Scrapy 1.3.0 使用简介
scrapy 1.3.0 python 2.7
创建一个项目:
Before you startscraping, you will have to set up a new Scrapy project. Enter a directory whereyou’d like to store your code and run:
scrapy startproject tutorial
然后就会得到一系列文件:
第一个爬虫
import scrapy
class QuotesSpider(scrapy.Spider):
name ="quotes"
def start_requests(self):
urls = [
'Quotes to Scrape',
'Quotes to Scrape',
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
page =response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
自定义的QuotesSpider类继承了scrapy.Spider类,并且有三个属性:
- name:用来识别爬虫,必须唯一
- start_requests():必须返回一个请求连接的可迭代的对象(一个请求的生成器或者列表)
- parse():被调用,用来处理服务器的响应,response 参数是TextResponse 的实例,保存整个网页用来被更有用的函数处理。
运行爬虫:
scrapy crawl quotes
结果:
刚刚的运行过程:
start_requests方法返回了scrapy的请求清单(scrapy.Request objects),
一旦接收到请求,scrapy会初始化Response对象,并且调用相关方法(例子中用的是parse方法)
将response传递给它。
start_requests简介:
用urls生成请求列表的start_requests()方法,可以用写了一系列的URLS的start_urls属性代替,
这个列表将会被默认的接口实现start_requests(),来初始化spider的请求。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls =[
'Quotes to Scrape',
'Quotes to Scrape',
]
def parse(self, response):
page =response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
parse函数没有显式调用,因为在scrapy中parse是默认的回调方法
抽取数据
scrapy最好用的学习抽取数据的方法是选择器来使用scrapy shell。
Scrapy shell — Scrapy 2.11.0 documentation
Scrapy shell会自动用下载的网页创建一些实用对象,例如:
Response object andthe Selector objects (for both HTML and XML content)
使用scrapy shell测试数据
当抽取数据为空时,可以用浏览器查看请求的网页
Finally you hitCtrl-D (or Ctrl-Z in Windows) to exit the shell and resume the crawling:
用css选择器来抽取数据
scrapy shell "Quotes to Scrape"
使用 response.css('title')抽取数据会得到一张叫“ SelectorList”的列表。SelectorList代表 Selector对象列表,这个对象包装了 XML/HTML的元素,这些元素可以因一部的抽取数据。
::text 用在CSS查询中, 表示我们只想抽取 <title> 标签中的text元素。
因为extract只是获取到一个列表,所以有extract_first()、response.css('title::text')[0].extract()这样的用法,可以直接抽取到列表中的元素
注意: using.extract_first() avoids an IndexError andreturns None when it doesn’t find any element matching the selection.
参考下载的页面学习:
后面是使用正则表达式抽取数据
XPath:a brief intro
除了CSS, Scrapy 选择器也支持 XPath的表达形式:
使用火狐浏览器的firebug:
抽取名言和作者
首先观察网页 Quotes to Scrape:
抽取特定内容:
空格好像是用来处理div class=“tags”这个 div标签中第一个标签。
知道每个数据怎么取出后,可以使用代码获得:
for quote inresponse.css("div.quote"):
... text =quote.css("span.text::text").extract_first()
... author =quote.css("small.author::text").extract_first()
... tags = quote.css("div.tagsa.tag::text").extract()
... print(dict(text=text, author=author,tags=tags))
最后得到的爬虫:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'Quotes to Scrape',
'Quotes to Scrape',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author': quote.css('spansmall::text').extract_first(),
'tags': quote.css('div.tagsa.tag::text').extract(),
}
存储爬取的数据:
使用命令行:
- scrapy crawl quotes -o quotes.json -json格式
- scrapy crawl quotes -o quotes.jl -jsonlines格式
下一页:
先观察代码:
但是这样只能获取锚元素,想要获得连接可以:
下面是能自动进入下一页爬取的爬虫:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'Quotes to Scrape',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author': quote.css('spansmall::text').extract_first(),
'tags': quote.css('div.tagsa.tag::text').extract(),
}
next_page = response.css('li.nexta::attr(href)').extract_first()
if next_page is not None:
next_page =response.urljoin(next_page)
yield scrapy.Request(next_page,callback=self.parse)
至此爬虫可以用urljoin()建立一个绝对URL,并且能产生到下一页的新请求,然后将
自己注册到毁掉函数中,抽取下一页数据,直到爬完所有数据。
通过以上方法,可以构建一个复杂的爬虫,按照用户定义rules来爬取网页。
使用scrapy参数:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
url = 'Quotes to Scrape'
tag = getattr(self, 'tag', None)
if tag is not None:
url = url + 'tag/' + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text':quote.css('span.text::text').extract_first(),
'author': quote.css('span smalla::text').extract_first(),
}
next_page = response.css('li.nexta::attr(href)').extract_first()
if next_page is not None:
next_page =response.urljoin(next_page)
yield scrapy.Request(next_page,self.parse)
针对上面的程序,使用命令:
scrapy crawl quotes -oquotes-humor.json -a tag=humor
it will only visit URLs from the humor tag,such as http://quotes.toscrape.com/tag/humor.
相关文章:

Scrapy 1.3.0 使用简介
scrapy 1.3.0 python 2.7 创建一个项目: Before you startscraping, you will have to set up a new Scrapy project. Enter a directory whereyou’d like to store your code and run: scrapy startproject tutorial 然后就会得到一系列文件: 第一个爬…...
单机+内部备份_全备案例
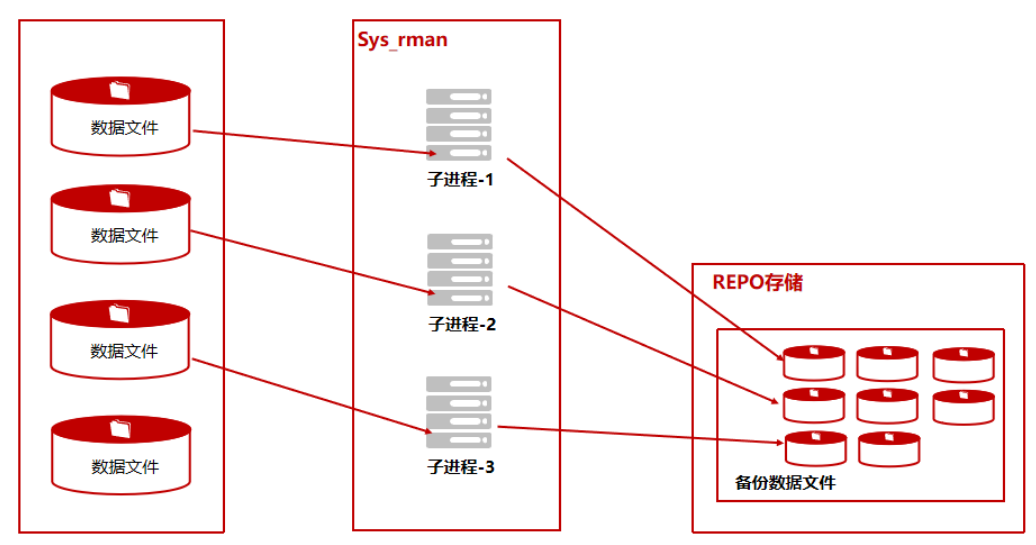
此场景为单机数据库节点内部备份,方便部署和操作,但备份REPO与数据库实例处于同一个物理主机,冗余度较低。 前期准备 配置ksql免密登录(必须) 在Kingbase数据库运行维护中,经常用到ksql工具登录数据库,本地免密登录…...
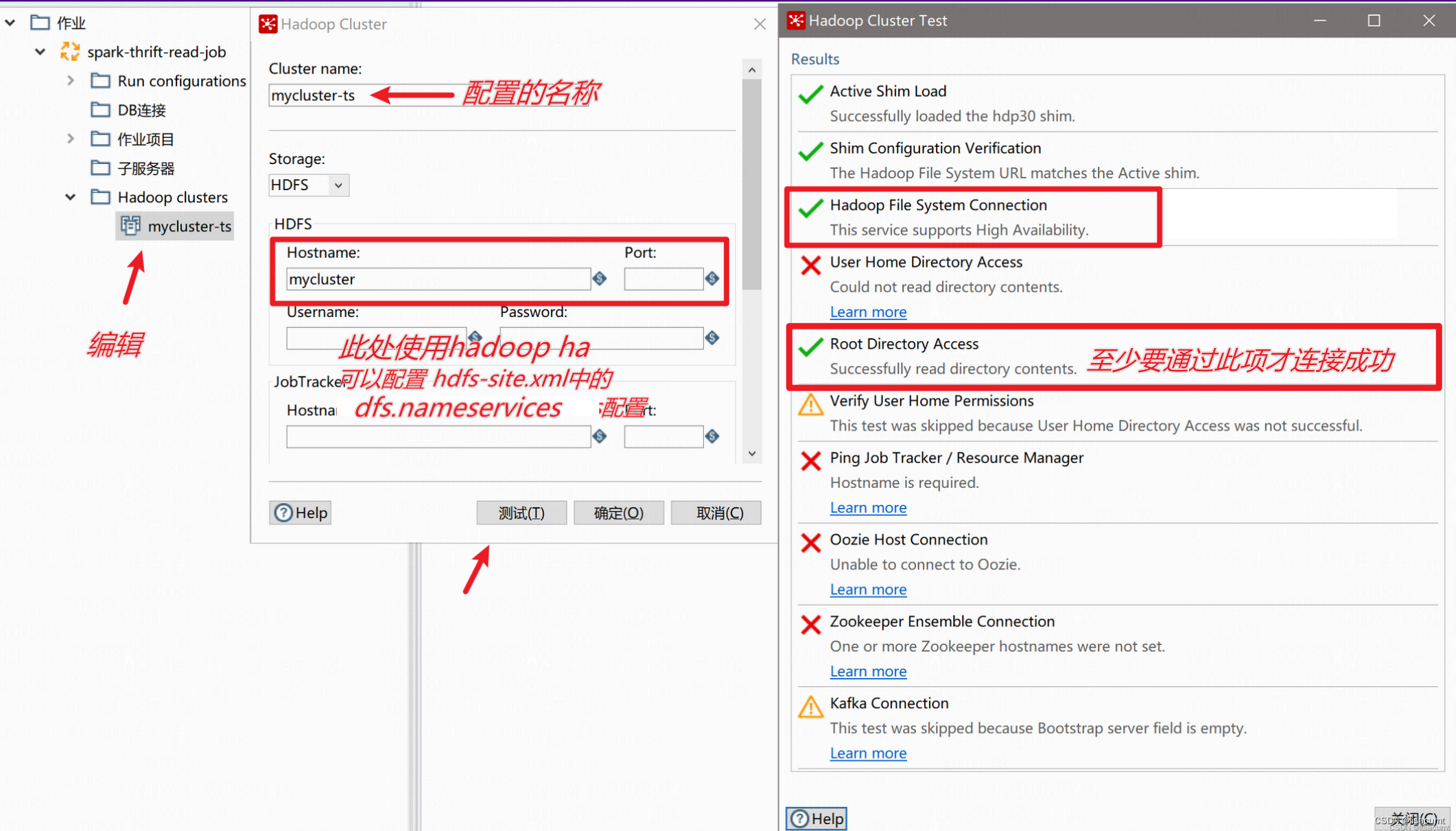
【kettle】pdi/data-integration 打开ktr文件报错“Unable to load step info from XML“
一、报错内容: Unable to load step info from XML step nodeorg.pentaho.di.core.exception.KettleXMLException: Unable to load step info from XMLat org.pentaho.commons.launcher.Launcher.main (Launcher.java:92)at java.lang.reflect.Method.invoke (Met…...

cocos creator人开发小游戏免费素材资源
1、首先熟悉官方的手册和api文档,文档还是比较详细,游戏的方方面面都涉及到了 官方手册: http://docs.cocos.com/creator/manual/zh/官方api文档: http://docs.cocos.com/creator/api/zh/官方论坛: https://forum.coco…...

除了sd webui,compfy还有一个sd UI
GitHub - VoltaML/voltaML-fast-stable-diffusion: Beautiful and Easy to use Stable Diffusion WebUI...

c++属于同一个类的不同对象之间可相互访问private和protected成员
先看一个代码例子: #include <stdio.h>class A { private:char* name;void printA_Name() const {printf(name);} public:A(char* name) {this->name name;}void printA_Name(const A& a) {printf(a.name);}void printA_Name2(const A& a) {a.pr…...
QT/C++ 远程数据采集上位机+服务器
一、项目介绍: 远程数据采集与传输 课题要求:编写个基于TCP的网络数据获取与传输的应用程序; 该程序具备以下功能: 1)本地端程序够通过串口与下位机(单片机)进行通信,实现数据采集任务 2)本地端程序能将所获取下位机数据进行保存(如csv文本格式等); 3…...

算法每日一题:保龄球游戏的获胜者
大家好,我是星恒 今天的每一一题是一道简单题目,但是没能秒掉,原因就是题意理解不到位,边界问题没有判断清楚 不过这本来就是一个试错,迭代,积累经验的过程,加油加油,相信做多了&…...

Do you know about domestic CPUs
Do you know about domestic CPUs CPU指令集国产CPU CPU指令集 国产CPU 参考文献 国产CPU之4种架构和6大品牌指令集及架构一文深入了解 CPU 的型号、代际架构与微架构国产GPU芯片厂商有哪些深入GPU硬件架构及运行机制详解服务器GPU架构和基础知识...

软件设计模式 --- 类,对象和工厂模式的引入
Q1:什么是软件设计模式? A:软件设计模式,又称设计模式。它是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。综上&…...
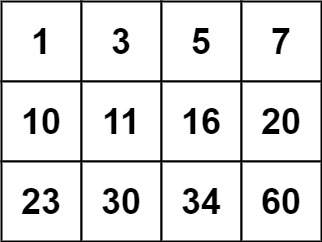
LeetCode74二分搜索优化:二维矩阵中的高效查找策略
题目描述 力扣地址 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则&…...

三极管组成的光控开关电路原理图
什么是光控开关 光控开关/光控时控器采用先进的嵌入式微型计算机控制技术,融光控功能和普通时控器两大功能为一体的多功能高级时控器(时控开关),根据节能需要可以将光控探头(功能)与时控功能同时启用&…...
系统列)
【PostgreSQL】从零开始:(四十二)系统列
PostgreSQL 中的系统列 PostgreSQL 中的系统列是一组特殊的列,用于存储关于表和视图的元数据信息。这些列是由 PostgreSQL 数据库自动创建和维护的,并且不能直接修改或删除。 每个表都有多个系统列,这些列由系统隐式定义。因此,…...

快速、准确地检测和分类病毒序列分析工具 ViralCC的介绍和详细使用方法, 附带应用脚本
介绍 viralcc是一个基因组病毒分析工具,可以用于快速、准确地检测和分类病毒序列。 github:dyxstat/ViralCC: ViralCC: leveraging metagenomic proximity-ligation to retrieve complete viral genomes (github.com) Instruction of reproducing resul…...

DNs服务学习笔记
DNS:域名系统(英文:Domain Name System)是一个域名系统,是万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。类似于生活中的11…...

获取线程池中任务执行数量
获取线程池中任务执行数量 通过线程池进行任务处理,有时我们需要知道线程池中任务的执行状态。通过ThreadPoolExecutor的相关API实时获取线程数量,排队任务数量,执行完成线程数量等信息。 实例 private static ExecutorService es new Thr…...

RK3566 Android 11平台上适配YT8512C 100M PHY
RK3566代码之前适配的1000M IC RTL8211F , 现在需要在之前的基础上修改PHY IC 为裕泰的YT8512C ----------------------------------------------------------------------//将1000M 的配置关掉,改为100M 配置,查看RK3566 资料关于以太网的配置即可知道如何修改 #if…...
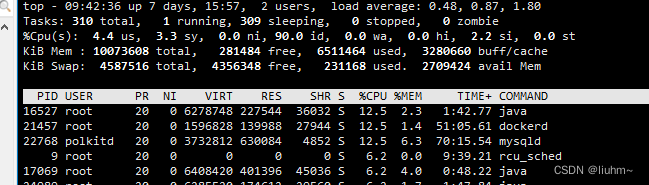
docker 部署haproxy cpu占用特别高
在部署mysql 主主高可用时,使用haproxy进行负载,在服务部使用的情况下发现服务器cpu占比高,负载也高,因此急需解决这个问题。 1.解决前现状 1.1 部署配置文件 cat > haproxy.cfg << EOF globalmaxconn 4000nbthrea…...
Oracle导出CSV文件
利用spool spool基本格式: spool 路径文件名 select col1||,||col2||,||col3||,||col4 from tablename; spool off spool常用的设置: set colsep ; //域输出分隔符 set echo off; //显示start启动的脚本中的每个sql命令,缺…...

图像分割实战-系列教程12:deeplab系列算法概述
🍁🍁🍁图像分割实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 1、deeplab概述 图像分割中的传统做法:为了增大感受野,通常都会选择pooling…...

基于RAG架构的企业级私有化大模型知识库实战指南
1. 项目概述:当大语言模型遇见企业级数据如果你最近在关注企业级AI应用,特别是如何安全、高效地利用大语言模型来处理和分析内部数据,那么“h2oai/h2ogpt”这个项目绝对值得你花时间深入了解。这不仅仅是一个简单的聊天机器人接口,…...

职得Offer校园求职助手Pro深度评测:一个AI Agent陪你跑完求职全流程
一、 职得Offer是什么?—— 不止是工具,更是全程陪伴的AI求职伙伴 在AI应用爆发的今天,面对市面上众多的简历模板、面经题库和招聘平台,求职者尤其是学生群体,依然会陷入“信息过载却无从下手”的困境。“职得Offer校…...

OpenCore Legacy Patcher:让你的老款Mac重获新生,畅享最新macOS系统
OpenCore Legacy Patcher:让你的老款Mac重获新生,畅享最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台2008…...

Mastra AI编排框架:构建生产级智能工作流的完整指南
1. 项目概述:一个面向开发者的AI应用编排框架最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:如何把不同的AI模型、工具和数据源高效地串联起来,形成一个稳定、可维护的智能工作流。无论是想做个智能客服,还是搞…...

GitHub开源项目法律合规自动化:exoclaw-github的设计与实现
1. 项目概述:一个为GitHub仓库定制的“法律条款”守护者最近在开源社区里折腾,发现一个挺有意思的现象:很多开发者辛辛苦苦维护的项目,因为缺少清晰、合规的贡献者协议或开源许可证,导致后续在代码合并、版权归属甚至商…...

跨镜跟踪技术白皮书:ReID瓶颈与镜像无感解决方案
跨镜跟踪技术白皮书:ReID瓶颈与镜像无感解决方案前言在数字孪生、视频孪生、全域安防感知等领域,跨镜跟踪作为全域连续感知、目标轨迹溯源的核心技术,已成为智慧园区、工业厂区、城市治理、交通枢纽等场景落地的关键支撑。当前,行…...
)
别再手动调图了:用Python+Midjourney API自动批处理建筑效果图(含GitHub开源脚本+37个真实项目参数)
更多请点击: https://kaifayun.com 第一章:别再手动调图了:用PythonMidjourney API自动批处理建筑效果图(含GitHub开源脚本37个真实项目参数) 建筑可视化团队常面临重复性高、参数微调繁琐的出图任务——同一方案需生…...

开源AI智能体技能库:模块化设计赋能AI应用开发
1. 项目概述:一个开源的AI智能体技能库最近在GitHub上闲逛,发现了一个挺有意思的项目,叫free-ai-agent-skills。光看名字,你可能会觉得这又是一个堆砌各种AI工具调用的代码仓库。但点进去仔细研究后,我发现它的定位和设…...
)
千问 LeetCode 2402.会议室 III public int mostBooked(int n, int[][] meetings)
这道题是经典的会议室 III,核心是双堆模拟,一个堆管空闲会议室(按编号排序),一个堆管正在使用的会议室(按结束时间排序)。解题思路1. 排序:按会议开始时间升序排列。 2. 双堆初始化&…...

【NotebookLM政治学研究加速器】:20年政治理论研究员亲授5大高阶用法,告别文献综述低效时代
更多请点击: https://intelliparadigm.com 第一章:NotebookLM政治学研究辅助的范式革命 传统政治学研究长期依赖人工文献综述、手工编码与静态模型推演,面临信息过载、理论验证滞后与跨文本语义关联薄弱等结构性瓶颈。NotebookLM 作为基于引…...