【机器学习基础】DBSCAN
🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学!
⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战 欢迎订阅!本专栏针对机器学习基础专栏的理论知识,利用python代码进行实际展示,真正做到从基础到实战!
💡往期推荐:
【机器学习基础】机器学习入门(1)
【机器学习基础】机器学习入门(2)
【机器学习基础】机器学习的基本术语
【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式)
【机器学习基础】一元线性回归(适合初学者的保姆级文章)
【机器学习基础】多元线性回归(适合初学者的保姆级文章)
【机器学习基础】对数几率回归(logistic回归)
【机器学习基础】正则化
【机器学习基础】决策树(Decision Tree)
【机器学习基础】K-Means聚类算法
💡本期内容:紧接着上一篇介绍的K-Means聚类,本篇文章针对原型聚类的缺点,介绍了密度聚类DBSCAN,丰富了无监督学习的内容介绍。
文章目录
- 1 DBSCAN发展状况
- 2 DBSCAN算法的基本概念
- 3 DBSCAN参数设置
- 4 DBSCAN算法的核心思想
- 5 DBSCAN伪代码描述
- 6 DBSCAN的优缺点
1 DBSCAN发展状况
目前,人们提出的聚类算法主要分为五种类型:划分法、层次法、基于模型的算法、基于密度的算法和基于网格的算法。基于密度的聚类算法是以出格合适对不确定命据集举行聚类,不用计较各种各样的距离,而是基于密度,就可以迅速的完成样本集的聚类。基于密度的聚类方式在数据识别、数据分析、图象处置、网络安全等范畴有着普遍的利用,是以,关于基于密度聚类算法的钻研有着普遍的现实和现实意义。
基于密度的经典代表算法主要有两种:DBSCAN和OPTIC。针对这两种经典的算法,学术界展开了大量的讨论。DBSCAN于1996年由Ester等提出,DBSCAN算法它不仅可以对高密度区域进行聚类划分,还可以对低密度区域进行过滤,最终在噪声数据集中得到任意形状的簇。同时,DBSCAN也存在一些很明显的缺点,使用DBSCAN必须先确定Eps和MinPts这两种参数。因为DBSCAN算法对这两种参数感应较高,一旦取值不当就会影响聚集效果。OPTIC是1996年Ankerst等提出来的,是对DBSCAN算法的一大改进。
2 DBSCAN算法的基本概念

DBCSAN是密度聚类中最为经典的一种算法,这种算法不需要提前设置制定聚类数量,但是对于用户设置的eps和minpts参数的数值波动较大。能够有效地识别噪声点。对于样本集,它既可以应用于凸样本集,同样也可以被非凸样本集所利用。这类聚类算法是通过数据集密度的紧密程度来进行划分的,但当采样区域密度不均匀,组间距离相差很大时,算法组的效果会很差。同一类型的图案是紧密相连的,应在离类型外围不远的地方提供相同类型的样品。最后,将每一组紧密相连的样本分为不同的类别,产生聚类效应。
3 DBSCAN参数设置
DBSCAN涉及的参数和关系较多并且受参数设置的影响较大,有两个算法参数:邻域半径eps和最少点数目minpts,3种点的类别:核心点,边界点和噪声点,4种点的关系:密度直达,密度可达,密度相连,非密度相连。
- E邻域:对于给定一个对象,如果它与点的距离小于等于eps则称该邻域是是该对象的E邻域。E邻域是用户主观选择的,eps的值限制着核心点的搜索范围。
- 核心对象:对于给定的对象时,如果样品中的对象E邻域的附近的数目是大于或等于minpts值,称为核心目的是给定对象。
- 直接密度可达:在一个样本集里,如果一个对象点m是核心对象,另一个对象n点在该对象m的邻域半径里,那么则称样本点n从样本点m直接密度可达。
- 密度相连:对于对象m和对象n,如果有核心对象o,使得数据对象m和对象n均从o密度可达,那么则称对象m和对象n密度相连。
- 密度聚类簇:在一个给定数据集中,对于一个核心点与他密度可达的所有点组成一个密度聚类簇。
- 噪声:在一个数据集中,如果一个点在聚类结果上不属于任何一个聚类簇,那么则称该点为噪声。
- 核心点:如果一个边界点在某个核心对象的邻域内,并且该点不是核心对象那么该点是核心点。
在实验实际操作中, DBSCAN有三个输入数据:数据集、邻域半径eps、最少点数值minpts,DBSCAN受半径eps和最少点数值minpts数值波动较大,并且是用户根据实际操作情况认为设置的。

4 DBSCAN算法的核心思想
从以上的叙述中我们可以看出,其基本思想与广度优先搜索思想类似,主要受eps和minpts数值的影响。
-
它从一个随机的没有经过访问的一个对象点开始进行搜索,并检查对象点的E邻域是否含有至少minpts个对象,如果它附近点的数量少于minpts,那么该点将会暂时标记为噪声点,如果附近点的数目大于等于minpts,那么该对象点会创建一个新的簇,并将把该点和它的E邻域内的所有对象全部放入列为候选集合。
-
而后,这些核心对像会被该算法迭代的聚集,并把这些核心对想中直接必读可达的对象添加到新的簇中,随后检索被添加对象的e邻域是否包含minpts个对象,并重复上述操作,直到簇不能再扩展或者候选集合为空,输出,在这个过程中会牵扯密度可达簇的聚集。
-
在完成收集集群后,将DBSCAN然后从对象的其余部分选择随机对象尚未访问和聚类过程。直到所有的对象都已经分配。

DBSCAN还有一个特点,如果一个点不是一个簇的噪声并且该点的附近点少于minpts数值,那么该点被标记为不属于任何簇的噪声点。噪声点被识别为选择对象过程的一部分,如果特定的对象点没有足够的附近点,则将其标记为噪声点。
5 DBSCAN伪代码描述

6 DBSCAN的优缺点
- 优点:
- DBSCAN与k-means划分聚类算法相比,DBSCAN能够处理任何形态的类,而k-means只能处理凸型的类;DBSCAN不需要自己划分聚类簇的情况,k-means需要在算法执行前进行各种参数的设置。
- DBSCAN可以有效地识别和剔除噪声,并且可以在根据实验需要输入过滤噪声的参数。
- 对于样本集中的异常点不敏感。
- 缺点:
- 从DBSCAN运行的情况来看,主要确定邻域半径eps和邻域样本数阈值minpts,可以看出算法对eps和minpts这两个由用户确定的参数非常敏感,主要是由于带有很大的主观性。确定eps和minpts非常复杂,一旦取值不好,就会对聚类效果产生不好的影响,造成聚类质量下降甚至无法进行工作。
当minpts取值一定时,如果eps数值设置的较小,会产生大量的离群点,大部分数据都不能进行聚类,如果设置的数值较大,大部分数值和类都会聚类到同一个簇,在簇得中心会出现一个空洞;
当eps取值一定时,如果minpts的值太大,集群中的点会被标记为离群点,如果值太小,会导致产生大量的核心点。所以eps和minpts的取值搭配不同,就会产生不同的聚类效果。 - DBSCAN是基于密度聚类算法,从实验结果来看,当空间聚类的密度不均匀、聚类间隔差别很大时,数据集不能很好地产生簇,就会造成聚类效果质量下降。
- 当DBSCAN处理较大的数据库的时候,核心对象不断地添加同时没有被访问的对象就会停留在内存中,如果内存过小,就会造成内存的拥堵,这就需要大量的内存来支持程序的执行,来储存核心对象的信息,并且i/o消耗也很大;对于DBSCAN和整个样本集只采用了邻域半径eps和邻域样本数阈值minpts一组参数。如果样本集中存在不同密度的簇或者嵌套簇,那么DBSCAN 算法不能很好地处理这种情况
- DBSCAN算法可以有效地识别和剔除噪声,这既是它的一大优点,同时也是它的一大缺点,这就造成了DBSCAN不适用于网络安全等领域的问题。
- 由于算法邻域半径eps的选取需要用到距离公式的选取,在实际操作中经常用到k-距离曲线方法,对于DBSCAN处理高维度的数据,就会造成运算困难,存在“维度灾难”。
相关文章:
【机器学习基础】DBSCAN
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…...

计算机硬件 4.4键盘与鼠标
第四节 键盘与鼠标 一、认识键盘 1.地位:计算机系统最基本的输入设备。 2.外观结构:面板、键帽、底盘、数据线。 3.组成键区:主键区、功能键区、辅助键区和编辑(控制)键区。 二、键盘分类 1.按接口分 ①AT口&…...

Flappy Bird QDN PyTorch博客 - 代码解读
Flappy Bird QDN PyTorch博客 - 代码解读 介绍环境配置项目目录结构QDN算法重要函数解读preprocess(observation)DeepNetWork(nn.Module)BirdDQN类主程序部分 介绍 在本博客中,我们将介绍如何使用QDN(Quantile Dueling Network)算法…...

听GPT 讲Rust源代码--compiler(9)
File: rust/compiler/rustc_trait_selection/src/traits/select/mod.rs 在Rust源代码中,rust/compiler/rustc_trait_selection/src/traits/select/mod.rs文件的作用是实现Rust编译器的trait选择器。 首先,让我们逐个介绍这些struct的作用: Se…...

Go语言中关于go get, go install, go build, go run指令
go get go get 它会执行两个操作 第一个, 是先将远程的代码克隆到Go Path的 src 目录那二个, 是执行go install命令 那如果指定的包可以生成二进制文件那它就会把这个二进制文件保存到这个 Go Path 的bin目录下面这是 go install 命令执行的操作 如果只需要下载包,…...

石头剪刀布游戏 - 华为OD统一考试
OD统一考试 分值: 100分 题解: Java / Python / C++ 题目描述 石头剪刀布游戏有 3 种出拳形状: 石头、剪刀、布。分别用字母 A,B,C 表示游戏规则: 出拳形状之间的胜负规则如下: A>B; B>C; C>A; 左边一个字母,表示相对优势形状。右边一个字母,表示相对劣势形状。…...
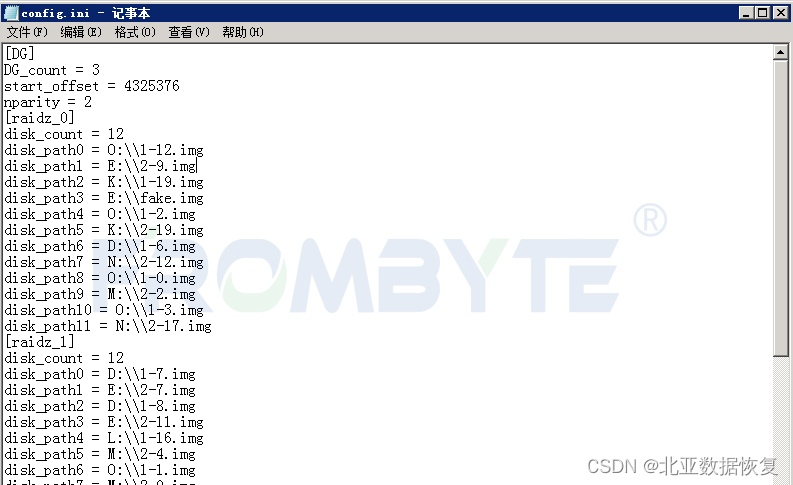
【北亚服务器数据恢复】ZFS文件系统服务器ZPOOL下线的数据恢复案例
服务器数据恢复环境: 服务器中有32块硬盘,组建了3组RAIDZ,部分磁盘作为热备盘。zfs文件系统。 服务器故障: 服务器运行中突然崩溃,排除断电、进水、异常操作等外部因素。工作人员将服务器重启后发现无法进入操作系统。…...
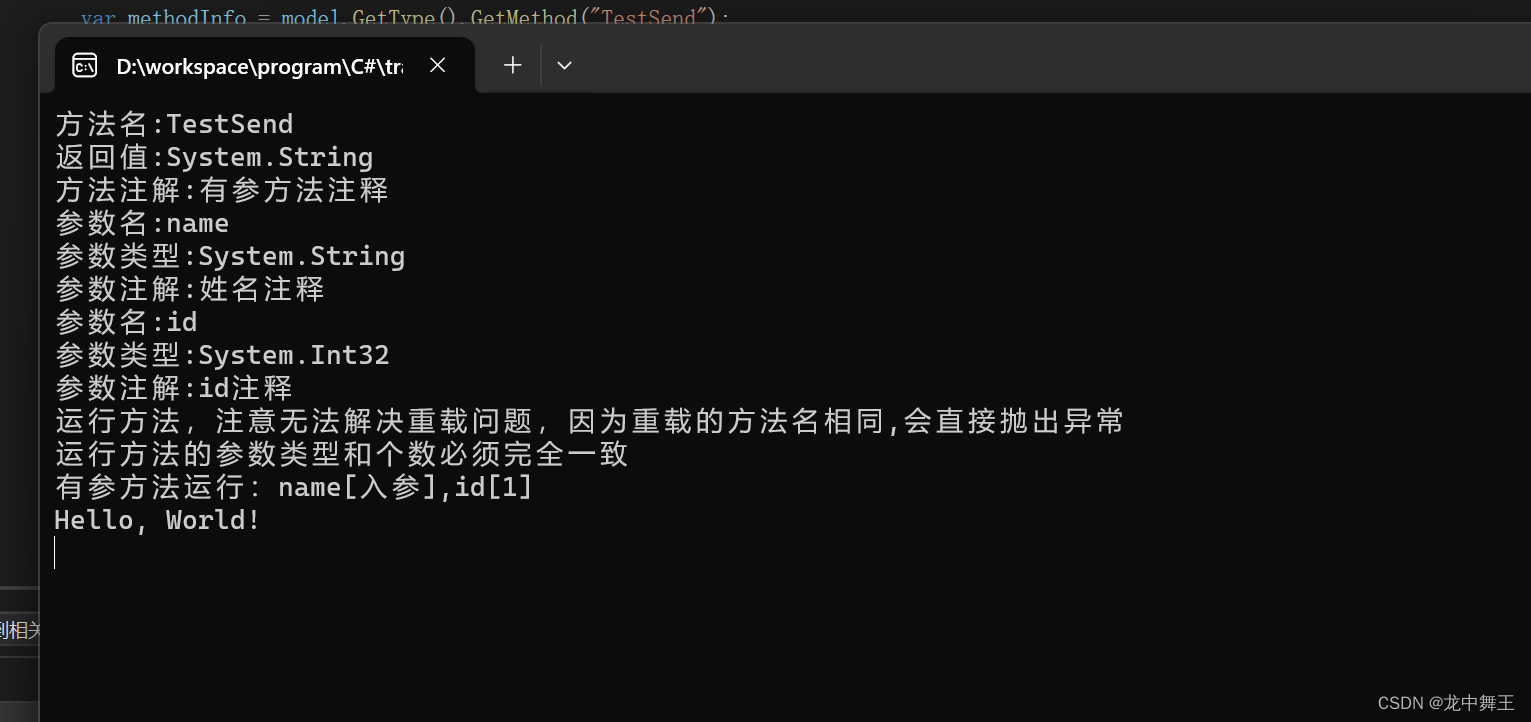
C# 反射的终点:Type,MethodInfo,PropertyInfo,ParameterInfo,Summry
文章目录 前言反射是什么?常用类型操作SummryPropertyInfoMethodInfo无参函数运行 有参函数运行,获取paramterInfo 总结 前言 我之前写了一篇Attribute特性的介绍,成功拿到了Attribute的属性,但是如果把Attribute玩的溜,那就要彻…...

2020年认证杯SPSSPRO杯数学建模D题(第一阶段)让电脑桌面飞起来全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 D题 让电脑桌面飞起来 原题再现: 对于一些必须每天使用电脑工作的白领来说,电脑桌面有着非常特殊的意义,通常一些频繁使用或者比较重要的图标会一直保留在桌面上,但是随着时间的推移,…...

谷歌推出创新SynCLR技术:借助AI生成的数据实现高效图像建模,开启自我训练新纪元!
谷歌推出了一种创新性的合成图像框架,这一框架独特之处在于它完全不依赖真实数据。这个框架首先从合成的图像标题开始,然后基于这些标题生成相应的图像。接下来,通过对比学习的技术进行深度学习,从而训练出能够精准识别和理解这些…...
Vue2中使用echarts,并从后端获取数据同步
一、安装echarts npm install echarts -S 二、导入echarts 在script中导入,比如: import * as echarts from "echarts"; 三、查找要用的示例 比如柱状图 四、初始化并挂载 <template><div id"total-orders-chart" s…...

【Redux】自己动手实现redux-thunk
1. 前言 在原始的redux里面,action必须是plain object,且必须是同步。而我们经常使用到定时器,网络请求等异步操作,而redux-thunk就是为了解决异步动作的问题而出现的。 2. redux-thunk中间件实现源码 function createThunkMidd…...
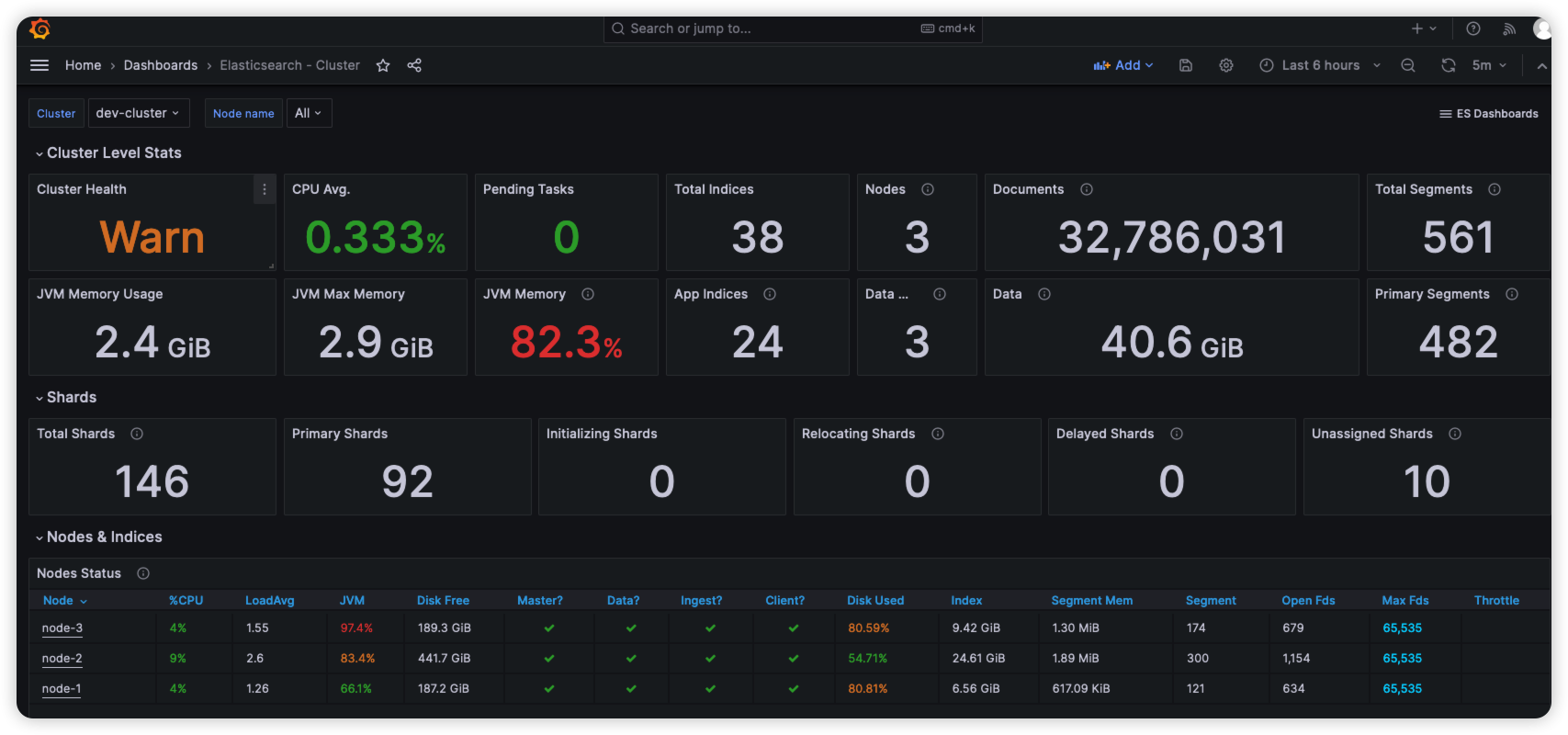
ElasticSearch使用Grafana监控服务状态-Docker版
文章目录 版本信息构建docker-compose.yml参数说明 创建Prometheus配置文件启动验证配置Grafana导入监控模板模板说明 参考资料 版本信息 ElasticSearch:7.14.2 elasticsearch_exporter:1.7.0(latest) 下载地址:http…...
VS Code 如何调试Python文件
VS Code中有1,2,3处跟Run and Debug相关的按钮, 1 处:调试和运行就不多说了,Open Configurations就是打开workspace/.vscode下的lauch.json文件,而Add Configuration就是在lauch.json文件中添加当前运行Python文件的Configuratio…...
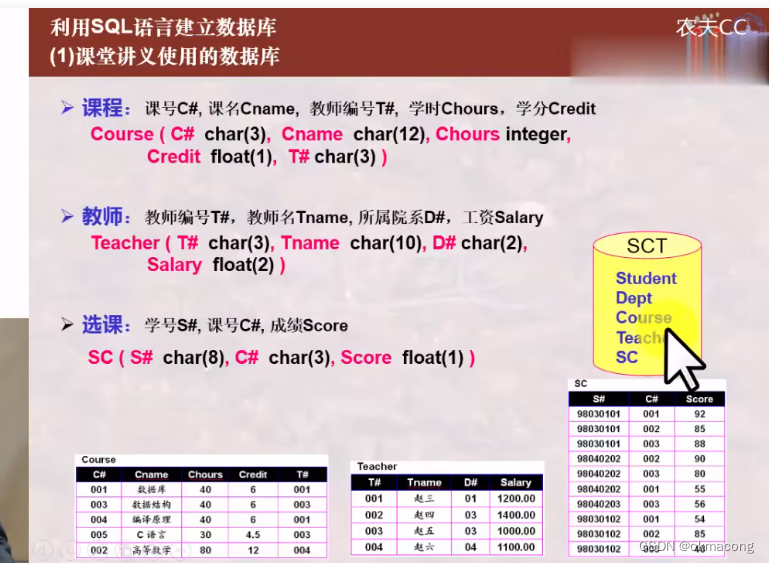
day06、SQL语言之概述
SQl 语言之概述 6.1 SQL语言概述6.2 SQL语言之DDL定义数据库6.3 SQL语言之DML操纵数据库 6.1 SQL语言概述 6.2 SQL语言之DDL定义数据库 6.3 SQL语言之DML操纵数据库...

3D目标检测(教程+代码)
随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。 一、3D目…...

让设备更聪明 |启英泰伦离线自然说,开启智能语音交互新体验!
语音交互按部署方式可以分为两种:离线语音交互和在线语音交互。 在线语音交互是将数据储存在云端,其具备足够大的存储空间和算力,可以实现海量的语音数据处理。 离线语音交互是以语音芯片为载体,语音数据的采集、计算、决策均在…...

React Hooks之useState、useRef
文章目录 React Hooks之useStateReact HooksuseStatedemo:在函数式组件中使用 useState Hook 管理计数器demo:ant-design-pro 中EditableProTable组件使用 useRef React Hooks之useState React Hooks 在 React 16.8 版本中引入了 Hooks,它是…...

提供电商Api接口-100种接口,淘宝,1688,抖音商品详情数据安全,稳定,支持高并发
Java是一种高级编程语言,由Sun Microsystems公司于1995年推出,现在属于Oracle公司开发和维护。Java以平台无关性、面向对象、安全性、可移植性和高性能著称,广泛用于桌面应用程序、嵌入式系统、企业级服务、Android移动应用程序等。 接口是Ja…...

git的使用 笔记1
GIT git的使用 使用git提交的两步 第一步:是使用 git add 把文件添加进去,实际上就是把文件添加到暂存区。第二步:使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。 .git 跟踪管理版本的目录 创建版本库…...

不只是安装:在龙芯2k1000LA上为Loongnix配置WiFi、蓝牙与触摸屏驱动的完整流程
龙芯2k1000LA开发板外设驱动深度配置指南:从WiFi到触摸屏的全栈解决方案 在国产化硬件开发领域,龙芯2k1000LA开发板凭借其完全自主的LoongArch架构,正成为物联网和嵌入式设备开发者的重要选择平台。不同于x86架构的"开箱即用"体验&…...

Go语言外部服务调用可靠性实践:Icepick库的重试、熔断与并发控制
1. 项目概述与核心价值 最近在折腾一个需要深度集成多个外部API的后端服务,遇到了一个老生常谈但又极其棘手的问题:如何优雅、可靠地处理那些可能失败的外部调用?重试、熔断、降级、超时控制……这些概念听起来都懂,但真要把它们组…...

UltraScale架构FPGA功耗优化技术与工程实践
1. UltraScale架构的功耗优化技术全景解析在当今高性能计算和通信领域,功耗已成为FPGA选型的决定性因素之一。Xilinx UltraScale架构通过多层次的创新,在20nm工艺节点上实现了显著的功耗降低。作为深耕FPGA设计十余年的工程师,我将从实际应用…...

iPhone、iPad、Mac功能联动!
今天分享几个iPhone、iPad、Mac之间的联动技巧 通讯转接 iPhone不在身边或者不方便拿出来接听电话,在身边的iPad、Mac也可以接听电话,设置方法如下: 打开设置 – 电话 – 在其他设备上通话 – 勾选上iPad、Mac设备就可以了,iPh…...

PP 蜂窝板生产线智能控制系统架构与 PLC 程序设计思路
PP 蜂窝板生产线智能控制系统架构与 PLC 程序设计思路摘要:针对 PP 蜂窝板产线多段速度同步、温度压力闭环、真空度稳定与定长裁切精度要求,本文介绍基于 PLCHMI 的智能控制系统整体架构,分模块阐述挤出温控、真空定型、牵引同步、在线测厚与…...

OrangePi串口实战:从pyserial配置到USB-TTL数据抓取
1. 环境准备与硬件连接 第一次玩OrangePi串口通信时,我对着桌上那堆USB-TTL模块和杜邦线发呆了半小时。后来才发现,硬件连接其实比想象中简单。你需要准备三样东西:OrangePi开发板(我用的是OrangePi 5)、USB-TTL转换模…...
)
从数据库设计到前端展示:一条龙搞定Java BigDecimal精度问题(附Spring Boot配置建议)
从数据库设计到前端展示:全面解决Java BigDecimal精度问题实战指南 在电商系统开发中,价格计算是核心业务逻辑之一。一个简单的折扣计算可能引发连锁反应:用户输入0.66折,数据库存储为float类型,Java读取后乘以10却得到…...

如何用ChatGPT进行金融数据分析:从入门到实战的完整指南
如何用ChatGPT进行金融数据分析:从入门到实战的完整指南 【免费下载链接】awesome-chatgpt-zh ChatGPT 中文指南🔥,ChatGPT 中文调教指南,指令指南,应用开发指南,精选资源清单,更好的使用 chatG…...

如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南
如何快速上手MuseTalk:从零开始的实时高质量唇语同步完整指南 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk 想要为静态人物图像添加…...

如何快速完成Windows系统部署:高效自动化工具完整指南
如何快速完成Windows系统部署:高效自动化工具完整指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat Wind…...