ES(Elasticsearch)的基本使用
一、常见的NoSQL解决方案
1、redis
Redis是一个基于内存的 key-value 结构数据库。Redis是一款采用key-value数据存储格式的内存级NoSQL数据库,重点关注数据存储格式,是key-value格式,也就是键值对的存储形式。与MySQL数据库不同,MySQL数据库有表、有字段、有记录,Redis没有这些东西,就是一个名称对应一个值,并且数据以存储在内存中使用为主。redis的基本使用
2、mongodb
- MongoDB可以在内存中存储类似对象的数据并实现数据的快速访问。
- 使用Redis技术可以有效的提高数据访问速度,但是由于Redis的数据格式单一性,无法操作结构化数据,当操作对象型的数据时,Redis就显得捉襟见肘。在保障访问速度的情况下,如果想操作结构化数据,看来Redis无法满足要求了,此时需要使用全新的数据存储结束来解决此问题,即MongoDB技术。mongodb的基本使用
3、ES(Elasticsearch)
- ES(Elasticsearch)是一个分布式全文搜索引擎,重点是全文搜索。
二、ES的使用
ES简介
- es是由Apache开源的一个兼有搜索引擎和NoSQL数据库功能的系统,其特点主要如下。
-
- 基于Java/Lucene构建,支持全文搜索、结构化搜索(应用于加速数据的查询)
-
- 低延迟,支持实时搜索
-
- 分布式部署,可横向集群扩展
-
- 支持百万级数据
-
- 支持多条件复杂查询,如聚合查询
-
- 高可用性,数据可以进行切片备份
-
- 支持Restful风格的api调用
-
全文搜索
-
全文搜索的理解:
比如用户要在淘宝上买一本书(Java开发),那么他就可以以Java为关键字进行搜索,不管是书名中还是书的介绍中,甚至是书的作者名字,只要包含java就作为查询结果返回给用户查看。这就可以理解为全文搜索。- 搜索的条件不再是仅用于对某一个字段进行比对,而是在一条数据中使用搜索条件去比对更多的字段,只要能匹配上就列入查询结果,这就是全文搜索的目的。而ES技术就是一种可以实现上述效果的技术。
-
全文搜索的实现:
要实现全文搜索的效果,不可能使用数据库中like操作去进行比对,这种效率太低了。ES设计了一种全新的思想,来实现全文搜索。具体操作过程如下:-
- 将被查询的字段的数据全部文本信息进行拆分,分成若干个词
- 例如“中华人民共和国”就会被拆分成三个词,分别是“中华”、“人民”、“共和国”,此过程有专业术语叫做分词。分词的策略不同,分出的效果不一样,不同的分词策略称为分词器。
-
- 将分词得到的结果存储起来,对应每条数据的id
- 例如id为1的数据中名称这一项的值是“中华人民共和国”,那么分词结束后,就会出现“中华”对应id为1,“人民”对应id为1,“共和国”对应id为1
- 例如id为2的数据中名称这一项的值是“人民代表大会“,那么分词结束后,就会出现“人民”对应id为2,“代表”对应id为2,“大会”对应id为2
- 此时就会出现如下对应结果,按照上述形式可以对所有文档进行分词。需要注意分词的过程不是仅对一个字段进行,而是对每一个参与查询的字段都执行,最终结果汇总到一个表格中
分词结果关键字 对应id 中华 1 人民 1,2 共和国 1 代表 2 大会 2 -
- 当进行查询时,如果输入“人民”作为查询条件,可以通过上述表格数据进行比对,得到id值1,2,然后根据id值就可以得到查询的结果数据了。
-
-
上述过程中分词结果关键字内容每一个都不相同,作用有点类似于数据库中的索引,是用来加速数据查询的。
- 但是数据库中的索引是对某一个字段进行添加索引,而这里的分词结果关键字不是一个完整的字段值,只是一个字段中的其中的一部分内容。并且索引使用时是根据索引内容查找整条数据,全文搜索中的分词结果关键字查询后得到的并不是整条的数据,而是数据的id,要想获得具体数据还要再次查询,因此这里为这种分词结果关键字起了一个全新的名称,叫做倒排索引。
ES的应用场景
- ES作为全文检索的搜索引擎,在以下几个方面都存在着相应的应用:
-
- 监控。针对日志类数据进行存储、分析、可视化。针对日志数据,ES给出了ELK的解决方案。其中logstash采集日志,ES进行复杂的数据分析,kibana进行可视化展示。
-
- 电商网站。用于商品信息检索。
-
- Json文档数据库。用于存放json格式的文档
-
- 维基百科。提供全文搜索并高亮关键字
-
Es的windows版安装
-
windows版安装包下载地址:https://www.elastic.co/cn/downloads/elasticsearch
- 下载zip文件,然后直接解压即可,解压完的目录如下:(data目录,是使用了数据库后自己给你创建的,里面的存放的就是你ES数据库的文件)
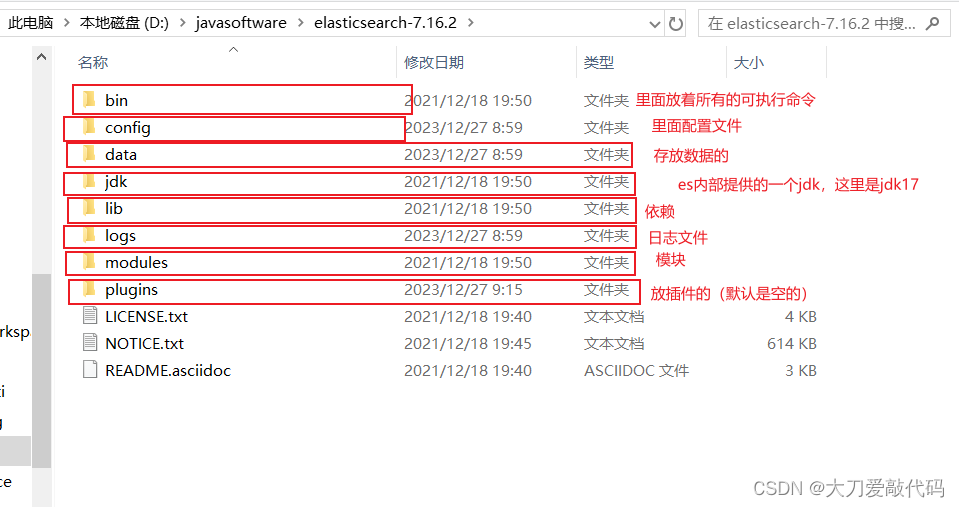
- 下载zip文件,然后直接解压即可,解压完的目录如下:(data目录,是使用了数据库后自己给你创建的,里面的存放的就是你ES数据库的文件)
-
ES的运行:在bin目录下,双击elasticserach.bat文件。(默认端口号:9200)
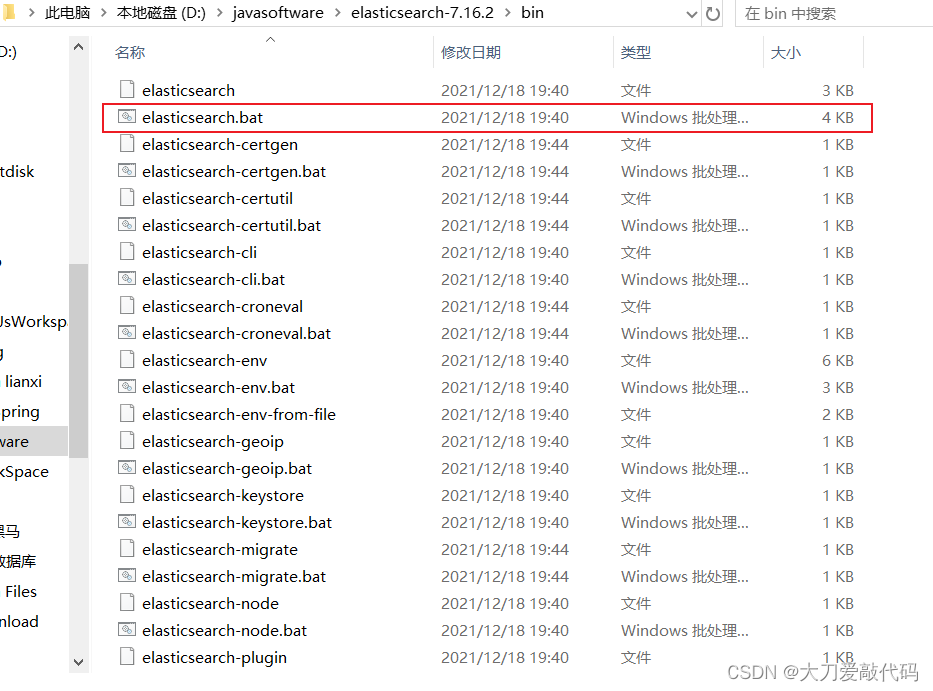
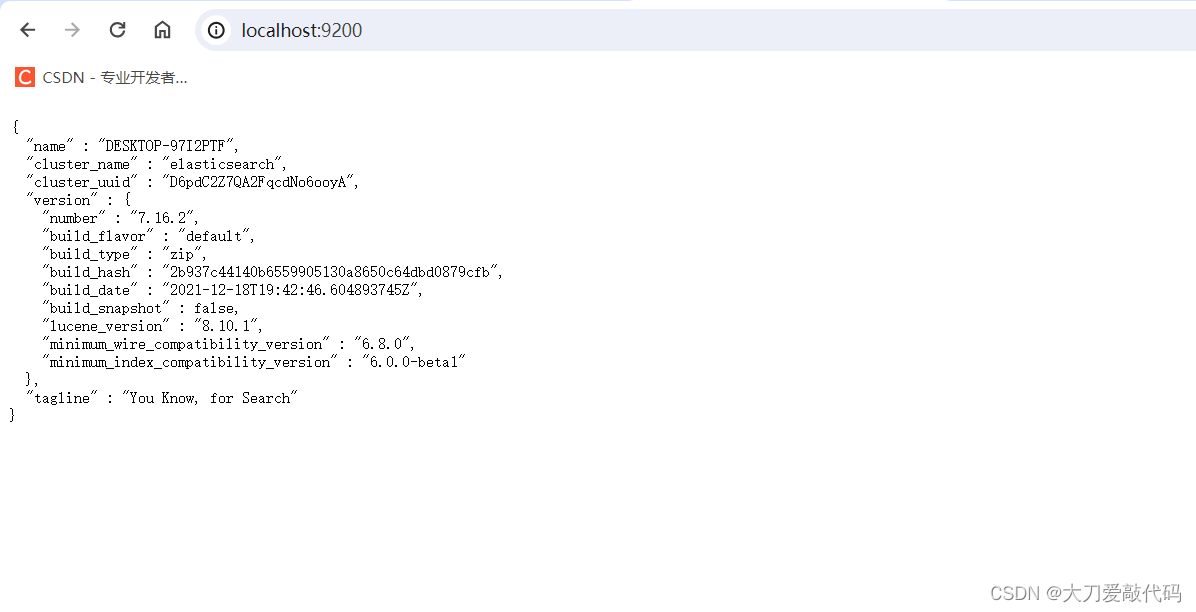
然后访问:http://localhost:9200/,看到下面的json数据后,表示es已经启动成功。
ES的基础操作
ES的基础操作-----索引操作
- 对于mysql数据库,我们一般需要创建数据库之后才能继续操作,而ES则需要创建索引之后才能继续操作。
- 对于es的操作,我们只需要发web请求就可以了。要操作ES可以通过Rest风格的请求来进行(因为它支持rest风格,可以使用postman进行操作),也就是说发送一个请求就可以执行一个操作。比如新建索引,删除索引这些操作都可以使用发送请求的形式来进行。
- ES中保存的数据,只是格式和数据库存储的数据格式 与我们的mysql等数据库不同而已。
- 在ES中我们要先创建倒排索引,这个索引的功能又有点类似于数据库的表。
- 然后将数据添加到倒排索引中,添加的数据称为文档。
- 所以要进行ES的操作要先创建索引,再添加文档,这样才能进行后续的查询操作。
不具备分词效果的索引的创建(没有指定分词器)
创建索引:注意这里使用的请求方式是put而不是post
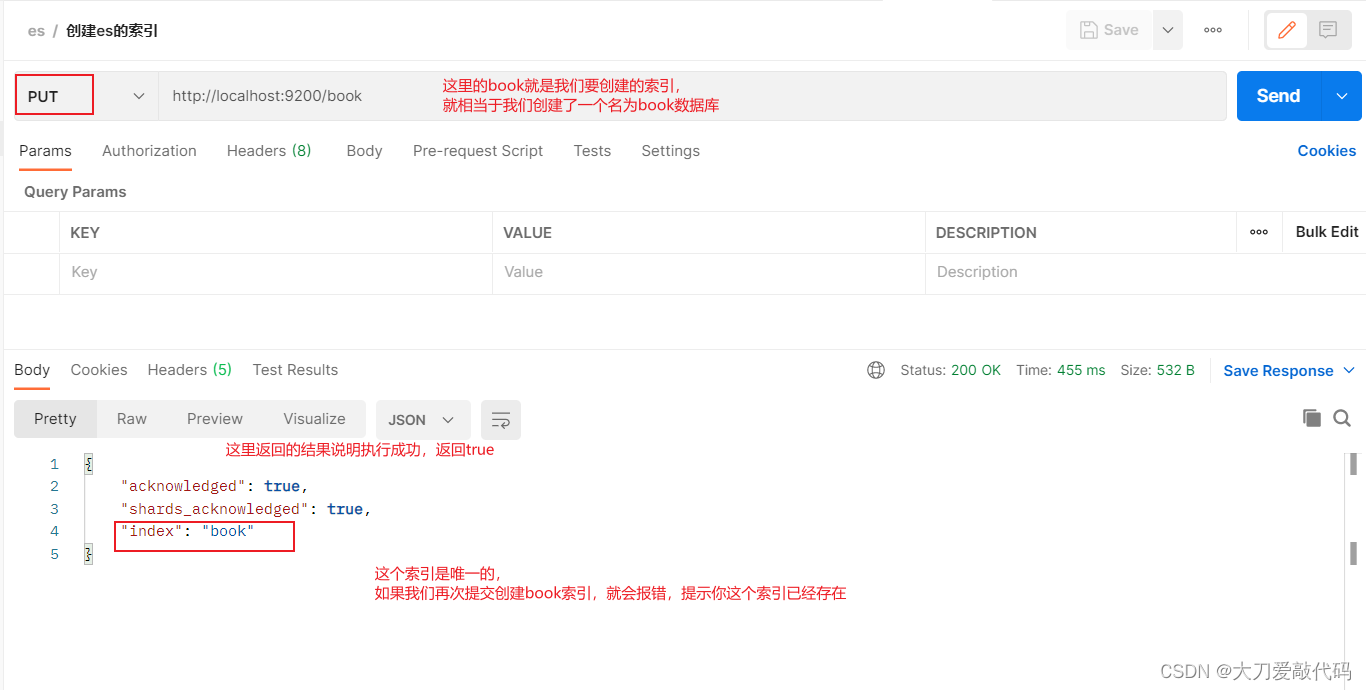
获取索引
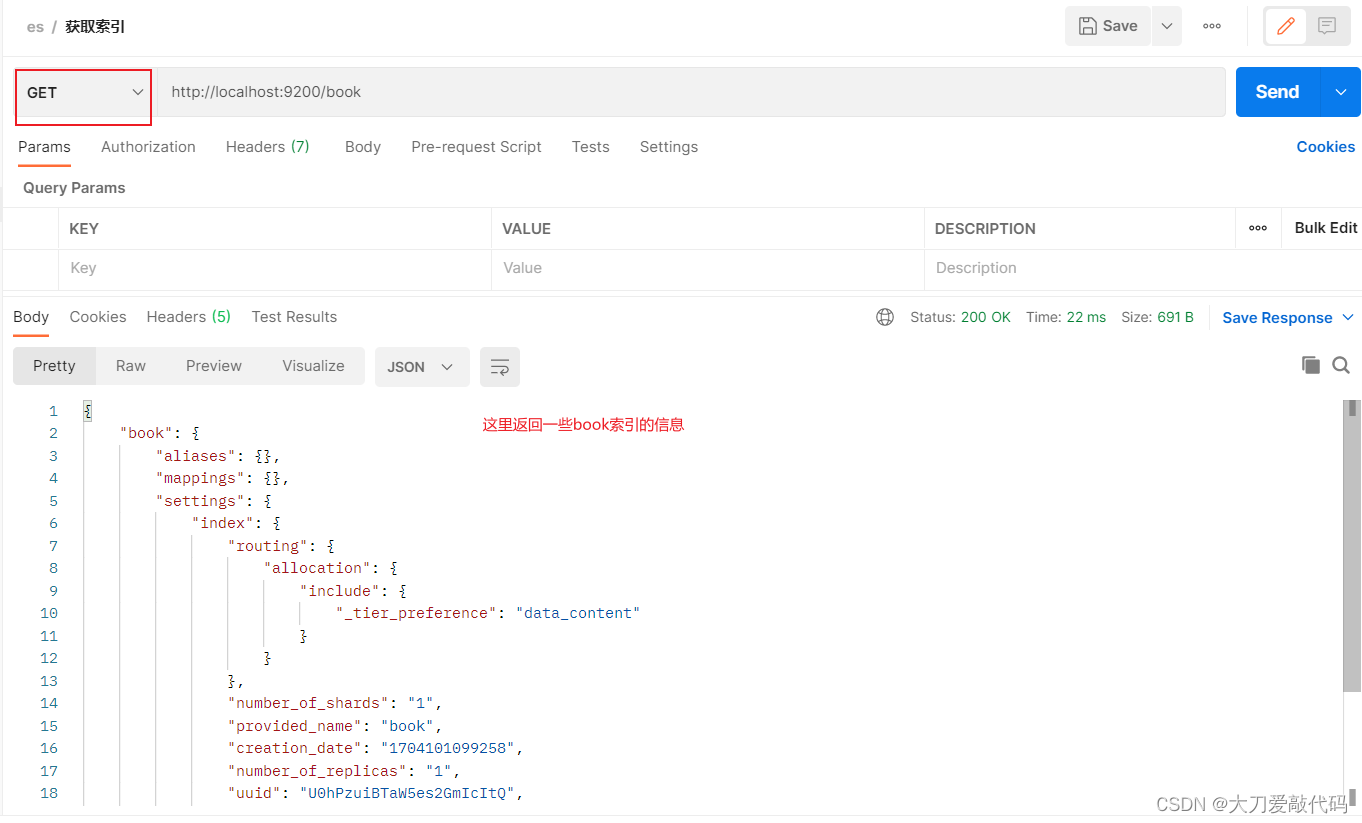
获取无分词器的索引返回的信息:
{"book": {"aliases": {},"mappings": {},"settings": {"index": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "book","creation_date": "1704103713618","number_of_replicas": "1","uuid": "1mabgD9eR7WvHVZeCBfVqw","version": {"created": "7160299"}}}}
}
删除索引

利用分词器进行创建索引(创建索引并指定分词器)
- 我们在创建索引时,可以添加请求参数,设置分词器。
- ik分词器的下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 分词器下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。使用IK分词器创建索引格式:
创建带分词器的索引:创建索引并指定规则

参数数据如下:
{"mappings":{ //mapping表示:定义mappings属性,替换创建索引时对应的mappings属性"properties":{ // properties表示:定义索引中包含的属性设置(属性是自定义的)"id":{ // 设置索引中包含id属性(相当于数据库表中创建一个id字段)"type":"keyword" //设置当前属性为关键字,可以被直接搜索},"name":{ // 设置索引中包含name属性"type":"text", //设置当前属性是文本信息,参与分词 "analyzer":"ik_max_word", //选择当前属性的分词策略,这里表示使用IK分词器进行分词 "copy_to":"all" // 表示把分词结果拷贝到all属性中,即all属性中也有name属性同样的作用},"type":{"type":"keyword"},"description":{"type":"text","analyzer":"ik_max_word","copy_to":"all"},"all":{ //all是一个定义属性(虚拟的属性,数据库中不存在的属性),用来描述多个字段的分词结果集合,当前属性可以参与查询"type":"text","analyzer":"ik_max_word"}}}
}
查询带分词器的索引
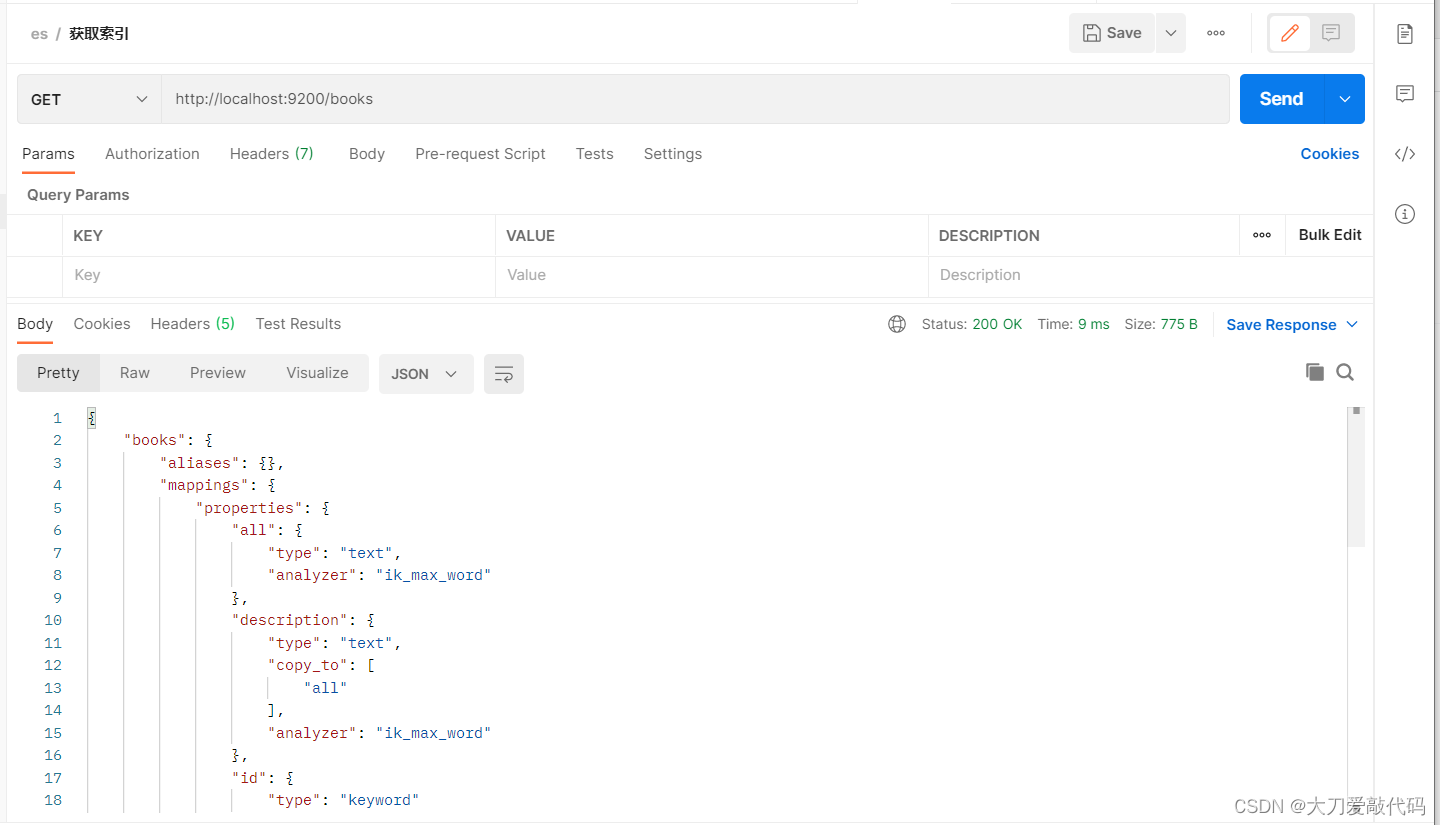
返回值:(与前面的查询不带分词器的相比,会发现mappings里面多了很多数据信息)
{"books": {"aliases": {},"mappings": { //mappings属性已经被替换"properties": {"all": {"type": "text","analyzer": "ik_max_word"},"description": {"type": "text","copy_to": ["all"],"analyzer": "ik_max_word"},"id": {"type": "keyword"},"name": {"type": "text","copy_to": ["all"],"analyzer": "ik_max_word"},"type": {"type": "keyword"}}},"settings": {"index": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "books","creation_date": "1704103876876","number_of_replicas": "1","uuid": "nQ2Jmml6QSOGwOI2cswwJw","version": {"created": "7160299"}}}}
}
ES的基础操作-----文档操作
- 前面我们已经创建了索引了,但是索引中还没有数据,所以要先添加数据,ES中称数据为文档,下面进行文档操作。
添加文档:
- 添加文档有三种方式:创建books索引下的文档
POST请求 http://localhost:9200/books/_doc #使用系统生成id(自动帮你创建)
POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增)POST请求 http://localhost:9200/books/_create/1 #使用指定id(必须指定id)
传参数据一般不使用id属性:因为指定了也不会生效,要么默认帮你创建,要么在请求路径上进行指定
参数的使用:
{"id": 1, //一般不使用这一行"name": "springboot1","type": "book","desctiption": "an book"
}
第一种请求方式:
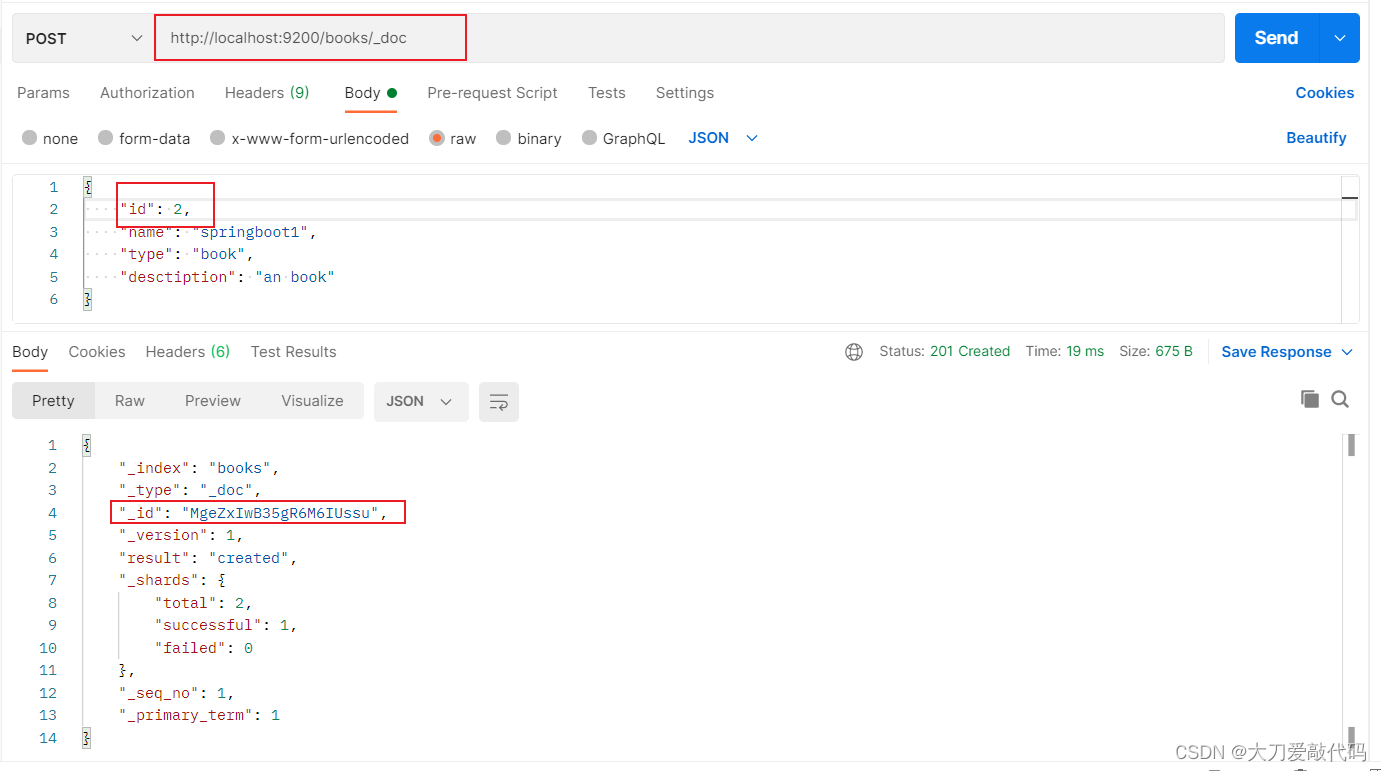
返回结果:
{"_index": "books","_type": "_doc","_id": "MgeZxIwB35gR6M6IUssu","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1
}
第二种请求方式:

返回结果:
{"_index": "books","_type": "_doc","_id": "55","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1
}第三种请求方式:
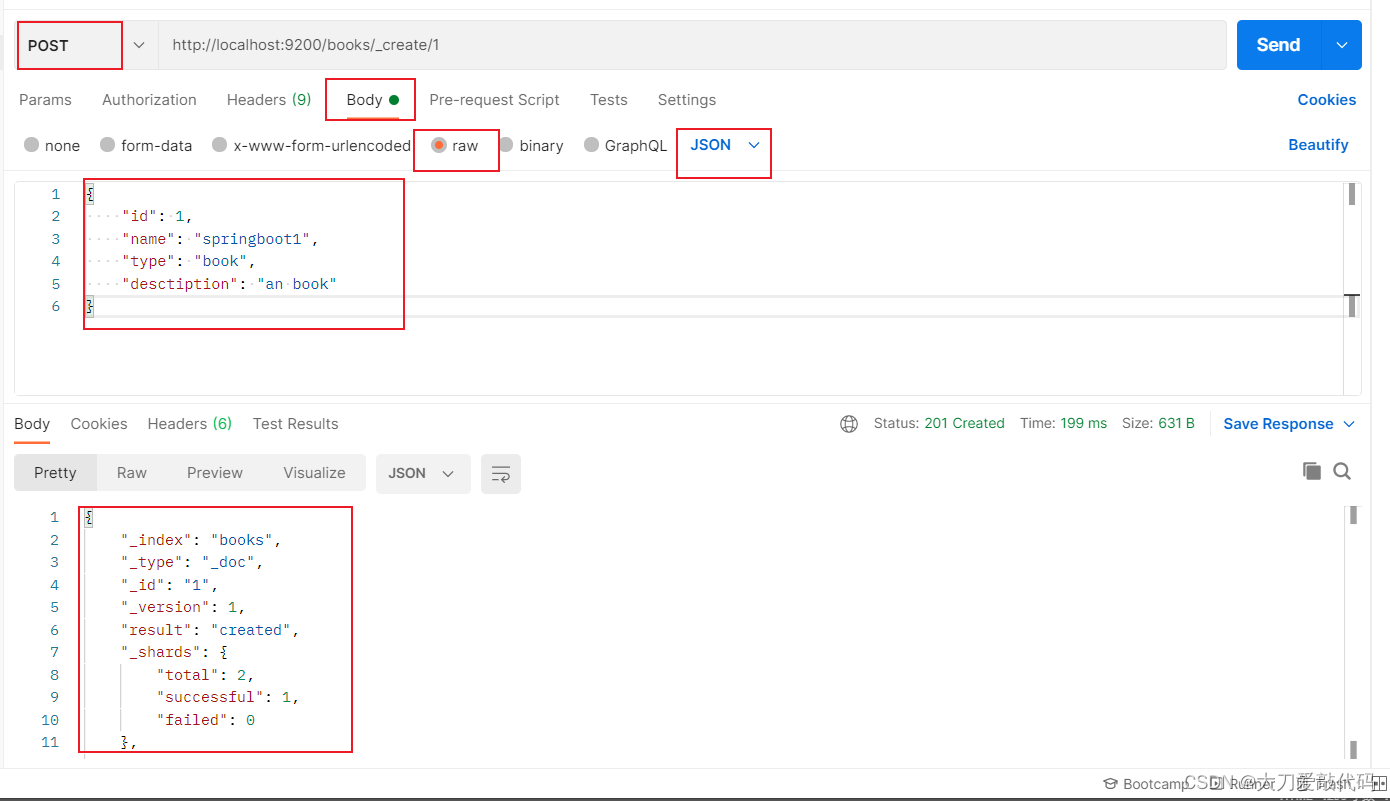
返回结果:
{"_index": "books","_type": "_doc","_id": "1","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}
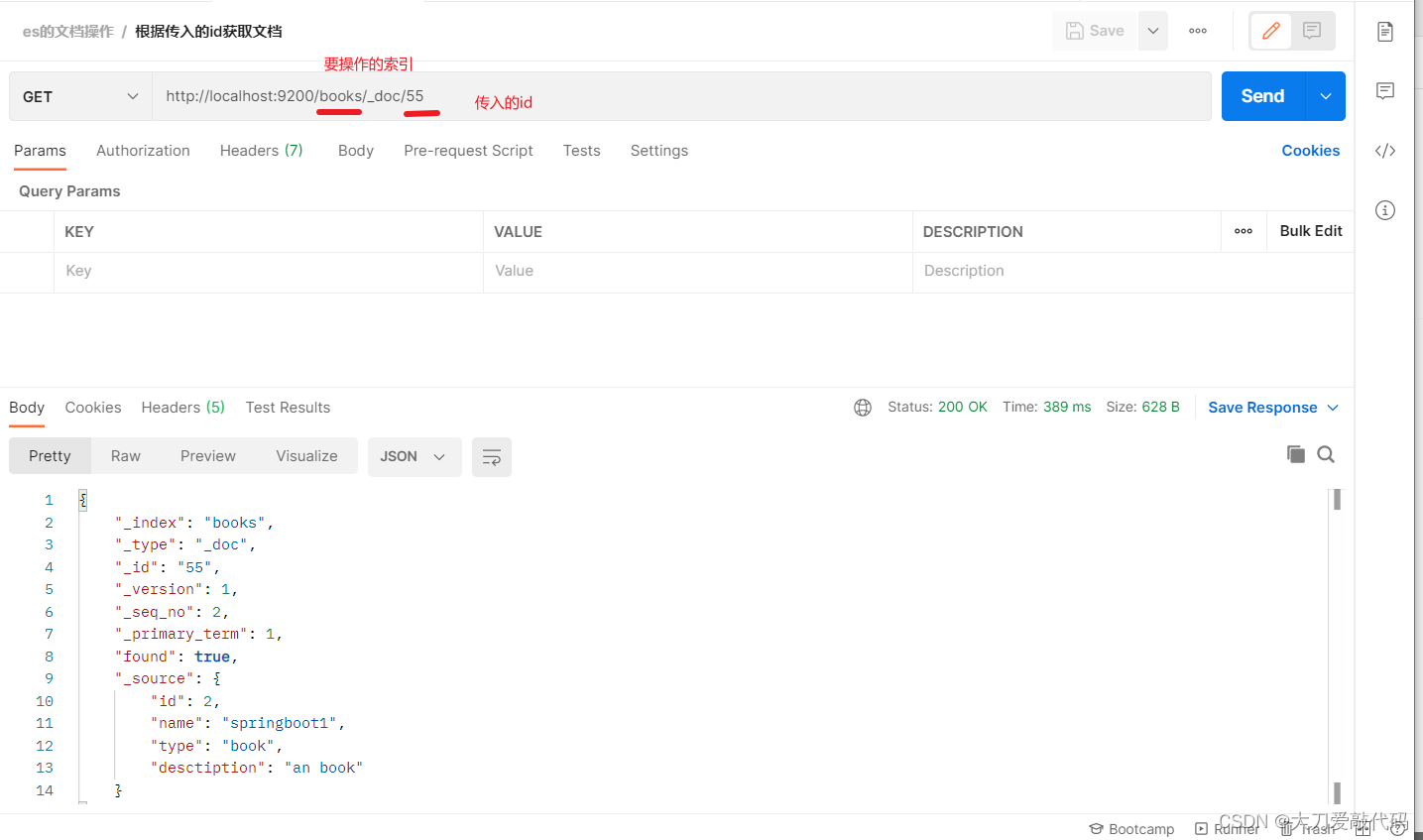
获取文档
- 根据id获取某个索引的文档:http://localhost:9200/books/_doc/1
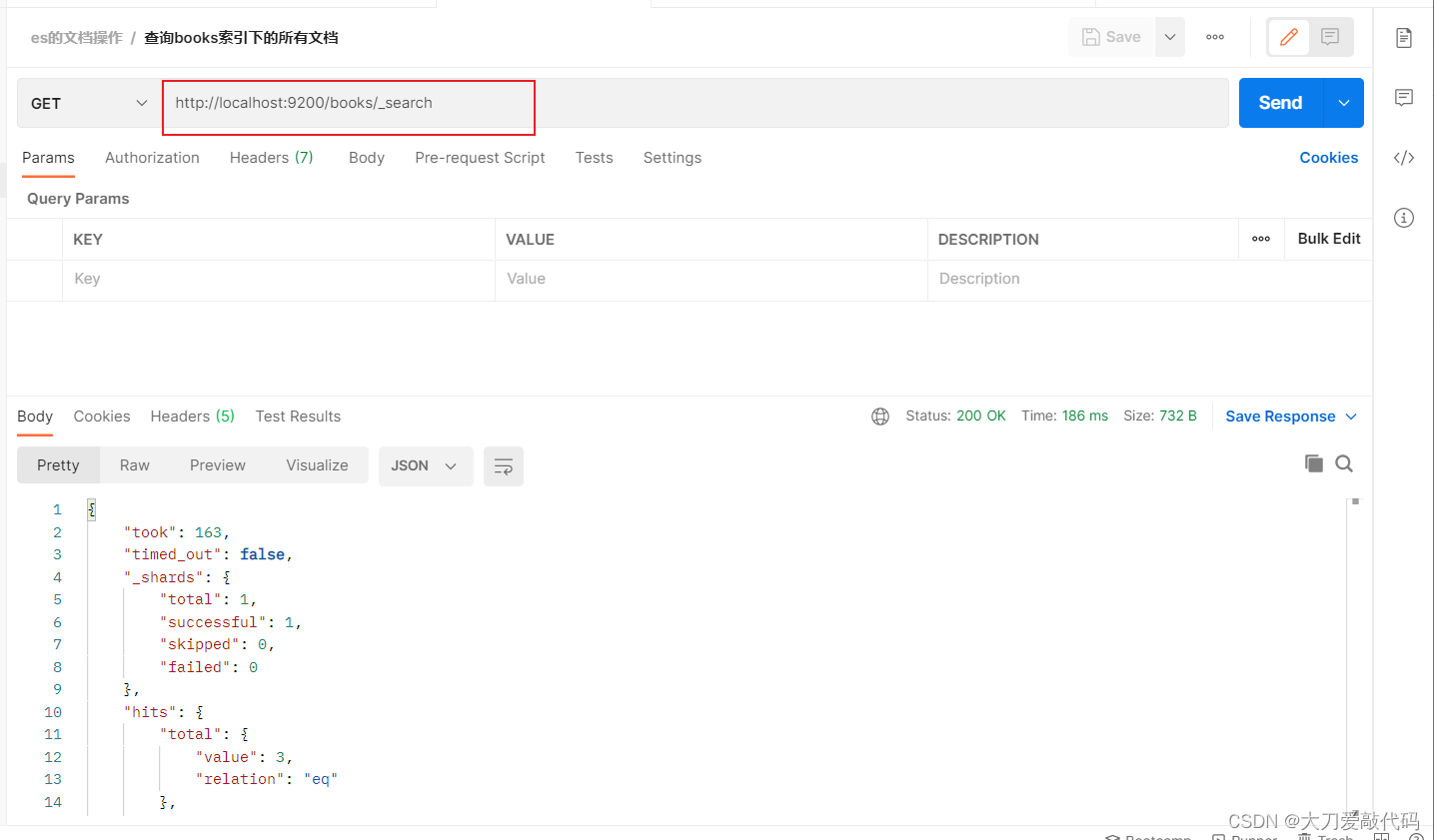
- 获取某个索引的所有的文档:GET请求 http://localhost:9200/books/_search
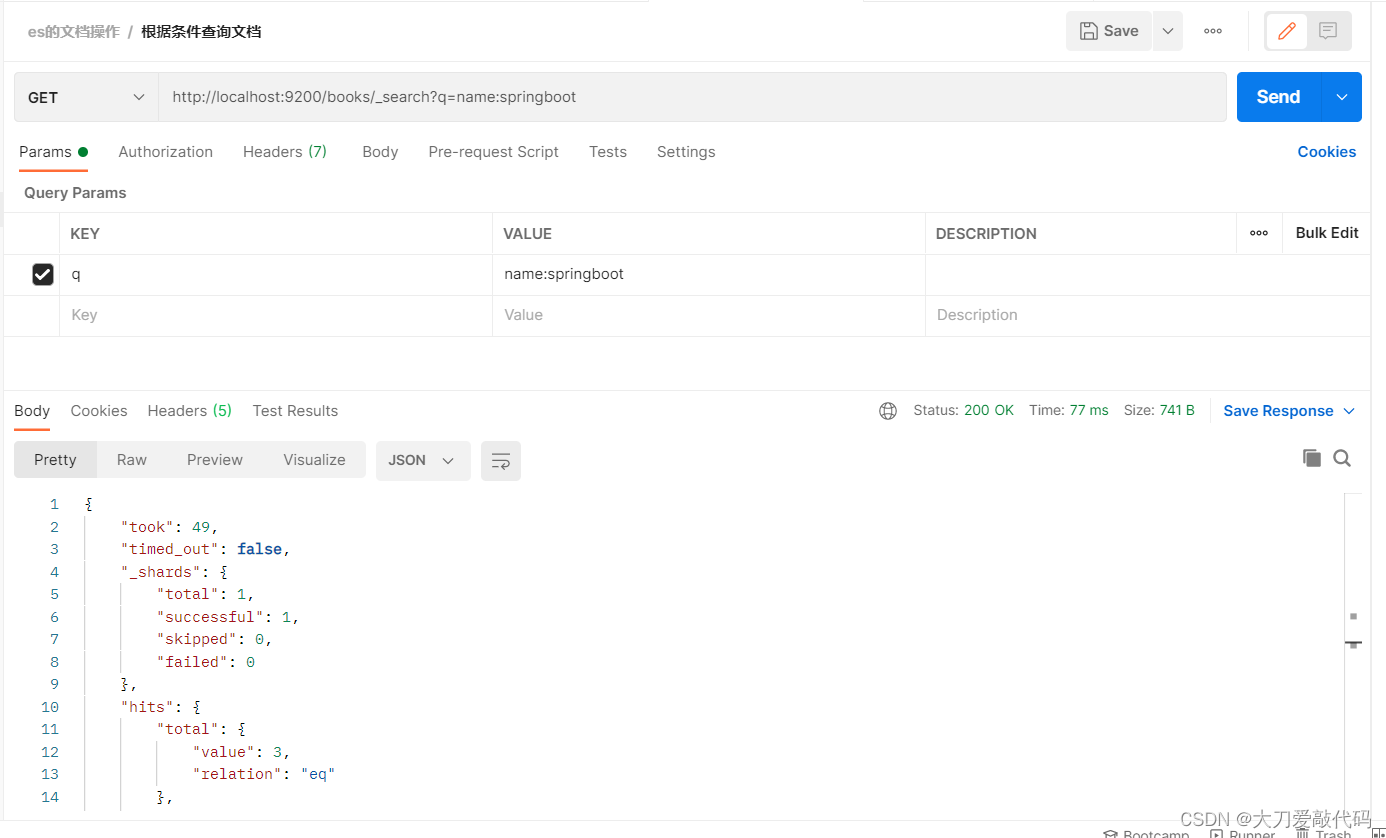
3. 根据指定条件获取某个索引的所有的文档:
GET请求 http://localhost:9200/books/_search?q=name:springboot
# q=查询属性名:查询属性值
删除文档
- 根据id进行删除:DELETE请求 http://localhost:9200/books/_doc/1
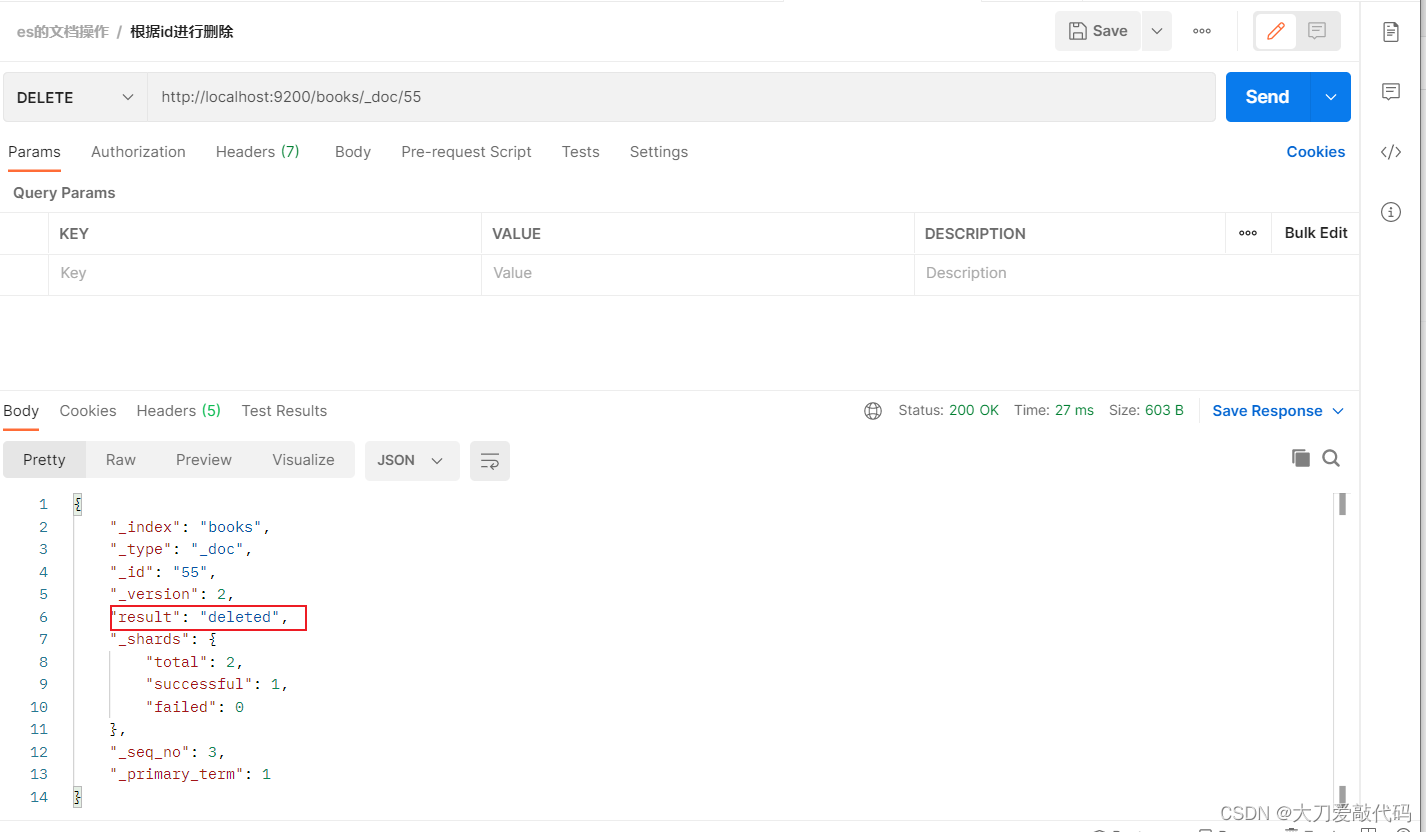
修改文档(分为全量更新和部分更新)
全量更新(注意这里是put请求,以及_doc)
- PUT请求 http://localhost:9200/books/_doc/1:根据指定id进行修改,传入的数据就是修改后的数据。
//文档通过请求参数传递,数据格式json
{"name":"springboot","type":"springboot","description":"springboot"
}

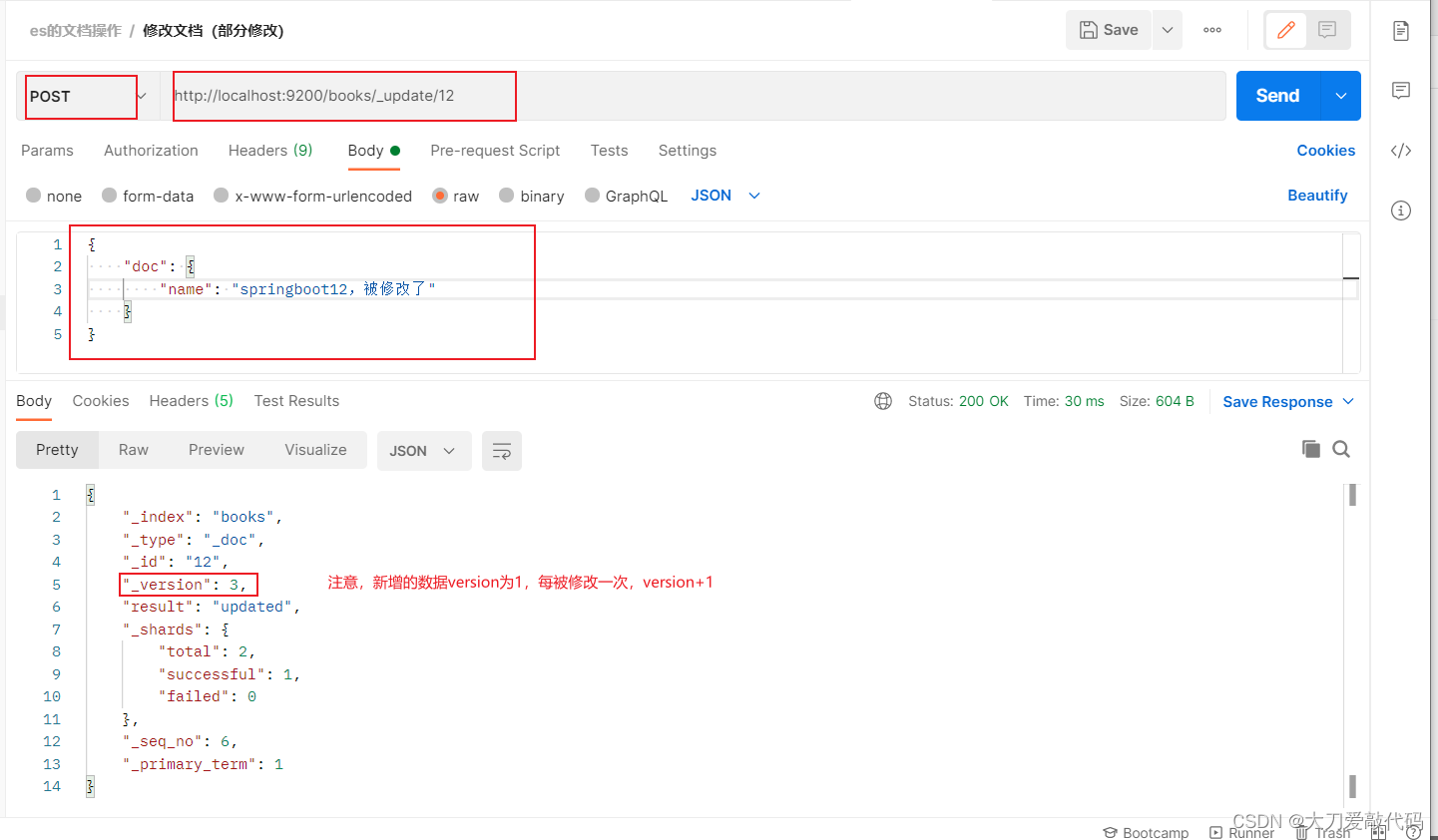
修改文档(部分更新)注意:这里是post请求,以及_update
- POST请求 http://localhost:9200/books/_update/1
//文档通过请求参数传递,数据格式json
{ "doc":{ //部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新"name":"springboot" //仅更新提供的属性值,未提供的属性值不参与更新操作}
}
三、Springboot整合ES
-
整合步骤(依旧是拿三板斧):
-
- 导入依赖
-
- 做配置(springboot底层有默认的配置)
-
- 调用它的api接口
-
-
ES有两种级别的客户端,一种是Low Level Client,一种是High Level Client。
- Low Level Client:这种客户端操作方式性能方面略显不足,不推荐使用,但是springboot最初整合ES的时候使用的是低级别客户端,所以企业开发需要更换成高级别的客户端模式。
- High Level Clien:高级别客户端与ES版本同步更新
Springboot整合Low Level Client的ES(不推荐使用了,这里了解一下)
- ES早期的操作方式如下:
步骤①:导入springboot整合ES的starter坐标(spiringboot里面有指定版本(就是低级别的版本号)
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
步骤②:进行基础配置
spring:elasticsearch:rest:uris: http://localhost:9200
配置ES服务器地址,端口9200(默认就是9200)
步骤③:使用springboot整合ES的专用客户端接口ElasticsearchRestTemplate来进行操作
@SpringBootTest
class Springboot18EsApplicationTests {@Autowiredprivate ElasticsearchRestTemplate template;
}
springboot测试类中的测试类的初始化方法和销毁方法的使用
- @BeforeEach:在测试类中每个操作运行前运行的方法
- @AfterEach :在测试类中每个操作运行后运行的方法
@SpringBootTest
class Springbootests {@BeforeEach //在测试类中每个操作运行前运行的方法void setUp() {//各种操作}@AfterEach //在测试类中每个操作运行后运行的方法void tearDown() {//各种操作}}
Springboot整合High Level Client的ES
- 高级别客户端方式进行springboot整合ES,操作步骤如下:
步骤①:导入springboot整合ES高级别客户端的坐标,此种形式目前没有对应的starter
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
这里的springboot版本为:2.5.4,es的版本为7.16.2,那时候的springboot没有整合高级别的ES,所以配置文件里不需要配置,只能写硬编码配置
步骤②:使用编程的形式设置连接的ES服务器,并获取客户端对象
步骤③:使用客户端对象操作ES,例如创建索引,为索引添加文档等等操作。
ES-----创建客户端
@SpringBootTest
class Springboot18EsApplicationTests {@Autowiredprivate BookMapper bookMapper;private RestHighLevelClient client;@Testvoid testCreateClient() throws IOException {//先创建ES客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);client.close();}
}
配置ES服务器地址与端口9200,记得客户端使用完毕需要手工关闭。由于当前客户端是手工维护的,因此不能通过自动装配的形式加载对象。
ES-----根据客户端创建索引
@SpringBootTest
class Springboot18EsApplicationTests {@Autowiredprivate BookMapper bookMapper;private RestHighLevelClient client;@Testvoid testCreateIndex() throws IOException {//先创建ES客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);//在通过ES客户端创建索引CreateIndexRequest request = new CreateIndexRequest("books");client.indices().create(request, RequestOptions.DEFAULT); client.close();}
}
高级别客户端操作是通过发送请求的方式完成所有操作的,ES针对各种不同的操作,设定了各式各样的请求对象,上例中创建索引的对象是CreateIndexRequest,其他操作也会有自己专用的Request对象。
ES-----根据客户端创建索引(使用Ik分词器)
使用分词器IK:
//json的参数:
{"mappings":{"properties":{"id":{"type":"keyword"},"name":{"type":"text","analyzer":"ik_max_word","copy_to":"all"},"type":{"type":"keyword"},"description":{"type":"text","analyzer":"ik_max_word","copy_to":"all"},"all":{"type":"text","analyzer":"ik_max_word"}}}
}
@Testvoid testCreateClientIndexByIk() throws IOException {
// 创建客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);CreateIndexRequest request = new CreateIndexRequest("books");String json = "{\n" +" \"mappings\":{\n" +" \"properties\":{\n" +" \"id\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\",\n" +" \"copy_to\":\"all\"\n" +" },\n" +" \"type\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"description\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\",\n" +" \"copy_to\":\"all\"\n" +" },\n" +" \"all\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";//设置请求中的参数(添加分词器)request.source(json, XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);client.close();}
IK分词器是通过请求参数的形式进行设置的,设置请求参数使用request对象中的source方法进行设置,至于参数是什么,取决于你的操作种类。当请求中需要参数时,均可使用当前形式进行参数设置。
ES-----为索引添加文档
// 添加文档:@Testvoid testCreateClientIndexByIkAddData() throws IOException {
// 创建客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);// 进行添加操作,因为前面已经创建好了books索引Book book = bookMapper.selectById(1);
// 把book对象数据转换为json数据,String json = JSON.toJSONString(book);
// 指定添加的文档的id为book.getId(),需要添加文档的索引为booksIndexRequest request = new IndexRequest("books").id(book.getId().toString());
// 传入数据request.source(json,XContentType.JSON);client.index(request,RequestOptions.DEFAULT);client.close();}添加文档使用的请求对象是IndexRequest,与创建索引使用的请求对象不同。
ES-----为索引批量添加文档
// 批量添加@Testvoid testCreateClientIndexByIkAddBatchData() throws IOException {
// 创建客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);// 进行添加操作,因为前面已经创建好了books索引List<Book> bookList= bookMapper.selectList(null);
// BulkRequest的对象,可以将该对象理解为是一个保存request对象的容器,
// 将所有的请求都初始化好后,添加到BulkRequest对象中,再使用BulkRequest对象的bulk方法,一次性执行完毕BulkRequest bulk = new BulkRequest();for (Book book : bookList) {// 把book对象数据转换为json数据,String json = JSON.toJSONString(book);
// 指定添加的文档的id为book.getId(),需要添加文档的索引为booksIndexRequest request = new IndexRequest("books").id(book.getId().toString());
// 传入数据request.source(json,XContentType.JSON);
// 把数据放进BulkRequest对象里面bulk.add(request);}
// 批量执行client.bulk(bulk,RequestOptions.DEFAULT);
// 关闭客户端client.close();}批量做时,先创建一个BulkRequest的对象,可以将该对象理解为是一个保存request对象的容器,将所有的请求都初始化好后,添加到BulkRequest对象中,再使用BulkRequest对象的bulk方法,一次性执行完毕。
ES-----查询文档
根据id查询
@Test//按id查询void testGetById() throws IOException {// 创建客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);// 根据id查询GetRequest request = new GetRequest("books","1");GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 获取查询到的数据中的source属性的数据String json = response.getSourceAsString();System.out.println(json);client.close();}
条件查询
@Test//按条件查询void testSearch() throws IOException {// 创建客户端HttpHost host = HttpHost.create("http://localhost:9200");RestClientBuilder builder = RestClient.builder(host);client = new RestHighLevelClient(builder);//SearchRequest request = new SearchRequest("books");//创建条件查询对象SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 设置查询条件searchSourceBuilder.query(QueryBuilders.termQuery("all", "spring"));
// 把查询条件放进请求中request.source(searchSourceBuilder);// 根据请求获取返回数据SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 获取返回数据里面的hits属性(获取的具体属性,可以看上面的postman操作)SearchHits hits = response.getHits();for (SearchHit hit : hits) {String source = hit.getSourceAsString();//把json数据转换为对象Book book = JSON.parseObject(source, Book.class);System.out.println(book);}}
Mysql与Es数据同步的实现(这里只是基本了解一下)
- 在实际项目开发中,我们经常将mysql作为业务数据库,ES作为擦汗寻数据库,用来实现读写分离,缓解mysql数据库的查询压力,应对海量数据的复杂查询。
1、同步双写
- 这是一种最为简单的方式,在将数据写入mysql的同时,也把数据写到ES里面
- 优缺点:
- 优点
-
- 业务逻辑简单
- 2、 实时性高
-
- 缺点:
-
- 硬编码,有需要写入MySQL的地方,都需要添加写入es的代码
-
- 业务强耦合
-
- 存在双写失败丢失数据的风险
-
- 性能较差,本来的mysql的性能不是很高,再加一个es系统的性能必然会下降
-
- 优点
2. 异步双写
- 针对多数据源写入的场景,可以借助MQ实现异步的多源写入
- 优缺点
- 优点:
-
- 性能高
-
- 不易出现数据丢失问题:主要基于MQ消息的消费保障机制,比如ES宕机或者写入失败,还能重新消费MQ消息;
-
- 多源写入之间相互隔离,便于扩展更多的数据源写入
-
- 缺点:
-
- 硬编码问题:接入新的数据源需要实现新的消费者代码
- 2、系统复杂度增加,映入了消息中间件
- 3、数据实时问题,mq是异步消费,用户输入,不一定会马上同步让他看到
-
- 优点:
3、基于sql抽取(定时任务)
- 上面两种方案都存在硬编码问题,代码的侵入性太强,如果对实时性要求不高的情况下,可以考虑用定时器来处理:
-
- 数据库的相关表中增加一个字段为updatetime(自己定义的名称)字段,任何CURD操作都会导致该字段的实际发生变化
-
- 原来程序中的crud操作不做任何变化
-
- 增加一个定时器程序,让该程序按一定的时间周期扫描指定的表,把该时间段内发生的变化的数据提取出来
-
- 比较此字段来确认变更数据,然后把变更的数据逐条写入ES中。
-
- 优缺点:
- 优点:
- 1、不改原代码,没有侵入性,没有硬编码;
- 2、没有业务强耦合,不改变原来程序的性能;
- 3、worker代码编写简单,不需要考虑增删改查;
- 缺点:
- 1、时效性太差,由于采取定时器根据固定频率查询表来同步数据,尽管将同步周期设置到秒级,也还是会存在一定时间的延迟。
- 2、对数据库有一定的轮询压力。
- 优化的方案:
- 1、将轮寻放到压力不大的从库上
- 2、借助logstash实现数据同步,其底层实现原理就是根据配置定期使用sql查询新增的数据写入es中,实现数据的增量同步(经典方案)
- 优点:
4、基于Binlog实现同步
-
前三种代码要么有代码侵入,要么有延迟。
-
而基于Binlog与mysql实现同步:既能保证数据同步的实时性又没有代入、侵入性。
-
实施步骤
- 1、读取mysql 的binlog日志,获取指定表的日志信息;
- 2、将读取的信息转为mq;
- 3、编写一个mq消费程序;
- 4、不断消费mq,每费完一条消息,将消息写入到es中;
-
优缺点:
- 优点:
- 1、没有代码侵入,没有硬编码;
- 原有系统不需要任何变化,没有感知;
- 3、性能高
- 4、业务解耦,不需要关注原来系统的业务逻辑
- 缺点:
- 1、构建Binlog系统复杂
- 2、如皋采用MQ消费解析的Binlog信息,也会存在MQ延时的风险
- 优点:
数据迁移工具选型
- 对于上面的四种数据同步方案,“基于Binlog实时同步”方案是目前最为常用的,也诞生了很多优秀的数据迁移工具,主要有以下几种:
- 1、canal (原理是伪装成mysql的从数据库)
- 2、阿里云DTS (需付费)
- 3、databus
- 4、Flink
- 5、CloudCanal
- 6、Maxwell
相关文章:
ES(Elasticsearch)的基本使用
一、常见的NoSQL解决方案 1、redis Redis是一个基于内存的 key-value 结构数据库。Redis是一款采用key-value数据存储格式的内存级NoSQL数据库,重点关注数据存储格式,是key-value格式,也就是键值对的存储形式。与MySQL数据库不同࿰…...

【JVM面试题】Java中的静态方法为什么不能调用非静态方法
昨晚京东大佬勇哥在群里分享了一道他新创的JVM面试题,我听完后觉得还挺有意思的,分享给大家 小佬们先别急着看我的分析,先自己想想答案 你是不是想说 因为静态方法是属于类的,而非静态方法属于实例对象 哈,有人这样回答…...

对‘float16_t’的引用有歧义
float16_t 是一个半精度浮点数类型,通常在一些需要高性能和低精度的场合被使用。 如果加了using namespace cv;后,OpenCV库中也有一个名为float16_t的类型定义,与最初的float16_t存在冲突,导致编译失败。 为了解决这个问题&#…...
Windows重装升级Win11系统后 恢复Mysql数据
背景 因为之前电脑硬盘出现问题,换了盘重装了系统,项目的数据库全部没了,还好之前的Mysql是安装在的D盘里,还有留存文件 解决办法 1.设置环境变量 我的路径是 D:\SoftWare\Application\mysql-5.7.35-winx64 此电脑右键属性 …...

MySQL之四大引擎、账号管理以及建库
目录 数据库存储引擎 简介 存储引擎得查看 support字段说明 InnoDB MyISAM MEMORY Archive 数据库管理 元数据库简介 元数据库分类 相关操作 MySQL库 数据表管理 三大范式 基本数据类型 优化原则 整形 实数 字符串 text&blob 日期类型 选中标识符 数…...

shell编程——查找局域网内存活主机
题目要求:写一个shell脚本,探测局域网内存活主机 首先,我们的思路是在循环中不断ping主机,然后根据ping的结果来判断主机是否存活 本题中ping语句如下: ping -c 3 -i 0.3 -W 1 192.168.1.1 解释一下参数࿱…...
python django 个人记账管理系统
python django 个人记账管理系统。 功能:登录,新用户注册,个人信息修改,收入,支出记录,收入记账管理,支出记账管理,收入,支出统计 技术:python django&…...
)
C#的Char 结构的方法之IsLetterOrDigit()
目录 一、Char 结构 二、Char.IsLetterOrDigit 方法 1.定义 2.重载 3.示例 4.IsLetterOrDigit(Char) 5.IsLetterOrDigit(String, Int32) 一、Char 结构方法 CompareTo(Char)将此实例与指定的 Char 对象进行比较,并指示此实例在排序顺序中是位于指定的 Char …...

配置Docker私有仓库
# 打开要修改的文件 vi /etc/docker/daemon.json # 添加内容: "insecure-registries":["http://自己服务器的ip地址:设置的端口号"] # 重加载 systemctl daemon-reload # 重启docker systemctl restart docker在自己设定的文件夹内使用DockerCo…...
计算机网络-动态路由
网络层协议:ip,ospf,rip,icmp共同组成网络层体系 ospf用于自治系统内部。 一个路由器或者网关需要能够支持多个不同的路由协议,以适应不同的网络环境。特别是在连接不同自治系统的边缘路由器或边界网关的情况下&#…...

光耀未来 第一届能源电子产业创新大赛太阳能光伏赛道决赛在宜宾举行
1月3日,第一届能源电子产业创新大赛太阳能光伏赛道决赛在宜宾盛大举行,本次比赛吸引了全国范围内的光伏行业顶尖人才和创新团队参与。 为深入贯彻《关于推动能源电子产业发展的指导意见》,推动我国能源电子产业升级,工业和信息化部…...
【小沐学NLP】Python实现TF-IDF算法(nltk、sklearn、jieba)
文章目录 1、简介1.1 TF1.2 IDF1.3 TF-IDF2.1 TF-IDF(sklearn)2.2 TF-IDF(nltk)2.3 TF-IDF(Jieba)2.4 TF-IDF(python) 结语 1、简介 TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Fr…...
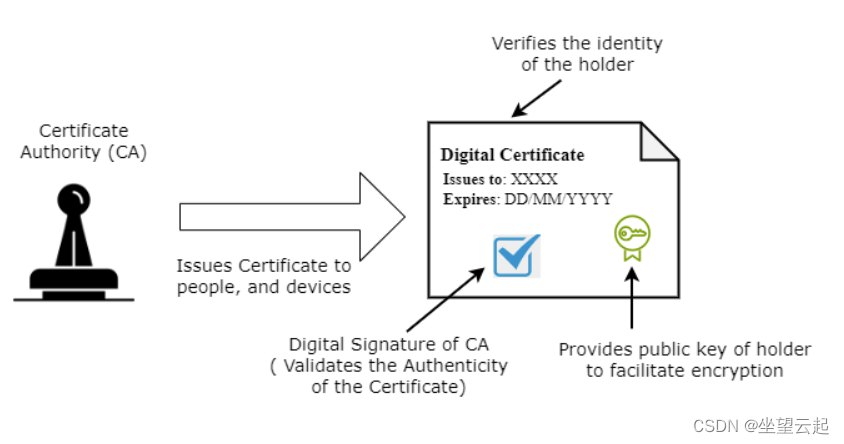
.cer格式证书文件和 .pfx格式证书文件有什么区别?
这里我们将讨论.cer和.pfx文件类型之间的差异。 什么是数字证书? 数字证书在电子通信中用作验证身份的密码机制。我们需要这些证书来建立安全的在线通信渠道,并确保数字数据的隐私、真实性和正确性。 数字证书包括主题(实体详细信息…...
【docker实战】安装tomcat并连接mysql数据库
本节用docker来安装tomcat,并用这个tomcat连接我们上一节安装好的mysql数据库 一、拉取镜像 我们安装8.5.69版本 先搜索一下 [rootlocalhost ~]# docker search tomcat NAME DESCRIPTION …...

LeetCode 每日一题 Day 32 ||递归单调栈
2487. 从链表中移除节点 给你一个链表的头节点 head 。 移除每个右侧有一个更大数值的节点。 返回修改后链表的头节点 head 。 示例 1: 输入:head [5,2,13,3,8] 输出:[13,8] 解释:需要移除的节点是 5 ,2 和 3 。…...

【mars3d】FixedRoute的circle没有跟polyline贴着模型的解决方案
问题:【mars3d】官网的贴模型示例中,参考api文档增加了circle的配置,但是FixedRoute的circle没有跟polyline贴着模型 circle: { radius: 10, materialType: mars3d.MaterialType.CircleWave, materialOptions: { color: "#ffff00"…...
Day7 vitest 之 vitest配置第三版
项目目录 runner Type: VitestRunnerConstructor Default: node, 当运行test的时候 benchmark,当运行bench测试的时候 功能 自定义测试运行程序的路径。 要求 应与自定义库运行程序一起使用。 如果您只是运行测试,则可能不需要这个。它主要由library作者使用 …...

git补充上次提交
1.首先,确保你还没有执行 git push 操作。如果尚未推送到远程仓库,那么可以在本地进行修正。 2.添加遗漏的文件: git add <遗漏的文件路径>3.提交新修改或新增的文件,并将它与上一次提交合并(如果希望保持提交历…...

计算机网络名词解释
1.ICMP 网际控制报文 允许主机或路由器报告差错情况和提供有关异常情况的报告 2.RIP路由信息协议 是一种分布式的,基于距离向量的路由选择协议 3.BGP 外部网关协议 是不同自治系统的路由器之间交换路由信息的协议 4.IGMP 网际管理协议 使用多播路由器知道多播…...
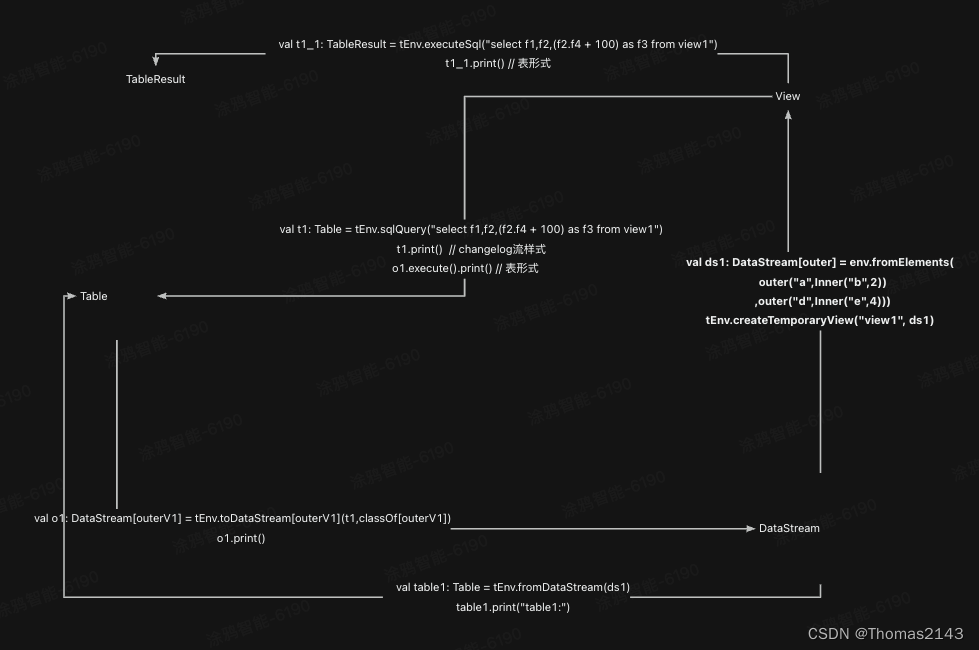
flink table view datastream互转
case class outer(f1:String,f2:Inner) case class outerV1(f1:String,f2:Inner,f3:Int) case class Inner(f3:String,f4:Int) 测试代码 package com.yy.table.convertimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.tabl…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...
)
别再依赖SDK了!手把手教你用OpenCV和Eigen从零实现RGB-D相机对齐(附完整C++代码)
从零实现RGB-D相机对齐:OpenCV与Eigen实战指南 在计算机视觉领域,RGB-D相机的深度与彩色图像对齐(D2C)是一个基础但至关重要的技术环节。虽然市面上大多数商用RGB-D相机都提供了现成的SDK和API来实现这一功能,但对于真…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

GD32F103C8T6烧录方式全解析:串口ISP、ST-Link Utility、Keil在线,哪种最适合你?
GD32F103C8T6烧录方案深度评测:从原型开发到量产部署的全场景指南 在嵌入式开发领域,选择正确的程序烧录方式往往决定着开发效率和生产成本。作为STM32F103的国产替代方案,GD32F103C8T6凭借其出色的性价比赢得了广泛关注。但许多开发者在迁移…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界
UABEA:终极跨平台Unity资源编辑器,免费解锁游戏资源分析新境界 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA(Unity Asset Bundle Extractor Avalonia&#…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...