MySQL中的索引之分类,原理,作用,优缺点和执行计划
索引
- 索引的作用:加速查找
- 例如: 300w条数据的表中查询,无索引需要700s, 利用索引可能只需要1s
- 用索引的时机是,数据量巨大,并且搜索快速
- 索引为什么能实现加速查找
- 基于索引的内部存储结构
- 索引底层基于 B+Tree 的数据结构存储的
- 在创建一张表的时候,将数据按照先后顺序放在一个文件里
- 如果你为表里的数据创建索引后,会将数据生成额外的数据结构
- 在这个数据结构中,将索引的这一列按照另外的规则进行存储,即 B+Tree 的结构
- 只要给一个 字段添加索引,就会为这个字段新增一个 B+Tree 的结构
- 背后的缺点是额外维护数据结构,并且新增或删除数据时,速度比之前要慢
- 只有查找会变快,新增,修改,删除都会变慢
- MySQL中的索引都是 基于 B+Tree 实现的
- 在MySQL中,如果要创建一张表,可以指定不同的引擎
- myisam 引擎,用的是非聚簇索引 (数据和索引结构 分开存储)
- 在这个表里创建索引,称为非聚簇索引
- 表是表,索引结构式索引结构,拆开放的
- innodb 引擎,用的是 聚簇索引 (数据和主键索引结构存在一起)
- 创建表的时候,实际上是没有表的,而是将主键通过树形结构存储起来
- 没有这个表的,节点不仅存储主键,而且把每行存储的信息存储在上面
- myisam 引擎,用的是非聚簇索引 (数据和索引结构 分开存储)
- 基于两种引擎创建的表,底层都用 B+Tree 来存储,但是存储中也是不太一样的
- 有了索引结构的查询效率,比表中逐行查询的速度要快很多,且数据量越大越明显
- https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
mysiam引擎
create table 表名(id int not null auto_increment primary key,name varchar(32) not null,age int
) engine=myisam default charset=utf8;
- 在索引中的节点存储了表中数据行的内存地址, 这样就可以直接找到当前行的数据
聚簇引擎
create table 表名(id int not null auto_increment primary key,name varchar(32) not null,age int
) engine=innodb default charset=utf8;
- 根据索引结构,通过主键拿到当前行的所有数据
- 如果除了主键索引,还需要创建如 name 的索引
- 这时候,就会创建一个辅助索引,生成另外一套数据结构
- 按照name来存放,会存储主键id, 再根据主键根据主键索引文件中查找
两种索引的文件对比
-
开发中,一般使用 innodb 引擎,支持事务,行级锁,外键等特点
-
在mysql5.5之后,所有默认引擎也是 innodb
-
可以找到 mysql的安装目录,比如:
/usr/local/mysql/data/userdb -
常见不同引擎的表,生成的文件也不一样
-
比如 big 这张表,是基于 innodb 引擎的
- big.frm 表结构
- big.ibd 数据和索引结构
-
对于表 t2 是 myisam 引擎的话
- t2.frm 表结构
- t2.MYD 数据
- t2.MYI 索引结构
- 它的底层帮我们创建3个文件
-
我们后续用的 innodb ,都是聚簇索引
索引的优缺点
- 优点: 查找速度快,约束 (主键, 唯一, 联合唯一)
- 缺点: 插入、删除、更新速度比较慢, 因为每次操作都需要调整整个B+Tree的数据结构关系
- 所以,在表中不要无节制的创建索引,不使用索引反而会适得其反
查询要命中索引
- 比如有一张300w数据量的用户表
表结构示例
create table `users` (`id` int(11) not null auto_increment,`name` varchar(32) default null,`email` varchar(64) default null,`password` varchar(64) default null,`age` int(11) default null,primary key (`id`), --- 主键索引unique key `big_unique_email` (`email`), --- 唯一索引index `ix_name_pwd` (`name`, `password`), --- 联合索引
) engine=InnoDB default charset=utf8;
- 以上表结构中有三个索引,2个 key, 1个 index(普通)
- 一般,基于索引列搜索都可命中索引,加速查找
- 注意,联合索引,查询其中之一也是快的
查询示例
select * from big where id=5;
select * from big where id>5;
select * from big where email='xxxx@qq.com';
select * from big where name='xxx';
select * from big where name='sss' and password='ssdd';
命中索引的场景
- 以下几种情况是常用的是否命中索引的场景
1 )类型不一致场景
select * from users where name = 123; -- 不会命中索引
select * from users where email = 123; -- 不会命中索引-- 下面用主键
select * from users where id='123'; -- 会命中索引
2 )使用不等于
select * from users where name != 'xxxx'; -- 不会命中索引
select * from users where email != 'xxxx@qq.com'; -- 不会命中索引-- 主键
select * from users where id != 123; -- 不会命中索引
3 )使用 or
select * from users where id = 123 or password = 'x'; -- 不会命中 这里后面联合索引中只用了一个
select * from users where name = 'xx' or password = 'y'; -- 不会命中 用 or 将联合索引拆成了两个-- 下面会命中
select * from users where id = 10 or password='xx' and name='yy'; -- 命中 这里 or 前后都是索引
4 )使用排序
- 根据索引排序时,选择的映射列不是索引,则不走索引
select * from users order by name asc; -- 未命中
select * from users order by name desc; -- 未命中-- 主键会命中
select * from users order by id desc; -- 会命中
5 )like 模糊匹配时
- 通配符在最后面可以命中
select * from users where name like '%xxx' -- 不会命中
select * from users where name like '_xxx' -- 不会命中
select * from users where name like 'xx%xx' -- 不会命中-- 通配符在最后,会命中
select * from users where name like "xxxx%" -- 命中
select * from users where name like "xxxx_" -- 命中
6 )使用函数
select * from users where reverse(name) = 'xxxx'; --- 不会命中-- 特别的
select * from users where name = reverse('abc') -- 会命中
7 )联合索引
-
如果是联合索引,最遵循最左前缀原则
-
如果联合索引为 (name, password)
name and passsword命中name命中password不会命中name or password不会命中
-
最左边用可以命中,用or连接则不能
关于执行计划 explain
- mysql中提供了执行计划, 用于预判sql的执行效率
- 不能准确预判,只作为参考
- 语法:
explain sql语句
1 )使用
explain select * from users- 这会输出当前sql的分析表格
2 )解析 type
-
基于输出表格字段中的 type 来看,它是一个重要的性能指标
- 其值的性能依次排序为:
- all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
-
详解如下
- ALL,全表扫描,数据从头到尾找一遍,(一般没有命中索引,都会执行全部扫描)
select * from users全部扫描select * from users limit 1;这里特别,遇到 limit 结束后不再扫描
- INDEX, 全索引扫描,对索引从头到尾扫描一遍
explain select id from users;explain select name from users;
- RANGE, 对索引列进行范围查找
explain select * from users where id > 10;explain select * from users where id in (1,2,3);
- INDEX_MERGE 合并索引,即使用了多个单列索引
explain select * from users where id = 10 or name='xxx'
- REF, 根据索引直接去查找 (非键)
select * from users where name = 'xxx'
- EQ_REF, 连表操作时常见, 也是根据索引查询
explain select article.title, users.id from article left join users on user.id = article.uid
- CONST, 常量,表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快
explain select * from users where id = 123;这里是主键explain select * from users email = 'xxxx@qq.com唯一索引
- SYSTEM, 系统,表仅有一行(=系统表) 这里是 const连接类型的一个特例
explain select * from (select * from users where id=1 limit 1) as A;
- ALL,全表扫描,数据从头到尾找一遍,(一般没有命中索引,都会执行全部扫描)
-
综合以上,一般来说,性能在 RANGE 及其以上,性能算是 OK的
-
当然,这不是最终结果,只是初步的评价,和最终效率一定会有差异
3 )其他字段
- id 执行顺序
- select_type 查询类型
- SIMPLE 简单查询
- PRIMARY 最外层查询
- SUBQUERY 映射为子查询
- DERIVED 子查询
- UNION 联合
- UNION RESULT 使用联合的结果
- …
- table 正在访问的表名
- partitions, 涉及的分区,不常用,mysql将数据划分到不同的 idb文件中,箱单与数据的拆分
- 分区是指,一个特别大的文件拆分成多个小文件
- possible_keys, 查询涉及到的字段上若存在索引,则该索引将被列出
- 即:可能使用的索引
- key, 在查询中实际使用的索引,若没有使用索引,显示为 null
- 比如,有索引,但未命中,则 possible_keys显示,key则显示为 null
- key_len, 表示索引字段最大可能的长度
- 类型字节长度 + 变长2 + 可空1
- 例如,key_ken = 195, 类型 varchar(64)
- 195 = 64 * 3 + 2 + 1
- ref, 连表时显示的关联信息
- 例如,A和B连表,显示连表的字段信息
- rows, 估计读取的数据行数 (只是预估值)
- filtered, 返回结果的行栈需要读到行的百分比
explain select * from users where id = 1;100, 这里只读了一行,返回结果也是1行explain select * from big where password = 'xxx'10, 读取了10行,返回了1行,注意,这里 xxx的 password在第10行
- extra, 该列包含mysql解决查询的详细信息
Using index表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index的访问类型弄混了Using where- 表示mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里设计索引中的列
- 当(并且如果)它读取索引时,就能被存储引擎检验
- 因此,不是所有带 where 子句的查询都会显示 Using where
- 有时,Using where的出现就是一个暗示,查询可受益于不同的索引
Using temporary- mysql在对查询结果排序时会使用一个临时表
Using filesort- mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行
- mysql有两种文件排序算法,这两种排序方式都可以在内存或磁盘上完成
- explain 不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成
Range checked foreachrecord(index map: N)- 这意味着没有好用的索引,新的索引将在连接的每一行上重新估算
- N是显示在possible_keys列中索引的位图,并且是冗余的
相关文章:

MySQL中的索引之分类,原理,作用,优缺点和执行计划
索引 索引的作用:加速查找 例如: 300w条数据的表中查询,无索引需要700s, 利用索引可能只需要1s用索引的时机是,数据量巨大,并且搜索快速 索引为什么能实现加速查找 基于索引的内部存储结构索引底层基于 BTree 的数据结构存储的在…...

如何做好档案数字化前的鉴定工作
要做好档案数字化前的鉴定工作,可以按照以下步骤进行: 1. 确定鉴定目标:明确要鉴定的档案的内容、数量和性质,确定鉴定的范围和目标。 2. 进行档案清点:对档案进行全面清点和登记,包括数量、种类、状况等信…...

pytorch04:网络模型创建
目录 一、模型创建过程1.1 以LeNet网络为例1.2 LeNet结构1.3 nn.Module 二、网络层容器(Containers)2.1 nn.Sequential2.1.1 常规方法实现2.1.2 OrderedDict方法实现 2.2 nn.ModuleList2.3 nn.ModuleDict2.4 三种容器构建总结 三、AlexNet网络构建 一、模型创建过程 1.1 以LeNe…...
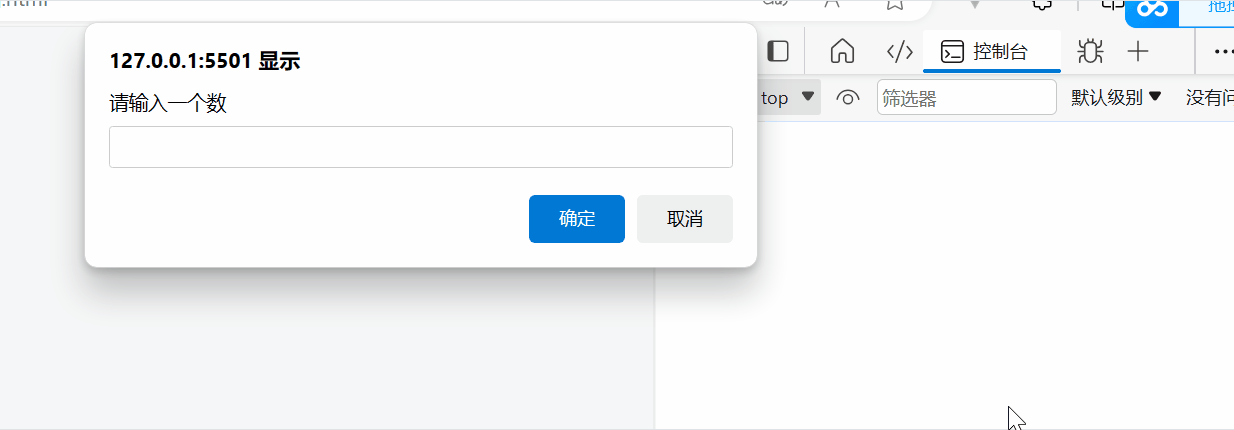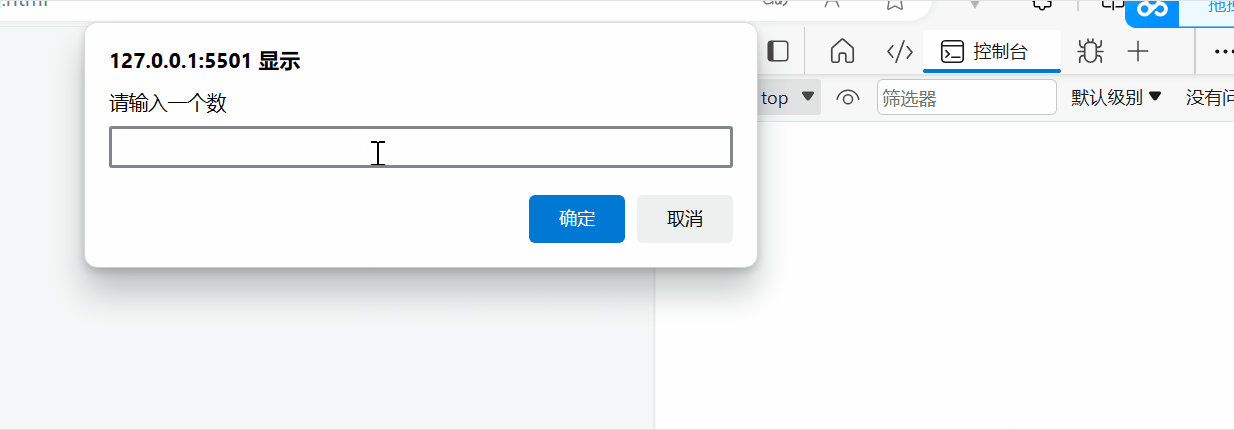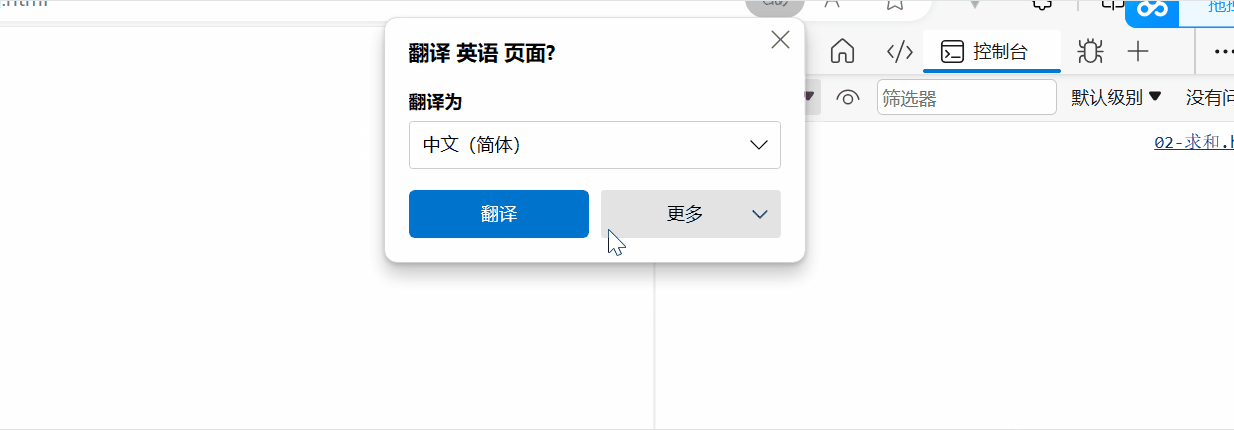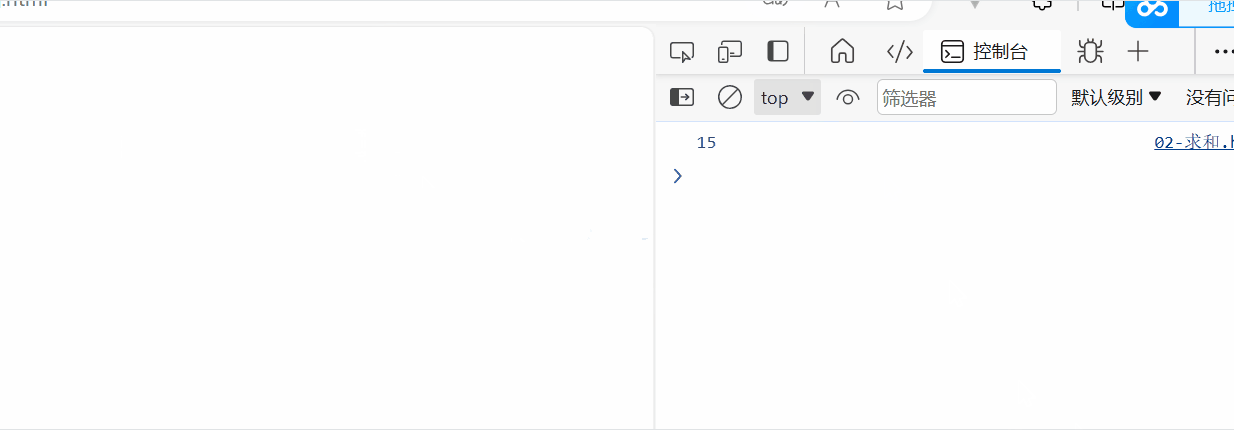
用js让用户输入一个数累加和
需求:用户输入一个数, 计算 1 到这个数的和。 比如 用户输入的是 5, 则计算 1~5 之间的累加和 并且输出到控制台 <body><script>let numprompt(请输入一个数)let sum0for(let i1;i<num;i){sumi}console.log(sum)</script…...

踩坑记录-安装nuxt3报错:Error: Failed to download template from registry: fetch failed;
报错复现 安装nuxt3报错:Error: Failed to download template from registry: fetch failednpx nuxi init nuxt-demo 初始化nuxt 项目 报错 Error: Failed to download template from registry: fetch faile 解决方法 配置hosts Mac电脑:/etc/hostswin电…...
-Spark非常用及重要特性)
大数据学习(31)-Spark非常用及重要特性
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

【教学类-43-14】 20240103 (4宫格数独:正确版:576套) 不重复的基础模板数量:576套
作品展示::——4宫格 576套不重复模板(48页*12套题) 背景需求: 生成4宫格基础模板768套,观看64页内容时,明显看到有错误 【教学类-43-13】 20240103 (4宫格数独:错误版…...

AIGC开发:调用openai的API接口实现简单机器人
简介 开始进行最简单的使用:通过API调用openai的模型能力 OpenAI的能力如下图: 文本生成模型 OpenAI 的文本生成模型(通常称为生成式预训练 Transformer 或大型语言模型)经过训练可以理解自然语言、代码和图像。这些模型提供文…...
)
c基础(二)
指针: 含义:是一个值,一个值代表着一个内存地址,类似于存放路径 * 运算符 : 1 字符*表示指针 作用:通常跟在类型关键字的后面,表示指针指向的是什么类型的值 int * foo, * bar;声明指针后会…...

人工智能趋势报告解读:ai野蛮式生长的背后是机遇还是危机?
近期,Enterprise WordPress发布了生成式人工智能在营销中的应用程度的报告,这是一个人工智能迅猛发展的时代,目前人工智能已经广泛运用到内容创作等领域,可以预见的是人工智能及其扩展应用还将延伸到我们工作与生活中的方方面面。…...
 (完))
三、C语言中的分支与循环—goto语句 (10) (完)
在C语言中,goto语句允许程序无条件地跳转到同一函数内的标记位置。这个标记位置通过一个标签和冒号(:)来标示。goto语句可以用于从深层嵌套的循环或条件语句中直接跳出,或者跳过某些代码执行。尽管goto语句在某些情况下可以使程序逻辑变得清晰࿰…...

RabbitMQ 常见问题
1. 如何保证消息顺序消费 在RabbitMQ中,消息最终会保存在队列中,在同一个队列中,消息是顺序的,保持先进先出的原则,这个由Rabbitmq保证。而不同队列中的消息,RabbitMQ 是无法保证其顺序性。顺序消费主要是…...

阶段二-Day10-日期类
日期类结构: 1.java.util.Date是日期类 2.DateFormat是日期格式类、SimpleDateFormat是日期格式类的子类 Timezone代表时区 3.Calendar是日历类,GregorianCalendar是日历的子类 一. 常用类-Date 1.1 Date构造方法 Date(long date) 使用给定的毫秒时间价值构建…...
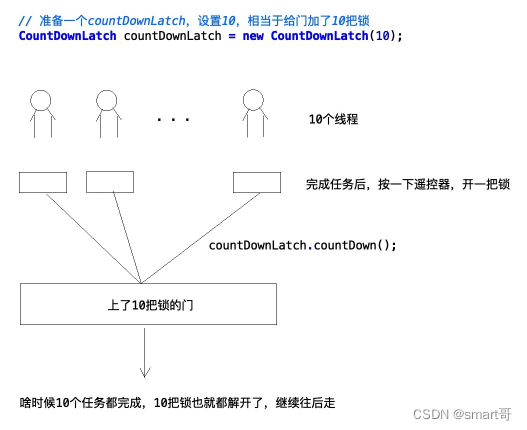
多任务并行处理相关面试题
我自己面试时被问过两次多任务并行相关的问题: 假设现在有10个任务,要求同时处理,并且必须所有任务全部完成才返回结果 这个面试题的难点是: 既然要同时处理,那么肯定要用多线程。怎么设计多线程同时处理任务呢&…...
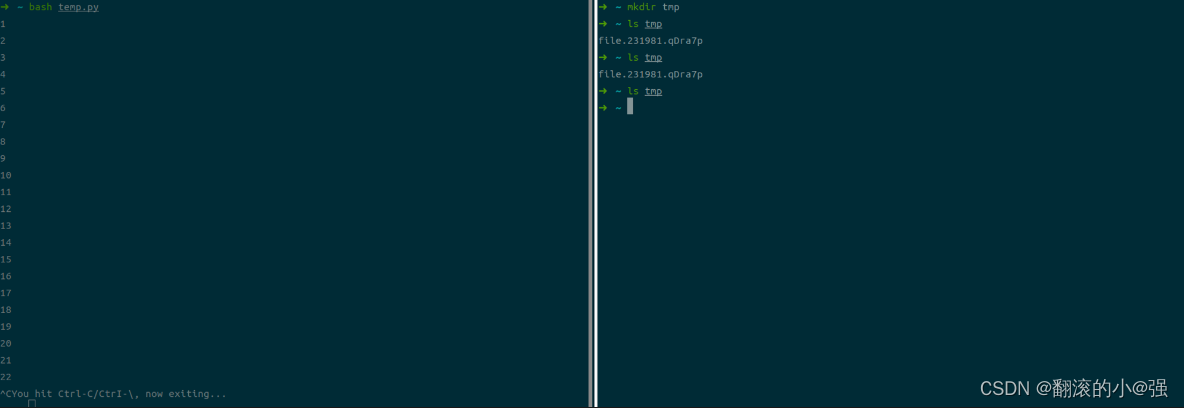
Shell脚本学习笔记
1. 写在前面 工作中,需要用到写一些shell脚本去完成一些简单的重复性工作, 于是就想系统的学习下shell脚本的相关知识, 本篇文章是学习shell脚本整理的学习笔记,内容参考主要来自C语言中文网, 学习过程中,…...

ROS-安装xacro
安装 运行下列命令进行安装,xxxxxx处更改为自己的版本 sudo apt-get install ros-xxxxxx-xacro运行 输入下列命令 roscd xacro如果没有报错,并且进入了xacro软件包的目录,则表示安装成功。 参考: [1]https://wenku.csdn.net/ans…...

为什么说 $mash 是 Solana 上最正统的铭文通证?
早在 2023 年的 11 月,包括 Solana、Avalanche、Polygon、Arbitrum、zkSync 等生态正在承接比特币铭文生态外溢的价值。当然,因铭文赛道过于火爆,当 Avalanche、BNB Chain 以及 Polygon 等链上 Gas 飙升至极值,Arbitrum、zkSync 等…...
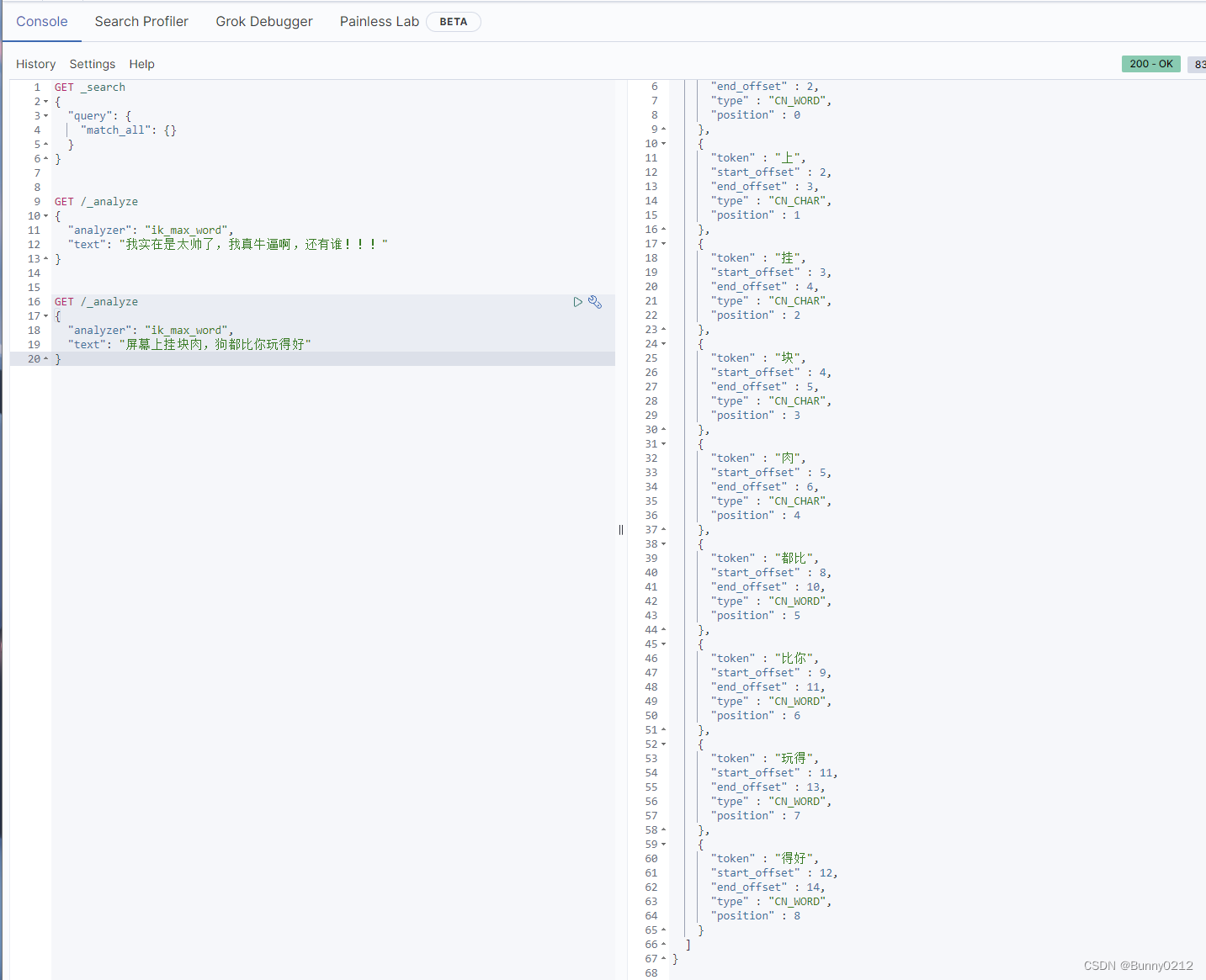
安装elasticsearch、kibana、IK分词器、扩展IK词典
安装elasticsearch、kibana、IK分词器、扩展IK词典 后面还会安装kibana,这个会提供可视化界面方面学习。 需要注意的是elasticsearch和kibana版本一定要一样!!! 否则就像这样 elasticsearch 1、创建网络 因为我们还需要部署k…...

Spring中常见的BeanFactory后处理器
常见的BeanFacatory后处理器 先给出没有添加任何BeanFactory后处理器的测试代码 public class TestBeanFactoryPostProcessor {public static void main(String[] args) {GenericApplicationContext context new GenericApplicationContext();context.registerBean("co…...
)
FPGA LCD1602驱动代码 (已验证)
一.需求解读 1.需求 在液晶屏第一行显示“HELLO FPGA 1234!” 2. 知识背景 1602 液晶也叫 1602 字符型液晶,它是一种专门用来显示字母、数字、符号等的点阵 型液晶模块。它由若干个 5X7 或者 5X11 等点阵字符位组成,每个点阵字符位都可以显示一 个字符,每位之间有一个点距的…...

2026最权威的AI辅助写作方案推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术环境里头,知网的AI内容识别机制已然全面实现落地,针对由…...

忘记压缩包密码怎么办?3步找回加密文件的终极免费解决方案
忘记压缩包密码怎么办?3步找回加密文件的终极免费解决方案 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个加…...

青龙脚本自动化:五款实用脚本助你轻松管理日常任务
青龙脚本自动化:五款实用脚本助你轻松管理日常任务 【免费下载链接】huajiScript 滑稽の青龙脚本库 项目地址: https://gitcode.com/gh_mirrors/hu/huajiScript 在当今快节奏的数字时代,自动化工具已成为提升效率的必备利器。如果你正在寻找一款能…...

SBQE:量子机器学习数据编码的创新方法
1. SBQE:量子机器学习数据编码的新范式量子计算领域最近迎来了一项突破性进展——SBQE(Shot-Based Quantum Encoding)数据编码方法。作为一名长期跟踪量子机器学习发展的研究者,我亲历了这项技术从理论提出到实验验证的全过程。SB…...

如何用ImageSearch在千万级图库中秒速找到任何图片:新手终极指南
如何用ImageSearch在千万级图库中秒速找到任何图片:新手终极指南 【免费下载链接】ImageSearch 基于.NET10的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 你是否曾因为找不到…...

碧蓝航线Live2D模型提取:3步快速获取游戏角色资源的完整指南
碧蓝航线Live2D模型提取:3步快速获取游戏角色资源的完整指南 【免费下载链接】AzurLaneLive2DExtract OBSOLETE - see readme / 碧蓝航线Live2D提取 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneLive2DExtract 你是否曾经想提取碧蓝航线中精美的Li…...
:从网络搭建到渐进式训练全流程)
手把手教你用PyTorch复现EfficientNetV2(附完整代码):从网络搭建到渐进式训练全流程
从零实现EfficientNetV2:代码级解析与渐进式训练实战 当你第一次翻开EfficientNetV2论文时,那些复杂的复合缩放系数和渐进式训练策略可能让人望而生畏。但别担心——本文将带你用PyTorch从最基础的卷积模块开始,逐层构建这个高效的视觉模型。…...

基于STC89C51单片机的多波形信号发生器设计与Proteus仿真
基于STC89C51单片机的多波形信号发生器设计与Proteus仿真 摘 要 随着电子技术和集成电路的飞速发展,信号发生器作为电子测量领域的基础设备,其性能和智能化水平不断提升。本设计以STC89C51单片机为控制核心,设计了一款多波形信号发生器。系统…...

从DesignCon 2011看EDA技术演进:高速链路、低功耗与3D-IC设计启示
1. 从一场行业盛会看电子设计的未来风向每年年初,硅谷的心脏地带——加州圣克拉拉,都会迎来一场电子设计自动化(EDA)与半导体设计领域的年度盛事:DesignCon。对于像我这样在硬件设计领域摸爬滚打了十几年的工程师来说&…...

工业物联网协议选型实战:从MQTT、DDS到CoAP的架构设计指南
1. 工业物联网数据连接协议全景解析在工业物联网这个领域摸爬滚打了十几年,我越来越深刻地体会到,一个项目的成败,往往在技术选型的起点上就埋下了伏笔。尤其是在数据连接协议的选择上,这绝不是简单地挑一个“最流行”或者“最新”…...