机器学习-生存分析:如何基于随机生存森林训练乳腺癌风险评估模型?
一、 引言
乳腺癌是女性最常见的恶性肿瘤之一,也是全球范围内女性死亡率最高的癌症之一。据统计,每年全球有超过200万人被诊断为乳腺癌,其中约60万人死于该疾病。因此,乳腺癌的早期诊断和风险评估对于预防和治疗乳腺癌具有非常重要的意义。
近年来,机器学习和生存分析等数据挖掘技术在乳腺癌研究中得到了广泛应用。这些方法可以挖掘患者的临床、基因、影像等多种数据,预测患者的生存期、疾病进展和治疗效果,为临床决策提供科学依据。其中,随机生存森林算法作为一种有效的生存分析方法,已经在乳腺癌研究中得到了广泛应用。
本文旨在探讨基于随机生存森林算法进行乳腺癌风险评估模型训练的方法。具体而言,我们将收集乳腺癌患者临床、基因和影像等多种数据,进行预处理后,使用随机生存森林算法训练乳腺癌风险评估模型,并分析模型性能和特征重要性。通过本研究,我们希望能够为乳腺癌早期诊断和风险评估提供一种新的方法和思路。
二、乳腺癌风险评估模型
2.1 传统风险评估方法局限性
传统的乳腺癌风险评估方法主要基于临床特征和家族史等风险因素,如Gail模型和Tyrer-Cuzick模型。然而,这些方法存在一些局限性。首先,它们仅考虑了有限的风险因素,忽略了其他潜在的重要因素,如基因表达和影像学特征等。其次,传统方法通常采用线性回归模型,无法捕捉非线性关系和交互作用。最后,由于传统方法对数据的假设较强,对异常值和缺失值较为敏感。
2.2 随机生存森林算法简介
随机生存森林算法是一种基于决策树的机器学习方法,可以用于生存分析和风险评估。与传统方法相比,随机生存森林算法具有以下优势:
-
首先,它可以处理多种数据类型,包括连续型、离散型和分类型数据,以及高维数据。 -
其次,该算法能够自动选择特征,并且能够处理非线性关系和交互作用。 -
此外,随机生存森林算法对异常值和缺失值具有较好的鲁棒性。
2.3 为何选择随机生存森林
本文选择随机生存森林作为乳腺癌风险评估模型的训练算法,原因如下:首先,随机生存森林算法可以处理多种数据类型,包括临床、基因和影像等多种数据,使得模型能够充分利用多源数据的信息。其次,该算法能够自动选择特征,从而减少了人工特征工程的复杂性。最后,随机生存森林算法能够捕捉非线性关系和交互作用,提高了乳腺癌风险评估模型的预测性能。
通过选择随机生存森林算法作为乳腺癌风险评估模型的训练算法,我们希望能够克服传统方法的局限性,并提高乳腺癌风险评估的准确性和可靠性。
三、实例展示
-
「数据集准备」
library(survival)
head(gbsg)
结果展示:
pid age meno size grade nodes pgr er hormon rfstime status
1 132 49 0 18 2 2 0 0 0 1838 0
2 1575 55 1 20 3 16 0 0 0 403 1
3 1140 56 1 40 3 3 0 0 0 1603 0
4 769 45 0 25 3 1 0 4 0 177 0
5 130 65 1 30 2 5 0 36 1 1855 0
6 1642 48 0 52 2 11 0 0 0 842 1
-
「示例数据集介绍」
> str(gbsg)
'data.frame': 686 obs. of 10 variables:
$ age : int 49 55 56 45 65 48 48 37 67 45 ...
$ meno : int 0 1 1 0 1 0 0 0 1 0 ...
$ size : int 18 20 40 25 30 52 21 20 20 30 ...
$ grade : int 2 3 3 3 2 2 3 2 2 2 ...
$ nodes : int 2 16 3 1 5 11 8 9 1 1 ...
$ pgr : int 0 0 0 0 0 0 0 0 0 0 ...
$ er : int 0 0 0 4 36 0 0 0 0 0 ...
$ hormon : int 0 0 0 0 1 0 0 1 1 0 ...
$ rfstime: int 1838 403 1603 177 1855 842 293 42 564 1093 ...
$ status : Factor w/ 2 levels "0","1": 1 2 1 1 1 2 2 1 2 2 ...
age:患者年龄
meno:更年期状态(0表示未更年期,1表示已更年期)
size:肿瘤大小
grade:肿瘤分级
nodes:受累淋巴结数量
pgr:孕激素受体表达水平
er:雌激素受体表达水平
hormon:激素治疗(0表示否,1表示是)
rfstime:复发或死亡时间(以天为单位)
status:事件状态(0表示被截尾,1表示事件发生)
-
「划分训练集和测试集」
# 划分训练集和测试集
set.seed(123)
data <- gbsg[,c(-1)]
train_indices <- sample(x = 1:nrow(data), size = 0.8 * nrow(data), replace = FALSE)
test_indices <- sample(setdiff(1:nrow(data), train_indices), size = 0.2 * nrow(data), replace = FALSE)
train_data <- data[train_indices, ]
test_data <- data[test_indices, ]
-
「构建随机生存森林模型」
library(randomForestSRC)
rfsrc_fit <- rfsrc(Surv(rfstime,status)~.,
ntree = 100,
nsplit = 5,
importance = TRUE,
tree.err=TRUE,
data=train_data)
rfsrc_fit
结果展示:
> rfsrc_fit
Sample size: 548
Number of deaths: 241
Number of trees: 100
Forest terminal node size: 15
Average no. of terminal nodes: 24.85
No. of variables tried at each split: 3
Total no. of variables: 8
Resampling used to grow trees: swor
Resample size used to grow trees: 346
Analysis: RSF
Family: surv
Splitting rule: logrank *random*
Number of random split points: 5
(OOB) CRPS: 0.15674136
(OOB) Requested performance error: 0.29986439
-
「模型结果可视化(变量重要性和误差)」
plot(rfsrc_fit)

-
「绘制树结构」
plot(get.tree(rfsrc_fit,3))

-
「绘制生存曲线」
plot.survival(rfsrc_fit,subset=1:6)

# 绘制前6个特征的生存曲线
matplot(rfsrc_fit$time.interest,
100*t(rfsrc_fit$survival.oob[1:6,]),
xlab = "time",
ylab = "Survival",
type="l",lty=1,
lwd=2)

-
「计算Brier score并绘图」
# 1. 采用km法计算Brier score
bs_km <- get.brier.survival(rfsrc_fit,
cens.model = "km")$brier.score
head(bs_km)
# 2. 采用rfsrc法计算Brier score
bs_rsf <- get.brier.survival(rfsrc_fit,
cens.model = "rfsrc")$brier.score
head(bs_rsf)
结果展示:
# km
> head(bs_km)
time brier.score
1 72 0.001880723
2 98 0.003769397
3 120 0.007472802
4 160 0.008729987
5 171 0.012496130
6 173 0.014353439
# rfsrc
> head(bs_rsf)
time brier.score
1 72 0.001880938
2 98 0.003772356
3 120 0.007461321
4 160 0.008692986
5 171 0.012499945
6 173 0.014383175
绘制图形并比较:
plot(bs_km,type="s",col=2,lwd=3)
lines(bs_rsf,type = "s",col=4,lwd=3)
legend("bottomright",
legend = c("cens.model"="km",
"cens.moedl"="rfs"),
fill = c(2,4))

-
「变量重要性」
importance <- subsample(rfsrc_fit)
plot(importance)

-
「绘制部分依赖图(PDP)」
# 1. 连续变量:age对事件发生率的影响
partial_obj <- partial(rfsrc_fit,
partial.xvar = "age",
partial.type = "mort",
partial.values = rfsrc_fit$xvar$age,
partial.time = rfsrc_fit$time.interest)
pdta <- get.partial.plot.data(partial_obj)
plot(lowess(pdta$x, pdta$yhat, f = 1/3),
type = "l", xlab = "age", ylab = "adjusted mortality")

# 2. 分类变量:grade对事件发生率的影响
grade <- quantile(rfsrc_fit$xvar$grade)
partial.obj <- partial(rfsrc_fit,
partial.type = "surv",
partial.xvar = "grade",
partial.values = grade,
partial.time = rfsrc_fit$time.interest)
pdta <- get.partial.plot.data(partial.obj)
## plot partial effect of gradefsky on survival
matplot(pdta$partial.time, t(pdta$yhat), type = "l", lty = 1,
xlab = "time", ylab = "gradefsky adjusted survival")
legend("topright",
legend = paste0("grade = ", unique(grade)), fill = 1:3)

-
「优化节点参数」
tune.nodesize(Surv(rfstime,status) ~ ., data)
结果展示:
> tune.nodesize(Surv(rfstime,status) ~ ., data)
nodesize = 1 error = 33.31%
nodesize = 2 error = 32.82%
nodesize = 3 error = 32.01%
nodesize = 4 error = 33.09%
nodesize = 5 error = 33.88%
nodesize = 6 error = 33.13%
nodesize = 7 error = 33.12%
nodesize = 8 error = 32.78%
nodesize = 9 error = 32.79%
nodesize = 10 error = 31.9%
nodesize = 15 error = 33.69%
nodesize = 20 error = 33.31%
nodesize = 25 error = 33.49%
nodesize = 30 error = 34.14%
nodesize = 35 error = 34.17%
nodesize = 40 error = 33.66%
nodesize = 45 error = 33.94%
nodesize = 50 error = 33.13%
nodesize = 55 error = 34.57%
nodesize = 60 error = 34.56%
nodesize = 65 error = 35.26%
nodesize = 70 error = 35.12%
nodesize = 75 error = 33.26%
nodesize = 80 error = 49.99%
nodesize = 85 error = 49.99%
nodesize = 90 error = 49.99%
optimal nodesize: 10
$nsize.opt
[1] 10
$err
nodesize err
1 1 0.3330546
2 2 0.3282237
3 3 0.3201412
4 4 0.3309179
5 5 0.3388146
6 6 0.3312895
7 7 0.3311966
8 8 0.3277592
9 9 0.3279450
10 10 0.3190264
11 15 0.3368636
12 20 0.3330546
13 25 0.3349127
14 30 0.3414158
15 35 0.3416945
16 40 0.3365849
17 45 0.3393720
18 50 0.3313359
19 55 0.3456893
20 60 0.3455964
21 65 0.3526106
22 70 0.3512170
23 75 0.3325901
24 80 0.4999071
25 85 0.4999071
26 90 0.4999071
优化后的最佳节点数为10。
四、结论
本文的研究目的是开发一个乳腺癌风险评估模型,以提高对乳腺癌患者的早期诊断和预测能力。为了实现这一目标,我们介绍了传统风险评估方法的局限性,并引入了随机生存森林算法作为乳腺癌风险评估模型的训练算法。
乳腺癌是女性最常见的恶性肿瘤之一,早期诊断和预测对于患者的治疗和生存率至关重要。本文提出的乳腺癌风险评估模型具有潜在的价值和应用前景。
首先,该模型可以为医生和患者提供更准确的乳腺癌风险评估结果,帮助医生制定个性化的预防和治疗方案。其次,该模型可以帮助筛查高风险人群,并提供早期诊断的指导,从而提高乳腺癌的生存率。此外,该模型还可以用于辅助临床决策、优化资源分配和指导公共卫生政策。
然而,需要注意的是,乳腺癌风险评估模型仍处于研究阶段,还需要进一步的验证和改进。同时,随着技术的不断进步和数据的积累,乳腺癌风险评估模型的性能和应用前景也将进一步提升。
总之,本文的研究为乳腺癌风险评估提供了一种新的方法,并展示了随机生存森林算法在乳腺癌风险评估中的潜力。这一研究对于乳腺癌的早期诊断和预测具有重要的临床意义和实际应用价值。
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
相关文章:
机器学习-生存分析:如何基于随机生存森林训练乳腺癌风险评估模型?
一、 引言 乳腺癌是女性最常见的恶性肿瘤之一,也是全球范围内女性死亡率最高的癌症之一。据统计,每年全球有超过200万人被诊断为乳腺癌,其中约60万人死于该疾病。因此,乳腺癌的早期诊断和风险评估对于预防和治疗乳腺癌具有非常重要…...

MySQL学习笔记1: 数据库的简单介绍
目录 1. 数据库是什么2. 数据库这一类软件中的一些典型代表2.1. Oracle2.2. MySQL2.3. SQL Server2.4. SQLite (lite 轻量版) 3. 数据库的类型3.1. 关系型数据库3.2. 非关系型数据库 4. 总结 1. 数据库是什么 数据库是一类软件,这一类软件可以用来管理数据…...
)
【Docker】安装ELK(Docker Compose)
一、创建挂载目录 mkdir -p /docker/elk/elasticsearch/{plugins,data} mkdir -p /docker/elk/logstash 二、给目录授权 chmod 777 /docker/elk/elasticsearch/data 创建logstash配置文件 vim /docker/elk/logstash/logstash.conf input {tcp {mode => "server" h…...

【机器学习:欧氏距离 】机器学习中欧氏距离的理解和应用
【机器学习:欧氏距离 】机器学习中欧氏距离的理解和应用 距离公式二维更高的维度点以外的物体属性欧几里得距离的平方概括历史 在数学中,欧氏距离’是指欧氏空间中任意两点之间的直线距离。这种距离可以通过应用勾股定理来计算,利用两点的笛卡…...

系统安全及应用
1、基本安全措施 1.1、系统账号清理 在Linux系统中,除了用户手动创建的各种账号之外,还包括随系统或程序安装过程而生产的其他大量账号。除了超级用户root之外,其他大量账号只是用来维护系统运作、启动或保持服务进程,一般是不允…...

Danil Pristupov Fork(强大而易用的Git客户端) for Mac/Windows
在当今软件开发领域,团队协作和版本控制是非常重要的方面。在这个过程中,Git成为了最受欢迎的版本控制工具之一。然而,对于Git的使用,一个好的客户端是至关重要的。 今天,我们要为大家介绍一款强大而易用的Git客户端—…...
最新GPT4.0使用教程,AI绘画,ChatFile文档对话总结+GPT语音对话使用,DALL-E3文生图
一、前言 ChatGPT3.5、GPT4.0、GPT语音对话、Midjourney绘画,文档对话总结DALL-E3文生图,相信对大家应该不感到陌生吧?简单来说,GPT-4技术比之前的GPT-3.5相对来说更加智能,会根据用户的要求生成多种内容甚至也可以和…...

【ARM 嵌入式 编译系列 7.2 -- GCC 链接脚本中 DEFINED 函数与 “AT>“ 符号详细介绍】
文章目录 GCC 链接脚本中 DEFINED 函数DEFINED() 函数> (放置在哪个区域)AT> (加载地址) (填充字节) 在链接脚本中,组合示例 GCC 链接脚本中 DEFINED 函数 在 ARM GCC 链接脚本(.ld 文件)中,DEFINED() 是一种内置函数&…...
Linux基础——进程初识(二)
1. 对当前目录创建文件的理解 我们知道在创建一个文件时,它会被默认创建到当前目录下,那么它是如何知道当前目录的呢? 对于下面这样一段代码 #include <stdio.h> #include <unistd.h>int main() {fopen("tmp.txt", …...

国科大图像处理2024速通期末——汇总2017-2019、2023回忆
国科大2023.12.28图像处理0854期末重点 图像处理 王伟强 作业 课件 资料 一、填空 一个阴极射线管它的输入与输出满足 s r 2 sr^{2} sr2,这将使得显示系统产生比希望的效果更暗的图像,此时伽马校正通常在信号进入显示器前被进行预处理,令p…...
)
编程笔记 html5cssjs 026 HTML输入类型(2/2)
编程笔记 html5&css&js 026 HTML输入类型(2/2) 输入类型:date输入类型:color输入类型:range输入类型:month输入类型:week输入类型:time输入类型:datetime输入类型…...
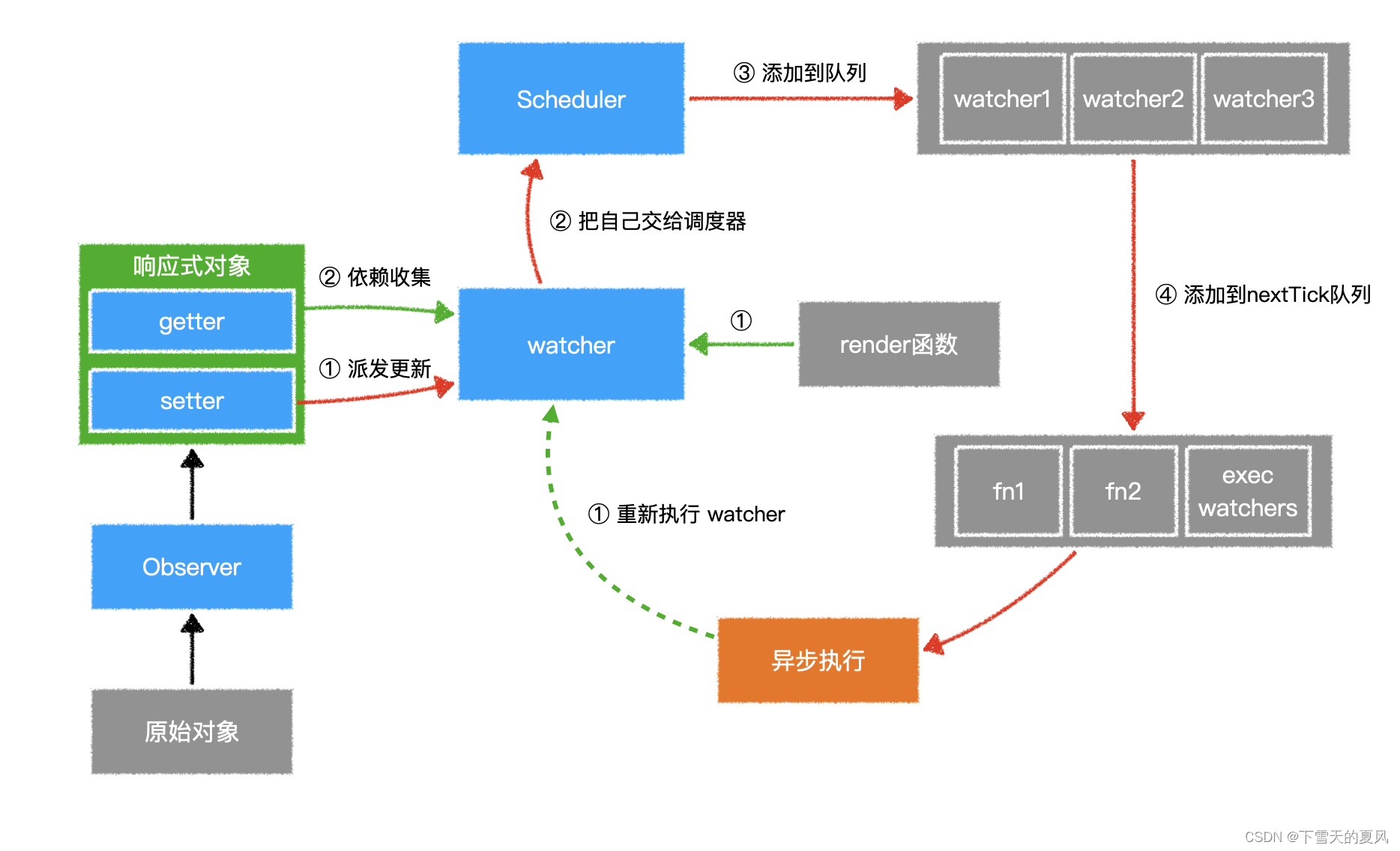
Vue2 - 数据响应式原理
目录 1,总览2,Observer3,Dep4,Watcher5,Schedule 1,总览 vue2官网参考 简单介绍下上图流程:以 Data 为中心来说, Vue 会将传递给 Vue 实例的 data 选项(普通 js 对象&a…...

基于华为云解析服务实现网站区域封禁
前言 中国大陆以外的网络攻击不断,个人博客时常遭受不明个人或组织的攻击,给网站的安全运行带来了巨大的风险,同时DDoS、CC攻击等还会消耗服务器的资源,站长可能需要因此支付高昂的服务器、CDN的流量费用。 因此,如果…...

在 Docker 中配置 MySQL 数据库并初始化 Project 项目
1. 文件准备 1.1. 添加 SQL 文件头部内容 每个 SQL 文件的头部需要添加以下内容: DROP DATABASE IF EXISTS xx_..; CREATE DATABASE xx_..; USE xx_..;1.2. 修改 AUTO_INCREMENT 在每个 SQL 文件中,将 AUTO_INCREMENT 修改为 1。 1.3. 插入机型 在 SQL…...
生活中的物理3——神奇陷阱(随机倒下的抽屉柜门)
1实验 材料:大自然(风)、抽屉门松掉的抽屉 实验 1、找一个大风的日子,打开窗户(不要找下雨天,不然你会被你亲爱的嫲嫲KO) 2、让风在抽屉面前刮过 3、你发现了什么??&…...

数模学习day08-拟合算法
这里拟合算法可以和差值算法对比 引入 插值和拟合的区别 与插值问题不同,在拟合问题中不需要曲线一定经过给定的点。拟 合问题的目标是寻求一个函数(曲线),使得该曲线在某种准则下与所 有的数据点最为接近,即曲线拟…...
第13课 利用openCV检测物体是否运动了
FFmpeg与openCV绝对是绝配。前面我们已经基本熟悉了FFmpeg的工作流程,这一章我们重点来看看openCV。 在前面,我们已经使用openCV打开过摄像头并在MFC中显示图像,但openCV能做的要远超你的想像,比如可以用它来实现人脸检测、车牌识…...
C#之反编译之路(一)
本文将介绍微软反编译神器dnSpy的使用方法 c#反编译之路(一) dnSpy.exe区分64位和32位,所以32位的程序,就用32位的反编译工具打开,64位的程序,就用64位的反编译工具打开(个人觉得32位的程序偏多,如果不知道是32位还是64位,就先用32位的打开试试) 目前只接触到wpf和winform的桌…...

使用CentOS 7.6搭建HTTP隧道代理服务器
在现代网络环境中,HTTP隧道代理服务器因其灵活性和安全性而受到广泛关注。CentOS 7.6,作为一个稳定且功能强大的Linux发行版,为搭建此类服务器提供了坚实的基础。 首先,我们需要明确HTTP隧道代理的基本原理。HTTP隧道代理允许客户…...

Swift爬虫使用代理IP采集唯品会商品详情
目录 一、准备工作 二、代理IP的选择与使用 三、使用Swift编写唯品会商品爬虫 四、数据解析与处理 五、注意事项与优化建议 六、总结 一、准备工作 在开始编写爬虫之前,需要准备一些工具和库,以确保数据抓取的顺利进行。以下是所需的工具和库&…...
)
YOLOv8花生种子霉变识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 本文基于YOLOv8目标检测算法,构建了一套火焰烟雾检测系统,并对两类目标(有火/烟、无火/烟)进行了训练与评估。实验使用自建数据集,共包含训练集248张、验证集77张、测试集42张。实验结果表明,模型在测…...
)
Vue2项目里,用lodash的debounce给搜索框‘降降温’(附完整代码和常见坑点)
Vue2实战:用lodash的debounce优化搜索框性能与避坑指南 搜索框是Web应用中最高频的交互组件之一,但处理不当可能成为性能黑洞。当用户快速输入"vue"、"react"等关键词时,传统实现会为每个字符触发搜索请求,导…...

如何用MAA自动化助手彻底解放你的《明日方舟》游戏时间:5个实用技巧
如何用MAA自动化助手彻底解放你的《明日方舟》游戏时间:5个实用技巧 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址…...


26-cv-2777、26-cv-2964、26-cv-3022、26-cv-3949、26-cv-4062、26-cv-5488 Winnie Rosaline Kan 版权画维权!
案号:26-cv-2777、26-cv-2964、26-cv-3022、26-cv-3949、26-cv-4062、26-cv-5488原告品牌:Winnie Rosaline Kan 版权画品牌方:Casetagram Limited起诉地:美国伊利诺伊州代理律所:Keith起诉时间:2026年03月1…...

我的技术博客从0到月入过万,用了这五个变现路径
很多测试同行问我:“每天写测试用例、提Bug、做自动化,这些重复性的工作内容,真能写成文章还有人看?”我的答案是:不仅能,而且测试人做技术博客,有着其他岗位难以复制的独特优势。因为我们每天都…...

Git多用户代理架构解析:实现细粒度权限管理与统一访问入口
1. 项目概述:从单兵作战到团队协作的代码管理跃迁如果你是一个独立开发者,或者在一个小团队里,你可能习惯了把代码往GitHub、Gitee这样的平台上一扔,设置个私有仓库,然后通过个人账号的SSH密钥来管理访问权限。这种方式…...

终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘
终极指南:3分钟掌握Deepin Boot Maker,轻松制作Linux启动盘 【免费下载链接】deepin-boot-maker 项目地址: https://gitcode.com/gh_mirrors/de/deepin-boot-maker 你是否曾经因为复杂的命令行操作而对Linux系统安装望而却步?或者面对…...

XXMI启动器终极指南:一站式游戏模组管理平台,轻松实现二次元游戏个性化
XXMI启动器终极指南:一站式游戏模组管理平台,轻松实现二次元游戏个性化 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款功能强大的开源游…...

第5章 集群初始化
本章说明: 集群初始化是 Kubernetes 部署过程中最核心的一步。本章使用 kubeadm 在 master01 节点上初始化高可用集群控制平面。初始化时需要指定 VIP(192.168.3.59:6443)作为控制平面统一入口,这样后续加入的其他 Master 节点和 Worker 节点都通过 VIP 访问 API Server,…...