elasticsearch系列五:集群的备份与恢复
概述
前几篇咱们讲了es的语法、存储的优化、常规运维等等,今天咱们看下如何备份数据和恢复数据。
在传统的关系型数据库中我们有多种备份方式,常见有热备、冷备、全量+定时增量备份、通过开发程序备份等等,其实在es中是一样的。
官方建议采用snapshot方式进行备份与恢复(它是有点冷备的意思,采用直接物理copy的方式,适合大数据量情况下),民间开源的有elasticsearch-dump方式进行备份但是这种方式只适用于小数据量的情况下,它是基于scroll语法进行的备份操作。
咱们今天就一起看下如何操作snapshot。es支持把快照保存到远端s3、hdfs、azure、gcs、本地磁盘,前4中需用安装插件和第三方能力,而本地磁盘的方式呢相对来说成本较小,我们今天就以本地磁盘的方式作为案例带大家看下。
单节点案例
首先我们看下单节点的情况下,我们首先需要在配置文件中配置好本地磁盘:
path.repo:["/opt/elasticsearch-cluster/snapshot_repo"]可以配置多个仓库,如果刚开始没有配置这个需要配置后重启es,通过http方式来注册一个仓库:
PUT http://192.168.11.14:9200/_snapshot/testbackup{"type": "fs","settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup"}}
注册成功以后咱们需要验证下是否可以正常访问该仓库:
POST http://192.168.11.14:9200/_snapshot/testback/_verify{"nodes" : {"mDRki1qVRBGnJiGEHUNlpg" : {"name" : "node-1"}}}
节点可以正常读写当前仓库,只有这个时候才可以执行备份操作,那么咱们现在执行下全库备份:
PUT http://192.168.11.14:9200/_snapshot/testback/snapshot_2{"accepted" : true}
如果数据量很小这个直接就是秒级的,如果数据量达到一定程度即便是物理copy也是需要很长一定时间的,那么这个时候就可以查看当前备份的任务状态:
GET http://192.168.11.14:9200/_snapshot/testback/snapshot_2/_status{"snapshots" : [{"snapshot" : "snapshot_2","repository" : "testback","uuid" : "O7YoR7dSQKueRff3jI4yow","state" : "SUCCESS","include_global_state" : true,"shards_stats" : {"initializing" : 0,"started" : 0,"finalizing" : 0,"done" : 54,"failed" : 0,"total" : 54},"stats" : {,,,,},"indices" : {,,,,, # 备份的索引信息}}]}
备份好了以后我们看下如何进行恢复,有些系统级的索引是没必要恢复的,此时我们就可以仅仅恢复业务索引:
POST http://192.168.11.14:9200/_snapshot/testback/snapshot_2/_restore{"indices": "log-server-*", #通过通配字符可以恢复批量索引"ignore_unavailable": true,"include_global_state": false}
单节点的基本操作就说完了,咱们看下集群中的恢复案例应该如何搞,有没有什么不一样的地方。
集群案例
咱们以2个节点的集群作为案例,那么我们需要考虑一个事情,仓库配置的话是需要每个节点都配置么?备份的时候是每个节点下的仓库都有一部分数据么?恢复的时候怎么读取所有节点上的快照数据呢?
假设只需要在master节点上配置仓库即可,咱们启动后注册一个仓库看下结果:
PUT http://192.168.11.14:9200/_snapshot/my_backup
{"type": "fs", "settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup" }
}{"error" : {"root_cause" : [{"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryMissingException[[my_backup] missing];']]"}],"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryMissingException[[my_backup] missing];']]"},"status" : 500
}我们可以看到直接报错了,提示和node-2上的仓库访问出现异常,那么我们把另外一个节点也配置上仓库再看下效果:
PUT http://192.168.11.14:9200/_snapshot/my_backup
{"type": "fs", "settings": {"location": "/opt/elasticsearch-cluster/snapshot_repo/my_backup" }
}{"error" : {"root_cause" : [{"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.11.14:9300][internal:admin/repository/verify]]; nested: RepositoryVerificationException[[my_backup] a file written by master to the store [/opt/elasticsearch-cluster/snapshot_repo/my_backup"] cannot be accessed on the node [{node-2}{NI3uZdOPSBCybjAZVFd2Lg}{hmw7r2S0S7GB7y3vWvLHzQ}{192.168.114.14}{192.168.114.14:9300}{cdhilmrstw}{ml.machine_memory=33382490112, xpack.installed=true, transform.node=true, ml.max_open_jobs=20}]. This might indicate that the store [/home/app/es/backup] is not shared between this node and the master node or that permissions on the store don't allow reading files written by the master node]; nested: NoSuchFileException[/home/app/es/backup/tests-8N681uUdQeiPuaxhj8tNag/master.dat];']]"}],"type" : "repository_verification_exception","reason" : "[my_backup] [[NI3uZdOPSBCybjAZVFd2Lg, 'RemoteTransportException[[node-2][192.168.14.14:9300][internal:admin/repository/verify]]; nested: RepositoryVerificationException[[my_backup] a file written by master to the store [/opt/elasticsearch-cluster/snapshot_repo/my_backup"] cannot be accessed on the node [{node-2}{NI3uZdOPSBCybjAZVFd2Lg}{hmw7r2S0S7GB7y3vWvLHzQ}{192.168.114.14}{192.168.114.14:9300}{cdhilmrstw}{ml.machine_memory=33382490112, xpack.installed=true, transform.node=true, ml.max_open_jobs=20}]. This might indicate that the store [/home/app/es/backup] is not shared between this node and the master node or that permissions on the store don't allow reading files written by the master node]; nested: NoSuchFileException[/home/app/es/backup/tests-8N681uUdQeiPuaxhj8tNag/master.dat];']]"},"status" : 500
}
可以看到此时错误又变了,提示无法读取主节点上的仓库,这是因为啊2个节点之间的仓库没有做共享,这个时候我们只需要把所有节点的备份仓库做nas共享即可,至于恢复的时候和单节点是一样的,
总结
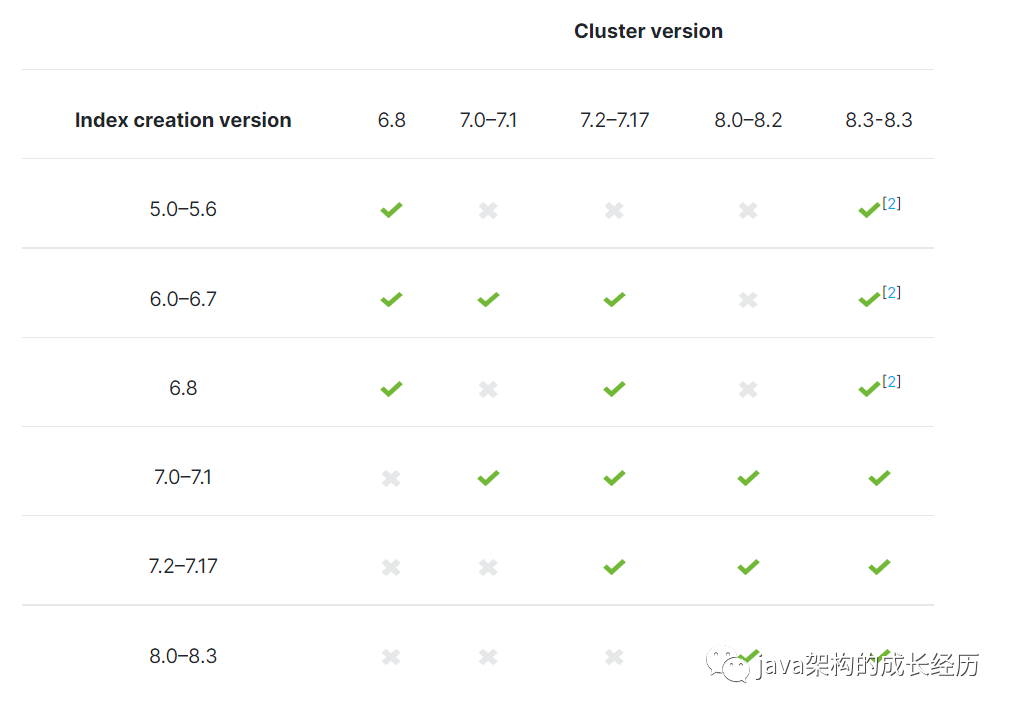
至此我们的恢复与备份就说完了,除了以上的问题大家还需要关注下各个版本之间的数据差异,是否可以跨版本恢复,es的版本更新速度还是很快的,所以大家一定要关注下,以下是官方给的一个版本限制:
Elasticsearch系列经典文章
-
elasticsearch列一:索引模板的使用
-
elasticsearch系列二:引入索引模板后发现数据达到一定量还是慢怎么办?
-
elasticsearch系列三:常用查询语法
-
Elasticsearch 底层存储原理解密
-
Elasticsearch优化建议
-
干货 | Elasticsearch 8.X 节点角色划分深入详解

相关文章:
elasticsearch系列五:集群的备份与恢复
概述 前几篇咱们讲了es的语法、存储的优化、常规运维等等,今天咱们看下如何备份数据和恢复数据。 在传统的关系型数据库中我们有多种备份方式,常见有热备、冷备、全量定时增量备份、通过开发程序备份等等,其实在es中是一样的。 官方建议采用s…...

【Elasticsearch源码】 分片恢复分析
带着疑问学源码,第七篇:Elasticsearch 分片恢复分析 代码分析基于:https://github.com/jiankunking/elasticsearch Elasticsearch 8.0.0-SNAPSHOT 目的 在看源码之前先梳理一下,自己对于分片恢复的疑问点: 网上对于E…...
elasticsearch如何操作索引库里面的文档
上节介绍了索引库的CRUD,接下来操作索引库里面的文档 目录 一、添加文档 二、查询文档 三、删除文档 四、修改文档 一、添加文档 新增文档的DSL语法如下 POST /索引库名/_doc/文档id(不加id,es会自动生成) { "字段1":"值1", "字段2&q…...
opencv期末练习题(2)附带解析
图像插值与缩放 %matplotlib inline import cv2 import matplotlib.pyplot as plt def imshow(img,grayFalse,bgr_modeFalse):if gray:img cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)plt.imshow(img,cmap"gray")else:if not bgr_mode:img cv2.cvtColor(img,cv2.COLOR_B…...

【Mybatis】深入学习MyBatis:高级特性与Spring整合
🍎个人博客:个人主页 🏆个人专栏: Mybatis ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 高级特性 1 一级缓存和二级缓存 一级缓存 二级缓存 2 延迟加载 5 整合Spring 1 MyBatis-Spring模块 2 事务管理 结…...

C语言与人生函数的对比,使用,参数详解
各位少年,大家好,我是博主那一脸阳光。,今天给大家分享函数的定义,和数学的函数的区别和使用 前言:C语言中的函数和数学中的函数在概念上有相似之处,但也存在显著的区别。下面对比它们的主要特点ÿ…...

机器人动力学一些笔记
动力学方程中,Q和q的关系(Q是sita) Q其实是一个向量,q(Q1,Q2,Q3,Q4,Q5,Q6)(假如6个关节) https://zhuanlan.zhihu.com/p/25789930 举个浅显易懂的例子,你在房…...
Plantuml之甘特图语法介绍(二十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
Docker support for NVIDIA GPU Accelerated Computing on WSL 2
Docker support for NVIDIA GPU Accelerated Computing on WSL 2 0. 背景1. 安装 Docker Desktop2. 配置 Docker Desktop3. WLS Ubuntu 配置4. 安装 Docker-ce5. 安装 NVIDIA Container Toolkit6. 配置 Docker7. 运行一个 Sample Workload 0. 背景 今天尝试一下 NVIDIA GPU 在…...
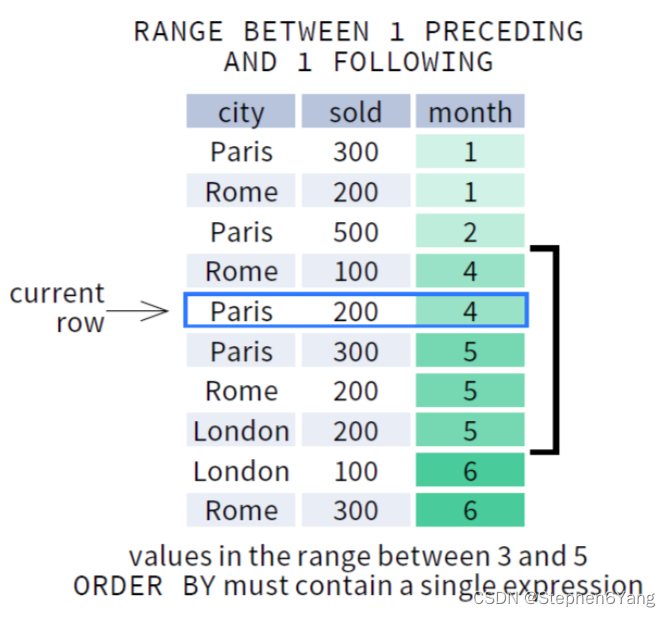
SQL窗口函数大小详解
窗口大小 OVER 子句中的 frame_clause 选项用于指定一个滑动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。 指定窗口大小的语法如下: ROWS…...

C#上位机与欧姆龙PLC的通信06---- HostLink协议(FINS版)
1、介绍 对于上位机开发来说,欧姆龙PLC支持的主要的协议有Hostlink协议,FinsTcp/Udp协议,EtherNetIP协议,本项目使用Hostlink协议。 Hostlink协议是欧姆龙PLC与上位机链接的公开协议。上位机通过发送Hostlink命令,可…...

认识SpringBoot项目中的Starter
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 循序渐进学SpringBoot ✨特色专栏&…...

ChatGPT 4.0真的值得花钱买入吗?
性能提升: ChatGPT 4.0的推出不仅意味着更先进的技术,还代表着更强大的性能。相较于3.5,4.0在处理任务时更为高效,响应更迅速。 更智能的理解: 随着版本的升级,ChatGPT 4.0对语境的理解能力得到了进一步的…...

vue3对比vue2是怎样的
一、前言 Vue 3通过引入Composition API、升级响应式系统、优化性能等一系列的改进和升级,提供了更好的开发体验和更好的性能,使得开发者能够更方便地开发出高质量的Web应用。它在Vue.js 2的基础上进行了一系列的改进和升级,以提供更好的性能、更好的开发体验和更好的扩展性…...

openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证
文章目录 openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证184.1 验证项目的检查表184.2 升级版本查询184.2.1 验证步骤 184.3 检查升级数据库状态184.3.1 验证步骤 openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证 本章介绍升级完成后的验证操作。给出验…...
)
[Verilog语言入门教程] Verilog 减法器 (半减器, 全减器, 加减共用)
依公知及经验整理,原创保护,禁止转载。 专栏 《元带你学Verilog》 <<<< 返回总目录 <<<< “逻辑设计是一门艺术,它需要创造力和想象力。” - 马克张伯伦(Mark Zwolinski) 减法器是数字电路中常见的组件,用于减去两个二进制数的和。 在Verilog中…...

预编译仓库中的 Helm Chart
背景 内网部署项目, 没法直接hlem install , 需要提前看看有哪些镜像, 拉到本地看看 要使用预编译仓库中的 Helm Chart,你可以使用 helm fetch 命令来将 Chart 下载到本地,并使用 helm template 命令来预编译该 Chart。 首先,你可以使用以…...

Python requests get和post方法发送HTTP请求
requests.get() requests.get() 方法用于发送 HTTP GET 请求。下面介绍 requests.get() 方法的常用参数: url: 发送请求的 URL 地址。params: URL 中的查询参数,可以是字典或字符串。headers: 请求头信息。可以是字典类型,也可以是自定义的…...

在Cadence中单独添加或删除器件与修改网络的方法
首先需要在设置中使能 ,添加或修改逻辑选项。 添加或删除器件,点击logic-part,选择需要添加或删除的器件,这里的器件必须是PCB中已经有的器件,Refdes中输入添加或删除的器件标号,点击Add添加。 添加完成后就会显示在R1…...

轻松调整视频时长,创意与技术的新篇章
传统的视频剪辑工具往往难以精确控制时间,而【媒体梦工厂】凭借其先进的算法和界面设计,让视频时长的调整变得简单而精确,助你释放无限的创意,用技术为你的创意插上翅膀,让每一秒都有意义。 所需工具: 一…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...
、事务管理和文件上传(阿里云OSS))
员工管理(新增员工)、事务管理和文件上传(阿里云OSS)
员工管理(新增员工) 思路就是就是新增的员工基本信息和批量保存员工的工作经历信息,也就是后端对应了两条sql语句, 1.保存员工基本信息 Emp实体类中新添一个字段用于保存员工工作经历 //封装工作经历 private List<EmpExpr> exprList; (1)Cont…...
)
手把手教你用OPA4377搭建一个精密电流检测电路(附AD原理图/PCB)
精密电流检测电路设计实战:基于OPA4377的完整解决方案 在工业自动化、新能源系统和医疗设备等领域,精密电流检测一直是电路设计中的关键挑战。传统方案往往面临噪声干扰、非线性失真和温度漂移等问题,而现代CMOS运算放大器如OPA4377为解决这些…...

3分钟搞定抖音无水印下载:从新手到高手的完整指南
3分钟搞定抖音无水印下载:从新手到高手的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

【Gemini JavaScript开发支持终极指南】:20年谷歌AI工程师亲授7大避坑法则与实时调试秘技
更多请点击: https://intelliparadigm.com 第一章:Gemini JavaScript开发支持概览 Gemini API 的 JavaScript 集成能力 Google Gemini 提供了官方 Node.js SDK( google/generative-ai),支持在服务端与浏览器环境中调…...

NotebookLM Pro版到底贵在哪?——基于172小时真实工作流压测的TCO建模分析
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Pro版到底贵在哪?——基于172小时真实工作流压测的TCO建模分析 在连续172小时跨时区协同实验中,我们部署了3类典型知识工作流:法律条文溯源分析、学术论文…...

NotebookLM如何重构你的NLP工作流,72小时实现从零标注到可部署模型闭环
更多请点击: https://intelliparadigm.com 第一章:NotebookLM如何重构你的NLP工作流,72小时实现从零标注到可部署模型闭环 NotebookLM 是 Google 推出的实验性 AI 助手,专为结构化文档理解与知识驱动建模而设计。它并非传统 LLM …...

SBQE:量子机器学习数据编码的创新方法
1. SBQE:量子机器学习数据编码的新范式量子计算领域最近迎来了一项突破性进展——SBQE(Shot-Based Quantum Encoding)数据编码方法。作为一名长期跟踪量子机器学习发展的研究者,我亲历了这项技术从理论提出到实验验证的全过程。SB…...
)
HFSS新手避坑指南:手把手教你设置Floquet Port和主从边界(附矩形波导实例)
HFSS阵列仿真实战:从Floquet Port到主从边界的精准设置 第一次打开HFSS准备仿真周期性结构时,那种既兴奋又忐忑的心情我至今记忆犹新。作为计算电磁学领域的黄金标准工具,HFSS在阵列天线、频率选择表面等周期性结构分析中展现出无可替代的价…...

职慧AI陪练产品全景解析:六大训练模式如何覆盖销售培养全场景
摘要:市面上的AI陪练产品大多只能做"话术对练",真正能覆盖销售能力培养全链路的产品长什么样?本文深度拆解职行力职慧AI陪练的六大训练模式——话术陪练、情景对话、智能考试、微课学习、AI专家问答、训练官带教,以及背…...