Java技术栈 —— Hadoop入门(一)
Java技术栈 —— Hadoop入门(一)
- 一、Hadoop第一印象
- 二、安装Hadoop
- 三、Hadoop解析
- 3.1 Hadoop生态介绍
- 3.1.1 MapReduce - 核心组件
- 3.1.2 HDFS - 核心组件
- 3.1.3 YARN - 核心组件
- 3.1.4 其它组件
- 3.1.4.1 HBase
- 3.1.4.2 Hive
- 3.1.4.3 Spark
一、Hadoop第一印象
Apache Hadoop ( /həˈduːp/) is a collection of open-source software utilities that facilitates using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.[2]
Apache Hadoop是一款开源软件,它集合了各种实用程序,这些实用程序通过计算机集群组成的网络,来帮助解决涉及大量数据和计算的问题。它使用MapReduce程序模型,为分布式存储与大数据计算提供了软件架构。
上面是Wiki的定义,Hadoop也称为大数据存储与计算的基础架构。
| 一、参考文章或视频链接 |
|---|
| [1] Apache Hadoop - Apache website |
| [2] Apache Hadoop - Wiki |
二、安装Hadoop
在执行文章[2]所说的./sbin/start-dfs.sh时,我遇到了一个报错
programmer@pc-ubuntu:~/DevelopEnvironment/hadoop-3.3.6$ ./sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: ssh: connect to host localhost port 22: Connection refused
Starting datanodes
localhost: ssh: connect to host localhost port 22: Connection refused
Starting secondary namenodes [pc-ubuntu]
pc-ubuntu: ssh: connect to host pc-ubuntu port 22: Connection refused
根据参考文章[3],需要提前准备环境与配置端口
sudo apt -y install openssh-server openssh-client
# {your_hadoop_home}/etc/hadoop/hadoop-env.sh file
export HADOOP_SSH_OPTS="-p 22"
pdsh是Parallel Distributed SHell并行分布式 Shell的缩写,是一种并行分布式运维工具。它可以并行执行对远程目标主机的操作,在有批量执行命令或分发任务的运维需求时,使用这个命令可达到事半功倍的效果。同时,PDSH还支持交互模式,当要执行的命令不确定时,可直接进入PDSH命令行,非常方便。
PDSH通常用于大批量服务器的配置、部署、文件复制等运维操作,在使用时,仍需要配置本地主机和远程主机间的单向SSH信任。另外,PDSH还附带了pdcp命令,此命令可以将本地文件批量复制到远程的多台主机上,这在大规模的文件分发环境下是非常有用的。但我在安装pdsh后反而出现了访问拒绝,请看参考文章[4]和[5]。
配置免密登录时的命令解析:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys这三行命令是用于生成和配置 SSH 密钥以进行安全的远程登录的操作。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa:
ssh-keygen:是 OpenSSH 提供的一个工具,用于生成 SSH 密钥对。
-t rsa:指定要生成的密钥类型为 RSA。
-P ‘’:表示为空密码,即不设置密码保护私钥。
-f ~/.ssh/id_rsa:指定生成的私钥文件的位置和名称。
执行这个命令后,会在指定的目录下生成一个名为id_rsa的私钥文件和一个名为id_rsa.pub的公钥文件。cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys:
cat:是一个文件操作命令,用于读取文件的内容并输出到标准输出。
~/.ssh/id_rsa.pub:表示读取私钥文件id_rsa中的公钥内容。
>> ~/.ssh/authorized_keys:表示将公钥内容追加到授权文件authorized_keys的末尾。
执行这个命令后,会将公钥内容添加到authorized_keys文件中,用于授权远程主机使用该公钥进行身份验证。chmod 0600 ~/.ssh/authorized_keys:
chmod:是一个文件权限操作命令,用于修改文件的权限。
0600:表示设置文件的权限为只有所有者有读写权限,其他人没有任何权限。
~/.ssh/authorized_keys:表示要修改权限的文件。
执行这个命令后,会将authorized_keys文件的权限设置为只有所有者可以读写,以增强安全性。- 综合起来,这三行命令的目的是生成 SSH 密钥对,将公钥添加到授权文件中,并设置授权文件的权限,以便进行安全的 SSH 远程登录。
最后按照参考文章[2]的描述,单机版Hadoop安装完成。

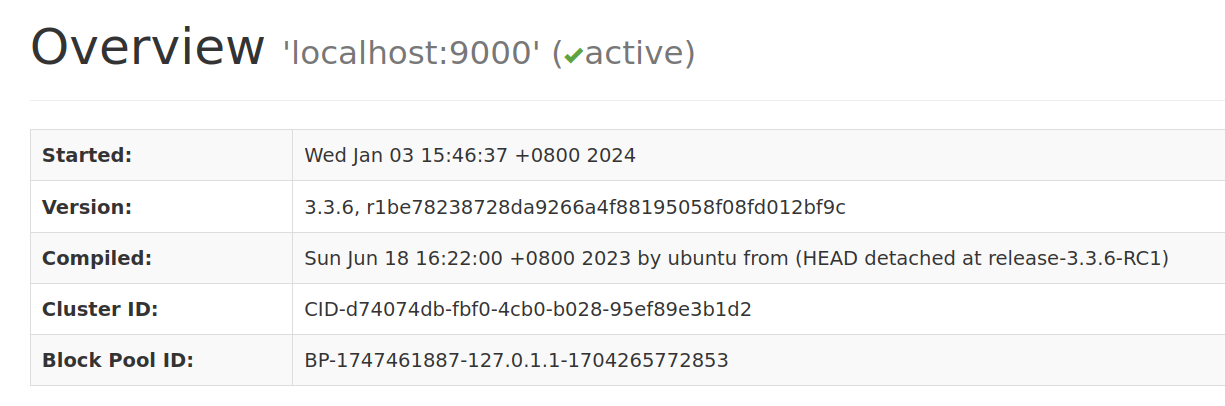
Hadoop 3.0.0版本后,访问地址从http://localhost:50070 变更为http://localhost:9870。[6] 看到如下访问效果后,你就可以愉快的开始与Hadoop玩耍了。
| 二、参考文章或视频链接 |
|---|
| [1] Apache Hadoop - Apache website |
| 重点参考:[2] 《史上最详细的hadoop安装教程(含坑点)》- CSDN |
| [3] Hadoop: connect to host localhost port 22: Connection refused when running start-dfs.sh - Stackoverflow |
| 这篇说卸载pdsh[4] 安装pdsh后反而pdsh Permission denied的问题 - Solution1 |
| 这篇说修改pdsh配置[5] 安装pdsh后反而pdsh Permission denied的问题 - Solution2 |
| [6] 安装pdsh后反而pdsh Permission denied的问题 - Solution2 |
三、Hadoop解析
3.1 Hadoop生态介绍
各程序员要紧紧围绕在以
Hadoop为核心的大数据生态周围,高举分布式的旗帜,发扬并行计算、高扩展性、高容错、高吞吐量、低成本的优势,真正做到学懂弄通、学深悟透、学以致用,扎实推进编程能力建设工作,久久为功,为大数据时代的产业兴旺添砖加瓦。
看到hadoop官网的左侧导航栏[1],可以证明,三大组件是HDFS、MapReduce、YARN,曾经被我弄混的HBase等词汇,则是Hadoop生态下的其中一个模块,而非Hadoop本身的核心组件,在更详细的介绍Hadoop之前,这些边界必须厘清,不然总有弄糊涂的一天。
Apache Hadoop的前身是Google的 Google File System (GFS),GFS也是一个分布式的文件系统,以下是一些Hadoop的特点
- Hadoop是高度可扩展的
- Hadoop相比于RDBMS关系型数据库管理系统,具有水平扩展的能力(即可以用堆机器的方式扩展系统,而非单独把一台机器配置拉满)
- Hadoop会创建并保存数据副本,以使其具有容错性。
- Hadoop具有经济性,组成它的机器一般都很便宜。
- Hadoop利用数据的局部性,去在存储数据的节点上处理数据,而不是将数据通过网络传来传去,从而浪费带宽。这一点特性就像你想看一本书,但是不能外借,你亲自去图书馆阅读
- Hadoop可以处理结构化,半结构化,无结构化的数据。这一点在当今时代尤为重要,因为大部分数据都没有格式定义的。

图1 - Hadoop 生态框架 —— 参考文章[2] PS:此图没画出模块之间的关系

图2 - Hadoop 生态框架 —— 参考文章[6]
| 3.1 参考文章或视频链接 |
|---|
| [1] Hadoop Documentation- Apache |
| 重点阅读:[2] Introduction to the Hadoop Ecosystem for Big Data and Data Engineering - Analytics Vidhya |
| [3] 大数据学习(二)Hadoop - 知乎 |
| [4] Hadoop Ecosystem |
| [5] Hadoop Ecosystem Components and Its Architecture |
| [6] Hadoop Ecosystem - A Comprehensive Guide for 2024 |
3.1.1 MapReduce - 核心组件
话说天下大势,合久必分,分久必合。——《三国演义》
但是分合之后,将是不同的历史阶段,就像化学反应也是原子的分合,经过剧烈的反应之后,事物已经产生了质的变化,这体现了一个道理:“内部矛盾是事物发展的源泉,决定着事物的性质和发展方向”。
MapReduce由Google公司提出,论文名称是 MapReduce: Simplified Data Processing on Large Clusters,作者是Jeffrey Dean and Sanjay Ghemawat,第一个作者Jeffrey Dean牛到什么程度?他是Tensorflow项目的负责人😮,太牛了,牛的冒烟了,已经翱翔了,这谁跟的了啊,这个人假以时日,必成大器,其余请自行百度。可以看到下面这张图,Map就是拆解,Reduce就是组合,Map计算各个key对应的value,Reduce将相同的key的value整合起来。
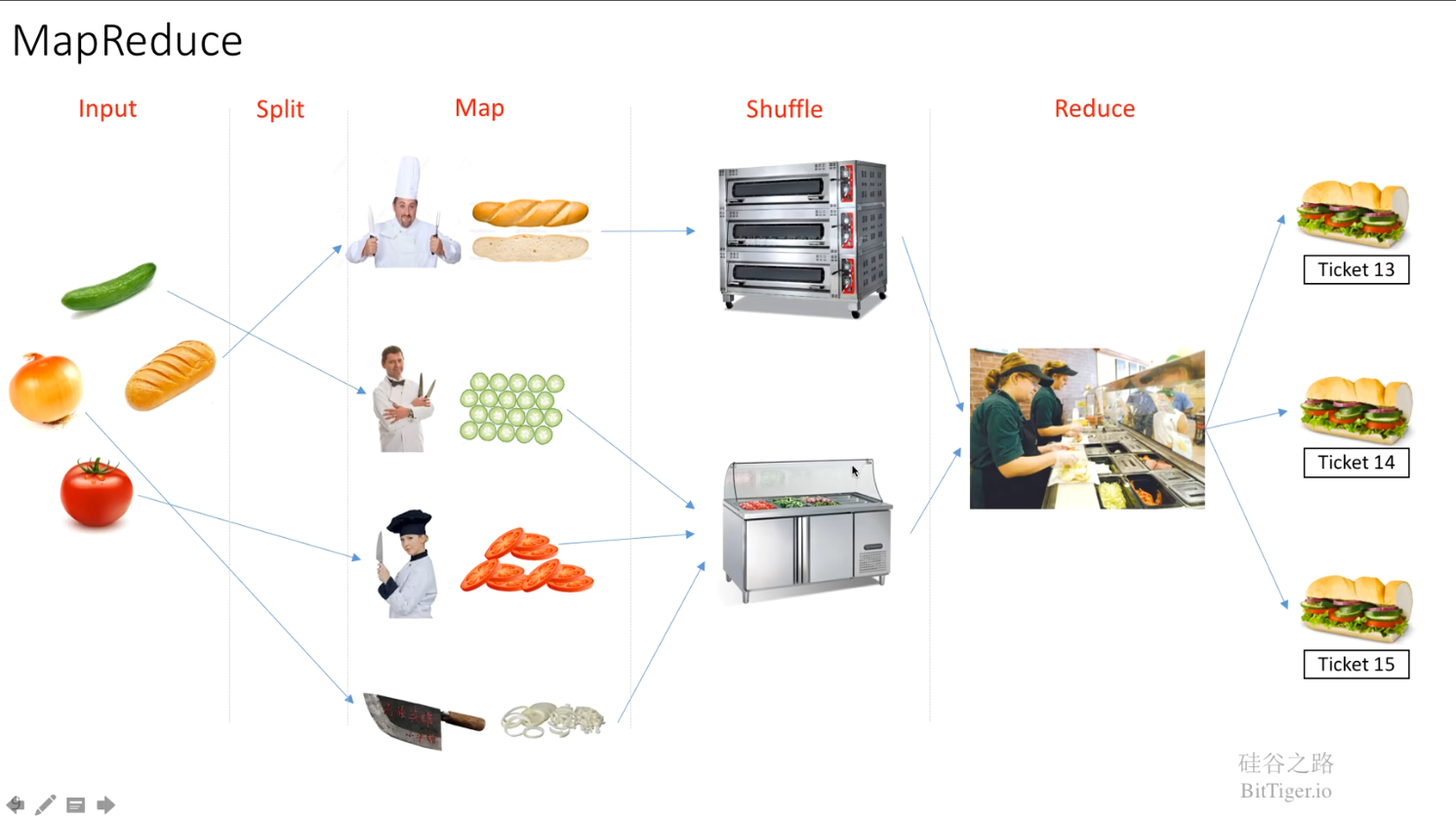
图3 - MapReduce原理图 (来自【深入浅出讲解 MapReduce】- bilibili)
| 3.1.1 参考文章或视频链接 |
|---|
| [1] MapReduce: Simplified Data Processing on Large Clusters.pdf CSDN资源地址(免费):MapReduce: Simplified Data Processing on Large Clusters.pdf |
| [2] 《深入浅出讲解 MapReduce》- bilibili |
| [3] 《【狂野大数据】一天搞定大数据之MapReduce》- bilibili |
| [4] 《关于谷哥传奇工程师Jeff Dean的笑话》 |
| [5] Jeff Dean - 百度百科 |
| [6] 有谁可以介绍一下谷歌大牛Jeff Dean以及与他相关的事迹么? - 知乎 |
| [7] 《Markdown 使用 Emoji 表情》- CSDN |
| [8] MapReduce可不可以只要Reduce不要Map?- bilibili spark中可以直接reduce |
3.1.2 HDFS - 核心组件
HDFS(Hadoop Distributed File System 存储的文件系统)
3.1.3 YARN - 核心组件
YARN = Yet Another Resource Negotiator,直译为另一种资源协调者,那么意译就是Hadoop的资源管理系统,
想想Hadoop的这三大核心组件,和古代的三省六部,有什么共同之处?中书省(决策)、门下省(审核)、尚书省(执行),我以为不能牵强附会,将三省的功能对应到这三大组件上,因为从功能角度来说对不上号,但是这种系统的设计思想和模式,却在Hadoop和三省六部制度中,都得到了体现,作为程序员,你能设计一个好用的系统和代码框架,理论上说,也具备设计制度的能力,从这个意义出发,你可以说,计算机里面哪有什么编程和打打杀杀,都是江湖。
注意,Linux里也有一个工具叫做yarn,Hadoop的YARN和Linux的YARN两个是不同的事物,但都有资源管理的意思在,有人说Linux里的yarn是Yet Another Replacing NPM的缩写,不过根据开发者的回答,这种说法应该只是个巧合,Stackoverflow有人提过这个问题。[1]
| 3.1.3 参考文章或视频链接 |
|---|
| [1] What does yarn (package manager) (in Linux) stand for? |
3.1.4 其它组件
3.1.4.1 HBase
HBase is a Column-based
NoSQL database. Itruns on top of HDFSandcan handle any type of data. It allows forreal-time processingandrandom read/write operationsto be performed in the data.[1]
图2中,HBASE是在HDFS之上的,这也印证了 runs on top of HDFS 的说法,这里有点可以类比与MySQL底层使用B+树作为存储结构的意思了。具体可以看参考文章
| 3.1.4.1 参考文章或视频链接 |
|---|
| 重点阅读:[1] Introduction to the Hadoop Ecosystem for Big Data and Data Engineering - Analytics Vidhya |
| [2] 《Hbase 和 MySQL 的区别是什么?一文深度对比!》 |
| [3] 《美团一面:为什么选用Hbase,Hbase和MySQL的区别是什么?》 |
| [4] 【头条面试:请描述MySQL的B+树索引原理,B+树索引有哪些好处】- bilibili |
| 重点观看:[5] 【B+树,B-link树,LSM树…一个视频带你了解常用存储引擎数据结构(中)】- bilibili |
3.1.4.2 Hive
Hive is a distributed data warehouse system developed by Facebook. It allows for easy reading, writing, and managing files on HDFS. It has its own querying language for the purpose known as Hive Querying Language (HQL) which is very similar to SQL. This makes it very easy for programmers to write MapReduce functions using simple HQL queries.[1]
Hive是一款由Facebook开发的分布式数据仓库系统,它可以很方便的在HDFS的基础上进行文件读写与管理。Hive有自己的查询语言,名为Hive Querying Language (HQL),HQL与SQL很像,这使得程序员可以非常方便的使用HQL查询编写MapReduce的函数
由此我们可以看出Hive与HDFS也是不一样的,其具体区别
| 3.1.4.2 参考文章或视频链接 |
|---|
| 重点阅读:[1] Introduction to the Hadoop Ecosystem for Big Data and Data Engineering - Analytics Vidhya |
| [2] Hive VS HBase: What Is The Difference? |
3.1.4.3 Spark
Apache Spark 是用于大数据工作负载的开源分布式处理系统。它利用内存中缓存和优化的查询执行,对任何大小的数据进行快速分析查询。它提供 Java、Scala、Python 和 R 语言的开发 API,并支持跨多个工作负载(批处理、交互式查询、实时分析、机器学习和图形处理)重用代码。[2]
| 3.1.4.3 参考文章或视频链接 |
|---|
| [1] Introduction to the Hadoop Ecosystem for Big Data and Data Engineering - Analytics Vidhya |
| [2] What is Apache Spark? |
相关文章:
Java技术栈 —— Hadoop入门(一)
Java技术栈 —— Hadoop入门(一) 一、Hadoop第一印象二、安装Hadoop三、Hadoop解析3.1 Hadoop生态介绍3.1.1 MapReduce - 核心组件3.1.2 HDFS - 核心组件3.1.3 YARN - 核心组件3.1.4 其它组件3.1.4.1 HBase3.1.4.2 Hive3.1.4.3 Spark 一、Hadoop第一印象…...
Shell脚本小游戏:石头剪刀布
脚本代码: #!/bin/bash echo "接下来的是石头剪刀布的游戏" echo "定义1:包子;2:剪刀;3:布" echo "------------------------------" NUMecho $[RANDOM%31] #1包子 #2剪刀…...
Windows10系统的音频不可用,使用疑难解答后提示【 一个或多个音频服务未运行】
一、问题描述 打开电脑,发现电脑右下角的音频图标显示为X(即不可用,无法播放声音),使用音频自带的【声音问题疑难解答】(选中音频图标,点击鼠标右键,然后选择“声音问题疑难解答(T)”…...

Unity | 渡鸦避难所-5 | 角色和摄像机之间的遮挡物半透明
1 前言 角色在地图上移动到岩石后面时,完全被岩石遮挡,玩家只能看到岩石。这逻辑看起来没问题,但并不是玩家想要看到的画面,玩家更希望关注角色的状态 为了避免角色被遮挡,可以使用 Cinemachine Collider 功能&#x…...

ResNet论文阅读和简单实现
论文:https://arxiv.org/pdf/1512.03385.pdf Deep Residual Learning for Image Recognition 本模块主要是阅读论文,会做简单的翻译(至少满足我自己能看明白)。 Introduction 由上图可见,在20层和56层的网络上训练的…...
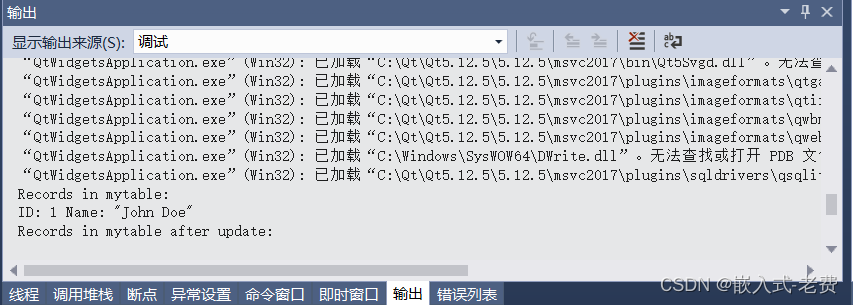
QT上位机开发(数据库sqlite编程)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 编写软件的时候,如果用户的数据比较少,那么用json保存是非常方便的。但是一旦数据量大了之后,建议还是用数据库…...

在ARMv8中aarch64与aarch32切换
需求描述 在项目调试过程中,由于内存或磁盘空间不足需要将系统从aarch64切换到aarch32的运行状态去执行,接下来记录cortexA53的调试过程。 相关寄存器描述 ARM64: SPSR_EL3 N (Negative):表示运算结果的最高位,用于指示运算结果是否为负数。 Z (Zero):表示运算结果是否…...

拧巴的 tcp
本来想说说 tcp fastopen(tfo),但没什么意义,看 rfc7413 好了,还是 tcp 的惯常套路,引入一个新特性,解决了某个问题,带来一些新问题,然后就是各种 tradeoff,哪里适用哪里不适用。久而…...

java servlet 学生管理系统myeclipse开发oracle数据库BS模式java编程网
一、源码特点 java servlet 学生管理系统是一套完善的web设计系统,对理解JSP java编程开发语言有帮助servletbeandao (mvc模式开发),系统具有完整的源代码和数据库,开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Oracle 10g…...

使用buildx构建多架构镜像
使用buildx构建多架构镜像 1. 前置条件 docker 19.03以上版本 ubuntu 22.04 2. 安装相关组件 2.1 安装docker sudo apt-get updatesudo apt-get install \apt-transport-https \ca-certificates \curl \gnupg-agent \software-properties-commoncurl -fsSL https://mirrors.…...

Crow:run的流程4 准备接收http请求
完成tcp的accept后,下一步需要接收tcp的数据,同时完成http的分析 class Connection { public:void start(){adaptor_.start([this](const asio::error_code& ec) {if (!ec){start_deadline();parser_.clear();do_read();}else{CROW_LOG_ERROR << "Could not …...
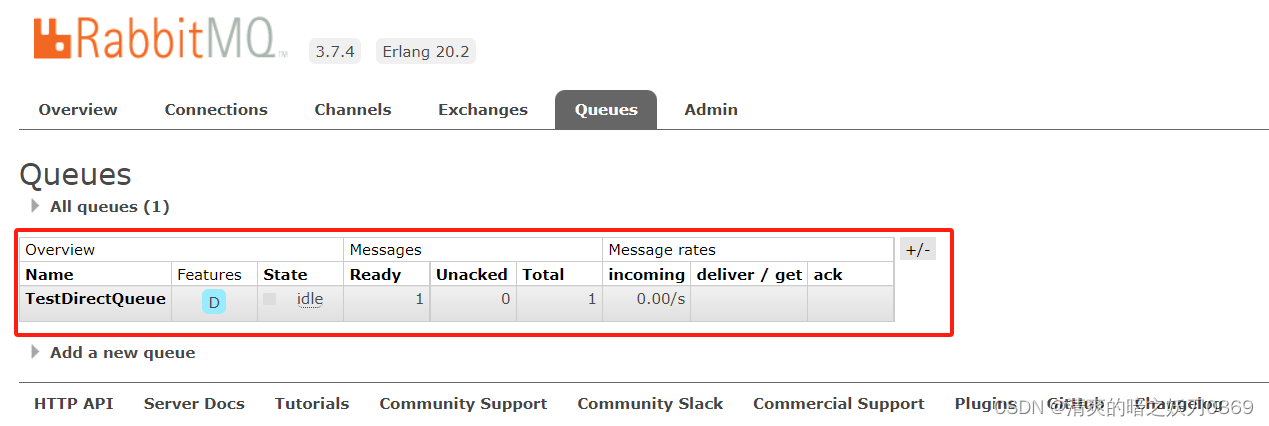
Springboot集成RabbitMq一
0、知识点 1、创建项目-生产者 默认官方start.spring.io已不支持自动生成低版本jkd的Spring项目,自定义用阿里云的starter即可:https://start.aliyun.com 2、创建配置类 package com.wym.rabbitmqprovider.utils;import org.springframework.amqp.core.…...

零知识证明(zk-SNARK)- groth16(一)
全称为 Zero-Knowledge Succinct Non-Interactive Argument of Knowledge,简洁非交互式零知识证明,简洁性使得运行该协议时,即便 statement 非常大,它的 proof 大小也仅有几百个bytes,并且验证一个 proof 的时间可以达…...

Spring java和go并发的实现策略
Spring Java框架和Go框架在处理并发请求时采用了不同的策略。 1. Spring Java框架: Spring框架基于Java语言,通常使用线程池来处理并发请求。具体来说,Spring框架中的Servlet容器(如Tomcat、Jetty等)会使用线程池来管…...

第二十五章 JDBC 和数据库连接池
一、JDBC 概述(P821) 1. 基本介绍 (1)JDBC 为访问不同的数据库提供了统一的接口,为使用者屏蔽了细节问题。 (2)Java 程序员使用 JDBC,可以连接任何提供了 JDBC 驱动程序的数据库系统…...
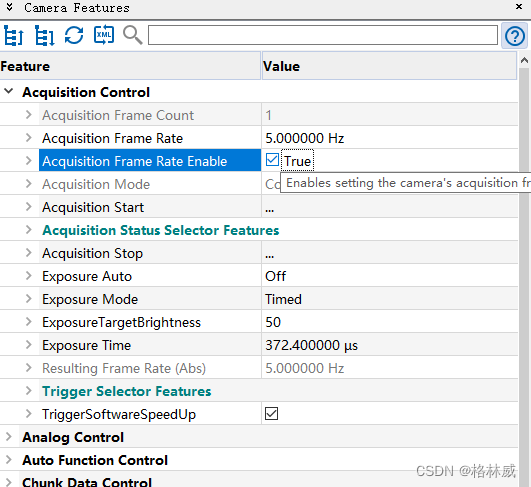
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的固定帧率(C++)
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的固定帧率(C) Baumer工业相机Baumer工业相机的固定帧率功能的技术背景CameraExplorer如何查看相机固定帧率功能在NEOAPI SDK里通过函数设置相机固定帧率 Baumer工业相机通过NEOAPI SDK设置相机固定…...

基于Java课堂签到系统
基于Java课堂签到系统 功能需求 1、用户登录:学生需要使用学号或手机号等唯一标识登录系统。 2、签到功能:在课堂开始时,学生可以通过系统进行签到,以证明出席。 3、签出功能:在课堂结束时,学生可以通过…...

springboot整合webservice使用总结
因为做的项目中用到了webservice,所以在此总结一下。 一、webservice简介 Web Service也叫XML Web Service, WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术。是通过SOAP在Web上提供的软件服务,使…...

MySQL中的索引之分类,原理,作用,优缺点和执行计划
索引 索引的作用:加速查找 例如: 300w条数据的表中查询,无索引需要700s, 利用索引可能只需要1s用索引的时机是,数据量巨大,并且搜索快速 索引为什么能实现加速查找 基于索引的内部存储结构索引底层基于 BTree 的数据结构存储的在…...

如何做好档案数字化前的鉴定工作
要做好档案数字化前的鉴定工作,可以按照以下步骤进行: 1. 确定鉴定目标:明确要鉴定的档案的内容、数量和性质,确定鉴定的范围和目标。 2. 进行档案清点:对档案进行全面清点和登记,包括数量、种类、状况等信…...

Obsidian Importer:一站式笔记数据迁移终极指南
Obsidian Importer:一站式笔记数据迁移终极指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-importer …...

LTspice仿真波形图看不清?这4个隐藏操作技巧让你效率翻倍
LTspice波形分析进阶指南:4个被低估的高效操作技巧 当电路仿真结果呈现在眼前时,多数用户会本能地拖动鼠标进行粗略查看。但真正的高手知道,波形分析阶段的细微操作差异,往往决定了问题定位的效率与设计迭代的速度。本文将揭示那些…...
LunaTranslator完整指南:5步掌握视觉小说实时翻译技巧
LunaTranslator完整指南:5步掌握视觉小说实时翻译技巧 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 想要畅玩日文视觉小说却苦于语言障碍?LunaT…...

基于谐波补偿的多环路控制双向DC-AC逆变器建模
目录 手把手教你学Simulink——基于谐波补偿的多环路控制双向DC-AC逆变器建模 一、背景与挑战 1.1 为什么需要“谐波补偿多环路”? 1.2 核心痛点与设计目标 二、系统架构与核心控制推导 2.1 整体架构:主环路 谐波补偿环路的“分工合作” 2.2 核心…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...

LinkSwift:九大网盘直链下载的技术革新与优雅突围
LinkSwift:九大网盘直链下载的技术革新与优雅突围 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

回溯52-59
52. 全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 class Solution(object):def fun(self,nums,path):if len(path)len(nums):self.res.append(path[:])for i in range(len(nums)):if self.visit[i]0:self.vi…...

AISuperDomain:构建AI API智能网关,解决网络延迟与高可用难题
1. 项目概述与核心价值最近在折腾一些自动化脚本和本地化AI应用时,我遇到了一个挺普遍但又有点烦人的问题:如何让我的程序能稳定、高效地访问那些部署在境外的AI服务API,比如OpenAI、Claude或者一些开源的模型托管平台。直接调用?…...
)
DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板) DeepSeek Chat 作为开源大语言模型对话接口,其生产就绪性需通过结构化、可…...

从硬开关到软开关:推挽谐振变换器原理与PSIM仿真实战
1. 从经典到谐振:为什么我们需要推挽变换器?在电源设计的工具箱里,推挽变换器(Push-Pull Converter)绝对算得上是一位“老将”。它的核心思想非常直观:利用一个带中心抽头的变压器,让两个开关管…...