排序算法——关于快速排序的详解
目录
1.基本思想
2.基本原理
2.1划分思想
2.2排序过程
(1)选择基准值
(2)分割过程(Partition)
(3)递归排序
(4)合并过程
2.3具体实例
2.4实现代码
2.5关键要点
3.性能分析
3.1空间效率
3.2时间效率
3.3稳定性
1.基本思想
快速排序(Quick Sort)是一种常用的排序算法,它采用分治法的思想,通过递归地将数据分解成小于基准值和大于基准值的两部分,然后对这两部分进行排序,最终将它们合并起来。
2.基本原理
2.1划分思想
在待排序表L[l...n]中任取一个元素pivot作为枢轴(或称基准,通常取首元素),通过一趟排序将待排序表划分为独立的两部分L[l...k-1]和L[k+l...n],使得L[l...k-l]中的所有元素小于pivot;L[k+l...n]中的所有元素大于或等于pivot,则pivot放在了其最终位置L(k)上,这个过程称为一次划分。
2.2排序过程
(1)选择基准值
从待排序数组中选择一个元素作为基准值。通常选择第一个元素,但也可以选择随机元素或数组中间的元素。
(2)分割过程(Partition)
将数组按照基准值进行分割,将小于等于基准值的元素放在基准值的左侧,大于基准值的元素放在右侧。同时,基准值所在的位置被确定,这个位置之前的元素都小于等于基准值,之后的元素都大于基准值。这一过程可以使用双指针法来实现。
(3)递归排序
对基准值左侧和右侧的子数组分别进行递归排序。即对左侧子数组和右侧子数组分别重复步骤1和步骤2。
(4)合并过程
递归排序完成后,整个数组已经被拆分成若干有序的子数组,只需简单地将这些子数组合并即可得到最终的有序数组。
2.3具体实例
一趟快速排序的过程是一个交替搜索和交换的过程,下面通过实例来介绍
*来自2024版王道数据结构考研复习指导
设两个指针i和j,初值分别为low和high,取第一个元素49为枢轴赋值到变量pivot。

对算法的最好理解方式是手动地模拟一遍这些算法。
2.4实现代码
void Quicksort(ElemType A[], int low, int high) {if (low < high) {//递归跳出的条件//Partition()就是划分操作,将表A [low…high]划分为满足上述条件的两个子表int pivotpos = Partition(A, low, high);//划分Quicksort(A, low, pivotpos - 1);//依次对两个子表进行递归排序Quicksort(A, pivotpos + 1, high);}
}int Partition(ElemType A[], int low, int high) {//一趟划分ElemType pivot = A[low]; //将当前表中第一个元素设为枢轴,对表进行划分while (low < high) {//循环跳出条件while (low < high && A[high] >= pivot)--high;A[low] = A[high];//将比枢轴小的元素移动到左端while (low < high && A[low] < pivot)++low;A[high] = A[low];//将比枢轴大的元素移动到右端}A[low] = pivot;//枢轴元素存放到最终位置return low;//返回存放枢轴的最终位置
}2.5关键要点
(1)基准值的选择:选择待排序数组中的一个元素作为基准值。通常情况下选择第一个元素,但也可以采用其他策略,如随机选择。
(2)分割过程:将数组分割成两个子数组,一个包含小于等于基准值的元素,另一个包含大于基准值的元素。这个过程通常被称为分区(partition)。
(3)递归排序:对分割得到的两个子数组递归地应用快速排序算法。这是分治策略的关键,通过不断递归排序,最终实现整个数组的排序。
(4)合并过程:将排好序的子数组与基准值合并起来,形成最终的有序数组。
(5)终止条件:当子数组的长度为1或0时,不再进行递归,因为长度为1或0的数组被认为是有序的。
(6)不稳定性:快速排序是一种不稳定的排序算法,即相等元素的相对位置可能在排序前后发生变化。
(7)空间复杂度:快速排序是原地排序算法,不需要额外的存储空间,只需要在递归调用时保持一些辅助变量。
(8)平均时间复杂度:快速排序的平均时间复杂度为O(n log n),其中n是数组的长度。最坏情况下为O(n^2),但在实际应用中,快速排序通常表现良好。
3.性能分析
3.1空间效率
由于快速排序是递归的,需要借助一个递归工作栈来保存每层递归调用的必要信息,其容量与递归调用的最大深度一致。最好情况下为O(log2n);最坏情况下,因为要进行n-1次递归调用,所以栈的深度为O(n);平均情况下,栈的深度为O(log2n)。
3.2时间效率
快速排序的运行时间与划分是否对称有关,快速排序的最坏情况发生在两个区域分别包含n-1个元素和0个元素时,这种最大限度的不对称性若发生在每层递归上,即对应于初始排序表基本有序或基本逆序时,就得到最坏情况下的时间复杂度为0(n^2)。
快速排序是所有内部排序算法中平均性能最优的排序算法
3.3稳定性
在划分算法中,若右端区间有两个关键字相同,且均小于基准值的记录,则在交换到左端区间后,它们的相对位置会发生变化,即快速排序是一种不稳定的排序方法。例如,表L={3,2,2},经过一趟排序后L={2,2,3},最终排序序列也是L={2,2,3),显然,2与2的相对次序己发生了变化。
相关文章:
排序算法——关于快速排序的详解
目录 1.基本思想 2.基本原理 2.1划分思想 2.2排序过程 (1)选择基准值 (2)分割过程(Partition) (3)递归排序 (4)合并过程 2.3具体实例 2.4实现代码 2.5关键要…...

序言:《未来已来》
尊敬的读者, 你是否曾经在面对冗长的报告、繁琐的工作、沉重的生活压力时感到困扰,渴望找到一种方式来提升效率,释放压力?你是否曾经在自我创业的道路上,苦于找不到有效的市场营销方式,寻求突破?…...

【Spring实战】22 Spring Actuator 入门
文章目录 1. 定义2. 功能3. 依赖4. 配置5. 常用的应用场景1)环境监控2)运维管理3)性能优化 结论 Spring Actuator 是 Spring 框架的一个模块,为开发人员提供了一套强大的监控和管理功能。本文将深入探讨 Spring Actuator 的定义、…...

JSON安全性
确保JSON处理的安全性是现代Web开发中重要的一环。以下是一些关键的安全实践,用于防止JSON注入攻击以及确保数据在传输过程中的安全性: 1. **验证和清洗输入:** - 在将任何数据写入数据库之前,请确保验证用户输入。对于期望的JSON…...

spring-boot-maven插件repackage(goal)的那些事
前言:在打包Springboot项目成jar包时需要在pom.xml使用spring-boot-maven-plugin来增加Maven功能,在我的上一篇博客<<Maven生命周期和插件的那些事(2021版)>>中已经介绍过Maven和插件的关系,在此不再赘述&…...

ubuntu的boot分区被删除恢复
在鼓捣黑苹果的时候,误删了ubuntu的boot分区,进系统的时候出现emergency mode,那么现在来讲讲怎么恢复 首先做一个ubuntu的启动盘,然后进入启动盘的系统选择试用 呼出命令行,然后添加一个源 sudo add-apt-repository…...

【userfaultfd 条件竞争】starCTF2019 - hackme
前言 呜呜呜,这题不难,但是差不多一个多月没碰我的女朋友 kernel pwn 了,对我的 root 宝宝也是非常想念,可惜这题没有找到我的 root 宝宝,就偷了她的 flag。 哎有点生疏了,这题没看出来堆溢出,…...

深度学习中的自动化标签转换:对数据集所有标签做映射转换
在机器学习中,特别是在涉及图像识别或分类的项目中,标签数据的组织和准确性至关重要。本文探讨了一个旨在高效转换标签数据的 Python 脚本。该脚本在需要更新或更改类标签的场景中特别有用,这是正在进行的机器学习项目中的常见任务。我们将逐…...
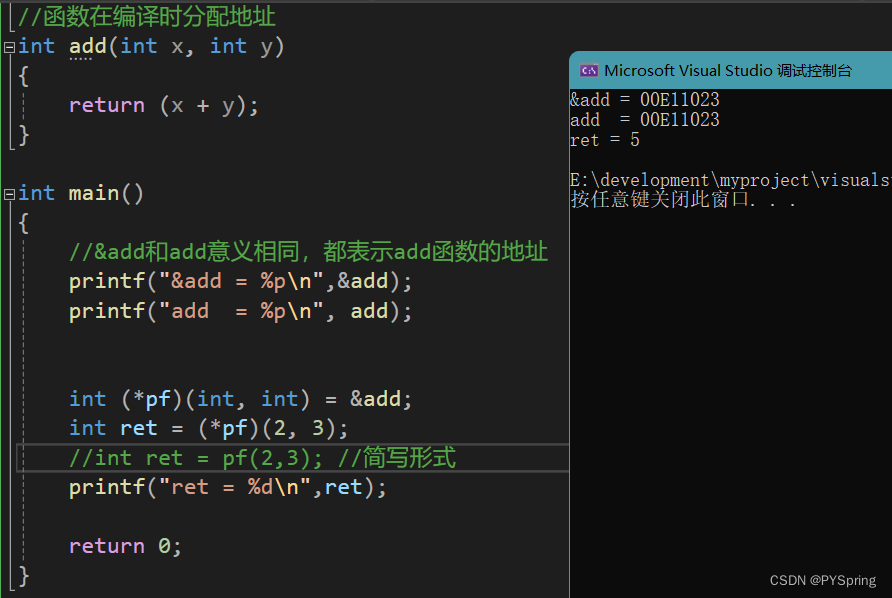
c语言-函数指针
目录 前言一、函数指针1.1 函数指针定义1.2 函数指针调用函数1.3 函数指针代码分析 总结 前言 本篇文章介绍c语言中的函数指针以及函数指针的应用。 一、函数指针 函数指针:指向函数的指针。 函数在编译时分配地址。 &函数名 和 函数名代表的意义相同…...

conda
一、安装 推荐清华源 https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/?CN&OD选择版本 Miniconda3-py39_4.12.0-MacOSX-arm64.pkg测试命令 conda help二、更换仓库 配置加速 https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/没有 .condarc 文件则执行…...

【Vue】灵魂拷问
1、说说Vue的优缺点 优点:渐进式,组件化,轻量级,虚拟dom,响应式,单页面路由,数据与视图分开缺点:单页面不利于seo,不支持IE8以下,首屏加载时间长 2、为什么…...

Scrapy 1.3.0 使用简介
scrapy 1.3.0 python 2.7 创建一个项目: Before you startscraping, you will have to set up a new Scrapy project. Enter a directory whereyou’d like to store your code and run: scrapy startproject tutorial 然后就会得到一系列文件: 第一个爬…...
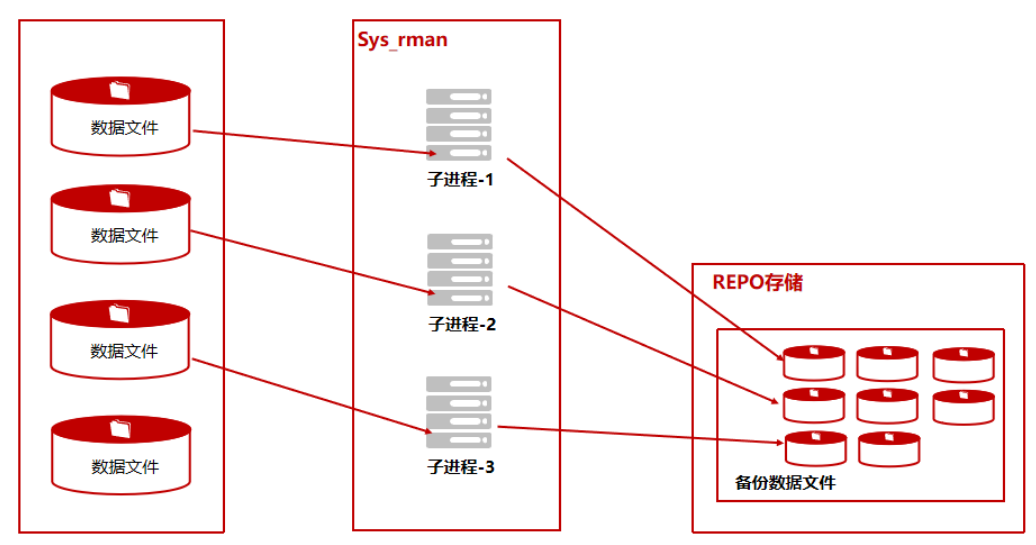
单机+内部备份_全备案例
此场景为单机数据库节点内部备份,方便部署和操作,但备份REPO与数据库实例处于同一个物理主机,冗余度较低。 前期准备 配置ksql免密登录(必须) 在Kingbase数据库运行维护中,经常用到ksql工具登录数据库,本地免密登录…...
【kettle】pdi/data-integration 打开ktr文件报错“Unable to load step info from XML“
一、报错内容: Unable to load step info from XML step nodeorg.pentaho.di.core.exception.KettleXMLException: Unable to load step info from XMLat org.pentaho.commons.launcher.Launcher.main (Launcher.java:92)at java.lang.reflect.Method.invoke (Met…...

cocos creator人开发小游戏免费素材资源
1、首先熟悉官方的手册和api文档,文档还是比较详细,游戏的方方面面都涉及到了 官方手册: http://docs.cocos.com/creator/manual/zh/官方api文档: http://docs.cocos.com/creator/api/zh/官方论坛: https://forum.coco…...

除了sd webui,compfy还有一个sd UI
GitHub - VoltaML/voltaML-fast-stable-diffusion: Beautiful and Easy to use Stable Diffusion WebUI...

c++属于同一个类的不同对象之间可相互访问private和protected成员
先看一个代码例子: #include <stdio.h>class A { private:char* name;void printA_Name() const {printf(name);} public:A(char* name) {this->name name;}void printA_Name(const A& a) {printf(a.name);}void printA_Name2(const A& a) {a.pr…...
QT/C++ 远程数据采集上位机+服务器
一、项目介绍: 远程数据采集与传输 课题要求:编写个基于TCP的网络数据获取与传输的应用程序; 该程序具备以下功能: 1)本地端程序够通过串口与下位机(单片机)进行通信,实现数据采集任务 2)本地端程序能将所获取下位机数据进行保存(如csv文本格式等); 3…...

算法每日一题:保龄球游戏的获胜者
大家好,我是星恒 今天的每一一题是一道简单题目,但是没能秒掉,原因就是题意理解不到位,边界问题没有判断清楚 不过这本来就是一个试错,迭代,积累经验的过程,加油加油,相信做多了&…...

Do you know about domestic CPUs
Do you know about domestic CPUs CPU指令集国产CPU CPU指令集 国产CPU 参考文献 国产CPU之4种架构和6大品牌指令集及架构一文深入了解 CPU 的型号、代际架构与微架构国产GPU芯片厂商有哪些深入GPU硬件架构及运行机制详解服务器GPU架构和基础知识...

Awesome List Creator:基于规则引擎的自动化资源清单生成工具
1. 项目概述:一个清单的“引擎”在信息过载的时代,无论是开发者寻找工具库,还是学习者梳理知识体系,一份结构清晰、内容精选的“Awesome List”(优质资源清单)都堪称无价之宝。然而,维护一份高质…...
)
DeepSeek Mesh可观测性体系构建:1个Prometheus+3类自定义指标+7类黄金信号告警模板(附YAML源码)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Mesh可观测性体系全景概览 DeepSeek Mesh 是面向大规模 AI 模型推理服务的云原生服务网格,其可观测性体系并非简单叠加监控指标,而是围绕模型生命周期、推理链路与资源…...

智能体元观察者技能:提升AI自主决策的监控与反思能力
1. 项目概述:一个面向智能体的“元观察者”技能最近在折腾智能体(Agent)开发,特别是那些需要长期运行、具备一定自主决策能力的应用时,发现一个普遍痛点:智能体在执行任务时,往往“埋头苦干”&a…...

凌晨还在改论文?这些降重黑科技帮你一键通关
凌晨对着电脑屏幕改论文,那种既疲惫又焦虑的感觉,经历过的人都懂。好在现在的降重工具已经不只是“替换同义词”那么简单了,像 毕业之家 和 PaperRed 这两款主流工具,各自走了完全不同的技术路线,可以根据你的痛点来选…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...

SITS 2026多目标优化落地指南:从梯度冲突到任务解耦,7步实现Pareto前沿精度提升23.6%
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在SITS 2026竞赛框架下,AI原生多任务学习(AI-Native Multi-Task Learning, AMTL)不再依赖传统单任务迁移…...

从手忙脚乱到智能掌控:League-Toolkit如何解决你的英雄联盟痛点
从手忙脚乱到智能掌控:League-Toolkit如何解决你的英雄联盟痛点 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾经在极地大…...

【研报 A109】2026年脑机接口产业化专题报告:首个侵入式产品获批,医保完成赋码
摘要:脑机接口行业正迎来产业化应用的关键元年,2026年行业正式从实验室研究走向规模化商业化落地,当前行业处于导入期尾端、爆发前夜,非侵入式与半侵入式路径已率先打通商业化通道,侵入式则处于临床验证阶段。政策端&a…...

怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南
怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPi…...

3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南
3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英…...