量进行接收。
指针和引用的区别
引用:
- 语法上,没有开辟空间,在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
- 引用比指针使用起来相对更安全
- 没有NULL引用,但有NULL指针
- 有多级指针,但是没有多级引用
- . 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节)
#include<iostream>
#include<time.h>
#include<assert.h>
using std::cout;
using std::endl;
using std::cin;int main()
{int c = 20;const int& d = c;cout << sizeof(d);return 0;
}

6. 指针语法上,开辟了空间,在底层实现上实际也是有空间的
7. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
两者共同点:
1.引用的底层是汇编实现的
引用表面好像是传值,其本质也是传地址,只是这个工作有编
译器来做
内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调
用建立栈帧的开销,内联函数提升程序运行的效率。
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
int Add(int a, int b)
{return a + b;
}
int main()
{Add(1, 2);return 0;
}
这里是没有inline修饰,需要创建函数栈帧


使用inline修饰
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
inline int Add(int a, int b)
{int c = a + b;return c;
}
int main()
{Add(1, 2);return 0;
}未显示展开

要想看到展开我们需要以下操作

内联函数 优点:
- 可以调试
- 效率高,会展开
- 不用创建栈帧,提高效率
缺点:
不适合于大型的函数,每次调用inline修饰过的函数,就会展开一次,如果函数有100行,调用10000次,合计就要运行100 * 10000行,没有inline修饰的函数,每调用一次,就会找到相同的函数栈帧进行调用,总次数就是 100(函数的行数) + 10000(反汇编的call),所以inline修饰大型函数就会影响可执行程序的大小
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。(简单的理解,看编译器的心情来决定展不展开)
需要注意的是,如果在其他cpp文件使用inline修饰函数,再到头文件声明,在其他cpp文件使用这个函数就会报错,因为使用inline修饰的函数在链接时不会生成符号表。这是因为inline函数在编译时会被直接插入到调用它的地方,而不会产生独立的函数代码。
day1_1.cpp
#include"day1_1.h"
int main()
{fun(10);return 0;
}
day1_2.cpp
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
inline void fun(int a)
{cout << a << endl;
}
day_1.h
#include<iostream>
using std::cout;
using std::endl;
using std::cin;inline void fun(int a);

所以我们使用inline修饰函数,在对当前cpp文件或者在头文件定义和声明就行了
auto
auto关键字可以用于自动推导变量的类型,让编译器根据变量的初始化表达式推导出其类型,从而简化代码书写
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
int main()
{int a = 10;int* b = NULL;auto c = a;auto& d = a;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;return 0;
}

这里typeid(a).name()是返回a的类型
我们可以得出结论
- auto 必须初始化
- auto 不能当函数参数,返回值也不行
- auto不能声明数组
范围的for循环
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
前面我们学习过C语言的for循环语句,
int i = 0;
for (i = 0; i < 100; i++)
{printf("%d ", i);
}
但是在c++中的for语句有点差别
#include<iostream>
using std::cout;
using std::endl;
using std::cin;int main()
{int a[] = { 1,2,3,4,5,6,7,8,9 };for (auto e : a){cout << e << " ";}return 0;
}意思就是遍历一遍a数组,每个元素都依次赋值给e,自动判断结束, 修改e不会修改里面的元素
如果我们要修改元素的值
#include<iostream>
using std::cout;
using std::endl;
using std::cin;int main()
{int a[] = { 1,2,3,4,5,6,7,8,9 };for (auto& e : a){e++;cout << e << " ";}return 0;
}
我们可以使用引用来进行修改
指针空值nullptr
#include<iostream>
using std::cout;
using std::endl;
using std::cin;
void func(int)
{cout << "f(int)" << endl;
}
void func(int*)
{cout << "f(int*)" << endl;
}
int main()
{func(0);func(NULL);return 0;
}

这里的函数只写了类型,没有写变量,这个在c++是可以的,
看到结果的人可能会发现,为啥都打印了f(int),NULL不是指针类型吗,
其实不是,在c++
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:

如果是c++就是把NULL定义成了一个宏,C语言就是一个指针类型
所以c++就为了弥补这个错误,就写出了一个nullptr来代表NULL空指针
注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入
的。 - 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
相关文章:
C++初阶------------------入门C++
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...
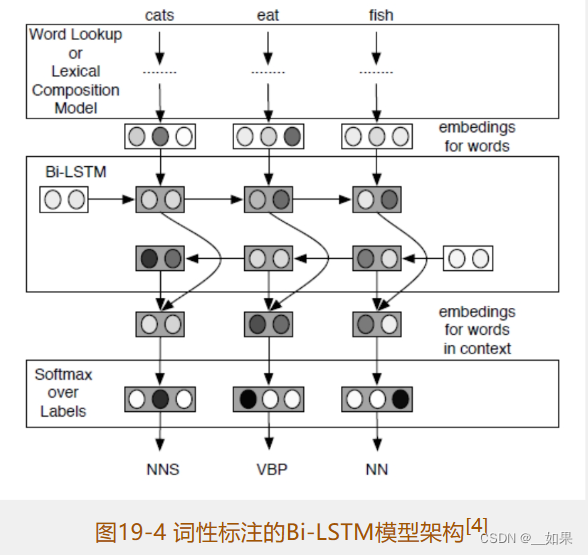
深度学习核心技术与实践之自然语言处理篇
非书中全部内容,只是写了些自认为有收获的部分。 自然语言处理简介 NLP的难点 (1)语言有很多复杂的情况,比如歧义、省略、指代、重复、更正、倒序、反语等 (2)歧义至少有如下几种: …...
AI-ChatGPTCopilot
ChatGPT chatGPT免费网站列表:GitHub - LiLittleCat/awesome-free-chatgpt: 🆓免费的 ChatGPT 镜像网站列表,持续更新。List of free ChatGPT mirror sites, continuously updated. Copilot 智能生成代码工具 安装步骤 - 登录 github&am…...
网络安全-真实ip获取伪造与隐藏挖掘
目录 真实ip获取应用层网络层网络连接TOAproxy protocol ip伪造应用层网络层TOA攻击proxy protocol 隐藏代理 挖掘代理多地ping历史DNS解析记录国外主机解析域名网站RSS订阅网络空间搜索引擎 总结参考 本篇文章学习一下如何服务如何获取真实ip,隐藏自己的ip…...
)
CMake入门教程【核心篇】添加子目录(add_subdirectory)
文章目录 1.概述2.添加子目录3.指定二进制目录4.排除子目录5.使用别名6.传递变量7.检查子目录是否存在 1.概述 add_subdirectory是 CMake 中的一个命令,用于向当前项目添加一个子目录。它的语法如下: #mermaid-svg-9zKJ3AvoVRln9hon {font-family:"…...

Prototype原型模式(对象创建)
原型模式:Prototype 链接:原型模式实例代码 注解 模式定义 使用原型实例指定创建对象的种类,然后通过拷贝这些原型来创建新的对象。 ——《设计模式》GoF 目的 在软件系统中,经常面临这“某些结构复杂的对象”的创建工作&am…...
[Redis实战]分布式锁
四、分布式锁 4.1 基本原理和实现方式对比 分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。 分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行…...
SpingBoot的项目实战--模拟电商【2.登录】
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于SpringBoot电商项目的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.功能需求 二.代码编写 …...
http——https实现指南
第一部分:HTTPS安全证书简介 什么是HTTPS安全证书? 在网络通信中,HTTPS安全证书是一种由可信任的证书颁发机构(CA)签发的数字证书,用于保障网站与用户之间的数据传输安全。通过加密和身份验证,…...
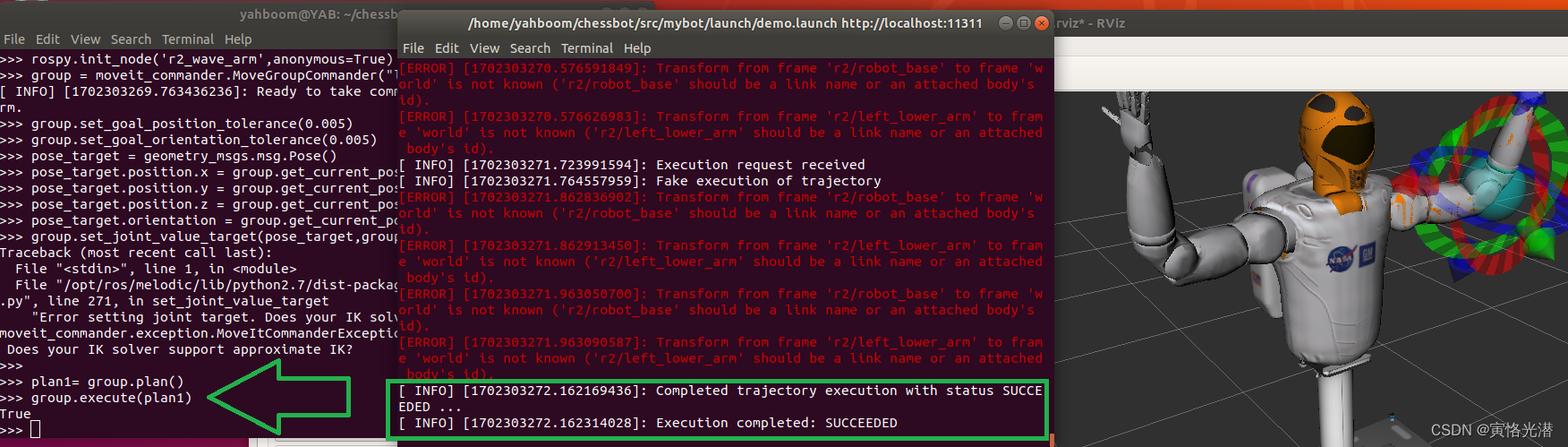
ROS仿真R2机器人之安装运行及MoveIt的介绍
R2(Robonaut 2)是NASA美国宇航局与GM通用联合推出的宇航人形机器人,能在国际空间站使用,可想而知其价格是非常昂贵,几百万美刀吧,还好NASA发布了一个R2机器人的Gazebo模型,使用模型就不需要花钱了,由于我们…...

【linux 多线程并发】线程属性设置与查看,绑定CPU,线程分离与可连接,避够多线程下的内存泄漏
线程属性设置 专栏内容: 参天引擎内核架构 本专栏一起来聊聊参天引擎内核架构,以及如何实现多机的数据库节点的多读多写,与传统主备,MPP的区别,技术难点的分析,数据元数据同步,多主节点的情况…...
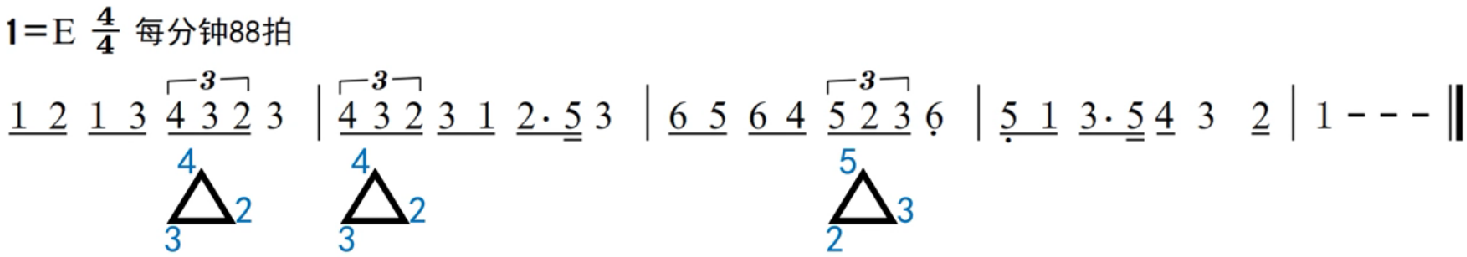
70.乐理基础-打拍子-三连音
上一个内容:69.乐理基础-打拍子-大切分与变体-CSDN博客 62-66是总拍数为一拍的节奏型,一共有七个,68-69是两拍的节奏型。 三连音说明: 1.三连音的总拍数可以是一拍、两拍、四拍。。。。 2.打拍子比较难,或许需要用V字…...

100天精通Python(实用脚本篇)——第111天:批量将PDF转Word文档(附上脚本代码)
文章目录 专栏导读1. 将PDF转Word文档需求2. 模块安装3. 模块介绍4. 注意事项5. 完整代码实现6. 运行结果书籍推荐 专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教…...

如何在 NAS 上安装 ONLYOFFICE 文档?
文章作者:ajun 导览 ONLYOFFICE 文档 是一款开源办公套件,其是包含文本文档、电子表格、演示文稿、表单、PDF 查看器和转换工具的协作性编辑工具。它高度兼容微软 Office 格式,包括 .docx、.xlsx 、.pptx 、pdf等文件格式,并支持…...
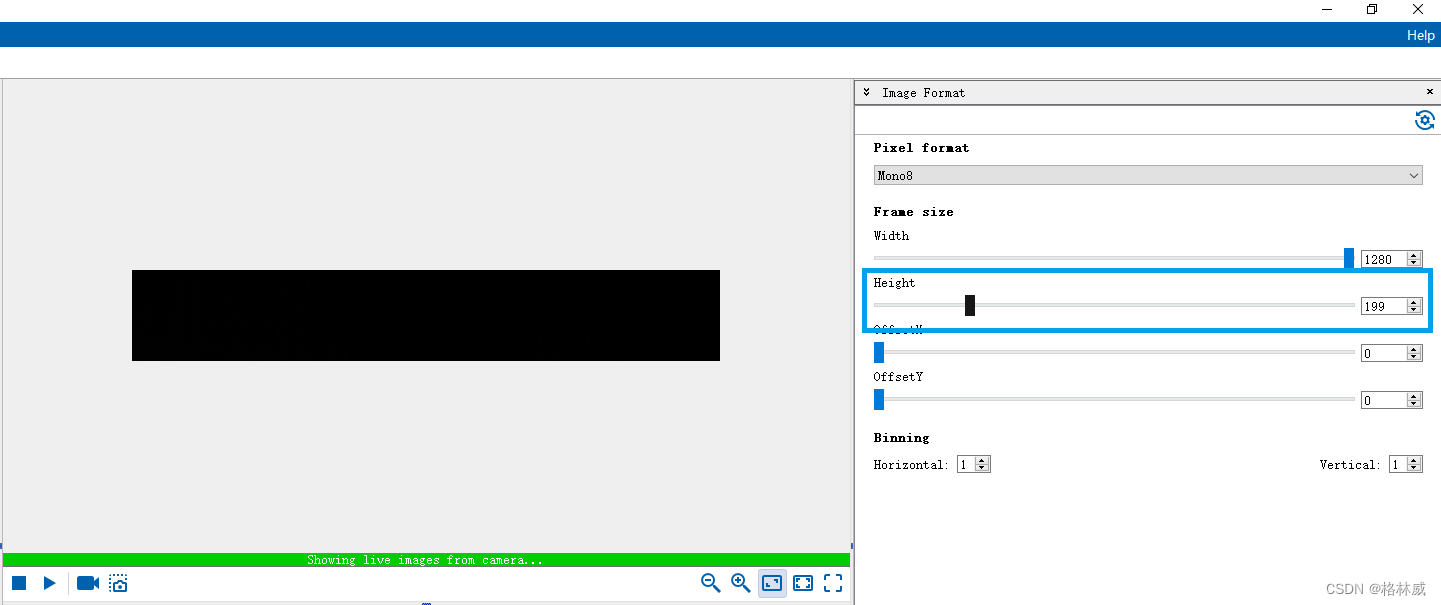
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的图像剪切(ROI)功能(C++)
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的图像剪切(ROI)功能(C) Baumer工业相机Baumer工业相机的图像剪切(ROI)功能的技术背景CameraExplorer如何使用图像剪切(ROI)功…...

从 WasmEdge 运行环境读写 Rust Wasm 应用的时序数据
WebAssembly (Wasm) 正在成为一个广受欢迎的编译目标,帮助开发者构建可迁移平台的应用。最近 Greptime 和 WasmEdge 协作,支持了在 WasmEdge 平台上的 Wasm 应用通过 MySQL 协议读写 GreptimeDB 中的时序数据。 什么是 WebAssembly WebAssembly 是一种…...
算法训练营Day34(贪心算法)
1005.K次取反后最大化的数组和 1005. K 次取反后最大化的数组和 - 力扣(LeetCode) 秒了 class Solution {public int largestSumAfterKNegations(int[] nums, int k) {Arrays.sort(nums);// -4 -3 -2 -1 5//-2 -2 0 2 5int last -1;for(int i 0;i<…...
uniapp:全局消息是推送,实现app在线更新,WebSocket,apk上传
全局消息是推送,实现app在线更新,WebSocket 1.在main.js中定义全局的WebSocket2.java后端建立和发送WebSocket3.通知所有用户更新 背景: 开发人员开发后app后打包成.apk文件,上传后通知厂区在线用户更新app。 那么没在线的怎么办&…...

ARM1.2作业
实现数码管不同位显示不同的数字 spi.h #ifndef __SPI_H__ #define __SPI_H__ #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_rcc.h"//MOSI对应的引脚输入高低电平的信号PE14 #define MOSI_OUTPUT_H() do{GPIOE->ODR | (0x1 << 14);}whi…...

【算法专题】递归算法
递归 递归1. 汉诺塔问题2. 合并两个有序链表3. 反转链表4. 两两交换链表中的节点5. Pow(x, n) --- 快速幂 递归 在解决⼀个规模为 n 的问题时,如果满足以下条件,我们可以使用递归来解决: 问题可以被划分为规模更小的子问题,并且…...

从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍
从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍 当你在Excel中处理上千行数据时,是否曾被那些零散的#N/A或空白单元格折磨得焦头烂额?CtrlF查找替换、IFERROR函数嵌套、手动拖拽填充柄...这些操作在小型数据集…...

Go语言集成Ollama本地大模型:gollama库实战指南
1. 项目概述:当Go语言遇上本地大模型如果你是一名Go语言开发者,同时又对本地运行的大型语言模型(LLM)感兴趣,那么你很可能已经感受到了两者之间的“次元壁”。一方面,Go以其简洁、高效和强大的并发能力&…...

2026年DevOps平台选型推荐:聚焦国产化适配与效能提升的关键考量
在数字化转型进入深水区的当下,中国企业对于DevOps平台的选型标准已发生深刻变化,从基础功能的完备性转向对本土化适配深度、安全合规能力与长期技术演进空间的综合权衡。2026年,这一趋势将更为显著,企业决策者需要在众多方案中寻…...

STM32CubeMX+STM32CubeIDE:STM32G030F6P6TR的免费开发生态入门
STM32G030F6P6TR:超值型Cortex-M0 MCU如何以最小封装实现64MHz性能突破在嵌入式系统设计中,“性价比”往往意味着在某些关键指标上的妥协——更小的封装通常伴随更低的主频或更少的外设。然而,STM32G0系列的推出打破了这一行业惯例。STM32G03…...

【审计专栏-监督监管】【信息科学与工程学】计算机科学与自动化——第一百五十篇 招投标领域中的应用数学02
编号 033 维度 内容 编号 033 领域 招投标数学分析 类型 餐饮工程“食材价格虚高”与“供应链绑定”式合谋识别 招投标领域 团餐服务、食材集中采购、厨房设备采购 子领域 学校食堂承包、机关单位食堂外包、大型活动供餐、中央厨房建设 招投标的行业 …...

终极指南:如何用GetQzonehistory完整备份你的QQ空间历史记录
终极指南:如何用GetQzonehistory完整备份你的QQ空间历史记录 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里的青春记忆会随着时间流逝而消失ÿ…...

SAP MIGO BADI增强实战:从自定义表到屏幕集成的完整指南
1. SAP MIGO BADI增强实战入门 第一次接到MIGO屏幕增强需求时,我完全理解那种既兴奋又忐忑的心情。兴奋是因为终于有机会深入SAP核心模块的增强开发,忐忑则是因为MIGO作为物料管理的核心事务,任何改动都可能影响整个业务流程。经过多个项目的…...
)
保姆级教程:在HCL模拟器上给H3C路由器配置DHCP服务器(双网段实战)
从零构建H3C路由器双网段DHCP服务:模拟器实战与协议解析 在虚拟实验室中搭建网络环境已成为现代工程师的必备技能,而DHCP服务作为网络自动化的基石,其配置过程往往成为初学者接触企业级设备的第一个实战挑战。本文将使用H3C官方推出的HCL模拟…...

从零到一:手把手部署openGauss极简版并完成基础运维
1. 环境准备:从零搭建openGauss的基石 第一次接触openGauss时,我被它"极简版"的宣传吸引,但真正动手部署才发现,前期环境准备才是决定成败的关键。就像盖房子需要打地基,数据库安装前的系统配置直接影响后续…...

资源管理器老崩溃?可能是combase.dll在捣鬼,手把手教你用DISM和干净启动搞定它
深度解析Win10资源管理器崩溃:combase.dll故障诊断与系统级修复指南 当你在Windows 10中拖拽文件时突然遭遇黑屏闪烁,随后资源管理器自动重启,这种看似随机的崩溃往往与一个关键系统组件——combase.dll密切相关。作为COM基础库的核心文件&am…...