湖仓架构的演进
1.数据仓库架构的历史演进
起初,业界数据处理首选方式是数仓架构。通常数据处理的流程是把一些业务数据库,通过ETL的方式加载到Data Warehouse中,再在前端接入一些报表或者BI的工具去展示。
数据仓库概念是 Inmon 于 1990 年提出并给出了完整的建设方法。随着互联网时代来临,数据量暴增,开始使用大数据工具来替代经典数仓中的传统工具。此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构。
后来随着业务实时性要求的不断提高,人们开始在离线大数据架构基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是 Lambda 架构。
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的 Kappa 架构。
2.Lambda架构
传统的数仓架构
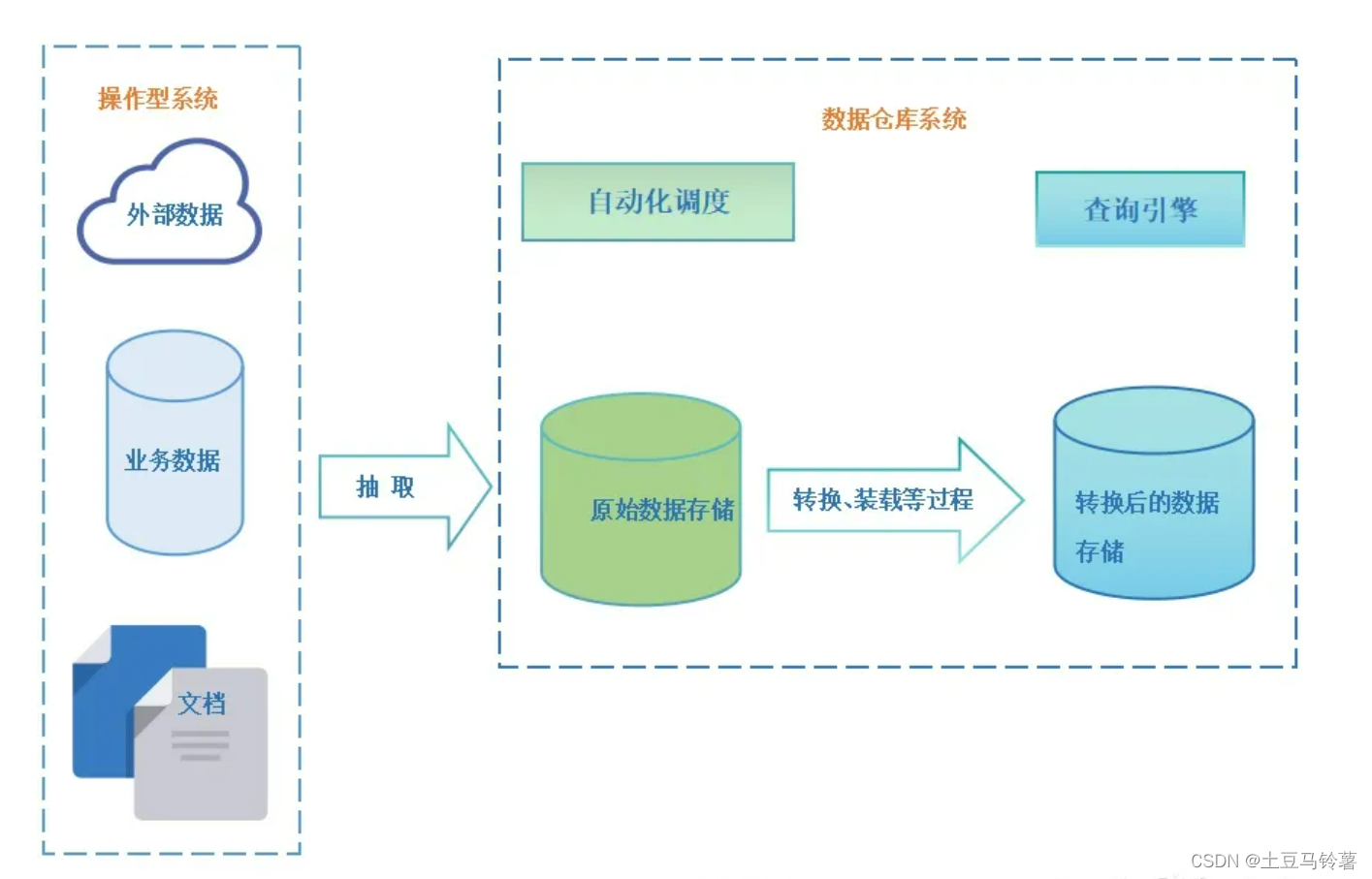
随着大数据的兴起,越来越多的公司开始面临海量数据的处理问题。传统的批处理系统无法满足实时数据处理的需求,而简单的流式处理系统又无法进行复杂的历史数据分析。这就需要一种混合架构,能够兼顾实时性和复杂分析。Lambda架构应运而生。

从底层的数据源开始,经过Kafka、Flume等数据组件进⾏收集,然后分成两条线进⾏计算:⼀条线是进⼊流式计算平台(例如 Storm、Flink或者SparkStreaming),去计算实时的⼀些指标;另⼀条线进⼊批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔⽇才能看见。
在这种架构下,流处理和批处理同时存在,以实现不同的业务场景数据需求。
- 批处理:批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图:批处理层使⽤可处理⼤量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。
- 流处理:流处理层通过提供最新数据的实时视图来最⼩化延迟。流处理层所⽣成的数据视图可能不如批处理层最终⽣成的视图那样准确或完整,但它们⼏乎在收到数据后⽴即可⽤。⽽当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。
Lambda架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以⽤晚上的时间来整体批量计算,这样把实时计算和离线计算⾼峰分开,这种架构⽀撑了数据⾏业的早期发展,但是它也有⼀些致命缺点,并在⼤数据3.0时代越来越不适应数据分析业务的需求。Lambda架构存在问题:
- 同时维护实时平台和离线平台两套引擎,运维成本高
- 实时离线两个平台需要维护两套框架不同但业务逻辑相同代码,开发成本高
- 数据有两条不同链路,容易造成数据的不一致性
- 数据更新成本大,需要重跑链路
- 随着业务数据量的增大,批量计算在计算窗⼝内⽆法完成。
3.Kappa架构
Kafka的创始⼈Jay Kreps认为在很多场景下,维护⼀套Lambda架构的⼤数据处理平台耗时耗⼒,于是提出在某些场景下,没有必要维护⼀个批处理层,直接使⽤⼀个流处理层即可满⾜需求,即下图所⽰的Kappa架构:

这种架构只关注流式计算,数据以流的⽅式被采集过来,实时计算引擎将计算结果放⼊数据服务层以供查询。可以认为Kappa架构是Lambda架构的⼀个简化版本,只是去除掉了Lambda架构中的离线批处理部分。
Kappa架构的兴起主要有两个原因:Kafka不仅起到消息队列的作⽤,也可以保存更长时间的历史数据,以替代Lambda架构中批处理层数据仓库部分。流处理引擎以⼀个更早的时间作为起点开始消费,起到了批处理的作⽤。
Flink流处理引擎解决了事件乱序下计算结果的准确性问题。Kappa架构相对更简单,实时性更好,所需的计算资源远⼩于Lambda架构。但是,Kappa架构不能完全取代Lambda架构,Kappa架构也有其缺点:
- 对消息队列存储要求高,消息队列的回溯能力不及离线存储
- 消息队列本身对数据存储有时效性,且当前无法使用 OLAP 引擎直接分析消息队列中的数据
- 全链路依赖消息队列的实时计算可能因为数据的时序性导致结果不正确
4.Lambda架构 VS Kappa架构
两种架构的区别如下:
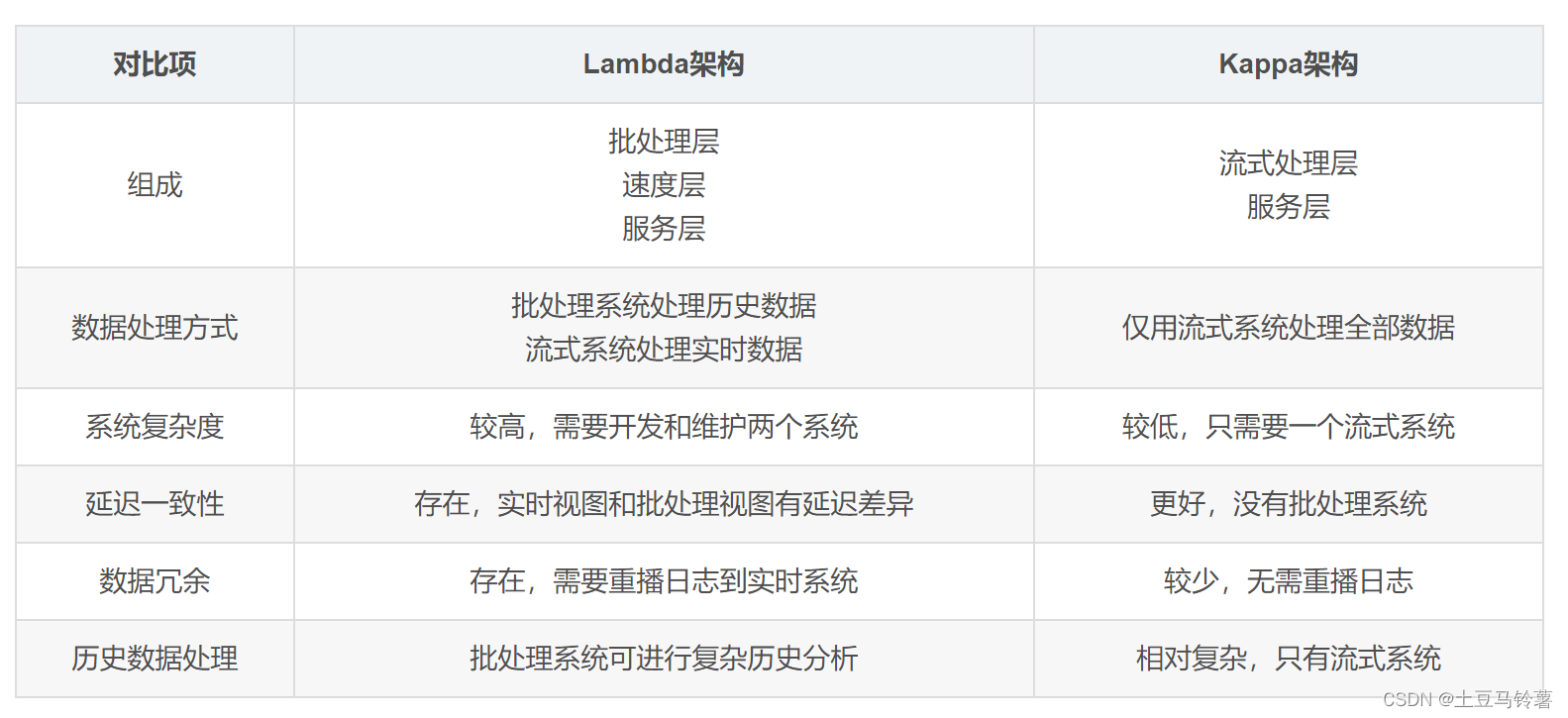
Lambda架构通过批处理层和速度层的组合,兼顾了低延迟和复杂分析,但系统较复杂,存在数据冗余和延迟不一致问题。
Kappa架构只通过流式系统实现所有处理,简化了架构,但历史数据分析相对复杂,需要流式系统保证精确一次语义。
Lambda和kappa架构两者都有各自的优缺点,需要根据具体场景进行技术选型和设计权衡。他们都有各⾃的适⽤领域;例如流处理与批处理分析流程⽐较统⼀,且允许⼀定的容错,⽤Kappa⽐较合适,少量关键指标(例如交易⾦额、业绩统计等)使⽤Lambda架构进⾏批量计算,增加⼀次校对过程。还有⼀些⽐较复杂的场景,批处理与流处理产⽣不同的结果(使⽤不同的机器学习模型,专家系统,或者实时计算难以处理的复杂计算,可能更适合Lambda架构。
5.湖仓一体架构
随着企业数据量的爆炸式增长,以及越来越多的企业上云,数据平台面临的数据存储、数据处理的挑战越来越大,采用什么样的技术来构建和迭代这个平台一直是业界研究的热点,新技术和新思路不断涌现。这些技术归纳下来以数据仓库 (Data Warehouse) 和数据湖 (Data Lake) 为两类典型的路线。近年来这两个路线在演进过程中边界日趋模糊,逐渐走向融合,开始形成所谓的现代数据架构 (Modern Data Architecture),又称湖仓一体 (Data Lakehouse)。
针对传统意义的数据湖,若在对象存储或者Hadoop上能够构建出具备数仓语义的一个格式,使得我们在湖上的格式有更强的能力去做数仓,则需要具备几个条件:
- 湖上可靠的数据管理:即需要一种开放的高性能的数据组织方式。采用传统方式定义表时,缺乏一种高效的表的组织方式。我们通常用 Hive表,它就是一个目录,没有特殊的能力。我们需要一种更高效的组织能力,兼顾一些仓的特性。
- 支持机器学习和数据科学:湖仓一体的技术需要有一套开放的标准或者开放的接口。大家在用数仓的时候,会发现它是存算一体的数仓,存储就是为了计算所定制。虽然性能很好,但不开放,也就是所有的生态都要建立在上面,但数据湖则是天然开放,Flink和Spark等其他引擎都能使用这些数据。
- 最先进的SQL性能:若湖仓一体只是湖,那么很轻易就能办到,但是它的性能会比较差。如果要使表具备仓的性能,比如能够匹敌类似Snowflake或者Redshift这样的性能,则需要一个高性能的SQL引擎,这也是Databricks做了Photon引擎的原因,有了这些,我们就可以真正在湖上构建出一个高性能的数仓,也就是“湖仓一体”。
如今在开源领域主要有四种技术拥有这些特性,分别是:Hudi、Iceberg、Delta Lake和Paimon。它们的功能整体上比较接近,都是一种数据的组织方式,即定义了一种表的格式,这个格式主要是定义数据的组织方式,而不是确定一种数据的存储格式。与一些纯粹的数据格式或Hive表(Hive 3.0版本前)相比,它提供了ACID事务能力,这样就具备了仓的能力,它可以提供一些事务的特性和并发能力,还可以做行级数据的修改、表结构的修改和进化,这些都是传统大数据格式难以完成的事项。
湖仓一体的技术优势:
- 优化数据入湖流程:相比传统的成熟形态,比如T+1的入仓形态或者入湖的形态,它可以用T+0的高效的流式入湖形态,大大降低了数据的可见时延。
- 支持更多的分析引擎:它是开放的,所以能够支持很多引擎。我们内部也对接了很多不同的引擎,包括Flink、Spark 、Presto和StarRocks等。
- 统一数据存储和灵活的文件组织:采用比较灵活的文件组织方式,具备了一些额外的特性,使得流和批都可以用这种文件组织方式进行消费。
- 增量读取处理能力
- 解决了数据湖 ACID 的问题
湖仓一体的这些优势,意味着我们可以通过这些技术以比较实时的方式提供可靠的原始数据访问能力给应用。
湖仓一体功能架构:

湖仓一体数据流转架构

数据入湖流程:

湖仓一体数据治理:

6.湖仓一体数据治理
6.1 统一的数据管控平台
数据管控管控服务,集成数据标准、数据质量、数据安全等全方位数据治理能力。
主要能力:
-
数据标准:数据标准编目、录入、发布、贯标、落标全方位能力提供。
-
落标检查:通过贯标流程,执行标准落标检查,赋能数据标准落地,实现贯标成果。
-
数据质量:以SQL形式灵活构建数据质量检查规则,高效检测数据质量缺陷。
-
质量模板:参数化的模板形式,复用质量规则,解决质量规则构建低效、繁杂的痛点。
-
质量报告:可视化展示数据质量检查结果,多维度展示质量问题。
-
数据权限:以最细粒度管控至行列级权限的全方位数据权限管控,保证数据使用安全。
-
数据保护:结合智能化手段和咨询方法论,妥善处理敏感数据,保护数据隐私。
6.2 数据资产目录
统一的数据资产目录,实现全局数据资产统管,对外提供数据资产服务。
主要能力:
- 元数据:自动化采集多元异构数据库资源列表详情,提供全局元数据服务。
- 数据血缘:自动化采集数据血缘关系,提效数据溯源和故障定位。
- 数据特征:分析数据资产全方位信息视图,赋能用户高效数据探查。
- 数据推荐:通过协同过滤算法,精准推荐用户需要的数据资产。
- 相似性分析:基于数据相似性来实现数据资产的智能匹配,赋能自动标签、自动落标
- 数据地图:数据地图门户,支持可视化、层级化展现全局数据资产,根据数据探查需求进行下钻、分析。
- 数据搜索:提供高性能全局数据资产搜索,帮助用户快速获取目标数据资产。
- 资产关联:提供标签、描述、关联数据标准和其他数据资产的方式丰富资产视图。
6.3 数据安全

隐私计算使数据在加密状态下可以计算,安全性和准确性由数学理论保证,无需提供可信第三方、平台硬件以及操作系统。

7.数据服务能力
能力构成
- 数据API:通过API为各个应用提供数据接口,打通应用之间的数据流转,构建新型应用。
- 数据标签平台:为业务部门直接提供有业务语义的高质量数据生产资料。
- 数据交换共享平台:为各个不同的部分提供有业务语义的数据搜索与共享能力,打通数据孤岛,构建业务协同效应。
- 数据报表平台:提供可视化报表的开发与分享能力,从数据统计中发现数据价值。
- 数据科学平台:提供数据建模、模型运行、模型服务发布等能力,帮助数据分析师构建端到端的机器学习开发与运行能力。
数据API服务开发、发布、调用管理与监控统计的数据服务平台。将多样的数据转换为业务应用直接使用的数据资产,打通数据与业务,完善企业数据中台建设。数据API服务开发、发布、管控。

标签建设开发、生命周期管理、标签应用为一体,支撑企业差异化的标签画像服务和运营需求;通过标签开发、管理、更新、监控、用户画像赋能企业更好的洞察客户需求、防控业务风险、提高服务质量和效率。

数据交换共享平台支撑企业数据共享交换的基础性互联互通平台。促进数据交易,实现企业内外部跨层级、跨系统、跨部门的数据共享和业务协同提供基础支撑。包括:数据资产发布管理、数据资产统计分析、数据资产编目管理、数据资产共享管理、数据资产数据安全管理、数据资产流程与审核管理、数据资产检索管理。
相关文章:
湖仓架构的演进
1.数据仓库架构的历史演进 起初,业界数据处理首选方式是数仓架构。通常数据处理的流程是把一些业务数据库,通过ETL的方式加载到Data Warehouse中,再在前端接入一些报表或者BI的工具去展示。 数据仓库概念是 Inmon 于 1990 年提出并给出了完…...
)
【头歌实训】Spark MLlib ( Python 版 )
文章目录 第1关:基本统计编程要求测试说明答案代码 第2关:回归编程要求测试说明参考资料答案代码 第3关:分类编程要求测试说明参考资料答案代码 第4关:协同过滤编程要求测试说明参考资料答案代码 第5关:聚类编程要求测…...

Java基础进阶(学习笔记)
注:本篇的代码和PPT图片来源于黑马程序员,本篇仅为学习笔记 static static 是静态的意思,可以修饰成员变量,也可以修饰成员方法 修饰成员的特点: 被其修饰的成员, 被该类的所有对象所共享 多了一种调用方式, 可以通过…...

uView NoticeBar 滚动通知
该组件用于滚动通告场景,有多种模式可供选择 #平台差异说明 App(vue)App(nvue)H5小程序√√√√ #基本使用 通过text参数设置需要滚动的内容 <template><view><u-notice-bar :text"text1&quo…...
外包干了3个多月,技术退步明显。。。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...

JSON的一些资源
以下是一些推荐的学习资源: 1. **官方网站**: - JSON.org: 这是一个很好的起点,它提供了JSON的基本介绍和语法规则。 2. **在线教程和课程**: - CSDN全方面学习各种资源。 - W3Schools (w3schools.com): 提供了一个关于JSON的教程,涵…...

最优化理论期末复习笔记 Part 1
数学基础线性代数 从行的角度从列的角度行列式的几何解释向量范数和矩阵范数 向量范数矩阵范数的更强的性质的意义 几种向量范数诱导的矩阵范数 1 范数诱导的矩阵范数无穷范数诱导的矩阵范数2 范数诱导的矩阵范数 各种范数之间的等价性向量与矩阵序列的收敛性 函数的可微性与展…...
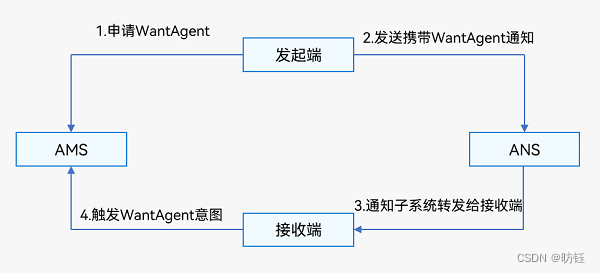
鸿蒙应用中的通知
目录 1、通知流程 2、发布通知 2.1、发布基础类型通知 2.1.1、接口说明 2.1.2、普通文本类型通知 2.1.3、长文本类型通知 2.1.4、多行文本类型通知 2.1.5、图片类型通知 2.2、发布进度条类型通知 2.2.1、接口说明 2.2.2、示例 2.3、为通知添加行为意图 2.3.1、接…...

如何停止一个运行中的Docker容器
要停止一个运行中的Docker容器,你可以使用以下命令: docker stop <容器ID或容器名> 将 <容器ID或容器名> 替换为你要停止的具体容器的标识符或名称。你可以使用以下命令查看正在运行的容器:docker ps 这将列出所有正在运行的…...
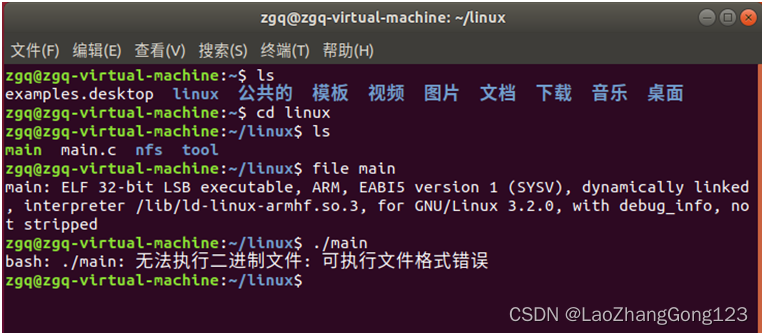
Linux第19步_安装“Ubutun交叉编译工具链”
由于Ubuntu系统使用的GCC编译器,编译结果是X86文件,只能在X86上运行,不能在ARM上直接运行。因此,还要安装一个“Ubutun交叉编译工具链”,才可以在ARM上运行。 arm-none-linux-gnueabi-gcc是 Codesourcery 公司&#x…...
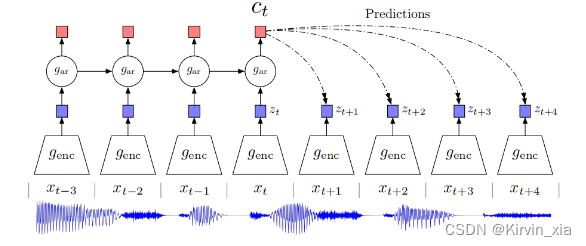
【论文阅读笔记】 Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding 摘要 这段文字是论文的摘要,作者讨论了监督学习在许多应用中取得的巨大进展,然而无监督学习并没有得到如此广泛的应用,仍然是人工智能中一个重要且具有挑战性的任务。在这项工作…...

CNN——LeNet
1.LeNet概述 LeNet是Yann LeCun于1988年提出的用于手写体数字识别的网络结构,它是最早发布的卷积神经网络之一,可以说LeNet是深度CNN网络的基石。 当时,LeNet取得了与支持向量机(support vector machines)性能相…...
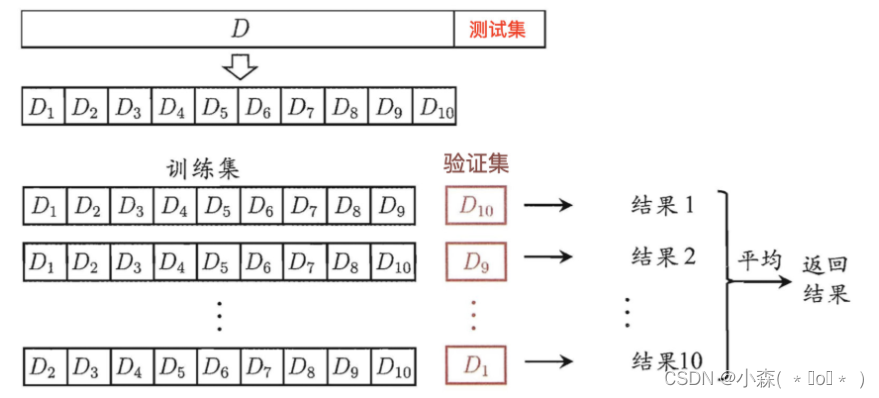
分类模型评估方法
1.数据集划分 1.1 为什么要划分数据集? 思考:我们有以下场景: 将所有的数据都作为训练数据,训练出一个模型直接上线预测 每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别 存在问题&…...

RabbitMQ高级
文章目录 一.消息可靠性1.生产者消息确认 MQ的一些常见问题 1.消息可靠性问题:如何确保发送的消息至少被消费一次 2.延迟消息问题:如何实现消息的延迟投递 3.高可用问题:如何避免单点的MQ故障而导致的不可用问题 4.消息堆积问题:如何解决数百万消息堆积,无法及时…...
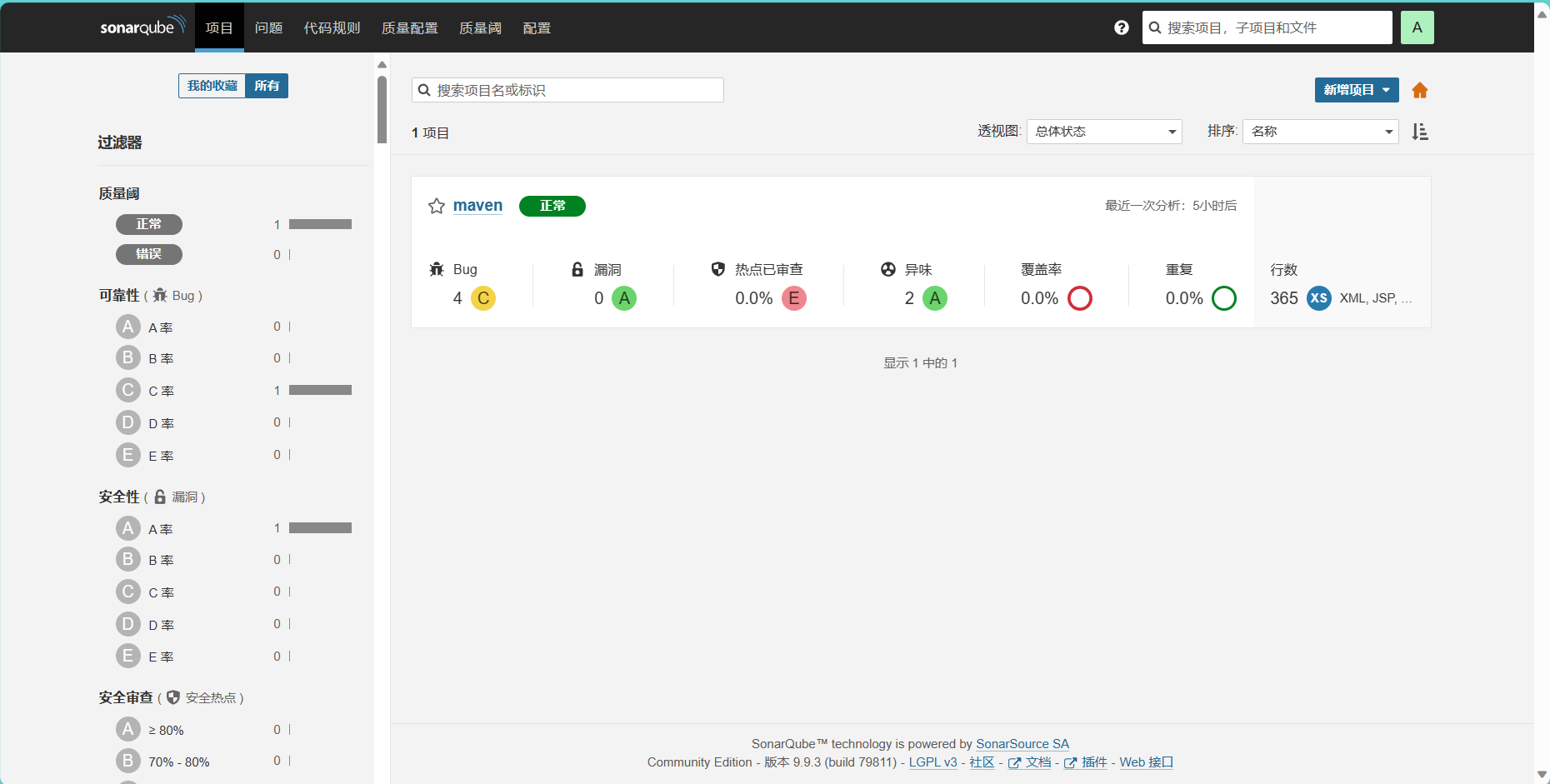
SonarQube 漏洞扫描
SonarQube 漏洞扫描 一、部署服务 1.1 docker方式部署 #安装docker curl -L download.beyourself.org.cn/shell-project/os/get-docker-latest.sh | sh yum install -y docker-compose #进去输入:set paste可以保证不穿行 [rootlocalhost sonar]# vim docker-compose.yml v…...

Web前端篇——ElementUI的Backtop 不显示问题
在使用ElementUI的Backtop回到顶部组件时,单独复制这一行代码 <el-backtop :right"100" :bottom"100" /> 发现页面在向下滚动时,并未出现Backtop组件。 可从以下3个方向进行分析: 指定target属性,且…...

MySQL 管理工具
1、MySQL 管理 系统数据库 a. mysql 命令 语法:mysql [options] [database] -u,--username 指定用户名-p,--password[name] 指定密码-h, --hostname 指定服务器IP或域名-P, --portport 指定连接端-e,--executename 执行SQL语句并退出 mysql -h192.168.200.202 -…...

LeetCode 33 搜索旋转排序数组
题目描述 搜索旋转排序数组 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., num…...
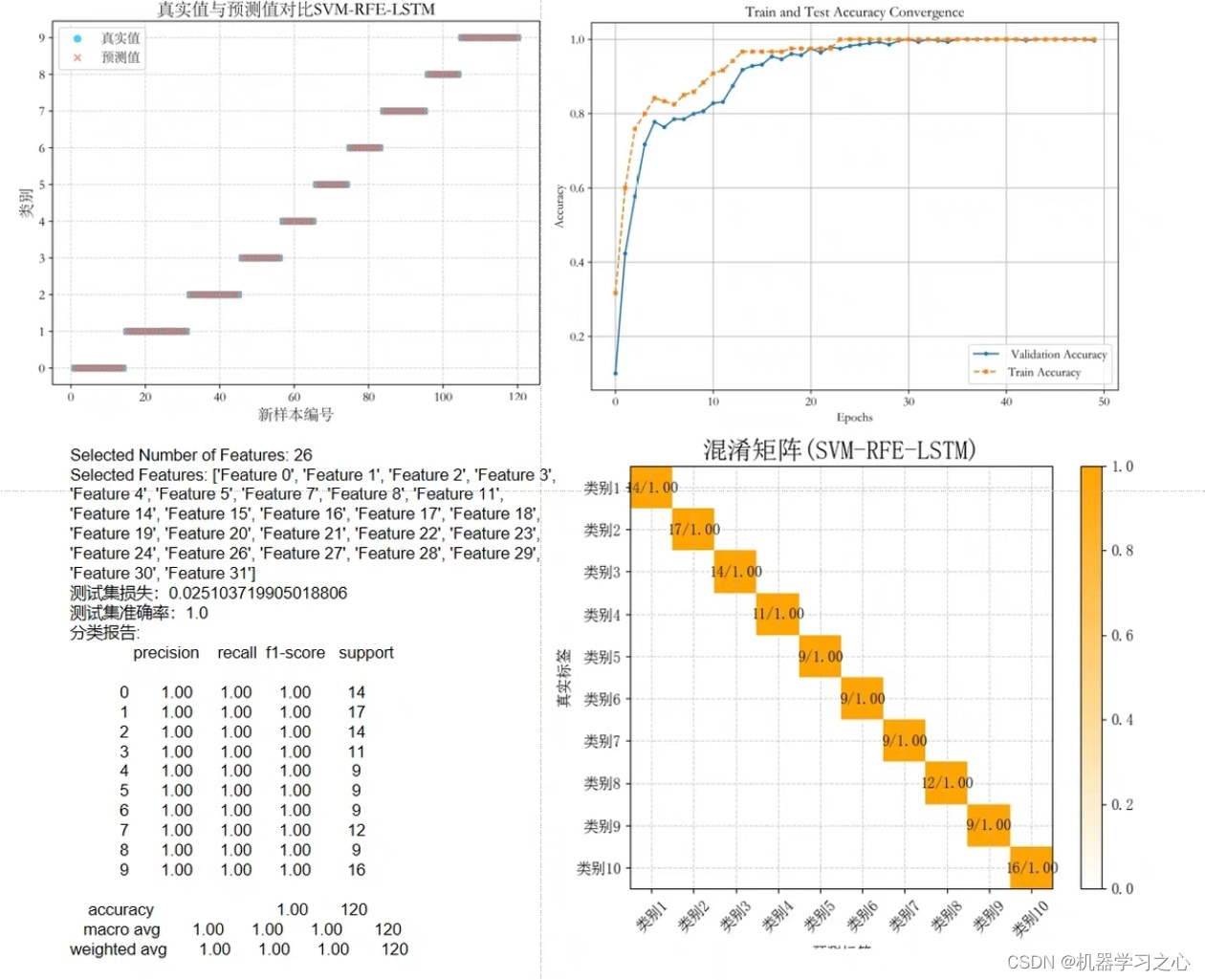
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测 目录 分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 基于SVM-RFE-LSTM的特征…...
JetBrains Rider使用总结
简介: JetBrains Rider 诞生于2016年,一款适配于游戏开发人员,是JetBrains旗下一款非常年轻的跨平台 .NET IDE。目前支持包括.NET 桌面应用、服务和库、Unity 和 Unreal Engine 游戏、Xamarin 、ASP.NET 和 ASP.NET Core web 等多种应用程序…...

欢迎使用Marp CLI
欢迎使用Marp CLI 【免费下载链接】marp-cli A CLI interface for Marp and Marpit based converters 项目地址: https://gitcode.com/gh_mirrors/ma/marp-cli 第二页幻灯片 列表项1列表项2列表项3 代码演示 def hello_world():print("Hello from Marp CLI!"…...

C#+FastReport 实战:动态图片绑定与报表生成全流程解析
1. 动态图片绑定与报表生成的核心思路 在C# WinForms应用开发中,动态图片绑定与报表生成是一个常见的需求场景。想象一下这样的业务场景:用户需要上传自己的产品图片,系统自动生成包含该图片的销售报表。这种需求在零售、医疗、教育等行业非常…...

WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录
WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 微信聊天记录中包含了我们珍贵的回忆、重要的工作…...
直接拿来用)
别再折腾了!我整理好的Elsevier LaTeX模板(通用版+复杂版)直接拿来用
Elsevier LaTeX模板终极避坑指南:从编译报错到一键投稿 第一次打开Elsevier官方LaTeX模板时,我盯着满屏的报错信息足足愣了五分钟——作为一个刚踏入科研领域的研究生,这简直像在解一道没有提示的数学证明题。经过三个月的反复试错和数十次期…...

东方博宜OJ入门题解:从A+B到高精度算法的实战解析
1. 东方博宜OJ平台入门指南 第一次接触在线评测系统(OJ)时,很多人都会被各种题目搞得晕头转向。东方博宜OJ作为国内知名的编程练习平台,特别适合编程新手从零开始系统学习。我刚开始刷题时也走过不少弯路,今天就和大家分享一些实战经验。 这…...

VMware ESXi版本回退全攻略:从适用条件、DCUI操作到6.x升7.0的‘后悔药’失效分析
VMware ESXi版本回退深度解析:从技术原理到实战避坑指南 在虚拟化运维领域,版本升级往往伴随着不可预知的风险。当新版本出现兼容性问题或性能异常时,版本回退能力就成为系统管理员手中的"后悔药"。然而,不同于普通软件…...

RT-Thread aarch64虚拟平台文件系统移植实战:从QEMU virt到LittleFS
1. 项目概述与核心价值最近在折腾RT-Thread的aarch64虚拟平台,特别是qemu-virt64-aarch64这个BSP(Board Support Package,板级支持包)上的文件系统支持。这看起来像是一个很具体的移植工作,但实际上,它触及…...

终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘
终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker 你是否曾经因为复杂的命令行操作而对Linux系统安装望而却步?或者面对…...

AI VTuber技术栈全解析:从Live2D到GPT-SoVITS的实战搭建指南
1. 项目概述:为什么我们需要一份AI VTuber的“Awesome”清单? 如果你最近在GitHub、B站或者一些技术社区里逛过,大概率会看到一个词反复出现: AI VTuber 。它不再是科幻电影里的概念,而是正在快速渗透到直播、内容创…...

海洋AI工具集seait:从数据处理到模型部署的工程实践指南
1. 项目概述:一个面向“海洋”的AI工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫seait。第一眼看到这个名字,我下意识地把它拆成了“sea”和“it”,心想这大概是个和海洋或者海事相关的IT工具。点进去一看&am…...